
基于聚类分析的船舶主机频繁工作区性能评估
2021-05-28 01:05:08郑齐清林金海赵泽楷俞文胜
泉州师范学院学报 2021年2期
郑齐清,林金海,赵泽楷,俞文胜
(1.泉州师范学院 航海学院,福建 泉州 362000;2.泉州海事局,福建 泉州 362000)
随着IMO对船舶排放标准的提高,以及监管措施更加严格,船舶经营成本进一步加大.航运业向数字化发展,将传统航运与物联网、大数据、云计算、人工智能等为代表的现代信息技术进行融合,提高船舶能源利用效率及营运管理.智能能效管理是智能船舶的八大功能模块之一[1],通过船舶能效数据挖掘分析可深入了解船舶及其设备相关性能,为能效管理计划制定、实施、监测、评估与改进提供决策依据.目前,国内外均在船舶能效数据挖掘分析方面开展了研究,如尹奇志等[2]对船舶能效数据清洗方法进行研究,根据能效数据特征,利用阈值理论及关联理论对故障数据进行识别,运用插值法及灰色关联法对数据有效补齐;孙峰等[3]用K值自适应的K均值聚类法得到定速航行船舶主机的3种工况,并得出各工况下的主机功率与油耗率的关系曲线,以评估柴油机运行性能;邓小玉[4]运用数据挖掘技术建立了船舶能耗数据库和知识库管理模型;高梓博[5]运用主成分分析法对能效数据异常值检测,利用高斯混合模型和EM算法对主机能效数据进行聚类分析,得到船舶3种运行工况,在此基础上进行了性能评估分析;汪益兵等[6]采用K均值聚类算法对船岸一体化平台能效数据进行挖掘分析;Perera等[7-8]通过EM算法实现GMM聚类,得到船舶主机频繁工作区,运用主成分分析法对船舶性能进行分析监测.以上研究成果表明了数据挖掘分析技术的应用有助于船舶高效运营管理,包括航次或全生命周期的能耗分析、航次计划的制定等.
聚类分析是数据挖掘分析中一种重要的分析方法,是一种无监督的学习算法,适用于无标记的船舶能效数据分析.关于船舶能效聚类分析中常用的算法有K均值算法、高斯混合模型和EM算法等.高斯混合模型算法使用高斯分布作为参数模型,并用EM算法进行训练,理论上适用于任何类型的分布,但相较K均值算法每一步迭代的计算量比较大,模型较复杂.K均值算法也称快速聚类法,算法原理简单,易于理解,并且便于处理大规模的数据,但K值难以事先选取,聚类结果会出现局部最优.考虑到K均值聚类算法可解释度较强,算法简单,易于实现,本文以目标船一个时间段内的能效数据为基础,采用K均值聚类算法对数据进行分析,提出层次聚类法解决K值选取的问题,并在数据预处理基础上,利用聚类和拟合方法得到频繁工作区下船舶主机的性能曲线.
1 能效数据收集及预处理
数据来源于某目标船的航行数据,该船主机型号为MAN B&W 6S60MC,额定功率10 320 kW,额定转速89 r/min.采集的数据包括主机转速、主机功率、主机油耗、船舶航速、水深等.数据质量直接影响数据分析的有效性及准确性,进行数据挖掘分析前须进行数据质量分析和预处理.因能效数据为在船期间每日定时收集的数据,所以数据的特点与船上安装传感器实时测取的数据不同,不存在缺失值或突变值,本次分析数据点之间的时间跨度较大,在针对定速航行数据分析时需剔除停泊和机动航行时的数据.
船舶的航行状态分为停泊、机动航行及定速航行三种,主机运行性能评估主要是定速航行的工况分析.停泊时,船速、主机转速、主机油耗及功率应为0;机动航行时,主机油耗应大于0,小于定速航行时的油耗,与邻近数据点数值差较大.为此,可对数据进行识别,最终获得定速航行状态下的能效数据.表1为预处理后的部分能效数据.
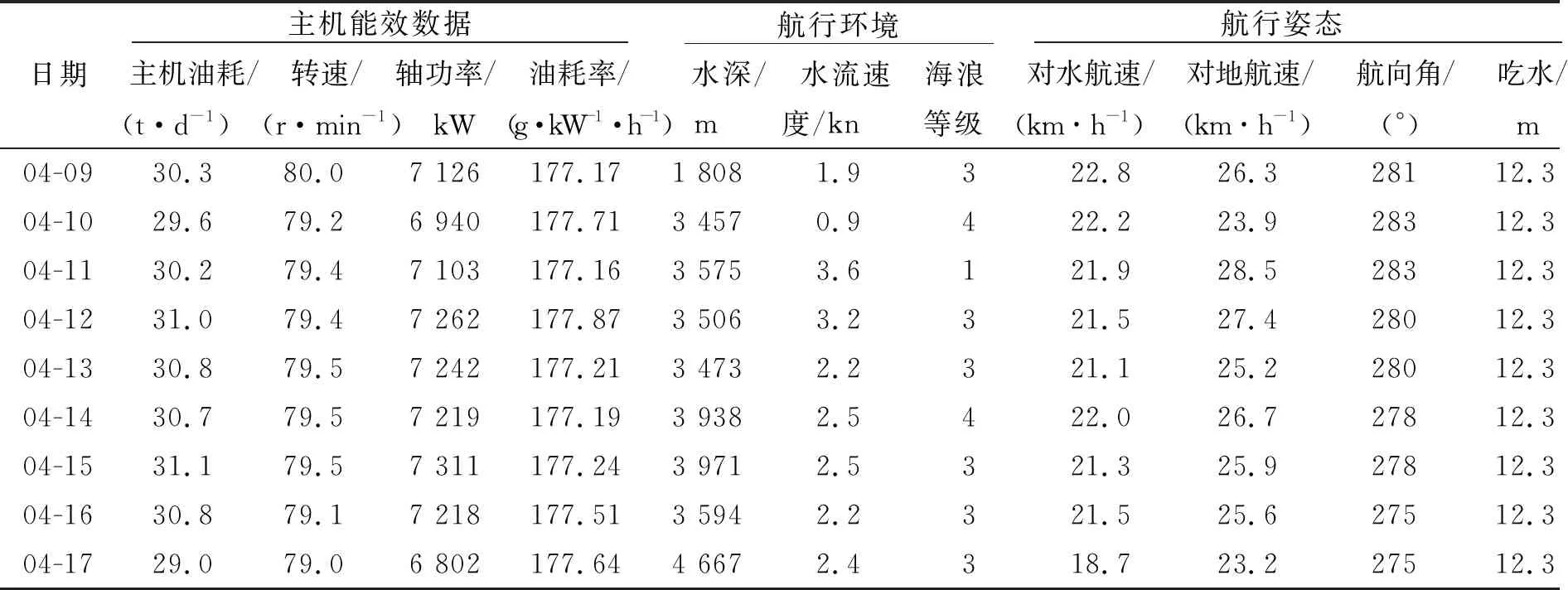
表1 预处理后的能效数据(2018年)Tab.1 Energy efficiency data after preprocessing(2018)
2 主机频繁工作区聚类分析
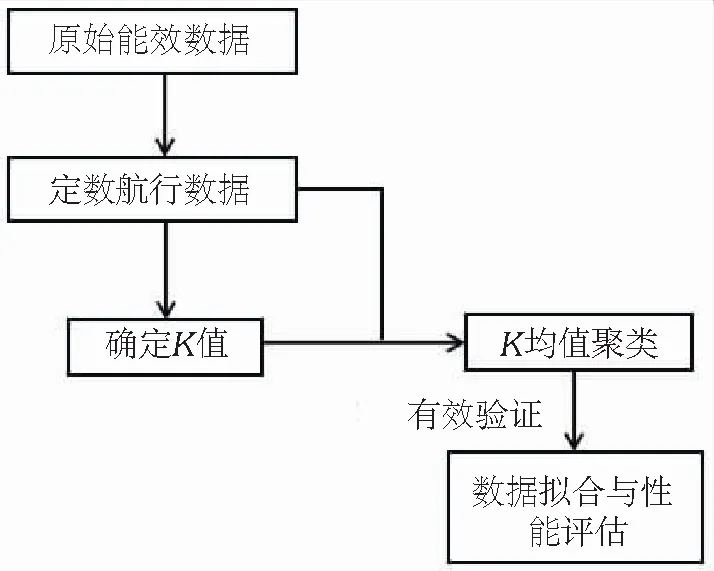
图1 聚类分析研究的技术路线图Fig.1 Technical roadmap of clustering analysis research
船舶海上航行时,通常按照船东或租家的要求来设定转速,在航次内或某一时间段内,主机可能会在不同的设定转速下运行,实际转速会随着外界环境的改变而变化.如水流、水深、吃水、风速、风向、波浪等对主机负荷的影响,将导致主机实际运行转速在设定转速附近波动,形成主机频繁工作区.为得到主机频繁工作区,分析不同工况下主机性能表现,本研究采用K均值聚类分析法,其聚类分析研究的技术路线如图1所示.
2.1 确定K值
进行K均值聚类前须事先确定K值,若K值选取不合适则会影响整个聚类结果.本文研究中采用层次聚类法来确定分类数K,该方法是一种常见的聚类方法,常用于数据挖掘领域,不需要事先知道数据共划分为几个类别,以欧氏距离作为相似度度量值,按照相似度关系生成树状图.树状图是二叉树,从根开始,节点代表类,它们可以是内部节点或终端节点,每个内部节点都延伸出两个边,边的高度为两个子类的相似度.图2和图3分别为数据处理前与处理后的聚类结果.其中,图2中的数据包括了船舶停泊、机动航行及定速航行三种状态下的数据,其所示处理前的数据可划分为4类;图3中的数据为船舶定速航行时的数据,其所示数据可划分为2类,为此K均值聚类可确定K值为2.
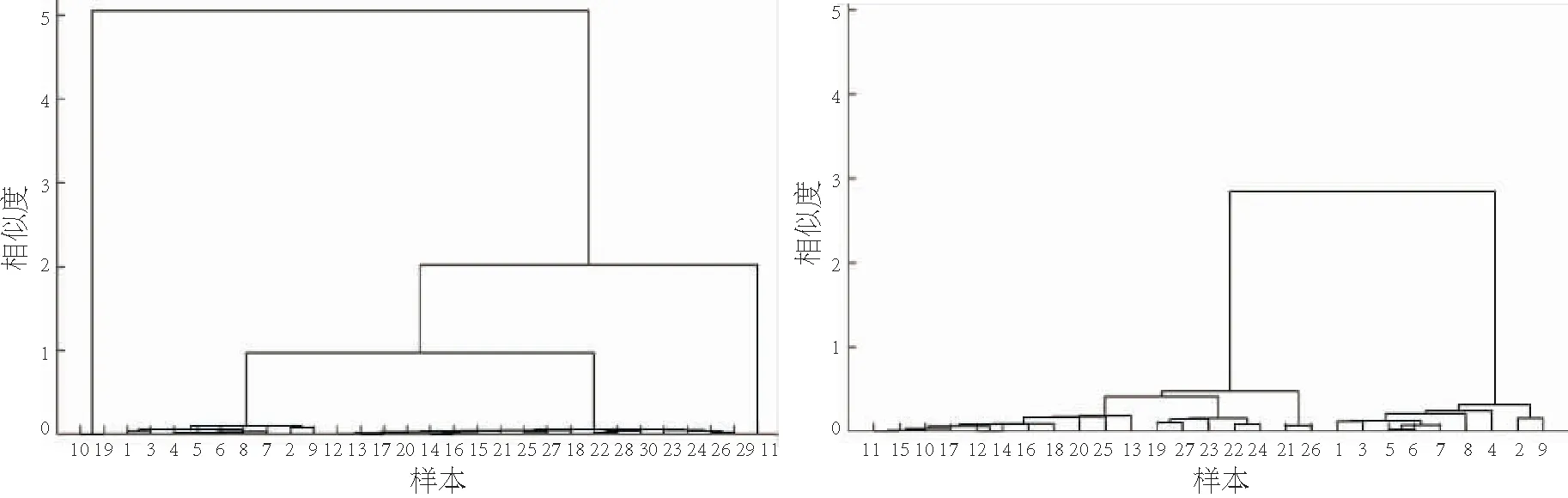
图2 数据处理前层次聚类图 图3 数据处理后层次聚类图Fig.2 Hierarchical clustering before data processing Fig3 Hierarchical clustering after data processing
2.2 K均值聚类
K均值聚类是一种基于距离的无监督算法,算法快速简单,便于处理大量的数据,适用于无标签数据集的聚类分析[9-10].其算法基本思想是:首先,设定K个聚类中心,把样本数据分配至距其最近的类,通常使用数据与类中心的欧氏距离来计算;其次,重新计算每个类的中心,若聚类中心发生变化,则重新计算数据至新类中心的距离,再重新分配,直至类中心不再变化,并输出聚类结果.
设第K个初始聚点的集合是:
记
可以将样品分成不相交的K类,得到第一次分类结果:
(1)
由式(1),再计算新的聚点集合L(1),有
(2)
式(2)中ni是类G(0)中的样品数,获得新的集合为:
(3)
对集合L(1)再进行分类,记
获得新的分类结果:
(4)
重复以上计算步骤m次,得
(5)
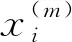
与
相同,则计算结束.
采用上述计算方法,对处理后的主机能效数据进行K均值聚类分析,可获得如图4所示的聚类结果.针对聚类过程中可能出现局部最优解的问题,可通过合理选择K值,数据归一化或离群点处理,或提出改进的K均值算法等方法,解决由初始聚类中心点随机性选择导致算法陷入局部最优的困境.图4显示主机转速、功率及油耗率三者之间的相互关系,数据被聚成2类,聚类1中转速、功率及油耗率的聚类中心点分别为:68.76 r/min、5 161.44 g/(kW·h)和180.5 g/(kW·h);聚类2中转速、功率及油耗率的聚类中心点分别为:79.4 r/min、7 135.89 kW和177.41 g/(kW·h).由此可知,目标船定速航行时主机实际运行转速分布在以68.76 r/min和79.4 r/min 为中心点的附近.从图4可知主机转速与功率和油耗率的关系,随着主机转速的升高,主机功率增大,而油耗率下降;从功率与油耗率关系来看,随着主机功率增大,油耗率下降.一般情况下,主机油耗率在85% MCR左右最低.
2.3 最佳聚类数验证
好的数据聚类结果应是同一聚类中的数据样本相似度高而差异度小,类与类间的相似度小而差异度大,即数据样本与所属类的中心之间的距离比到其它类的中心的距离都小[6].为验证文中K均值聚类有效性,本文采用基于欧式距离的距离评价函数作为聚类有效性指标,以函数最小为准则判别数据最佳聚类数K.
设有数据集T={m1,m2,…,mn},聚类数为K.设聚类空间为I={T,K},类间距离为每个聚类中心到全域中心(所有样本的均值)的欧式距离之和:
其中:Dout为类间距离,m为所有样本均值,mi为每个分类中的样本均值.类内距离就是每个分类中所有样本到此类中心的欧式距离之和:
其中:Din为类内距离,p为任一数据样本,mi为类中所有样本的均值.当Dout≈Din时,聚类数最佳,定义距离评价函数为:
K的最优选择为:
Min{F(T,K)},(K=1,2,3,…,n).
本研究中,K取值为K=2,3,…,9.运用MATLAB软件编程,得到函数值F(T,K)随聚类数K变化关系图如图5所示.从图中可知,当K取值为2时,函数值最小,验证了文中K均值聚类结果的有效性.

图5 主机能效数据K均值最佳聚类数 图6 主机功率与油耗率关系曲线Fig.5 The best clustering number of K-means Fig6 Relation curve between engine powerof energy efficiency data and fuel consumption rate
3 频繁工作区的主机性能评估
经济性是主机性能评估主要指标之一,也是主机油耗率的直接反映其经济性.由于船舶主机受外界环境的影响其负荷是波动的,为维持实际转速在设定转速周围,调速器会调整供油量,改变主机的输出功率.为此,可用油耗率随负荷的变化关系来评估主机经济性能.
采用K均值聚类法将工况点划分为2类,并使用二次多项式对数据散点拟合,形成主机负荷与油耗率的关系曲线图,如图6所示.从全域数据点的拟合曲线看,总体上油耗率随着负荷的增加而降低.从聚类1的拟合曲线看,油耗率随着负荷的增加而降低,变化趋势与说明书的负荷特性曲线较为一致.从聚类2的拟合曲线看,变化趋势与说明书的负荷特性曲线有差异.由于船舶主机运行环境复杂,造成数据点偏移的因素众多,在此笔者根据实船工作经验分析其原因:说明书中负荷特性是在试验台上测取的,反映的是设定转速情况下,油耗率随负荷变化的规律,试验时主机各项性能参数良好,工作环境相对稳定,如进气温度及压力、冷却水温度及流量、燃滑油温度及压力等;而目标船下水时间是2003年,本次实船测取数据时,船舶主机各部件结构参数已发生变化,如缸套磨损、排气阀磨损、喷孔结碳、轴瓦磨损等,加上外界环境条件的变化,这些因素都可能引起燃烧不良,导致主机热效率下降,油耗率升高,而具体是哪种因素造成的则需根据船舶实际进行诊断.
4 结语
利用数据分析方法对目标船的主机能效数据进行预处理及聚类分析,获得了船舶定速航行的主机频繁工作区,对不同工作区域下的主机性能表现进行评估.根据研究结果,有以下结论:
(1)利用船舶停泊、机动航行及定速航行状态下的数据特征,进行数据预处理,得到定速航行时的主机能效数据;利用层次聚类法解决了K均值聚类算法中K值取值的问题;然后,采用K均值聚类算法对数据散点进行聚类,得到定速航行状态下的主机频繁工作区;最后,对各聚类中的数据散点进行拟合,获得了主机功率与油耗率关系曲线.
(2)通过分析主机功率与油耗率关系曲线,有助于了解不同负荷下的主机性能表现.本文采用的分析方法用于评估主机的运行性能是可行的,在此基础上可以为船舶能效管理提供参考.
(3)海上船舶航行环境复杂多变,影响主机能耗的因素很多,本研究只是选取了主机转速、功率、油耗率等能效数据进行分析,后续研究中,还要综合评价各因素对主机能耗的影响,可以通过实船数据与出厂数据的对比,进行船舶设备性能退化评估、预测及恢复研究.如通过导入主机出厂试验时功率与油耗率关系曲线,与主机实际运行时的功率与油耗率关系曲线对比,计算数据的偏离值与偏离度,分析偏离的主要因素及其影响程度,为主机操作管理提供参考.
猜你喜欢
车主之友(2022年5期)2022-11-23 07:22:20
疯狂英语·新读写(2021年6期)2021-08-05 07:49:10
印刷工业(2020年5期)2020-03-29 06:46:50
上海铁道增刊(2017年3期)2018-01-22 03:01:18
车迷(2017年12期)2018-01-18 02:16:10
中学生英语(2017年6期)2017-07-31 21:28:55
流程工业(2017年4期)2017-06-21 06:29:48
青年歌声(2017年6期)2017-03-13 00:57:56
建筑机械化(2015年7期)2015-01-03 08:09:00
自动化博览(2014年6期)2014-02-28 22:32:07
