
增强语义信息与多通道特征融合的裂缝检测
2021-05-26 03:13:44顾书豪李小霞王学渊陈菁菁
计算机工程与应用 2021年10期
顾书豪,李小霞,2,王学渊,2,张 颖,陈菁菁
1.西南科技大学 信息工程学院,四川 绵阳621010
2.特殊环境机器人技术四川省重点实验室,四川 绵阳621010
裂缝是最常见的路面缺陷之一,为保障行车安全,准确检测路面裂缝具有重要的研究价值[1]。在过去的几年中裂缝检测已成为道路养护系统研究的热点。传统的人工道路裂缝检测方法非常耗时且易受主观判断影响,随着计算机视觉技术的发展,人们开始致力于将计算机视觉技术应用于裂缝的自动检测[2]。研究人员已提出了各种基于视觉的方法来检测道路裂缝,早期多采用人工设计特征的裂缝检测算法,例如灰度特征[3]、边缘特征[4]、Gabor滤波器[5]以及方向梯度直方图(Histogram of Oriented Gradient,HOG)[6]。这些方法检测效果依赖于特征的选择,极容易出现空洞、相近特征区域之间相互“污染”以及误识等问题。同时,由于道路路面状况复杂多样,裂纹像素附近的对比度较差,给裂缝的识别和检测带来了极大挑战,在这样复杂的情况下,人工设计单个或多个特征难以检测不同道路的图像裂缝。
近年来,卷积神经网络(Convolutional Neural Network,CNN)已广泛应用于计算机视觉中的目标检测[7]。不同于人工设计特征的方法,CNN 具有自动学习特征的能力,同时不同层次学习不同的特征:低层的卷积层能表达图像的细节信息,学习图像的局部区域特征,有利于图像中各目标区域边界的定位;高层的卷积层能表达图像的语义信息,学习深层次的抽象特征,有利于图像中各目标区域的分类。一些研究人员提出将基于CNN的目标检测算法[8]用于道路路面、混凝土建筑等的裂缝自动检测,并取得了较好的效果,但是仅能定性分析裂缝的有无,难以对裂缝进行定量的分析与尺寸测量。Yang等人[9]将全卷积网络[10](Fully Convolutional Network,FCN)应用于像素级裂缝检测,FCN采用反卷积结构进行上采样,弥补多次标准卷积和池化层引起的细节损失,但网络缺少局部细节信息和语义信息,出现较为严重的类内不一致现象。Ronneberger 等人[11]提出UNet 模型,其编码器和解码器呈对称结构,结合底层和高层的信息逐级上采样恢复图像细节。Badrinarayanan等人[12]提出SegNet模型,利用池化索引对高层特征进行细节修复,具有较好的图像分割效果,但其有效感受野[13]较小,高层的语义信息不足。Chen等人[14]提出DeepLab模型,利用扩张卷积(Dilated Convolution)[15]扩大特征提取网络的有效感受野,提高高层语义信息,但缺失了图像的细节信息。Peng 等人[16]提出全局卷积网络(Global Convolutional Network,GCN)将编码器-解码器结构与大卷积核相结合,以获取更大的感受野。
然而,上述方法均存在网络高层的感受野较小,高层特征图的语义信息不足的问题,导致网络分类性能较差。同时,在卷积网络中多重池化下采样导致图像的细节信息丢失,加上网络高层与低层特征在特征表示级别上有所不同,简单的特征融合方式并不能有效恢复图像细节信息,使得网络难以有效提取裂缝特征进行精确的预测。
基于此,本研究提出了一种增强语义信息与多通道特征融合的全卷积语义分割网络实现像素级裂缝检测,采用编码器-解码器结构有利于恢复图像细节信息,并在网络高层采用扩张卷积替换标准卷积,扩大有效感受野,整合图像上下文信息,增强高层特征的语义表达能力。同时提出了基于注意力机制的多通道特征融合方法,能够更好地关注裂缝像素的前景信息,利用高层特征全局语义信息指导语义与细节特征逐级融合,帮助图像更加精确地恢复细节信息,生成更具判别性的特征图,进一步提升图像中裂缝像素的分割效果。最后在公开的裂缝数据集上对本文提出的裂缝检测网络进行训练,对裂缝图像中的裂缝和非裂缝像素分类,并评估裂缝检测精度。
1 裂缝检测方法

图1 裂缝检测网络模型
本文提出的增强语义信息与多通道特征融合的路面裂缝检测模型,能够有效解决高层语义信息不足的问题,以及更好地融合多通道特征达到更优的检测效果。网络整体为编码器-解码器结构,如图1所示。其中,CB为标准卷积模块(Convolution Block),由两层3×3 的标准卷积构成;ΜaxPooling 为最大池化下采样。同时,在编码器末端采用增强语义信息的多层扩张卷积模块(Cascade Dilated Conv),以有效解决高层特征语义不足的问题。在解码器部分,提出一种基于注意力机制的多通道特征融合(Attention-based Feature Fusion,AFF)模块,使网络能更好地关注裂缝图像前景信息。
1.1 增强图像语义信息的扩张卷积模块
扩张卷积(Dilated Convolution)目前广泛运用于语义分割任务中,假设标准卷积核的大小为k×k,则扩张率为r 的扩张卷积k'大小可由式(1)计算:

如图2所示,是连续的两层卷积核大小为,图(a)是扩张率r=1 的普通卷积,图(b)为扩张率r=2 的扩张卷积,红点表示实际参与计算的卷积核,蓝色代表感受野大小。相比普通卷积,扩张卷积能够有效增加卷积网络的感受野,同时网络参数量保持不变。

图2 普通卷积与扩张卷积对比图
通常,裂缝具有多种尺度以及拓扑结构,采用普通卷积难以有效提取到裂缝的特征,同时网络的感受野较小,如图3(a)所示,3 层3×3 的普通卷积仅能增加7×7的感受野,特征图语义信息不足,导致裂缝检测存在困难。因此,本文提出在编码器末端采用多层扩张卷积,使网络高层特征图具有更大的有效感受野,能够有效利用全局信息的相关性,增强高层特征的语义表达能力。
同时为避免堆叠的扩张卷积造成大范围像素信息不相关,出现空洞或边缘缺失等问题,需要对扩张率大小进行限制。假设有3层卷积核大小k=3 的扩张卷积,其扩张率分别为{r1,r2,r3},定义两个非零权重之间的最大距离为M3=r3,代表第i 层卷积中非零权重之间的最大距离,其中M3=r3,当M2≤k=3 时符合设计要求,其计算公式如式(2):

如图3(b)所示,采用扩张率分别为{1,2,5}的扩张卷积堆叠,此时特征图最终感受野增加了17×17,能够提取到更多的像素语义信息,有效避免像素之间缺乏相关性,有利于提高像素分类准确率。
如图4所示,输入A 表示输入特征图中受限的有效感受野,而输出A'表示经过扩张卷积后特征图的有效感受野扩大。采用扩张率分别为1、2、5 组合而成的多层扩张卷积,能够扩大有效感受野并保持图像细节,增强高层特征图语义信息,提高网络分类精度。扩张率组合实验结果对比分析见2.4节。

图3 普通卷积与多重扩张卷积有效感受野示意图
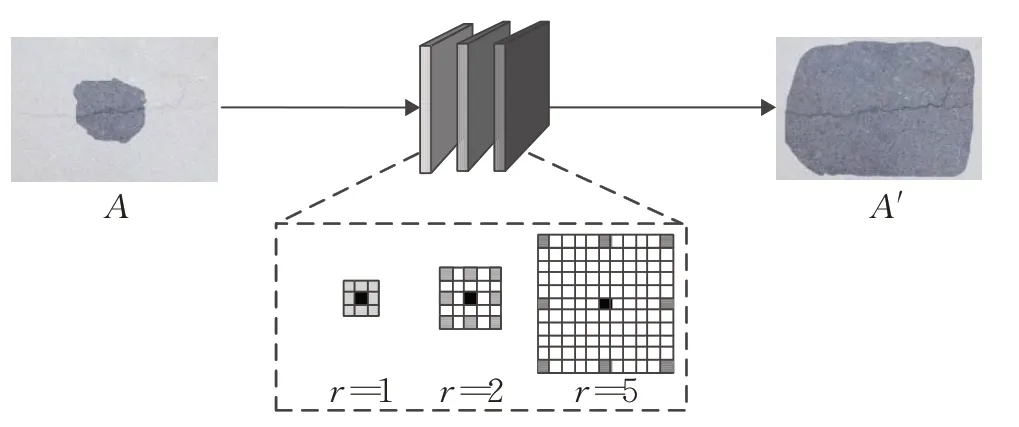
图4 增强语义信息的多层扩张卷积模块
1.2 基于注意力机制的多通道特征融合模块
自然场景下的裂缝图像通常包含大量前景和复杂的背景信息。在裂缝检测任务中,精确地提取裂缝前景信息,能够提高模型的分类性能。本文采用注意力机制来更多地关注裂缝图像的前景区域,生成更具有判别性的特征,从而有助于进一步提高裂缝检测精度。
注意力机制可以被视作一种信息选择机制,利用权重对输入信息进行再编码,使之更接近于真实标签。常用的注意力机制可以看作注意力权重向量α 与输入特征y 对应位置元素的点积,如式(3)所示,其中c ∈{1,2,…,C},C 表示通道数总数,真实标签为yT。

在语义分割网络中,二者在特征表达上存在差异,简单的特征融合,如像素求和与通道拼接等,往往忽略了语义信息与细节特征之间的不一致。由此,本文设计了一种基于注意力机制的多通道特征融合模块,利用高级特征提供语义信息来指导多通道的特征融合,使网络能够正确关注到裂缝图像的前景信息,从而生成更具判别性的融合特征。
如图5 所示,H 表示来自网络高层的语义特征,L表示来自低层的细节特征。首先,将高层语义特征和低层细节特征串联,利用批量归一化来平衡特征的数据分布,经过Relu激活函数得到特征向量x,如式(4)所示。
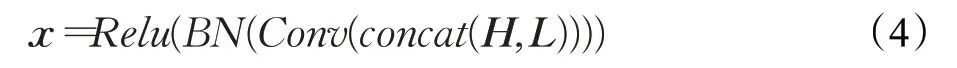
其次,如式(5)所示,对于特征向量x,采用全局平均池化(Global Average Pooling,GAP)提取出全局平均向量,依次通过Relu激活函数和Sigmoid激活函数得到最终的权重向量α。

最后,利用该权重向量与低级特征相乘,对低级特征进行加权,如式(6),将高级特征与加权后的低级特征相加得到融合后的特征图:

在本文的裂缝检测网络中,在解码器部分逐级应用基于注意力的特征融合模块AFF模块,使网络更好地关注裂缝前景信息,并通过逐级上采样,融合来自网络高低层的不同特征图以恢复图像细节信息,达到更好的预测结果。特征融合方式对比实验结果见2.4节。
2 实验与分析
2.1 实验数据与设置
本文采用的实验配置如下:CPU 为Intel®CoreTΜi7-7700Κ,主频为4.20 GHz,内存为16 GB;GPU 为GeForce GTX 1080Ti,显存为11 GB。本文实验所用深度学习框架为TensorFlow1.8,使用CuDNN V7 和Cuda9.1 版本。采用的裂缝数据集为CRACΚ500[17]与CrackForest[18]裂缝公共数据集。
CRACΚ500数据集:训练数据包含1 896张图像,验证数据包含348 张图像,测试数据包含1 124 张图像。验证数据用于在训练过程中选择最佳模型,防止出现过拟合。训练结束后,在测试数据和其他数据集上进行测试以评估泛化性能。
CrackForest 数据集(CFD):由118 张RGB 图像组成,分辨率为480×320。所有图片拍摄于中国北京的人行道,可以反映北京市现有的城市人行道表面状况。这些图像照明不均匀,并包含阴影、油斑和水渍等噪声,这使得裂缝检测非常困难,可直接用于评估算法性能。
由于裂缝图像数量较少,很容易导致训练过程中出现过拟合,同时为保留图像原有的色彩信息,仅采用随机逆时针旋转30°、60°、90°、水平和竖直翻转等数据增强手段,如图6所示。在训练时训练集图像大小缩放为256×256,验证和测试期间不使用数据扩充。
使用二分类交叉熵(Binary Cross Entropy,BCE)+骰子系数损失(Dice Loss)作为训练过程中的损失函数。使用Μomentum 优化器训练100 轮,学习率初始化为0.001。训练批次大小设置为8,动量为0.9,权重衰减为0.000 5。
二分类交叉熵损失函数如式(7):
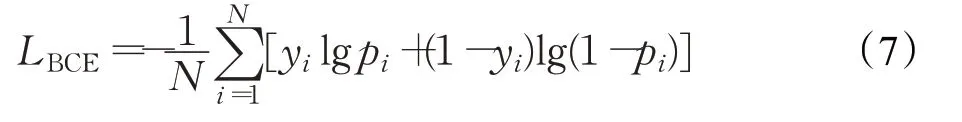
其中,N 表示图像包含的像素数目,yi和pi分别为第i个像素点的标签值和预测概率。

图5 基于注意力的特征融合(AFF)模块
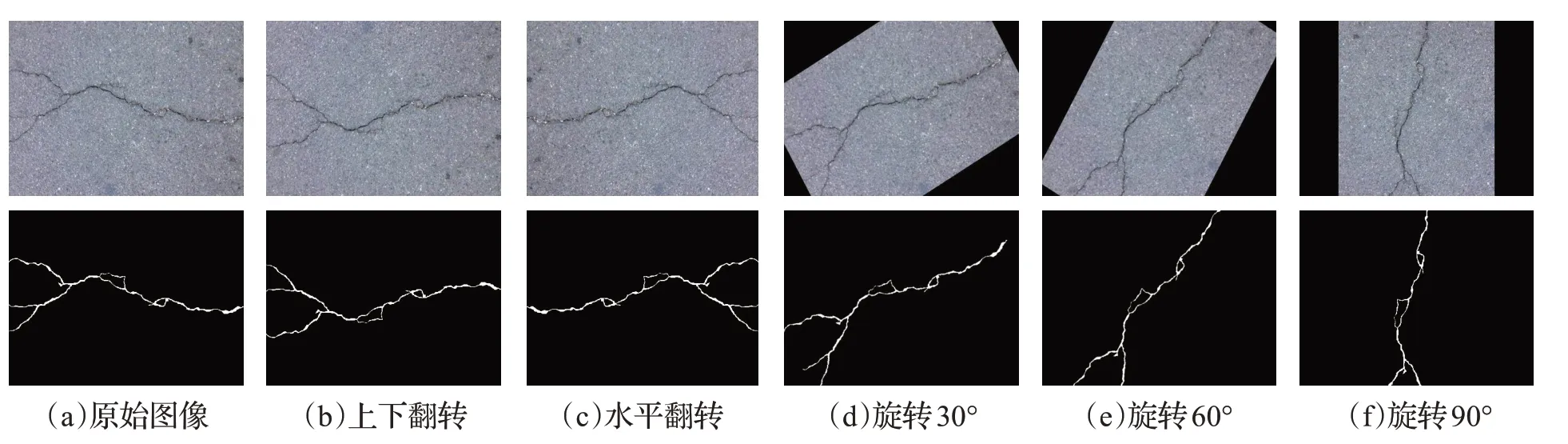
图6 数据增强示意图
骰子系数损失函数表达式如式(8),ε 为设置值,作用为防止过拟合,可设置为1:
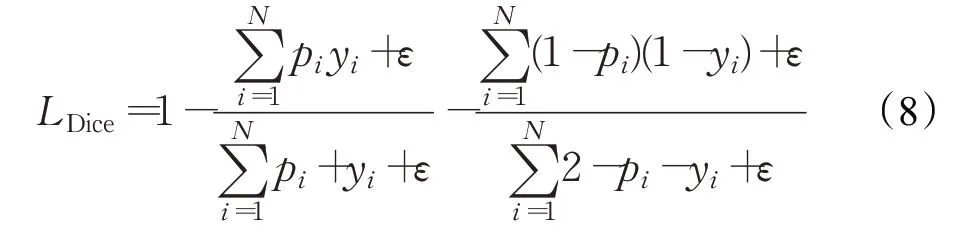
综上,本文采用的组合损失函数如式(9)所示:

组合损失函数能同时关注像素级别的分类正确率和图像前景的分割效果,使模型训练更加稳定,同时能有效克服裂缝图像中正负样本分布不均衡的问题,从而获得更加精确的像素级检测结果。
2.2 评估指标
由于裂缝图像前后景类别分布不均,使用准确率和召回率评估模型性能均存在一定的偏差,本文采用F1score 和平均交并比(Intersection over Union,IoU)来评估提出的网络模型,F1score 主要用于评价网络对于裂缝像素与背景像素的分类精度,同时兼顾了分类模型的精确率和召回率。交并比是用于评价网络模型对于裂缝像素的分割效果,平均交并比是对所有类别取平均值。F1score 和平均交并比这两项指标越高,代表网络对裂缝的检测性能越好。
2.3 对比实验
为了充分比较各模型对裂缝图像的像素级检测性能,以验证本文方法的有效性,将提出的模型结构与UNet、SegNet、FC-DenseNet56[19]和GCN等先进的编码器-解码器结构网络模型进行实验比较。在CRACΚ500 等公开裂缝数据集上进行模型训练和测试。在CRACΚ500数据集上完成模型训练后,首先在CRACΚ500 测试集上测试,为了进一步验证算法通用性能和可迁移性,在CRACΚ500训练后的模型不经过任何微调,直接在CFD数据集上测试,并与GCN 等编解码器结构的先进语义分割网络进行对比,实验结果如表1所示。

表1 不同裂缝数据集上模型性能指标对比
从表1 中可以看出,在CRACΚ500 测试集上测试,本文提出的方法明显优于现有的先进语义分割算法,平均IoU达到72.5%,F1score达到96.8%,能够对裂缝图像进行更好的分割,且相比UNet 与GCN 等方法参数更少,仅有1.66×107。在CRACΚ500数据集上训练的模型直接在CFD数据集上测试,本文方法取得了最高的IoU和F1score,平均IoU和F1score分别达到71.8%和95.2%,表明模型具有很好的泛化性能,可以推广到其他裂缝检测任务上。
图7 是本文方法与其他方法在CRACΚ500 测试集的预测结果对比,本文方法在分割裂缝时准确度更高,较少出现断裂和孔洞,对于图7中第三行的低对比度图像分割效果更好,而其他方法出现大量的误分类和漏分。
图8 是本文方法与UNet 和GCN 等算法在CFD 数据集上的测试结果比较,可以看出本文方法对裂缝分割效果更好,对于第三行图像中的断裂处能够正确分割,且较少出现误分和漏分,证明本文方法具有较好的通用性和可迁移性。
2.4 消融实验
为了验证本文方法中扩张率参数选取的合理性以及特征融合方式的有效性,在CRACΚ500 数据集上进行测试,特征融合方式包括逐像素相加(Sum)、通道拼接(Concat)和基于注意力的特征融合(AFF,本文方法)。表2 是在满足式(2)设计要求下,不同扩张率的卷积组合与特征融合方式在CRACΚ500 上的分割效果对比。{1,1,1}表示采用标准卷积提取特征。

图7 CRACΚ500测试集实验结果对比

图8 CFD数据集测试结果对比
由表2 可以看出,在卷积扩张率组合为{1,2,5}以及采用基于注意力机制的特征融合方式在CRACΚ500测试数据集上达到最高的交并比(IoU)与F1score 指标。由不同扩张率的组合实验可以看出,在加入了扩张卷积模块的情况下,随着扩张率的变化,此时特征图有效感受野扩大,图像能够接收到更多的上下文信息,丰富了高层特征中的语义信息,切实提高裂缝预测准确率,IoU 和F1score 随着感受野扩大而提高。此外,特征融合方式的对比实验结果表明,加入注意力特征融合模块之后,网络对于裂缝的分割效果普遍优于普通特征融合的分割方法,平均IoU和F1score最高提升了1.5个百分点以上,同时比通道拼接的特征融合方式参数上更优。
此外,为验证本文设计的多层扩张卷积模块与多通道特征融合模块对于裂缝检测性能的提升,需要进行模块之间的消融实验,实验结果对比见表3。
表3 为语义增强模块与多通道特征融合模块的消融实验结果。其中,对比实验0和实验1可知,语义增强模块在不增加参数量的情况下,平均IoU 提升了2.8 个百分点,F1score 提升了3.4 个百分点。对比实验0 和实验2 可知,采用多通道特征模块,平均IoU 提升了2.3 个百分点,F1score 提升了3.1 个百分点。对比实验0 和实验3 可知,语义增强模块和多通道特征模块的组合,相比最原始的网络平均IoU 最高提升了3.2 个百分点,F1score最高提升了3.6个百分点。综上所述,本文提出的语义增强模块与多通道特征融合模块均能提升裂缝检测性能,且组合起来能达到最优的检测精度与分割效果。
由上述实验结果可知,利用多层扩张卷积增大网络感受野,有效地增强了特征图的语义表征能力。同时本文提出的基于注意力机制的多通道特征融合模块,融合语义信息与图像细节特征,能够有效提高上采样后对于图像细节信息的修复效果,使生成的特征图更具有判别性,进一步提升了图像中裂缝的分割精度。
3 结束语
本文针对现有裂缝检测算法准确率低的问题,提出了一种新的裂缝自动检测算法。以编码器-解码器结构的全卷积分割网络为基础,设计了增强语义信息的多层扩张卷积模块以及基于注意力机制的多通道特征融合模块,从而有效融合语义信息和细节特征。在两个不同的裂缝数据集上进行了对比实验,结果表明本文方法有效提高了裂缝检测的准确率,能够稳健地在复杂场景的裂缝图像中检测出裂缝。在CRACΚ500 等数据集上获得更好的裂缝像素检测效果,评估指标达到72.5%的平均IoU 和96.8%的F1score,优于现有的先进方法。同时,在CrackForest数据集上的结果表明本文方法具有很好的泛化性能,可广泛用于裂缝图像的自动标注以及道路质量评估等实际场景中。

表2 扩张率与特征融合方式CRACΚ500测试集指标对比

表3 模块间消融实验结果对比
猜你喜欢
艺术家(2023年8期)2023-11-02 02:05:28
小哥白尼(军事科学)(2022年2期)2022-05-25 13:19:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
开放教育研究(2020年2期)2020-03-31 01:54:14
红领巾·萌芽(2019年8期)2019-08-27 15:30:15
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
现代语文(2016年21期)2016-05-25 13:13:44
CHIP新电脑(2016年3期)2016-03-10 14:22:03
大连民族大学学报(2015年2期)2015-02-27 08:28:11
