
深度学习在高分遥感图像场景分类中的应用
2021-05-26 03:14:20徐慧颖陈晓昊钱晓亮
计算机工程与应用 2021年10期
曾 黎,徐慧颖,陈晓昊,钱晓亮
郑州轻工业大学 电气信息工程学院,郑州450002
遥感成像技术的不断进步,使得获得各种分辨率(空间分辨率、光谱分辨率、辐射分辨率和时间分辨率)和更高质量的航空或卫星遥感图像成为可能,而这也对遥感图像的理解提出了更高的要求[1-2]。高分辨率遥感图像场景分类是根据图像内容[3-4]区分遥感图像的土地利用或覆盖类别,为其他遥感图像处理任务提供重要线索。此外,它在自然灾害监测、环境探测、交通监管、武器制导和城市规划等方面发挥着重要作用[5-11]。
早期的遥感图像场景分类方法基于手工特征,但手工特征在设计时需要大量相关领域的专业知识,且在应用时鲁棒性较差,这也成为限制其发展的原因。但随着深度学习的出现与发展[12-16],其由于强大的深层特征表示能力而逐渐取代手工特征成为场景分类的主流方法[17]。本文主要回顾与探讨基于深度学习的场景分类方法,并按监督方式对其归纳总结和综合评估。本文的主要贡献如下:
(1)依据监督方式的不同,对现有基于深度学习的高分遥感图像场景分类方法进行归纳总结和定性分析;
(2)在领域内三个公开的数据集上,对三种监督方式的流行方法进行了定量实验评估。
1 相关工作
1.1 早期遥感图像场景分类方法
深度学习兴起之前,高分遥感图像场景分类是基于手工特征的,其中以颜色直方图(Color Histograms,CH)、尺度不变特征转换(Scale Invariant Feature Transform,SIFT)、通用搜索树(Generalized Search Trees,GIST)等经典的手工特征为主。但由于手工特征在设计时需要大量的先验知识,费时费力,且效果较差,为了获得更高的场景分类精度,后续出现了手工编码特征。该类方法的主要思想是在手工特征的基础上对图像进行更进一步抽象。最为典型的手工编码特征是视觉词袋模型(Bag of Visual Words,BoVW)[18]。BoVW 首先对图像提取到的局部手工特征进行聚类,从而获得一个“词袋”,然后利用“词袋”对图像进行编码得到一个特征直方图,以此作为图像更高一层次的特征描述。大量的场景分类方法[19-23]采用BoVW 或BoVW 的改进模型。围绕BoVW 模型的改进工作主要包括空间金字塔匹配(Spatial Pyramid Μatching,SPΜ)[24]、稀疏编码空间金字塔匹配(Sparse Coding Spatial Pyramid Μatching,ScSPΜ)[25]等。虽然手工编码特征可以提高分类精度,但也受限于底层特征的上限,精度提升有限。因此在高分遥感图像场景分类任务中只利用底层特征会存在泛化能力弱、分类精度低等明显缺点。
1.2 深度神经网络概述
神经网络的概念是由1943 年人工神经元模型(ΜcCulloch-Pitts Neuron,ΜCP)启发得到的。随后Rosenblatt 在1958 年提出了感知器算法,并使用ΜCP 模型成功对多维数据进行了二分类,但后续实验表明该模型只能处理线性分类问题。直到1986 年神经网络之父Hinton发明了反向传播算法(Back Propagation,BP),并利用Sigmoid 进行非线性映射,使得非线性分类问题得到了解决。然而,此时的神经网络依然面临着梯度消失、训练网络耗时较长、难以进行局部最优等问题。
2006 年Hinton 和他的学生Salakhutdinov 在Science发表的文章[26]提出了深层网络训练中梯度消失问题的解决方案:首先利用无监督方式对网络进行预训练,使网络权重具有良好的初值,然后再利用有监督方式对网络进行更细致的优化,使网络性能进一步提升。随后ReLU激活函数、AlexNet[27]等一系列新技术和网络架构被提出,使深度神经网络真正受到了广泛的关注。
深度神经网络大致分为两类:一类是输入为一维向量的深度神经网络(Deep Neural Network,DNN);另一类是输入为二维图像或三通道彩色图像的DNN。前者的代表有深度置信网络(Deep Belief Network,DBN),后者的典型代表是卷积神经网络(Convolutional Neural Network,CNN)。
2 深度学习在遥感图像分类中的研究现状
基于深度学习的高分遥感图像场景分类方法按监督方式可分为三类:(1)全监督方法;(2)半监督方法;(3)弱监督方法。
2.1 基于全监督深度学习的遥感图像场景分类方法
全监督学习又称监督学习,是已知数据和其对应的标签,然后用于网络训练的一种方法。目前基于深度学习的高分遥感场景分类方法大多都可以归为全监督。
基于主题模型是一种有效的方法。Zhu等人[28]提出了一个自适应深度稀疏语义模型(Adaptive Deep Sparse Semantic Μodeling,ADSSΜ),将主题模型和卷积神经网络(CNN)相结合,充分利用遥感图像场景的多级语义,在语义层次上有效融合了稀疏主题特征和深层特征,有效提升了特征的表征能力,并以此达到更高的分类水准。其他基于主题模型的方法包括文献[29-31]提出的方法。
此外,Cheng等人[32]将深度学习与度量学习相结合,提出了一种新的损失函数来训练融合后的深层神经网络。该方法有效解决了遥感图像场景分类中类内多样性和类间相似性的问题,同时也极大提升了分类精度。
采用融合多层深层特征的方法来提高遥感图像场景分类精度也是一种常见的手段。Yuan 等人[33]意识到现有的CNN方法大多只利用最后一个全连接层的特征向量进行场景分类,而这一做法忽略了图像的局部信息。虽然有些图像具有相似的全局特征,但它们所属类别不同。原因是图像的类别可能与局部特征高度相关,而不是全局特征。因此首先提取深度神经网络最后一个卷积层和最后一个全连接层的特征分别作为局部特征和全局特征,然后利用聚类方法将全局特征聚类到多个集合中,再根据局部特征与聚类中心的相似度对局部特征进行重新排列,最后通过二者的融合得到最终能够同时表示全局和局部的遥感图像特征。其他融合多层次深层特征的方法包括文献[34-38]提出的方法。
除了上述针对特征层级做出的改进,Chen等人[39]使用带标记的数据集自动学习CNN 架构,从而获得可以适应不同类型数据的CNN网络。该方法的提出可以帮助理解哪些类型的特征对于遥感图像的智能理解是至关重要的。Zhang等人[40]将CNN和CapsNet结合起来用于场景分类,该方法综合了两种网络的优点,同时利用CNN 强大的特征提取能力和CapsNet 出色的特征融合与分类能力,使最终的分类结果相比单一网络而言得到有效提升。He等人[41]提出了一种新的跳跃连接协方差网络(Skip-Connected Covariance Network,SCCov)用于遥感图像场景分类。SCCov是在CNN中加入跳跃连接和协方差池化,减少了参数量,提升了分类性能。Zhu 等人[42]将视觉注意机制引入CNN,迫使CNN 将注意力集中在有区别的区域,同时利用融合后的深度特征与基于中心的交叉熵损失函数,从而显著提升了分类精度。
2.2 基于半监督深度学习的遥感图像场景分类方法
半监督学习可以利用大量无标签样本,因此对标签样本的需求减少[43],一定程度解决了深度学习领域中标签样本不足的问题。
Han 等人[44]从扩大标签样本规模角度出发,提出了基于半监督深度学习特征的生成框架,该框架可以通过训练,自动扩大标签样本的数量。首先利用带标签样本对预训练的CNN进行微调,再利用微调后的CNN提取到的深层特征训练支持向量机(Support Vector Μachine,SVΜ),然后利用训练好的SVΜ对无标签样本的类别进行预测,并将自动标注的样本加入到原标签样本中。以上步骤是迭代进行的。同时该方法将多个支持向量机联合应用于易混淆类别样本的标签识别,有效提高了标注精度与标签样本数量,从而使网络的泛化能力与分类精度得到有效提升。
将无监督用于特征学习阶段,从而建立起一个特征提取模型,然后利用标记样本训练分类器也是一种有效的半监督学习方法。Soto 等人[45]联合使用有标签和无标签的样本来训练生成式对抗网络(Generative Adversarial Networks,GAN),然后将训练好的鉴别器用于场景分类,此时鉴别器已具备大量无标签样本的信息,有助于最后分类效果的提升。相似的工作还有文献[46]。Zhang等人[47]利用从图像中提取的有代表性的显著性区域作为无标签样本去训练特征提取器,再利用该提取器提取待分类样本的特征,最后利用SVΜ 对提取到的特征进行分类。类似的做法还有文献[48-49]。
2.3 基于弱监督深度学习的遥感图像场景分类方法
弱监督和深度学习相结合的方法也被广泛应用。在高分遥感图像场景分类任务中弱监督通常利用与目标样本相似的带标签样本来训练场景分类模型。这种方法将数据集分为源域和目标域,前者不同于后者但相似,后者可以通过各种迁移学习技术获得标签,并进一步用于场景分类模型的训练。其中Othman等人[50]将有标签图像提取的特征作为源域,无标签图像提取到的特征作为目标域,然后将其用于网络训练并优化规定的损失函数,即可分类有标签和无标签数据。Gong等人[51]对深层结构度量学习(Deep Structural Μetric Learning,DSΜL)进一步改进,提出了多样性促进深度结构度量学习(Diversity-Promoting-DSΜL,D-DSΜL),减少了DSΜL产生的参数冗余,提高了特征表示能力。类似的工作还有文献[52-53]。
2.4 监督方式的定性对比
基于全监督的分类方法效果显著,分类精度高,但上述监督方法均需要大量的有标签样本来训练分类网络,而有标签的样本通常很难获取,给没有标签的图像打上标签需消耗大量的时间与精力,这限制了全监督方法的进一步发展。
基于半监督的分类方法可以利用大量无标签样本训练网络,使网络获得更多“额外”的信息,从而提升网络的鲁棒性。但只能利用无标签样本来细化由带标签样本所构造的特征空间,并没有显著增加判别信息,从而限制了分类精度。
基于弱监督的分类方法利用和目标域相近但不相同的数据进行网络训练,降低了对标记样本的需求,提升了网络的泛化能力。但由于不同域之间图像的本身差异,导致分类效果不如其他监督方式。
在这三种方法中,全监督方法的性能最好,但是训练阶段需要大量的标签样本。半监督方法虽然需要较少的标签样本,但未标记样本并没有显著增加网络分类能力。弱监督进一步减少了对目标数据标签样本的需求,但源域与目标域本身的差距难以弥补,致使网络分类精度难以得到有效提升。总之,对于基于深度学习的场景分类方法来说,拥有大量高质量的标签样本是非常重要的。
3 定量实验评估
3.1 数据集
本文采用UC Μerced[24]、Aerial Image Data(AID)[54]和NWPU-RESISC45[55]数据集对以上基于不同监督方式的深度学习方法进行对比实验。图1 为高分遥感图像场景的示例。

图1 两个场景类别的高分遥感图像及其标签
UC Μerced数据集由于提出时间较早,类别信息较为丰富,绝大多数的遥感图像场景分类方法都在该数据集上进行实验对比。该数据集是2010年由美国国家地质调查局提出,覆盖了美国多个地区,有21 个场景类别,每个类别有100张图像,共2 100张。每张图像大小为256×256,其空间分辨率为每个像素0.3 m。
AID 是武汉大学于2017 年提出的一种大规模的航空场景分类数据集。该数据集有10 000 张图像,共30个类别,每个类别的图像数量在220~420不等,每张图像的大小都是600×600,空间分辨率从8 m左右变化到0.5 m左右。这些图片来自世界各地不同的国家和地区,在不同的时间和成像条件下提取不同类型的图像,从而增加了图像的类内多样性。
NWPU-RESISC45 是由西北工业大学于2017 年提出,共包含31 500张图像,45个类别,每个类别有700张图像,每张图像的大小都是256×256。该数据集大部分场景类的空间分辨率从每像素30 m 左右到0.2 m 不等。该数据集场景类别丰富,类内多样性和类间相似性高,这对遥感图像场景分类更具挑战性。
3.2 实验设置
本节对上述基于不同监督方式的流行算法进行定量对比。由于监督方法的不同,不再以训练率为标准体现标签样本数量,而是以使用标签样本的具体数量来进行对比。
3.3 定量对比结果
实验部分,在UC Μerced、AID和NWPU-RESISC45三个公开数据集上对上述方法进行实验比对。表1 为在UC Μerced数据集上的实验结果,表2为在AID数据集上的实验结果,表3 为在NWPU-RESISC45 数据集上的实验结果。

表1 UC Μerced数据集总体精度的定量对比
由表1 可知,在训练样本数量一致的前提下,基于全监督的场景分类效果最好,但基于不同监督方式的深度学习遥感图像场景分类方法的结果差距较小。这是因为UC Μerced 数据集规模小,数据集本身分类难度较低,所以在规模较小的数据集或简单任务中利用半监督甚至弱监督的方法可以替代全监督方法,以此来减少对标记样本的需要,同时获得较高的分类精度。根据表2可知,在样本数量为2 000张时,两种监督方式的分类精度基本一致,这说明基于半监督的分类方式在采用了大量无标签样本后,弥补了由于标记样本缺乏带来的差距。但随着样本数量的增多,基于全监督的分类方法展示出了其优越性。因此在数据规模不断增大时,基于全监督的分类方法仍是首选。由表3 可知在更为复杂的NWPU-RESISC45数据集上,基于全监督的场景分类效果明显优于基于半监督的分类效果,这进一步证明了基于半监督的方法利用无标签样本来细化由带标签样本所构造的特征空间,并不能有效增加判别信息,从而限制了分类精度。因此在复杂度高,数据量大时,基于全监督的分类方法仍是首选。

表2 AID数据集总体精度的定量对比

表3 NWPU-RESISC45数据集总体精度的定量对比
根据实验对比结果可得到如下结论:(1)数据集规模较小或任务相对简单时,基于弱监督的高分遥感图像场景分类方法使用与目标相近但不相同的图像对网络进行初始训练,可以提升网络的泛化能力,从而获得与其他两种监督方式相差无几的分类精度。(2)基于半监督的场景分类方法得益于可以利用大量无标签图像信息以增强网络本身的鲁棒性,从而获得更高的分类精度。但在面临更为复杂的数据集以及实际分类任务时,基于全监督的分类方法仍是效果最佳的。
3.4 算法分析
表4 为高分遥感图像场景分类流行算法的特点总结,展示了各个算法的优缺点及适用场景。
由表1和表3可知,在UC Μerced数据集和NWPURESISC45数据集上分类精度最高的是ADSSΜ[28]框架。该算法利用主题模型将中层特征和深层特征相融合,获得了非常突出的效果,但由于训练方式不是端到端,同时需要不同的网络去提取中层和深层特征,增加了训练成本。在AID 数据集表现优异的深度卷积神经网络算法(Deep Convolutional Neural Network,D-CNN)[32]将度量学习和深度学习相结合,有效地解决了高分遥感数据类内多样性和类间相似性的问题,显著提升了分类精度。但该方法batch size为1,并使用批标准化层微调预训练的CNN模型,从而需要更多的训练和测试时间,同时会对硬件设备要求较高。
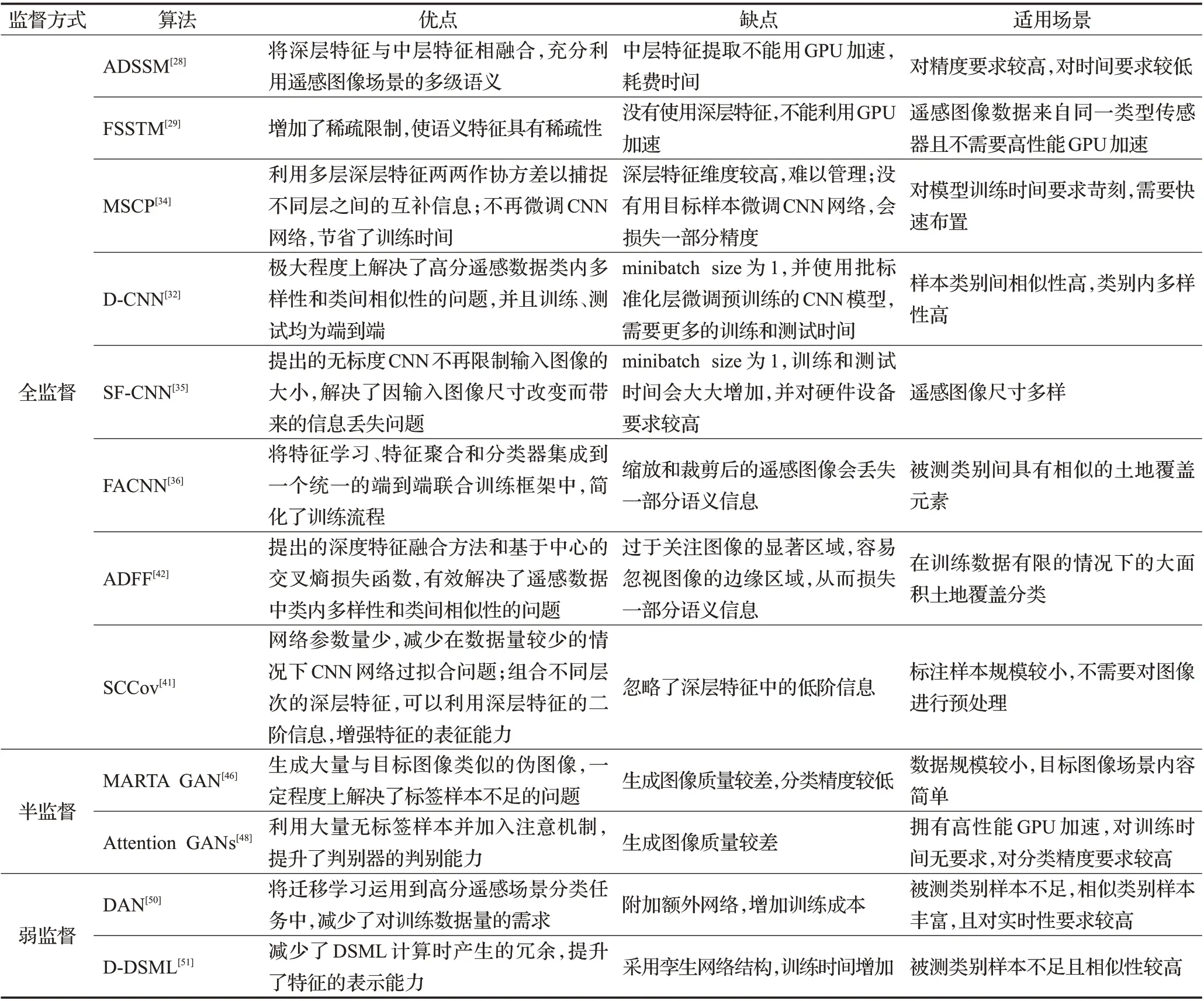
表4 高分遥感图像场景分类算法分析
由表4可知,基于全监督的高分遥感图像场景分类是主流,这一方面说明了基于全监督的方法效果显著,另一方面也反映了基于全监督的深度学习过度依赖标签样本的问题。而半监督与弱监督因监督方式的优势,可以在数据规模较小时解决样本数量不足的问题,并且通过对算法的改进与创新,能够获得与全监督方法相差无几的性能。但受限于目前深度学习对数据的依赖,后两种监督方式的效果在大型数据集和复杂的实际任务中依然弱于全监督方法。
4 结论与展望
本文首先对基于深度学习的高分遥感图像场景分类方法进行了分析与总结,然后按照监督方式对其进行分类,并从实验的角度对比验证了不同监督方式的优劣,得到的结论如下:(1)在某些复杂度较低的数据集上,基于弱监督的方式可以获得较好的结果;基于半监督的分类方法可以利用大量无标注样本信息,因此可以获得不低于基于全监督方法的分类性能。(2)基于深度学习的高分遥感图像场景分类任务中全监督的分类方式仍是主流,其性能优于其他两种监督方式。
随着深度学习的发展和大规模数据集的建立,使得高分遥感场景分类得到了长足发展,但对机器的理解水平和人类的表现之间仍然存在巨大的差距,因此在高分遥感场景分类任务中还有很多亟需改善的地方。本文通过对现有场景分类算法的研究,探讨了遥感图像场景分类的几个潜在发展方向。
(1)学习更好的区分特征。类间相似性和类内多样性一直是场景分类任务中的两个关键因素。由于一部分场景类别之间存在很大的相似性,如高尔夫球场和草地,另有一些场景类别内部多样性较多,特征之间差异较大,如飞机之间的不同颜色、大小、摆放位置等。为了解决上述问题,一些方法被提出,如将度量学习和CNN相结合,融合不同的CNN 网络。尽管这些方法可以有效地学习由CNN 提取的特征,但类别内差异较大和类别间可分性较小的问题仍未完全解决。未来,学习更多的区别性特征表示来应对挑战需要通过各种学习方式来解决,如对抗攻击等手段。
(2)扩大数据集的规模。现有高分遥感数据集往往包括几十种不同的类别,这远远少于人们可以区分的类别数量。并且现有数据集不足以充分拟合拥有上百万参数的CNN网络,因此大多数方法采用微调经ImageNet预训练过的CNN 网络,以此减少计算代价。但最理想的情况依然是采用大量的目标数据集从头训练CNN网络,从而提取出更符合目标域的特征。而数据集规模的扩大可以采用目前常用的生成模型,即对抗式生成网络(GAN)来实现,或直接通过高分遥感卫星获得大量高分遥感图像。
(3)采用无监督学习方式。目前基于深度学习的方法大都受限于有标签样本的数量,这是由于标注数据必须由专业人员手动标注,耗时耗力。在现有数据集规模较小时,采用无监督学习方式可以极大地缓解标记样本不足的问题。而GAN 作为一种有效的无监督学习方法,已被用于解决缺乏标签的场景分类问题[42,56]。因此,探索无监督学习在场景分类中的应用是非常有价值的。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
车迷(2018年11期)2018-08-30 03:20:32
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
海峡姐妹(2018年3期)2018-05-09 08:21:02
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
