
基于轻量级神经网络的地基云图识别
2021-05-25 13:37贾克斌刘鹏宇
北京工业大学学报 2021年5期
贾克斌, 张 亮, 刘鹏宇, 刘 钧
(1.北京工业大学信息学部, 北京 100124; 2.先进信息网络北京实验室, 北京 100124;3.华云升达(北京)气象科技有限公司, 北京 102299)
云是地球热力平衡和水气循环的重要组成部分,云的形状和形态反映了大气运动的稳定程度和天气特征,是预示未来天气变化的主要特征之一. 根据国际气象组织的标准[1],基于云的高度和形状,云分为3族10属29类,其中云属是本文关注的重点,它具有10个类别标签. 不同类别的云具有不同的形态,准确地识别云对提升天气预报的准确性、气候模型预测的有效性以及理解全球气候变化具有重要的意义.
目前,大多数气象站对云的识别依赖于气象观测员人工目测识别[2],但人工识别易受到观测员的心情、观测经验等主观因素的影响,此外,由于云的形状变幻莫测,人工观测工作量巨大,难以保证长时间不间断的观测,制约了云识别的准确性和连续性. 近年来,随着数字图像处理和模式识别技术的飞速发展,基于云图片的自动化识别技术已成为气象学方面的研究热点. 云自动化识别技术分为2个方向[3]:卫星云图云识别和地基云图云识别. 地基云图较卫星云图而言,具有更高的空间分辨率及更丰富的局部信息,因此,基于地基云图的云自动化识别更受到研究人员的关注. 但由于云的非刚体结构以及其多变的特性,利用经典图像特征建立地基云图识别模型的实验效果并不理想. 例如:李晨溪等[4]对云图的灰度数据进行扩展自相似(extended self-similar,ESS)模型标度分析,利用不同云系的标度特征对5类共150张云图进行识别,准确率接近90%,但由于测试样本数量有限,无法验证算法的鲁棒性. 张弛等[5]提出一种基于可见光- 红外图像信息融合的云状识别方法,对5种云图进行识别,平均准确率为82%,但此算法需综合考虑全天空云图及红外云图,适用性不高. 因此,利用深度学习自动提取云的特征完成云识别是一个有效的途径.
近年来,随着数据集的产生、计算性能的提升、各类机器学习算法的发展,利用深度学习处理具体问题越来越受到关注. 2012年,Google公开的ImageNet[6]数据集使得研究人员拥有了训练、测试以及竞赛的素材. 此后,AlexNet[7]、GoogleNet[8]、ResNet[9]等经典的网络依次出现,一次次地刷新了各类比赛的记录,甚至完成了人力都无法实现的分类任务. 目前,基于深度学习的分类网络的研究方向主要有2个:一个是追求模型的准确性,因此,为了拟合大量的数据通常添加各种复杂的技巧,使模型的参数量和计算量变大,增加了实际部署网络模型的困难,典型的有Inception-V3[10]、DenseNet[11]等;另一个是追求模型的轻量化,通过一些技巧让模型的参数大幅度减少,同时尽可能保证准确率,典型的有Xception[12]、MobileNet-V2[13]、ShuffleNet[14]等. 云识别的任务核心为对云图片进行分类,因此,这些成熟的研究成果均可以作为构建模型的参考.
目前,已有部分学者公开了自己的云数据集并提出了相应的分类方法. 这些数据集针对不同的应用场景进行图像采集并加以筛选,包括SWIMCAT[15](Singapore whole-sky imaging catagories database)、HUST[16](Huazhong University of Science and Technology)和MGCD[17](multimodal groud-based cloud datobase). 其中,SWIMCAT用WAHRSIS设备在新加坡采集784张图片,并且将云分为5类(非国际气象组织标准类别). Dev等[15]使用了传统的方法,即提取颜色和结构特征用于分类,准确率达到了95%;HUST利用自己的设备采集了1 231张图片,并分为8类云与1类无云,同时提出了颜色统计转换(color census transform,CCT)结合支持向量机(support vector machine,SVM)的方法进行云分类,准确率达到了79.8%;MGCD采集了共8 000张图片,分为5类云、1类混合云以及1类晴空,并利用分层多模态融合(hierarchical multimodal fusion,HMF)进行分类,达到了87.9%的准确率. 可以看到,这些数据集均不是按照国际气象组织的标准严谨分类的,不具有应用的泛化性. 在这3个数据集的基础上,CCSN[18](cirrus cumulus stratus nimbus)利用自己的设备以及互联网采集了2 543张图片,标注为标准的10类云以及额外1类航迹云. 基于此数据集,Zhang等[18]提出了一种深度学习网络模型CloudNet,其结构与AlexNet十分相似,准确率达到了91%. CCSN虽然具有全部的类别,但是其图片有很多是通过互联网获取的,图片质量参差不齐,因此,基于此数据集训练出来的模型难以实际部署至具体设备以实现产业化. 另外,目前的大多数方法都处于实验阶段,没有考虑模型的参数量及计算量,导致模型过大,通常只能本地测试而无法集成于算力较小的设备. 此外,赵亮亮[19]利用图像与辐射信息融合识别方法也取得了很好的效果.
本文利用华云升达(北京)气象科技有限公司的全天空成像仪采集了大量高质量地基云图片,并且利用经典算法将原始图片进行畸变校正预处理. 通过人工标注与迁移学习辅助验证对校正后的图片进行分类,构建了地基云图片数据集HBMCD(Huayun BJUT-MIP cloud dataset),涵盖标准10类云和无云,数量达到了25 119张. 基于此数据集,本文提出了一种轻量级的云识别网络LCCNet,通过多组实验证明,LCCNet在保证分类准确率的同时大幅度降低了模型的参数量以及运算量.
1 地基云图数据集HBMCD
1.1 地基云的分类和特点
根据国际气象组织标准,按照云的形状、形成原因,云分为积雨云、雨层云、卷云、高层云、层积云、卷层云、层云、卷积云、高积云和积云10个云属. 云属分类及其特点如表1所示. 本文以此表为依据,对收集到的图片进行筛选及分类.

表1 云的基本信息
1.2 HBMCD构建方法
1) 图像采集与预处理
本文采集地基云图的设备是全天空成像仪,如图1所示. 这是一套全自动、全色彩的天空成像系统,其成像部分是一套具有高性能电荷耦合器(charge coupled device,CCD)镜头的数字成像系统,能够定时拍摄全天空可见光图像,并且可利用太阳追踪装置转动镜头来阻挡太阳直射的入射光. 但是由于CCD镜头的光学特性,原始地基云图成像会发生切向畸变,成像看起来就像将一张正常的图片包裹在一个球体里,如图2所示. 因此,常用的图像识别方法在处理畸变图像时会因为其角度、亮度、黑色边缘等原因发生误检. 为校正原始地基云图的畸变,本文采取张正友相机标定法[20],结合图像裁切、亮度调节等操作对图片进行预处理,预处理效果如图3所示,图像已恢复至正常的视觉观感.

图1 全天空成像仪Fig.1 All-sky imager

图2 地基云图径向畸变Fig.2 Radial distortion of ground-based cloud image

图3 地基云图预处理效果Fig.3 Preprocessing effect of ground-based cloud image
2) 人工标注与辅助验证
因为数据量庞大,人工分类易出现错误,本文利用2个步骤对地基云图进行标注.
第1步对部分预处理的图片进行人工分类,形成原始数据集,并利用原始数据集进行迁移学习得到迁移学习模型,如图4(a)所示;第2步利用迁移学习模型对数据集进行辅助验证,将分类错误的图片以及分类置信率低的图片筛选出来并进行重新确认类别,如图4(b)所示. 然后逐次加入其他图片,重复上述步骤,直至构建成完整的数据集.
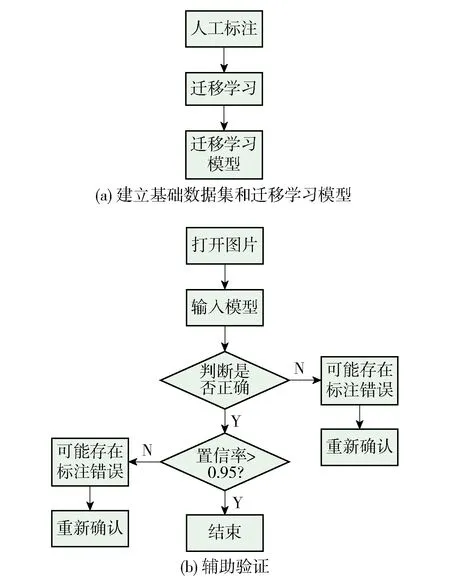
图4 数据集建构方法Fig.4 Dataset construction method
具体的方法如下.
在第1步中,首先对预处理的图片进行了筛选,尽量使图片均匀分布在不同的条件,如光照、天气状况、季节等. 然后选取其中一部分图片进行人工标注,标注的类别为国际气象组织标准的10类云属以及1类无云. 接着利用迁移学习对已分类图片进行辅助验证,为了保证更高的准确率,本文对比了5种经典的模型:VGG16、VGG19、Inception-V3、ResNet-152、DenseNet-201,测试迁移学习准确率. 测试结果见表2,通过对比可知,DenseNet-201的准确率最高,达到了96.50%,因此,选择此网络进行第2步的辅助验证.
在第2步中,设置DenseNet-201中SoftMax输出的最大概率为此图片在模型的置信度. 具体的辅助验证方法为:将一张图片输入至网络,将预测结果与实际标签对比,若分类错误,则再次确认其标签;若分类正确,则观察其置信度是否大于0.95,若大于则暂且认为此图片分类正确,若分类错误则再次确认其标签.
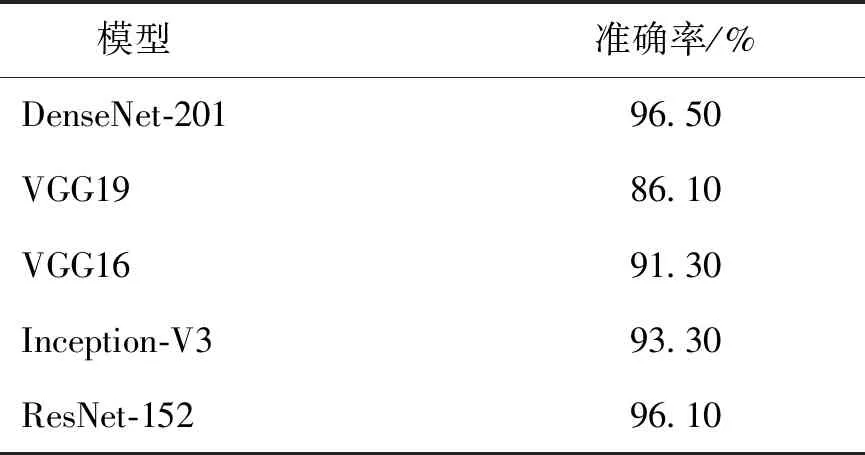
表2 迁移学习模型准确率对比
接着逐步添加其余图像,重复上述过程,对初步获得的数据集进行扩大和筛选,不断提高数据集的置信率直到构建成完整的数据集. 在筛选过程中,初次置信率未达标的图像分布如表3所示.
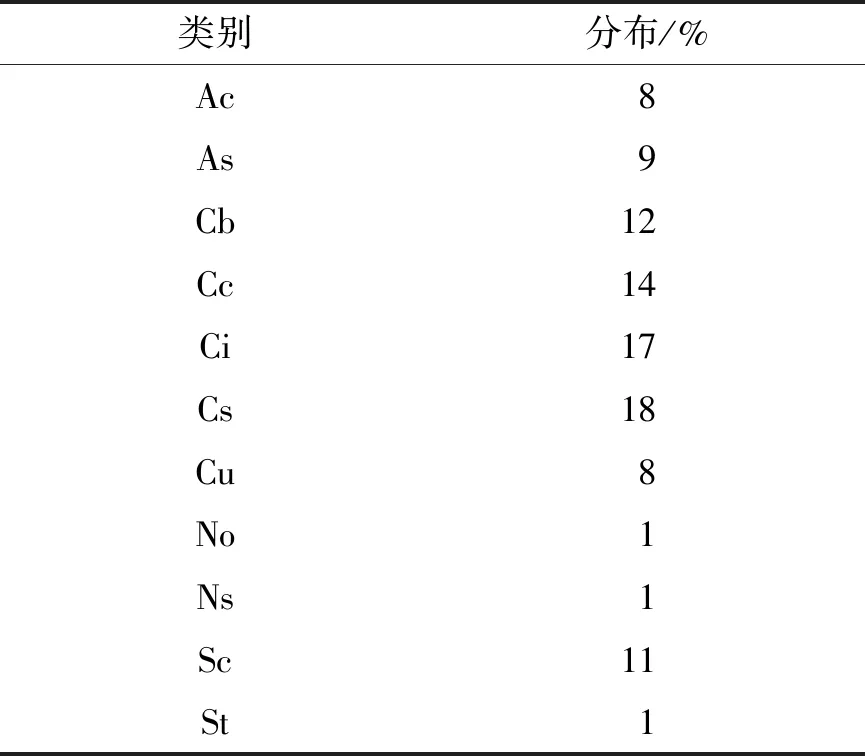
表3 未达标图像分布
最终得到的数据集各类别的图片数量如表4所示,图片共25 119张.
数据集公布的网址如下,可供下载研究.
https:∥github.com/SadaharuZL/HuaYun-BJUT-MIP-Cloud-Dataset.
1.3 数据集对比
表5对比了上文提到的4种数据集的类别、数量以及类别标签,可以看到,本文构建的HBMCD数据集种类齐全,符合国际气象组织标准,并且数量最多,几乎是CCSN的10倍,图像质量也较之更高.
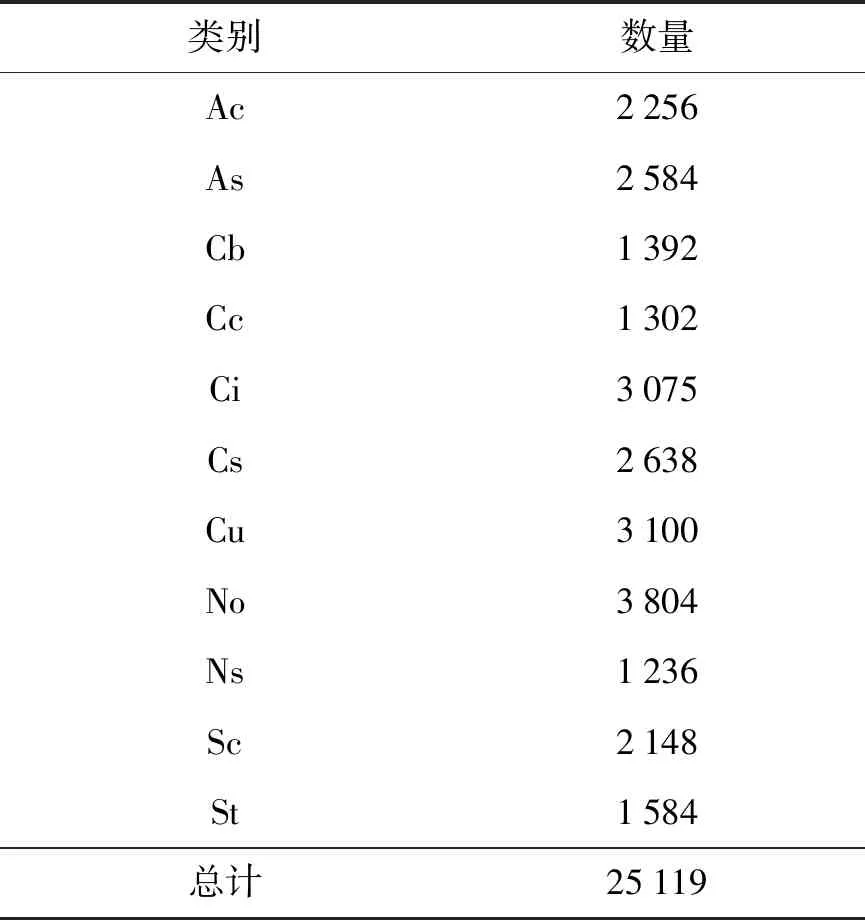
表4 HBMCD数据集信息
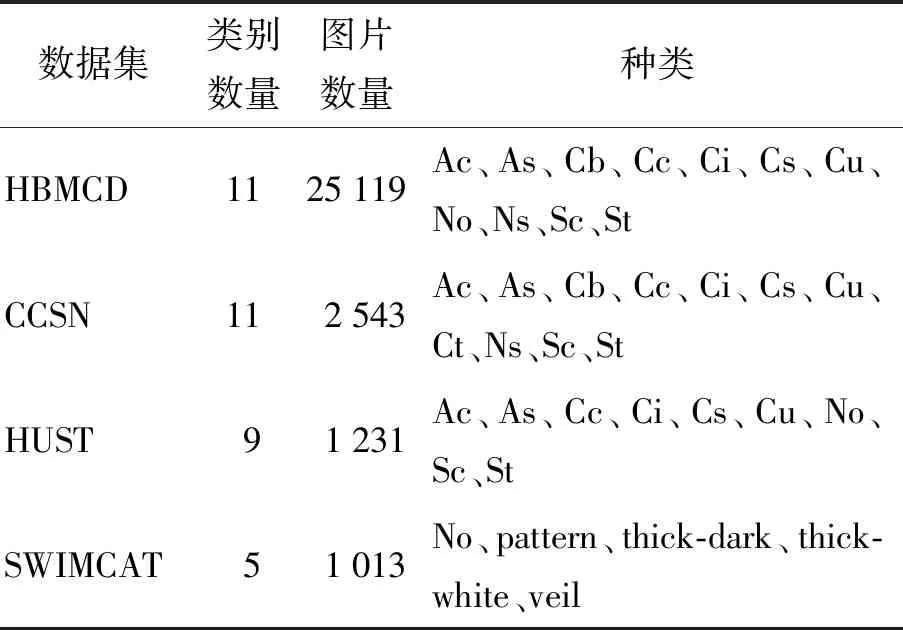
表5 数据集对比
2 轻量级分类模型LCCNet
基于上文提出的HBMCD数据集,本节通过重复多个轻量化的基本单元构建了一种轻量级的神经网络模型LCCNet.
2.1 建模分析
云体的层次结构极为丰富,因此,为使网络更适用于提取云的特征,所设计的网络模型需要在同一层具有不同的感受野,从而保证在网络同一层的特征图中的信息尽可能被利用到,实现对云体特征的全方面、精确的提取.
同时,由于多次重复一个相同结构的基本单元构建的网络具有易实现性及可拓展性,越来越多的网络模型采用这种结构,如ResNet、DenseNet、ShuffleNet等. 通常而言,这种基本单元的内部特征图尺寸在运算中会保持不变,有额外的一个模块对特征图进行通道扩增或降采样. 因此,这种基本单元可以总结为一个提取特征单元(extract-unit)和一个降采样单元(down sample-unit)的组合,本文也将采取这种模式.
2.2 基本单元
在提取特征单元中,本文利用了4种技巧,即深度可分离卷积(depthwise separable convolutions, DWConv)、逐点卷积(pointwise convolutions)、通道打乱(channel shuffle)、膨胀卷积(dilated convolution)[21].
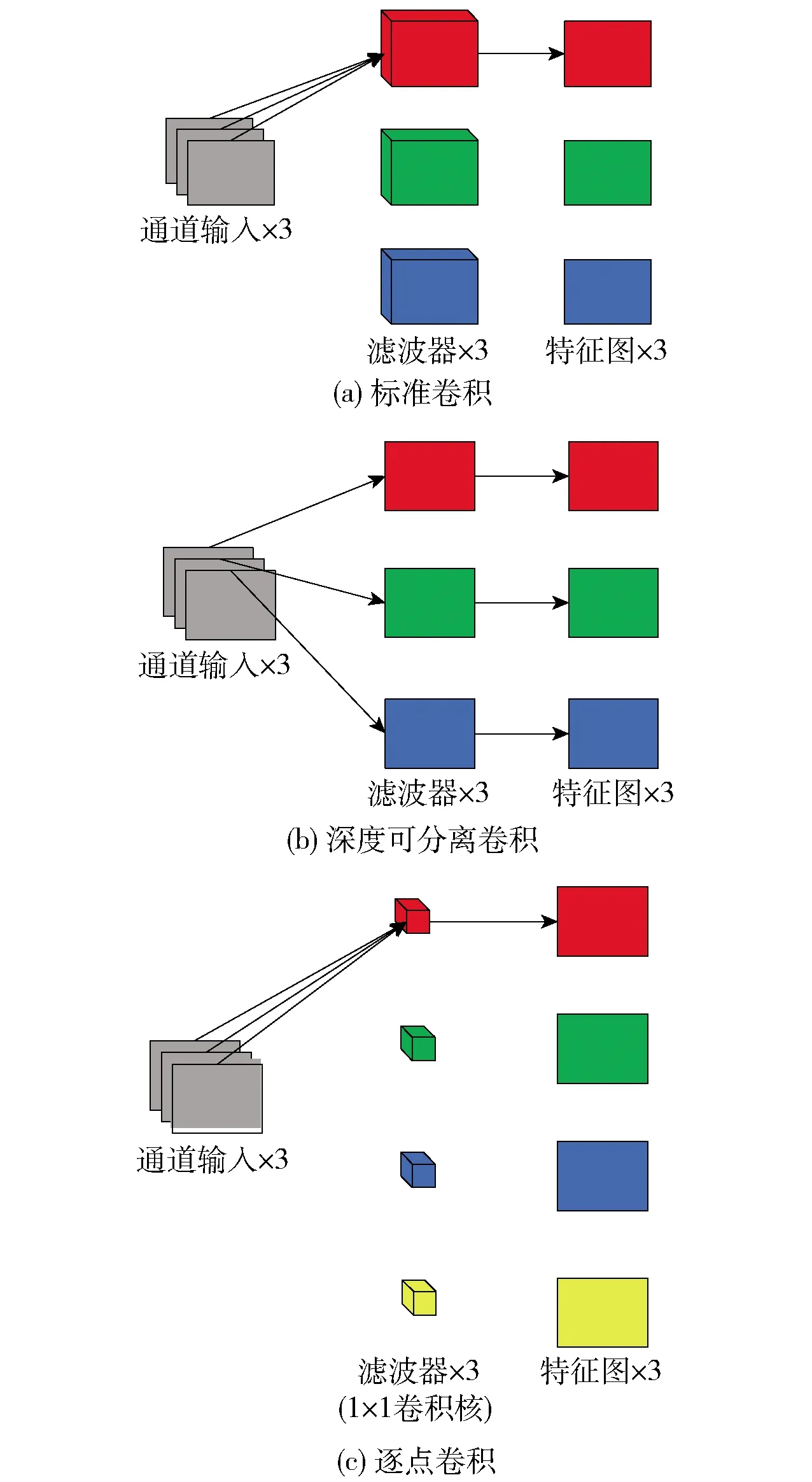
图5 3种卷积对比Fig.5 Comparison of three convolutions
首先,为了降低标准卷积运算的复杂度,根据分组卷积(group convolutions)的思想, Xception使用了深度可分离卷积进行逐通道地卷积. 如图5(b)所示,这种方法通过将输入通道拆分并与卷积核逐通道地进行卷积,理论上减小了卷积核的尺寸进而大幅度地降低模型的宽度. 同时,逐点卷积利用1×1的卷积核进行通道间的信息融合以及通道的扩张,如图5(c)所示. 这种方法既保留了提取特征单元的宽度与深度,又能大大地降低了模型的参数量.
然后,为了更充分地利用各个通道进行特征提取,弥补模型宽度的降低,ShuffleNet提出了利用通道间的转置将通道打乱的方法,如图6所示. 这种方法通过打乱通道间的信息,对信息在通道间进行了一次人为的融合,使模型的理解能力增强.
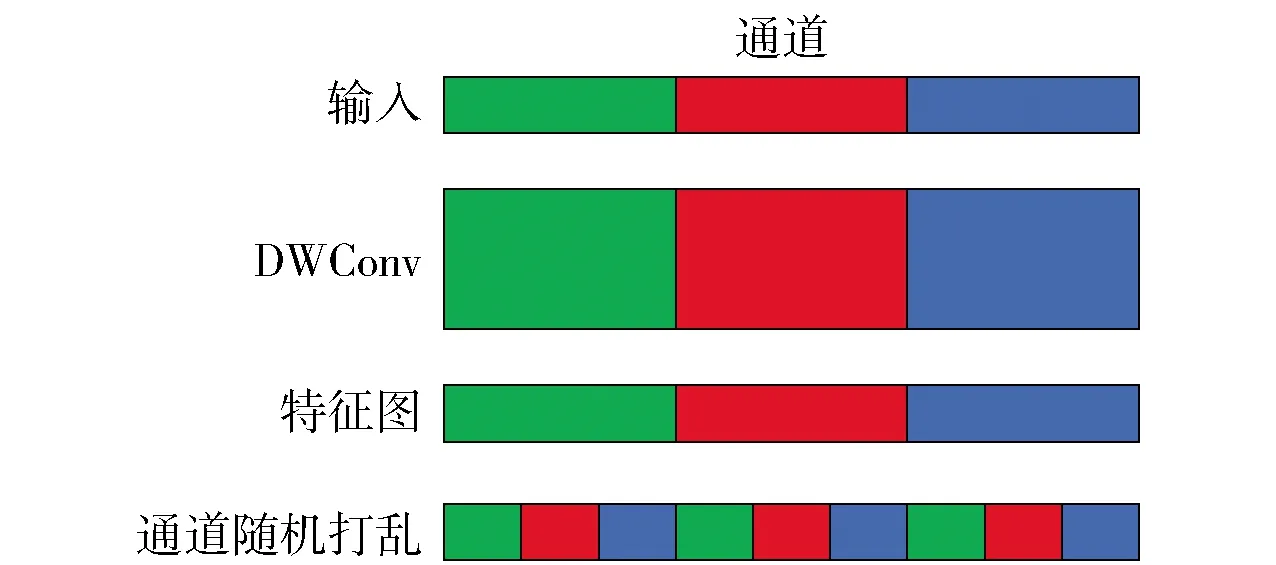
图6 通道打乱Fig.6 Channel shuffle
最后,为了降低模型的深度,本文采用了不同膨胀率r的膨胀卷积. 如图7(b)(c)所示,膨胀卷积使得相同尺寸的卷积核拥有了更大的感受野,因此,适当地利用这种卷积核可保证在提取相同层次的特征时降低模型的深度. 将这3种技巧组合,形成了本文的特征提取单元.
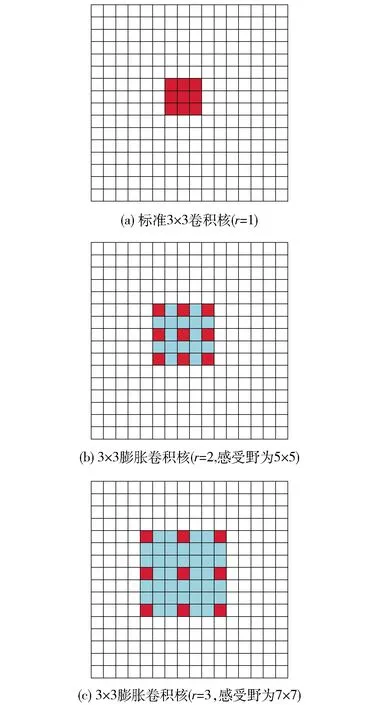
图7 3种膨胀卷积Fig.7 Three dilation convolutions
结合上述4种技巧,本文的特征提取单元如图8(a)所示. 它的流程为:首先,将输入的特征拆分为4组通道,其中第1组通道利用短链(short-cut)实现残差的提取,第2组通道利用标准深度可分离卷积和逐点卷积的组合进行特征提取,第3组与第4组通道的结构和第2组相同,但是它们的卷积核使用的是不同膨胀率的膨胀卷积,具有更大的感受野,使得几组通道获得不同感受野的信息,以便对云这种层次丰富的物体进行特征提取. 然后,将这4组通道连接,将通道打乱以发挥通道的表征能力,弥补通道宽度变窄的损失. 最后,利用全局池化以及2个全连接层对相连的通道进行整体特征的提取,结果与原通道的特征图中每个元素相乘,实现对通道的权重分配,这种方法被称为通道的注意力机制(attention mechnism)[22],它能让模型知道哪些通道的特征图更值得关注.
在降采样单元中,如图8(b)所示,首先,利用一个逐点卷积对打乱的通道进行信息间的整合;然后,分别利用3×3的平均池化和最大池化完成空间尺度的降采样,前者可以提取局部区域的整体信息,后者可以提取局部区域的轮廓信息;最后,将二者的通道相连,这样就实现了增加通道的宽度.
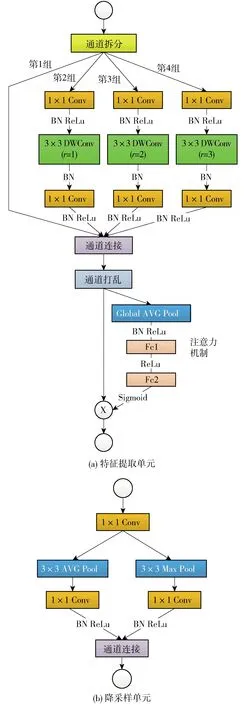
图8 模型基本单元Fig.8 Model basic unit
将重复不同次数的提取特征单元与降采样单元相结合,形成了本文的一个基本单元,本文称之为Stage. 下面利用不同的Stage构建LCCNet.
2.3 模型结构
LCCNet的结构如表6所示,首先经过一层普通的3×3卷积层和池化层提取浅层信息,然后利用4个不同的Stage提取特征,其中D为上文所说的降采样单元,E为提取特征单元. 最后经过全局池化和一层全连接层实现特征分类.
表中Stage的数量、输出通道数以及各模块重复次数等参数是通过多组对比实验选出的最优方案,保证准确率的同时最大程度压缩模型的规模.
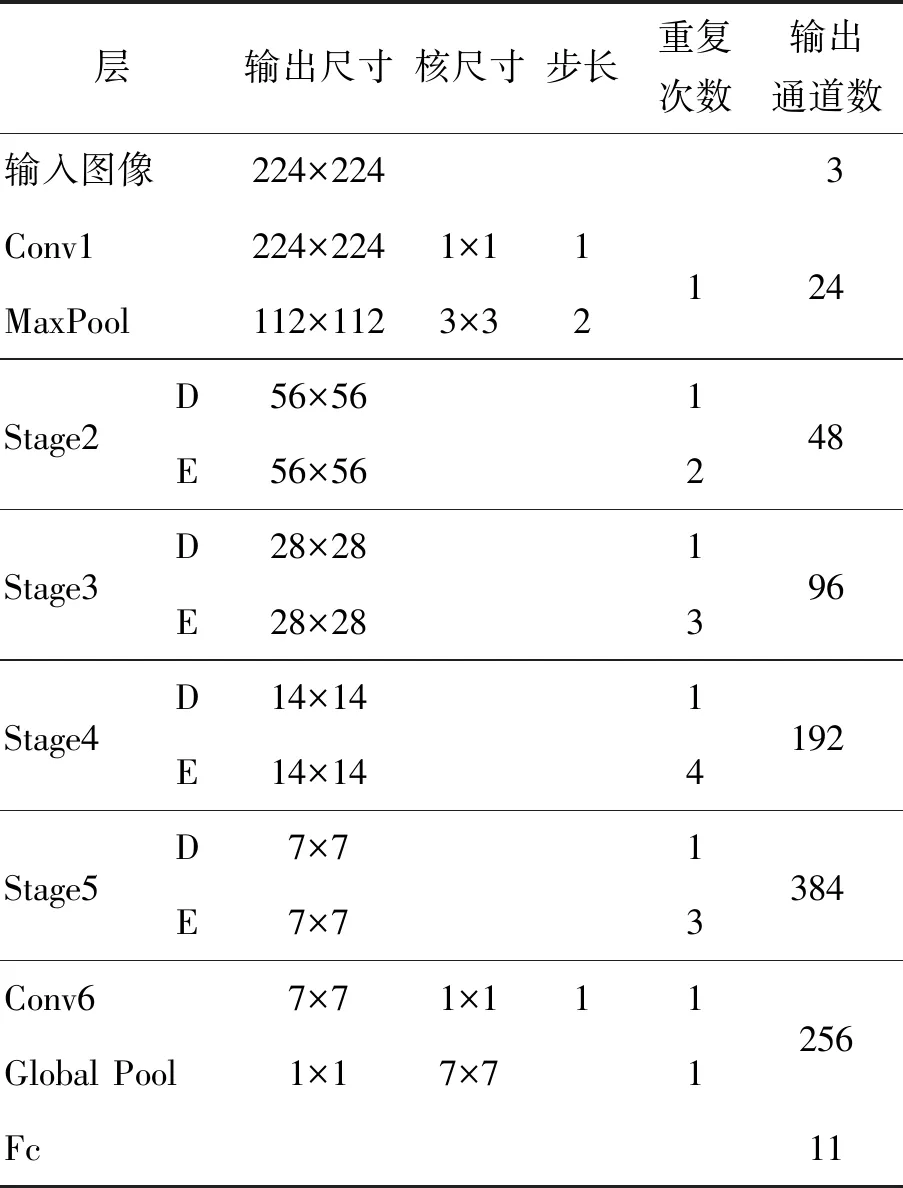
表6 模型结构
3 实验设置与结果
本节将介绍具体的实验内容,包括实验配置、模型的可视化、实验结果及分析.
3.1 实验配置
本文首先将按照8∶1∶1的比例分成训练集、验证集和测试集,然后对数据集进行数据增强,即通过图像旋转、裁切等方式使数据集规模进一步扩大,然后进行训练与测试,并且使用交叉验证将上述操作重复6次取实验结果的平均值. 本文使用Pytorch框架对LCCNet进行搭建,损失函数为交叉熵函数,优化器为Adam,迭代次数设置为100,初始学习率为0.01.
3.2 模型可视化
本文尝试了用Grad-Cam[23]方法对模型进行可视化,如图9所示. Grad-Cam的步骤为:选取特定目标层数,对此层数的所有通道进行加权平均,并以热力图的方式展现模型的提取特征能力. 本文选取了Stage4作为目标层数.
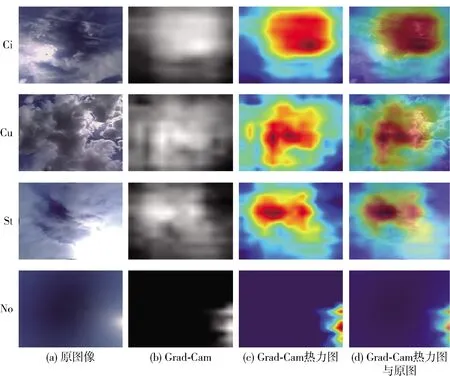
图9 模型可视化Fig.9 Model visualization
在图片上,选取了3种基本形状的云图,即卷云、积云、层云以及1类无云,在模型上选取了Stage4层. 可以看到,在卷云的Grad-Cam中,模型更注重右上部分的图像特征. 观察原图,在右上角确实有非常明显的马尾状的卷云. 在积云图片的Grad-Cam中,模型更注重中左侧部分的图像特征,观察原图确实是整块浓积云的主体. 在层云图片的Grad-Cam中,模型更注重中左上部分的图像特征. 观察原图,虽然层云几乎充满了整张图片,但是最清晰的部分集中于中左上部分. 而在无云中的Grad-Cam中,模型只关注了太阳附近的区域,而其他没有云的区域没有关注. 通过这4种基本形状的云图,可以看到LCCNet确实可以提取到图片有效特征以实现对云状的分类.
3.3 实验结果
1) 混淆矩阵
混淆矩阵如图10所示. 可以看到11个类别的整体实验结果都比较好,而其中卷积云、卷层云、卷云3个种类之间较容易发生混淆. 事实上,这3种云之间的变换非常频繁,因此,在图像上经常存在这2种甚至3种云,而在数据集中本文依据某种云分布区域的大小来决定这个图片的标签,当这几种云的占比相似时,模型可能会模糊不清,而人工判定也可能出现混淆,如图11所示.
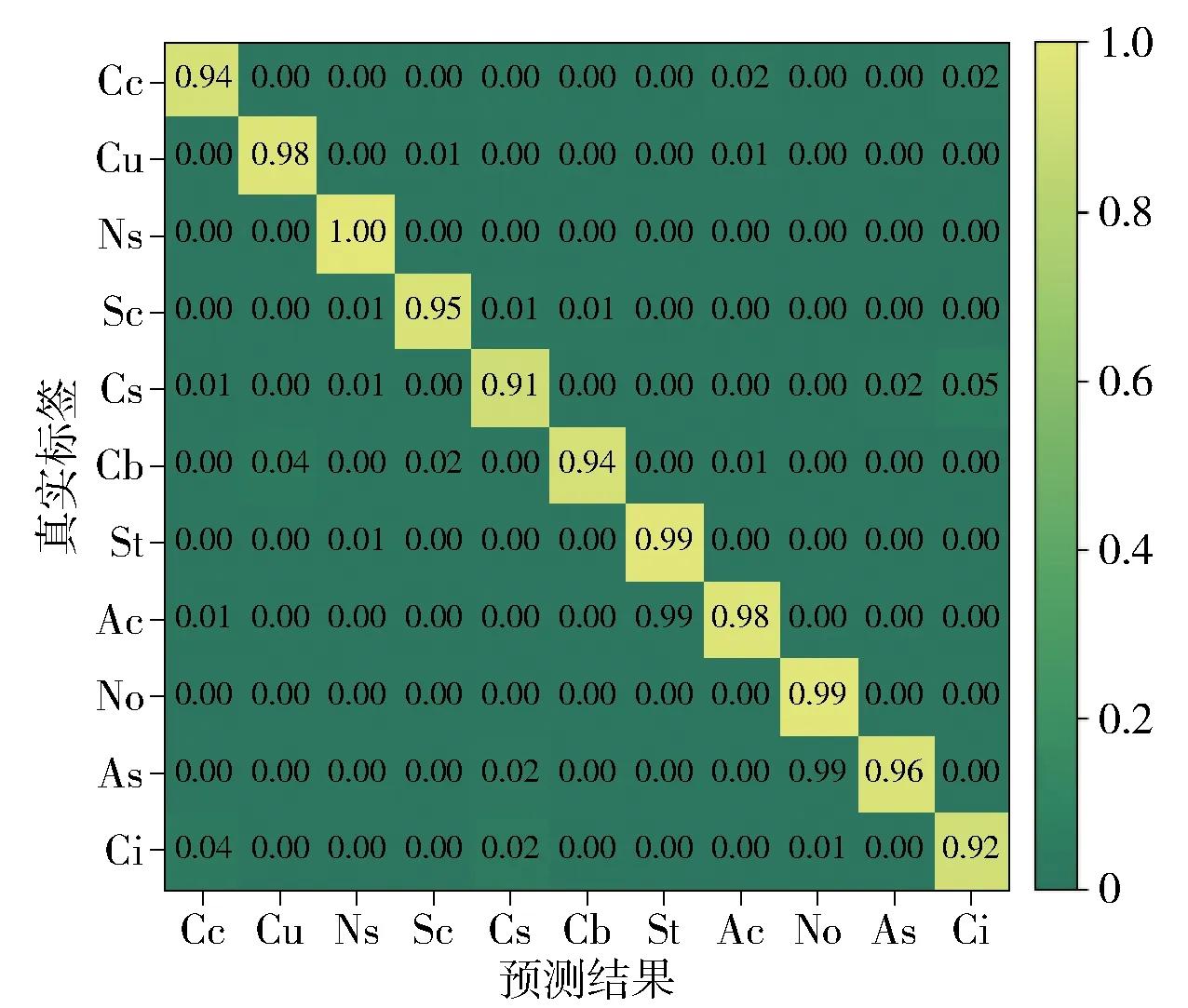
图10 混淆矩阵Fig.10 Confusion matrix

a区域为卷云;b区域为卷层云;c区域为卷积云 图11 易混淆的图Fig.11 Confusing figure
由表3可发现,在构建数据集时初次未达标的图像种类的分布也与混淆矩阵的结果一致,即卷积云、卷层云、卷云三者出现未达标的概率较大,需多次重复校验.
但为了使数据集更具有实用性和可靠性,并没有将这些图片删除. 另外,还有2组云,即积云和积雨云,也较容易发生混淆,这2种云在地对空的角度拍摄的图片中很难分辨,因此,数据集自身就有混淆的成分.
2) 单类的评价指标
针对单独的每类云,本文测试了查准率(precision)P、召回率(recall)R和F1三个指标,结果如表7所示.P、R、F1的定义分别为
(1)
(2)
(3)
式中:tp为被模型分类正确的正样本数量;fp为被模型分类错误的负样本数量;fn为被模型分类错误的正样本数量.
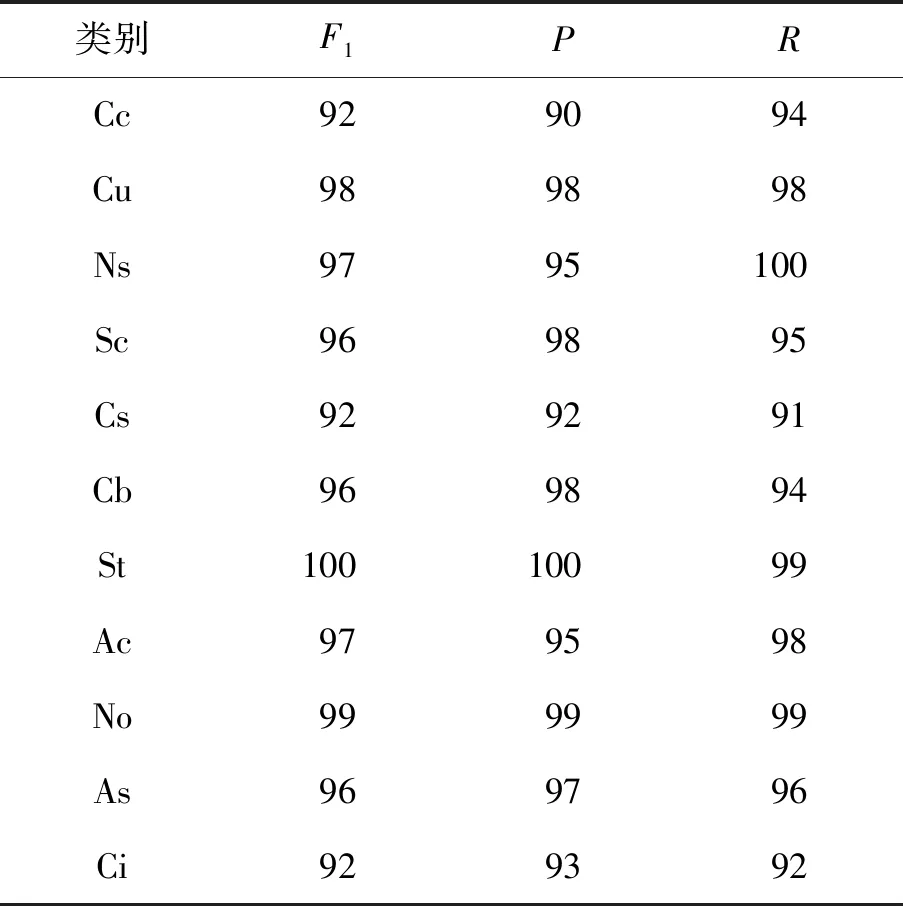
表7 单类评价指标
3) 多类的评价指标
为了验证模型的整体性能,计算了宏观(macro)和微观(micro)的准确率和召回率. macro指对每个类求出某个指标,然后对这些指标进行算术平均; micro指将所有类视为一个查询,将各种情况求和,进行指标的计算. 它们的计算公式分别为
(4)
(5)
(6)
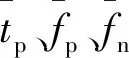
结果如表8所示,可以看到模型4个指标的平均值为96.0%,证明其有较高的可靠性.

表8 多类评价指标
4) 与其他方法的对比
本文与现有其他的地基云识别算法以及产业中常用的几种模型在准确率、参数量、浮点运算次数上进行了对比,结果如表9所示. 其中准确率的计算方法为
(7)
式中:A为准确率;i=0,1,…,n(n=11);T为所有图片的总数量.
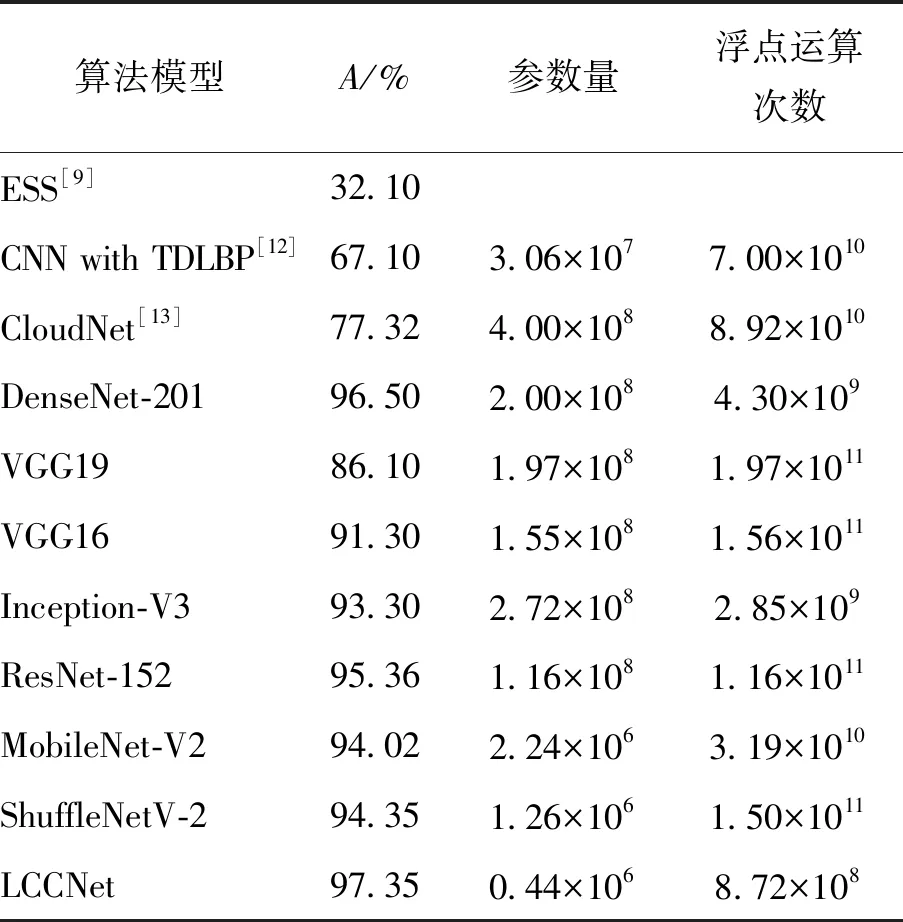
表9 结果对比
相较于现有其他的地基云图识别算法,本文的方法无论是准确率还是参数量都具有大幅度的优势. 相较于其他经典的图像识别算法,对于较大的模型,采取迁移学习的方式拟合本文的数据集,如DenseNet-201、VGG19、VGG16、ResNet-152、Inception-V3、ResNet-152、CloudNet. 对较小的模型,如MobileNet-V2、ShuffleNet-V2[24],选择重新训练,并且实验配置与LCCNet一致. 实验结果显示,LCCNet的参数量几乎是最小模型ShufflenetV2的1/3,运算复杂度几乎是它的一半,但是准确率却是所有模型中最高的,证明LCCNet的设计确实降低了复杂度并且保证了提取图片特征的能力.
4 结论
1) 利用全天空成像仪,通过图像预处理、人工标注和迁移学习等步骤,构建了涵盖11个标准类、2万余张地基云图的数据集,并在云图种类、云图的规范性上与现有公开数据集进行了比对,表明本文构建的数据集具有规模大、种类全、分辨率高、角度固定等优点,为后续基于该数据集进一步开展云状分类计数研究奠定了基础.
2) 基于重复提取特征单元及降采样单元,构建了轻量级云图分类模型LCCNet. 在分类准确度上,将本文模型与现有其他方法以及多种经典模型进行了比对,准确度最高,达到了97.35%;在轻量级程度上,与现有的MobileNet-V2等轻量级模型进行了比较,参数量及运算次数几乎达到了ShuffleNet-V2的1/3. 大量实验数据验证了本文所构建的LCCNet的高效性,为专属设备的集成提供了可能性.
3) 目前的数据集中依然存在着容易混淆的几类图片,在实际应用中依然存在着误检问题,因此,需要研究多标签的地基云图方法,将混淆图片中的云全部识别以解决此问题. 下一步会将算法模型与具体的设备结合在一起,进行更有实践性的测试.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
导航定位学报(2022年4期)2022-08-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
智能制造(2015年9期)2015-10-15
