
基于关联规则的网络信息数据挖掘方法
2021-05-25 10:04:18王润芳丁晓敏
科学技术创新 2021年11期
王润芳 丁晓敏
(长春工业大学人文信息学院 信息工程系,吉林 长春130122)
数据挖掘是一种利用分类、聚类、关联分析等多种方式对数据进行分析和处理的重要手段,当前信息技术和存储技术的发展,使得各行业拥有的数据信息量不断增加,而数据挖掘的应用需求逐渐凸显[1]。当前传统数据库已经无法实现对隐藏在海量数据当中的相关内容进行挖掘,因此造成了数据海量却缺乏信息的现象产生[2]。基于此,为了提升数据挖掘的实际应用效果,本文开展基于关联规则的网络信息数据挖掘方法研究。
1 网络信息数据挖掘方法设计
1.1 基于关联规则的数据挖掘规则设计
在对网络环境当中的信息数据进行挖掘时,设置数据挖掘规则的主要目的是找出在海量数据集当中的频繁事务,即频繁项集。关联规则是一种以增长趋势为主要形式的挖掘算法。本文结合关联规则,对网络信息数据挖掘规则进行设计[3]。在进行网络信息数据挖掘时,需要经历两次网络数据库。第一次,在开始挖掘阶段,对候选集进行挖掘。在这一阶段中,生成的单项频繁项集即为挖掘出的结果。第二次,在挖掘候选集的过程中对原本复杂程度较高的挖掘数据进行优化,以此缓解挖掘执行过程中的压力。具体挖掘规则为:
首先,将选取的待挖掘样本进行分块处理,并将处理后的结果输入到集群的各个节点当中,通过关联规则对每一项数据节点的支持度进行计算。再完成对map 程序的执行,从网络文件当中获取到本地相关数据集,并在mapper 当中输入一个已知的数据记录,利用combiner 完成对本地数据集记录内容的简易合并,并将其带有相同护具的键值统一分配到一个reducer 当中。再将提取到的所有数据值进行累积,并将其统一整合为一个整体,并通过上述计算得出的支持度从小到大的顺序组合成一个顺序图。
其次,在mapper 当中输入另外一个数值记录信息,并将其与上一步中的数值记录信息进行对比,将其中存在的相同数据信息统一发送到相同的节点当中,并对其进行频繁地挖掘,最终得到相应的挖掘结果。
最后,将不同数据值的数据信息统一到不同的数据节点当中,保证在同一时间当中,对应的频繁项集不会都存在于一个数据节点上,以此确保挖掘后的数据信息具有一定的规律顺序。再结合关联规则当中的默认对关键数值排序功能,将关键数值替换为构造算法当中的某一项,将所有的结果进行汇总,得到的数据才为通过数据挖掘得到的最终结果。
1.2 筛选网络信息数据挖掘候选集
完成对基于关联规则的数据挖掘规则设计后,在网络环境当中对信息进行数据挖掘时,由于信息量较为庞大,因此挖掘的候选集较多,会增加挖掘的压力,造成挖掘结果无法达到预期的问题产生。因此,为了有效提高本文基于关联规则的网络信息数据挖掘方法的挖掘效率,需要对其候选集进行筛选。根据网络信息数据挖掘候选集的性质,假设T 为数据集P 当中的频繁x 项候选集,则T 的所有x-1 项的子集也可以称之为使其频繁x-1 的项目集。因此,进一步分析得出,Tx为数据集P 当中的频繁x 项候选集,则频繁x-1 候选集集合Lx-1中包括的x-1项目子集的个数一定为x。若某一要素在挖掘的过程中将成为某一个x 维频繁项目集当中的元素,则该要素在频繁x-1 项目集合当中出现的次数一定不会小于x-1。根据上述分析,对网络信息数据挖掘候选集进行筛选,根据候选集的性质,本文提出进一步筛选候选集的个数算法为:利用Lx-1产生的Cx 之前先对Lx-1进行一次裁剪。统计Lx-1当中所有的项目弧线的实际次数,将Lx-1当中包含的出现次数小于x-1 的项目的项目集删除,以此得到L’x-1。为了实现对二者的区分,将上述过程称之为裁剪A,即候选集筛选前的裁剪。再利用关联规则本身提供的裁剪方式将其称之为裁剪B,即候选集筛选后的裁剪。因此,针对某一需要进行挖掘的候选集,其筛选的结果可通过如下算法产生:首先,对候选集进行裁剪A;用Lx-1对其中某一要去的执行连接求得候选集当中潜在的频繁项目集;对该项目集执行裁剪B,得到的最终结果即为筛选完成后的网络信息数据挖掘候选集。
1.3 候选集信息数据挖掘
在完成对网络信息数据挖掘候选集的筛选后,对候选集当中的信息进行数据挖掘,由于候选集当中仍然含有海量的数据信息,因此本文在挖掘的过程中,将编程思想作为基础,结合本文上述提出的数据挖掘规则,将网络环境当中候选集的海量数据进行重构,并对其文本进行统一分类。计算网络环境中候选集的每一类别下的特征出现概率。在实际挖掘过程中,若频繁出现某一特征下的数据时,则会造成挖掘的应用价值降低,导致挖掘的数据集中占重要数据集的百分比下降。因此,为了能够有效避免这一问题的产生,本文在实际执行关联规则对网络信息候选集进行数据挖掘时,引入另一种Apriori 算法,对该网络环境当中的每一个候选集的权重集合理分配,其分配方式可用如下表达式表示:

公式(1)中,M表示网络环境当中的每一个候选集的权重分配值;Q 表示该候选集在网络环境当中的出现次数;d 表示Apriori 算法系数。根据上述公式(1)完成对候选集的权重分配,并在此基础上,对网络环境当中的所有候选集进行分类,以此确保最终挖掘结果的准确性,进一步提高关联规则的应用意义。通过上述权重分配结果,得到的数值可看作是对候选集的评价结果,通过对评价输出的数据最终值与全局簇中心点数值是否存在一致性进行判断,完成对网络信息数据的挖掘。若结果显示二者之间存在一致性,则认为该数值具有一定的应用价值,若计算结果显示二者之间不存在一致性,则可利用执行智能过滤行为对其进行过滤,并将过滤的数据看作是冗余数据,直到完成对网络环境当中所有的离群点均挖掘完毕后,完成对其一致性判断。
2 对比实验
为进一步验证本文提出的基于关联规则的网络信息数据挖掘方法在实际应用中的性能,建立如下对比实验:
采用经典数据集作为实验样本,挖掘该数据集当中的所有关联规则,对数据集分别进行从1~9 的标号,不同标号对应不同的事务,其中标号1 为事务A、B、E;标号2 为事务B 和D;标号3 为事务B 和C;标号4 为事务A、B、D;标号5 为事务A 和C;标号6 为事务B 和C;标号7 为事务A 和C;标号8 为事务A、B、C、E;标号9 为事务A、B、C。当前数据集当中项与项之间存在正相关时,则认为其提升度超过1;当项与项之间存在负相关时,则认为其提升度小于1。将实验环境的支持度水平设置为0.3,置信度水平设置为0.8,利用Python3.1 的开发工具,通过编程的方式完成对两种挖掘方法的应用实现。对比两种挖掘方法完成挖掘后,得出的数据集中占重要数据集的百分比,并将实验结果记录如表1 所示。
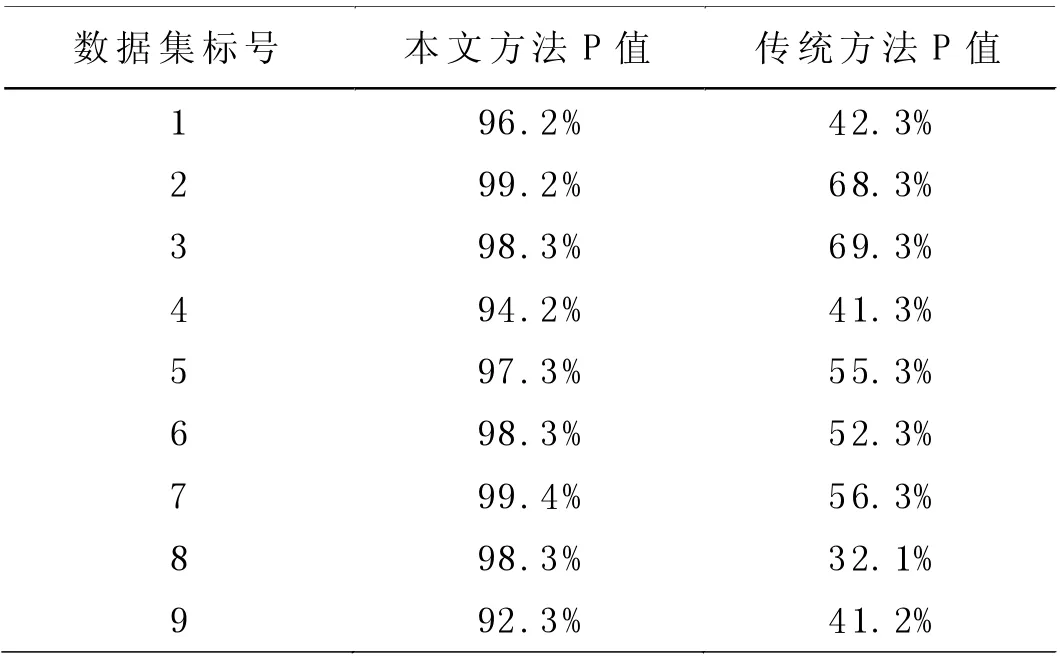
表1 两种挖掘方法实验结果对比表
表1 中P 值表示为本文方法或传统方法完成挖掘后,得到的数据集中占重要数据集的百分比,P 值越大则表示该方法挖掘有效性更强;反之,P 值越小则表示该方法挖掘有效性越弱。由表1 可以看出,本文方法的P 值均在90.0%以上,而传统方法P 值仅在30.0%~70.0%范围以内,明显本文方法P 值更高。从标号1、标号4、标号8 和标号9 可以看出,传统方法在对事务较多的数据集进行挖掘时,其有效性更差,而本文方法在对数据集挖掘的过程中不会受到数据集内部事务数量的影响。因此,通过对比实验进一步证明,本文提出的基于关联规则的网络信息数据挖掘方法在实际应用中的挖掘有效性更强,能够完成对更高利用价值的信息数据挖掘,提高数据的有效利用率。
3 结论
数据挖掘是当前一种多学科相互交织的新兴技术,在各个行业领域当中的应用优势逐渐凸显,本文通过开展基于关联规则的网络信息数据挖掘方法设计研究,提出一种全新的挖掘方法,并通过实验证明了该方法的实际应用效果。当前该挖掘方法只针对网络环境,引入如何实现将该挖掘方法与其它相关领域的应用更加紧密地结合,是未来研究的重点,以此进一步扩大本文挖掘方法的适用范围。
猜你喜欢
作文大王·低年级(2022年12期)2022-12-23 02:16:15
中国交通信息化(2022年10期)2022-11-17 08:19:42
大众投资指南(2021年35期)2021-02-16 01:06:26
河南水利年鉴(2020年0期)2020-06-09 05:43:44
电力与能源(2017年6期)2017-05-14 06:19:37
汕头大学学报(自然科学版)(2017年1期)2017-03-03 05:38:37
信息通信技术(2015年6期)2015-12-26 01:16:46
唐山学院学报(2015年6期)2015-02-22 08:08:24
天津师范大学学报(自然科学版)(2014年2期)2014-11-01 03:41:40
电子设计工程(2014年18期)2014-02-27 12:00:13
