
基于异构SoC卷积神经网络加速器的设计与实现
2021-06-03 10:06曾春明
现代计算机 2021年9期
曾春明
(四川大学计算机学院,成都610065)
0 引言
2012年AlexNet在Image Net LSVRC中获得冠军,卷积神经网络(CNN)成为了计算机图像分类识别领域的核心热门算法,并推动了深度学习的大爆发。从第一个CNN模型LeNet-5到第一个DCNN(深度卷积神经网络)模型AlexNet,再到VGG、GoogLeNet、ResNet,网络层数已经从几层发展到了上百层。其中,ResNet从理论上证明了CNN网络模型层数的增加带来了越来越好的理论数据拟合能力。同时算量对硬件资源的要求越来越高,包括大量的浮点数计算、超高的内存占用、总线数据搬移时延、高功率等。理论研究中的模型在边缘推理端的商用部署中并不友好,包括硬件成本高、能耗高、性能实时性弱等缺点。在工业领域,深度学习产品的商用落地已越来越迫切。商用落地包括云端和边缘端。云端依靠着强大的服务器硬件系统,其商用落地已实现,多是用于模型训练和高精度大模型的推理。然而边缘端多是移动类平台,其硬件性能不足、功率受限等缺点限制着深度学习产品的部署落地。同时,边缘端难以部署深度学习产品的情况也会加大云端服务器压力,导致云端服务器承担大量模型推理计算工作,其带宽成本、硬件成本、维护成本、维护难度等都将上升。因此,边缘端深度学习产品的商用落地,已经成为一个重要的研究课题。
为促进深度学习产品更好落地,早期有学者提出了一些压缩网络模型来加速网络计算。2013年Misha等人[1]通过矩阵低秩分解的方法减少了深层网络模型的多态参数数量。2014年Hinton等人[2]通过以知识蒸馏为基础的teacher-student框架,将大型神经网络学习到的先验知识通过蒸馏迁移到模型更加轻巧的小型神经网络上,在保持较好性能的同时,也达到了网络模型压缩的目的。2016年Han等人[3]通过设定阈值的方式完成了对大型冗余网络的神经元裁剪,并对权重参数进行K-means聚类量化来减少权重参数占用的存储空间。同时,量化将浮点数转化为定点数以减少对算力的需求。2016年Andrew Lavin等人[4]提出CNN的Winograd算法,通过减少卷积运算中乘法次数来加速卷积运算。2017年Zhang等人[5]以分组卷积为基础,人工设计出稀疏连接的轻量网络ShuffleNet,对算力和存储空间的要求减少至可部署在移动设备上。2017年Google提出NAS[6]技术和TPU计算架构,NAS技术通过网络架构搜索的方式代替人工设计来寻找最优化的神经网络架构,TPU是基于脉动阵列而设计的专用高速神经网络计算芯片以配合CPU完成神经网络的前向推理运算。
综合上述研究,神经网络的推理加速主要包括三个层次:在网络架构层,设计低冗余高性能的轻量网络;在算子层,设计高效的算子实现算法;在硬件层,设计高并行算力和高吞吐量访存架构;本文针对算子层和硬件层进行研究。在算子层上,提出一种差异化渐进型量化方案,以兼顾加速模型推理和降低量化网络模型带来的精度损失的问题。在硬件层上,基于异构SoC设计高并行计算架构以加速卷积层算子、BN层算子、激活层算子的运算速度。
1 量化方法
量化技术是通信领域的一门技术,量化技术会产生数据压缩的效果。信息熵是信息量的度量,如公式(1)。一个事件xi发生的概率越小,若其发生了,其携带的信息量就越大。深度神经网络的量化技术是将多个小概率事件合并为一个大概率事件。因此信息量的损失取决于量化的程度。卷积神经网络通常由多个算子层构成,每一层的本质是对输入数据进行特征提取得到特征图m,并将特征图m作为下一层的输入数据。网络浅层输出的特征图m保留了原输入数据更多的信息量。在经过多层特征提取后,网络深层的输入和输出特征图都是更加利于模式匹配和计算的抽象特征数据;每一层输出特征图m的信息越完整,最终网络输出的精度会越理想。现有的量化技术将所有可量化层采用同等程度的量化操作,如float32量化为int8,其每层损失信息量的比例近似,并未对不同的网络层采用不同的量化策略。差异化量化采用逐层加强量化程度的思想来减少量化带来的信息损失,达到更好的近似原模型输出精度的目的。
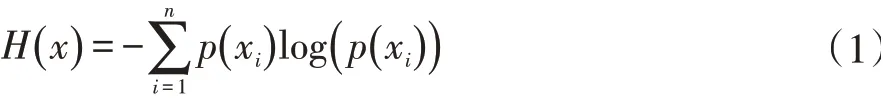
1.1 量化建模
假设原数据为n bit浮点数,量化目标为m bit定点数,其关系可表示为式子(2)。其中,s为待定系数,式子(2)的原型为式子(3)。

进一步,为了达到量化的效果,采用分段函数改进式子(2)为式子(4)。

其中,Seg(x)为式子(5):
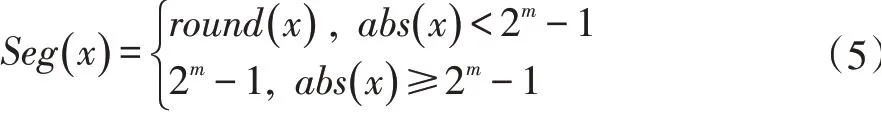
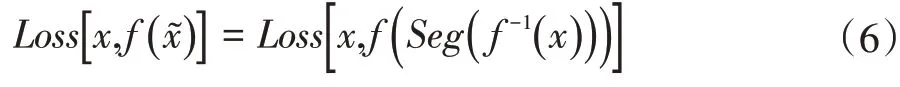
本文从局部最小误差的角度考虑,针对每一个量化数据进行误差度量,将Loss函数设置为L2范数。则具体Loss函数为式子(7)。
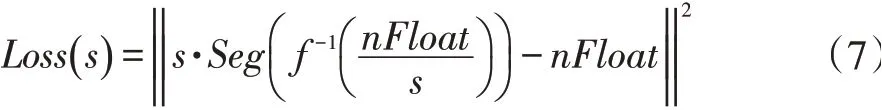
Loss函数值为最小值时的s*值时,量化数据为最优,s*是式子(8)的解,本文采用不动点迭代法式子(9)进行求解。
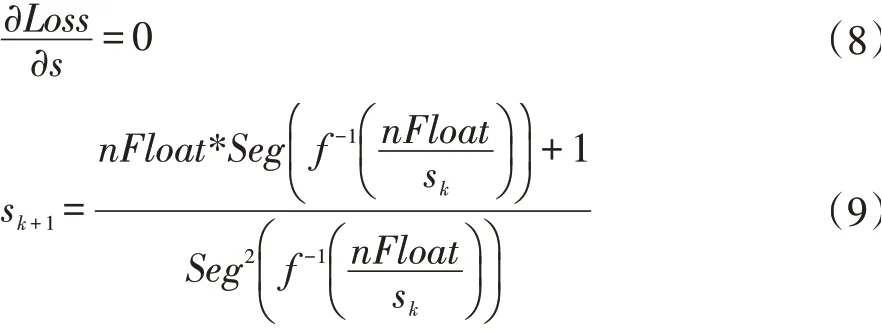
1.2 卷积量化
卷积层占用了卷积神经网络的大部分运算时间,卷积的计算本质上是乘法和加法运算,如公式(10)。其中是第k个通道的输入特征图的元素值是第k个通道的卷积核值是第k个通道卷积运算后的输出结果。

公式(10)的运算是32位浮点数运算。该量化模型在进行卷积计算之前,根据1.1小节量化公式,先将权重参数和输入特征图参数进行m bit量化操作后再进行卷积运算。量化后在CPU等片上Cache里可以缓存更多低比特数据且可减少访存频率,低比特数据的运算占用的硬件时钟数也更少。
1.3 模型预处理
卷积神经网络一般由输入层、卷积层、激活层、全连接层等组成。本文采用的ResNet-50网络模型主要包括卷积层、批归一化、激活层、池化层等。卷积层计算本质上是大量浮点数的乘累加操作,公式如下:

在神经网络训练阶段,通常会引入批规范化层(BN层)以解决梯度爆炸、收敛速度慢等问题,同时还能提高模型精度。批规范化层的计算如公式(12):
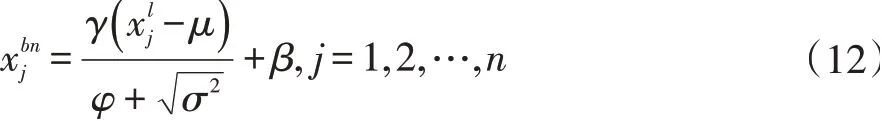

在神经网络推理阶段,BN层作为一层独立神经网络层已不是必要,但BN层在推理阶段却占用了一层额外推理运算时间且占用了更多软硬件计算资源。在神经网络模型中,批规范化层通常都是放在卷积层之后。因此,本文将批规范化层的参数与卷积层的权重参数合并,将双层融合为一层,在减少参数的同时也可提高神经网络前向推理速度。将公式(11)带入公式(12)中,可得:
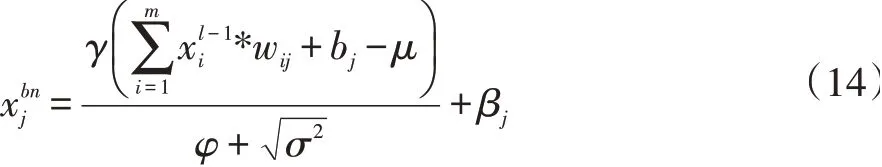
展开整理后可得:
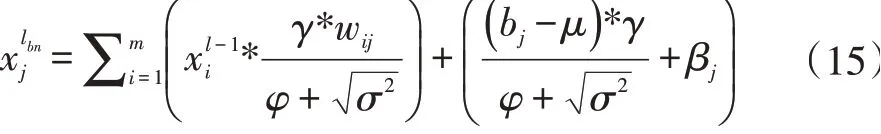
由公式(14)和(15)可得融合后的卷积计算公式如下:
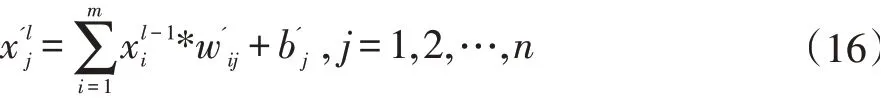
2 加速系统的设计
本文先采用第1小节提出的量化方法对网络模型进行量化预处理,以减少模型的参数数量、单个参数占用空间大小和网络层数。本文设计的异构量化加速系统由输入模块、负载分流模块、卷积加速模块、输出模块构成。
2.1 输入模块
输入模块的输入是RGB三通道图像,该模块负责对输入图像像素值进行预处理,其预处理结果采用第1.2小节的量化方法进行量化,量化后的预处理图像将输入到加速系统进行推理计算。
2.2 加载模块
网络模型参数通过第2节的量化算法进行量化后被保存在外存的模型文件中。CPU从外存读取模参数文件,将参数文件加载DDR内存中,并通过AXI总线将参数文件在内存缓冲区的信息配置给加载模块,加载模块在进行网络加速计算时,可以将网络模型的参数加载进卷积加速模块的Block RAM片上存储器中,从而完成与输入特征图的卷积加速计算。
2.3 卷积加速模块
卷积加速模块采用HLS高层次综合工具实现FPGA的硬件编码。卷积加速模块包括多个卷积加速核,为了实现多通道卷积并发运算,每个卷积加速核负责一个通道的卷积运算。由于每个特征图会被送入多个卷积神经元进行卷积计算,为了实现特征图数据复用,减少DDR内存访存次数和释放AXI总线带宽消耗,多个通道的特征图会被流式缓存在卷积加速模块的全局缓冲区中,卷积加速模块中的多通道卷积加速核共享全局缓冲区中的输入特征图数据进行多通道卷积运算。采用HLS实现卷积加速模块时,每个卷积加速核的算法采用HLS流水线和循环展开进行设计。
2.4 输出模块
卷积加速模块完成所有通道的卷积运算后,输出模块负责将运算结果合并处理以得到下一层的输入特征图。经过多次加速循环计算之后,最后一层的运算结果将返回到ARM中完成分类计算。
3 实验设计及结果分析
3.1 实验设计
本文的加速系统是基于软硬件协同设计完成加速。在ARM端移植Linux操作系统和修改Caffe深度学习框架基础上,卷积层的运算将通过主从调度方式分配给FPGA卷积加速模块进行加速运算。本文采用多线程自旋询问的方式等待卷积加速模块完成加速计算,运算结果通过AIX总线回写到DDR内存中供CPU进行后续计算。实验选择ResNet-50分类网络模型进行实验,采用ImageNet数据集作为训练集和测试集。
实验包括两个部分,分别测试不同量化方案对分类精度的影响和在异构加速系统上的加速效果。实验第一个部分采用第1.2小节的量化方法对ResNet-50网络由浅到深逐层进行差异化量化,测试在不同量化策略对网络分类Top1的精度影响;实验第二个部分分别测试量化的ResNet-50模型单独在ARM下和在异构加速系统下的加速比。
3.2 实验结果与分析
不同量化策略对网络模型精度和加速比的实验数据如表1。ResNet-50网络模型的卷积层输入特征图主要尺寸是56×56、28×28、14×14和7×7四类,针对不同的层由浅入深分别采用32bit、16bit、8bit进行差异化量化。
针对实验一的实验结果可以看出,对不同的层采用不同的量化策略会出现不同的精度损失。量化的程度越大,加速比越高。与在ARM下的推理时间相比,异构加速系统的最小加速比为2.86,最大加速比为11.43。其中,最小加速比与最大加速比为3.99倍,同时Top1精度比值为1.044,精度损失相对百分比为4.22%。

表1 ResNet-50不同量化策略下的精度和加速比
4 结语
本文提出了一种基于异构SoC的卷积神经网络加速系统,通过差异化量化方案对不同的神经网络层进行量化,并在ZCU102开发板上验证了本文提出的方法,使用ImageNet数据集在ResNet-50分类网络上进行Top1精度和加速比的测试,精度损失在可接受范围中的最大加速比可达到11.43,可满足移动边缘端嵌入式设备的神经网络产品的部署需求。本文的差异化量化方案是人工制定,后续的研究将考虑加入自动化量化方案,针对通用的自动化量化方案进行研究。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
计算技术与自动化(2022年1期)2022-04-15
煤气与热力(2022年2期)2022-03-09
小猕猴智力画刊(2021年11期)2021-11-28
上海师范大学学报·自然科学版(2019年5期)2019-12-13
高中生·天天向上(2018年7期)2018-07-23
新高考·高二数学(2017年6期)2018-03-29
