
监控场景下基于机器注意的多任务行人属性识别
2021-05-25 13:37陈双叶
北京工业大学学报 2021年5期
陈双叶, 徐 凯, 胡 鑫
(北京工业大学信息学部, 北京 100124)
由于行人属性的鲁棒性,行人属性识别的研究已经成为计算机视觉方向的一个重要研究领域. 人的属性识别在人的面部识别[1-3]、行人重识别[4-6]等领域显示了巨大的潜力. 当前的行人属性识别主要关注2种应用场景:自然场景和监控场景. 相比于自然场景下的识别[7-8],监控场景下的行人图像模糊,分辨率低,易被遮挡且光照变化大. 因此,监控场景下的属性识别更具挑战性.
大量报告显示,传统的行人属性识别方法如HOG[9]、SIFT[10]、SVM[11]、CRF模型[12]方法,性能远没有达到现实应用的要求,已经逐渐被基于深度学习的方法取代. DeepMAR[13]和CAN[14]利用属性间的依赖性,通过特征共享,从单张图像上直接识别所有属性. 其好处是简单、直观和高效, 但是,由于缺乏细粒度识别的考虑,这些模型的性能仍然受到限制. PANDA[8]、LGNet[15]、PGDM[16]算法基于局部的思想,使用局部信息补充全局,这样虽然可以提高整体识别性能,但也带来了以下缺点:首先,不正确的零件检测结果将为最终分类带来错误的指导;其次,由于引入了人体部位,因此需要更多的训练或推理时间. 视觉注意机制已经在行人属性识别中引入[17-18],但是现有的工作仍然有限,在这一领域,仍然需要探索如何设计新的注意力模型或从其他领域借鉴[19]. Wu等[20]提出基于序列语境关系学习的方法(sequence contextual relation learning, SCRL),将属性关系序列作为平行分支,再融合经过CNN处理的图像序列分支,从序列中学习上下文关系,改善行人属性识别.
此外,在许多属性识别工作中都考虑加入了属性分组方法. Abdulnabi等[21]提出按照属性的语义信息作为依据进行属性分组. Fukui等[22]和Fang等[23]综合考虑属性的空间位置和语义关系,将属性分为局部和全局属性,再使用不同的CNN模型以多任务方式对2组属性进行分类. Tan等[24]提出基于行人解析的分组方法.
通过对多种行人的属性识别方法的深入研究,本课题组发现一个现象:多属性的联合识别确实有不错的优势,也被大多数人接受[14-16,25],但是联合识别的结果中某些单项属性识别精度远低于单独识别[13],所以认为虽然联合属性识别能利用属性间的联系,提升识别准确率,但是对于部分属性(小、易遮挡),可能不会引起神经网络的注意,导致这些属性的识别性能下降.
为了解决上述的问题,达到更高的识别性能,本文提出了一种限制神经网络关注的多任务属性识别方法. 与Abdulnabi等[21]、Fukui等[22]、Fang等[23]和Tan等[24]的方法不同,本文结合最新流行的人工智能(artificial intelligence,AI)解释性研究[26-27],从机器的“思维”角度出发,提出一种更直观的基于机器注意区域的属性分组方法. 同时,本文还设计了端到端的网络模型和辅助分类损失函数,该网络模型既可以利用属性间的依赖关系,又不会相互产生干扰.
1 基于机器注意的多任务识别方法
结合机器注意[28]和多任务学习[29]的优势,提出了一种限制神经网络关注区域的多任务属性识别方法. 首先依据神经网络对不同属性的关注区域差异划分属性分组,然后设计端到端的网络模型和相应的辅助分类损失函数.
1.1 属性分组
神经网络的黑盒特性一直以来都是机器学习领域的一大难题,它们缺乏可分解性,无法分解为各个直观组件,因此难以解释[30]. 幸运的是,随着可解释AI研究的发展,深度学习的面纱正在被逐渐揭开. Selvaraju[26]和Chattopadhay等[27]的研究基于目标检测结果,反向传播得到只保留有用特征的带权重热图,即类激活热图(class activation mapping,CAM). 这些方法解释了深度神经网络的目标检测原理,即对于某一类标签,神经网络对于输入图片中哪些区域的像素值更敏感,换句话说,对于需要预测的属性,深度神经网络更关注图片中的哪部分区域. 由此可以认为,在属性的联合识别中,由于神经网络对部分属性的关注区域重合,其中特征不明显的属性与特征突出的属性之间的重合,就会导致神经网络更集中于识别特征更突出的网络,从而忽略特征不明显的属性,进而导致该部分属性识别的准确性较低.
通过对属性识别的可视化研究[27]可以发现,不同的属性在神经网络中有不同的受关注区域,如图1所示. 不同属性的受关注区域之间可能互不影响,也可能有很大重叠,对于有重叠的2个不同种类的属性,由于其分类所需的特征不同,在重叠的图像区域进行特征提取时必然会产生竞争. 此外,像帽子、背包、靴子这样的属性有具体且局部的关注区域,而像年龄、性别这种抽象属性,通常不涉及固定的关注对象和关注位置. 综合上述考虑,本研究综合考虑神经网络对每种属性关注区域,以及抽象属性的特点,将属性划分到不同的组中,保证神经网络对每一个属性有相同且足够的关注,同时组内的属性不会产生干扰,不同组的属性可以通过信息共享相互促进,以此达到更高的精度. 具体的属性分组见表1.

表1 Market-1501-attribute属性分组

图2 提出的网络结构模型Fig.2 Proposed network structure model
1.2 网络结构
网络模型框架如图2所示,该网络框架主要包括以下3个部分.
1) 输入网络:因为深度神经网络的底层卷积部分是用来提取低级图像特征(例如纹理、线条等)的,所以本研究没有直接将原始图像直接作为后续的输入,而是选择将经过第1个卷积块(baseblock)处理之后的数据作为各个子网络的输入. 这样一来,既可以减少网络的计算量,减轻硬件的负担;又可以增强网络各子任务间的联系,加强属性间信息交流.
2) 特征提取网络:特征提取部分共分为4个特征提取子任务网络,分别用来提取不同属性组的特征. 子网络模型使用VGG16[31]作为基础网络,选用其3个中间卷积块(即图2中的卷积块_1, 卷积块_2, 卷积块_3),然后连接1个升维卷积块(卷积块_4),将卷积核数量提升至2 048,再经全局平均池化(global average pooling,GAP)[22]处理后输入到后续的分类层. 这样既可以增加模型复杂度,提升拟合能力,又不用承担使用全连接层导致的计算量激增,还可以使模型支持任意尺寸输入,使用灵活,便于移植到其他类型任务中.
3) 属性预测网络:在该部分,本研究将各特征提取子任务网络提取出来的特征信息分别输入到2个分类网络:一个是辅助分类网络,将每组特征提取子网络输出的特征信息输入到各自的子分类网络进行组内属性的识别;另一个是最终输出的全分类网络,是将各子特征提取网络的输出信息整合,再一起输入到全识别分类网络中,进行所有属性的识别. 其中辅助分类网络只在训练阶段用于辅助训练,在应用阶段会被删除. 通过2个分类网络的设计,能达到以下3个目标:① 网络对子任务内各属性间注意区域不重叠. ② 融合各子任务信息实现属性的联合识别. ③ 不增加应用阶段的计算量.
1.3 损失函数
行人属性识别是一种多标签分类问题. 对于这些属性,本文将其视为多个单独的二分类问题,考虑sigmoid交叉熵损失函数. 假设属性识别网络的输出是N×1的向量, 其中N是属性总数, 每个值对应模型给对应属性的预测得分:xn=xω+b. 经sigmoid函数映射为输出为0~1的概率, 即
(1)
损失函数部分的设计分为两部分,第1部分是全分类网络的损失函数loss_full,使用交叉熵损失函数衡量每个属性真值标记与预测得分之间的误差,即
(2)
式中:N为属性总数;n为式(1)中的属性预测得分经sigmoid函数映射的输出;Qn为真实标签.
第2部分是辅助分类损失函数loss_aux. 通过辅助分类损失函数的反向传播将各子网络限制关注自己组内的属性

(3)

最终的损失函数loss_total是2个分类网络损失函数的加权,即
loss_total=loss_full+loss_aux
(4)
2 实验分析
在本节中,将在2个公开数据集(DukeMTMC-attribute,Market-1501-attribute)上测试本研究方法的性能表现,其中包括与流行方法的比较以及自身的对比实验.
2.1 数据集介绍
Duke-attribute数据集和Market-1501-attribute数据集是在大学校园中监控场景下采集的大型数据集,行人身份大多是学生,但是季节存在显著差异,所以衣着服饰也存在多样性. 另外,由于是在实际监控场景下采集的行人图像,因此存在分辨率低、遮挡、行人重叠等问题,行人属性识别存在一定的挑战. DukeMTMC-attribute数据集中,16 522张图像作为训练集,19 889张图片作为测试集;Market-1501-attribute数据集中,19 732张图片作为训练集,13 328张图片作为测试集.
由于这2个数据集都采集于监控摄像头,距离远导致分辨率低,给属性标注工作带来一定的难度,因此存在部分颜色类标签不准确以及部位遮挡的情况. 且在监控场景下搜集的样本数据,颜色类属性存在极大的不平衡性,如图3所示,这对神经网络的识别干扰严重,故本研究虽然进行了颜色类属性的识别评估,也与其他方法的准确率进行了对比,但是由于所有方法在颜色类属性上的精度都很低,没有实际应用的意义,所以本研究不将上衣颜色属性和下衣颜色属性加入到整体的比较中去. 对比结果如表2所示,其中,APR*A代表不同的基础网络:APR*1,Resnet18;APR*2,Resnet34;APR*3,Resnet50.
2.2 对比实验
本小节在Market-1501和DukeMTMC数据集上进行了实验验证,并且与其他的方法进行了对比.
参考Zheng等[32]的实验参数配置,本研究使用在ImageNet数据集上预训练的VGG16网络权重进行初始化,优化器选择SGD优化器,并设置weight decay=5×10-4,Momentum=0.9. 并且将预训练网络层与新增网络层的学习率按照1∶10进行梯度的反向传播. 初始学习率设置为0.01和0.001,在经过20 000次迭代后,将各自学习率衰减为原来的1/10. 实验平台使用PC机(CPU: Intel(R) Core(TM) i5-10400 @ 2.90 GHz, GPU: GeForce RTXTM2070 super, 内存:32 GB, Ubuntu 18.04)
与其他方法的对比结果如表3、4所示,其中,“年龄*”表示4种年龄段属性(幼儿、青少年、成年和老年)的平均准确率. 通过对表3、4的分析,可以发现本文方法虽然没有在每个单项属性上都取得领先,但是达到了最高的平均准确率. 这说明本研究通过限制神经网络在每个子任务中的关注,成功地使得其对每个属性都有了足够的关注,进而使整体的识别性能得到很大的提升.

图3 各数据集颜色类属性的正样本数量Fig.3 Number of positive samples for the color attributes of each dataset

表2 Market-1501颜色类属性准确率
2.3 消融实验
2.3.1 验证预处理卷积模块有效性
本小节设置对比实验,验证共享低级卷积特征的有效性. 实验1采用将原始图像数据直接输入到4个子特征提取网络中去,进行特征提取;实验2采用先将原始图像数据输入到预处理卷积模块进行低级特征的提取,再送入4个子特征网络提取网络中去. 为保证实验的公平,本研究在2个实验的属性预测部分采用相同的策略,即均采用全分类网络和辅助分类网络的输出结构,且都训练相同的迭代次数. 实验结果如图4所示. 从图中可以明显看出,加入预处理卷积模块之后,不仅可以达到更高的识别精度,训练速度也大大加快,达到最高精度的时间更短. 所以,共享图像的低级特征可以更有效加强各任务之间的信息交流,达到更高的识别效果,还可以加快模型的收敛速度.

表3 在Market-1501数据集上的实验结果

表4 在DukeMTMC数据集上的实验结果对比
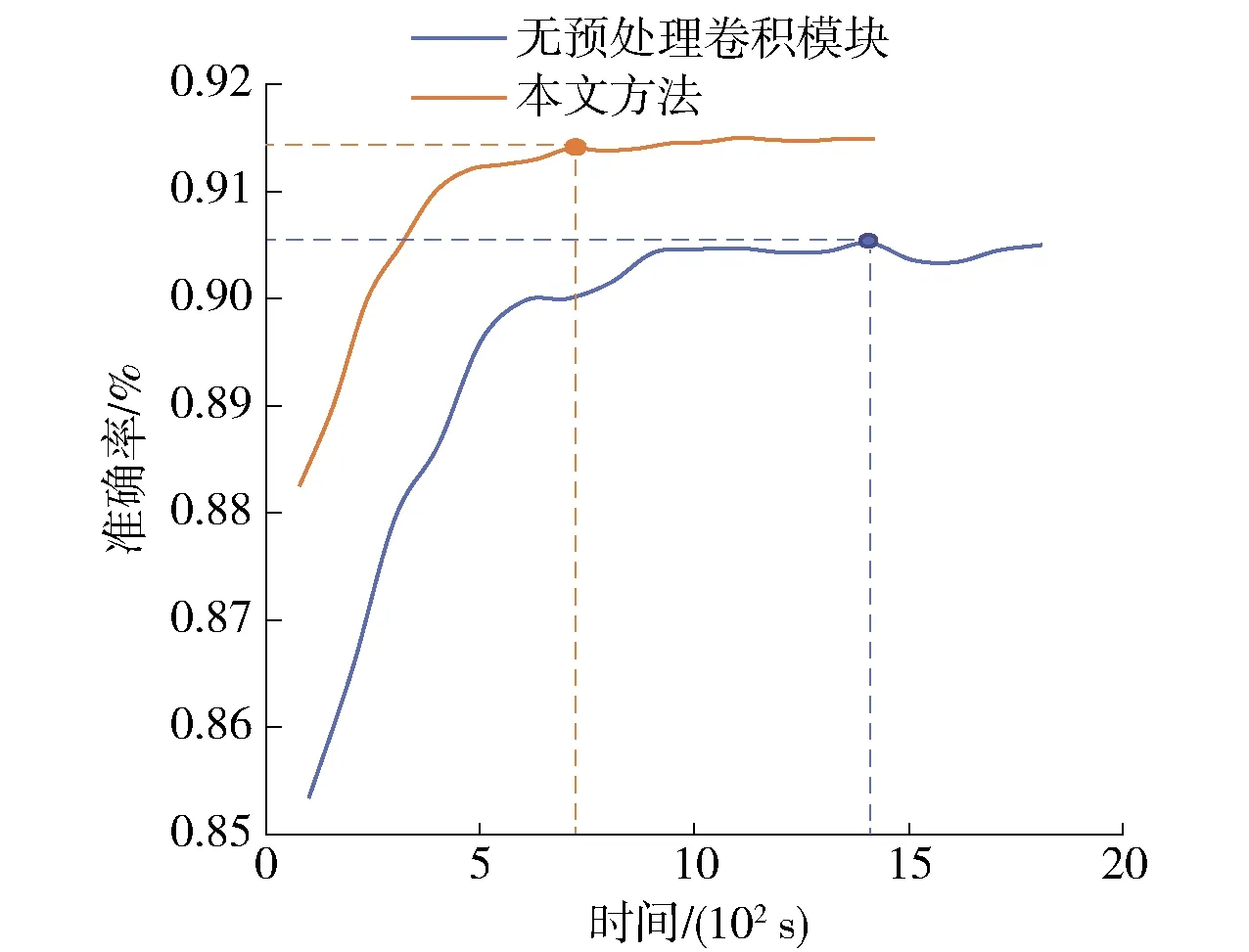
图4 预处理卷积模块的消融对比实验Fig.4 Ablation comparison experiment of preprocessing convolution module

图5 辅助分类模块消融实验准确率对比Fig.5 Comparison of the accuracy of the ablation experiment of the auxiliary classification module
2.3.2 验证限制关注区域方法的有效性
本小节通过消融实验来证明限制关注区域方法的有效性. 在控制其他模块不发生改变的情况下,设置3组实验. 实验1:删除辅助分类网络部分,直接使用全分类网络进行训练和测试. 实验2:删除全分类网络部分,仅保留辅助分类网络进行属性的预测. 实验3:全分类网络和辅助分类网络的联合训练,即本文提出的方法. 上述3组实验中,实验1可以限制深度神经网络(模型)只关注特定区域,而不去考虑与组间属性的联系性;而实验2与实验1相反,完全放开了深度神经网络的限制,使其可以自由地选择与其他属性进行特征信息的交换,无论是干扰或是促进. 实验3就是本文的方法,通过恰当的分组和损失函数的设计,让神经网络在一定的监督下,进行有限的“信息交换”. 实验结果如图5所示,从图中可以明显地看出,实验3具有最好的性能. 这证明了限制关注区域方法的有效性,即通过对神经网络施以一定的监督,可以达到更好的性能.
3 结论与展望
本文从机器注意的角度出发,提出一种新颖的限制神经网络注意的多任务行人属性识别方法,并设计了一个端到端的网络模型进行验证.
1) 该模型通过共享图像的低级特征,分别提取各属性组相关的高级特征,最后加入辅助分类网络,进行所有属性的融合识别,达到了最佳的属性识别精度.
2) 通过消融实验,证明了本文模型设计的有效性和合理性.
3) 端到端模型训练的简单性也为嵌入到其他行人任务上(例如行人重识别)提供了方便.
未来的工作计划解决以下3个问题:1) 研究一种更为可行的方法,解决多属性类不平衡问题;2) 研究多任务场景下,反向传播时的损失加权融合问题;3) 结合高精度属性识别模型改进行人重识别问题.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
电机与控制学报(2018年9期)2018-05-14
小天使·一年级语数英综合(2017年6期)2017-06-07
计算机应用(2016年10期)2017-05-12
