
基于变分推断和元路径分解的异质网络表示方法
2021-06-01 03:41:34孙海超谭洪胜
上海交通大学学报 2021年5期
袁 铭, 刘 群, 孙海超, 谭洪胜
(重庆邮电大学 计算机科学与技术学院, 重庆 400065)
网络表示学习[1-2]是网络数据挖掘中的一项重要技术,能够将网络中的每个节点用一个向量表示出来,从而把网络结构映射到一个由节点向量组成的低维空间,为基于网络拓扑的链路预测、节点分类、聚类等任务提供数据结构的支撑.在实际应用中,不同的复杂信息网络通常都具有异质性,其表现为在同一个网络中包含多种不同类型的节点和多种不同类型的链接关系,这种网络也被称为异质网络.与同质网络相比,这类网络通常具有丰富的交互关系.其中,不同类型的节点和链接都隐含了极其丰富的语义和结构信息,如智能电网、生物蛋白质网络、社交网络等.
近年来,同质网络表示学习已经取得了丰富的成果.Deepwalk算法[3]利用随机游走首次将网络结构建模为语料序列,结合Skip-Gram模型得到节点的低维表示,为网络分析任务提供了新的思路.随后,更多的同质网络表示算法被提出[4-6],如Node2vec算法和LINE算法,采用不同的随机游走设计,结合Skip-Gram模型学习更为准确的节点向量表示.但以上方法将不同类型的节点和链接都视为相同类型来建模,不具备针对异质网络的有效设计.显然,如果忽略网络的异质性问题,容易导致各种网络分析任务的准确性有所降低.只有表征出网络中不同类型节点及链接的独有特征,才能捕获网络中丰富的语义,因此对异质网络表示学习的研究具有重要意义.
由于异质网络中节点和链接的复杂性,传统的同质网络表示方法难以直接应用于异质网络表示学习中.近年来,国内外许多研究者进行的一些相关研究,可以概括为以下3类.① 基于浅层网络的方法,这类方法通过随机游走捕获网络结构,结合浅层模型学习节点向量的表示.文献[7]中提出了HIN2vec算法,通过联合执行多个预测训练任务来预测两个节点之间的关系,并将预测任务转化为二分类问题,利用两层神经网络学习异质网络中节点和元路径的表示.文献[8]中提出了Metapath2vec算法,利用基于元路径的随机游走构建节点的异质邻居,扩展了Skip-Gram模型,从而为结构和语义上相近的节点建模.文献[9-10]中针对异质文本网络和跨网络场景学习节点的表示,采用网络分解来简化异质网络的表示建模.② 基于深度网络的方法,这类方法采用不同深度学习的方法获得网络中高度非线性的特征.文献[11-13]中尝试将卷积神经网络、自动编码器、强化学习等方法用于异质网络中节点的表示学习.随着图神经网络在网络分析任务中表现出优异的性能,一些研究者将其扩展到了异质网络的分析中[14-15],针对异质网络中不同类型节点和链接的特点,改进图神经网络消息传递方式,聚合不同类型邻居生成节点的向量表示.③ 基于属性异质网络的方法,这类方法尝试利用年龄、性别、地理位置等额外的节点信息,研究更为复杂的异质网络场景.文献[16-17]中针对金融现金检测和用户购物场景,利用线性变换将额外的属性信息映射到低维空间,并通过设计分层的异质网络表示架构,较好地进行了融合,学习到更加丰富的节点表示.
尽管将上述各种表示方法应用于不同网络任务中都获得了较好的效果,但是仍然存在以下两个问题.首先,节点间关系的表示都是基于邻居节点的相似性计算获得的,无法反映无直接边的节点间的相似关系;其次,整个网络拓扑结构的表示过程采用的均为基于元路径的随机游走策略,忽略了相邻节点间的真实关系.显然在实际网络中,不存在直接连边的节点仍然有可能具有较高的相似性,而简单的基于固定概率随机选择生成的节点序列,并不能保证生成高度紧密相似的节点序列.为此,本文提出了基于变分推断和元路径分解的异质网络表示方法HetVAE,主要贡献如下:
(1) 引入路径相似度度量,通过不同语义下的异质路径实例计算出同类型节点的相似度,并在相似度的引导下设计不同类型节点的选取概率,改进了基于元路径随机游走的节点选择策略,使得生成的节点序列更准确.
(2) 引入变分推断理论,通过变分Bayesian推断优化真实先验分布与后验分布之间的误差,同时近似推导出潜在变量,从而学习到更符合真实网络分布的节点向量,使得异质网络中的节点向量表示更具稳健性.
(3) 引入元路径思想将异质网络拆分为多个同质子网络,以便获取原始网络不同视角下的丰富语义信息,进而结合注意力机制,通过网络重建和将拆分后各个加权子网络的节点向量进行融合.
本文通过相似度改进的节点选择策略,较好地解决了异质网络中传统元路径随机游走不精确的问题;利用变分推断捕获网络的真实分布,改进了传统异质网络表示模型不能观测潜在变量的缺陷;结合注意力机制,自动融合不同视角下的语义信息.在多个数据集上的不同网络任务的实验结果表明,所提方法能够获得更好的结果.
1 预备知识
首先,给出后续使用的基本定义和概念.其中,关于异质网络以及元路径的概念可以参考文献 [18-19].
一个典型的异质网络DBLP学术网络如图1所示.该网络中4种不同类型的节点,作者(A)、论文(Pa)、会议(C)、关键词(T) 如图1(a)所示;网络中3种不同类型的边关系,包含论文和作者、论文和会议、论文和关键词如图1(c)所示.这3种类型的边关系分别涵盖了3条元路径,每一条元路径代表一种语义,元路径APaA代表两位作者的合著关系,元路径APaCPaA代表两位作者的文章发表在同一期刊/会议上,元路径APaTPaA代表两位作者的文章具有相同关键词.

图1 DBLP异质网络示例Fig.1 An example of a DBLP heterogeneous network
元路径引导下的邻居节点:在异质网络中给定一条元路径P,对于任意节点vi,元路径P引导下的邻居节点定义为节点vi通过元路径P到达的所有节点,记为NP(vi),定义中的邻居节点也包含vi本身.由图1(c)可知,对于节点A1,在元路径APaA下的邻居节点是A2.
2 基于变分推断的异质网络表示模型
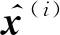
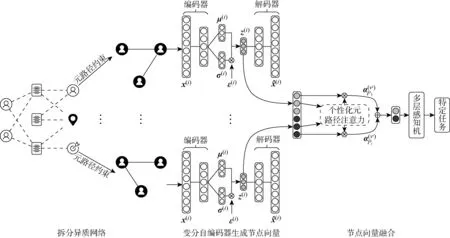
图2 HetVAE的整体框架Fig.2 Overall frame work of HetVAE
2.1 拆分异质网络
2.1.1改进的随机游走策略 在异质网络中元路径用于定义不同类型节点之间的关系.由于元路径约束下的随机游走能够探索异质网络的复杂完整结构,捕获网络的全局语义信息,所以基于元路径的随机游走成为异质网络挖掘中的一种通用方法.然而,传统的元路径随机游走由于游走过程随机性较强,无法体现节点间的相似关系,导致不能精确地表示网络结构.目前,在异质网络表示的节点相似性计算中,大多数计算公式都是基于同质网络而设计的,如路径总数相似度、游走相似度、成对游走相似度等计算方法,更倾向于使高度可见(即与大量路径有关联的对象)或者高度集中的对象(即占一组关联路径中很大比例的对象)获得更高的相似度[19].这一类相似度度量方法没有考虑路径背后的不同语义,忽略了对象和链接之间的异质性,使得相似性计算方法缺乏合理性.
为了解决这一问题,本模型引入PathSim算法[19]来度量异质网络下元路径上节点的相似性.这种节点相似性度量方法能够通过考虑异质网络中的链接关系类型,识别出元路径下语义更为一致的相似节点.改进后的元路径随机游走节点选择策略,使得生成的节点序列能够在有限步骤的随机游走过程中捕获网络中的语义信息,提高生成的节点序列的质量.
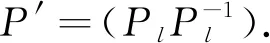
sim(v,y)=
(1)
在获得对应于不同元路径的同质网络过程中,为了更准确地选择元路径引导中的不同类型节点,本模型分成两种情况进行处理.
(1) 当后继邻居节点类型与元路径起始节点类型一致时,则计算出该后继节点与其前驱节点的sim(v,y)值,相似度值越大的节点具有更大的选择概率.对邻居节点的选择概率公式为
(2)
(2) 对于不同于元路径起始节点类型的邻居节点,由于其主要作用是构成语义约束,所以对这类邻居节点的选择概率可以相同,其计算公式如下:
(3)
节点选择策略如图3所示,其中虚线表示根据式(3)的选择概率选择下一跳节点.以A1节点为例,下一跳节点包含Pa1、Pa2两个节点,其类型与A1节点不同,因此选择的概率相同.实线表示从Pa类型根据式(2)的选择概率选择下一跳节点,以Pa2节点为例,下一跳节点包含A2、A3两个节点,其类型与初始节点A1相同,则应计算元路径APaA下的PathSim相似度,并根据式(2)的选择概率选择节点,根据选择概率计算可知A2被选择的可能性比A3更大,这是由于在APaA元路径下,从A1节点出发到A2节点具有更多的可达路径.
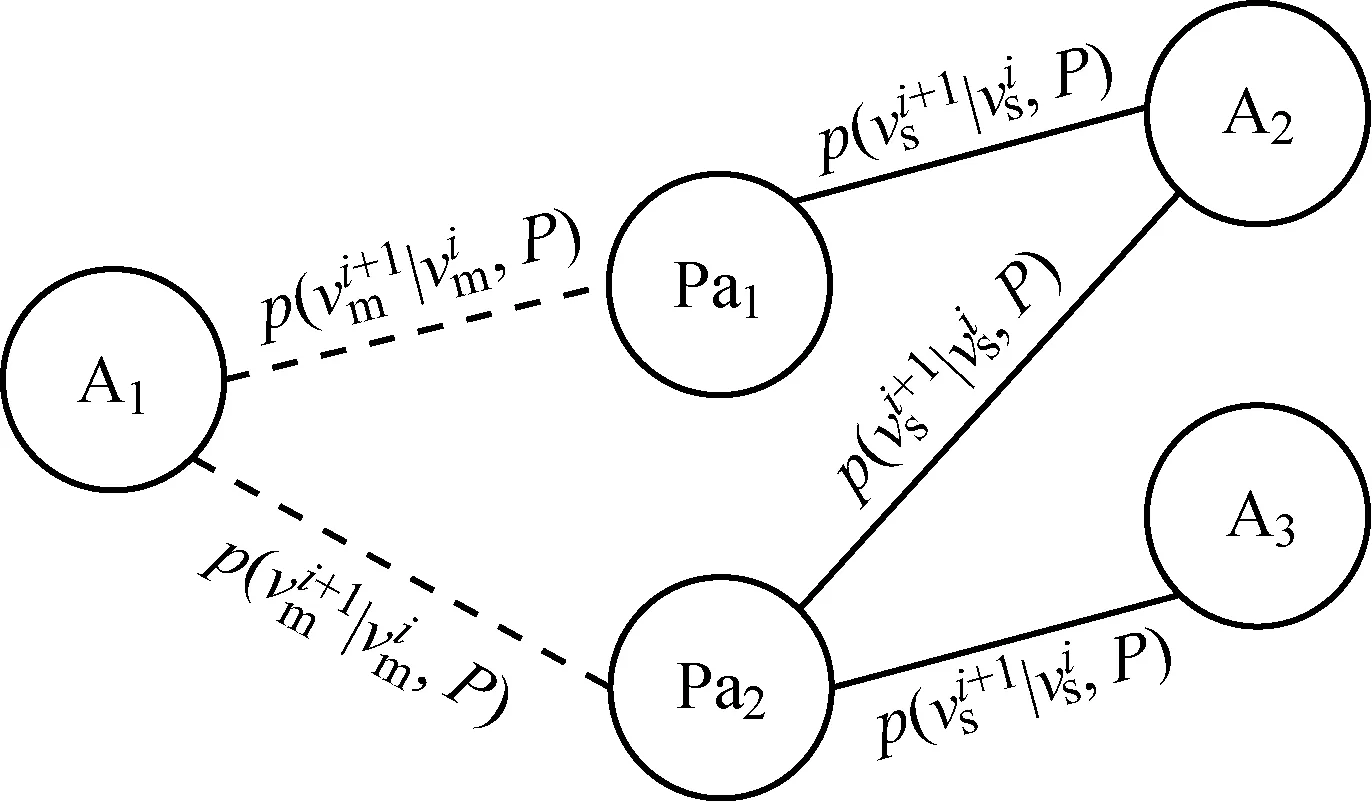
图3 节点选择策略示例Fig.3 Example of a node selection strategy
2.1.2重建同质网络 通过在元路径随机游走过程中保留元路径P1,P2,…,Pi引导下的同类型邻居节点,异质网络能转化为多组同质节点序列H1,H2,…,Hi.为了能够捕获网络中反映每个节点的特征向量,本模型将上述节点序列重构为同质网络.
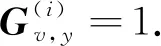
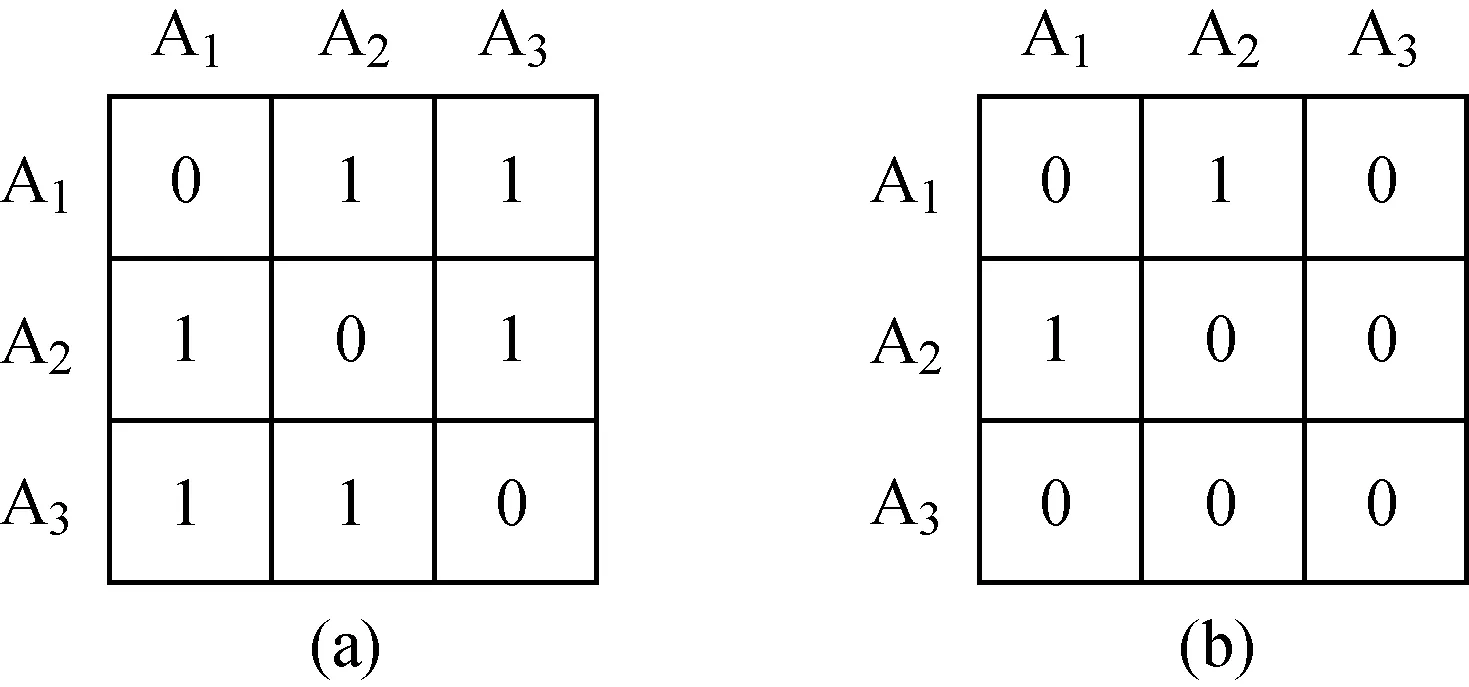
图4 DBLP中重构同质网络矩阵说明Fig.4 Reconstruction of homogeneous network matrix in DBLP
2.2 变分自编码器生成节点向量
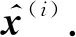
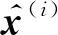
DKL(qφ(z(i)|x(i))‖pθ(z(i)|x(i)))=
lnpθ(x(i))-Eqφ(z(i)|x(i))[lnpθ(x(i)|z(i))-
lnqφ(z(i)|x(i))]
(4)
式中:Eqφ(z(i)|x(i))为识别模型的期望.其从后验分布中采样的潜在变量z(i)可以表示为
z(i)=μ(i)+σ(i)⊙ε(i)
(5)
式中:⊙表示逐元素乘法.最终获得原始网络分布中每一个数据x(i)的损失函数近似估计结果为
Γ(θ,φ;x)≃
(6)
式中:第1项为近似后验分布和先验分布的KL散度;第2项为重建误差对后验分布的期望.
为了获得原始异质网络中节点的向量表示,HetVAE将生成的多个同质网络矩阵作为变分自编码器的输入.在本文中,输入数据和生成数据均为节点对象.通过训练,利用变分推断理论对隐空间中的节点数据分布进行采样,生成各个同质网络中所有节点的向量表示.模型的编码器和解码器均为多层感知机(MLP).
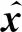
(7)
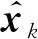
对于输入的xk其对应的隐空间表示zk由下式计算可得:
(8)
(9)
(10)
(11)
(12)
c=2,3,…,C
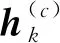
(13)
式中:μd、σd分别为μk、σk的第d维的均值和方差分量,即μk=[μ1μ2…μD]和σk=[σ1σ2…σD]两个向量.为了加速收敛速度,将编码器原本的均值输出σ转化为上式中的ln(σ2),记为δ=ln(σ2).通过计算σ=eδ/2可以得到原本的均值σ,这使得编码器可以更容易获得不同比例的均值σ.经过简化之后的KL散度损失函数可以表示为
(14)
对应的隐变量z的式(12)则重写为
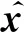
(17)
(18)
(19)
c=2,3,…,C-1
由于所获得的同质网络邻接矩阵是典型的稀疏矩阵,即在邻接矩阵G(i)中零元素远远多于非零元素.如果直接对G(i)最小化重建误差,网络将更容易重建零元素,而不是更有意义的非零元素.因此,HetVAE对非零元素加入了更多的惩罚,使模型能够优先重建非零元素,修正后的重建误差损失函数如下:
(20)
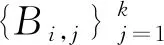
模型训练的损失函数由式(7)变换如下:
Γvae=Γrec+ΓKL+Γreg=
(21)
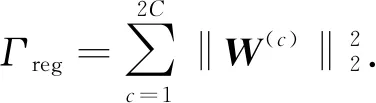
2.3 多视角信息的融合
显然,只有将多视角下的同质网络表示向量进行融合才能获得原始异质网络中节点的最终向量表示.由于拆分后的子网络描述了不同语义,进行向量融合的一种合理的方式就是利用注意力机制[21].常见的注意力机制包括自注意力和多头注意力等.自注意力机制减少了对外部信息的依赖,擅长捕捉数据或特征的内部相关性.多头注意力机制通过利用多个注意力头来学习注意力权重,擅长捕捉不同空间的关联关系.考虑到不同视角下节点对不同语义的关注程度,自注意力机制并不适合于求解不同视角的关注,同时多头注意力机制由于需要计算多次权重,会严重影响模型的训练速度.因此,本文模型结合多层感知器实现注意力机制,将不同子网络的节点向量进行融合.
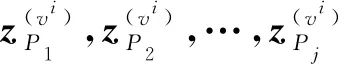
(22)
(23)
(24)
(25)

(26)
2.4 模型算法描述
综上所述,HetVAE的核心思想如下所示:

算法1HetVAE算法模型.
输入异质网络G(V,E)
元路径集合{P1,P2,…,Pi}
惩罚因子B
输出节点的最终表示Z
(1) forPi∈{P1,P2,…,Pi}do
/*拆分异质网络*/
(2) for eachvi∈Vdo
(3)v←startvi
(4) if type(v) is equal to type (y) then
(5) calculate sim(v,y), select a node by Eq.2
/*选取同类型节点*/
(6) else
(7) select a node by Eq.3
/*选取不同类型节点*/
(8) obtain homogeneous node sequencesHi
/*获得同质节点序列*/
(9) end if
(10) reconstructing a homogeneous network
/*重构同质网络*/
(11) end for
(12) end for
(13) forG(i)∈{G(1),G(2),…,G(i)} do
(14) initialized parametersW(i),b(i),B
(15) repeat
(16) minimizeΓvae=Γrec+ΓKL+Γreg
(17) until converge
(18) extract the hidden layer to get the
node representationz(i)/*获取隐层表示*/
(19) end for
(20) for eachvi∈Vdo
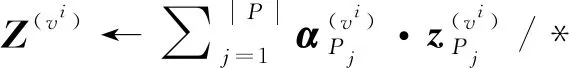
(22) end for
(23) returnZ(vi)

3 实验与结果
为了验证HetVAE模型的有效性,在3个真实数据集DBLP、AMiner、Yelp上使用微观F1值(Micro-F1)、宏观F1值(Macro-F1)、标准化互信息(NMI)和调整兰德系数(ARI)评价指标,针对3种典型的异质网络挖掘任务:节点分类、节点聚类、可视化进行了实验评估.
3.1 数据集
实验使用的3个被广泛研究的公开数据集:DBLP[14]、AMiner[8]、Yelp (https://www.yelp.com/dataset/),其详细描述如表1所示.其中:Bu为企业;S为服务;St为星级;U为用户.
(1) DBLP数据集:包含论文、作者、会议/期刊、关键词4类节点,并按照作者的研究领域划分为4个类别,包含数据库、数据挖掘、人工智能、信息检索,以此作为标签.模型使用元路径集合{APaA,APaCPaA,APaTPaA}进行实验.
(2) AMiner数据集:实验抽取了AMiner的一个子集,包含论文、作者、会议/期刊3类节点,同样按照作者的研究领域进行划分,得到8个类别,包含计算机语言学、计算机图形学、计算机网络和无线通信、计算机视觉和模式识别、计算机系统、数据库和信息系统、人机交互、理论计算机科学,以此作为标签.模型使用元路径集合{APaA,APaCPaA}进行实验.
(3) Yelp数据集:包含企业、用户、星级、服务4类节点,按照企业的类型进行划分,得到3个类别,包含酒店、购物、食品,以此作为标签.模型使用元路径集合{BuSBu,BuStBu,BuUBu}进行实验.
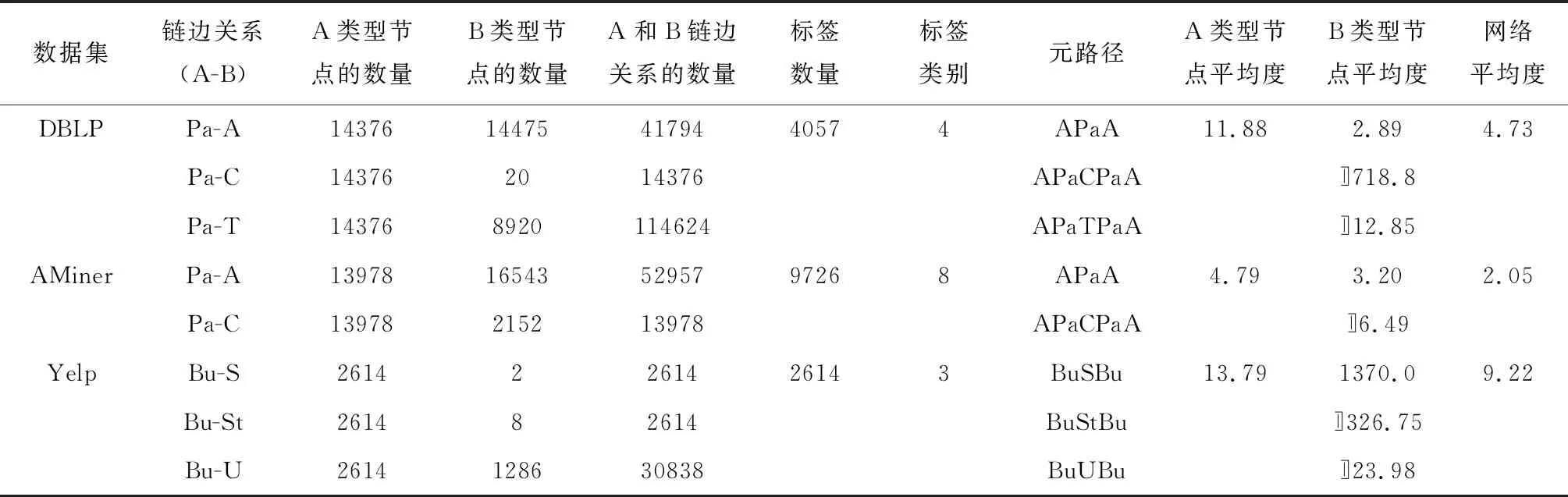
表1 数据集描述Tab.1 Dataset description
3.2 对比算法
实验选取了一些较新的先进方法进行了比较,包含2个同质网络方法和4个异质网络方法,用以验证本文算法的有效性.对于同质网络算法,在实验中忽略节点的异质性,将算法应用在整个异质图中.对于异质网络算法,在实验中测试了所有元路径.对比算法给出的均为最优结果.
(1) Deepwalk[3]:采用随机游走捕获网络结构,利用Skip-Gram模型学习节点的表示.
(2) Node2vec[4]:通过调整随机游走的深度和广度获得网络结构,利用带负采样的Skip-Gram模型学习节点表示.
(3) HIN2vec[7]:以元路径形式指定的一组关系联合执行多个预测训练任务,学习异质网络中节点和元路径的表示.
(4) Metapath2vec[8]:利用元路径随机游走构建节点的异质邻居,并采用异质的Skip-Gram模型最大化异质上下文概率.
(5) HERec[22]:设计了一种类型约束策略来过滤节点序列,并采用Skip-Gram模型来对网络进行嵌入.
(6) HAN[14]:设计了异质图下的节点级注意力和语义级注意力,并采用图神经网络对基于元路径的邻居特征进行分层聚合生成节点向量.
(7) HetVAErw:未使用改进的随机游走选择策略,采用普通元路径随机游走算法的模型.
(8) HetVAEsk:未使用VAE生成节点向量,采用Skip-Gram算法对网络进行训练的模型.
(9) HetVAEcon:未使用个性化元路径注意力机制,采用拼接的方式融合最终向量的模型.
(10) HetVAE:本文所提出的完整模型.
3.3 参数设置
本模型的所有实验均在Intel(R) Core(TM) i5-7300HQ(2.5 GHz) CPU,NVIDIA GTX1060(6G) GPU,16 GB内存的硬件环境下完成训练,所涉及的代码使用Python和Tensorflow框架实现.
为了进行公平对比,实验中将所有算法最终生成的节点向量维数设置D=128,对于需要随机游走的算法,设置每个节点的步数为10,随机游走长度为80.对于Deepwalk、Metapath2vec、HERec,选取了各自文献中给出的窗口大小参数为5.对于Node2vec其窗口大小参数为5,广度优先参数为4,深度优先参数为1,负采样比率为5.对于HIN2vec,设置窗口大小参数为4.对于HAN,其正则化参数为0.001,注意力头个数为8,注意力向量维度为128,实验采用了其论文中相同的处理方法,对节点特征进行提取.在DBLP、AMiner数据集中,节点特征为作者论文关键词的词袋表示;在Yelp数据集中,节点特征为企业星级类别的词袋表示.对比实验参数设置均与其文献推荐的最优参数一致.在实验中,对于DBLP数据集而言,网络结构为14475-1000-128-1000-14475,每一个数字代表网络每一层的神经元个数,学习率设置为 0.000 1,惩罚项B设置为2,批处理大小为32.对于AMiner数据集而言,网络结构为16543-2000-128-2000-16543,学习率设置为 0.000 35,惩罚项B设置为150,批处理大小为128.对于Yelp数据集而言,网络结构为2614-1000-128-1000-2614,学习率设置为 0.000 1,惩罚项B设置为64,批处理大小为128.
3.4 节点分类
对于节点分类任务,将模型学习到的节点向量作为特征向量,和文献[13]相同,采用K=5的K近邻(KNN)分类器进行分类,使用Micro-F1和Macro-F1作为分类结果评估指标.为了使结果具有可靠性,采用重复10次的结果平均值,并将数据集的训练集按照30%、50%、70%、90%的比例选取,同时打乱数据顺序,以比较不同训练尺度下的分类效果.
节点分类任务实验结果如图5所示,其中:Fmi为Micro-F1;Fma为Macro-F1;R为标签节点的比例.从图5中可以看出,HetVAE具有最优性能.值得注意的是,AMiner网络中各类方法表现得非常接近(见图5(c)和(d)),其他的异质网络方法均没有超过同质网络方法.由表1可知,这是因为AMiner网络的平均度更小,网络中节点更为稀疏,从而导致各种方法难以训练,结果不具有显著差异.得益于对稀疏矩阵的特殊处理,所提方法仍然有不错的表现.尽管DBLP和AMiner这两个网络都是文献网络,但是相较于AMiner,DBLP增加了关键词这类节点,各种类型节点的平均度更大.依靠论文之间相同的关键词,论文类型节点能够与更具相关性的文章进行相连.在与网络中其他类型节点组合的过程中,能够产生出语义准确丰富的元路径.通过对比这两个真实异质网络的实验结果,能够发现对于语义信息越丰富的网络DBLP,HetVAE效果更好.在不同于文献网络的Yelp网络中,边关系主要集中在企业和用户之间,其网络平均度相较于DBLP和AMiner网络更大,节点邻居数目更多,更难精确地获得有意义的网络结构,但所提方法仍然取得了最优结果,说明了HetVAE具有较好的可拓展性.
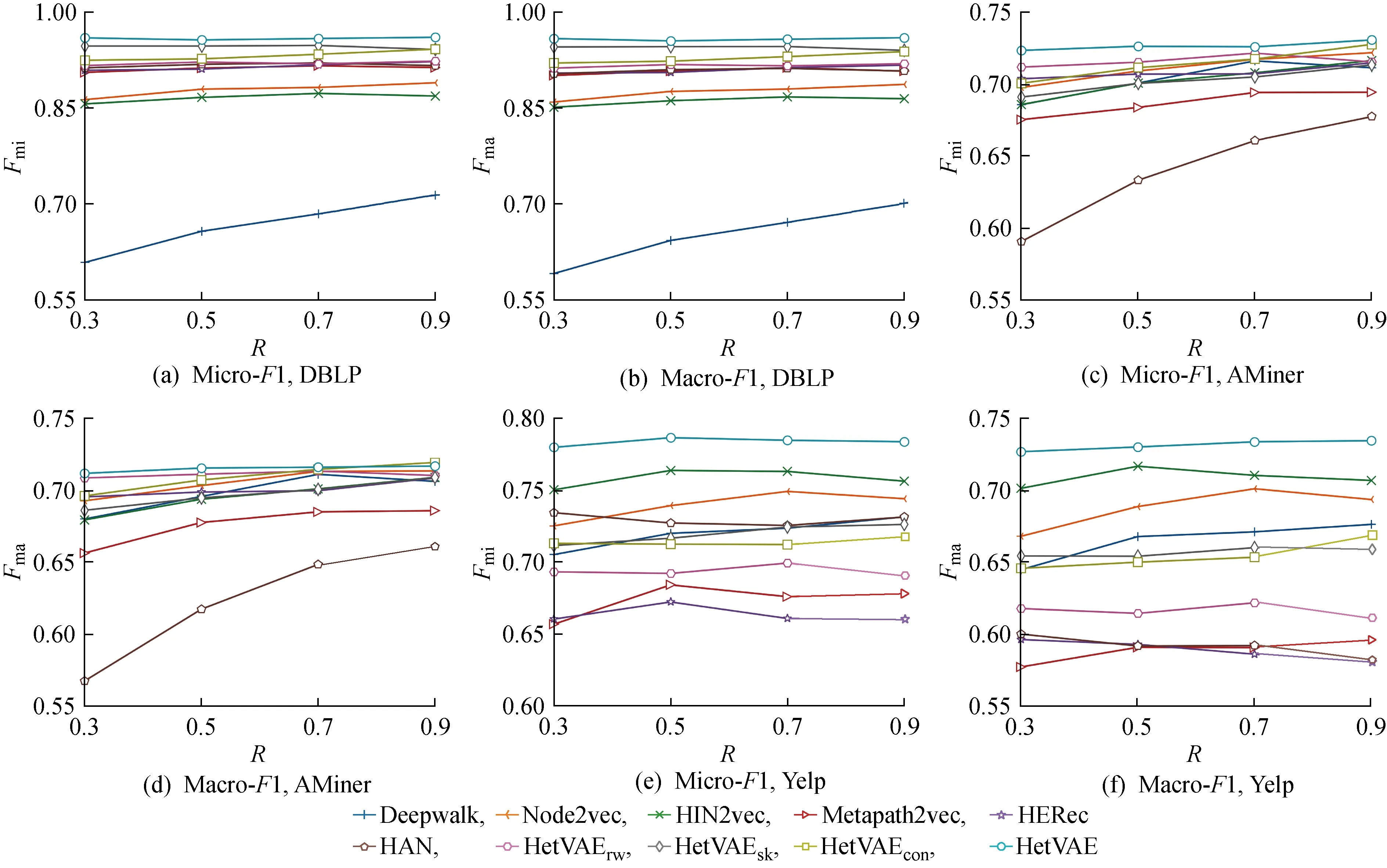
图5 节点分类任务实验结果Fig.5 Experimental results of node classification tasks
为了验证不同模块的有效性,设计了一组消融实验(见图5).从图5中可以看出,相对于HetVAE,HetVAErw的性能在DBLP、AMiner网络中出现小幅度下降,在Yelp网络中性能下降幅度较大,这说明改进的随机游走策略在节点平均度越大的网络中影响越大.同时网络中节点平均度越大,找到有意义的节点越困难.当网络的平均度较小时,随机游走可以选择的下一跳节点数量有限,在游走一定次数之后,普通随机游走算法同样能够选择到可能相似的节点.实验结果证明了本文对随机游走的节点选择策略改进的有效性.
由图5(e)和(f)可见,在Yelp网络中,Metapath2vec和HERec算法由于仅能使用单条元路径,其效果相比于同质网络表示算法表现较差,说明普通的元路径随机游走算法在边关系具有高度偏向性的网络中具有缺陷.而利用多条元路径的算法HIN2vec、HAN、HetVAE,由于对多视角信息的有效利用,能够学习到更为丰富的节点表示.对于仅采用简单拼接方式融合节点向量的方法HetVAEcon,其性能表现比HetVAE差.这说明个性化元路径注意力机制能够更好地为每个节点融合多视角信息,同时避免非重要信息带来的噪声影响,对学习不同语义的关注程度具有重要作用.
3.5 节点聚类
对于节点聚类任务,同样将模型学习到的节点向量作为特征向量,和文献[13]相同,采用K均值(K-Means)进行节点聚类,其中K值的设置随数据集不同而不同.在DBLP实验中K=4,在AMiner实验中K=8,在Yelp实验中K=3.同时使用NMI和ARI作为聚类质量的评价指标.实验中均对聚类过程重复10次,取平均结果作为最终结果.
节点聚类任务的定量结果如表2所示,其中加粗的数值代表每列对比算法的最高值.由表2可以知道,HetVAE均优于所有对比方法,且大部分异质网络方法都比同质网络方法表现得更好.其中,HIN2vec和HAN在部分数据集中的聚类效果较差,这是因为链路预测任务的准确性与网络整个拓扑结构描述的全面性密切相关,而节点分类任务的准确性与能否有效捕获局部的节点相似性有较大的关系.未使用变分推断的HetVAEsk方法在节点的聚类任务中表现不如HetVAE,这说明考虑隐空间下的数据分布采样,能够有效地捕获节点的相似性特征.
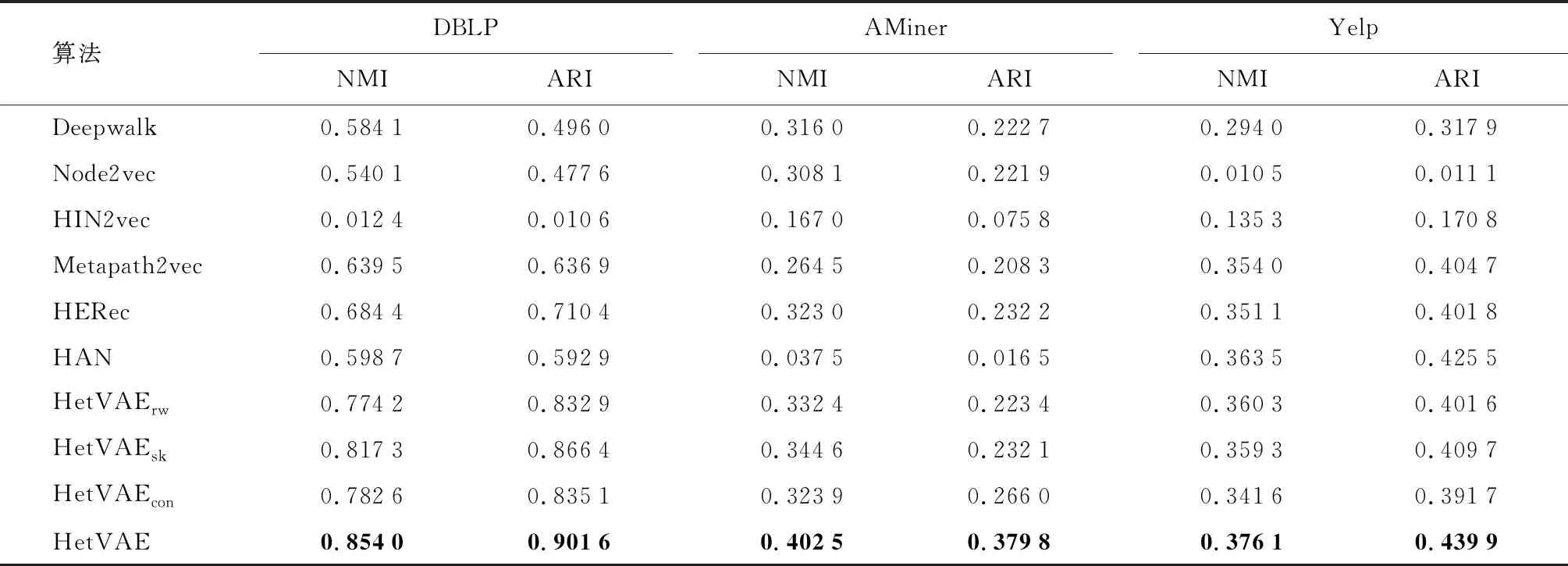
表2 节点聚类任务的定量结果Tab.2 Quantitative results of node clustering tasks
3.6 可视化
为了直观地观察模型学习到的节点序列向量的质量,采用向量的降维可视化方式,使用t-SNE方法将在DBLP网络中学习到的所有作者的128维节点向量表示映射到2维空间中,不同的颜色代表其所属的研究领域,在DBLP中作者的研究领域被划分为4个不同类别,以不同颜色区分.在DBLP网络中的向量可视化结果如图6所示.其中:X为2维空间横坐标;Y为2维空间纵坐标.
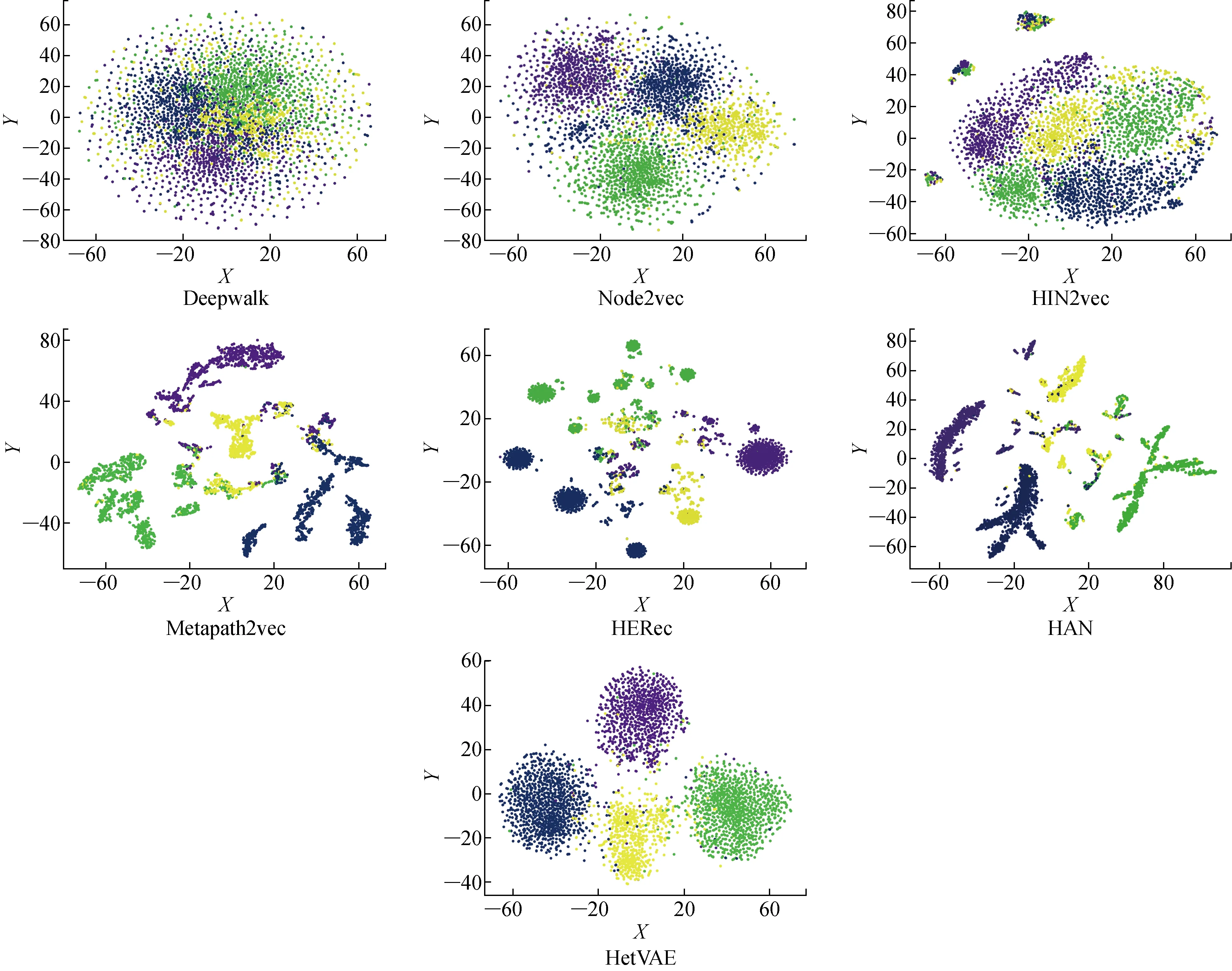
图6 在DBLP网络中的向量可视化结果Fig.6 Vector visualization results in DBLP network
由图6可见,相比于其他方法,HetVAE能够使得相同颜色的节点很好地聚集在一起,具有更高的区分度.
3.7 参数灵敏度
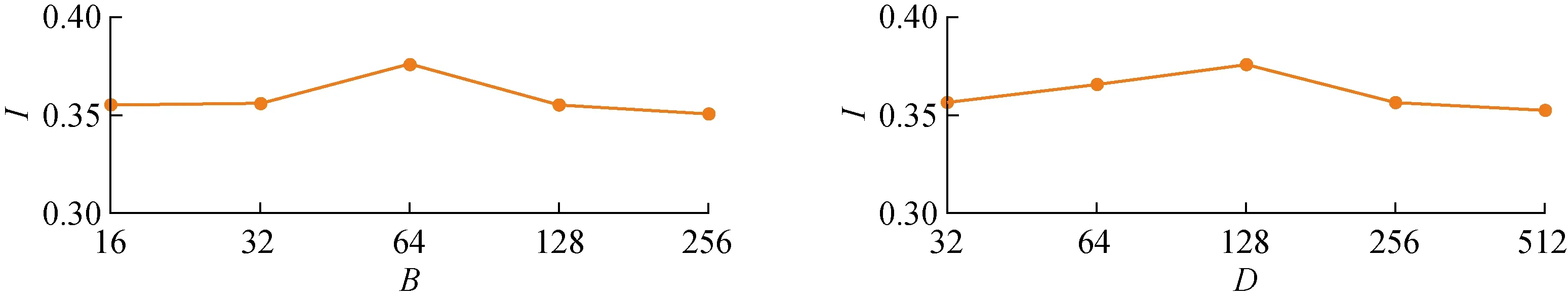
图7 在Yelp网络中的参数灵敏度实验结果Fig.7 Results of parametric sensitivity experiments on Yelp network
为了测试参数对模型的影响,对Yelp网络数据集进行了节点聚类任务的参数灵敏度实验,测试参数包括惩罚因子B和向量表示维度D,实验结果如图7所示,其中I为NMI分数.由图7可知,对于B因子,当B为16和32时,NMI分数比较平均;当B为64时,NMI分数达到峰值,此时聚类的效果最好;当B取值超过64时,NMI分数随着惩罚因子B的增大而下降.由此可以看出,对非零元素过大的惩罚会为模型优化带来困难,适中的惩罚让模型更容易学习更高质量的表示.对于向量维数D,当D的取值在32~128之间的时候,NMI分数持续上升;当D为128维时,NMI分数达到峰值;而当维数翻倍增加到256和512时,NMI分数逐步出现下滑.这表明更大的维度能够编码更多的信息,但同时可能造成冗余信息导致性能下降,节点向量需要一个合适的维度来编码语义信息.对DBLP、Aminer网络数据集的参数测试情况类似,这里不再赘述.
4 结语
本文针对异质网络提出了基于变分推断和元路径分解的异质网络表示方法HetVAE.通过对异质网络进行多条元路径的拆分,改进传统元路径随机游走的节点选择策略,较好地捕捉了不同视角下的子网络结构.进一步利用变分推断,对潜在空间中的变量采样,优化真实先验分布与后验分布之间的误差,为多视角下的子网络拓扑结构进行概率建模,获得高质量的节点向量表示.最后采用个性化元路径注意力机制,对节点向量表示进行融合,保留了原网络的丰富语义和更真实的拓扑结构.实验结果表明,HetVAE能够有效地提高节点表示的质量,在不同的网络任务中具有更好的准确性和有效性.在未来的工作中,将针对社交网络应用,研究适合于推荐算法的异质网络表示方法,使得网络表示更符合真实应用场景,并探索网络表示的可解释模型.
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
理科考试研究·高中(2017年7期)2017-11-04 14:09:30
现代语文(2016年21期)2016-05-25 13:13:44
中国塑料(2016年11期)2016-04-16 05:26:02
云南师范大学学报(自然科学版)(2015年5期)2015-12-26 12:46:16
汽车零部件(2015年1期)2015-12-05 06:40:20
中央民族大学学报(自然科学版)(2015年2期)2015-06-09 08:45:26
汽车维修与保养(2015年7期)2015-04-17 02:12:40
物理实验(2015年10期)2015-02-28 17:36:52
大连民族大学学报(2015年2期)2015-02-27 08:28:11
