
三维卷积和视频帧采样算法下斗殴检测技术
2021-05-26 03:13:58黎晓昀
计算机工程与应用 2021年10期
黎晓昀,贾 杰
1.江西应用科技学院 人工智能学院,南昌330100
2.南昌航空大学 信息工程学院,南昌330063
在当今社会形势下,人工智能应用已遍布人类生活的各个方面,成为人们生活所依赖的技术。其中,智慧小区就是近年来热点研究和建设的项目与应用。然而简单的门禁管理和人员来访登记已无法满足需求,对小区监控视频的结构化分析正成为智慧小区领域的研究重点。这其中,对小区人员的行为分析,尤其是斗殴行为识别和分析尤为迫切和重要,这既是社区安防的需要,也是视频监控领域亟待解决的问题。
本文提出一种新的基于三维卷积神经网络(Three-Dimensional Convolution Neural Network,3D-CNN)的斗殴行为检测方法,应用于智慧社区视频监控领域。主要贡献如下:
(1)提出了一种斗殴行为关键区域检测算法。通过应用姿态估计算法模块,得到人体目标关节和肢体的单位位移信息,从而确定斗殴行为的起始位置,形成斗殴行为预识别空间。
(2)提出了一种时空采样算法,使得训练视频数据被采样至一个设定的降维空间,同时保留视频数据的时空特征,保证深度学习网络的单次训练任务能学习到整个行为过程的信息。
(3)构建了一个基于三维卷积的神经网络进行时空特征提取和识别。
本文提出的方法在两个公共数据集上取得了较好的性能。
1 研究现状
近年来,行为识别的研究引起了中外学者的广泛关注。随着智慧社区建设的深入和深度学习算法[1-3]的发展,斗殴行为检测在安防领域中被提出了新的更高的要求。传统的基于传感器的行为识别方法[4],无法保证设备的长期稳定性和鲁棒性,并且传感器设备十分容易收到外部环境的干扰,难以有效对斗殴行为进行识别和检测。文献[5]提出了基于图像的斗殴行为检测方法,其采用直方图的方向和幅值的熵以及速度的方差来判断是否发生打斗行为,对斗殴行为检测做了探讨和研究。文献[6]提出了联合加权重构轨迹与直方图熵的异常行为检测算法。文献[7]提出了一种基于3D-CNN 结构的暴力检测方法,通过三维深度神经网络直接对输入进行操作。文献[8]立足于目标距离关系以及图像光流特征进行跟踪定位,以确定帧图像中目标间位置距离关系,再基于光流方向直方图熵来判定打架行为。文献[9]提出一种双流CNN模型的打斗行为识别方法。由Hinton等人提出的深度学习网络[10],使得基于图像的深度学习研究快速发展,如目标检测[11]、图像分类[12]等研究,已发展较为成熟并逐步实现了工业化。基于神经网络的行为识别[13-14]研究也得到了较大的发展。近几年,对智慧社区监控视频中斗殴行为识别检测的研究正成为越来越多学者关注的焦点。
本文为了解决上述问题,提出了一种新的基于三维卷积神经网络的斗殴行为检测方法,利用基于人体姿态信息的关键区域检测算法定位目标行为区域,形成斗殴行为预识别空间。同时,针对深度学习训练数据,提出了时空采样算法,配合构建三维卷积神经网络的单次训练输入设置,使网络学习到整个行为动作的时空信息。相关实验证明了本文方法的优越性能。
2 提出的方法
本文提出了一种新的基于三维卷积神经网络的斗殴行为检测方法。首先利用人体姿态算法将监控视频做姿态估计处理,形成骨架信息。然后获取人体手腕关节点的单位位移量,从而作为斗殴行为动作的起始判断依据,形成斗殴行为预识别空间。训练模型过程中,针对深度学习训练数据冗余和优化程度不够的问题,提出了时空采样算法,配合所提出的三维卷积神经网络的单次训练输入设置,使网络学习到整个行为动作的时空信息,进行特征提取和分类判断。所提方法流程图如图1所示。
2.1 斗殴行为预识别空间
针对监控视频行为检测起始定位的难点,首先将视频进行姿态估计处理,如openpose算法[15]和alphapose算法[16]。因为斗殴行为几乎都伴随着手腕关节点的快速位移,所以获取手部关节点的速度成为预判的关键。定义相邻两帧,第n 帧和第n+1 帧间手部关节点的距离如式(1)所示:
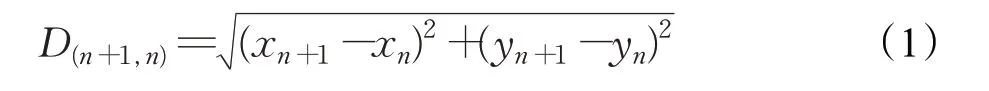
其中,D(n+1,n)表示距离,xn+1、yn+1、xn、yn分别表示相邻两帧间手部关节点的坐标信息。颈部到髋部的距离,即躯干长度如式(2)所示:

其中,D(neck,hip)表示距离,xneck、yneck、xhip、yhip分别表示颈部和髋部关节点的坐标信息。根据姿态估计算法得到的数据,做了样本统计,当手腕速度满足式(3)时,则可预判为挥拳斗殴行为,将第n 帧标注为预识别空间的起始。

根据统计结果,一次完整挥拳的持续时间约为0.5~1.2 s。因此对监控视频来说,即持续15~36帧。保险起见,本文取40 帧作为单个预识别空间元素的容量。如图2所示为预识别处理的对比。
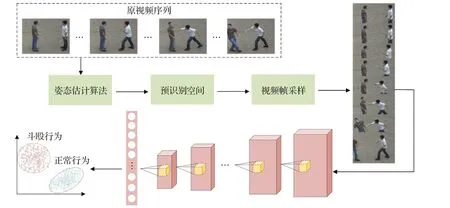
图1 斗殴行为检测总体构架

图2 预识别空间处理对比
2.2 视频帧采样算法
针对上一节的预识别空间内的视频帧,本文提出了一种基于时空采样的视频帧采样算法。为了有效地学习视频的整体时间信息,本文模型能够一次处理所有帧。然而,一个主要的挑战是处理长度不等的各种视频。在现有的大多数方法中,每个视频都被分成16 帧的短片段,然后模型从这些短片段中学习时间信息。3D-CNN[17]将每个视频分成16帧。然而,在每秒30帧的视频中,16帧只能持续约0.5 s,无法表达全部的动作信息。视频帧是高度冗余的,一些连续的帧几乎是相同的,如图3(a)所示的斗殴行为视频的前8帧。现有的方法以这种方式为其网络提供信息,因此必须通过特征或评分融合的后处理来聚合来自单个帧或短剪辑的部分时间信息。在图3(b)中这段视频的8 个均匀采样帧可以很好地捕捉到整体的时间动态信息。
与原始视频帧相比,采样后的帧在相同数量的图像帧下提供了更多的动态信息。因此,相当于在40 帧的视频上,采样出长度为8帧的视频。将40帧平均分为8个部分,每部分5 帧,在各部分的5 帧中随机采样1 帧,组成采样后的视频,如式(4)所示:

当视频被采样到一个恒定长度后,构建了三维卷积神经网络在一个过程中处理后的视频。
2.3 基于三维卷积的斗殴行为检测神经网络
三维卷积最早是在文献[17]中提出用于动作识别的,后来在文献[18]中改进为11 层3D 网络。基于三维卷积的模型在许多基于视频的应用中得到了广泛的应用。与2D-CNN相比,3D-CNN同时从多个帧中提取空间和时间特征。2D-CNN仅作用于二维输入,因此在二维卷积过程中也会丢失时间信息。在2D-CNN中,在卷积层上进行二维卷积,从上一层的特征图上提取局部邻域的特征,然后施加一个偏置,通过激活函数传递结果。在(a,b)处的单位值如式(5)所示:

其中,tanh(∗)为双曲正切函数,t 和x 是当前特征图的连接参数,H 和W 是特征图的高度和宽度,z 是特征图的偏置。当应用于视频分析问题时,需要获得多个连续帧中的动作信息。三维卷积解决了这个问题,如式(6)所示:

其中,D 是三维卷积核在时间维度的值。因此,通过执行3D 卷积从空间和时间两个维度提取特征,可获取多个相邻帧中的动作信息。

图3 视频帧采样对比图

图4 三维卷积神经网络
通常3D-CNN 的输入是16 个连续的原始RGB 帧,从16帧剪辑中提取外观和时间信息。然而16个连续的帧不足以表示整个操作。因此根据2.2节得到的采样后的视频,设置单次输入训练的帧数为8,设计了如图4的三维神经网络。
本文提出的三维卷积网络有6 个卷积层,5 个最大池化层和2 个全连接层,最后连接着Softmax 层。所有的三维卷积核在时间和空间维度上都是3×3×3 和步长为1,过滤器的数量在图中标出。3D 池化层表示从pool1 到pool5。除了前两个池化层的核尺寸是1×2×2,其余所有池化层的核大小都是2×2×2。每个全连接层有1 024个输出单元。
3 实验结果与分析
3.1 数据集和实验条件
本文在两个公共数据集上进行实验和分析。CASIA数据集[19]作为实验数据,该数据由中国科学院自动化研究所模式识别实验室采集提供,共1 446段视频,在室外环境下拍摄,交互行为包括打斗、跟随、超越、会合等。所有视频由分布在水平视角、斜角和俯角的三个静止的摄像机同时拍摄,帧率为25 frame/s,分辨率为320×240。UT 交互数据集(http://cvrc.ece.utexas.edu/SDHA2010/Human_Interaction.html)是一个人类交互动作视频数据集,具有握手、指点、拥抱、击打、推、踢6 类人类交互动作,共120 个视频段,视频格式为720×480,30 frame/s,视频中人像的大小为200像素。UT交互数据集的数据量较小,为了深度学习模型的准确性,通过数据增强处理,如加噪、水平翻转、缩放等手段,将数据集拓展为总量约1 000 段视频的增强数据集。同时,将两个数据集中打斗行为作为异常数据集,其余作为正常行为标注。为了平衡正负样本数据,对异常数据集做数据增强处理,保持正负样本比例1∶1左右。本文将训练集和测试集的样本按4∶1的比例划分。
本文实验设备采用配置为Intel®Xeon®E-2136 CPU,16 GB RAΜ,NVIDIA QUDARO P5000(16 GB)GPU,操作系统为Ubuntu 18.04。采用Caffe 深度学习框架完成了深度学习模型的实现。相应的算法是在Μatlab2016b 和VS2017 中开发的。3D-CNN 的最大迭代次数为12 000,初始学习速率为0.001。
3.2 实验分析
本文设计了4 个实验来证明所提方法的优越性。首先,对预识别空间进行实验分析,检验其作用和性能。如表1所示,在两个数据集上对有无预识别空间处理进行了分析。预识别空间在监控视频检测时可缩小搜索范围,在数据训练时可有效去除非目标动作干扰视频帧部分。

表1 预识别空间的作用和准确率比较%
时空采样算法能够进一步地优化训练数据,在预识别空间数据的基础上去除冗余视频帧。同时,根据保留的单个视频的帧数,设计了相应的3D-CNN 网络参数,使两者相等。也就是说,3D-CNN不会将视频数据切割成多个小块后再通过一致性函数做分数融合操作,而是一次性提取和学习到整个视频的动作时空特征。表2和表3 分别展示了时空采样算法的性能和不同采样帧数的性能,可以看出8帧采样的时空采样算法检测准确率最高。
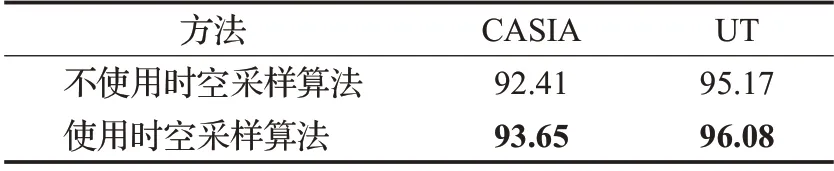
表2 时空采样算法的作用和准确率比较%

表3 时空采样不同帧数的准确率比较 %
本文还对近年来的一些斗殴行为检测算法进行了分析,并与本文所提方法进行比较。文献[20]提出了基于加权样本选择与主动学习的视频异常行为检测算法。文献[6]提出了联合加权重构轨迹与直方图熵的异常行为检测算法。但是,它们都忽略了行为动作的时空特性,单纯的瞬时信息无法准确地识别斗殴行为,正确率较低。文献[7]提出了一种基于3D-CNN 结构的暴力检测方法,通过三维深度神经网络直接对输入进行操作,但是对神经网络的训练数据没有做优化处理,并且没有提出针对监控视频检测过程的处理方法。文献[8]立足于目标距离关系以及图像光流特征进行跟踪定位,以确定帧图像中目标间位置距离关系,再基于光流方向直方图熵来判定打架行为。文献[9]提出了一种双流CNN 模型的打斗行为识别方法,忽视了对训练数据的优化和光流模态计算量大的缺点。表4 展示了本文所提方法和近期其他算法的准确率的比较数据,显示了本文方法的优越性和鲁棒性。

表4 本文方法和其他算法准确率的比较 %
4 结论
本文提出了一种新的基于三维卷积神经网络的斗殴行为检测方法。首先针对监控视频行为检测起始定位的难点,利用基于人体姿态信息的关键区域检测算法定位斗殴行为起始帧,进而形成斗殴行为预识别空间。针对深度学习训练数据冗余和优化程度不够的问题,提出了时空采样算法,结合本文提出的三维卷积神经网络的单次训练输入设置,使网络学习到整个行为动作的时空信息。实验结果证明了本文方法的优越性和鲁棒性。
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
作文大王·低年级(2018年10期)2018-12-06 06:22:44
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
