
改进的基于DNN的恶意软件检测方法
2021-05-26 03:14:20张柏翰
计算机工程与应用 2021年10期
张柏翰,凌 捷
广东工业大学 计算机学院,广州510006
蓬勃发展的互联网为人们的工作和生活提供诸多便利,同时也可能被不法分子利用,成为其牟利犯罪的工具。诸如计算机病毒、蠕虫、木马、僵尸网络、勒索软件等在内的恶意软件长期以来都是不法分子用以破坏操作系统、窃取用户重要数据的利器,互联网应用的普及则加剧了恶意软件的传播。根据ΜcAfee Labs 在2019年8月发布的威胁报告[1],恶意软件总数在2019年第一季度已经突破9亿;而在恶意二进制可执行文件方面,从2017 年至2019 年间,单季度最高新增量高于110 万。对恶意软件的检测和查杀一直是网络空间安全研究领域的重要课题之一。
恶意软件检测方法可根据是否需要运行软件分为静态分析方法和动态分析方法。静态分析方法只对二进制可执行文件中的代码进行分析,动态分析方法则对可执行文件运行时的行为进行分析。无论哪种分析方法,传统手段都需要大量人工工作和专家经验,效率较低。而且攻击者使用多态组合、仿冒、压缩、混淆等方法,有意让恶意软件避开检测软件的检测[2],这无疑增加了人工分析的难度。近年来机器学习尤其是深度学习在图像处理、文本处理等领域的成功实践,为从事恶意软件分析工作的研究人员带来启示。当前网络空间中恶意软件样本庞大的数量,以及二进制可执行文件本身庞大的可提取特征的数量,使得深度学习方法非常适合于恶意软件分类工作。
2015 年,微软开放了一个数量上万的带标签的恶意代码样本集,供研究者们使用[3]。在已有的工作中,Zhang等[4]、Dinh等[5]、Burnaev等[6]、Drew等[7]、Patri等[8]以及Gsponer 等[9]使用该数据集研究基于机器学习的对恶意软件家族进行多分类的方法。Κebede等[10]、Κim[11]、Rahul 等[12]同样研究恶意软件的分类问题,不过他们使用的是容易取得更好效果的神经网络模型。以上研究工作的目的均是对恶意软件按所属家族分类。而在恶意PE(Portable Executable)文件检测中,也即关于PE文件的“善”“恶”的二分类问题方面的最新研究中,有许多基于机器学习的方法被提出。文献[13]使用共享近邻聚类算法检测新恶意软件。文献[14]基于生成对抗网络构建恶意软件检测器模型。文献[15]构建集成了卷积神经网络和长短期记忆网络的检测器模型。文献[16]使用深度置信网络构建检测器模型。文献[17]针对缺乏确定性质样本的情况,提出了一种基于半监督深度神经网络的恶意样本标记方法。文献[18]基于许多新类型的恶意软件都是现有恶意软件的变体这一事实,将可执行文件转为灰度图,并使用基于卷积神经网络(Convolution Neutral Network,CNN)的分类器进行同源性分类,以训练好的分类器来识别。文献[19]描述了一种端到端恶意PE 文件检测模型ΜalConv,其直接将未经处理的原始PE 文件作为特征向量,并由使用了嵌入层和一维卷积层的神经网络模型提取特征,从而做出“善恶”的判别。该文献作者Raff 等人表示他们的模型在恶意PE文件的检测上具有不错的效果,然而文献[20]的作者Κolosnjaji 等人针对该模型提出一种基于梯度下降的生成对抗样本的算法,由该算法生成的对抗样本逃避ΜalConv 检测的成功率可达到60%。文献[21]基于Endgame 公司开放的恶意PE 文件特征数据集Ember[22],用10个全连接层建立二分类模型DeepΜalNet,对PE文件的善恶进行判断,输出PE文件为恶意软件的概率。DeepΜalNet 非端到端检测模型,其接收的数据为PE文件经过预处理后得到的特征向量。该模型对恶意PE 文件具有不错的检出效果,且目前尚未有人提出针对此种模型的对抗攻击方法。然而在本文实验过程中,发现其存在参数数量过多和泛化性较差的问题。
在数据集方面,Virusshare、Virustotal、Μalshare等网站提供大量恶意软件样本供学习和研究使用,Μicrosoft也开放恶意PE样本集供研究,其中每个PE文件具有所属恶意软件家族的标签。至于正常可执行文件样本,由于政策等因素,互联网上并未有组织或个人开放大量可用原始样本。也正因此,大量的关于恶意软件的分类研究工作均集中在对恶意软件所属家族的归类问题上。Endgame 公司于2017 年开放了一个用于研究恶意软件检测的数据集,其中包含由100 万个PE 文件样本通过特征工程转化而来的100 万个长为2 381 的32 位浮点数特征向量。本文在该数据集上设计并开展了验证性实验。
本文将针对文献[21]设计的恶意PE 文件检测器模型所存在的泛化性较差的问题,改进模型结构,提高模型的泛化能力,并使模型在后续剪枝工作中保持可用性。
1 相关工作
1.1 基于DNN的二分类模型
本文使用具有多个全连接层的神经网络构成恶意软件检测器模型。检测器接收的数据为将PE文件进行预处理后得到的特征向量,预处理的方法将在后文介绍。实验中曾在模型中加入一维卷积层和循环神经层,但与单纯使用全连接层的模型相比其效果不佳。由此推测,由本文所述数据预处理程序提取的特征向量不具备时序性,因而本文最后选择深度神经网络(Deep Neural Network,DNN)作为恶意软件检测器模型的基础架构。
特征向量输入模型后,会经过多个模块M 。这里模块M 是一个数据处理流程:模块M 接收输入数据或由上一个模块处理后得到的输出数据X ,经过批归一化层(Batch Normalization,BN),使得向量X 各维数值x0,x1,…,xn均值趋于0,方差趋于1;然后数据经过一个具有n 个神经元的全连接层,此全连接层采用relu作为激活函数;最后使用定向Dropout方法,在每一个训练步骤中挑选一定数量的权重参数,使其失活,通过这种方法防止神经网络过度依赖某些神经元,导致训练得到模型过度拟合数据集而泛化性差。
数据从最后一个模块输出后,再进入一个只有一个神经元的全连接层,即输出层。该层以sigmoid 函数作为激活函数,得到介于0 和1 之间的32 位浮点数,表示判定输入样本为恶意PE文件的概率。
需要指出的是,本文设计的模型使用定向Dropout方法替代DeepΜalNet所用的普通Dropout方法,并通过实验验证其有效性。
1.2 全连接层
全连接层由一个线性函数加一个激活函数组成,如式(1)所示。假设ni-1为第i 个模块接收的输入向量Xi的维数。第i 个全连接层的权重矩阵为Wi,其由ni个维度为ni-1的向量构成,bi为偏置向量,维数为ni。a为激活函数,目的是对线性函数的输出作非线性变换。

在本文设计的检测器模型中,除了输出层外的每个全连接层使用的激活函数皆为relu 函数。实验曾尝试使用sigmoid、leaky-relu、erelu、prelu等函数作为模块M中全连接层使用的激活函数。实验中发现,relu及其变种函数的效果最好,因此本文最终使用relu 作为模块M 中全连接层的激活函数。而在输出层中,本文使用sigmoid作为激活函数。
1.3 Batch Normalization
在训练模型时,若各层网络接收的输入数据的分布不一致,则后层网络需为了适应输入数据的变化而不停调整,如此将导致学习速度降低,模型无法很好地收敛。因而本文设计的模型中引入BN机制,利用反向传播使各网络层的数据分布一致。
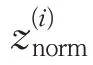

1.4 正则化

DeepΜalNet 模型使用Dropout 方法防止过拟合。这种在模型的每一步训练中随机选择权重并令其失活的正则化方法在一定程度上可以防止模型过度依赖部分权重,但也导致模型训练成型后所有权重的重要性一致,即没有一个可以显式择取的最优子网络,因而不利于模型后续剪枝中保持高可用性。而本文的实验中使用一种称为“定向Dropout”的方法代替Dropout。下一节将解释这种正则化方法。

定向Dropout正则化方法由Aidan等人提出[23],是一种“基于重要性的剪枝方法”,其在每个网络层中,对神经元的权重或是神经元的线性输出值按大小排序(采用L1或L2范数),然后选出较小的一部分,从这部分权重或神经元中再随机选出一部分,使其失活。这是一种优化的Dropout方法,不仅可以使模型更好地避免过拟合,提高模型的泛化能力,同时,可以使模型在训练后得到一个最优子网络,有利于模型的后续剪枝操作。
如同Dropout 正则化,定向Dropout 也分为针对权重和针对神经元的两种,分别称为权重剪枝和单元剪枝,它们筛选出重要权重的方法可分别用式(7)和式(8)表示,其中argmax-k 表示选出前k 个权重或单元。权重剪枝针对同一个神经元里的所有权重,将它们按一范数从大到小排序,然后选出前k 个作为保留权重,对其余权重行Dropout方法。单元剪枝则针对同一个神经层中的所有神经元,将它们根据各自的权重向量的二范数从大到小排序,选出前k 个作为保留神经元,对其余神经元同样行Dropout方法。之所以不将残余权重或神经元直接摒除,是因为它们中可能有一些会在后续训练步骤中重新显现重要性而进入前k,因此只对它们行随机失活法,保证公平性。记模型参数数量为 ||θ ,候选失活参数占比为γ,对候选失活部分的随机Dropout 比例为α,则在每次定向Dropout 时保留活性的参数数量为(1-γα) ||θ 。
在本文的实验中使用针对权重的定向Dropout正则化方法替代Dropout方法,并测试其效果。

2 本文方法描述
2.1 数据集
EndGame公司开放的Ember数据集,是由对100万个PE文件(包含正常可执行文件和恶意可执行文件)提取的特征向量和它们的标签组成。其中,标签0表示样本为正常可执行文件,标签1 表示样本为恶意可执行文件,标签-1 代表可执行文件未知善恶。在本文的实验中,使用数据集中60 万条带有非-1 标签的数据(其中包括标签为0和1的数据各30万条)作为训练模型时使用的数据集,另外20 万条(其中包括标签为0 和1 的数据各10万条)作为测试模型时使用的数据集。
在测试模型时,除了使用Ember 数据集做测试,也使用另外两个样本集来测试模型的泛化能力。一个是从Virusshare.com 下载的包括59 011 个恶意PE 文件的样本集。在正常可执行文件样本方面,由于许多软件受版权法律保护,网上也没有开放数量较大的正常可执行文件样本集。本文的实验采用The Universitiy Of Arizona开放的项目lynx-project(获取地址为https://www2.cs.arizona.edu/projects/lynx-project/Samples/),其中包含39个善意PE文件,这些文件使用了一系列恶意代码常用的编码方法,包括使用VΜProtect、ExeCryptor 和Themida等工具对代码进行混淆,以及添加自修改逻辑从而防篡改的方法。本文的实验中使用这个项目来测试检测模型的误报率。
2.2 数据预处理
对每个PE 文件提取用于检测器模型判别PE 文件善恶的信息,描述如下:
文件总体摘要信息。包括文件的虚拟大小,导入、导出函数数量,符号数量,是否有签名、重定向、RSRC节、TLS节。
PE 头部信息。这些信息提取自符合COFF(Object Common File Format)规范的PE 文件头部的字段。提取的数据包括时间戳、目标机器、子系统、镜像特征、DLL 特征、魔数、镜像版本、链接器版本、代码部分字节数、文件头部大小、提交堆的大小。
导入函数信息。包括文件导入的库名以及从导入的库中引用的函数名。使用哈希函数将每个名称字符串转成256或1 024个二进制位数表示。
导出函数信息。包括一系列导出函数的名称字符串。同样使用哈希函数,将每个字符串转成长为128的二进制位串。
节信息。PE 文件有多个节,从每个节中提取的信息包括节名、节大小、节的熵值、节的虚拟地址、节的特征(如是否可写内存)。将节名使用哈希函数转为50位串。将节名分别与节大小、节的熵值、节的虚拟地址配对,并使用哈希函数分别转为50 位串。将入口节的特征用哈希函数分别转为50位串。
数据目录信息。数据目录包括导出表、导入表、资源目录、异常目录、安全目录、重定位基本表、调试目录、描述字串、机器值、TLS 目录、载入配值目录、绑定输入表、导入地址表、延迟载入描述、COΜ 信息。导出每个数据目录的大小和虚拟地址。
字节统计信息。将文件中每个不同大小的字节(0~255)出现的次数进行统计,并除以文件总字节数,进行归一化。
字节熵的统计信息。对文件使用固定大小的滑动窗口,将其按一定步长在文件上滑动,每滑动一步,计算窗口中的信息熵。在本文的实验中,滑动窗口的大小为2 048 Byte,滑动步长为1 024 Byte。
可打印字符串的统计信息。选出的每个字符串需至少包含5个可打印字符。统计信息包括字符串总数,字符串平均长度,每条字符串的出现次数,字符串的信息熵。
将上文所述的文件总体摘要信息、PE头部信息、导入函数信息、导出函数信息、节信息、数据目录信息、字节统计信息、字节熵的统计信息、可打印字符串的统计信息打包,并转为由2 381个32位浮点数构成的特征向量。其中,提取的各类文件信息对应的浮点数个数如表1所示。

表1 PE文件特征向量概况
2.3 编码与实验设计
本文所述实验使用易于搭建模型并测试、编码较简易的Κeras 框架来搭建恶意软件检测模型,训练模型时使用Nvidia P100计算卡做运算。
实验中,首先依文献[21]所述搭建恶意软件检测器模型DeepΜalNet,并在Ember 数据集上训练,使模型收敛。如图1 为文献[21]所述检测器模型DeepΜalNet 的结构图,其中包含10 个全连接层,在每个全连接层之后,使用BN和Dropout以避免模型过拟合,同时加速模型的收敛过程。模型的详细参数可参考https://github.com/vinayakumarr/dnn-ember。

图1 DeepΜalNet网络结构图
本文设计的检测器模型同样基于DNN,但与Deep-ΜalNet不同的是,本文模型在每个模块中先使用BN机制处理模块接收的向量,然后使用定向Dropout 算法择取全连接层中的一部分权重使其失活,之后才让数据流过模块中的全连接层。在定向Dropout中使用的γ 和α参数大小分别为0.66 和0.75。本文设计的检测器模型结构如图2 所示。其中m 表示模块个数,在实验中测试了拥有10 个模块的模型和拥有4 个模块的模型的效果,前者各模块包含的神经元数与DeepΜalNet 相同,后者各模块包含的神经元数分别为2 381、4 762、2 381、1 024、128。

图2 本文模型网络结构图
实验使用Ember数据集中的标签为0和1的数据各30万条,共60万条数据,作为训练模型用的数据集。使用交叉熵损失函数作为模型目标优化函数,并使用Adam作为梯度下降的优化器,设置其学习率为0.01。为了加速模型收敛过程,防止模型在部分数据上过拟合,实验中将60 万条训练数据打散,并设置模型每一次梯度下降过程中使用的批的大小为32 768。让每个模型在训练集上训练500 epoch(周期),并在每个epoch后使用测试集对模型进行验证,计算并记录模型在测试集上的准确率。将模型在测试集上的准确率与epoch的关系绘制为坐标曲线,从而观察模型的训练情况。
本文在对实验结果进行评估时采用的度量指标包括平均预测概率、召回率(模型在恶意软件样本集上的预测)、误报率(模型在正常软件样本集上的预测)。所述“平均预测概率”即指模型将样本集中的文件预测为恶意的概率的平均值。在本文实验中,经过训练的恶意软件检测模型可接收一个二进制可执行文件的字节内容,运算后返回一个介于0和1的浮点数,数值越接近1,则表示文件为恶意的概率越大。召回率,或称“查全率”,表示模型在恶意样本集中预测为“恶意”的样本数占恶意样本集总数的百分比。误报率表示模型在正常样本集中预测为“恶意”的样本数占正常样本集总数的百分比。本文的实验分析中未采用二分类机器学习问题中常用的准确率、F1分数以及AUC作为度量指标,是因为受限于测试集中有限的正常样本数量(本文实验仅采用39个正常软件样本),这些指标并不能准确反映本文实验中模型的性能。另外,本文实验重点关注模型对恶意软件的识别能力以及面对加壳文件时的判别能力,故将平均预测概率作为评价模型性能的重要指标之一。
3 实验结果与对比分析

图3 各模型在验证集上的准确率变化情况
在训练过程中,在完成每一个测试步骤后,使用Ember测试集验证模型的性能。图3展示了DeepΜalNet以及本文设计的模型(分别具有10 个模块和4 个模块)在前100 个训练周期中的准确率变化情况。实验中,DeepΜalNet 以及本文模型在100 个训练周期基本达到稳定状态;在超过500个训练周期以后,各模型在Ember测试集上的准确率都在0.96左右。
实验中用Virusshare 恶意样本集中的59 011 个恶意PE 文件测试训练好的模型。表2 展示各个模型对Virusshare 样本集中恶意PE 文件的平均预测概率,表3则展示各模型在不同阈值下在Virusshare 上的查全率。实验中还将阈值与预测概率大于某个阈值的文件数量的对应关系绘制成坐标曲线,如图4 所示,该曲线在第一象限与纵轴和横轴围成的面积越大,则说明检测器模型对恶意PE 文件的识别效果更好。从结果上看,本文模型对恶意PE 文件的平均打分更高,打分为1.0 的PE文件数量比DeepΜalNet 多出20 000 个,这意味着在设置尽可能高的阈值的情况下,相比DeepΜalNet,本文设计的检测器模型能检测出更多的恶意PE文件。分析其中原因,是因为本文模型使用定向Dropout 方法削弱了许多不重要的权重,减少了不必要的隐藏特征对判别过程的干扰,而DeepΜalNet使用普通Dropout方法则仅仅是让模型不过度依赖于部分节点,从而防止过拟合。可以说,本文模型在经过训练后得到了一个最优子网络。
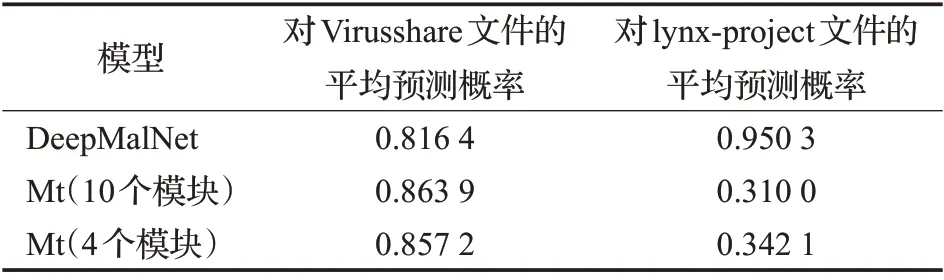
表2 DeepΜalNet和本文模型Μt在Virusshare和lynx-project上的平均预测概率

表3 DeepΜalNet和本文模型Μt在Virusshare上的查全率

图4 各模型的阈值与正例数关系
实验中还使用了lynx-project正常样本集的39个善意PE文件对几个训练好的模型进行测试。表2给出这些模型对lynx-project的平均预测概率,表4展示各模型在不同阈值下在lynx-project 上的误报率。实验结果显示,DeepΜalNet 对这39 个样本给出的平均预测概率为0.95,其中预测概率大于0.90 的样本达到34 个,误报率十分大。相应地,本文模型对lynx-project的平均预测概率为0.31,比DeepΜalNet 在lynx-project 上的平均预测概率小0.64。前文已述,lynx-project样本集中的可执行文件皆采用过Themida等加壳工具进行加壳,而这些加壳工具及其变种通常也被用于为恶意软件加壳。可执行文件在经过加壳工具的混淆操作后,其原始程序代码成为高熵值的字节序列,除了PE文件头、脱壳存根程序以及某些未经过混淆处理的节外,其中基本已无可用于分析文件善恶的信息。实验分析认为,由于训练后的DeepΜalNet 将被加壳的可执行文件的一些共同特征(比如高字节熵值)作为将文件判定为恶意软件的重要特征并赋予较高权重,或者说,由于其未将被加壳文件的这些相关特征的权重降低,导致其对lynx-project中的大多数被加壳文件的预测结果十分接近于1。而本文模型在训练过程中不断削弱范数较小的权重,从而达到精炼特征的效果,因而降低了加壳文件的一些共有特征对本文模型判别可执行文件善恶的影响。该实验结果进一步表明本文模型相较DeepΜalNet 更好地避免了过拟合。
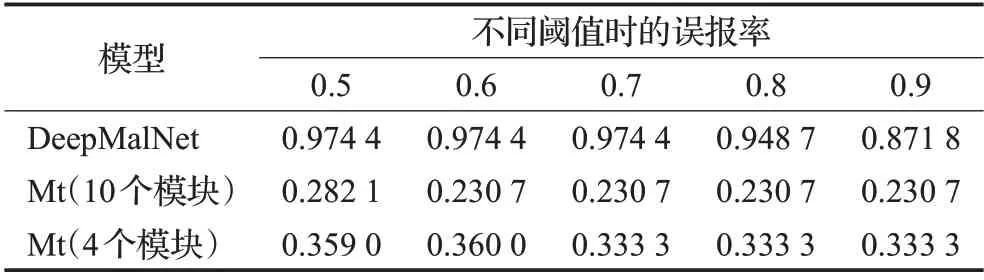
表4 DeepΜalNet和本文模型Μt在lynx-project上的误报率
根据以上实验结果可知,相比同样采用Ember训练集进行训练的DeepΜalNet 模型,本文设计的恶意软件检测模型在Ember训练集上训练后,其在Ember验证集上的准确率与DeepΜalNet同为0.96。在泛化能力的测试中,相比DeepΜalNet,本文模型对Virusshare 恶意PE样本集的平均预测概率提高0.048,对lynx-project 正常PE样本集的平均预测概率降低0.64。实验结果表明本文设计的模型相比DeepΜalNet 模型具有更好的泛化能力。
4 结束语
本文针对常用的恶意软件检测模型存在的泛化能力较差的问题,提出一种改进的基于DNN 的恶意软件检测方法,在模型中引进定向Dropout 方法对模型权重进行剪枝,弱化重要性较低的权重,减少它们对模型预测过程的影响。与同样基于DNN且使用Ember作为训练数据集的DeepΜalNet 相比,本文方法不仅在Ember数据集上有同样高的验证准确率,且在使用别的样本集做测试时,本文方法的查全率更高而误报率更低。结果表明,本文方法的模型泛化性更好,而更好的泛化能力能让模型避免为应对新恶意软件而过于频繁地重训练。
未来的工作中,需对本文提及的对二进制可执行文件的预处理方法进行改进,以提取更多有助于模型识别恶意软件的特征,同时需探索更优模型结构,进一步提高模型的预测准确率,并保证模型具有良好的泛化性和鲁棒性。
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34
中学生数理化·中考版(2021年3期)2021-07-22 07:41:30
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52
当代陕西(2020年17期)2020-10-28 08:18:18
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
数学学习与研究(2017年3期)2017-03-09 18:12:42
