
一种用于解决特征选择问题的新型混合演化算法
2021-05-24 06:57:34李天翼陈红梅
郑州大学学报(理学版) 2021年2期
李天翼,陈红梅
(西南交通大学 信息科学与技术学院 四川 成都 611756)
0 引言
特征选择作为一种有效降低数据维度的方法,已广泛应用于机器学习、模式识别等领域,其主要任务是删除原始数据集中的不相关特征和冗余特征。根据评估条件,特征选择主要可以分为过滤、包装和嵌入式三类方法[1]。基于过滤模型的方法与分类器相互独立,这类算法会依照相应的评价函数对数据集中的每一个特征进行评估。包装型方法则利用指定的分类器,通过不同的搜索策略来评估特征子集。嵌入式方法是指特征选择算法将被结合到学习算法的训练过程中,旨在学习阶段评估特征子集。
假设数据集中的特征数量为n,则搜索空间中将包含2n个候选解。故使用穷举法来获得最佳特征子集显然是不切实际的。一些学者将特征选择视为组合优化问题,认为其目标是尽量减少特征数量并提高分类性能。因此在解决优化问题时体现出良好性能的演化算法受到了广泛的关注。如两种可以有效选择特征子集的二进制灰狼优化算法[2]、在寻优过程中引入二进制粒子群优化算法搜索最佳特征子集[3]、基于二维粒子群算法的特征选择方法[4]等。
但是演化算法也具有过早收敛、计算成本较高等缺点。此外,为提高获得全局最优解的概率,还需要平衡探索和开发之间的关系。近年来,学者们认为将不同的算法进行杂交、混合是获得更好性能的重要方法。混合型算法会利用并结合单一优化算法或策略的优势,同时更有效地平衡探索和开发的关系。如将鲸鱼优化算法与差分进化算法相结合以克服原始鲸鱼算法过早收敛的缺点[5];将灰狼算法与正余弦算法结合的新型混合方法以结合两种算法的优势[6]。混合型演化算法在聚类[7]、工程测试问题[8]、车间调度[9]、函数优化[10]、运动跟踪[11]、特征选择[12-13]等众多领域都有广泛应用。
本文提出一种基于包装模型的特征选择算法——HWOA。我们使用正余弦算法的位置更新方法代替鲸鱼算法的收缩环绕机制,并引入改进的灰狼优化算法增加搜索过程中的多样性。为加快收敛速度并增强算法跳出局部最优的能力,我们还引入非线性参数调整策略和混沌映射。在真实数据集上的实验结果表明,该算法在一定程度上提高了分类性能,同时有效降低数据维度。
1 相关工作
在本节中,我们将介绍本研究的相关工作,内容主要包括三个经典的演化算法:鲸鱼优化算法(WOA)、正弦余弦算法(SCA)和灰狼优化算法(GWO)。
1.1 鲸鱼优化算法
鲸鱼优化算法的灵感来自座头鲸的狩猎行为[14]。在开发阶段,鲸鱼使用泡泡网攻击方式,通过产生圆形或“9”字形路径来包围猎物。这对应了收缩环绕机制和螺旋更新机制两种不同的方式,我们假设选择两种方式的概率相等,均为50%,则搜索代理的下一位置计算为
其中:X*表示当前最优解的位置;X表示当前鲸鱼的位置;t表示当前迭代;b是用于定义螺旋线形状的常数;l是[-1,1]中的随机数;p是[0,1]中的随机数;A=2·a·r-a和C=2·r是两个系数向量;r是一个取值在[0,1]中的随机向量,a负责平衡探索和开发之间的关系,在迭代过程中线性地从2递减至0。
在探索阶段,原始算法中的搜索代理可以利用向量A的变化来搜索猎物。当|A|>1时,当前鲸鱼会随机地选择其他鲸鱼的位置作为目标位置,即在探索阶段会迫使搜索代理远离当前的最优解,其数学模型为Xt+1=Xrand-A·|C·Xrand-Xt|,其中:Xrand是从当前群体中随机选择一个搜索代理的位置向量。
1.2 正余弦算法
正余弦算法是Mirjalili于2016年提出的一种新型优化算法[15]。该方法会创建不同的初始随机解决方案,并要求他们使用基于正弦或余弦函数的数学模型向外波动或朝向最佳解决方案前进,位置更新公式为
其中:Xt是第t次迭代时搜索代理的位置;X*t是目标全局最优解决方案;r1、r2、r3、r4均为[0,1]内的随机数。
1.3 灰狼优化算法
灰狼优化算法(GWO)是Mirjalili等通过模拟灰狼种群的社会等级和狩猎行为提出的随机算法[16]。根据社会地位从高到低排列,灰狼种群可分为四个级别:Alpha、Beta、Delta和Omega。在传统灰狼算法中,具有最佳适应度的解定义为Alpha,排名第2、第3的解分别定义为Beta和Delta,这三者也被称为优势狼。其余的候选解被视为Omega。灰狼包围猎物的行为可以描述为Xt+1=Xpt-A·|C·Xpt-Xt|,其中:t表示迭代次数;X是灰狼的位置;Xp是猎物的位置;A=2·a·r1-a和C=2·r2是两个系数向量,r1与r2是两个取值均在[0,1]中的随机向量。
在狩猎阶段,我们假设优势狼对猎物的潜在位置有更多的了解,Omega狼则需要根据优势狼的位置更新各自的位置。灰狼狩猎的数学模型为Xt+1=(X1+X2+X3)/3,其中:X1=|Xα-A1·|C1·Xα-X||。X2与X3的计算方法与X1类似。
2 提出新型特征选择算法
在本文中我们将鲸鱼优化算法与正余弦算法、改进后的灰狼优化算法进行结合,提出一个新型的混合演化算法——HWOA。此外,我们还引入参数的对数衰减调整方案,并使用混沌映射调整位置更新公式中的权重参数。最终我们将该方法应用于解决特征选择问题。
2.1 演化算法的混合
正余弦算法已被证实在开发阶段表现良好。而在原始鲸鱼算法的迭代初期,由于控制参数的值较高,更倾向于探索,因此更需要平衡探索和开发的关系。此外,鲸鱼算法将在探索阶段随机地选择“鲸鱼”,并以此为参考对其他搜索代理进行更新,这使得算法在早期搜索中具有过高的偶然性,最终导致创建一些质量较差的解。因此我们使用正余弦算法的位置更新方案代替了原始鲸鱼算法中的收缩环绕机制。由于螺旋更新机制使用对数螺旋函数,在较短时间内能覆盖较大范围的搜索空间。故在HWOA中将保留螺旋更新机制。
为增加搜索方式的多样性并避免算法陷入局部最优,我们还引入了一种改进的灰狼优化算法。在传统的灰狼算法中,由于种群对全局最优解的过度学习,算法易陷入局部最优。受到粒子群算法的启发,我们将个人最佳位置(pbest)的概念加入到位置更新公式中。为更好地反映灰狼种群的社会等级,我们还引入一组权重参数(w1,w2,w3)。这三个参数分别表示Alpha、Beta和Delta在狩猎行为中的决策权重,且需要满足条件0≤w3≤w2≤w1≤1;w1+w2+w3=1。
改进灰狼算法的位置更新为Xt+1=w·X′+c1·rand1·(Xpbest-Xt)+c2·rand2·(X1-Xt),其中:X′=w1·X1+w2·X2+w3·X3;Xpbest表示当前搜索代理的个人历史最佳位置;w表示惯性权重;t表示当前迭代;c1和c2称为学习因子,其值为0~4;rand1和rand2是[0,1]中的随机数。
2.2 有效的参数调整策略
首先,学术界已经证实惯性权重w对于准确地寻找全局最优解起到重要作用,而在原始的粒子算法中w是在一定范围内线性递减或者取某个固定值。为提高整体多样性并增强算法避免陷入局部最优的能力,混沌理论中的逻辑映射被用于非线性地更新参数w,wt+1=μ×wt×(1-wt)。
其次,作为平衡探索与开发关系的控制参数a,在原始算法中线性地从2递减到0。为提高开发效率,我们选择对数衰减函数对a进行非线性更新,描述为
其中:a0表示参数a的初始值;af是参数a的最终值;max_iter表示最大迭代次数。
2.3 应用于特征选择问题
由于特征选择问题是二值优化问题,我们会把位置向量中值为1处相应的特征选入特征子集中,否则将其删除。为实现将位置向量中的连续值转换为离散值,我们使用Sigmoid函数转换为
另一重要问题是选择合适的适应度函数。特征选择作为组合优化问题,主要目标是提高后续的分类性能,并选择尽可能少的特征。在本项研究中,适应度函数描述为fitness=αER(D)+β|S|/|F|,其中:ER(D)是分类器的分类错误率;|S|表示所选特征子集中的元素数量;|F|表示原始特征集中的特征数量;α和β是平衡错误率和所选特征比之间关系的参数,且α+β=1,一般参数的经验值取α=0.99。
2.4 算法流程
结合前文所述,本部分给出HWOA算法的实现流程。
1)初始化相关参数和种群;
2)根据概率参数p与0.5之间的定量关系选择不同的位置更新方法;
3)如果p<0.5,则使用SCA算法对当前搜索代理进行位置更新;
4)如果p≥0.5,则根据系数A的绝对值和1的定量关系选择WOA的螺旋更新机制或改进的灰狼算法;
5)如果|A|<1,我们使用螺旋更新方式,否则使用改进的灰狼算法,注意更新相关参数;
6)对每个搜索代理执行上述操作之后,通过Sigmoid函数离散位置向量;
7)计算每个搜索代理的适应度函数值,根据该值对代理进行升序排序;
8)更新当前排名适应度值前三的搜索代理,并更新每个搜索代理的个人历史最佳位置(pbest);
9)确定是否满足停止条件,若满足则输出当前最优解作为结果,否则根据上述过程再次执行算法。
3 实验与结果
在本节中,我们使用本文提出的HWOA算法与其他6个基于包装模型的特征选择算法在11个UCI数据集上进行对比实验,给出实验结果并进行分析。
3.1 数据集介绍
为验证特征选择方法的有效性,我们需要在真实数据集上进行对比实验。表1展示了11个用于实验的真实数据集,他们来自UCI机器学习存储库,具有不同数量的实例和特征。数据集的详细信息如表1所示。

表1 UCI数据集描述
3.2 参数设置
由于我们提出的算法基于包装模型,因此算法需要与指定的分类器配合才能完成特征选择任务。本文中我们选择基于欧氏距离矩阵的KNN分类器(K=5)。为了进行对比实验,我们选择了6种对比算法(SCA、BGWO、BPSO、HGWOSCA、SCWOA和HPSO-WOA)。此外,我们使用10折交叉验证来评估所选特征子集的性能。所有参数均设置为经验值,种群数量定义为10,迭代次数设置为100次,每个算法重复执行20次。粒子群算法中的学习因子设置为1.5,控制参数a的初始值为2.0,惯性权重w的初始值为0.9。
3.3 评价指标
特征选择的评估标准的名称与计算公式如下。

3.4 实验结果与分析
实验结果见表2~9,表中的黑体数字表示该行中的最佳值。


表2 每种特征选择方法的平均分类正确率及标准差

表3 每种特征选择方法的平均特征子集大小
3.4.3适应度函数值(Mean、Best、Worst)的对比 基于包装模型的特征选择算法的另一个重要评估标准是适应度函数值。表4展示的是平均适应度值,实验数据表明HWOA算法可在9个数据集上获得最优值,且平均效果依旧最佳。此外,我们发现BPSO和HPSO-WOA的性能较差。尽管他们选择的特征子集维度很低,但在分类正确率和适应度函数值的比较中,他们的表现均不理想,说明这两种算法并没有选择出最合适的特征子集。

表4 每种特征选择方法的平均适应度
表5展示了算法的最佳适应度函数值。如我们所见,HWOA在本项比较中没有明显的压倒性优势,但是它的平均最佳适应度函数值仍排名第1。值得注意的是,对于某些数据集(例如breast-cancer、CMC等),不同的算法可能会实现相同的最佳适应度函数值。

表5 每种特征选择方法的最佳适应度
表6展示了最差适应度函数值。根据表6中的实验数据,HWOA在最差的适应度函数值方面表现良好,且在8个数据集中获得了最佳结果。这也在一定程度上表明HWOA具有更好的稳定性。尽管有时无法达到最佳适应度值,但其下限较高,说明HWOA不会产生太多质量较差的解。
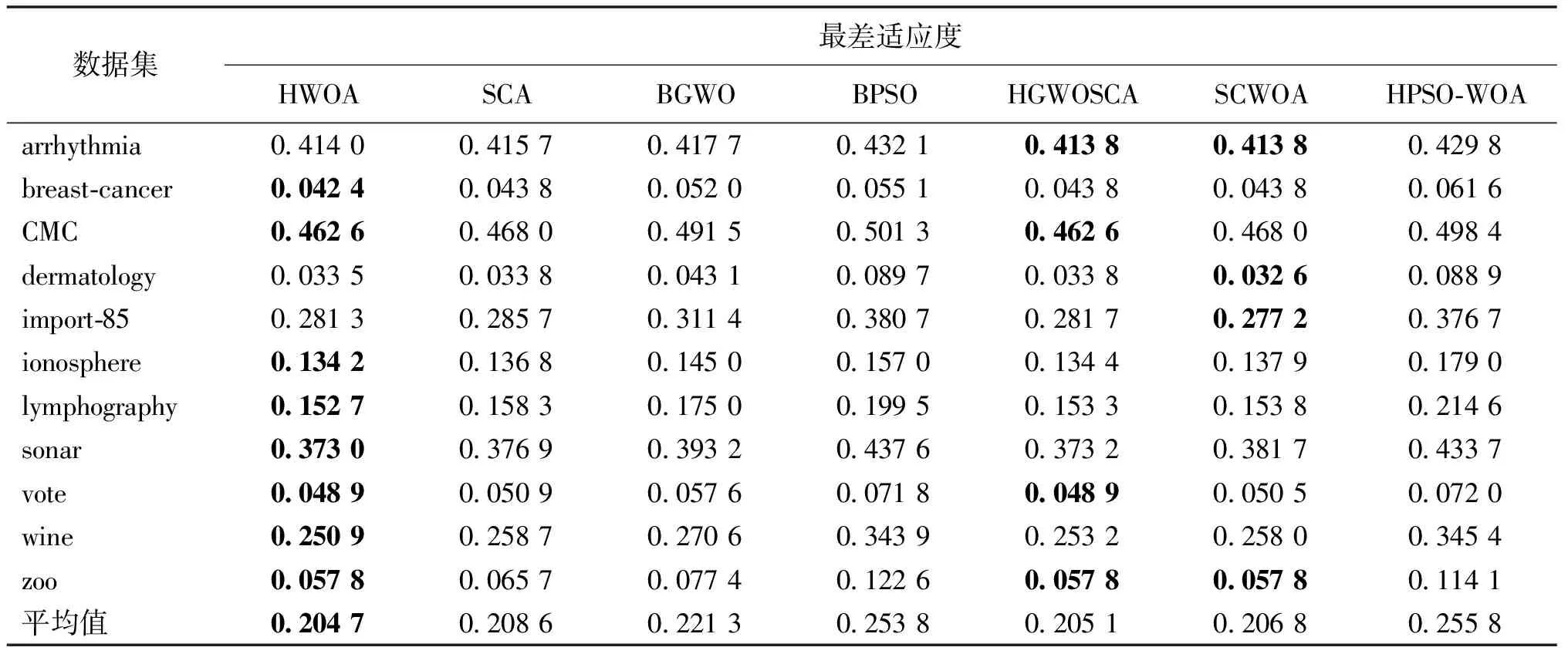
表6 每种特征选择方法的最差适应度
3.4.4特征选择结果的可解释性 本文所提出的算法是基于包装模型的群智能优化算法,它本质上属于元启发式算法。这类算法的一个重要特点就是算法中会存在随机因素,即使是固定的输入(即同一个数据集、相同的迭代次数、相同的参数初始值),选择的特征子集依旧会存在差异。因此表7展示的内容包括HWOA算法在20次执行中获得的最高分类正确率、最佳适应度函数值,以及此时对应的特征子集。表中{}内的数字即为所选特征在原始数据集中序号。为节约空间,若序号从x到y的特征均被选择,则简写为x~y。即{1~3}表示一个特征子集,其中包括序号为1、2、3的特征。

表7 HWOA算法获得的最佳特征子集
3.4.5迭代初期解的质量对特征选择结果的影响 在算法初始,我们根据每个位置设置的随机数随机生成当前个体的位置向量。因此算法在迭代初期具有随机性,获得的解也具有随机性。表8展示对应不同数据集,每个算法迭代早期的适应度函数值(AvgF)。通过表8我们可以发现,BGWO算法在迭代初期的平均适应度函数值较低,获得的解质量更高。HWOA、SCA、HGWOSCA和SCWOA 4个算法在迭代早期的平均适应度值比较接近。但是从表4展示的结果我们发现,当迭代次数设置为100时,BGWO算法只在arrhythmia数据集上获得最佳平均适应度函数值,而HWOA算法则在9个数据集上获得最佳值。这说明迭代初期解的质量对特征选择的最终结果无显著影响,早期获得质量更优的解并不意味着最终可以达到更好的特征选择效果。
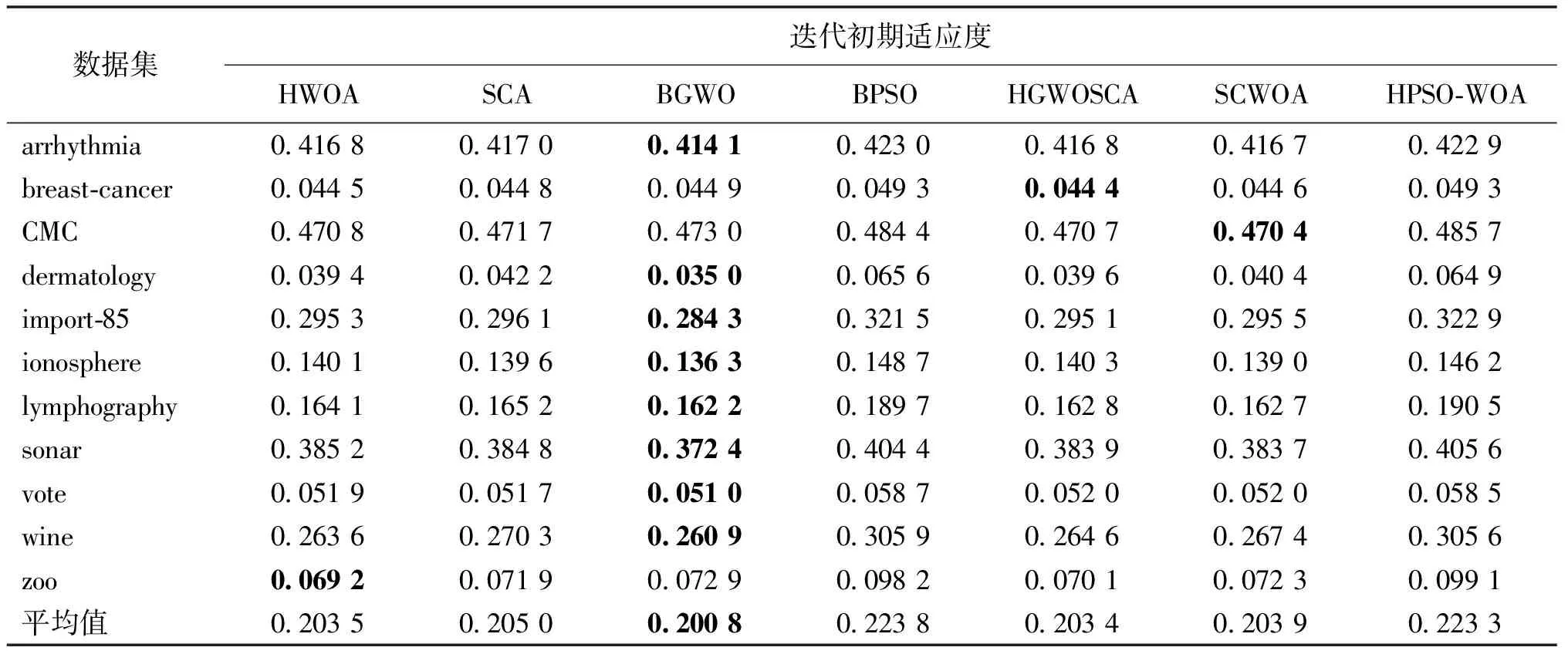
表8 每种特征选择方法迭代初期的适应度函数值
3.4.6显著性检验 为了更好地说明本文特征选择方法性能的普遍优越性,下面给出详细的Friedman检验和Nemenyi后续检验结果(本文选用显著性水平α=0.1)。首先,根据表2的平均分类正确率对实验涉及的7个算法在11个数据集上测得的分类精度高低进行排序并赋值,具体结果如表9所示。

表9 不同数据集上算法性能排序结果
若算法性能相同则其平均序值相同,且第i个算法的平均序值ri服从自由度为(k-1)和(k-1)(N-1)的F分布。由表9数据可知各个算法的平均序值不同。由Friedman检验可知,各类算法的性能显著不同,需要进行后续的Nemenyi检验。利用Nemenyi检验计算平均序值差别的临界值域CD,其计算公式为
(1)
其中:k表示算法的个数;N表示数据集的个数;qa是一个由k值和显著性α共同决定的参数。在本文中,k=7,N=11,查表可知,当k=7时,qa=2.693(α=0.1)。代入公式(1)中,得到临界值CD=2.481。
比较HWOA算法与其他对比算法间的平均序值差,结果可得,除与SCWOA和HGWOSCA算法的序值差小于CD外,其余均大于临界值CD,故“两个算法性能相同”的假设被拒绝。说明本文特征选择方法性能显著优于其余算法,但与SCWOA算法和HGWOSCA算法相比优势并不明显。
4 总结
本文提出了一种基于包装模型的特征选择算法——HWOA。我们将正弦余弦算法、鲸鱼优化算法和改进后的灰狼优化算法进行混合,以利用不同算法的优势,提高算法的搜索能力,进而获得质量更优的解。同时引入逻辑映射和对数调整策略更新参数,以避免算法陷入局部最优。实验结果表明,该算法在一定程度上提高了分类性能。就适应度函数值的比较而言,HWOA也获得较好的性能。此外,对标准差结果的分析也证实了该算法具有较好的稳定性。将来我们考虑使用不同的混沌映射来调整相关参数,并尝试使用量子编码。
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
小太阳画报(2019年1期)2019-06-11 10:29:48
数学大王·低年级(2018年5期)2018-11-01 10:34:06
电子制作(2017年23期)2017-02-02 07:17:06
快乐语文(2016年15期)2016-11-07 09:46:31
西北工业大学学报(2015年4期)2016-01-19 03:31:47
都市丽人(2015年4期)2015-03-20 13:33:22
读写算(中)(2015年6期)2015-02-27 08:47:14
