
基于智能化公文主题分析的我国政策层级扩散倾向性研究
2021-05-26 09:08:00徐路路
情报学报 2021年4期
王 芳,徐路路
(南开大学商学院信息资源管理系,天津300071)
1 引言
政策,是一套用于指导政治、经济或商业决策的思想、原则或计划体系。公共政策,是指由政府机构或其代表颁布的关于特定主题的法律、监管措施、行动方针或资金优先权方案。2003年,Ander‐son[1]提出公共政策制定的周期一般包括五个阶段:①问题识别与议程设置;②政策提出;③政策采纳;④政策实施;⑤政策评估。其中,政策实施是指为使政策生效或问题得以解决而采取的行动。政策实施过程同时包含着政策的扩散。政策扩散既是政策实施的前提,也是政策实施的结果。1983年,Lucas[2]认为扩散过程渗透到政策决策过程中的频率远远高于公共政策被普遍接受的概率。目前,国外关于政策扩散的研究大多聚焦于地方政府间的横向学习和竞争[3]。在我国,政策扩散受自上而下政治权威的影响较大,中央政府在政策层级扩散中发挥着核心倡导者和推动者的作用。地方政府在领会和贯彻执行中央政策的过程中进行政策的部署、创新和发展。探测地方政府在传达和执行中央政策过程中的意愿、效果和创新,可以促进各级政府更加切实、有效地执行政策;同时,比较不同省市地区在政策扩散中的倾向性和区域部署,可以为政策创新与政府治理提供全方位、深层次、前瞻性的信息指引。
在政府体系内,公共政策通常以公文流转的形式进行传达,体现为法律、条例、规定以及公报、命令、决定、报告、通知、实施方案等。公文是行政机关为有效开展各类公务活动,传达贯彻国家方针、政策、决议而形成的具有特定法律效应的文种,具有权威性、准确性、规范性和前瞻性的特点。中央政府的政策类公文一般代表国家未来战略部署和对重点遴选领域的发展规划及指导意见[4]。公文与政令文件在不同层级政府间的传递可能伴随着政令主题变迁、政策失灵(如替换式失灵、象征式失灵及选择式失灵等)以及政策构件分解等问题[5]。根据文本特征和内容特征进行有效的政策解析,分析从中央到省部再到市区县的扩散过程中政策主题的演变,对于认识政策的垂直扩散规律具有重要意义,同时也为大数据时代政策扩散研究提供一种新思路、新视角。
2 研究回顾
一个政府的政策选择或创新会受到其他政府的影响。1966年,Crain[6]研究了创新在城市间的扩散之后,半个多世纪以来,科研人员围绕政策扩散的机制、形式、框架等内容展开了广泛研究。1983年,Rogers[7]对政策扩散的内涵、外延以及本质属性进行了界定和拓展,并指出政策扩散本质是社会成员利用某一渠道(公文、社交、指示等)实现沟通交流而形成机制创新和政策变迁的过程。2008年,Shipan等[8]提出,政策扩散是指在内外部压力之下,政策创新从一个政府传播到另一个政府的过程。除了水平政策扩散之外,由自上而下的压力而导致的垂直政策扩散也受到了学者们的关注,如Berry等[9]和Sugiyama[10]。在垂直扩散中,学习和竞争不再是政策扩散的关键要素,中央政府的核心作用更加明显。欧洲的公共政策研究通常侧重于将欧盟与国内政治的纵向联系作为政策变化的主要解释因素[11]。Kim等[12]基于2018年美国50个州的数据的研究发现,一项政策从州到其下属地方政府的纵向扩散取决于州的财政能力和地方政府的人事能力。
大量研究聚焦于政策扩散的时空演变规律。1971年,Brown等[13]运用案例分析方法揭示了美国公共政策扩散过程中的时空演变规律,发现政策扩散在时间维度上呈S形曲线分布,在空间维度上则呈现出明显的“层级效应”(先行后驱式)和“邻近效应”(区域扩散式)。1973年,Gray[14]对教育、公民福利等领域政策的扩散强度和扩散速度进行分析,并构建了公共政策扩散的评价模型。1994年,Berry[15]将政策扩散模式总结为:全国互动模型(The National Interaction Model)、区域扩散模型(The Regional Diffusion Model)、领 导-跟 进 模 型(Leader-Laggard Model)、垂直影响模型(Vertical Influence Models)。2007年,Karch[16]对政策扩散时空演变前期的发展进行了探究,多维度分析政策创新和扩散机制成因。2008年,Shipan等[8]总结了政策扩散的7个教训:政策扩散不只是相似政策的地理集聚;地方政府之间相互竞争;政府互相学习;政策扩散不总是有益的;在政策扩散中政治与政府能力十分重要;政策扩散取决于政策自身;去中心化对于政策扩散至关重要。2012年,周望[17]分析了中国“政策试验”实践中以“试验-推广”为基本特征的政策扩散过程,认为这一过程呈现为一个在多层级间互动的立体化网络,即水平扩散过程会受到政府层级结构的垂直性影响。针对政策扩散时空演变问题开展研究的学者还有Shimogawa等(2012,日本城市农村政策扩散分析)[18]、Gatrell(1984,空间扩散模型体系构建)[19]以及吴建南等(2007,中国政府创新扩散要素分析)[20]、孙慧(2017,中国地市级政策扩散分析)[21]等。
政策扩散机制和驱动因素也受到了较多关注。1969年,Walker[22]对美国各州创新政策的实施、发展和扩散过程进行了研究,指出州际信息网络是影响公共政策扩散的重要因素,该成果标志着政策创新与政策扩散理论的产生。Mintrom[23]认为,沟通网络及政策信息交流平台对政策传播发挥着重要推动作用。1990年,Berry等[24]指出,政策扩散演变过程受系统内部激励促进因素(经济、社会、历史等)和外部推动因素(政策创新、强制推动)的影响。2007年,Karch[16]总结了4种政策扩散的机制,并指出分析政策扩散现象时,需要关注地理邻近、模仿、效仿、竞争等因素。2009年,Marsh等[25]在学习、竞争、强制和模仿4种机制的基础上,指出在政策扩散过程中存在政策发展迁移和演变的现象。此外,2011年,Makse等[26]认为政策自身的复杂性、兼容性、可观察性、相对优势和可试验性对于其扩散也具有重要影响。2016年,张剑等[27]对科技成果转化政策的扩散机制进行了量化分析,发现不同类型(规划类、法律类等公共政策)的政策在扩散的强度、速度、广度和方向四个维度上有所不同。
综上所述,目前政治学、公共政策、国际关系、情报学以及区域政策分析等领域的学者,基于政策扩散的理论框架和研究假设,开展中国政策扩散的探索研究,取得了丰富的研究成果。同时,也存在一些问题。首先,中国政府结构和政令执行系统不同于欧美国家,在政策扩散与创新模式上存在较大差异,例如,美国政策试验多是单个州立法,通过之后各州自愿模仿和学习[28];而中国的政策实施过程多是中央主导开展试点,并进行自上而下的传达和执行,上级政府以意见、通知、命令等公文形式实现政策的逐级扩散,处于层级结构顶端的政策推动者有力保障了政策的实施和落实[29],因此,政策扩散模式更多为自上而下的层级式扩散。其次,国内研究大多关注政策扩散与区域经济、省(市)长年龄等变量间的相关关系,而对政策内容本身的扩散关注不足[30-31]。第三,相关研究多采用案例研究(如低保政策[32]、养老保险政策[33]以及行政审批制度[34]等)以及Berry提出的事件史分析方法(如文献[1-2,35])。案例研究方法有利于发现新的理论性要素,但是却无法有效识别多源异构大规模政策公文的主题信息,从而难以进行深层的政策主题统计分析。大数据背景下,基于海量政府公文的挖掘与探测成为政策研究关注的新兴领域[36-37],但是运用关键词词频统计、内容分析等传统文本分析方法无法准确揭示政策文本主题的演变与扩散情况[38-40]。因此,本文将根据我国政策扩散的特点,以大数据政策为例,运用文本挖掘方法深入文本内部识别政策文件的主题、侧重点以及扩散模式,通过对大规模政府公文的信息抽取与主题挖掘,多维度分析政策发布时间、布局数量、政策主题强度、执行部门数量等特征,提出一种基于多特征融合的政策扩散倾向性指标模型,对政策执行主体采纳特定政策的意愿程度进行量化分析。
3 分析框架
3.1 我国层级政府间的公文流转模式
目前,我国的政策制定体系为:中共中央办公厅、国务院办公厅及其组成部门负责领导全国党政机关工作,制定国家级政策条例和管理办法,而地方性法规政策的审定、批准及实施由各级地方政府完成。在政策传达过程中,各省、自治区、直辖市等政府部门承接中央决策与指令,通过部门协调、调研咨询等方式制定区域性指导政策,传达党中央和国务院的决定、通知、公告、意见及批复等信息;地区级行政单位根据本地的产业结构、社会需求、经济侧重点等开展具体的行政管理与公共服务。公文是政策信息的物理载体。公文流转体现了从中央到省部再到各地市的政策垂直扩散过程[41]。根据公文流转及公文使用特点,将政策类公文在三级行动主体间的流转架构图如图1所示。
3.2 我国政策层级扩散的分析框架
在本文中,政策层级扩散主要是指一项政策自上而下地、从中央到省部再到地市的垂直扩散过程。根据我国政策扩散的特点,将政策执行主体划分为中央、省(自治区、直辖市)、地市县三级行动主体,运用文本挖掘方法分析政策文件的要素构件及政策侧重点。同时,公共政策、法律政策以及产业政策等政策种类的不同对于政策制定和扩散有不同的影响,因此,本文需要根据特定公文文本的结构特征与要素特征,提出基于多特征要素融合的政策扩散倾向性探测指标模型,对政策执行主体执行特定政策的意愿程度进行分析。本文的总体分析框架如图2所示。

图1 我国政策公文层级流转架构图
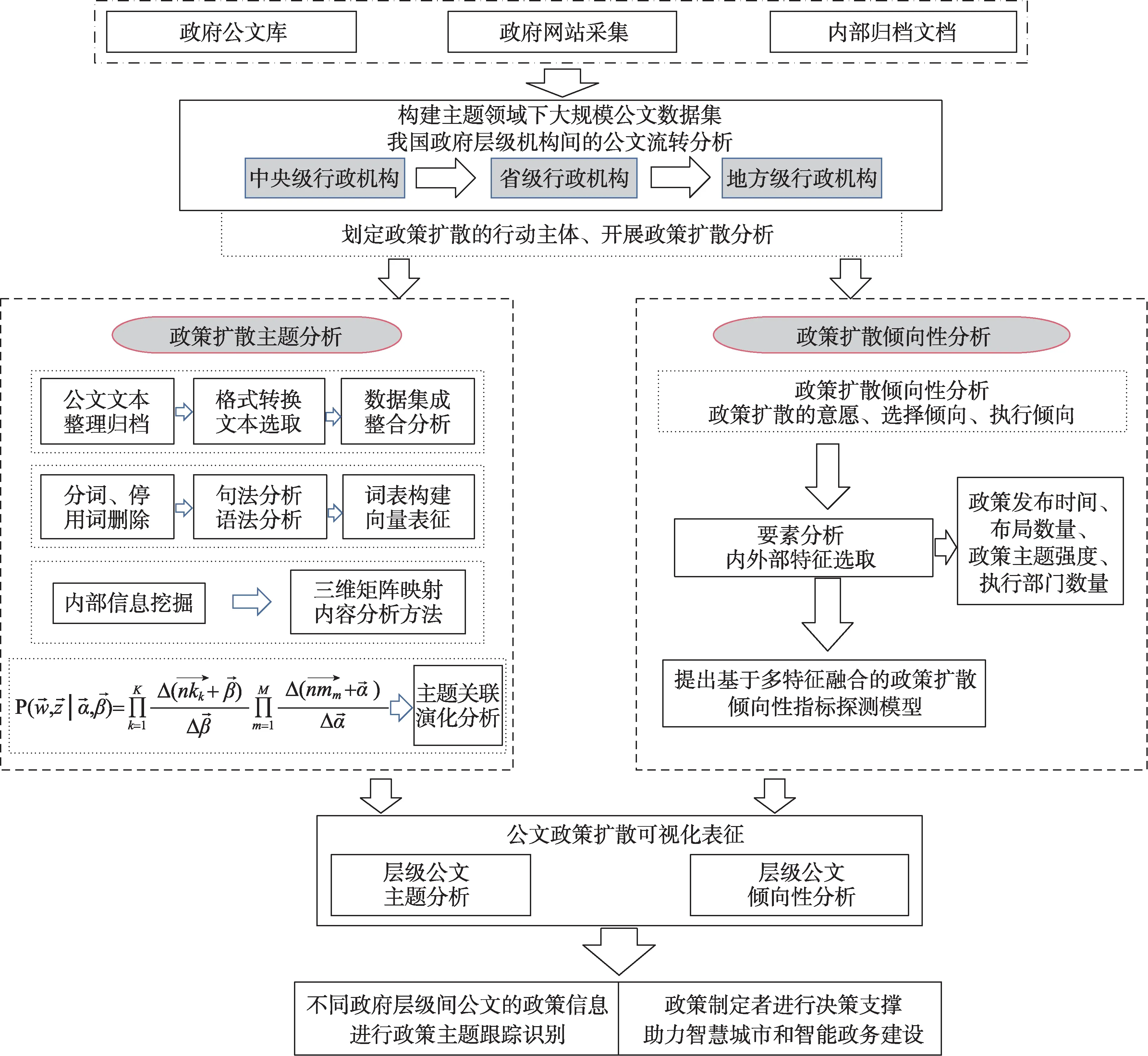
图2 政策层级扩散的分析架构
3.2.1政策扩散主题维度分析
本文采用主题概率模型对公文文本进行主题识别,分析我国政府从中央到省部再到地方的政策扩散过程和政令部署主题信息,揭示政策扩散的主题发展、继承、变迁等行为。LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,包含了词、主题和文档三层结构之间的多项式分布信息。作为一种非监督机器学习技术,LDA可以有效识别文档集或语料库中潜藏的主题信息[42-43],分析公文文本中的政策变迁与演变过程。LDA主题模型的联合分布概率可以表示为
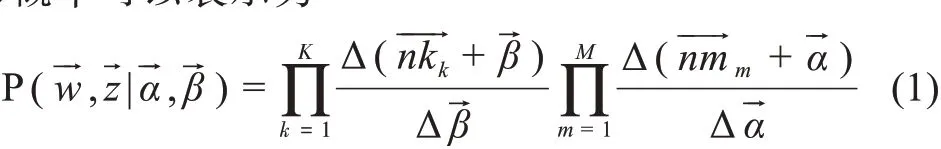
利用LDA模型可以得到文档-主题-主题词三维映射矩阵,通过计算中央与各省级单位、省级单位与地市级单位不同主题的相似度,可以构建不同行政级别上政策主题的关联路径,确定政策扩散的发展、创新与演进脉络关系。本文采用点积余弦相似度算法[44]计算政策主题相似度,以完成各机构政策主题的关联构建。
3.2.2 政策扩散的倾向性分析
政策扩散倾向性,是指特定行政主体执行与传播某一政策的意愿。就大数据政策而言,扩散倾向性分析是指对各级政府是否愿意围绕大数据主题开展一系列的政治经济布局,以及在大数据促进产业升级、提升政府治理效能等政策创新方面的能力和意愿进行量化研究。一个政府的政策扩散倾向性越强,越倾向于制定更多的政策文件、动员更广泛的政策执行单位。这一假设为量化分析特定行政机构的政策偏好和政策倾向性奠定了基础。目前,主要的量化分析方法有Walker[22]的政策扩散指数、Dye等[45]的政策采纳模型、Savage[46]的政策创新指数等,但上述模型仅仅考虑政策发布时间或数量等单一维度,未对政策扩散倾向性进行多尺度描述和分析。因此,本文尝试构建基于多特征融合的政策扩散倾向性指标模型(Policy Diffusion Tendency In‐dex,PDTI),从政策发布时间、政策布局数量、政策主题强度、执行部门数量等多个维度,综合量化行政部门的政策执行意愿,其中,α、β、γ、θ分别为调谐系数,各参量设置为

1)政策发布时间指标(Policy Release Time In‐dex,PRTI)
研究假设:政策发布时间体现出某一行政单位对上级政策的响应能力和重视程度。政策发布需要专家论证和领导班子研讨确定,发布时间越早表示该政府对上级政策的认同越大,对于该领域的政策部署越重视,后续相关政策的扩散及发展演进的倾向性也越大。借鉴Walker[22]提出的CIS指数(Com‐posite Innovation Score,政策创新指数),本文提出量化政策发布时间的PRTI指标,具体为

其中,Ti表示某层级政府单位发布该主题下某一政策的时间,i取值为0到j之间,j表示某单位该主题下政策的数量;Ts表示公文集中该主题下政策发布的最早时间;Te表示公文集中该主题下的政策发布的最晚时间;M为同一层级政府单位的数量;PRTI指标反映了某省市单一行政主体的政策发布时间,该值越大表示政策单位越重视、倾向性越大;APRTI指标表示同级别政府单位政策发布时间指标的平均值。
2)政策布局指标(Policy Layout Index,PLI)
研究假设:政策布局指标表示某层级政府围绕特定主题展开的政策布局和规划情况,包括制定一定数量的通知、公告及批复等公文。该指标反映了该层级政府的布局强度和布局决心,PLI越大表示政府进行了充分的政策分析和战略布局规划,相关产业后续的资金投入和行政管理也会相应加大,政策执行倾向性越大。政策布局指标制定为

其中,Topici表示某政策主题下某一层级单位相关的政策布局数量为i,i取值范围为0到j,j为政策布局的总数量;M为同一层级政府单位的数量;APLI是对PLI的均值化处理,可以探测同一层级单位政策布局指标的平均水平。
3)政策主题强度指标(Policy Topic Intensity Index,PTII)
研究假设:政策主题强度指标反映一段时间内公文文本数据源所呈现出的政策热度、政策关注度等信息,政策主题强度越大表示该段时间内政府围绕该主题的政策研究和政策创新投入的资金和精力越大,后续执行也具有更强的意愿和主动性。政策主题强度指标制定为
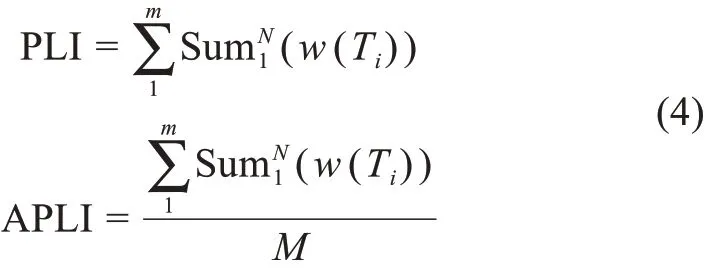
其中,w(Ti)表示T主题下的第i个主题词的权重;N表示该主题T下的主题词的个数;m表示某一层级单位下的公文数量;PLI则表示某一层级行政单位的所有公文所体现出的主题强度值;APLI是PLI的均值处理,表示各个政府单位的平均主题强度值。
4)邻近机构政策引导力指标(Neighbor Institu‐tions Policy Guidance Index,NIPGI)
研究假设:邻近省(市)的政策执行与创新状况会对本省(市)政策的执行和创新造成压力,地理位置因素显著影响政策扩散[15,47]。如果某一行政机构领先于邻近机构实现某项政策的制定和规划,那么该机构具有更强的政策引导力;若某省政策扩散行为晚于所有邻近省份,则认为其政策引导力为零。同理,假如A省的邻近政府都采纳该政策,B省的邻近政府尚未采纳该政策,即使A与B同时发布相关后续政策,本文仍认为B省具有更强的政策引导力。在已有研究基础[15]上,本文提出邻近机构政策引导力指标以考虑地理位置因素的影响,邻近机构政策引导力指标制定为
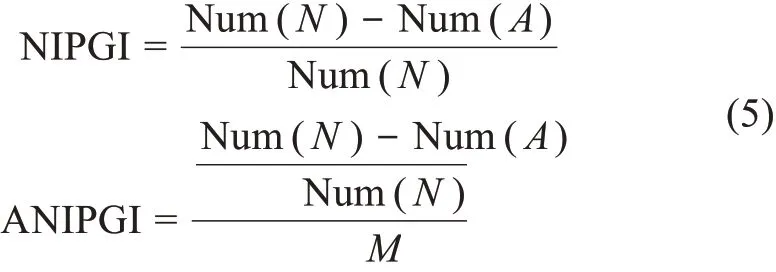
其中,Num(N)表示与某一层级特定政府机构相邻的机构的数量;Num(A)表示与某一层级政府机构相邻且已采纳某一政策的机构数量。二者比值反映了该机构对于邻近机构的政策辐射和引领作用,ANIPGI表示各单位指标的平均值以反映平均水平。该指标融合地理信息特征,可以更好地刻画群体性行政机构的政策扩散特征。
5)政策执行机构数指标(Amount of Policy Im‐plementing Agencies Index,APIAI)
研究假设:政策的有效执行和实施是后续相关政策制定的基础,政策反馈是实现政策扩散和区域演进的条件[48],政策执行机构数量越多,表示该层级行政单位下属各部门及各事业单位围绕该政策进行的合作越有效,政策的反馈机制和反馈效果越好,也表明该层级单位政策扩散和政策创新的决心。政策执行机构数指标制定为

其中,n(topic)表示某层级政府中关于某一主题政策的执行机构数量,该数值可以利用人工字符串匹配方法实现特定机构名称的抽取,共有m个主题则可求得某一层级单位的政策执行机构总数;ANPIAI为NPIAI的均值处理,代表大数据政策背景下同一层级不同行政单位的执行数量的平均值。
Strang[49]认为,政策扩散是指采纳某种行动或政策的地区改变未采纳地区的过程,而地理邻近位置是影响区域政策扩散的重要因素。同时,同级政策执行机构的广泛参与是政策扩散的试金石和政策创新演进的再生驱动力,有助于完善政策扩散的反馈机制。因此,本文在所构建的基于多特征融合的政策扩散倾向性指标模型中给予指标NIPGI和API‐AI较大权重,以更好地描述和表达该指标在政策扩散倾向性量化中的作用。
3.3 政策扩散的可视化表征
在政策扩散过程中,不同政府的政策公文传达的信息和主题并不完全相同。各地区根据本地区产业结构、经济模式等特点制定的政策,呈现出创新、发展及演进等特征。如何把握我国不同层级政府之间的政策扩散规律、探索政策内容本身的发展演进过程对于提升我国政府治理效能具有重要意义。
为清晰表达层级政府间政策扩散的规律,基于上述步骤识别出的政策主题结果和行政单位的政策扩散倾向性指标模型,基于Javascript语言的Web前端可视化技术设计一种政策扩散的可视化图谱,具体如图3所示。
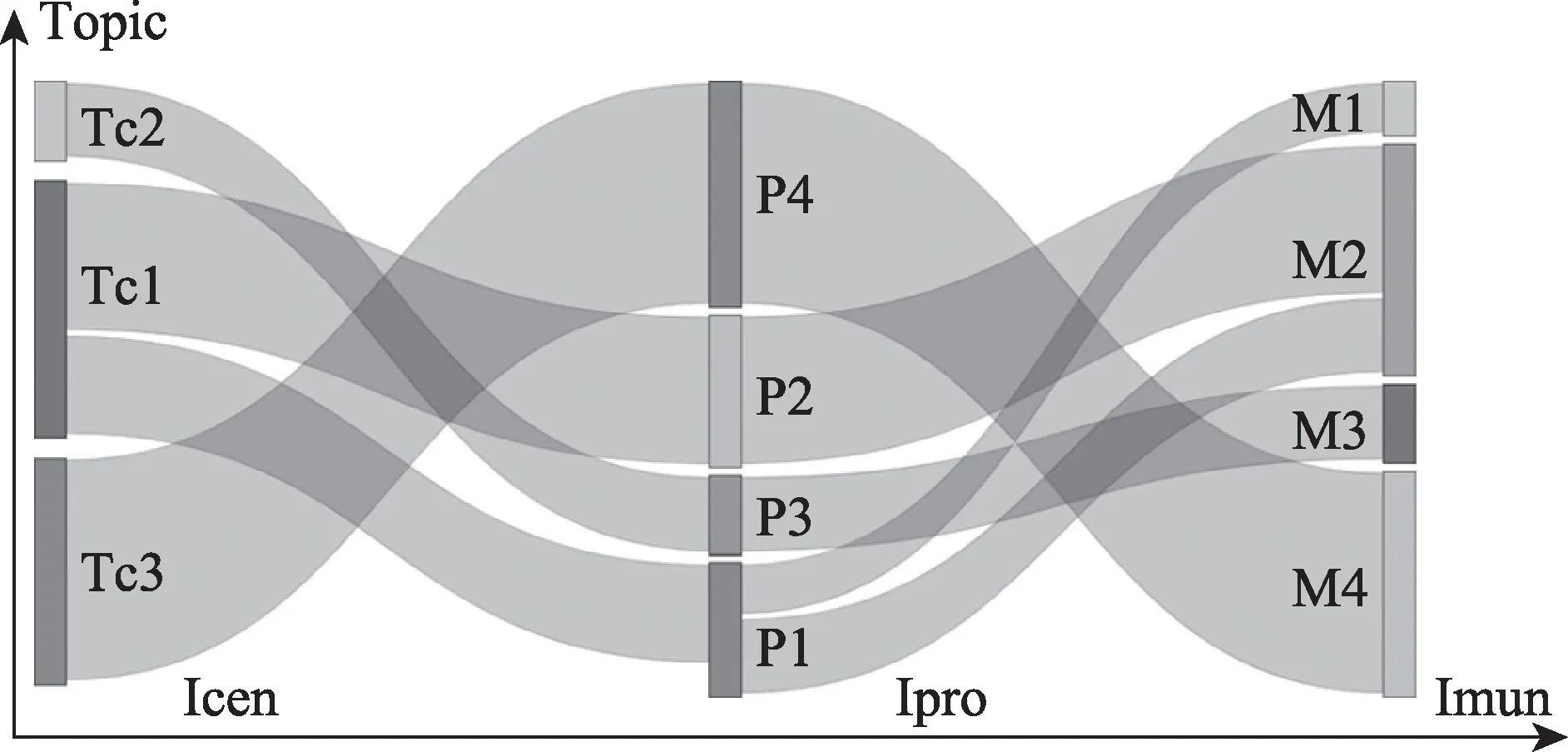
图3 层级政策扩散示意图
图3 中,横轴表示我国政府从中央到地方的三级 行 政 机 构INS(Institution),INS={Icen,Ipro,Imun}分别表示中央机构(center)、省级机构(province)和地方机构(municipal),P1、P2、P3表示各省级机构,M1、M2、M3等表示各地方机构;纵轴表示大数据领域政策主题Topic,分别含有{Tc1,Tc2,Tc3}等多个政策子主题,灰色连接表示政策主题的扩散路径,其粗细由点积余弦相似度算法求得,帮助政策制定者从宏观角度把握层级政府间政策主题的扩散路径,了解地域差异,并掌握政策文本的前继和后驱演化规律。
4 实验分析
4.1 实验环境和数据集获取
(1)硬件:Windows10操作系统、i5-4590 CPU、500G HardDrive。
(2)软件:scrapy抓取框架、pycharm、Knime、Gensim库 以 及D3等 工 具。
(3)数据集:2015年8月,国务院印发《促进大数据发展行动纲要》(国发[2015]50号),标志着大数据成为国家级的发展战略[50]。之后,国家发改委、环保部及各省市地方等推出关于大数据的发展意见和方案,大数据产业投入和应用场景建设逐渐展开。本文的主要研究政策由中央到地方的扩散过程,故剔除含有“请示”“报告”“函”等明显标志上行文及平行文的公文类型。以2015年为时间起始点,利用scrapy爬虫框架爬取中央及地方政府网站中标题含有“大数据”字段的政府公文,结合公文库获取等途径共获得有效公文数据535条。
4.2 政策文本主题识别与关联构建
4.2.1 参数设置与复杂度计算
实验采用Gensim中的LDA主题概率识别方法识别项目文本主题,LDA参数决定主题随机抽取数量、平滑系数、单词分配主题的概率和识别效率。经实验,设置文档-主题分布θ的参数α设为0.4,主题-主题词矩阵分布参数β设为0.1,采用Gibbs Sampling估计模型的后验参数,主题识别效果较好。主题识别需确定公文信息数据的主题数目。复杂度(Perplexity)是衡量一个语言模型优劣常用的一个指标,定义一个有M篇文档的文档集的主题模型的复杂度为
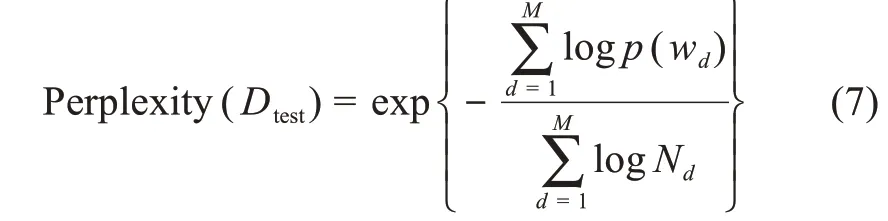
当困惑度取值最小时,主题未出现冗余且具有较好的拟合效果,由此建立主题-文档的映射关系及主题数。本文对中央政策主题数目及复杂度动态对应关系进行实验,在其他参数如上述表达情况下,文档主题数设置区间为[10,200],步进单位为25,得到主题数选择10时最优。
4.2.2 主题表征与关联构建
利用LDA主题识别模型可以得到文档-主题映射与主题-主题词映射关系,将中央大数据政策与省级、地市等公文文本分别进行主题模型试验。其中,中央公文主题设置为10,有10个主题词,省市级文件主题利用复杂度计算确定其主题数量。主题-主题词映射关系可以根据权重大小表征文本内容,采用余弦相似定理构建中央-省(自治区、直辖市)-地市三级政策单位的10个主题扩散关系,确定政策主题演进的前继、后驱关系。最后,可得到我国大数据领域政策主题在公文流程中的变化情况。表1列举了大数据领域国务院及其所属部门发布政策的10个子主题,主要包括金融、大数据区域试点、医疗、农业、信用监管以及城市设施建设和智慧城市等10个方面。表2列举了中央及各地方大数据领域政策中某一主题的主题词及权重值情况。以农业子主题为例,国务院等中央级单位主要从宏观角度围绕开展大数据农业应用、农业技能培训等主题展开,贵州作为省级单位传达中央信息政策并在大数据+农业方法展开规划,六盘水市大数据政策开展早于其他城市,建立大数据应用中心观摩点、推行云长制度、建立安全保障体系等具体工作;黔南州政府作为市级单位出现了“小镇”“编制”等主题词,结合公文内容可以得到该市发布的《关于扶持百鸟河数字小镇加快发展的政策措施》,以及建立黔南州大数据管理局并对人员编制进行了详细规定。本文利用LDA主题模型识别政策主题信息,并利用相似度计算建立不同层级政策主题之间的关联,设定阈值0.4,相似度大于0.4,即判定该层级单位主题与上一层级单位的政策扩散主题关联。

表2 政策主题-主题词表征(部分)
4.3 政策扩散主题可视化分析
按照上述研究流程及实验可知,我国大数据领域政策的主题分布以及政策主题在中央级别、省级及地市级三级行政单位的扩散情况。为揭示政策主题在不同机构间的扩散规律,本文基于Javascript语言的Web前端可视化技术,设计一种我国层级政府间的政策扩散可视化图谱。如图3所示,右侧一列Tc金融、Tc医疗、Tc农业、Tc政府平台等分别表示中央大数据政策的子主题,不同颜色的元素块大小与主题强度成正比,与表1中Topic1、Topic3、Topic4、Topic5等主题词一一对应;第二列表示我国部分省、自治区、直辖市等二级行政机构;第三列Tp监管、Tp城市设施等表示由二级行政机构向三级行政机构(市、州及地方行政公署等)扩散的主题;最后一列为发布大数据政策的城市(包括省会城市)主题分布情况。图4中灰色连线表示政策扩散的过程,线条粗细与主题强度成正比。该可视化图谱可以帮助政策制定者从宏观角度了解我国政策主题的扩散演进。
4.3.1 中央到省级单位的政策扩散主题分析

图4 层级公文政策扩散主题可视化(部分)
在从中央到地方的政策扩散过程中,各省、直辖市、自治区根据本地区的经济状况、产业特色制定不同的政策方针和重点发展方向,呈现出不同的政策主题分布。本文提出主题扩散比(即某一政府或行政单位所发布政策的子主题强度值与总主题的比值)概念,用于研究大数据政策扩散到不同省份时的主题分布情况,该指标可有效表达该地区的政策重点主题及占比情况。统计分析见附录1(前15个省级单位),加黑斜体的主题值表示各省级单位主题扩散比前3位的主题,即各省围绕大数据政策主要展开部署的具体主题。研究结果发现:①贵州(Topic2、Topic5、Topic7)是大数据政策开展最充分的省份,重点关注方向为:大数据试点区域建立、政府平台建设、设施、制度标准等;②广东(Topic1、Topic3、Topic6)重点围绕金融投资领域、市场监督与大数据医疗等热点方向展开政策发展;③上海(Topic1、Topic2、Topic5)更关注政府系统、云平台、云存储以及试点区域示范等基础性工作,为后续大数据在各领域各产业的有效融合打下基础;④河南(Topic1、Topic4、Topic6)主要对大数据与新型农业、农业信息化以及金融等领域的融合进行了政策引导与制定;⑤内蒙古自治区对大数据在农业和旅游方面的应用投入较多关注;⑥海南省在大数据提升旅游服务方面的政策倾斜尤为明显,可以推测海南省对于旅游服务和精准服务有着很大的政策需求。总体来看,各省份对大数据与农业、医疗、金融等领域的融合及示范区建设关注较多,但对与生态环境、气象等领域的融合的关注度有待于进一步提升。
基于Javascript语言的Web前端可视化技术,对我国31个省级行政单位与大数据政策主题间的扩散演进关系进行了可视化,可清晰表达大数据在省级行政单位的主题扩散关系,具体如图5所示。
4.3.2 省级到市级单位的政策扩散主题分析
从省级到市级政府的政策扩散主题分析,可揭示我国地方政府大数据政策的部署情况,充分反映我国政策扩散的主题分布特点。市级单位作为我国自上而下政策扩散的第三层行政单位,往往是具体政策的实践者和执行者。不同于中央政策统筹兼顾的特点和省级政府多领域、多主题协同发展的特点,市级单位往往按照省政府的政策规划和指示,围绕特定领域特定主题下的政策开展具体工作。因此,了解市级单位对具体政策的执行情况对上级政府制定下一步规划方针具有重要意义,同时,对于市级单位政策主题内容的揭示也有助于人民群众更好地监督政府,使政策内容落到实处。
本文选取贵州和广州作为典型省份,进行省级到市级政策扩散的分析。如图6所示,左侧元素块表示省级行政单位(贵州省、广东省),中间元素块表示政策扩散主题,灰色连线粗细表示主题强度大小,右侧表示各个市级单位。由图6可见,贵阳市在大数据方面表现卓越,主要承接省里政府平台建设、政策示范区试点、城市设施建设以及智慧城市发展等任务,六盘水市在示范区建设、大数据气象及医疗等领域具有一定的部署,铜仁、安顺等其他5个城市均在大数据政策方面进行了一定的规划;广东的市级单位中表现比较好的有深圳、梅州和清远3个城市,其中深圳市在大数据金融领域表现突出,这也与深圳作为国家经济特区的地位有关,而梅州、东莞、清远、江门、惠州等多个市级单位均在大数据领域积极展开战略部署,说明广东省的大数据政策推动较好。

图5 我国中央到省级政策扩散的主题可视化
4.4 政策扩散意愿倾向性计算与分析
利用本文提出的PDTI模型对不同层级行政机构的政策扩散倾向性进行计算,多维度考量政策发布时间、地理邻近机构以及执行部门数量等特征要素,综合分析特定行政机构对于特定政策的扩散意愿和倾向性。
4.4.1 PDTI的分指标计算
计算我国31个省级行政机构(除港、澳、台)在PDTI模型中的PRTI、APRTI、PLI、APLI、PTII、APTII、NIPGI、ANIPGI、APIAI、AAPIAI等10个分指标,具体结果如附录2所示。研究结果发现:
(1)PRTI指标靠前的省份有辽宁、湖南、新疆、甘肃、广东、北京等,其对中央大数据政策发布动态较为关注,相关政策发布的时间也比较早;
(2)贵州、上海、四川、甘肃等地的PLI值较大,表示这些省份对大数据相关政策具有较强的布局规划,发展大数据产业的倾向性显著;
(3)上海、山东、重庆、广东等地的NIPGI值均为1,表示对邻近省份的政策扩散影响力较大,在区域内发挥着引领和带头作用,而西藏、内蒙古、吉林、江苏等地的NIPGI值为0,表示该省份大数据政策制定时间晚于所有周围省份;
(4)PTII招标可深入政策文本内容进行主题挖掘,APIAI指标可对机构单位进行正则抽取,以反映政策内容本身的特点。结果显示,贵州、广东、河南等地具有较大的PTII值,而贵州、甘肃、上海、内蒙古等地的APIAI值靠前,表示政策执行的反馈机制更加充分。
4.4.2 省级政府政策扩散倾向性计算
通过分析政策文本的外部属性和内容主题特征,可以全面探测各级政府政策扩散的意愿和倾向性。基于第3.2.2节的分析和已有研究,本文对PD‐TI模型中α、β、γ、θ这4个调谐系数进行设置,最终5个分指标的权重值分别为0.15、0.15、0.15、0.30、0.25。对5个分指标进行加权整合,最终得到我国层级政府机构政策扩散倾向性的计算值。总体来看,我国省级政府在大数据政策方面的扩散倾向热度呈分散式特点,由点及面,统筹部署。各省级政府分析如下:
(1)贵州(PDTI=3.50)、上海(PDTI=2.23)、甘肃(PDTI=2.00)和广州(PDTI=1.79)对于大数据扩散倾向性最为显著,表现出政府在发展大数据产业方面的决心和政策倾向;

图6 贵州省和广东省的省级到市级政策扩散的主题可视化
(2)山东(PDTI=1.21)、重庆(PDTI=1.27)、湖北(PDTI=1.22)具有较强的政策扩散意愿,计划投入一定的资金和技术围绕大数据领域展开政策部署;
(3)四川(PDTI=1.03)、陕西(PDTI=1.00)、内蒙古(PDTI=0.91)和河北(PDTI=0.93)等绝大多数省份处于稳定的政策扩散和执行状态,未表现出明显的规划重点;
(4)西藏、黑龙江、广西以及云南等地则对大数据政策的扩散意愿不够强烈,政策扩散倾向性有待于提高。
4.4.3 市级机构政策扩散倾向性计算
市级政府作为特定政策的基层执行单位对于政策扩散至关重要。为有效表达我国市级政府在大数据政策扩散中的倾向性,本文结合地理信息与多要素分析雷达图,对市级政府展开分析,具体如图7所示。选取市政府较多,并且在PDTI模型中呈现不同特点的省份作为分析对象,包括贵州、山西、广东和河北4个省份。研究结果发现:
(1)贵阳市在贵州省大数据政策中处于绝对核心地位,在政策制定时间指标、布局指标、邻近地域影响等PDTI的5个分指标中均表现良好,六盘水市(PDTI=1.57)各要素表现均衡,铜仁市在NIPGI指标表现较好,体现出较强的邻近地理政策带动作用,黔西南布依族苗族自治州大数据政策制定时间较早,但后续在政策部署和政策制定上没有进行有效开展,在其他要素指标上得分较低,因而PDTI较低,大数据政策扩散倾向性较差。

图7 我国市级机构政策扩散倾向性可视化
(2)山西省有6个市级单位制定了大数据相关政策,包括阳泉市、吕梁市、大同市以及忻州市等。其中,阳泉市部署时间较早,吕梁市则在政策布局数量上较为充分,大同及忻州体现出较强的主题强度,临汾和晋城在邻近地域引导力指标上表现良好。总体来看,山西省各市在各指标要素上呈现不均衡特点,因此总体表现一般。
(3)广东省有12个市围绕大数据展开政策部署。其中,深圳、惠州等表现突出,深圳主题强度指标较大,政府涉及面广泛,惠州、韶关以及梅州等市在政策布局数量上较多。
(4)河北省石家庄、邯郸等表现出较强的政策扩散倾向。
5 结论与讨论
本文在分析我国政策文本结构和内容特征属性的基础上,利用LDA等文本挖掘方法分析政策在不同层级政府间扩散过程中的主题变迁,以揭示我国各级政府在政策扩散过程中的倾向性和特点,了解不同层级政府对于大数据政策的发展规划、侧重主题和区域部署,对于加强地域间合作、同主题方向下的政策学习提供了事实基础和方法论指导;利用可视化技术表达从中央到省级、地市级政策扩散过程中的主题变迁。同时,构建了包括政策发布时间、布局数量、政策主题强度、执行部门数量等指标在内的政策扩散倾向性指标探测模型,以刻画各个行政机构的意愿程度,对于除大数据政策之外的其他政策扩散研究也具有适用性。以大数据政策为例的研究得到如下研究发现:
(1)国务院及其所属部门发布的大数据政策主要包括10个子主题:金融、大数据区域试点、医疗、农业、信用监管以及城市设施建设和智慧城市等。
(2)在自上而下的政策扩散过程中,中央政府部门主要进行宏观指导,省级政府对各地市所承担的具体任务进行任务分配和重点部署,而地市级政府则主要承担试点建设、具体制度创新和人员编制等具体政策的细化制定和实施。
(3)在从中央到地方的政策扩散过程中,各省份根据本地区的经济发展水平和产业特色制定重点发展方向,政策呈现出不同的主题类型,例如,贵州侧重大数据平台与制度建设,广东侧重金融投资大数据,上海侧重政府平台与云存储,河南侧重农业大数据,内蒙古侧重农业和旅游大数据,海南侧重旅游大数据,等等。
(4)大数据政策扩散倾向性靠前的省份有贵州、上海、甘肃和广州;接下来是山东、重庆和湖北,计划在大数据领域投入一定的资金和技术;四川、陕西、内蒙古以及河北等绝大多数省份处于稳定执行状态,未表现出明显的规划侧重和重点意愿;而西藏、黑龙江、广西以及云南等地则对大数据政策的总体扩散意愿不强烈。
(5)就各分指标而言,辽宁、湖南、新疆、甘肃、广东和北京的政策发布时间较早,但有些省份后续的政策创新并没有跟上;贵州、上海、四川、甘肃等地具有更充分的布局规划,发展大数据相关产业的意愿强烈;上海、山东、重庆、广东对邻近省份的政策影响力较强,而西藏、内蒙古、吉林及江苏等地则影响力较弱;贵州、甘肃、上海、内蒙古等地的政策反馈机制更加充分。
由于受研究目标和文章篇幅所限,本文的研究局限有三方面:①由于本文的研究目标为政策文本的智能化分析,但是仅依靠文本分析难以充分揭示政策制定过程中的情境性因素和因果关系;②本文只分析了大数据政策一种政策类型,难以揭示不同类型政策扩散的差异;③本文所提出的政策扩散主题识别方法有待进一步改善与提高,在政策扩散倾向性分析中指标挖掘与制定不够全面,未来将进一步结合公共管理、政策研究等相关领域的研究成果进行指标的融合与扩展,以提高探测模型的准确性与科学性。
未来本研究组将继续推进以下三方面的研究:首先,主题概率模型在政策文本挖掘中力度较为不足,不同于论文、专利等主题特征明显的文本数据,纲领性的政策文本常常提及多个主题领域的内容,因此,为了更加准确和科学地识别政策主题内容,后续研究将对政策文本进行结构分解和功能识别,结合篇章语义技术对特定主题下同一篇政策文本的内容进行细粒度的拆解和分析。其次,本文侧重于分析政策在不同层级政府间的扩散问题,下一步研究将结合因果推断(如双重差分法、断点回归法等方法)分析扩散过程中的驱动因素与驱动机制,寻找不同类型政策扩散的内部驱动力。最后,本文选择特定领域的政策扩散为研究对象,未来将进一步研究县级、乡镇等行政机构对不同类型政策的扩散和推进。同时,本文仅仅分析了从中央到地方自上而下的政策扩散研究,未来将继续研究自下而上式扩散以及同级政府间的政策模仿机制,从而更加全面地揭示政策的扩散和演进机制。

附录1我国省级行政单位主题扩散比分析(前15位)

附录2基于多特征融合的政策扩散倾向性指标模型计算
猜你喜欢
房地产导刊(2022年8期)2022-10-09 06:19:34
房地产导刊(2022年6期)2022-06-16 01:28:40
有色金属(矿山部分)(2021年4期)2021-08-30 06:10:42
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
非公有制企业党建(2020年2期)2020-03-08 08:03:56
华人时刊(2019年21期)2019-11-17 08:25:07
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
新闻研究导刊(2015年17期)2015-12-25 12:36:42
语言与翻译(2015年4期)2015-07-18 11:07:43
