
面向多属性推荐系统的对抗深度分解模型
2021-06-03 06:41:12李宗阳沈志宏
计算机技术与发展 2021年5期
李宗阳,吉 源,沈志宏
(1.中国科学院 计算机网络信息中心,北京 100190;2.悉尼大学,悉尼 NSW2000)
0 引 言
推荐系统在各种在线电子商务网站和旅游门户网站中备受重视。传统的推荐系统通常对二维用户-项目评分数据进行操作,试图预测用户对特定项目(如产品)的偏好或评分。
近年来,除了用户项目评分外,各大网站平台还收集了各种有价值的信息。特别是,不同结构的信息,如购买意图、时间、地点、同伴和活动内容,都可被用来提高推荐性能[1-9]。在线网站中的非结构化文本评论通常包含用户对产品或服务的意见、态度和偏好,并在各种个性化推荐中与用户-项目评分数据一起被利用[10-14]。
相比之下,在这项工作中,除了考虑用户对项目的总体评分数据外,还考虑了多个属性的用户对项目的评分来解决推荐问题。在许多的电子商务网站上,除了总体评分外,在线用户通常还可以根据产品或服务的多个给定属性或方面对其满意度进行评分。
基于多个用户在各种不同属性上的项目评分以提供建议的系统,通常被称为多属性推荐系统(multi-criteria recommender system,M-CRS)。在过去的几年里,研究者们在处理多属性推荐系统方面做出了很大的努力。现有的方法大致可以分为三类,分别是基于启发式邻域的方法、基于聚合的方法和基于模型的方法。基于邻域的启发式方法首先通过使用各种多属性相似性度量并基于用户邻域的已知评分来预测用户的未知评分,从而为目标用户找到一个邻域列表[15-19]。尽管推荐结果是可以解释的,但是基于邻域的方法往往受到原始评分数据稀疏的影响,并且在处理大型数据集时可能无法扩展。假设总体项目评分和个别属性特定评分之间存在某种关系,基于聚合的方法尝试在它们之间构建聚合函数,然后应用该函数聚合多个属性特定评分以进行预测[17,20-24]。相比之下,基于模型的方法主要用于利用观察到的多属性评分数据开发预测模型,然后使用该模型预测用户对未知项目的评分[25-31]。不同的推荐方法对实际的推荐问题具有很强的鲁棒性,因此该文采用了基于学习模型的方法来解决多属性推荐问题。
张量分解在多属性推荐系统中得到广泛应用。张量是矩阵的多维扩展,是用于建模多面数据的应用程序中非常强大的工具。张量分解是基于模型的技术的里程碑。已针对多属性推荐系统开发了各种张量分解技术[32-33]。但是,所有用于多属性建议的现有技术都存在数据稀疏和污染的问题。换句话说,由于评分张量非常稀疏,并且在实际应用程序中包含恶意用户的虚假信息,因此产生的潜在因素仍然不足以实现令人满意的性能。
为了克服多属性推荐器系统中的数据稀疏和污染问题,该文尝试将辅助信息合并到评级张量中,以利用先验特征,并使用对抗性学习来防御来自假信息的攻击。 通常,辅助信息在传统的单属性推荐也称为边信息(side information)[10-14]。
但是,如何将辅助信息有效地整合到评分张量中,以及如何利用对抗性学习来增强模型的鲁棒性在该方案下仍是挑战。
为了克服这两个挑战,该文通过集成深度表示学习和张量因子分解提出了对抗性深度张量因子分解(ADTF)的方案,其中嵌入了辅助信息以有效补偿张量稀疏性,而对抗性学习则用于增强模型稳健性。
通过结合对抗性堆叠降噪自动编码器(adversarial stacked denoising autoencoder,ASDAE)和CANDECOMP / PARAFAC(CP)张量因子分解,展示了ADTF方案下的实例,其中用户和项目的辅助信息与稀疏的多属性评分和潜在因子在联合优化学习下紧密相关。一方面通过堆叠降噪自动编码器(stacked denoising autoencoder,SDAE)对用户和商品的边信息进行编码,以分别补偿用户和商品的塔克分解潜在因素。并使用梯度方法更新了三个潜在因子矩阵。另一方面,对抗训练用于学习中间层的有效潜在因素,而不是放在SDAE的外部输入上。
该文的贡献可总结如下:为了解决多属性建议中的数据稀疏和污染问题,提出了一种将深度结构和张量因子分解相集成的通用架构,嵌入了辅助信息以有效补偿张量稀疏性,并且采用了对抗性学习以增强模型的鲁棒性;基于通用体系结构提出一种特定的ADTF方案,其中CP张量分解和两个针对用户和项目的ASDAE结合在一起,以改进基于张量分解的建议;在三个真实数据集上的实验结果表明,在多属性推荐方面,提出的ADTF优于最新方法。
1 相关工作
1.1 多属性推荐系统
在推荐系统中已广泛使用多属性评分,现有的技术可以简单地分为三类,包括基于启发式邻域的方法、基于聚合的方法和基于模型的方法。基于启发式邻域的方法尝试使用各种多属性相似性度量来收集目标用户的邻居,然后基于这些邻居的已知评分估计未知评分[15]。Lakiotaki等人[16]使用多维距离度量计算成对用户之间的距离,然后采用多属性协同过滤方法确定每个用户最喜欢的项目。Liu等人[17]提出了一种基于用户偏好的偏好格来预测未知项的评分。Mikeli等人[18]利用多属性欧氏距离估计每对用户之间的总距离,并利用协同过滤技术解决推荐问题。Sreepada等人[19]提出了一种新的技术来学习每个用户偏好的属性以及使每个项目流行的属性。此学习有助于找到相似的用户/项目组,以便向用户推荐适当的项目。尽管推荐结果通常是可以解释的,但是基于邻域的方法往往受到原始评分数据的稀疏性的影响,并且在处理大型数据集时可能无法扩展。
假设总体用户评价与单项目属性评价之间存在一定的关系,基于聚合的方法主要是建立映射函数来聚合多个特定属性的评价进行预测。Lakiotaki等人[20]提出了一种效用加性方法,在给定的推荐属性下对边际用户的偏好进行综合。Jannach等人[21]提出使用支持向量回归来学习个别属性特定评分的相对重要性,然后使用加权方法将基于用户和项目的回归模型结合起来预测未知评分。Zheng[22]提出应考虑多个属性之间的依赖性,提出了一种基于属性链的多维度评分汇总推荐方法。Hamada等人[23]提出了一种基于聚合函数的方法,利用自适应遗传算法有效地融合了多属性推荐系统的属性评分,提高了多属性推荐系统的准确性。
另一方面,基于模型的方法旨在利用观察到的多属性评分数据学习预测模型,然后利用该模型估计用户对未知项目的评分[24]。Sahoo等人[25]提出了一种基于概率混合模型的算法,利用多属性评分依赖结构改进推荐。Nilashi等人[26]提出了一种基于自适应神经模糊推理和自组织地图聚类模型的推荐方法。Hamada等人[27]为提高推荐系统的预测精度,提出了一种基于模糊集和系统的结构和主要特征的推荐模型。Li等人[28]利用多线性奇异值分解技术,研究推荐任务的用户、项目和属性之间的显式和隐式关系。Hassan等人[29]提出了一种使用模拟退火算法训练的神经网络模型,以提高多属性推荐系统的预测精度。Tallapally等人[30]提出了一种扩展的叠层自动编码器来有效地学习每个用户的属性和总体评分之间的关系。
与上述工作不同的是,该文考虑了多属性推荐中的数据污染问题,并通过对抗训练和引入额外信息,来提高推荐系统的鲁棒性。
1.2 推荐系统中的对抗训练
推荐系统容易受到恶意用户的攻击,这些恶意用户会制作一些虚假信息进行数据污染,从而使得推荐模型的推荐结果偏离原始数据分布,从而导致推荐中的错误[34]。
最近,对抗性机器学习技术在各种任务(例如图像字幕,序列生成,图像到图像翻译,神经机器翻译和信息检索)上显示出了出色的性能。
尽管展示了巨大的潜力,但在推荐系统中应用对抗性机器学习技术的工作很少[35-36]。Wang等人[35]提出了一种minimax对抗游戏,以减少传统训练模型对对抗示例的敏感性,这成为了三种不同任务的最新方法,包括网络搜索、问题解答和项目推荐。He等人[36]通过选择具有成对损失函数的模型,将对抗性噪声引入训练过程来改进信息检索GAN(IRGAN)。
与先前的工作不同,该文进一步利用了将边信息纳入CP分解中的优势,以解决多属性建议中的数据稀疏问题,在多属性推荐系统中,通过对抗性训练来解决数据污染问题。
2 问题描述
先前的研究表明,矩阵分解及其变体是现代推荐系统中使用的主要技术[32-33]。在这一节中,将介绍矩阵分解技术的一些初步内容,并在表1中给出一些相关的符号。
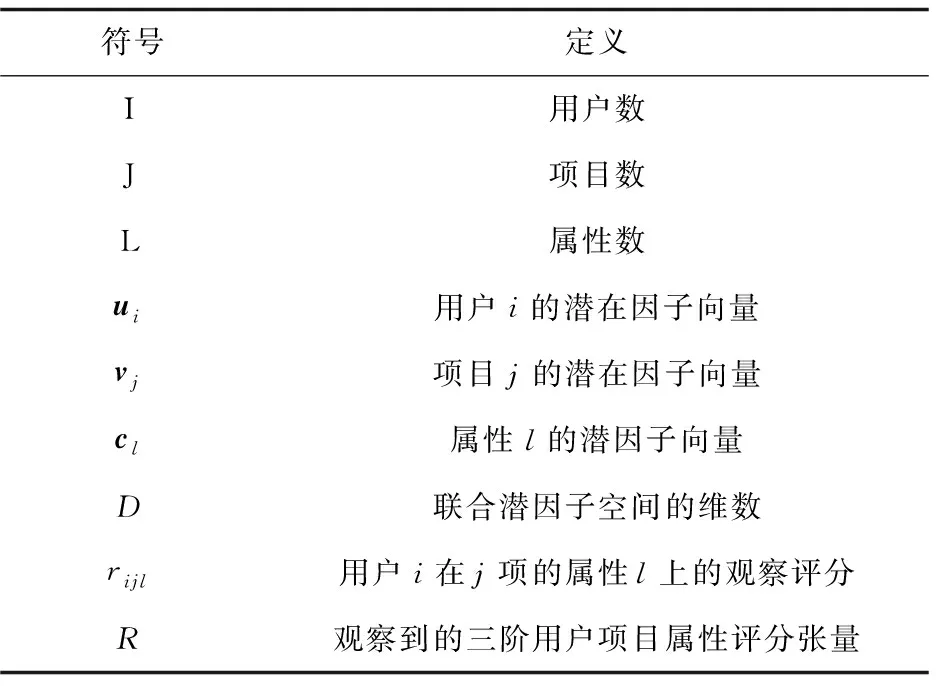
表1 符号定义
在推荐系统中,矩阵分解模型常被用于处理用户和项目之间的二维偏好关系,其中矩阵允许每个用户在[1-5]的5分评分表上任意对给定项目进行评分。
然后,基于已知的评分数据,将用户和项目投影到一个联合的潜在因子空间,使得用户项目偏好可以建模为该空间中潜在因子的内积。形式上,设um从用户m的矩阵因式分解模型导出的潜在因子表示,in为项目n的潜在表示。然后,可由此估计项目i的用户m的偏好评分rmn。
(1)
显然,推荐系统的关键挑战是如何在联合潜在因素空间中导出用户和项目的表示。为了实现这一点,使用等式(2)将观察到的用户项评分数据集的正则化平方损失最小化。
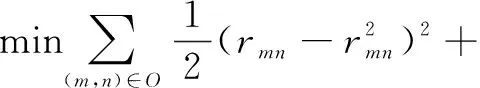
α(‖um‖1+‖in‖1)
(2)
其中,O是指用户项对的集合(m,n),其值rmn是已知的。第一项是预测误差的平方,第二项和第三项分布是L2范数,L1范数正则化,控制了模型复杂度,其中α和β是超参数。
公式(2)中的优化问题可以用经典的随机梯度下降法来解决,该方法迭代更新用户和项目的潜在因素向量[37]。一旦优化过程完成,公式(1)便可用于直接预测给定用户对未知项的评分。
通常,多属性推荐系统(MCRSs)是指除了支持推荐的总体用户项目评分之外,还利用各种不同属性的用户项目评分的系统。如文献[15]所述,MCR的公式如下:
U×V×C→R0×R1×…×RL-1
(3)
其中,左侧的U、V和C分别是用户、项目和属性的集合,而右侧的R0表示用户对项的总体评分,R1,…,RL-1表示用户对单个属性的评分(L为属性数)。在公式中,总体评分信息被视为一种特殊类型的属性评分。
给定观察到的用户项目属性评分数据,首先通过拟合观察到的数据建立多属性预测模型,然后应用该模型预测用户对未知项的总体评分和多属性特定评分。
自然地,引入一个三阶张量(矩阵的推广)来表示三维用户项目属性评分数据。
3 面向多属性推荐系统的对抗深度张量网络
基于张量分解的方法已广泛应用于多属性推荐系统[15-19]。但是,它们遭受数据稀疏和污染的困扰。事实证明,深度学习模型可以有效地从原始数据中发现各种任务的潜在表示[29-37]。对抗训练方法通过动态生成对抗示例来增强训练过程。为了改善基于张量分解的建议,利用深度学习和对抗训练有效地合并了辅助信息,从而使所得模型克服了上述缺点。
3.1 通用架构
该文提出的ADTF尝试将深度结构与张量分解结合起来,其中深度结构处理附带信息,而张量分解处理3D 用户项目属性评分数据。
为用户构建深层结构,其中分别将用户的真实和虚假辅助信息作为输入。通过联合优化网络和张量因子分解潜在用户的因子,学习到有效的用户潜在表示。
类似地,对物品构建同样的深层结构,其中将物品的真实和虚假辅助信息作为输入。通过联合优化深度网络和张量因子分解项目的潜在因子,可以学习项目的有效潜在表示。
辅助信息参与学习有效的潜在表示,这为张量分解提供了有效的知识迁移,而对抗训练则防御了来自虚假信息的攻击,因此所提出的对抗深度张量网络的通用架构可以缓解稀疏张量和数据污染问题。在通用架构的基础上,通过集成ASDAE和CP张量分解来提出特定的实例。
3.2 面向多属性推荐系统的对抗深度张量网络ADTF实例
基于上面提到的通用体系结构,特定的ADTF方案由三个组件组成:用户的ASDAE、项目的ASDAE和张量分解。如图1所示,在ADTF中,单个ASDAE会将真实和伪造的辅助信息都作为输入,而通过判别器进行对抗训练,通过自编码器进行特征提取。
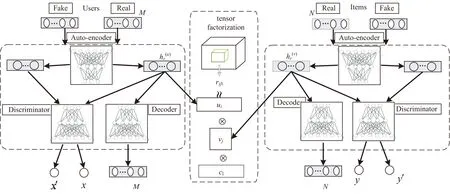
图1 对抗深度张量网络结构
(4)
并获得最终输出层L(u)的输出为:

(5)


ADTF通过以下目标函数从评分张量和辅助信息中学习用户的潜在因子、项目的潜在因子和属性潜在因子。
(6)
其中,总损失函数J由五个部分组成:张量分解的损失函数Lt,辅助信息的重构误差函数Lr,深度表示和潜在因子之间的近似误差函数La,对抗训练的重构误差函数Ld和防止过度拟合的正则化项freg之间的损失函数。
第一项Lt表示稀疏评级张量上的因式分解损失,其公式为:
(7)
其中,θt={U,V,C};二元张量I是稀疏性指标,其中每个元素指示是否观察到了相应的等级;⊗表示潜在因子向量在上述相应矩阵中的外积;⊙是按元素相乘。
第二项为辅助信息对于用户和物品的重建成本,其公式为:
(8)
其中,θr={Wu,bu,Wv,bv},α和β是惩罚参数。
第三项,用户和项目的深度表示和潜在因子向量之间的近似误差,公式为:
(9)
其中,θa={Wu,bu,Wv,bv,U,V},ρ和γ是惩罚参数。
对抗训练的损失函数公式表示为:
(10)

最后一项为正则化项freg,约束整个网络,其公式如下:

‖W(v)‖2+‖b(u)‖2+‖b(v)‖2
(11)
在公式(6)中,Θ=θt∪θr∪θa。
3.3 算法优化过程
张量分解与神经网络的结合难以通过统一的神经网络参数回传进行更新,而为了同时取得张量分解的高效性和神经网络的有效性,通过分布迭代优化而不是联合优化。
该文针对ADTF提出的分步迭代优化,通过使用以下两步过程来实现。
步骤I:给定所有神经网络的权重W与偏置b,u、v、c,对总损失函数J在公式中的梯度可以通过以下方式获得:
(12)
其中,Iijl指示是否观测到相应的评分。计算得到梯度后,统一进行梯度更新。
步骤II:固定潜在因子向量U、V和C,所有神经网络的权重W与偏置b可以通过SGD方法的反向传播来训练两个ASDAE:
(13)
(14)

(15)
循环迭代两个步骤,直到收敛为止。
通常,两个SDAE的中间层调节多属性评分和边缘信息的相互作用,以学习潜在因子。这两个中间层是使ADTF能够同时学习有效的潜在因素并捕获用户和项目之间的相似性和关系的关键。
4 实 验
4.1 实验设置
为了评估算法,该文使用了来自TripAdvisor、Yahoo!Movie和RateBeer的数据集,这三个数据集都被广泛用于多属性推荐系统的评估。在实验中,对每个数据集的实验结果进行五次交叉验证,并采用平均绝对误差(MAE)、命中率(HR)和归一化折现累积增益(NDCG)来评估推荐性能:
(17)
MAE越低,推荐性能越好。
(18)
其中,Hits@K是推荐列表中显示的目标项目数,GT是真实项目集。
(19)
其中,ZK确保排名结果的值范围为[0,1],ri是位置i处项目的评分。HR和NDCG越高,推荐性能越好。
通过多属性推荐实验,对提出的方法ADTF进行了验证。
4.2 实验对比方法
AFBM[9]:基于聚合函数的方法(aggregation function based method),使用矩阵分解将观察到的用户标准评级数据分解为因子,然后使用学习模型根据单个标准(不包括特殊总体标准)估算用户的评级。
CMF[10]:集合矩阵分解模型(collective matrix factorization),可联合分解多个不同矩阵,包括用户项目矩阵和包含附加边信息的矩阵;
HCF[11]:混合协同过滤模型(hybrid collaborative filtering),融合了矩阵分解和aSDAE模型;
DCF[12]:深度协作过滤(deep collaborative filtering)是一种广泛使用的深度学习推荐模型,结合了概率矩阵分解与降噪堆叠自动编码器来实现推荐效果;
t-SVD[24]:张量奇异值分解(tensor singular value decomposition)是将MF方法推广到更高维度的张量分解模型;
DTF:将文中的ADTF去除对抗训练模块,用于对比对抗训练模块的效果;
ADTF:文中所提出的对抗性深度张量因子分解模型(adversarial deep tensor factorization,ADTF),在深度学习网络中融合评分张量和辅助信息,并经过对抗训练以增强模型鲁棒性。
4.3 实验结果及分析
表2列出了评估方法的评分预测精度,其中每个数据集的最低MAE用黑体突出显示。
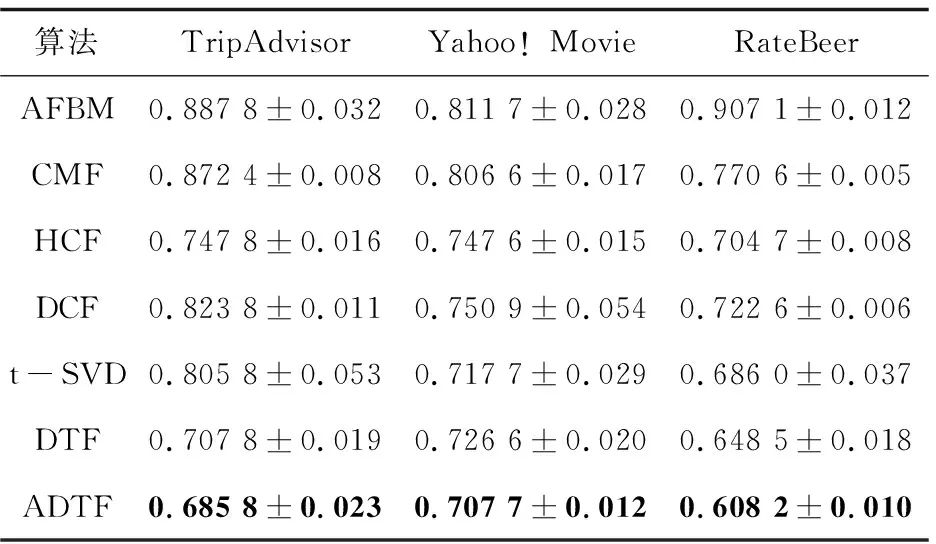
表2 不同算法在数据集上的MAE性能
可以看出,ADTF在MAE方面明显优于目前的对比方法。表2的实验结果表明,提出的基于张量因子分解的多属性评分信息联合建模方法,能够考虑用户、项目和属性维度之间的相关性,提高预测性能。相比之下,AFBM采用支持向量回归的方法对属性信息进行聚合,只考虑了用户与属性、项目与属性等三个维度中任意两个维度之间的相关性。t-SVD和ADTF的效果说明张量因子分解非常适合MCRS,因为它是一种很好的建模三维(即用户、项和属性)之间内在交互的方法。
可以看出,在一般情况下,HCF,DCF和CMF优于AFBM,而ADTF和DTF又优于t-SVD,这表明在2D评分矩阵或3D评分张量中合并辅助信息的有效性。ADTF,DTF,HCF和DCF优于CMF,表明深度结构可以更好地获取边信息的特征。HCF,DCF,CMF和AFBM仅考虑三个维度中任意两个维度之间的相关性,因此ADTF,DTF和t-SVD优于这些方法。ADTF的性能优于DCF,这表明张量分解方法可以有效地学习三个维度之间的内在相互作用,这对于多准则推荐系统是一个很好的选择。ADTF的性能优于DTF,这表明对抗训练可以有效提高深度学习网络的鲁棒性。

(a)HR@K (b)NDCG@K

(a)HR@K (b)NDCG@K
(a)HR@K (b)NDCG@K
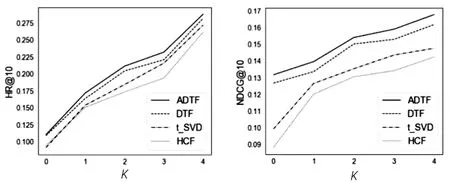
为了进一步评估Top-K项目推荐,图2~图4显示了三个数据集上不同方法的性能,其中潜在因子数设置为10。
图2~图4中推荐列表K的长度不固定,而是通过考虑K取值2到10之间来评估方法在不同Top-K场景下的推荐效果。这里,选择的K最大到10,是因为用户通常会只关注一些最重要的建议,而实际应用场景中,通常访问频率最高的也仅限于前十的推荐建议。可以观察到,随着K的增加,由于目标项目出现在Top-K列表中的可能性将会提高,因此得到的性能如预期一样得到改善。在三个数据集、不同场景下的Top-K推荐中,ADTF都取得了最好的效果,证明了提出的方法的有效性和鲁棒性。
5 结束语
该文提出对抗深度张量因子分解模型(ADTF)进行推荐,将深度表示学习和张量因子分解相结合。ADTF可以从评分张量和辅助信息中学习有效的潜在因子。在实际数据集上的实验结果表明,ADTF在评分预测任务和Top-K推荐任务上的表现优于最新模型。未来的工作中,将考虑改进辅助信息的合并方式和对抗性训练网络,以在多标准推荐系统中实现更好的性能。
猜你喜欢
数学物理学报(2021年4期)2021-08-30 08:27:50
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
中等数学(2020年1期)2020-08-24 07:57:42
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年8期)2020-01-02 04:45:23
商用汽车(2016年11期)2016-12-19 01:20:16
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
商用汽车(2016年6期)2016-06-29 09:18:54
商用汽车(2016年4期)2016-05-09 01:23:12
