
浅析Python爬虫获取数据实现调查研究的应用*
2021-06-03 04:55张勇常骁毅蒿花耿辉通讯作者
科学与信息化 2021年14期
张勇 常骁毅 蒿花 耿辉(通讯作者)
1. 西安交通大学第一附属医院国有资产管理办公室 陕西 西安 710061;2. 西安交通大学第一附属医院体检部 陕西 西安 710061
随着大数据时代的来临,数据规模、类型呈几何式增长,为从海量的信息数据里获取有价值的数据,衍生了网络爬虫,这是一种按研究人员设定获取信息源的规则,根据一定的算法编程实现自动地抓取网络信息数据的程序,研究人员获取到这些信息数据后,再进行数据清洗、加工,构建信息调查的信息数据基础。本文在已发表的文献的基础上,介绍Python构建爬虫获取数据进行信息调查的过程。
1 示例数据简介
本文以Emma等[1]2017年发表的信息调查“阿尔茨海默病患者及护理人员在网络社区寻求解决方案和情感支持”为例,介绍Python爬虫实现信息调查的方法。该研究的过程分为3个阶段,第一阶段使用以Python编程语言编写爬虫获取从2012年4月至2016年10月在alzconnected.org的Caregiver论坛中公开的2500个帖子及其各自的解决方案,第二阶段对这些帖子及其4219份回复进行了分析,第三阶段对分析的结果进行描述,大多数帖子(26%)与阿尔茨海默症症状的查询有关,而最高比例的答案(45.56%)与照顾者的健康状况有关。alzconnected.org网站有可能成为护理人员的情感支持渠道,但是,需要一个更加友好的界面来满足大多数护理人员分享技术技能等的需求。
2 Python构建爬虫的准备工作
首先登录网站分析网站结构,第一步获取初始的URL,初始URL地址可以人为地指定,也可由研究人员指定的某个或某几个目标网页决定;第二步根据初始的URL爬取页面并获得新的URL,获得新的URL地址后,爬取当前URL地址信息,解析网页内容,将网页有价值信息数据存储到CSV或数据库等存储介质中;第三步将上一步获取的URL整理成队列,从队列中读取新的URL,从而获得新的网页信息,解析新网页内容并单独存储;第四步设置爬虫系线设置的停止条件, 条件满足时停止获取数据退出程序。为保证能够快速搭建爬虫应用,本文使用集成安装环境Anaconda。
2.1 Anaconda的安装
Anaconda是一个开源的Python发行版本,直接去官网https://www.anaconda.com 下载安装就可以,安装过程中需要注意的一点是钩选Anaconda加入系统变量。
2.2 Google Chrome浏览器的开发者工具介绍
为方便浏览网页中有价值信息数据的源代码位置,需要使用Google Chrome浏览器的开发者工具。按F12(或快捷键Ctrl+Shift+i)调出开发者工具 。Chrome开发者工具最常用的4个功能模块:ELements、Console、Sources、Network。Elements:可查看或修改HTML的属性、CSS属性、设置断点、监听事件等。Console:用于执行一次性代码,查看动态数据对象,分析调试信息或异常信息等。Sources:用于查看需获取数据页面的HTML文件源代码、CSS源代码、JavaScript源代码,也可以调试JavaScript源代码,尝试添加断点给JS代码等。Network:查看网页数据与网络连接加载的相关时间等信息。
因本文需要使用到Elements,下面详细介绍Google Chrome浏览器的元素(Elements)使用方法及技巧,在网页分析及爬虫代码编写过程中,查看元素的代码,实现网页元素信息的快速定位是最关键的一点,使用Elements中左上角的箭头图标(或按快捷键Ctrl+Shift+C)进入选择元素模式,滑动鼠标从网页中选择需要查看的元素,然后可以在开发者工具元素(Elements)一栏中定位到该元素源代码的具体位置,从源代码中读出改元素的属性。
2.3 网页架构分析
Emma等[1]2017年发表的信息调查论文数据来源为:阿尔茨海默病患者及护理人员网络社区,即:该社区ALZConnected®(alzconnected.org)由阿尔茨海默氏症协会®提供支持,是一个免费的在线交流社区,面向受阿尔茨海默病或其他痴呆症影响的每个人,包括:患有这种疾病的人及其照顾者、家庭成员、朋友等,其网络地址为:https://www.alzconnected.org。
从首页https://www.alzconnected.org/进入网站,点击F12打开开发人员工具,Emma等研究信息数据主要来源于:Caregivers Forum(看护人论坛),用Elements标签的快速定位工具定位后Caregivers Forum是包含在:一组源代码的a标签里,其中的href为加载在网络地址后面的一组跳转地址,即:https://www.alzconnected.org加上discussion.aspx?g=topics&f=151成为一个全链接可以跳转到Caregivers Forum(看护人论坛)里,如图1所示:

图1 Elements标签的快速定位示意图
https://www.alzconnected.org/discussion.aspx?g=topics&f=15为点击跳转到Caregivers Forum(看护人论坛)的网络地址,这点可以通过点击Caregivers Forum按键跳转后的网络地址来验证。进入Caregivers Forum(看护人论坛)后,依旧利用快速定位工具,查看文档标题元素所在位置及其跳转地址,如图2所示:
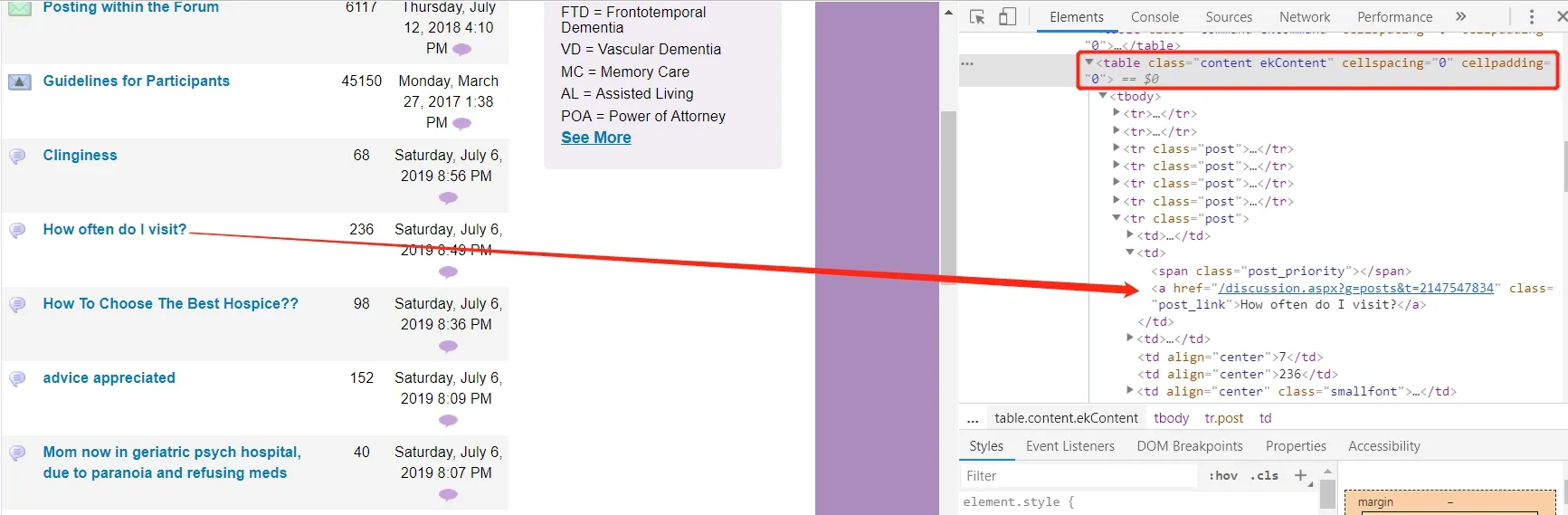
图2 标题元素所在位置及跳转地址
文档标题所在的table为:class=”content ekContent”的下拉地址里,XAPTH地址为:table class=”content ekContent”/tbody/tr/td[2]/a的a标签里面,即:网络地址和问题的text都可以在tbody标签里tr标签包含的第二个td的a标签里找到相应的href属性和text属性。
接下来找到爬虫程序的停止条件,当点击网页上的“last”跳转到网站的最后一页时,会出现“<<”样的标识,用Elements标签的定位,即“<<”和“<<”是等价的,在爬虫程序里既可以使用“<<”也可以使用“<<”的出现作为爬虫的停止条件。
3 依据网页的架构设计Python爬虫的核心技术
爬取阿尔茨海默病网络社区网站共分三步:第一步,指定爬虫获取信息数据入口;第二步,获取讨论主题下的问题目录;第三步,获取目录下的文章内容和回帖内容;第四步,存储以上内容到CSV或SQL等存储介质。
3.1 Python爬虫指定爬虫获取信息数据入口
首先给爬虫定义获取信息数据入口的domain和需要抓取Caregivers Forum(看护人论坛)的url,分别定义为domain和base_url:domain = ‘https://www.alzconnected.org’,base_url = domain + ‘/discussion.aspx?g=topics&f=151’。
3.2 获取Caregivers Forum论坛下的帖子目录
找到domain和base_url后根据题目所在网页源码位置,写入相应代码:etr_obj.xpath(‘//*[@id=“ctl00_ctl00_MainContent_ContentPlaceHolderRightSide_Forum1”]/table[2]/tbody/tr[7]/td[2]/a/font/font’)。定义需要爬取帖子目录的url:board[‘board_url’] = columns[0].xpath(‘a’)[0].attrib[‘href’],定义需要爬取帖子所在位置board[‘board_name’] = columns[0].xpath(‘a’)[0].text。之后循环拿出所有帖子目录,以及帖子所在的url(定义为board_url),再进入url获取分目录里的每一行的需要的信息:接着进入帖子目录,拿到帖子标题、发表时间和一系列有用的信息,在获取帖子目录的时候先判断目录共有页,只确定最后一页作为爬虫程序的停止条件即可:找到页码所在的位置,根据“<<”这个符号判断是否最后一页。确定了停止条件后进行循环抓取每页的数据,到最后一页结束程序,获取数据的主要代码如下:

爬出每一页的text就行。
3.3 获取目录下的帖子内容和回帖内容
获取帖子目录下的所有帖子及回帖内容,首先爬虫需获取每个帖子的跳转地址,地址用:topic_url进行定义,代码为:def get_content(self, topic_url, page): querystring = {“ajax”:””,”p”:str(page)},得到的topic_url地址和domain结合构造出帖子及回帖的url地址:url = self.domain + topic_url,让爬虫查找源代码获取帖子及回帖内容的文本代码所在位置并下载数据:c_eles = self.tree.xpath(‘//td class=”message ekMessage”’)。和获取帖子目录的方式一样得到最大页数,执行循环,爬取到最后一页为止跳出循环,查找下一问题url,遍历循环,获取所有内容。
3.4 爬虫的数据存储模块分类
3.4.1 文本存储。新建一个文本txt进行存储,代码为:with open(‘文本.text’,‘w’,encoding=‘utf-8’)as f: f.write(),写入完成后关闭text文件: f.close()。
3.4.2 csv表格存储。新建一个文本csv进行存储,首先引入csv库:import csv,with open(‘文本.csv’,‘w’, newline=‘’)as f,fieldname = [‘需要存储的数据名称’],writer = csv.DictWriter(f, fieldnames = fieldname),写入存储数据即可。
3.4.3 数据库存储。用Python命令创建数据库和表,将数据逐条存入数据库的表内,如图3所示,将页面上读取到的有价值的信息或者将处理过的信息存储到数据库中,以便以后分析时使用。Python支持的数据库包括Oracle、MySQL等所有主流数据库。

图3 Python命令创建数据库和表示意图
3.5 对爬虫获取数据进行处理
Emma等[1]使用了LIWC分析工具处理爬虫获取的数据,LIWC分析工具是Pennebaker等人在研究情绪书写的治疗效果时发明了基于计算机软件程序的文本分析工具—— 语言探索与字词计数(简称 LIWC),一种可以对文本内容的词语类别(尤其是心理学类词语)进行量化分析的软件,它的英文版本下载地址为:http://liwc.wpengine.com,类似的中文LIWC分析网站为:http://ccpl.psych.ac.cn/textmind。将爬虫爬取结果复制到LIWC分析工具里,点击分析,得到分词结果,进行分析,爬虫获取数据结果如图4所示。将结果中的Topics列,复制进LIWC分析工具里进行分析,如图5所示:

图4 爬虫获取数据结果

图5 数据进行LlWC分析
Emma等[1]获取到阿尔茨海默病患者论坛的数据后,利用LIWC分析工具对帖子和回复都进行了分析,论坛上的帖子传达最多的是照顾者从心碎到强烈愤怒的情感变化,分析还显示大多数帖子(26%)与有关阿尔茨海默病症状的查询有关,而最高比例的回复(45.56%)与照顾者的健康有关。
4 结束语
网络爬虫获取数据非常高效便捷,并且可以更新实时数据,2018年Python在IEEE顶级程序语言排行榜中排名第一,具有专业的数据统计和机器学习等高质量扩展库,尤其是Python语言构建爬虫获取数据进行临床研究,国内学者已有广泛应用:2017年学者卞伟玮等运用聚焦网络爬虫技术快速、准确地获得公共卫生服务系统的医疗数据,为健康风险评估模型提供数据基础[2]。2018年学者熊丹妮等运用网络爬虫获取医疗服务平台信息与《2016中国卫生和计划生育统计年鉴》的相关数据进行对比[3]。2018年学者罗春花利用网络爬虫软件搜集了全国30个地区的等级医院数据,从省级和经济区划单元两个层面对医疗服务能力的空间资源配置进行分析[4]。
研究人员通过Python爬虫获取到有价值信息数据后,进行数据清洗、加工,构建信息调查的数据基础,本文在已发表文献的基础上,介绍Python构建爬虫获取数据进行信息调查的过程。主要是将页面上读取到的有价值的信息或者将处理过的信息存储到数据库中,以便以后分析、抓取时使用。研究人员运用Python语言进行信息调查的过程为:①Caregivers Forum(看护人论坛)后,依旧利用快速定位工具,查看文档标题元素所在位置及其跳转地址;②只确定最后一页作为爬虫程序的停止条件即可:找到页码所在的位置,根据“<<”这个符号判断是否最后一页。③用熟悉的方式存储数据,数据存储格式姚方便后期处理数据。④运用LIWC分析工具处理爬虫获取的数据,得到结果并分析。其中需要注意的是爬虫获取数据后存储的格式要利于后期数据处理,否则还要进行数据转换,避免增加不必要的工作量。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
现代信息科技(2021年21期)2021-05-07
现代信息科技(2021年21期)2021-05-07
数码设计(2019年5期)2019-12-20
电子制作(2018年2期)2018-04-18
农家书屋(2016年11期)2016-12-23
小雪花·成长指南(2016年11期)2016-12-07
世界汽车(2016年9期)2016-09-29
小品文选刊(2009年7期)2009-05-25
杂文选刊(2006年20期)2006-05-14
