
面向软件缺陷预测的网络嵌入特征研究
2021-06-02 08:35:12刘靖雯晋武侠金洋旭
信息安全学报 2021年3期
刘靖雯, 晋武侠,2, 屈 宇, 金洋旭, 范 铭
1西安交通大学 陕西省智能网络与网络安全教育部重点实验室, 西安 中国 7100492西安交通大学 软件学院 西安 中国 710049
3美国加州大学河滨分校计算机科学与工程系 河滨 美国加州 92521
4中国银行软件中心 西安 中国 710038
1 引言
现代软件系统需求不断增多, 系统日渐复杂, 维护代码变得越来越费时费力, 导致复杂软件系统的缺陷和漏洞难以避免。国内外历史上出现过多次由于软件缺陷而导致的重大事故[1], 预测软件代码缺陷以有效保证软件可信性成为普遍关注的问题。软件缺陷预测[1-4]是使用代码复杂性和变更历史等软件特征构建分类器以预测可能包含缺陷的代码区域的过程, 该技术可提前发现潜在的缺陷和漏洞。近年来, Promise数据集和美国国家航空航天局项目(NASA数据集[5])的开源共享进一步推动了学术界在缺陷预测领域上的广泛研究。
根据缺陷预测使用的软件特征的不同, 已有的软件缺陷预测工作可分为基于代码度量特征的预测[6-8]和基于网络度量特征的预测[9-10]。传统代码度量特征主要包括Halstead特征[6], 基于依赖性的McCabe特征[7], 面向对象程序的CK特征[8]等, 但难以刻画软件的结构特征。网络度量特征基于软件实体间的依赖关系[11]构成的网络来度量结构特性, 例如自我中心网络的连接点、边数[4]等等, 但在高维的网络结构空间上度量结构特性, 复杂性较高。
为了降低网络结构特征表示的复杂性, 近年来网络嵌入(Network Embedding)算法研究取得重大进展。网络嵌入[12]的核心思想是, 在保持网络结构特性(一阶相似度、二阶相似度等)的同时, 将高维稀疏的网络结构或者图结构映射到低维稠密的向量空间。这种嵌入后的网络特征便于输入到机器学习模型中。嵌入方法主要包括基于矩阵分解的方法[13-14]、基于随机游走的方法[15-16]、基于深度学习的方法[17]。网络嵌入目前已应用到网络压缩[18-20]、可视化[21-23]、聚类[24]、链路预测[25-27]和节点分类[28]等不同领域。近年来软件关联网络嵌入也开始应用于软件缺陷预测领域, 然而, 不同软件关联网络以及不同网络嵌入算法对缺陷预测性能的影响研究仍然很稀缺。
本文将应用6种网络嵌入算法在12个开源的Java软件系统上, 研究基于网络嵌入特征的缺陷预测, 并在缺陷预测场景中深入分析网络嵌入算法保持的软件结构特征。首先, 从源代码层次、软件演化层次、开发者贡献层次分别构建软件关联网络, 从多层次刻画软件系统的结构。然后, 提出了一种基于网络嵌入和传统度量特征相结合的缺陷预测模型, 并分析不同软件关联网络上的缺陷预测性能。最后, 在缺陷预测场景中深入研究网络嵌入特征, 分析不同网络嵌入算法所保持的软件关联网络结构的差异以及导致缺陷预测性能差异的原因。具体工作如下:
(1) 构建3种软件关联网络模型。通过解析软件系统的源代码, 构建类层次依赖网络; 基于修订历史记录中文件的共同修改信息, 构建文件耦合网络; 通过挖掘开发者对程序模块的提交操作, 构建开发者贡献网络。
(2) 设计基于网络嵌入特征的缺陷预测模型。该模型通过网络嵌入算法学习软件关联网络的结构特征, 将高维稀疏网络结构编码至低维稠密向量空间; 并解决缺陷预测中常见的非平衡数据集问题。实验发现, 在传统的代码度量特征和网络度量特征上, 结合网络嵌入特征后, 缺陷预测性能平均提高了至少2%。
(3) 对比分析6种网络嵌入算法在构建的3种软件关联网络上通过随机森林、朴素贝叶斯、支持向量机和多层感知器的缺陷预测效果。实验发现: 使用DeepWalk、Grarep和Node2vec嵌入算法的缺陷预测效果最好, LINE和GF最差; 此外, 同一种算法在类依赖网络和文件耦合网络上的缺陷预测效果比开发者贡献网络要好; 随机森林分类模型可以在任意网络中得到最优的缺陷预测性能。
(4) 比较6种网络嵌入算法保持的软件关联网络的结构特性以分析缺陷预测效果存在差异的原因, 并探索网络嵌入算法的不同参数设置对网络结构特征表示以及缺陷预测性能的影响。对网络嵌入算法得到的节点特征向量进行聚类, 度量聚类后的网络结构特征与软件关联网络社区结构的相似性, 并分析相似性与缺陷预测性能之间的相关性。实验发现: 当网络嵌入算法擅长学习网络的同质性时, 可以达到良好的缺陷预测效果; 不同网络嵌入算法得到的聚类结构相似时, 其对应的缺陷预测结果也相近, 例如DeepWalk和Grarep算法的聚类结果相似, 其缺陷预测结果也相似; 网络嵌入特征和基于网络嵌入的缺陷预测性能对网络嵌入算法的参数配置比较敏感。
其余章节安排。第2节介绍相关研究现状; 第3节介绍软件关联网络建模和网络嵌入算法, 并给出案例展示; 第4节展示基于网络嵌入特征的缺陷预测方法; 第5节叙述实验和分析结果, 包括对数据的预处理、缺陷预测结果分析、网络嵌入特征分析、以及参数影响分析; 第6节总结本文工作并展望未来研究方向。
2 相关工作
2.1 软件缺陷预测
软件缺陷预测是软件工程领域研究的热点。软 件缺陷预测通过分析和挖掘软件库(例如项目托管的缺陷跟踪系统和版本控制系统), 根据软件源代码和开发过程设计与软件缺陷相关的度量指标, 构建缺陷预测模型, 使用训练出的模型识别出被测项目内可能存在缺陷的模块。开发人员可对这些潜在的缺陷模块投入更多的精力进行软件测试, 修改或完善代码以保证软件产品质量。Promise数据集的建立和美国国家航空航天局项目(NASA数据集[5])的开源共享推动了缺陷预测的研究进展。影响软件缺陷预测性能的主要因素包括: 度量指标的设计、预测模型的构建和数据集相关问题[30]。在预测模型中, 机器学习模型是目前主流的方法[31-32]。除此之外, 也有基于缓存的方法[33-34], 利用缺陷局部性原理识别缺陷。对于数据集, 经常会出现噪音[35]和非平衡[36-37]等问题, 目前也已经有针对这些问题的研究。
设计出与缺陷具有强相关性的度量指标是提高预测效果的关键。软件缺陷预测用到的特征常通过度量获取。传统的软件度量指标包括基于运算符和操作数的Halstead特征[6], 基于依赖性的McCabe特征[7], 面向对象程序的CK特征[8]等。同时, 也有研究表明, 软件演化数据在缺陷预测方面比代码度量更有效[38], 在缺陷预测中利用软件演化数据的一个方面是将变更过程建模为网络[39], 并使用不同的网络度量(例如, 度统计或中心度量)改进机器学习分类器的性能。其中Zimmermann和Nagappan[4]提出在缺陷预测中使用软件系统依赖关系图上的网络度量。Ma等人[10]进一步评估了网络度量在缺陷预测中的预测有效性。Chen等人[9]利用网络度量来预测有严重缺陷的软件, 他们发现大多数网络与严重的缺陷显著相关。另一方面是从代码修改[40-42], 开发人员经验[43-45], 程序模块间的依赖性[4,46]或项目团队组织构架角度[47-49]等方面出发来设计度量指标。程序的良好的语法定义、隐藏在抽象语法树中的丰富语义以及程序中的依赖网络信息通常无法被这些指标很好的捕获。因此传统方法的预测结果差强人意。
2.2 软件关联网络
软件关联网络主要是根据实体和实体之间的依赖关系构建的, 从各种不同的粒度(包、类、方法、函数)可对软件网络进行拓扑分析。软件关联网络产生于复杂网络理论, 复杂网络[50-51]最初是在物理学和数据科学中开发的, 并在不同领域被广泛采用。近年来, 该理论已成功地应用于软件工程领域。Myers CR[52]提出了复杂网络理论在软件系统中的应用。Concas等人[53]和Louridas等人[54]随后在软件系统中观察到了幂律分布。
软件网络被用于软件演化过程的建模和理解[55-56], 软件演化的预测[57], 软件结构的分析和评估[52,54], 软件执行过程和行为建模[58], 软件的质量评估[57,59-60], 软件的安全分析[61-63]。其中Li[55]提出了一种软件网络演化的模块化连接机制。Subelj等[64]分析了类依赖网络中存在的社区结构。Qu等[65]发现软件中方法和它们之间的调用关系呈现出相对显著的社区结构, 并基于软件网络的社区划分提出了两个类内聚的度量指标。Pan等[66]从实际的Java软件系统中构造了一组加权软件网络, 并利用加权k核分解对其拓扑性质进行了实证研究。Cai[58]将软件执行过程建模为演进的复杂网络。 Bhattacharya[57]通过源代码库和缺陷追踪系统中的实体关系构建网络以更好地理解软件演化过程, 并构建预测器以促进软件开发和维护。Concas等[59]研究了Java软件网络中划分的社区与缺陷之间的关系。Pan等[60]提出了一个针对软件网络的度量元来量化软件的稳定性。
2.3 网络嵌入算法及其应用
复杂网络结构中节点和边众多, 拓扑结构复杂, 难以高效分析。近几年出现的网络嵌入算法[13-17]可以有效解决网络数据难以分析的难题, 其中心思想就在保持网络结构特性(一阶相似度、二阶相似度等)的同时将高维稀疏的网络结构或者图结构映射到低维稠密的向量空间。

表1 常用的网络嵌入算法 Table 1 Common Network Embedding Algorithms
LE(Laplacian Eigenmaps)[64]方法和LLE(Locally Linear Embedding)[65]方法是传统的将网络节点映射为低维向量的方法。然而, 这些方法并没有很好的可扩展性。近些年又提出了很多的网络嵌入算法, 根据其主要性质可以分为3大类: 基于矩阵分解[13-14]、基于随机游走[15-16]、基于深度学习[17]。随机游走已经被用于近似网络的许多属性, 包括节点中心性和相似性, 适用于过大的无法完整测量的网络; 基于分解的算法以矩阵的形式表示节点之间的连接, 并将矩阵分解以获得向量表示; 基于深度学习的模型可 以对数据中的非线性结构进行建模, 捕获网络中非线性的特征。表1展示了每一类中的代表性算法以及它们保留的结构特征和时间复杂度。
网络嵌入算法是复杂网络分析的研究重点, 也是将深度学习应用到网络分析的有效途径, 网络嵌入算法学习到的特征表示可以用作基于图的各种任务的特征, 例如分类、聚类、链路预测和可视化。在软件工程领域, 由于软件内部存在复杂的调用以及依赖关系, 软件中存在多种类型的网络, 所以用网络嵌入算法可以解决很多软件中存在的问题。GefGroid[69]是基于网络嵌入算法的安卓恶意软件家族分析方法, 根据函数调用图划分出子图, 用struc2vec[70]将子图中API调用节点表示为向量, 通过向量相似度的计算聚类出安卓恶意家族。Node2defect[71]利用Node2vec[16]将软件中的依赖网络节点转化为向量, 用于软件的缺陷预测。Liu等[72]人利用DeepWalk[15]获取软件系统结构特征, 并结合软件抽象语法树的语义特征共同进行软件的缺陷预测。Ling等人[73]提出基于图嵌入的软件项目源代码检索方法。该方法利用LINE[29]将代码结构图中的节点转化为向量, 用户输入自然语言问题即可检索并返回相关的API 及其关联信息构成的连通代码子图。此外, 一些工作没有利用常见的网络嵌入算法, 而是通过构造目标函数将网络节点转化为低维的向量, 从而进行方法名或类名的推荐[74-75]。
3 软件关联网络与网络嵌入
本章将构建类依赖网络、文件耦合网络、开发者贡献网络等软件关联网络, 介绍6种常用的网络嵌入算法, 最后在一个真实软件系统上展示软件关联网络及其嵌入特征。
3.1 软件关联网络建模
本节将从源代码、演化历史中的共同修改、演化历史中的开发者贡献3个层次对软件结构进行建模, 生成软件关联网络。
3.1.1 类依赖网络 (Class Dependency Network, CDN)
从软件的源代码抽取类依赖网络[76]: 对于面向对象系统P, 其类依赖网络 CDNP= (V,E)是有向网络, 其中V为 CDNP顶点的集合, 每个顶点v∈V代表软件系统中的类/接口, E是网络的边集合, 代表类/接口之间的依赖关系。若类/接口v1、v2之间存在以下任意一种依赖关系, 则存在边 e = (v1,v2)∈ E :
1) 继承依赖(inheritance): 类v1(称为子类、子接口)继承类v2(称为父类、父接口)的功能, 并可扩展增加新功能。继承是类与类或者接口与接口之间最常见的依赖关系, 在Java中通过关键字extends标识;
2) 接口实现依赖(interface implementation): 类v1实现接口v2的功能, 在Java中此类关系通过关键字implements标识;
3) 方法调用依赖(aggregation): 类v1中的方法调用了类v2中的方法;
4) 返回值依赖(return types): 类v1中的方法返回了类 2v的对象;
5) 参数依赖(parameter types): 类v1的对象作为类v2中的方法的参数。
以图1为例, 图1(a)展示了Java类和接口的代码片段, 从中抽取出的类依赖网络见图1(b)。其中类A的方法调用了类B的方法, 因此存在一条从节点A指向节点B的边。
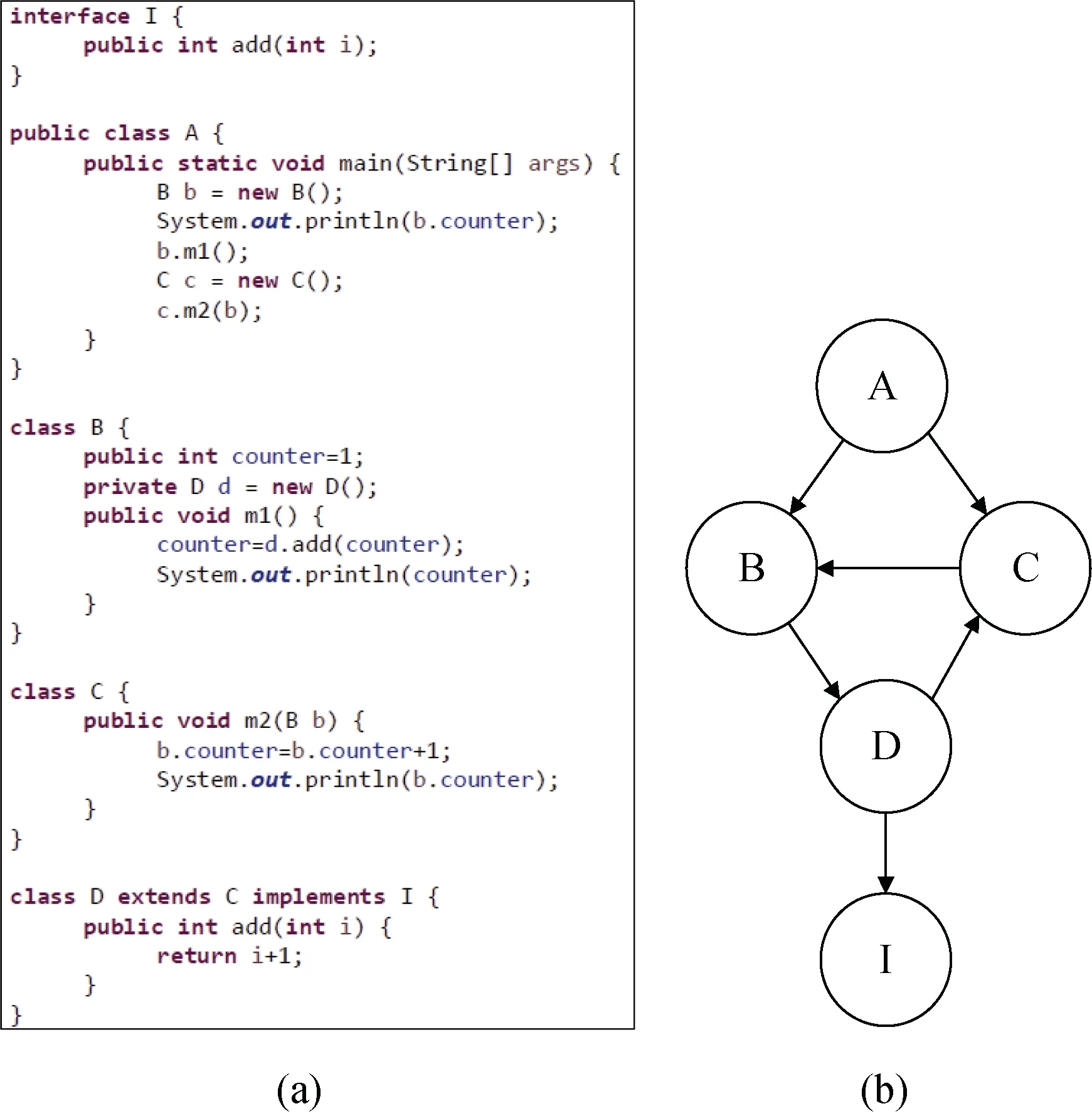
图1 类依赖网络示例 Figure 1 Class Dependency Network
3.1.2 文件耦合网络 (Change Coupling Network, CCN)
本文提出从软件演化历史(记录于软件的版本控制系统如Git)中的共同修改记录来构建文件耦合网络: 对于面向对象系统 P, 其文件耦合网络CCNP= (V,E)是无向带权图, 其中V为图 CCNP的顶点集合, 每个顶点v ∈ V 代表软件系统中的源文件, E是图的边集合, 代表源文件在修订历史记录中的的共同修改(co-change)关系, 权值代表源文件间的共同修改频次。
图2(a)示例出软件修订历史中的4次提交记录, 例如, A.java和C.java在Commit 1和Commit 3中都同时修改, 所以在CCN中A.java和C.java之间存在一条边且权值为2。图2(a)对应生成的文件耦合网络见图2(b)。
构建文件耦合网络需设置过滤阈值参数, 该参数是指一次提交所涉及的最大文件数。当一次提交记录中涉及的文件很多时, 相应的文件耦合网络会存在很多权值较小的边, 这种“大提交”往往是由一些通用修改导致, 比如license修改, 分支合并等。为了避免过耦合, 需要设置适当的过滤阈值参数以筛选出有效的用于构建文件耦合网络的提交记录。
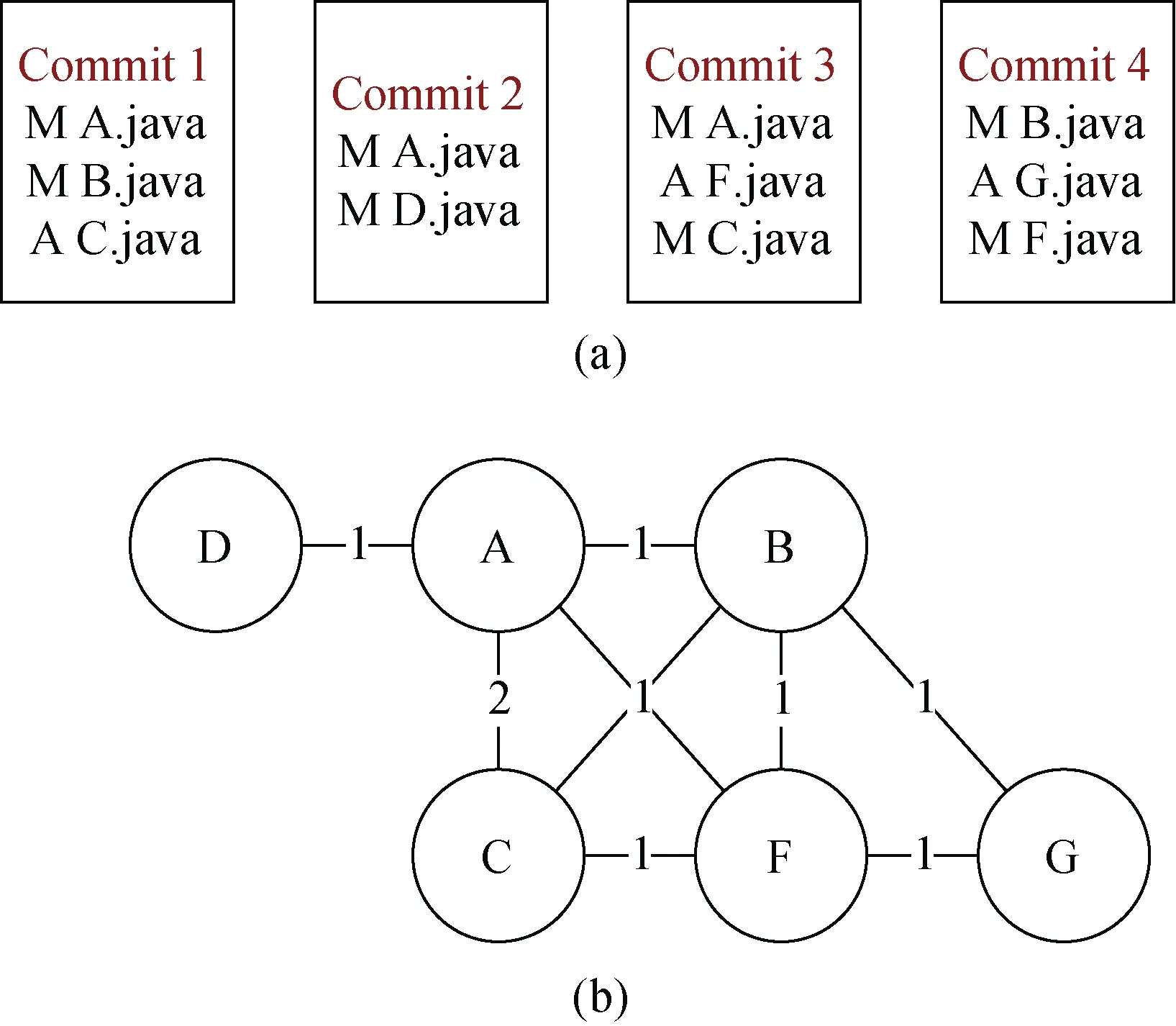
图2 文件耦合网络示例 Figure 2 Change Coupling Network
3.1.3 开发者贡献网络(Developer Contribution Network, DCN)
从软件演化历史中的开发者维护活动来构建开发者贡献网络DCN[43]: 对于面向对象系统P, 其开发者贡献网络 DCNP= (D,B,E)是个无向带权二分图。其中D,B为图 DCNP的顶点的两个集合, 每个顶点d ∈ D代表软件开发者, b ∈ B代表类/接口; E ⊆ {( d ,b) |d ∈ D∧b ∈ B}是图的边集合, 边(d,b)代表开发者d对类/接口b进行了提交操作; 边的权重表示开发人员对类/接口的提交次数。
图3是开发者贡献网络的示例。其中, 矩形代表类/接口, 人形图案代表开发者, 边代表开发人员对类/接口的修改提交操作, 边的标签代表开发人员提交该文件的次数。例如, 边(d5,b1)表示开发人员d5对类b1做了6次提交操作。文献[43]研究发现, 开发者贡献网络中中心性越高的类/接口越易发生缺陷(error-prone)。当一个类/接口被较多开发者修改, 则中心性会增强, 所以类b1和类b2比类b3发生缺陷的概率更大; 加之, 开发人员同时处理许多其他文件则中心性会增加, 所以类b1比类b2更有可能发生缺陷。
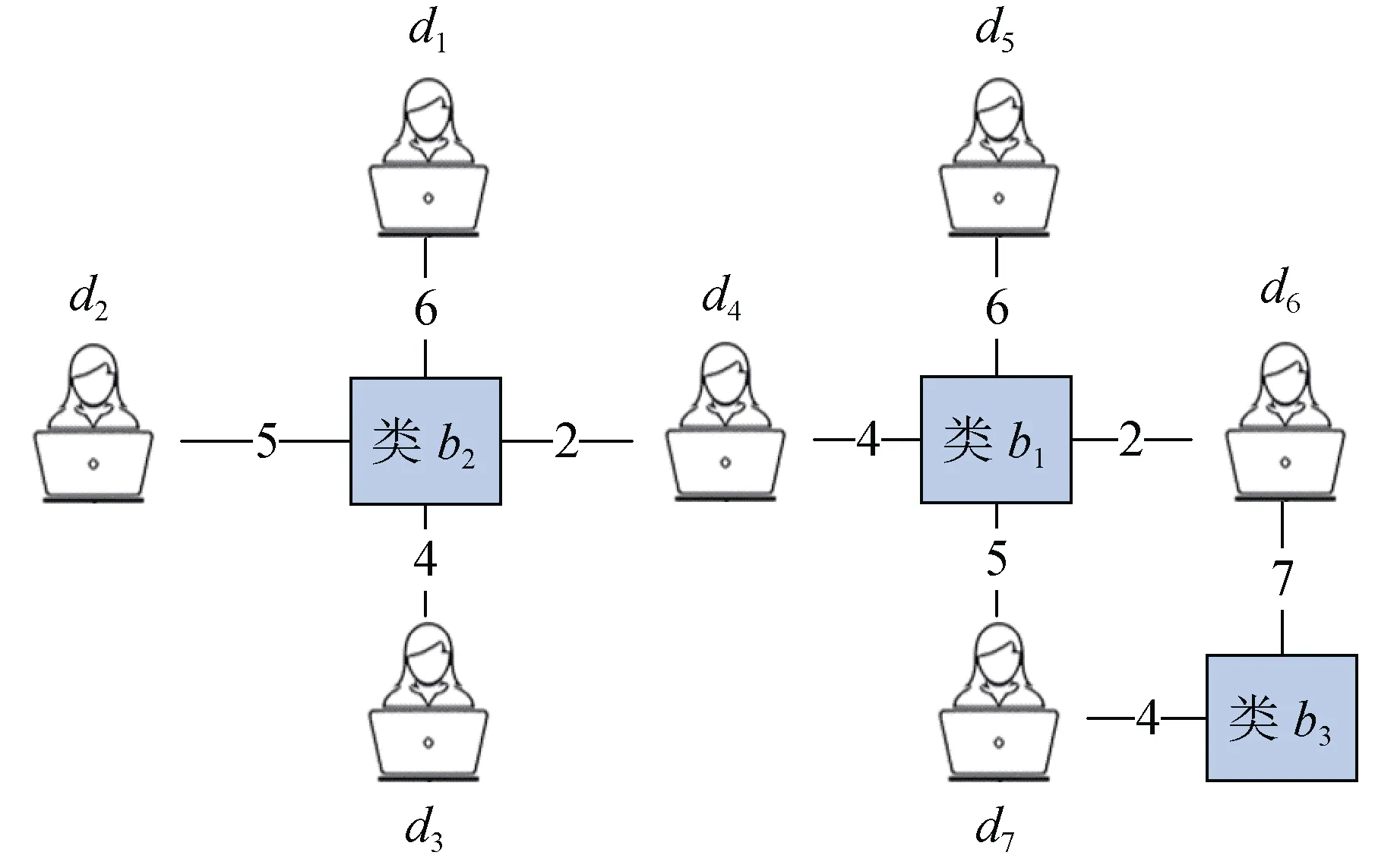
图3 开发者贡献网络示例 Figure 3 Developer Contribution Network
3.2 网络嵌入算法
网络嵌入[12]的核心思想是在保持网络结构特性(一阶相似度、二阶相似度等)的同时将高维稀疏的网络结构或者图结构映射到低维稠密的向量空间。本文选取DeepWalk、Node2vec、Grarep、Graph Factorization、SDNE和LINE算法共6种代表性的网络嵌入算法, 对软件关联网络进行特征表示。
1) DeepWalk. 由Perozzi等人[15]于2014年提出, 是最早的基于Word2vec的节点向量化模型, 网络中节点的邻域的概念可以使用自然语言中单词上的滑动窗口来定义。主要思路是利用网络中随机游走得到的节点序列, 生成节点的向量表示。DeepWalk发现网络中随机游走序列的节点分布类似于自然语言中的单词分布。因此对于网络中的每个节点, 生成长度为t的随机游走序列。然后用Skip-gram模型训练模型, 最大化随机游走序列中节点的概率:
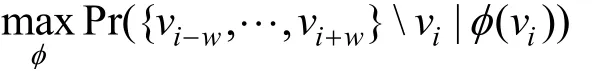
其中w是窗口大小, φ( vi)是节点 vi的表示向量, {vi-w,… , vi+w}vi是节点vi的上下游节点。
DeepWalk算法充分利用了网络结构中的随机游走序列的信息, 使用随机游走序列的信息只依赖于局部信息, 所以适用于分布式和在线系统。
2) Node2vec. 该算法通过改变随机游走序列生成的方式进一步扩展了DeepWalk算法, 由Grover于2016年提出[16]。DeepWalk随机地选取随机游走序列中下一个节点, 而Node2vec将广度优先搜索(BFS)和深度优先搜索(DFS)引入随机游走序列的生成过程, 通过两个参数p、q实现二者的平衡, 可以同时考虑到局部和全局的信息, 并且具有很高的适应性。
Node2vec中用参数p和q控制着行走过程中的转移概率。参数p为返回参数(return parameter), 若p值高, 可以保证在下一步采样已访问过的节点的可能性比较低; 参数q为输入-输出参数(in-out parameter), q> 1时随机游走会选择离当前节点更近的节点, 以此达到接近BFS的效果; q< 1时随机游走会选择离当前节点更远的节点, 达到类似DFS的效果。它的目标函数如下所示:
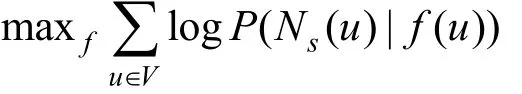
本式含义与DeepWalk类似, 其中 f(u)为当前节点u在嵌入空间的向量表示, Ns(u)为当前节点的上下游节点。
3) Grarep. 是基于矩阵分解的网络嵌入算法之一, 由Cao等人[13]在2015年提出。Grarep通过操纵不同的全局转移矩阵, 从图形中直接捕获不同的k阶关系信息, 不需要缓慢且复杂的采样过程。与其他算法不同的是, 该算法定义了不同的损失函数, 来捕获不同的k阶关系信息, 允许集成不同局部关系信息的非线性组合。
该算法将节点的转移概率定义为 A =D-1S, 其中D为度矩阵, S为邻接矩阵。利用A可以计算出k阶转移概率Ak。将将其中从起始点w到终止点c的k-step路径记作(w, c)。优化目标是: 最大化(w, c)所代表的路径在图中的概率; 最小化除了(w, c)以外的路径在图的概率来保留k阶相似度。Grarep的主要缺点是其可扩展性。并且, 该算法在学习过程中将奇异值分解方法(SVD)应用于矩阵的幂以获得节点的低维表示, 这可能会导致高昂的计算成本。
4) Graph Factorization. 由Ahmed等人[14]在2013年提出, 后面简称GF。目前来说, GF是第一个将算法复杂度降到O(|E|)的网络嵌入算法。为了获得表征结果, GF对网络的邻接矩阵进行因式分解, 最小化随后的损失函数如下所示:
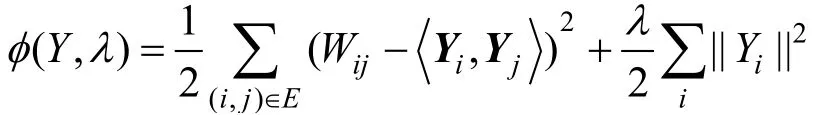
式中 Wij是节点i和节点j连接边的权重, < Yi,Yj>是降维后节点向量的内积, λ是正则化系数。值得注意的是, 这里的求和是针对观察到的边而非所有边,这是为了算法的可扩展性, 但这样可能会在结果中带来噪声。即使表示向量维度为|V|, 该损失函数的最小值仍然有可能大于0。
5) SDNE. 由Wang等人[17]在2016年提出, 使用深度自动编码器来同时保留一阶和二阶相似度的算法。一阶相似度衡量的是相邻的两个顶点对之间相似性。二阶相似度衡量的是两个顶点的邻居集合的相似程度。该算法通过保持网络的一阶相似度来保持网络局部结构, 通过保持网络的二阶相似度来保持全局的网络结构。论文采用了半监督结构, 其中的无监督组件(编码器、解码器)通过重构邻接矩阵来保持网络的全局结构, 具有相似邻域结构的顶点将被映射到相近的向量空间; 而监督组件借鉴了Laplacian Eigenmaps算法, 利用一阶相似度来保持局部的网络结构, 使得彼此相连的节点在映射空间中也十分靠近。由于模型高度非线性, 在参数空间中会存在很多局部最优解。为了解决该问题, 该算法采用Deep Belief Network来对参数进行预先训练, 完整算法可参考论文原文。SDNE的主要贡献在于提出了一种新的半监督深层学习模型, 结合一阶与二阶相似度的优点, 用于表示网络的局部结构属性和全局结构属性。
6) LINE. 由Tang等人[29]在2015年提出, 该方法的可扩展性很好,能够快速地对大规模网络进行嵌入,并且能够同时保留局部和全局的结构信息。它通过定义两个函数来计算节点的嵌入向量, 分别用于一阶相似度和二阶相似度的计算, 并最小化这两个函数的组合。一阶相似度的函数类似于GF算法, 因为它们都旨在保持邻接矩阵和降维后节点的点积接近。不同的是, GF通过直接最小化两者的差异来做到这一点, 而LINE用邻接矩阵和嵌入矩阵分别定义了每对节点的两个联合概率分布, 然后最小化这两个分布的Kullback-Leibler(KL)散度。这两个分布如下所示:
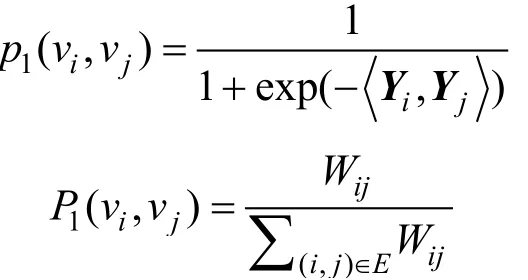
该算法的目标函数如下所示:
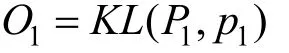
其中 vi,vj为网络中的两个节点, Yi,Yj是 vi,vj的嵌入向量, Wij是 vi,vj的连接权重。作者类似地定义了对于二阶相似度的概率分布和目标函数。该算法适用于任意类型的信息网络, 并能够轻易拓展到百万个节点。
3.3 案例展示
本节展示Lucene软件①https://lucene.apache.org/的3种软件关联网络及其网络嵌入结果。
图4可视化出3种软件关联网络: 使用工具Understand②https://scitools.com/抽取类依赖关系, 构建类依赖网络CDN, 见图4(a); 基于Git log中文件的共同修改记录, 构建的文件耦合网络CCN, 见图4(b); 通过挖掘开发者对文件的修改提交操作, 构建开发者贡献网络DCN, 见图4(c)。在3种软件关联网络中, 红色节点表示存在缺陷的类/接口/文件, 蓝色节点表示不存在缺陷的类/接口/文件, 绿色节点表示开发人员。从图中可以看出, 在该软件中存在缺陷的类/接口/文件相对较多, 且缺陷节点的分布没有明显规律。
选取Grarep和LINE网络嵌入算法将Lucene软件的CDN的节点转化为向量表示。为了观察向量反应出的网络节点之间的关系, 与文献[16]类似, 我们使用k均值聚类算法[84](k-means clustering algorithm)基于嵌入后的向量信息对网络节点进行聚类, 使距离相近的向量被划分到同一个簇(cluster)中, 不同簇使用不同颜色渲染, 结果如图5所示, 图5(a)为Grarep特征的聚类结果, 图5(b)为LINE特征的聚类结果。可以观察到, Grarep算法和LINE算法嵌入后的节点向量经聚类得到的结果存在很大差异, 初步得出不同网络嵌入保持的网络结构特征可能不同。
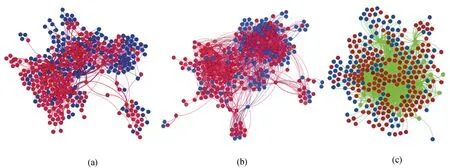
图4 Lucene的软件关联网络 Figure 4 Software Associated Network of Lucene

图5 Lucene软件CDN的网络嵌入特征的聚类结果 Figure 5 Clusters of Class Dependency Network Embedding Features for Lucene
4 基于软件关联网络嵌入的缺陷预测
本文设计了一种基于软件关联网络嵌入特征的缺陷预测方法, 该方法除了使用代码度量和网络度量的软件特征, 也使用了软件关联网络嵌入特征。本节先介绍方法流程, 再详细介绍每个步骤。
4.1 方法流程
图6展示了基于软件关联网络嵌入的缺陷预测流程:
1) 输入处理。根据软件的源代码和修订历史构建出CDN、CCN、DCN共3种软件关联网络。
2) 特征提取。从源代码和软件关联网络中分别提取出3种特征: 代码度量特征(CM)、网络度量特征(NM)、网络嵌入特征(NE)。其中CM和NM属于传统的度量特征。
3) 模型训练。对缺陷数据集使用SMOTUNED算法[77]进行非平衡数据的处理, 将上一步得到的3种特征和对应的缺陷标签输入随机森林、支持向量机、朴素贝叶斯和多层感知器进行模型训练并测试, 预测是否存在缺陷。
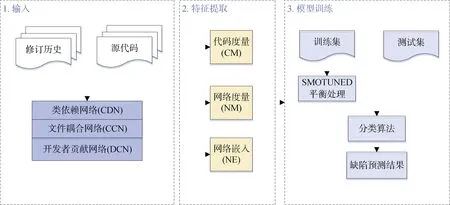
图6 基于软件关联网络嵌入的缺陷预测方法流程 Figure 6 Defect Prediction Based on Network Embedding
4.2 特征提取
本节详细介绍从源代码和软件关联网络得到的度量特征:
(1) 代码度量特征
本文将基于源代码的度量结果作为代码度量特征。已有研究提出了各种代码度量指标, 本文使用了常用的C&K(Chidamber-Kemerer)指标[8], McCabe的度量[7](Max_CC, Avg_CC)等共计20个代码度量指标。这些指标的集合记为CM(Code Metrics), 来源于公开可用的tera-PROMISE数据库, 表2展示指标的名称和说明。
(2) 网络度量特征
本文使用了59种基于网络的指标, 这些指标集合记作网络度量NM(Network Metrics), 包括对自我中心网络(Ego Network)的度量和对全局网络(Global Network)的度量。这些指标详见Zimmermann等[4]和Ma等[10]的研究工作, 其中16个指标的说明见表3。NM指标可以使用Ucinet①www.analytictech.com/ucinet/来计算, Ucinet可以处理矩阵格式的网络结构数据, 探测网络结构的度量指标。
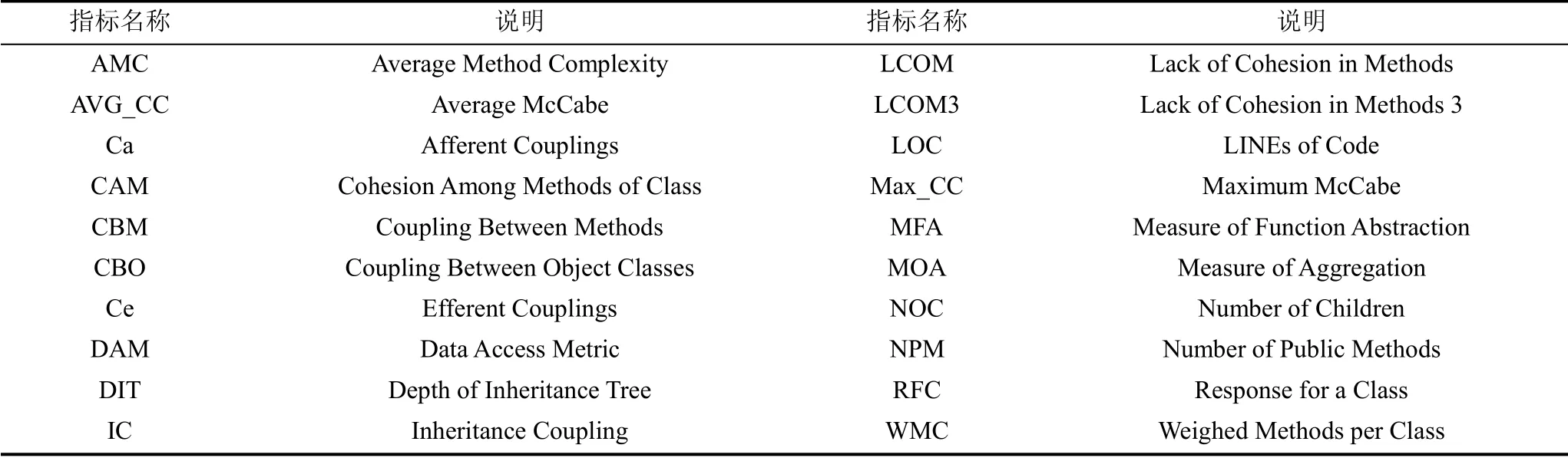
表2 代码度量(CM)和说明 Table 2 Code Metrics and Descriptions
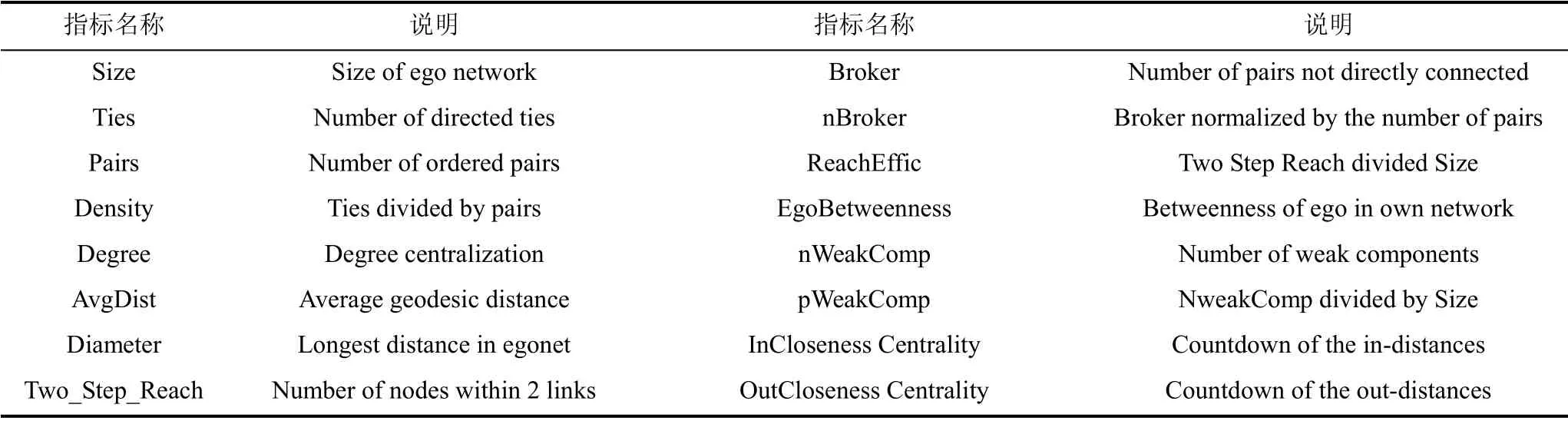
表3 网络度量(NM)和说明 Table 3 Network Metrics and Descriptions
(3) 网络嵌入特征
网络嵌入特征反映软件关联网络的结构信息, 本文分别使用DeepWalk、Node2vec、Grarep、Graph Factorization、SDNE和LINE算法, 将软件关联网络中的节点表示为反映网络结构信息的向量。

图7 3种特征合并后的特征向量示例 Figure 7 The Feature Vector with 3 Features
将该向量与此节点的代码度量和网络度量值合并后的向量 , 和对应的缺陷标签(节点对应的类/文件/接口是否存在缺陷)作为模型训练过程的输入。如图7所示, 对于Lucene软件中的一个节点org.apache. lucene.search.spans.SpanNotQuery.java, 使用DeepWalk算法, 三种特征合并后的向量为: 对该节点的代码度量、网络度量与基于DeepWalk得到的节点向量的合并。
4.3 模型训练
在模型训练过程中, 将特征向量和对应缺陷标签输入至机器学习模型中, 利用十次三折交叉验证训练缺陷预测模型。大多数训练集中缺陷和非缺陷的数据比例不平衡, 因此需要先平衡训练集, 然后输入至随机森林、多层感知器、支持向量机、朴素贝叶斯等4种分类器中进行训练。
4.3.1 非平衡数据集处理
很多机器学习算法都假设训练数据集是均匀分布的, 若把这些算法直接应用, 大多数情况下无法取得理想的结果, 这是因为实际数据往往分布的很不均匀, 存在长尾现象: 即数据中的一类样本在数量上远多于另一类。这种情况下, 传统机器学习训练算法的结果可能会偏向于多数类, 对于少数类的预测性能会很差。为了解决数据非平衡问题, He等人[78], Zhang等人[79]和Lopez等人[80]提出了处理非平衡数据的模型。包括: 模型融合(Ensemble)方法, 代价敏感分类(Cost-sensitive)方法, 基于核的算法(Kernel-based)和主动学习(Active Learning)算法等。
本文使用Agrawal等人[77]在2018年提出的SMOTUNED(Autotuning Version of SMOTE)算法来对实验数据进行平衡处理。SMOTUNED 算法是对Chawala等人[81]在2002年提出的SMOTE(Synthetic Minority Over-sampling Technique)算法的改进。SMOTE通过对少数类样本进行分析和模拟, 将新样本添加到数据集中来减少数据失衡程度。该方法从少数类中的每个样本x的k个近邻(欧氏距离)中随机挑选N个样本进行随机线性插值, 构造新的少数类样本, 并将新样本和原数据合成得到新的训练集。它是基于随机过采样的一种改进方案, 是目前处理非平衡数据的常用手段。但是, SMOTE算法中涉及很多参数, 参数的设置往往依赖于人们的经验, 有些研究使用了该算法的默认参数[77], 这样的设置并不能很好的适应所有数据集。SMOTUNED使用差分进化算法(Differential Evolution), 随机生成SMOTE算法中参数的初值, 通过变异、交叉、选择的演化过程逐步自适应地寻求参数的最优解。
4.3.2 随机森林
随机森林(Random Forest)[82]是利用多棵树对样本进行训练并预测的一种分类器, 可以基于开源机器学习框架scikit-learn①https://scikit-learn.org/stable/实现, 并利用scikit-learn的网格搜索(grid-search)功能调整随机森林的参数。随机森林以随机的方式建立包含多棵决策树的森林, 根据决策树的分类结果对每个记录进行投票表决决定最终的分类。随机森林可用于处理分类和回归问题。随机森林的随机性可以有效地防止过拟合情况的出现, 同时多棵决策树增强了模型的泛化能力。
4.3.3 多层感知器
多层感知器(Multi-Layer Perception, MLP)是一种基于误差反馈的人工神经网络, 由一个输入层、一个或多个隐层、一个输出层构成。MLP神经网络不同层之间是全连接的。训练过程包括正向和反向两种传播过程。在正向传播过程中得到输出结果, 在反向传播过程中进行验证, 根据误差逐层调整各层神经元的权值, 最终使输出结果满足要求。
4.3.4 支持向量机
支持向量机(Support Vector Machine, SVM)是一个利用有监督学习方法对数据进行二元分类的广义线性分类器。SVM的基本思想是在分类问题中求解能够正确划分训练数据集并且几何间隔最大的超平面。一些非线性可分的问题可以通过核函数替换实例和实例中的内积解决, 常用的核函数有: 高斯核函数、Sigmoid核函数和多项式核函数。本文的输入特征线性不可分, 因此选择高斯核函数。
4.3.5 朴素贝叶斯
朴素贝叶斯(Naive Bayesian, NB)是基于贝叶斯定理与特征条件独立假设的分类方法。通过贝叶斯公式可以由已知的先验概率和条件概率, 推算出后验概率P(B|A)。而朴素贝叶斯算法对条件概率分布做出了独立性的假设, 在这个假设的前提上, 结合贝叶斯定理即可得到分类结果。朴素贝叶斯有三个常用模型: 高斯、多项式、伯努利, 可以根据实际情况选择不同的模型。多项式朴素贝叶斯模型常用于文本分类问题中, A中的特征为单词在文本中出现的次数。如果A中的特征是连续变量, 则假设在B的条件下, A服从高斯分布, 则使用高斯朴素贝叶斯模型。由于本文中的输入特征均为连续变量, 因此选择高斯朴素贝叶斯模型。
5 实验
本章首先介绍选取的数据集及其预处理, 然后分析基于软件关联网络嵌入的缺陷预测结果, 紧接着分析网络嵌入保持的网络结构特征以及缺陷预测性能差异的原因, 最后分析不同参数配置下的网络嵌入特征对缺陷预测性能的影响。
5.1 数据集预处理
5.1.1 实验对象
本文使用了12个常用的大型开源Java软件系统作为实验对象。这些系统的缺陷数据来自于公开可用的tera-PROMISE数据库①http://openscience.us/repo/和D’Ambros等人[83]于2010年发布的缺陷数据集②http://bug.inf.usi.ch/index.php。这12个软件系统包括: Ant是用于自动化软件构建过程的命令行工具; Camel是集成框架; Ivy是传递依赖管理器; Lucene是搜索框架和算法; Poi是用来处理Microsoft Office文件的库; Synapse实现了高性能的企业服务总线(ESB); Tomcat是web服务器, Servlet和JSP容器; Velocity是模板引擎, 用于引用Java代码中定义的对象; Xalan用于处理xml文档; Equinox Framework是OSGi核心框架规范的实现; JDT Core是Eclipse IDE的核心组件; PDE UI也是Eclipse组件, 提供了一套全面的工具来开发和测试Eclipse插件和其他产品。
这些系统及其软件关联网络的统计信息如表4所示。表中SLOC列表示软件的源代码行数; |CRD∩ CCDN|代表了既出现在CDN中又在缺陷数据集中的实体的数量; |CRD∩ CCCN|代表了既出现在CCN 中又在缺陷数据集中的实体的数量; |CRD∩ CDCN|代表了既出现在DCN中又在缺陷数据集中的实体的数量; PCDNDefect表示CDN中被标记为缺陷的实体所占的百分比, PCCNDefect表示CCN中被标记为缺陷的实体所占的百分比, PDCNDefect表示DCN中被标记为缺陷的实体所占的百分比。
5.1.2 参数设置
(1) 软件关联网络的过滤阈值
如前文所述, 构建CCN和DCN时需要设置过滤阈值, 过大或过小的过滤阈值都不能有效反映耦合信息。本实验将以CCN为例, 使用从15到35、间隔为 5的不同过滤阈值进行预处理实验, 也对不设置过滤阈值 (即过滤阈值为∞)进行实验, 目的是验证不同过滤阈值对缺陷预测实验效果的影响, 同时找出最适用于缺陷预测模型的过滤阈值用于构建软件关联网络。过滤阈值为n意味着构建网络时忽略涉及的文件数超过n的历史修改提交记录。表5展示了不同过滤阈值下CCN的统计信息, NCCN代表节点数(节点代表的实体不一定在缺陷数据集中), ECCN代表边数。
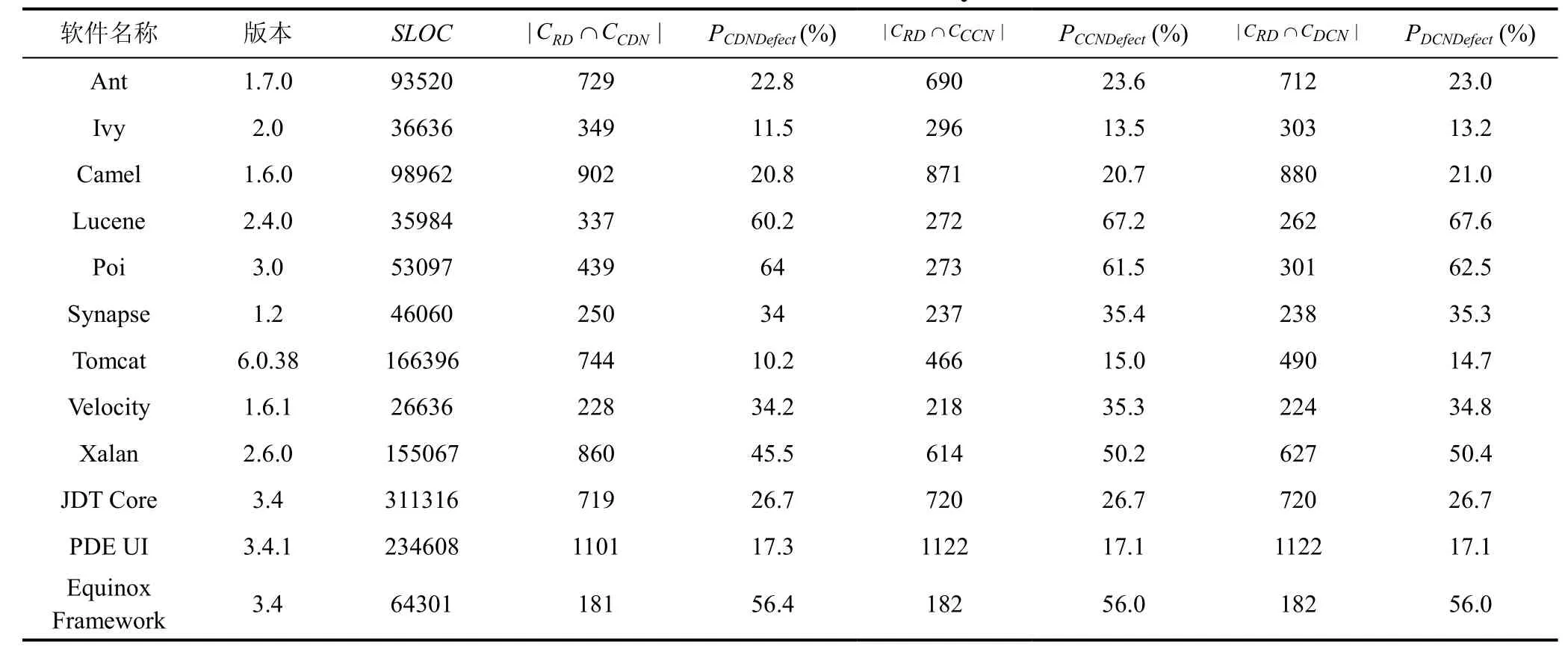
表4 实验对象统计信息 Table 4 Dataset Summary

表5 不同过滤阈值下CCN统计信息 Table 5 CCN Information under Different Thresholds
可以看出, 随着过滤阈值的增大, CCN规模逐渐增大, 网络分析所需的时间和空间开销也就越大。过滤阈值为∞的情况反映了最真实完全的CCN, 当过滤阈值为20以上时, 可以覆盖超过70%的节点, 所以建议使用大于20的过滤阈值。
在后续的缺陷预测实验中, 构建CCN和DCN时设置的过滤阈值默认为25。该参数变化对缺陷预测性能的影响将在5.4.1节实验分析。
(2) 网络嵌入算法参数
不同网络嵌入算法保持的网络结构信息不同, 目标函数不同, 涉及的参数存在差异。本节将介绍6种网络嵌入算法中的主要参数。
在DeepWalk和Node2vec中的可调节参数类似, number-walks是从每个节点出发的随机游走数量, walk-length是每个随机游走的长度。除此之外, Node2vec可以控制随机游走的方向, 通过修改p、q参数即可控制到邻居的转移概率。在LINE中的主要调节参数有epochs和order, 其中epochs可以控制训练的迭代次数, 而order可以控制算法中用到的相似度阶数。GraRep中的kstep参数可以用来更改算法中的k步转移概率矩阵, 用来保持网络中的k阶相似度。GF算法中的主要可调节参数为epochs, 用来控制训练迭代次数。SDNE中的encoder-list是一个二维向量, 其中第一维用于控制编码层的神经元数量, 第二维用于调整节点向量的维数。
本文的缺陷预测实验中网络嵌入算法借助OpenNE①https://github.com/thunlp/OpenNE实现, 均使用默认的参数设置。不同参数设置对软件关联网络嵌入特征以及缺陷预测效果的影响会在5.4.2小节实验分析。
5.2 缺陷预测结果分析
本节展示了基于传统度量特征和基于网络嵌入特征的缺陷预测结果, 并对比了基于不同网络嵌入特征得到的缺陷预测结果。
5.2.1 CDN的缺陷预测结果
表6展示了传统度量特征和Grarep算法得到的网络嵌入特征在CDN上通过随机森林分类器对12个数据集的缺陷预测AUC(Area Under Curve)值。AUC指标用于评估分类器性能, 该指标权衡了分类结果的精确率和召回率。
对于每个软件, 表6中展示的是十次三折交叉验证得到的平均AUC值, 基于传统的代码度量特征的预测结果见CM列; 基于传统的网络度量特征的预测结果见NM列; 代码度量和网络度量组合的实验结果见CM+NM列; 基于Grarep算法的缺陷预测结果以及与传统度量组合后的缺陷预测结果见NE列、CM+NE列和CM+NM+NE列。
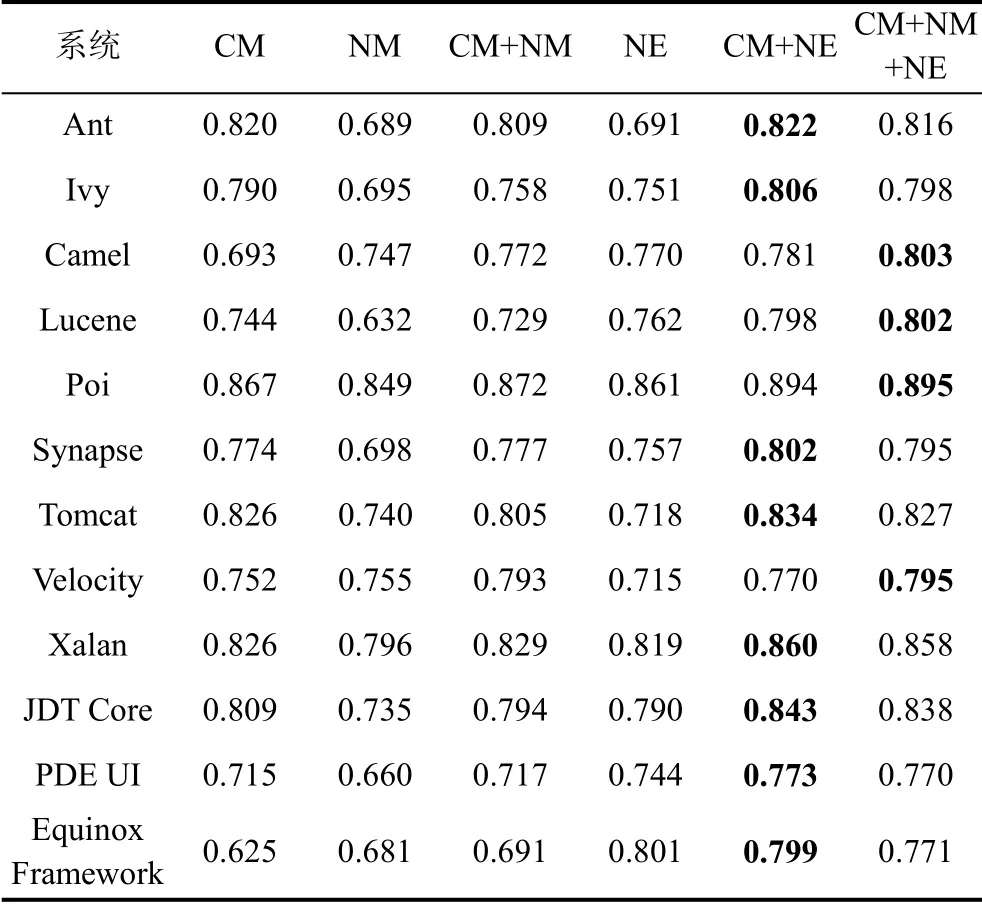
表6 CDN的缺陷预测AUC值 Table 6 AUC Value of Defect Prediction on CDN
表6中加粗的字体对应每行最大值, 即每个软件使用不同度量特征进行缺陷预测时得到的最优预测结果。从表中可以看出, 最大值分布在CM+NE、CM+NM+NE两列。即对于传统度量来说, 结合传统度量和网络嵌入特征可以使缺陷预测达到更好的效果。
图8显示了在CDN上传统方法以及分别与6种网络嵌入特征结合后通过随机森林分类器得到的缺陷预测AUC值。由于基于代码度量的缺陷预测效果在传统方法中相对较好, 因此图8中用于对比的传统方法选择基于代码度量的方法。通过图8可以观察到, 使用了DeepWalk、Node2vec、Grarep后, 在绝大多数的实验对象上的预测结果均得到改善; SDNE算法也可以在一定程度上提升预测效果; 而GF算法和LINE算法未能有效改进缺陷预测模型, 仅在4个实验对象上的实验效果有所提升。由此得到结论, 对于大多数实验软件, 结合基于DeepWalk、Node2vec、Grarep算法得到的特征可以提升在随机森林上的缺陷预测效果, 这些算法可以增加软件的网络结构信息, 从而改善缺陷预测效果。经对比计算可得, 在CDN上分别结合每种网络嵌入特征后的缺陷预测的性能(AUC)比仅考虑传统度量特征的预测性能, 性能提升程度的最大值是14.6%, 平均值是3.6 %。
与上述类似, 图9、图10、图11分别显示了在CDN使用朴素贝叶斯、支持向量机和多层感知器进行缺陷预测的AUC值。可以观察到, 结合DeepWalk、Node2vec、Grarep嵌入特征后明显提升了在这三种分类器上的缺陷预测效果, 这与在随机森林分类器上的缺陷预测效果(见图8)一致。通过计算可得: 结合网络嵌入特征后, 使用朴素贝叶斯性能提升最大值为15.7%, 平均值为3.3%; 使用支持向量机性能提升最大值为9.6%, 平均提升为2.5%; 使用多层感知器, 性能提升最大值为14%, 平均值为3.4%。使用随机森林缺陷预测的效果比朴素贝叶斯、支持向量机、多层感知器的效果要好, 性能平均高2%、10%、9%。
分析结果1: 在CDN上结合DeepWalk、Grarep、Node2vec特征后, 缺陷预测性能(AUC)优于仅考虑传统度量特征的预测性能, 且随机森林分类器比其他三种分类器的效果更好。
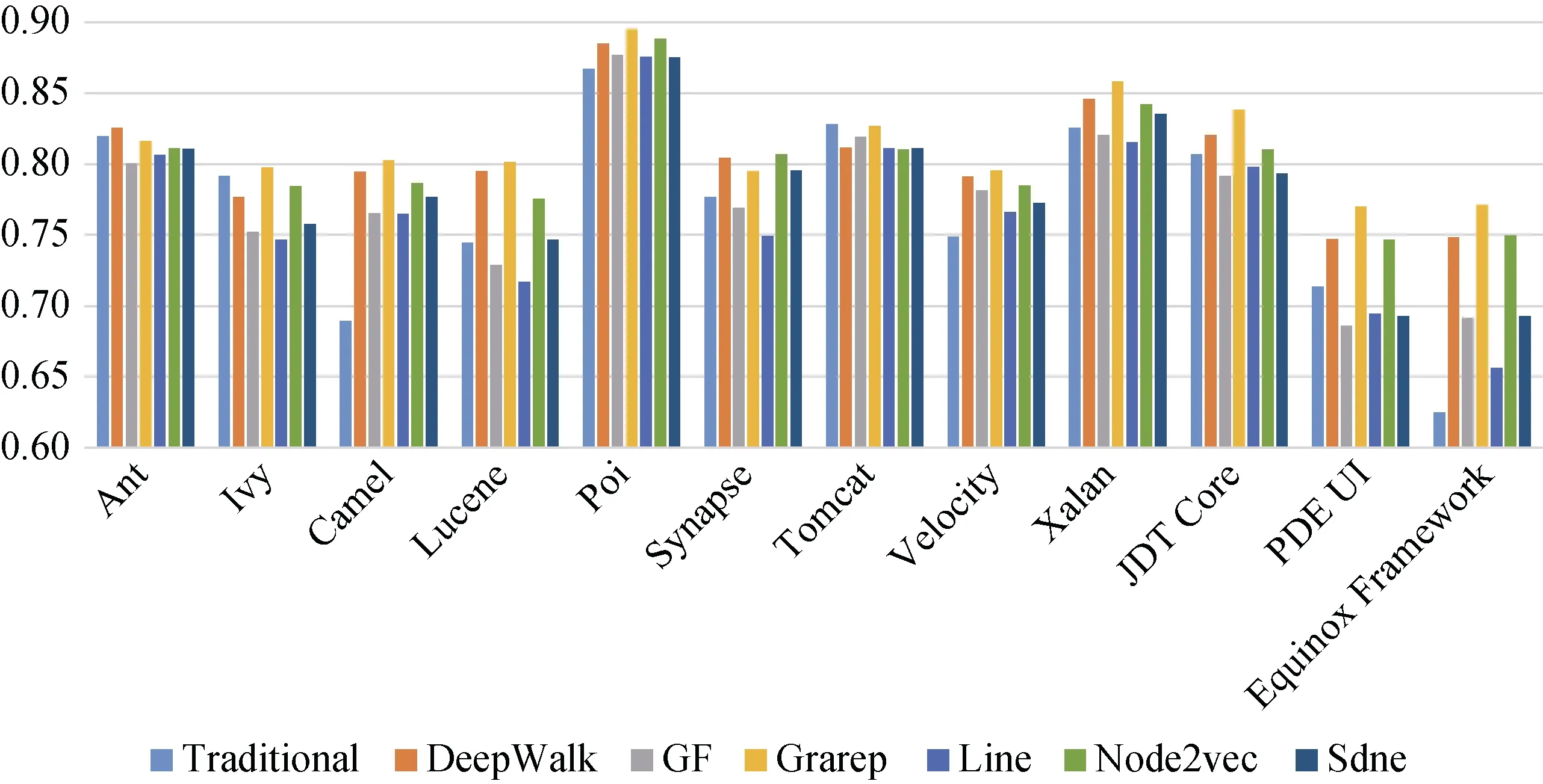
图8 CDN上缺陷预测的AUC值(使用随机森林分类) Figure 8 AUC Value of Defect Prediction on CDN (by Random Forest)
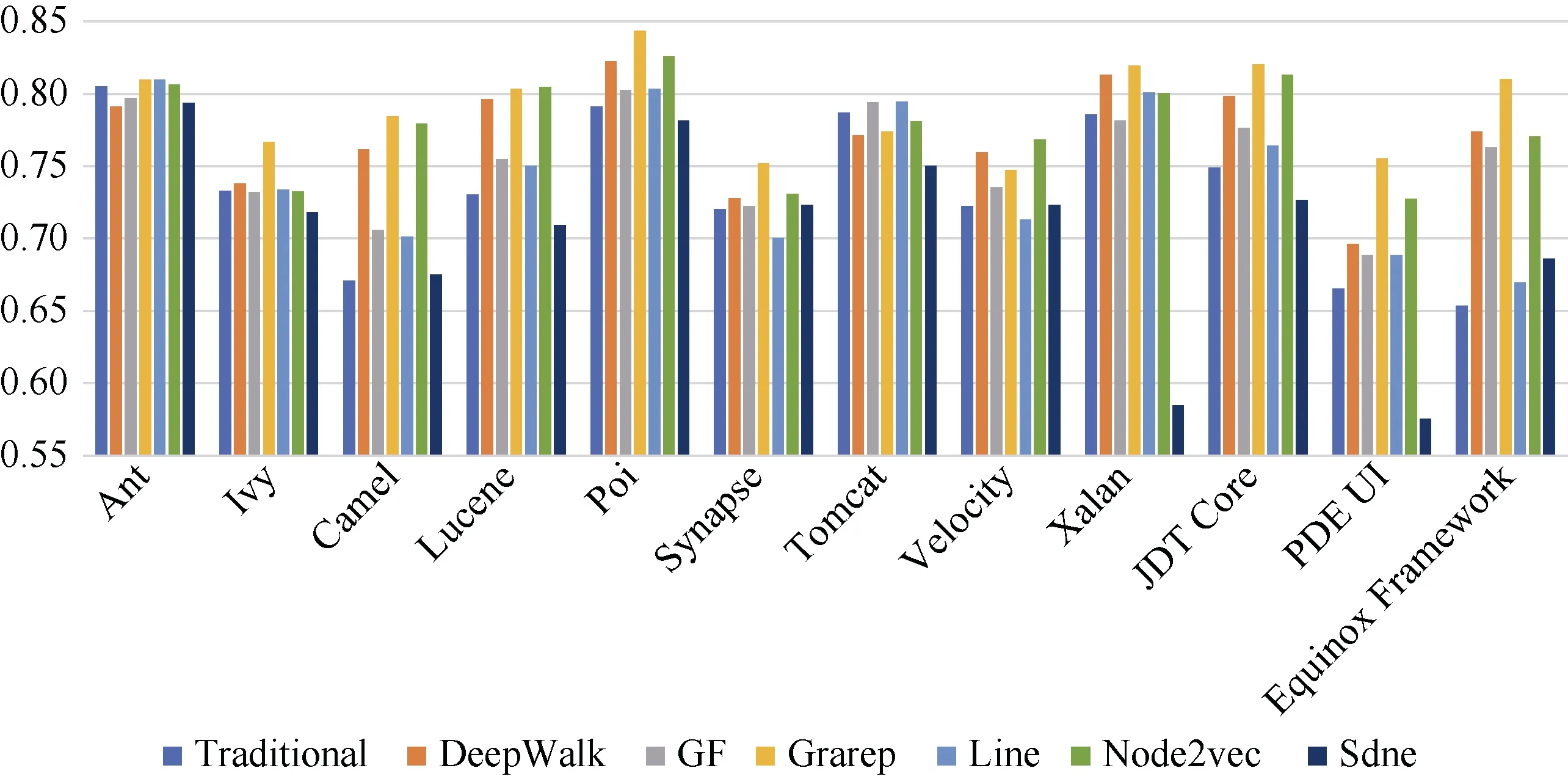
图9 CDN上缺陷预测的AUC值(使用朴素贝叶斯分类) Figure 9 AUC Value of Defect Prediction on CDN (by Naive Bayesian)
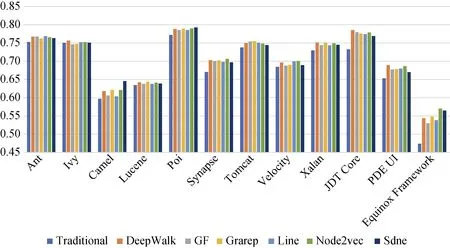
图10 CDN上缺陷预测的AUC值(使用支持向量机分类) Figure 10 AUC Value of Defect Prediction on CDN (by Support Vector Machine)
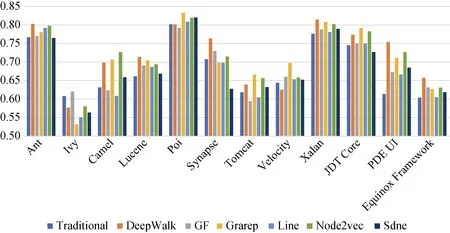
图11 CDN上缺陷预测的AUC值(使用多层感知器分类) Figure 11 AUC Value of Defect Prediction on CDN (by Multi-Layer Perception)
5.2.2 CCN的缺陷预测结果
表7展示了传统度量特征和Grarep算法得到的网络嵌入特征在CCN上通过随机森林分类得到的缺陷预测结果, 每列代表的含义和表6相同, CM、NM、CM+NM列为传统方法预测结果, NE、CM+NE、CM+NM+NE为结合网络嵌入特征的预测结果。表7中用加粗字体标出了每行的最大值。从加粗字体的分布可以发现, 在CCN中, 用Grarep算法得到的网络嵌入特征结合传统指标可以达到更好的缺陷预测效果。
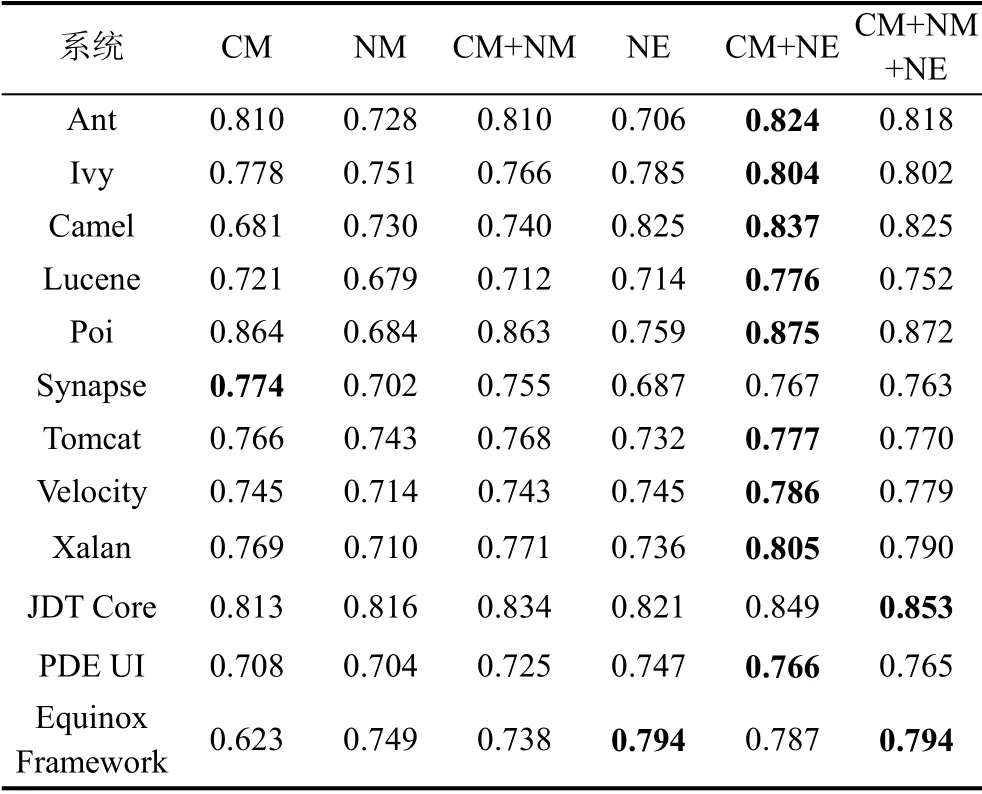
表7 CCN的缺陷预测AUC值 Table 7 AUC Value of Defect Prediction on CCN
图12展示了在CCN上传统方法以及分别与6种网络嵌入特征结合后通过随机森林分类器得到的缺陷预测AUC值, 由于基于代码度量和网络度量结合的缺陷预测效果在传统方法中相对较好, 因此图12中对比的传统方法选择基于传统度量结合的方法。从该柱状图中观察到, LINE和GF在CCN上仅有一半的实验对象性能得到提升, 而结合DeepWalk、Node2vec、Grarep、SDNE后, 缺陷预测性能都能有所改善。因此在CCN中使用传统度量和网络嵌入特征的结合有助于改善缺陷预测效果。经对比计算可得, 在CCN上结合网络嵌入特征后, 通过随机森林的缺陷预测性能相比于仅基于传统度量特征的预测方法, 性能提升程度的最大值是17.1%, 平均值是3.7%。

图12 CCN上缺陷预测的AUC值(使用随机森林分类) Figure 12 AUC Value of Defect Prediction on CCN (by Random Forest)
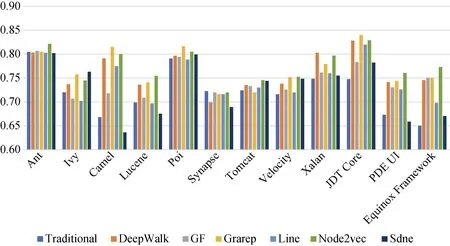
图13 CCN上缺陷预测的AUC值(使用朴素贝叶斯分类) Figure 13 AUC Value of Defect Prediction on CCN (by Naive Bayesian)
与上述类似, 图13、图14、图15分别显示了在CCN使用朴素贝叶斯、支持向量机和多层感知器进行缺陷预测的AUC值。可以观察到, 结合DeepWalk、Node2vec、Grarep嵌入特征后明显提升了在这三种分类器上的缺陷预测效果, 这与在随机森林分类器上的缺陷预测效果(见图12)一致。通过计算可得: 结合网络嵌入特征后, 使用朴素贝叶斯性能提升最大值为12.3%, 平均值为3.7%; 使用支持向量机性能提 升最大值为6.5%, 平均提升为2.2%; 使用多层感知器, 性能提升最大值为9.7%, 平均值为4%。使用随机森林缺陷预测的效果比朴素贝叶斯、支持向量机、多层感知器的效果要好, 性能平均高2%、10%、10%。
分析结果2: 在CCN上结合DeepWalk、Grarep、Node2vec特征后, 缺陷预测性能(AUC)优于仅考虑传统度量特征的预测性能, 且随机森林分类器比其他三种分类器的效果更好。
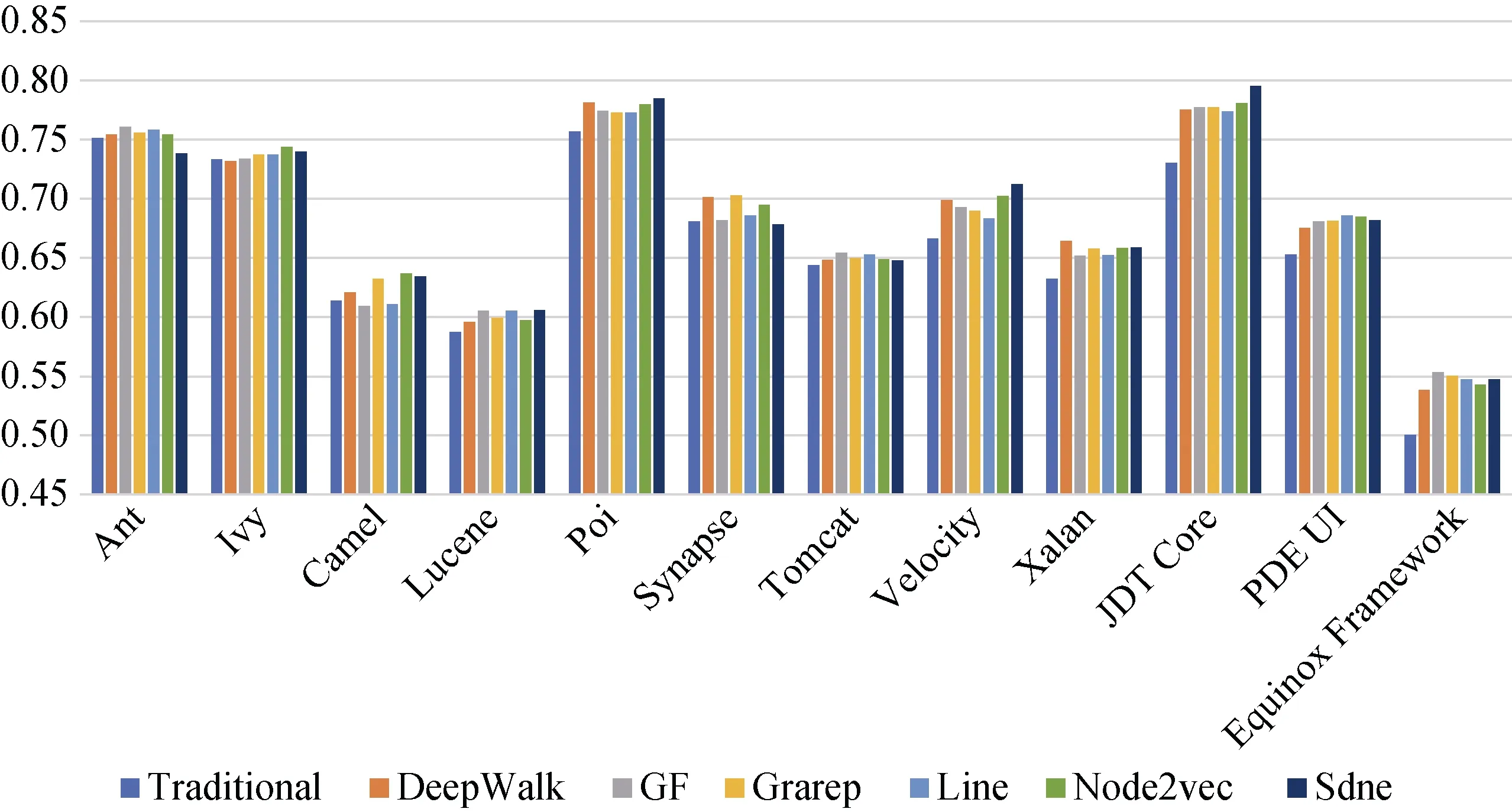
图14 CCN上缺陷预测的AUC值(使用支持向量机分类) Figure 14 AUC Value of Defect Prediction on CCN (by Support Vector Machine)
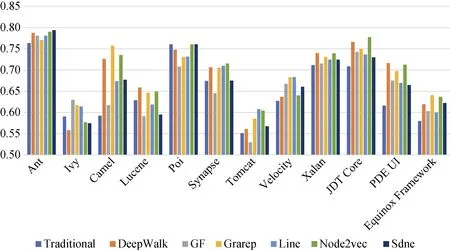
图15 CCN上缺陷预测的AUC值(使用多层感知器分类) Figure 15 AUC Value of Defect Prediction on CCN (by Multi-Layer Perception)
5.2.3 DCN的缺陷预测结果
表8展示了在DCN上传统度量特征和Grarep算法得到的网络嵌入特征通过随机森林分类器的预测结果, 每列所代表的含义和表6和表7相同, 加粗字体标出了每行的最大值。从最大值分布可以发现, 对每个实验对象来说, 缺陷预测的最好结果可能出现在传统方法中, 也可能出现在结合网络嵌入特征的方法中。也就是说, 在DCN中, 结合网络嵌入特征的缺陷预测结果不一定比基于传统方法的缺陷预测结果好, 没有明显的改进效果。
图16展示了DCN上传统方法以及分别与6种网络嵌入特征结合后通过随机森林分类器得到的缺陷预测AUC值。传统方法是基于代码度量的缺陷预测。从该柱状图中可以看出, 对于12个实验系统, 当Grarep、SDNE被应用于模型时, 可以提升半数实验对象的预测结果; 而其余网络嵌入算法在DCN上的效果不佳, 实验结果在大多数对象上均有下降。经过计算, 在DCN上, 结合Grarep算法或SDNE算法使得缺陷预测预测性能对比传统方法得到小幅提升, 平均提高0.8%, 而结合其余网络嵌入算法后的缺陷预测性能均未提升。
与上述类似, 图17、图18、图19分别显示了在DCN使用朴素贝叶斯、支持向量机和多层感知器进行缺陷预测的AUC值。由图17可知, 当DeepWalk、Grarep、SDNE被应用于基于朴素贝叶斯的模型时, 可以提升多数实验对象的预测结果, 平均提升1.1%,但不稳定。由图18可知, 分别结合6种网络嵌入算法在使用支持向量机分类算法后的缺陷预测结果, 在绝大多数的实验对象上的均得到小幅改善。且缺陷预测AUC值对比传统方法平均提高1.8%。而通过图19可知, 在多层感知器上的缺陷预测模型对比传统方法没有普遍且明显的性能提升。使用随机森林缺陷预测的效果比朴素贝叶斯、支持向量机、多层感知器的效果要好, 性能平均高2%、8%、9%。
分析结果3: 在DCN上结合网络嵌入特征的缺陷预测性能(AUC)对比仅考虑传统度量特征的预测性能没有明显改善,且随机森林分类器比其他三种分类器的效果要好。
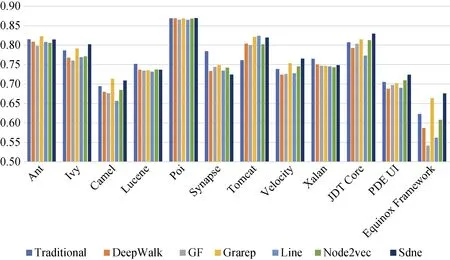
图16 DCN上缺陷预测的AUC值(使用随机森林分类) Figure 16 AUC Value of Defect Prediction on DCN (by Random Forest)
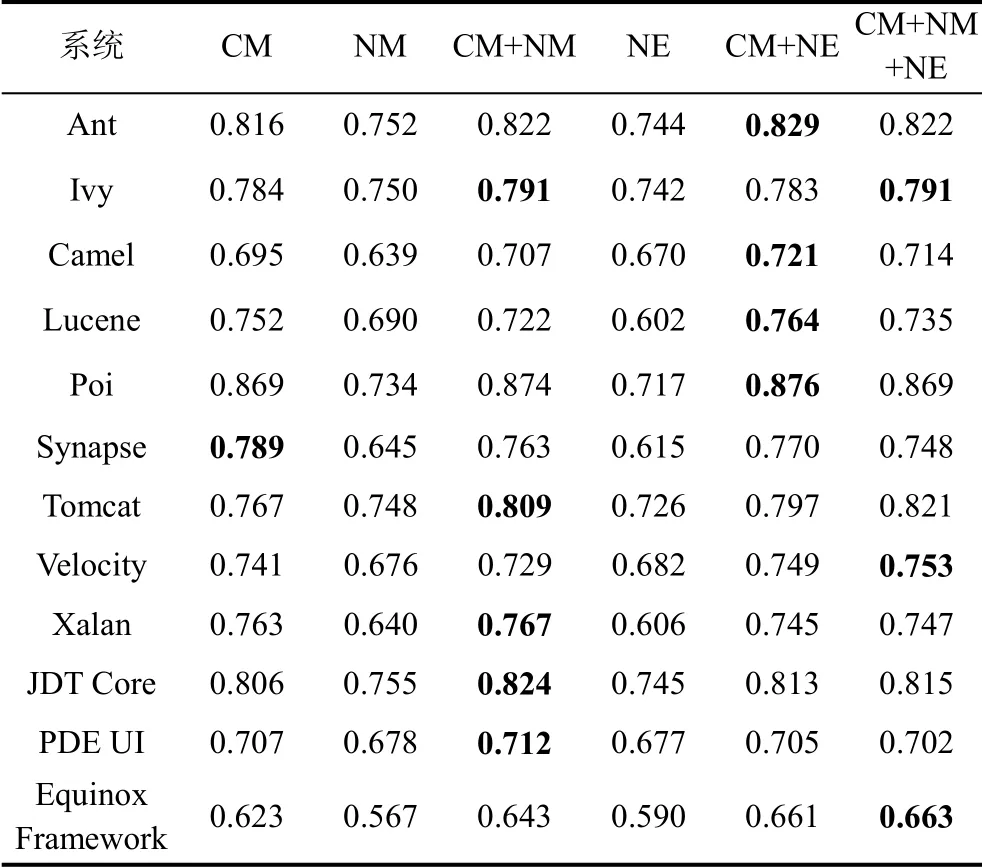
表8 DCN的缺陷预测AUC值 Table 8 AUC Value of Defect Prediction on DCN
5.3 软件关联网络嵌入特征分析
5.2 节实验发现基于不同的网络嵌入特征会得到不同的缺陷预测结果。为了进一步分析原因, 本节对网络嵌入特征进行深入研究。具体来讲, 使用k均值聚类[81]对网络嵌入特征进行聚类, 观察聚类结果在原软件关联网络结构的分布情况, 并结合缺陷预测结果进行比较, 总结引起前述缺陷预测实验效果差异的原因。
5.3.1 网络嵌入特征的可视化
通过网络嵌入算法得到网络中节点的向量表示, 对所有向量进行k均值聚类, 观察节点的聚类结果在软件关联网络中的分布, 以观察软件关联网络上的网络嵌入特征特性。为了对比, 我们根据软件网络中节点的亲疏关系划分出社区(community), 每个社区内部的节点间的联系相对紧密, 各个社区之间的连接相对比较稀疏。将社区划分结果与前述基于网络嵌入的聚类结果进行对比。
图20展示了Lucene软件的类依赖网络(CDN), 网络中共337个点, 1306条边。使用力引导布局来展示节点分布, 以便观察网络中节点之间的亲疏关系。网络中的节点利用Gephi工具①https://gephi.org/划分出社区, 连接紧密的节点位于同一社区, 每个社区内的节点分配同一种颜色。
由k均值聚类可以得到向量距离相近的网络节点, 我们将聚类结果表示在软件网络图中, 并借助Gephi工具画出, 分析节点的聚类在原软件网络中的分布。网络中的所有节点被分为8个簇, 不同的簇用不同的颜色表示, 两个节点如用一种颜色表示, 意 味着两个节点向量的距离相近, 从而被分到一个簇中, 图21展示了Lucene类依赖网络的节点分别基于6种网络嵌入特征的聚类结果。
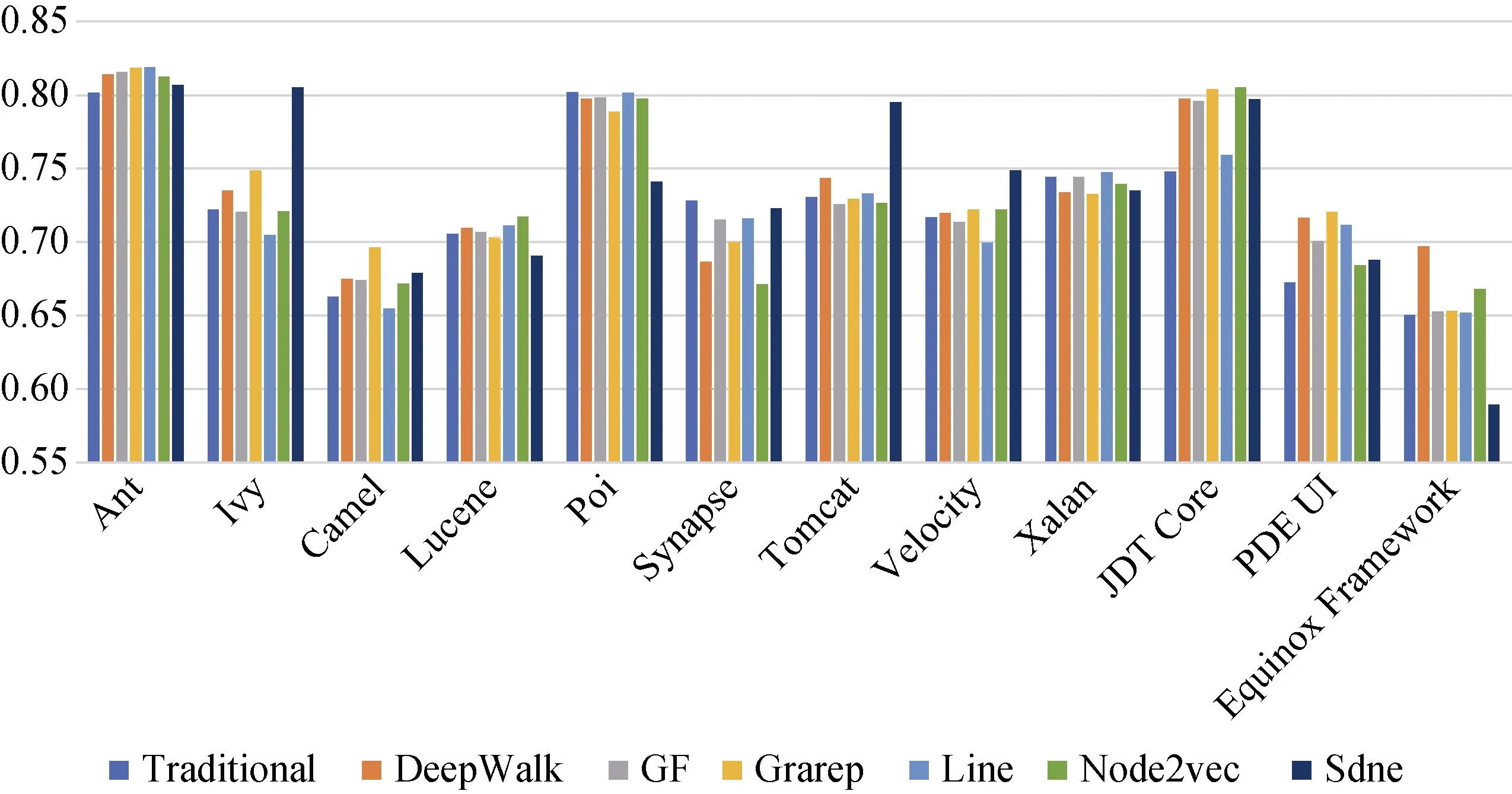
图17 DCN上缺陷预测的AUC值(使用朴素贝叶斯分类) Figure 17 AUC Value of Defect Prediction on DCN (by Naive Bayesian)
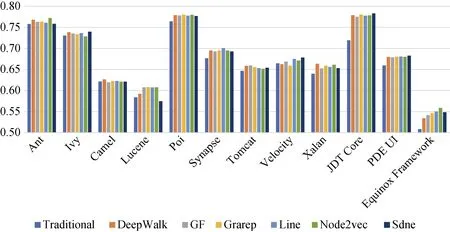
图18 DCN上缺陷预测的AUC值(使用支持向量机分类) Figure 18 AUC Value of Defect Prediction on DCN (by Support Vector Machine)
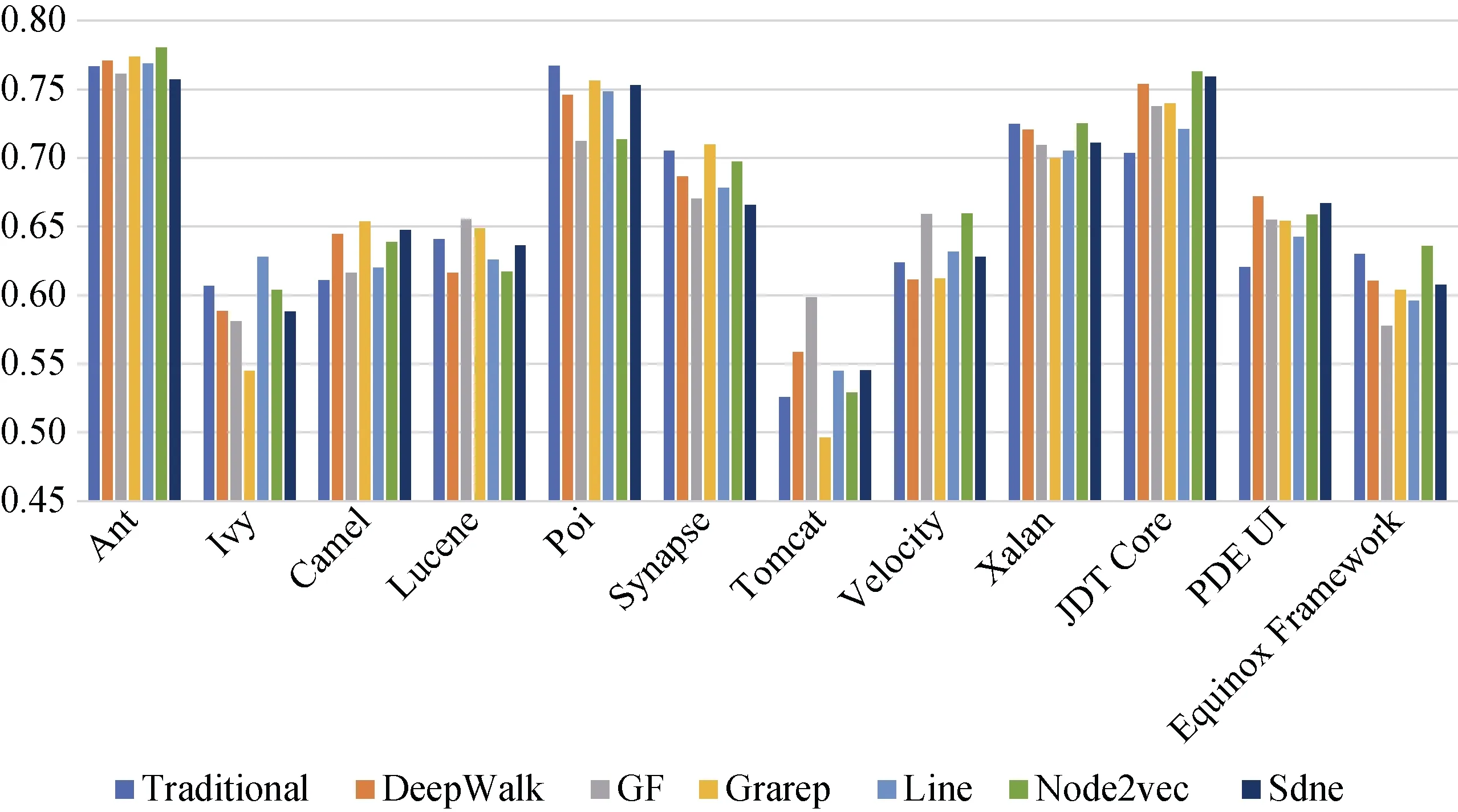
图19 DCN上缺陷预测的AUC值(使用多层感知器分类) Figure 19 AUC Value of Defect Prediction on DCN (by Multi-Layer Perception)
从图21可以发现, 不同网络嵌入的节点的聚类结果不一样。分析图中不同颜色节点的分布, 例如蓝色的节点, 经过DeepWalk、Node2vec和Grarep算法的聚类效果接近, 这3种网络嵌入算法均将原软件网络结构中连接紧密的节点聚为一类, 同一颜色的节点都相距很近。而LINE和GF算法将原软件网络中相距很远的节点映射到了相近的向量空间中, 从而聚类为一簇, 聚类结果与原软件网络没有明显的相关性。而基于SDNE算法的节点聚类结果图将网络中78%的节点聚为一类(橙色节点)。其余未展示出的11个软件也有同样类似的聚类结果。
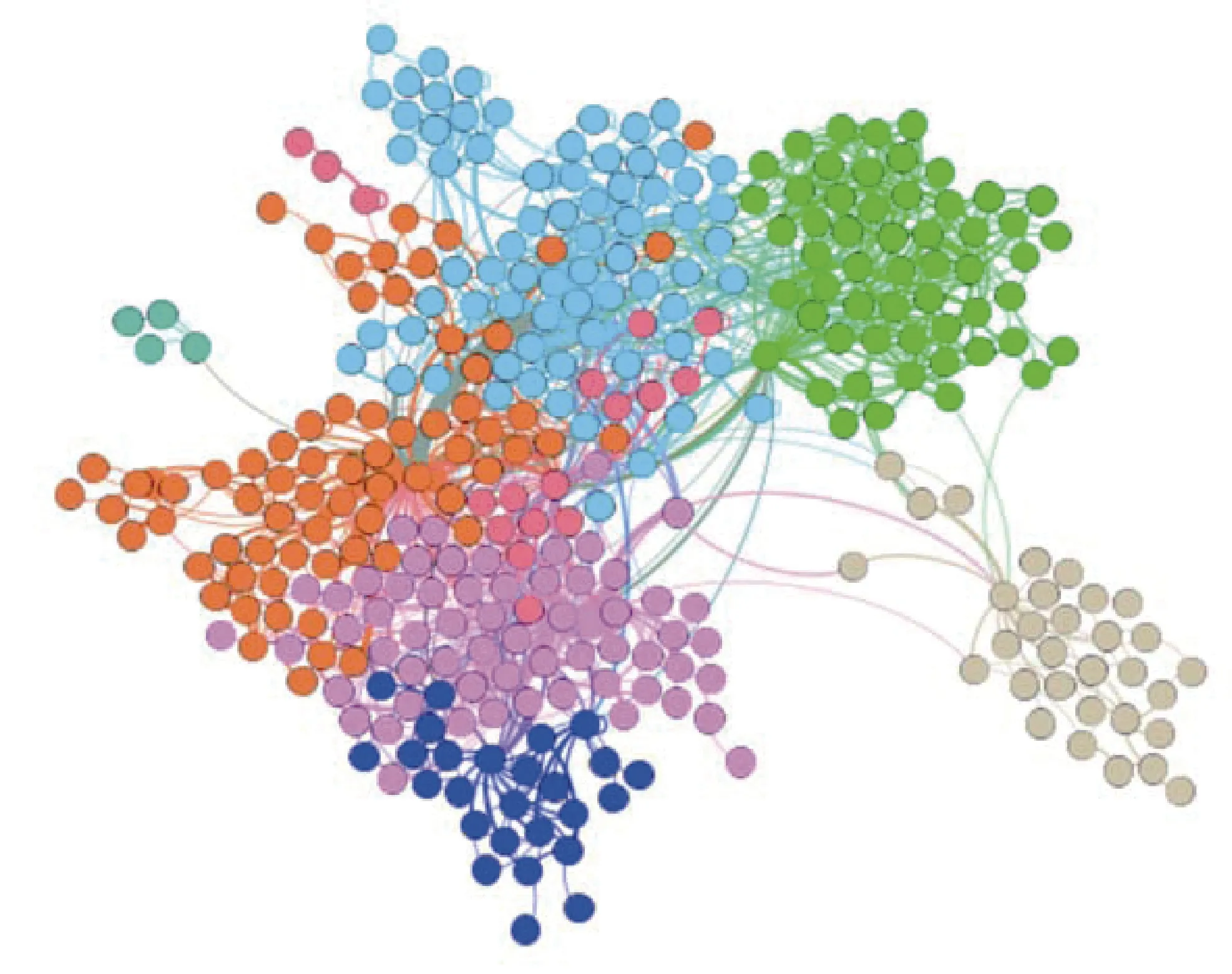
图20 Lucene软件类依赖网络(CDN) Figure 20 Class Dependency Network(CDN) of Lucene
分析结果4: 由上述可视化结果初步观察到, DeepWalk、Grarep和Node2vec算法比LINE和GF算法更擅长学习网络的同质性[16], 即倾向于将原软件网络中连接紧密的节点在向量空间中的距离也表示的相近。而LINE和GF算法却可能将网络中连接疏松的节点映射为在向量空间中相近的节点, 与原软件网络没有明显的相关性。
5.3.2 网络嵌入特征保持的网络结构分析
为了进一步分析6种网络嵌入算法学习网络同质性的能力, 本节用MoJoFM值[85]衡量基于网络嵌入的聚类结果与社区结构的相似程度(例如图11和图12之间的相似程度)。MoJoFM通过计算从一个结构转换到另一个结构所需的操作来度量两个结构之间的相似程度。较高的MoJoFM值意味着两个结构更相似。MoJoFM值介于0和1之间, 0表示最不相似, 1表示完全一样。MoJoFM的公式如下:
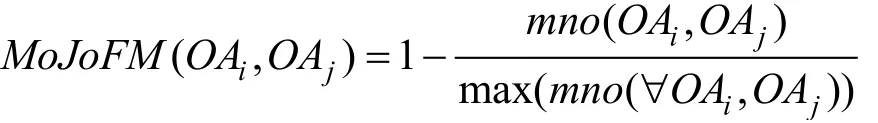
其中, mno(O Ai, OAj)表示从一个结构OAi转变成另一个结构OAj所需的Move操作和Join操作的数目。
表9对网络中划分的社区与6种网络嵌入特征的聚类结果的相似程度进行对比, 例如Lucene行DeepWalk列, MoJoFM值为47.98%, 说明Lucene的类依赖网络的社区结构与基于DeepWalk算法得到的聚类结果之间的相似程度为47.98%。MoJoFM值越大, 则说明聚类结果与社区的划分越相似, 网络嵌入算法能更好地保持网络中连接紧密的节点的结构特征, 对网络同质性的学习能力越强。
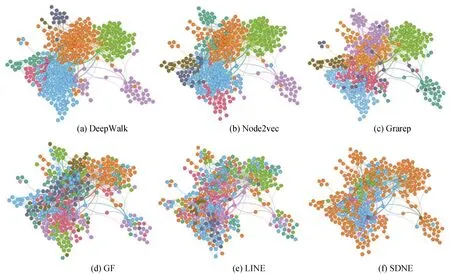
图21 Lucene类依赖网络的节点的聚类结果 Figure 21 Clusters of Class Dependency Network for Lucene

表9 Lucene的社区与聚类之间的MoJoFM值 Table 9 MoJoFM between Communities and Clusters for Lucene (%)
从表9可以发现, 对软件关联网络划分的社区与不同网络嵌入特征的聚类结果之间的MoJoFM值存在差别, 其中基于DeepWalk、Grarep、Node2vec算法的结果明显高于基于GF、LINE的结果。也就是说, 基于DeepWalk、Grarep、 Node2vec算法的聚类结果, 与网络的社区之间的相似程度更大, 可以使网络中紧密相连的节点映射到相近的向量空间。
分析结果5:该实验的定量分析结果验证了5.3.1节的可视化观察, 即: DeepWalk、Grarep和Node2vec算法比LINE和GF算法更擅长学习网络的同质性。
5.3.3 网络嵌入特征的缺陷预测性能分析
本节中用MoJoFM值对不同网络嵌入特征的聚类结果之间的相似性进行衡量, 并观察聚类结果的相似性与缺陷预测结果差值之间的关系。本节首先分析不同网络嵌入特征保持的软件网络结构信息之间的相似程度。用MoJoFM值衡量5.3.1节获得的6种网络嵌入特征的聚类结果之间的相似程度, Mo-JoFM值越大, 说明聚类结果越相似, 也就是网络嵌入特征保持的网络结构信息越相似。然后分析聚类结果相似性与相应缺陷预测性能差异之间的关系, 表10和表11展示Lucene软件基于不同网络嵌入的聚类结果之间的相似性与缺陷预测AUC差值。
对照表10和表11中的值可以发现, 对于Lucene软件, 两种网络嵌入特征的聚类结果之间相似度(MoJoFM)大于50%时, 则基于这两种网络嵌入的缺陷预测AUC差值不超过0.03。

表10 Lucene软件的网络嵌入聚类结果之间的MoJoFM值 Table 10 MoJoFM between Different Network Embedding Clusters for Lucene (%)
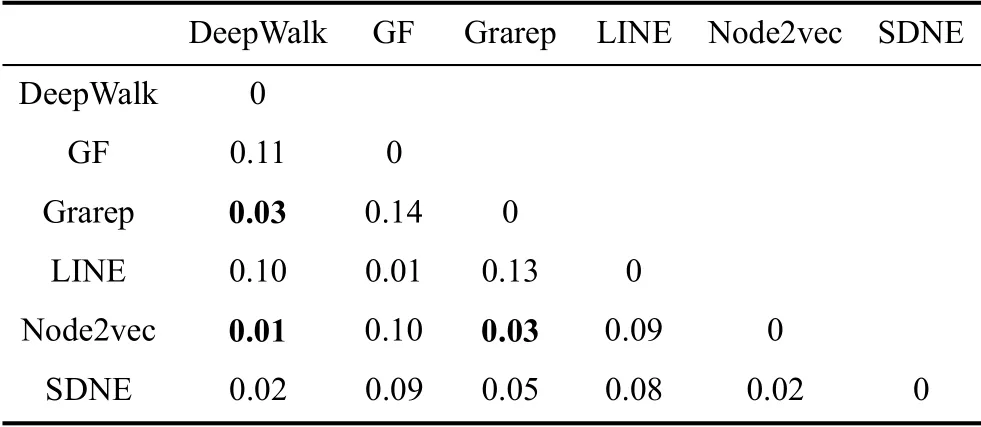
表11 Lucene软件基于不同网络嵌入的缺陷预测AUC差值 Table 11 AUC Difference Based on Different Network Embedding Algorithms for Lucene
对数据集中12个软件进行同样分析后发现类似的结果: 对某一软件, 用MoJoFM值度量任意两种网络嵌入特征的聚类结果之间相似度, 相似度大于50%则缺陷预测结果相近, 一般情况下缺陷预测AUC值之间相差小于0.05。并且由前述可知, DeepWalk、Grarep和Node2vec算法均擅长学习网络的同质性, 它们的缺陷预测性能良好且相近。
分析结果6: 当两种网络嵌入算法保持的软件关联网络的结构特征相似时, 其缺陷预测效果也相似; 且当网络嵌入能保持网络结构的同质性时, 则缺陷预测性能良好。
5.4 参数分析
本节分析不同的参数设置对缺陷预测带来的影响。5.4.1节展示了预处理时过滤阈值的选取对缺陷预测结果的影响。5.4.2节展示了网络嵌入算法在不同参数设置下的缺陷预测结果。
5.4.1 过滤阈值参数的影响分析
在数据集预处理中提到, 在构建CCN和DCN时需要找到最适用于缺陷预测模型的过滤阈值。图22展示了在不同过滤阈值下, 在CCN使用传统度量的缺陷预测AUC值。
如图22所示, 预测效果常在10~25之间上升, 在阈值为25的时候达到最佳, 在30和35时又有点回落。根据表5, 阈值为25时的网络已经包含了超过70%的真实节点信息。注意到在Equinox Framework上的实验阈值为10时的AUC值超过了阈值为 25的时候, 但这只是个例, 不具普遍性; 且阈值为10包含的节点信息过少, 无法准确地反映真实网络的情况。因而, 本文在前文缺陷预测实验中过滤阈值参数也是设置为25 (见5.1.2节)。
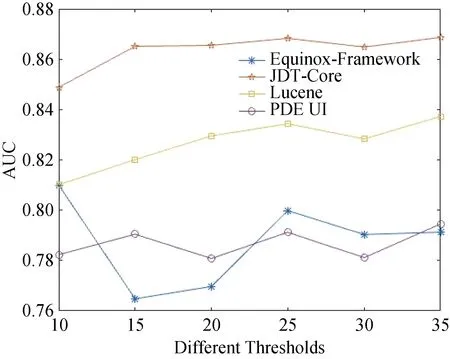
图22 不同过滤阈值下基于CCN的缺陷预测AUC值 Figure 22 AUC Value of Defect Prediction under Different Thesholds on CCN
分析结果7: 将CCN 和DCN用于缺陷预测时, 过滤阈值参数设置为25可使得缺陷预测性能得到最佳。
5.4.2 网络嵌入算法参数的影响分析
本节对网络嵌入算法的参数进行修改, 得到基于不同参数的网络嵌入的缺陷预测结果。每个网络嵌入算法选择一个主要影响参数进行修改, 表12和表13展示了5个软件在CDN上的基于不同参数的网络嵌入的缺陷预测结果。分析可得:
DeepWalk算法的步长参数从80改为40后, 缺陷预测效果没有明显差异。
GF算法的epochs参数从5调整为100后, 缺陷预测效果在所有软件中均有大幅提升。
Grarep算法中的kstep参数不同时, 可以得到不同阶次的全局信息, 将kstep从4调整为8后, 得到的缺陷预测结果并没有大的变动, 说明调整参数前后, 算法保持的网络结构信息相似。
LINE算法中的epochs参数从5调整为100后, 与GF算法类似, 缺陷预测效果在所有软件中均有大幅提升。
Node2vec算法的p、q参数用于控制随机游走的方向。当p=1、q=0.5时, 算法对比p=1、q=1更擅长学习网络的同质性。并且从缺陷预测结果可以观察到, 当算法参数选择p=1、q=0.5时, 拥有更好的缺陷预测效果, 即连接紧密的节点在低维向量空间中的表示结果也相近时, 可以获得更好的缺陷预测效果, 这与5.3节中得到的结论是一致的。
SDNE算法修改encoder-list参数的第一项, 将编码器的神经元个数从1000改为500, 缺陷预测效果变化较小, 说明调整该参数前后, 算法保持的网络结构信息相似。
分析结果8: 网络嵌入算法参数发生变化时, 相应的缺陷预测效果会受到不同程度的影响。特别是, 缺陷预测性能对Node2vec、LINE、GF算法的参数更为敏感。
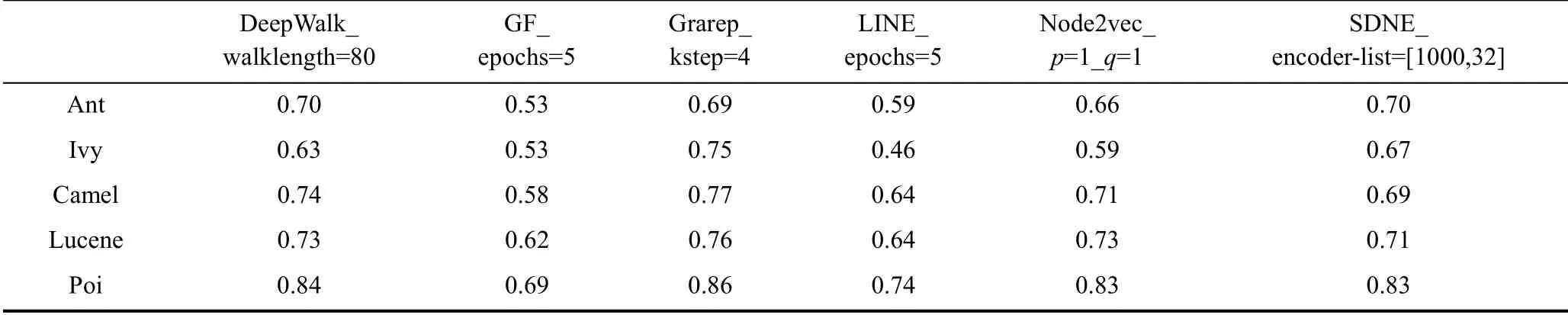
表12 基于网络嵌入的缺陷预测AUC值 Table 12 AUC Value of Defect Prediction Based on Network Embedding
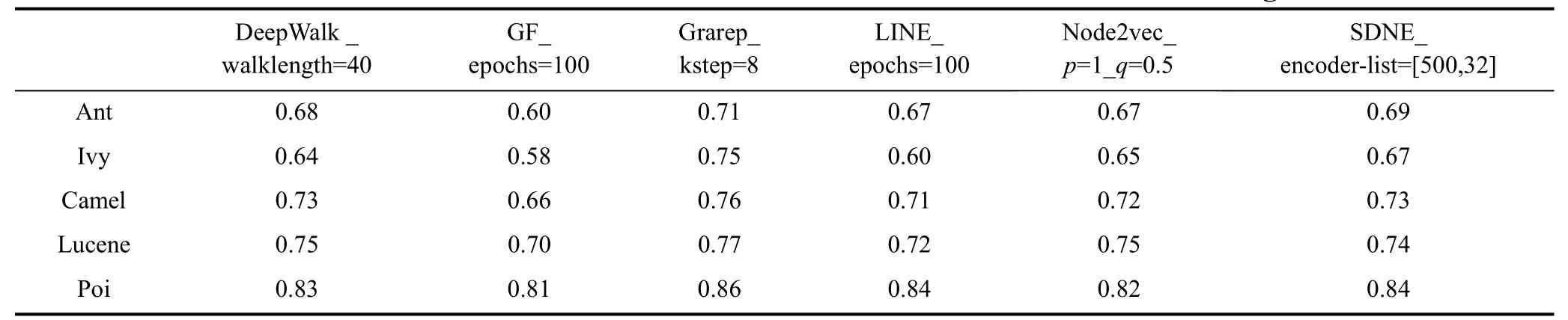
表13 基于网络嵌入的缺陷预测AUC值 Table 13 AUC Value of Defect Prediction Based on Network Embedding
5.5 实验小结
本章研究了基于不同网络嵌入特征的缺陷预测结果。首先展示了实验的数据集, 对实验软件构建了3种网络——CDN、CCN和DCN, 将传统度量特征和6种网络嵌入特征与对应缺陷标签输入至4种分类算法中进行训练并测试, 并用AUC值衡量缺陷预测效果, 总结见表14。然后分析了网络嵌入保持的网络结构特征以及缺陷预测性能差异的原因, 最后分析了不同参数设置下的网络嵌入特征对缺陷预测性能的影响。
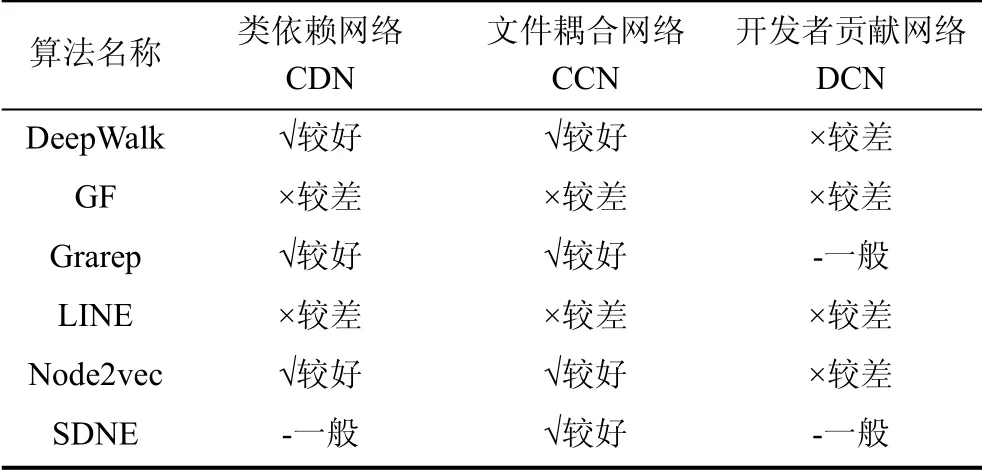
表14 面向缺陷预测的网络嵌入算法预测效果总结 Table 14 Summary for Defect Prediction Based on Network Embedding
总体而言: 1) 除了开发者贡献网络DCN之外, 在类依赖网络CDN和文件耦合网络CCN上, 在传统的度量特征上结合网络嵌入特征后, 缺陷预测性能得到显著提升; 2)使用随机分类器的效果要比朴素贝叶斯、支持向量机、多层感知器的效果要好; 3) DeepWalk、Grarep和Node2vec这3种网络嵌入算法保持的网络结构特性类似, 缺陷预测效果相近; 4) 与LINE和GF算法不同, DeepWalk、Grarep和Node2vec算法更擅长学习网络的同质性, 因而在相同软件关联网络上的缺陷预测效果更好; 5) 网络嵌入算法在不同的参数设置下保持的网络结构特性存在差异, 缺陷预测性能对网络嵌入算法参数敏感, 实验中应根据观察和经验选择合适的参数。
6 总结和未来工作
本文主要研究面向软件缺陷预测的网络嵌入特征, 设计了一种基于软件关联网络嵌入的缺陷预测方法, 全面分析了不同软件关联网络、不同网络嵌入算法、不同参数设置下的网络嵌入特征及其缺陷预测性能。通过实验分析, 主要发现类依赖网络和文件耦合网络比开发者贡献网络更能显著提升缺陷预测效果; DeepWalk、Grarep和Node2vec算法比LINE和GF算法更擅长保持网络结构的同质性, 因而这3种算法下的缺陷预测效果最好。此外, 缺陷预测对网络嵌入算法参数设置敏感。总之, 本文得出的实验结论有助于指导缺陷预测活动中如何选择软件关联网络和网络嵌入算法以获取较好的性能。
未来将进一步完善本文工作, 包括: 1)本文构建的类依赖网络是针对面向对象特性, 使用的实验对象是Java实现的软件系统。在应用于其他编程语言如C/C++、Python等实现的系统时, 需要扩展类依赖网络, 以更准确的描述软件网络结构, 我们未来将对这一部分进行探索。2)本文探究了对相同软件使用不同网络嵌入算法得到的缺陷预测效果的差异性原因, 也观察到不同软件上的缺陷预测效果存在一定差异。因此未来将分析不同软件系统上预测效果差异的原因。3)除了本文使用的AUC外, 还有其他评价分类性能的指标, 例如对于不均衡数据集的评估非常有效的MCC(Matthews Correlation Coefficient)指标。未来将使用更多的相关指标进一步验证本文缺陷预测效果。
致 谢 在此向给予指导的老师、提供帮助的同学和给本文提出建议的评审专家表示感谢。并且感谢国家重点研发计划资助项目(No.2018YFB1004500), 国家自然科学基金(No.61632015, No.61772408, No.U1766215, No.61721002, No.61833015, No.62002280, No.61902306, No.61602369), 国网陕西省电力公司科技项目(No.5226SX1800FC), 教育部创新团队(No.IRT_17R86)和中国工程科技知识中心项目, 中国博士后资助项目(No.2019TQ0251, No.2020M673439)的资助。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
新高考·高一数学(2022年3期)2022-04-28 07:02:46
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
电子测试(2017年15期)2017-12-18 07:19:27
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
智能系统学报(2015年4期)2015-12-27 09:38:39
新高考·高二数学(2015年11期)2015-12-23 18:17:44
