
基于改进卷积神经网络的肺结节识别算法
2021-05-27 05:48林振衡谢海鹤
莆田学院学报 2021年2期
傅 磊,林振衡,谢海鹤
(莆田学院 机电与信息工程学院,福建 莆田 351100)
0 引言
肺癌是发病率和死亡率增长最快,对人群健康和生命威胁最大的恶性肿瘤之一,做到临床早发现,早诊断,有助于患者得到早期治疗,提高预后[1]。肺癌的病灶体称为肺结节,是早期肺癌筛查的重要指标,若能及时在肺部检测出肺结节,对于肺癌的早期诊断和后续的治疗将起到至关重要的作用。目前医院大多数采用人工诊断的方法对CT图像进行诊断,但许多肺结节体积很小且某些特殊部位的肺结节与血管部分极为相似,而医生每天要接待大量患者,对大量的CT图像进行诊断,容易出现漏诊或误诊的情况[2]。因此,提高CT图像诊断准确率和诊断速度显得尤其重要。
目前,许多研究者致力于将计算机辅助检测技术和深度学习相结合,对肺结节进行自动高效的识别。卷积神经网络(convolutional neural network,CNN)是目前深度学习领域中常用的网络框架,尤其在计算机视觉领域更是一枝独秀。CNN从20世纪90年代的LeNet开始,到2012年AlexNet再到后来的ZFNet、VGGNet、GoogleNet和最近的DenseNet,模型的网络结构不但越来越复杂,而且越来越巧妙,尤其是可以很好地解决传播中梯度消失的问题[3]。
VGGNet作为CNN中具有代表性的网络模型,由牛津大学的视觉几何组(Visual Geometry Group)和Google DeepMind公司的研究员共同提出,在ILSVRC-2014的定位任务以及分类任务中,分别取得了第一名和第二名的成绩[4]。VGGNet通过使用3*3的卷积核来增加模型网络深度,在一定程度上提升了模型的表现。另外,VGGNet迁移到其他数据上同样具有很好的泛化能力[5]。到目前为止,VGGNet模型经常被用来提取图像特征。在2014年的ILSVRC比赛中,VGGNet在Top-5中取得了92.3%的正确率[6]。VGGNet有两种结构,分别是VGG16和VGG19,两者并没有本质上的区别,只是网络深度不一样[7]。虽然VGG模型的识别率较高且收敛速度快,但VGG模型的层数和参数是为1000个分类类别设计的,其权重参数数量多达6.5×107个,且大部分权重参数主要集中在全连接层上,这些海量的参数将大大增加模型训练所花的时间[8]。因此,本文针对经典的VGG16模型,提出了基于改进CNN的肺结节识别算法,该方法优化了经典VGG16全连接层结构,即在最后使用了2个全连接层替换经典VGG16模型中的3个全连接层,大大减少了权重参数参与模型训练的计算。另外,本文采用了迁移学习的方式共享VGG16预训练网络各层的权值参数,进一步优化了模型参数,加快模型收敛速度,从而辅助医生更快、更准确完成肺部CT图像的筛查,减轻医生的工作量,减少漏诊率及误诊率,提高工作效率。
1 实验数据集和预处理
由于VGG16网络模型层数和参数较多,为了避免过拟合现象发生,保证训练模型在其他数据上也有良好的表现,一般要求模型输入较多数据进行训练[9]。本文VGG模型训练所用的LIDC-IDRI公开数据集,由美国国家癌症研究所(National Cancer Institute)提供,包括胸部医学图像文件(如CT、X光片)和对应的诊断结果病变标注,目的是为了研究高危人群早期癌症检测[10]。
肺部CT原始图像在获取时,容易产生图像灰度不均匀、伪影、噪声等问题。因此,本文先将所用的LIDC-IDRI中的图像进行标准化处理。即将肺部CT图像像素值中大于400的像素值设定为1,在图像中显示为白色,肺部CT图像像素值小于-1000的设定为0,处理后的结果如图1所示。
由于VGG模型训练的肺部CT图像数据过于庞大,且肺部CT图像的特征较为复杂,碍于计算机能力的局限性以及肺部CT图像中含有较多的无关内容,需要对肺部CT图像进行分割,对CT图像中医生所关注的区域进行精确的定位,使得计算机只对肺部CT图像中感兴趣的部分进行学习,从而构建更加准确的肺结节识别模型。
本文选择分水岭分割方法对标准化后的肺部CT图像进行分割,分水岭算法是一种数学形态学方法。20世纪70年代末,S.Beucher等提出了用于灰度图像分割的分水岭算法,不久L.Vincent提出了基于沉浸沙型的V-S算法[11]。该算法分为排序和淹没两个过程。分水岭分割算法把图像看成一副“地形图”,其中亮度比较强的地区像素值较大,而比较暗的地区像素比较小,通过寻找“集水盆”和“分水岭界限”,对图像进行分割[12]。
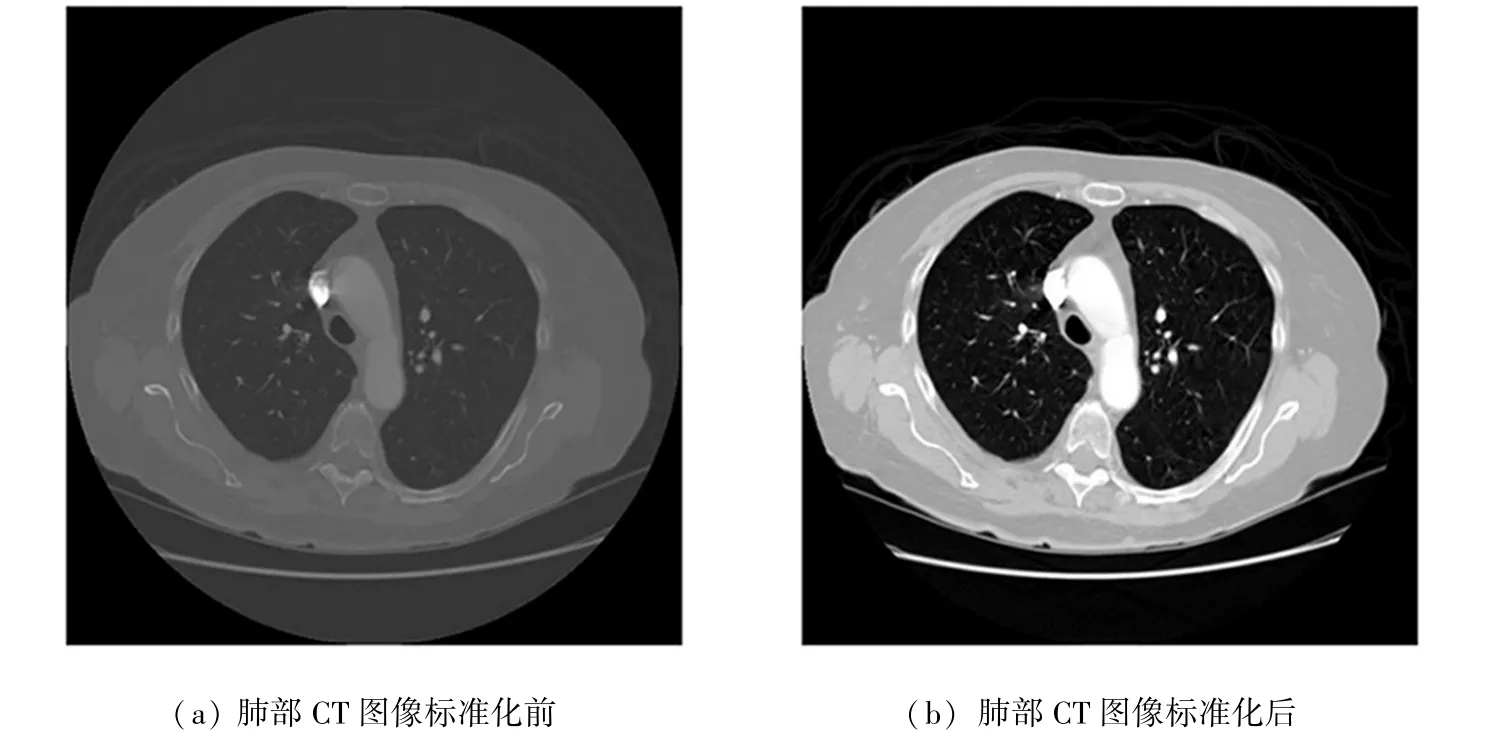
图1 标准化处理前后的肺部CT图像对比
分水岭位于输入图像的集水盆图像之间的边界点,而输入图像的集水盆图像通过分水岭变换得到。因此,为得到图像的边缘信息,一般把梯度图像作为输入图像,即

式(1)中,f(x,y)表示原来的图像,grad{.}表示图像的梯度运算,肺癌图像处理后的结果见图2。

图2 分水岭算法分割前后的肺部CT图像对比
2 VGG16神经网络模型
2.1 经典VGG16网络模型架构
经典VGG16网络模型共有16个层,这也是VGG16名称的由来,是一个相当深的CNN。VGG16包含5层卷积层、3层全连接层以及softmax输出层,层与层之间使用最大池化层分开,所有隐层的激活单元都采用ReLU函数[13]。经典的VGG16模型结构如图3所示[14],前2层卷积使用了3*3的过滤器,后3层是3个线性堆叠的3*3大小的过滤器,并在卷积层和层之间增加了ReLU作为激活函数,通过3*3的小尺寸过滤器一方面增加了网络模型的深度,另一方面可以提取到更加丰富的图像特征[15]。最后通过3个全连接层并利用softmax激励函数得到识别结果。虽然VGG模型收敛速度快,能有效地提升模型对图像的识别能力。但从图3中可以看出,经典VGG16模型通过组合卷积层增加网络的深度以提高识别率,但随着网络深度的加深导致其参数量十分巨大,其中最后3层的全连接层参数数量为123642856,约占总参数量的89.36%,这些海量的参数将大大增加模型训练所花的时间[16]。

图3 经典VGG16模型网络结构图
2.2 基于改进的VGG16网络的肺结节识别模型
经典VGG16模型的权重数量较大,其中3个全连接层参数集中度较高,通过组合卷积层增加网络的深度来提高模型识别率。但是随着VGG16网络深度的加深,模型收敛过程中容易发生波动且时间漫长,甚至可能出现网络退化的现象,且VGG16参数是针对1000个图像分类类别设计的[7]。针对本文所处理的医学图像特点,3个全连接层无形中增加了整个训练过程中权重参数参与模型训练的计算。另外,本文只针对2个图像类别进行分类。因此,为提高对肺部CT图像肺结节识别的准确性和计算效率,本文对经典的VGG16网络模型最后的全连接层结构进行了改进,即提出用2个全连接层结构替换经典VGG16模型中的3个全连接层,其中改进后的第1个全连接层的神经元为4 096个,第2个全连接层即最后输出的神经元为2个(有无肺结节),进而降低训练模型所用的参数个数,提高计算的效率和模型对肺结节识别的精度,改进的VGG16网络模型如图4所示。

图4 改进的VGG16模型网络结构图
在图4改进的VGG16模型中,各立方体宽度的不同代表图像通道个数的差异。图4中所用卷积层均采用3*3大小的卷积核,步长为1,所有池化层都采用2*2大小,步幅为2的最大池化操作。全连接层数由原来的3层变为2层,大大减少了模型训练过程中的计算量,最后采用ReLU作为激活函数,使得获得的图像特征更为明显,对肺结节的识别效果进一步提高。
2.3 基于改进的VGG16网络的迁移学习
由于在实际的肺结节识别过程中,经常无法收集到所有的可用样本集,如果只是依靠这些有限数量的样例用于训练建立模型,模型容易出现过拟合的问题。另外,由于VGG16的网络模型参数较多,有限数量的样本集将会导致整个模型框架的参数更新较慢,很难掌握所学习图像的具体特征。因此,本文提出用迁移学习的办法来解决上述问题,VGG16预训练网络是2014年开发的在ImageNet(多达140万张标记图像,1 000种不同类别)训练好的大型CNN,其网络框架是基于大量数据训练而得到的成熟网络,尤其是卷积层中的众多权重参数对于图像中的边缘、轮廓等特征已经进行了较为有效的特征提取[17]。本文将ImageNet上训练好的VGG16网络模型通过迁移学习的方式引入实验中。另外,针对肺结节CT图像的识别,本文在原来VGG16模型的基础上,进一步优化了模型参数,从而加快模型收敛速度,进一步提高肺结节识别的准确率。
3 实验结果与分析
为了研究所建立的改进VGG16模型对肺结节识别的有效性,本文使用了LIDC-IDRI公开数据集进行实验,实验操作系统为64位Windows 10,采用Intel(R)Core(TM)i7-7500U(2.5 GHz)CPU处理器,8GB RAM,运行环境为Python 3.5,Tensorflow-GPU=1.8.0,Anaconda=1.9.7的深度学习框架,同时安装了CUDA9.0及cuDNN v7的GPU计算加速库。
3.1 实验数据
实验数据源LIDC-IDRI中收录人1 018个研究实例,本文从中随机挑选了2 000张肺部CT图像(有无肺结节的图像各1 000张)用以建立经典的VGG16和改进的VGG16两种模型。其中,每一类的肺部CT图像(有无肺结节的图像)又按照8∶2的比例被随机划分为训练数据集和验证数据集。训练数据集用于训练经典VGG16模型和改进VGG16模型,验证数据集用于评估经典VGG16模型和改进VGG16模型的数据集。训练数据集由800张没有肺结节的正常肺部CT图像切片和800张有肺结节的肺部CT图像切片组成。每张肺部CT切片的图像大小均为224*224。
3.2 训练与测试结果
本文实验使用激活函数ReLU来加快模型的收敛速度,网络模型的学习率设置为0.01,使用的优化器是Adam,批处理大小取32,模型训练的最大迭代次数为200次。正常情况下,在模型的训练过程中,训练损失值和验证损失值都应处于下降趋势,否则说明VGG16模型的设计出现了问题或者模型的参数设置出现了问题。
从LIDC-IDRI肺部CT图像数据集中随机选出测试样本集进行预处理和肺部分割,并将其带入经典的VGG16模型和改进的VGG16模型进行评估。为了验证改进方法的效果,进行了5次重复实验,通过每次实验获得肺结节识别正确率对经典的VGG16模型和改进的VGG16模型进行对比评估,对比测试结果如表1所示。
表1 对比了经典VGG16模型和改进VGG16模型对LIDC-IDRI肺部CT图像验证数据集肺结节识别的正确率,可以看出改进的VGG16模型用2个全连接层结构替换经典VGG16模型中的3个全连接层,减少了全连接层数,大大减少了参数量,且对肺结节的识别结果优于经典VGG16模型。因此,本文提出的基于改进CNN的肺结节识别算法对肺结节有更好的识别准确率。
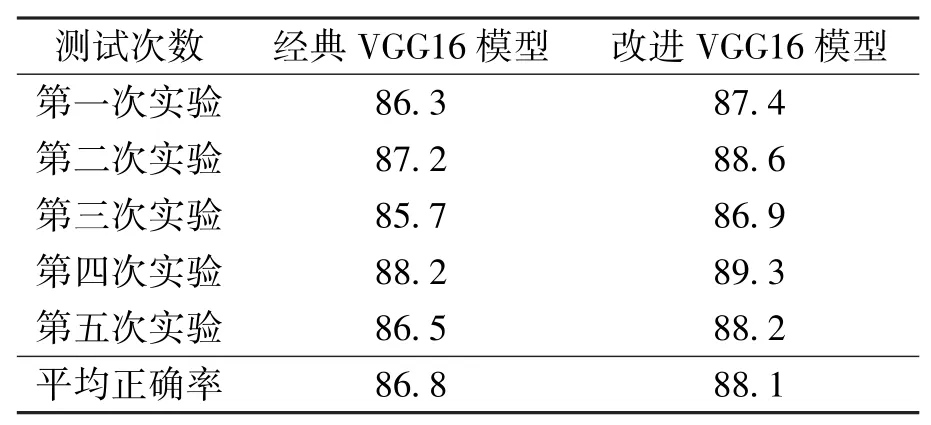
表1 两种模型识别正确率的对比 %
4 结论
本文对经典的VGG16模型进行改进,即优化了经典VGG16模型的全连接层结构,使用了2个全连接层替换经典VGG16模型中的3个全连接层,并使用迁移学习的方式将VGG16预训练网络各层的权值参数引入实验中。通过评估传统的VGG16模型和改进的VGG16模型在LIDCIDRI验证数据集正确率上的表现说明,提出的基于改进CNN的肺结节识别算法,在LIDC-IDRI验证数据集上对肺结节的识别率更高,比经典的VGG16模型收敛速度更快,肺结节识别效果更好,从而更好地帮助医生对肺部CT图像进行诊断,对肺癌的早期筛查及后续诊断具有十分重要的意义。
猜你喜欢
人人健康(2022年13期)2022-11-25
农业工程学报(2022年12期)2022-09-09
传染病信息(2022年2期)2022-07-15
中国典型病例大全(2022年9期)2022-04-19
好日子(2021年8期)2021-11-04
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
祝您健康(2021年9期)2021-09-05
健康体检与管理(2021年10期)2021-01-03
