
深度迁移学习在古筝品质分级中的应用
2021-05-26 03:13黄英来任洪娥王佳琪
计算机工程与应用 2021年10期
黄英来,温 馨,任洪娥,王佳琪
东北林业大学 信息与计算机工程学院,哈尔滨150040
随着经济和文明的发展,人们对民族乐器表现出越来越浓厚的兴趣,古筝面板市场也随之扩大。由于当前对古筝面板品质分级方法主要依赖乐器师个人经验,并根据QB/T1207.3—2011《筝》这一标准观察木材纹理和掂、敲、听等方式来进行主观判断,这种方法需要较长判断时间且结果易受人为因素影响;误判率较高,难以满足日益兴起的市场需求。
深度卷积神经网络(Deep Convolutional Neural Network,DCNN)[1]自2012 年后相继出现,并在计算机视觉与图像处理[2-3]领域上取得了超越人类专家的识别结果,然而训练好一个DCNN需要数百万个参数且离不开大量的标记样本,需要耗费大量训练开销和时间。针对很多领域[4-5]缺乏有效的标注数据这个实际问题,迁移学习给出了很好的解决方法,其通过放宽训练数据和测试数据必须为独立同分布的假设,将知识从源域迁移到目标域[6-11]。
目前在深度学习和迁移学习热潮下对木材的识别方法都是针对不同树种展开的,缺乏对同一树种不同品质板材之间进行分类的研究。本文通过分析以往对不同树种间研究的方法,来探索一种应用于古筝面板品质分级方法。Loke 等人[12]提出一种转换卷积神经网络(Convolutional Neural Network,CNN)输入层来直接捕获纹理属性和关系像素属性的新方法,在27 种木材分类中识别精度达到了93.94%,但该方法需要海量数据且受限于CNN 网络层数,层数过深时网络易过拟合。Ravindran 等人[13]基于预训练VGG16 模型实现了对10种热带楝科木材分类识别,识别精度达到了87.4%~97.5%。王莉影等人[14]利用预训练的Inception v3 模型实现了对针叶林和阔叶林遥感图像的分类,识别精度超过了97%。以上两种方法使用的是迁移学习中预训练模型,其很好解决了深度学习中所需海量数据和计算开销过大问题,但在源域和目标域出现一定的差距,目标域之间差距又较小的时候,预训练模型学习的多是源域和目标域间相似特征,难以充分提取到针对目标域中深层特征,模型提升精度有限。张锡英等人[15]通过融合空间映射网络(Spatial Transform Network,STN)和DenseNet解决了网络对输入数据敏感问题,从而提升了识别精度,在184种复杂背景下树木叶片上识别精度达到了90.43%。但由于DenseNet采用的密集连接机制使其实际占用内存较大,导致运行时间较长。
以往为了让模型提取更多特征,一种常用方式是在其后端堆叠卷积层增加深度来提取深层特征,这样做也带来了相应弊端。首先层数过深容易造成参数量冗余和过拟合现象发生,然后只是卷积层堆叠特征提取效率较低而且容易丢失前层特征,最后随深度增加ReLU进入负区间导致梯度为0,从而权重无法更新,风险也随之变大。为了高效地提取到板材图像间深层特征,本文设计了一种深度残差网络模型,其创新性主要有以下两点:其一,在预训练模型后端新增深层特征提取部分。该部分融合了残差连接和深度可分离卷积,在增强特征重利用同时,有利于高效提取到图像深层特征。其二,为保证神经元学习能力,使用LeakyReLU[16]函数代替传统的ReLU 激活函数,避免了过多神经元死亡的问题,增强了网络鲁棒性。最后将残差连接和深度可分离卷积融合单元块的输出向量送入全连接层用于图像分类。实验表明,本文使用的深度残差网络模型对比其他方法不仅识别精度更高,计算开销更小,运行时间也较短,为古筝面板市场实现准确高效品质分级提供了可能。
1 研究方法
1.1 残差连接
残差连接是一种常见的类图网络结构,残差连接解决了深度学习模型面临的表示瓶颈和梯度消失难题。其一方面将前面的输出张量与后面的输出张量相加,将较早的信息重新注入下游数据流中,从而减少了有效信息在处理过程中流失;其另一方面引入一个纯线性的信息携带轨道,与主要的层堆叠方向平行,有助于跨越任意深度层来传播梯度。残差连接公式如式(1)所示:

2016年,何恺明等人[17]在深层网络中引入残差连接并命名为残差网络(ResNet)。残差网络将式(1)原本带权值残差项代替为恒等映射。如果深层网络后面那些层是恒等映射,那么模型就可以退化为一个浅层网络。在残差单元中,通过“短连接”的方式,直接把输入x 传到输出作为初始结果,输出结果为H(x)=F(x)+x ,当F(x)=0 时,那么H(x)=x,也就是上面所提到的恒等映射。于是ResNet相当于将学习目标由学习一个完整的输出改为目标值H(x)和x 的差值,也就是所谓的残差F(x):=H(x)-x,此时网络拟合残差会更容易。残差单元结构图1所示。

图1 残差单元
ResNet-50 是ResNet 系列性能最优网络结构之一,其包含50层需要训练网络层数,通过使用类似图1残差单元,实现了在增加网络深度同时提升识别精度,解决了梯度消失的问题。
1.2 深度可分离卷积
深度可分离卷积是一种执行卷积更高效的方式,简单来说,其将标准卷积分解成深度卷积和逐点卷积,深度卷积对应着每一个输入特征图的通道,1×1逐点卷积负责将深度卷积提取的特征进行融合。如图2所示。
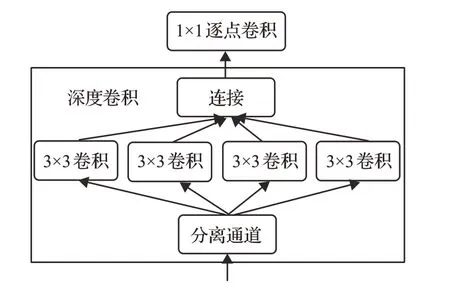
图2 深度可分离卷积
普通卷积计算过程如下所示:

其中,W 为卷积核,y 为输入特征图,i、j 为输入特征图分辨率,k、l 为输出特征图分辨率,m 为通道个数。深度卷积计算过程如下所示(⊗表示对应元素相乘):

逐点卷积计算过程如下所示:

深度可分离卷积计算方式如下所示:

深度可分离卷积对输入的每个通道先分别空间卷积,然后再通过逐点卷积将输出通道混合。这相当于将空间特征学习和通道特征学习分开,这样做所需参数要少很多,计算量也更小,因此可以得到更小更快的模型。
1.3 网络模型搭建
不同树种间的细胞与组织的形态及排列特征差别很大,所涉及的识别特征也较多。而本文研究是在同一树种不同品质板材之间进行分级,板材图像间相似性较高,这对模型特征提取能力提出了更高要求,仅使用主流预训练模型可以解决数据匮乏和网络开销过大问题,但难以充分提取到图像间深层特征,导致模型分类效果不佳。为了高效提取出不同品质板材图像中深层特征,利用预训练模型提取特征作为残差,并与后端新增网络相连,预训练模型可快速提取到源域和目标域间相似特征,同时作为残差连接一部分输入后端新增网络实现特征重利用。后端新增网络由于其权重和参数都是在板材图像上训练的,结合残差连接更有利于提取到目标域中有效特征,为提升模型性能,采用深度可分离卷积代替普通卷积来减少训练参数和降低计算复杂度,采用LeakyReLU函数代替ReLU函数提升模型鲁棒性。
基于上述思想将残差连接和深度可分离卷积融合起来,并将其命为残差-深度可分离卷积模块,在该模块中包含2 个3×3 深度可分离卷积层(SeparableConv 3×3)、1个1×1卷积层(Conv 1×1)、3个批处理化层(BN)[18]、1个LeakyReLU层、1个最大池化层(ΜaxPooling2D)、1个信息叠加层(Add),如图3所示。
在图3残差-深度可分离卷积模块中,首先使用2个3×3深度可分离卷积从ResNet-50提取特征向量中进一步提取图像深层特征,并在卷积层和深度可分离卷积层后使用了批标准化(Batch Normalization,BN)来加速模型收敛,BN层实现如下所示:


图3 残差-深度可分离卷积模块图
其中,xi为BN层输入数据,yi为BN层输出数据,γ 和β 都是训练参数。
在两个深度可分离卷积层中间使用LeakyReLU 函数来代替传统ReLU激活函数,LeakyReLU函数数学表达式如式(10)所示:

其中,ε 是一个很小的常数,可保留一些负轴的值。这种特殊的ReLU,当神经元不激活时仍会有一个小梯度的非零值输出,解决了ReLU函数进入负区间后神经元不学习的问题,从而避免了可能出现的神经元“死亡”现象。然后使用的最大池化(ΜaxPooling2D)在降低参数量的同时能更好保留图像纹理信息,有利于纹理丰富的板材图像分类。最后将“短连接”中1×1 卷积的原始向量线性下采样为与最大池化向量同样形状的向量,并与最大池化的向量相加实现残差-深度可分离卷积模块。
深度残差网络模型整体结构如图4所示。

图4 深度残差网络模型结构图
首先使用权重在ImageNet经过预训练的ResNet-50模型来提取图像初步特征,然后为更好利用上层网络有效特征和提取出图像深层特征,本文设计了一种残差-深度可分离卷积模块。它融合了残差连接和深度可分离卷积的优点。残差连接这种结构一方面可以将上层网络ResNet-50 提取的特征信息重新注入到下游数据中,从而解决了网络某一层太小导致的部分有效信息无法塞入进而永久性丢失的问题,增强了特征的重利用;另一方面残差连接引入的线性信息携带轨道可以缓解深度模型在反向传播中梯度消失的问题,而深度可分离卷积通过分别学习空间特征和通道特征实现了更高效的执行卷积方式,可进一步学习并提取图像深层特征。此外,由于ReLU 函数在训练时一旦输入值为负,则输出始终为0,其一阶导数也始终为0,导致神经元无法学习。在本实验中为尽可能让梯度流经整个网络,确保神经元一直保持学习能力,使用LeakyReLU 函数代替传统ReLU 函数。LeakyReLU 函数输出对负值输入有很小的坡度,保证导数总是不为0,从而解决了ReLU函数进入负区间后神经元参数无法更新的问题,增强了模型在训练过程中的鲁棒性。
1.4 模型参数量和计算量分析
模型的参数表如表1 所示(其中RS_block 表示残差-深度可分离卷积模块)。

表1 网络模型参数表
从表1 中最后3 行可以看到,虽然该深度残差网络模型总体参数约2 391万,但其中ResNet-50固定参数约2 358万,这一部分是不需要再次训练的参数,而模型实际需要从头开始训练的参数只有约32 万,不到总体参数的1.4%。
由于深度可分离卷积在降低模型参数量和计算量过程分析相似,本文以降低计算量(时间复杂度)为例进行分析。假设一个标准卷积层的输入特征图大小为M×H×W ,其中M 是输入特征图通道数,H 和W 是输入特征图的高和宽;输出特征图大小为N×H'×W',其中N 是输出特征图通道数,H'和W'是输出特征图的高和宽,卷积核大小为K×K ,卷积步长和补边为1。
标准卷积其计算复杂度如式(11)所示:

逐深度卷积计算复杂度如式(12)所示,逐点卷积计算复杂度如式(13)所示:

深度可分离卷积计算复杂度如式(14)所示,同普通卷积比如式(15)所示:

由以上公式可以看出,对于每一卷积层,深度可分离卷积层与普通卷积层相比可明显降低计算量,因此,当深度可分离卷积核K 的大小为3时,其参数量和计算量是标准卷积的1/9。
2 实验结果与分析
2.1 实验环境和数据
本次实验在Ubuntu系统下使用Κeras深度学习框架和Tensorflow后端作为开发环境,采用Jupyter Notebook编程软件和Python3.6 开发语言。本文实验结果中的acc 曲线、loss 曲线均是由TensorBoard 可视化数据绘制而成,以此来分析实验结果的实际情况。
实验数据来自东北林业大学木材样本馆,其采用古筝业内面板用材的品质分级标准,分为高级品、中级品、普及品共3 类泡桐木材,经奥林巴斯DP72 显微镜影像系统观察泡桐木材表面采集成像,共2 000 张图像。图像属性为10倍放大率、4 140×3 096像素、水平和垂直分辨率为72 dpi。该数据集按6∶2∶2的比例划分为3个集合:训练集、验证集、测试集。其中训练集为1 200 张图像,验证集和测试集分别是400 张图像。实验对3 种不同品质泡桐板材图像进行识别,如图5所示。

图5 样本图像
为了增强模型的泛化性,减少模型过拟合,采用数据增强对图像进行处理。数据增强是从当前的训练样本中生成更多的训练数据,其通过生成多种随机变换的图像来增加样本,使得模型在训练时有利于观察到数据分布的所有内容,从而具有更好的泛化性。采用的数据增强变换方式及参数如表2所示。

图6 数据增强生成的图像

表2 数据增强方式及参数
值得注意的是,表2中所用的方法是随机改变训练样本方式,且每轮数据增强时对每张图像都执行这7种方式叠加组合。这种随机改变训练样本组合方式的好处是可以降低模型对某些属性的依赖,从而提高模型的泛化能力。例如,可以对图像进行不同方式的旋转、平移和翻转等组合方式,使感兴趣的物体出现在不同位置,从而减轻模型对物体出现位置的依赖性。使用数据增强生成图像如图6所示。
因为数据增强目的是为了增加样本数量,提升模型在训练过程中表现来防止过拟合,所以一般只对训练集中样本进行数据增强。验证集和测试集中数据是用于预测的,因此未进行数据增强。通过采用表2中数据增强方式循环4 轮来将训练集中样本扩充4 倍,经数据增强,训练样本数为6 000,数据集样本总数为6 800。
2.2 超参数优化
超参数是在构建深度学习模型时架构层面的参数,它不同于经反向传播训练学习的参数(权重),需要人为手工设定初始值,如每层网络应该包含多少个单元或过滤器,优化器选为SGD、RΜSprop还是Adam,batch_size批尺寸设置的大小等。
为找出模型最佳性能的超参数,需根据模型在验证集上表现来进行超参数选择,为节省计算开销和运行时间,可将回调函数作用于模型,具体是将ΜodelCheckpoint与EarlyStopping 这两种Κeras 内置的回调函数相结合,一方面用EarlyStopping监控模型的验证精度,如果其在一定轮次内不再改善就中断训练,另一方面用Μodel-Checkpoint在每轮过后保存当前最优权重,从而能在训练结束后保存最佳模型。使用上面两种回调函数后可以在模型刚开始过拟合的时候就停止训练,从而避免用更多轮次重新训练模型,这有利于更快寻找到最优超参数。超参数优化过程如图7所示。

图7 超参数优化过程
经超参数优化后实验过程设置了25 个迭代周期,在RS_block1中每层网络包含128个单元,RS_block2中每层网络包含256个单元,batch_size设为16,损失函数为多元交叉熵函数,优化器采用Adam 优化,学习率设为较小的2E-5。Adam 优化器能较好地处理噪声样本,其利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,随着梯度变得稀疏,Adam比RΜSprop效果会好。
2.3 实验评估
之前将数据集划分为3个集合,除了划分训练集和验证集外,多划分了一个测试集。原因在于在训练和开发模型时总避免不了反复调节模型配置,在调节的过程中需要使用模型在验证集上的性能作为反馈信号,当每次根据验证集上性能来调节模型时,都会有部分验证数据信息泄露到模型中,如果一直基于此过程来调节模型配置,很快会导致模型在验证数据上过拟合。最终模型只是在验证集上表现良好,而人们真正需要的是模型在前所未见的数据上性能表现优异。
本文使用的深度残差网络模型在训练集和验证集上的准确率和损失函数变化分别如图8和图9所示。
从图8和图9中可以看出,模型在前15轮便基本收敛,收敛速度很快,同时验证精度很高。接下来在测试集上进行最后一次实验,使用测试精度来衡量模型最终的识别能力。

图8 模型准确率变化图

图9 模型损失函数变化图
2.4 实验结果
因为采集的三种等级泡桐板材样本数量接近,所以将识别精度acc 作为主要评价指标,如式(16)所示,其中true 为模型正确分类样本数,all 为总样本数目。

各种方法运行时间和测试精度对比的实验结果如表3所示。其中SVΜ表示SVΜ分类器结合人工特征提取的机器学习方法,CNN是Loke等人[12]提出转换CNN输入层的方法,参数和设置保持不变。VGG16、Inception v3分别对应Ravindran 等人[13]和王莉影等人[14]使用的预训练模型,ResNet-50[17]是未增加深层特征提取部分的预训练模型,ST-DenseNet 代表张锡英等人[15]融合STN 和DenseNet的模型,模型层数等设置保持不变。

表3 实验结果对比
2.5 实验分析
根据表3 中实验结果可发现,以SVΜ 为代表的机器学习方法运行耗时很短,但该方法识别精度较低且依赖人工经验提取特征,人工提取特征往往会耗费大量人力物力。Loke等人[12]提出的转换CNN输入层的方法虽可直接捕获图片纹理属性和关系像素属性来提升木材识别精度,但CNN 在数据不足和网络过深时表现并不好,容易过拟合。Ravindran 等人[13]和王莉影等人[14]用VGG16 和Inception v3 预训练模型进一步提升了识别精度,其中Inception v3 通过卷积分解在实现多尺度特征提取同时还减少了计算量和计算时间。ResNet-50[17]作为残差网络模型代表,在ImageNet上经过预训练后,由于其参数不必重新训练,运行时间很快,可快速提取到大量特征,但由于未增加深层特征提取部分,识别精度仅达到87.7%。总的来说,预训练模型经过在ImageNet充分训练后避免了因数据不足引起的过拟合,在小样本数据集上一定程度提升了识别精度,然而其在源域和目标域出现一定差距时,模型学习到参数并非都是和当前问题密切相关的,难以充分提取到图像深层特征,导致其识别精度提升有限。张锡英等人[15]使用ST-DenseNet 先对输入图片进行不变性归一化处理,提升了网络鲁棒性,然后采用DenseNet 中密集连接机制加强特征传递和重利用,有利于提升识别精度,但密集连接这一机制会占用大量内存,导致模型运行时间过长。
本文设计的深度残差网络模型在参数量和计算量上,由于采用预训练模型和深度可分离卷积,在保证网络深度的同时有效控制网络参数量,降低了模型训练对设备的要求,根据式(15)可知深度可分离卷积时间复杂度约为O(9M×H'×W'+M×N×H'×W'),相较普通卷积由式(16)可知其在时间复杂度上降低了近一个数量级,这有效减少了模型的运行时间。在模型鲁棒性和泛化性上,使用数据增强来增加训练样本,从而降低了模型过拟合风险,同时使用LeakyReLU函数解决了ReLU函数进入负区间后神经元死亡带来的权重不更新的问题,增强了模型鲁棒性。在模型特征提取性能上,设计的残差-深度可分离卷积模块可以有效作为信息蒸馏管道,ResNet-50提取特征向量作为残差,同时特征向量继续向下输入训练实现进一步特征提取,有利于将无关信息过滤掉,从而放大、细化和回收与图像类别相关的有用信息,使模型获得更好的分类效果。
3 结束语
为提升古筝面板品质分级识别精度,本文构建了一种适用其品质分级的深度残差网络模型。将泡桐图像数据集划分后,为保证深度学习模型训练需要的充足数据,一方面采用随机旋转、随机平移等数据增强技术来扩充训练样本,另一方面基于迁移学习将ImageNet 上经过预训练的ResNet-50模型迁移到该问题上。然后在预训练模型ResNet-50后设计了一种融合了残差连接和深度可分离卷积的新结构,不仅能够充分利用模型中前层网络有效特征,增强特征重利用,还能高效提取到图像深层特征。为提升模型鲁棒性,使用LeakyReLU 函数替代ReLU 函数。最后在泡桐图像数据集上与其他方法对比,该模型具有识别精度高、计算开销小、鲁棒性高、运行时间较短等优点,说明将该方法应用于古筝面板泡桐用材品质分级是可行的。今后还可以完善该方法并部署到移动端,为古筝市场实现木材品质自动化分级寻找一种科学高效的方法。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
北京航空航天大学学报(2020年10期)2020-11-14
自动化学报(2019年6期)2019-07-23
电子制作(2019年11期)2019-07-04
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
北京航空航天大学学报(2018年1期)2018-04-20
