
互联网存档中的视频采集研究
2021-05-23 12:23杨云鹏
新世纪图书馆 2021年3期

摘 要 随着互联网的快速发展和网络带宽的逐年增加,网络上视频内容逐渐增多,更多的内容从纯文本网页发布变为文本加视频发布。但是,互联网存档很难采集到网络视频,这些视频通常使用非标准工具和协议。本文提供了该领域采集技术的概述。基于几年采集网络视频内容的经验,本文提供了HTTP协议和RTMP协议视频采集的示例,阐述了采集网络视频内容的问题和解决方案。本文还提出了一种外部下载器作为视频采集模块,用于扩展网络视频内容采集。
关键词 互联网存档 网络视频 流媒体 视频采集
分类号 G250
DOI 10.16810/j.cnki.1672-514X.2021.03.04
Research on Video Collection in Internet Archiving: Taking National Library of China as an Example
Yang Yunpeng
Abstract With the rapid development of the Internet and the increase in network bandwidth year by year, video content on the Internet has gradually increased, and more content has changed from publishing plain text web pages to publishing text plus video. However, it is difficult for Internet archives to capture network videos, which usually use non-standard tools and protocols. This article provides an overview of acquisition techniques in this field. Based on years of experience in collecting network video content, this article provides examples of HTTP protocol and RTMP protocol video capture to illustrate the problems and solutions of collecting network video content. This article also proposes an external downloader for video capture module, which is used to expand network video content capture.
Keywords Internet archive. Web video. Streaming media. Video capture.
0 引言
視频已成为当今网络的重要组成部分。视频为了免于被盗版,一般都会采取加密传输的方法,免于用户直接访问视频源文件。这就使得Web档案管理员收集视频内容的任务变得更加困难,需要开发特定的方法和工具[1-2]。
本文的目的是讨论在网络上视频采集的难点。根据过去几年在国家图书馆网络采集中获得的经验,我们将视频采集中所遇到的问题分为两个主要类别,并使用一些典型的例子说明了几种技术解决方案。第一类使用标准HTTP协议传递视频内容的网站,其难点在于使用混淆视频文件链接的技术(例如:2或3跳跃重定向)。第二类问题是使用HTTP以外的传输协议的网站,从互联网上当前使用的各种流协议中,我们选择了最新且困难的RTMP流协议作为示例。值得注意的是,用于在网络上保存视频的技术发展得非常快,这里介绍的案例很可能在细节上迅速发生变化,我们的工具需要不断改进和更新。但是,其蕴含的原理,将帮助我们不断优化采集方法。
在本文的第二部分中,我们提出了一种体系结构设计以解决该问题,即将视频解耦下载下来,从而实现快速适应性和可伸缩性。这种设计原理更易于集成和更新,在可扩展性和灵活性方面都得到了很大的提升,进一步提高了效率。同时,与采集器同步工作为错误处理和流程管理提供了更好的支持。
1 视频采集方法
1.1 HTTP协议视频网站采集策略
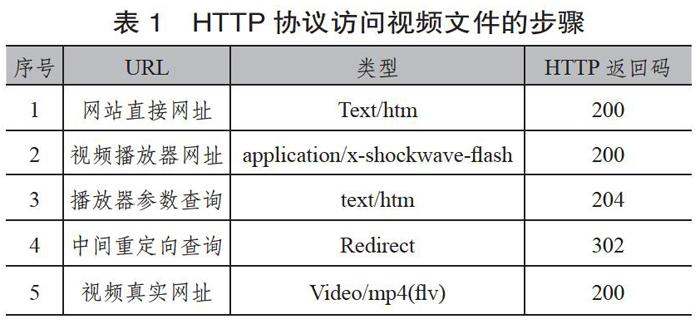
每个视频均由散列标识符唯一标识,并且通常可以在HTML页面中使用URL进行访问,该URL类似于http://www.*.com/uniqueID,采集网站视频时最困难的是访问视频的机制不断更新[3],需要不断努力隐藏视频文件的直接URL。使用经典的采集方法,爬虫必须遵循5个不同的直接链接或重定向步骤,才能实际访问视频内容。表1总结了中间URL的一般模式。
知道了视频标识符(foobar)和网站页面的URL(序号1),采集程序首先发现页面中使用的Flash播放器的URL(序号2)。从传递给播放器的参数列表中,采集程序可以标识出请求视频内容时要使用的HTMI查询(序号3)。在真正获取视频文件的URL(序号5)之前,采集程序必须提供包含编码令牌的中间重定向(序号4),例如主机的IP地址和请求的时间戳。视频的URL(序号5)集成在Flash参数中,该Flash参数在加载页面(序号1)时动态生成。采集程序主要问题在于正确识别此URL,因为它包含不同的转义字符,并且与Flash对象解释的其他参数混合在一起。例如,在当前视频网站页面中,“flashvars”参数的字符串长度为6374个字符,而要匹配的URL包含392个字符。在对页面(序号1)进行分析时,还可以在生成Flash参数的JavaScript片段中标识视频的URL(序号5)。在网站页面中,要解析文本行包含的“PLAYER_CONFIG”字符串,其后是随机排列的URL列表。在两个(“|”)字符之间,可以根据IP地址和时间戳提取视频的URL,该URL已经包括计算出的令牌。
可以看到,获取视频文件的路径是曲折的,视频资源的URL因为被重定向和添加临时令牌而混淆。在采集参数方面,这可以将采集程序修改为5级深度抓取视频网站。此外,序号2,序号4和序号5中的URL指向不同的子域,因此需要将它们显式添加到采集的范围内。
重定向生成的URL还存在一个问题,就是存档重放工具访问的问题。即使每个视频文件在网站上都得到了唯一标识,但是每次下载时会由于时间戳而动态生成不同的URL。因此,需要在URL索引中添加显式引用,以保持原始页面(在序号1中)和视频文件的URL(在序号5中)之间的联系。
在实践中,有两种方法可以在HTTP协议的视频网站上进行视频存档:在线视频采集技术和离线下载视频技术。在线采集视频技术采集过程中,视频文件是在爬网时使用Heritrix软件的附加处理器进行下载。例如,由亚当·泰勒编写的beanShell脚本会将所有中间URL(序号2~5)注入边界,因为中间跃点通常不在当前爬网范围内。视频文件将直接添加到采集程序的WARC文件中。离线方法首先根据网站页面的URL下载视频文件,然后在后期进行加工处理。它使用由里卡多·加西亚·冈萨雷斯开发的外部下载器,该下载器采集视频内容并将其转储为flv文件,然后使用WARC Tools工具将flv文件打包到不同的WARC文件中。两种方法都需要视频的原始URL(如出现在网页中)和文件名或指向视频内容的URL新生成链接。
在线采集方法的优点在于,视频文件的下载是由采集程序自身完成的,并且不需要其他外部工具监视和同步。此外,在与网站服务器进行对话之后,所有HTTP标头都存储在存档中。这种方法的缺点是视频内容的最终URI(如序号5)不再包含视频的原始标识符(如序号1),回溯视频标识符变得难以管理,归档文件也被所有重定向URL污染(它们不再是有效的URL,因为下载令牌的有效性受到限制)。离线方法在监视和管理外部下载程序(例如错误处理)方面提供了更大的灵活性。视频文件保留其原始标识符的名称,并且重定向URL不存储在存档中。由于外部下载程序不保留服务器响应,因此需要在每个存储flv文件的WARC文件中插入一个“假”HTTP头。
1.2RTMP协议视频网站采集策略
1.2.1 网络视频流协议概述
与互联网工程任务组(IETF)标准相对应的流技术允许服务器控制传输,并进行了严格的优化以保持实时运行。客户不必下载潜在的巨大文件,这种方法特别适合现场直播。实际上,流传输通常使用两种类型的实时流协议:实时传输协议(RTP)[rfc3550]发送媒体数据包,以及实时流协议(RTSP)[rfc2326]作为控制信息。RTP使用潜在的有损UDP,该UDP不会尝试重新传输丢失的数据包,因此系统被设计为可以承受传输期间数据包的丢失。这意味着客户端要能够很好地处理只获取到部分视频帧或音频样本数据的情况。这比基于TCP/IP的方法更好,后者可以进行不確定的重试次数(从而花费不确定的时间)来获取丢失的数据包。
实时流协议(RTSP)是一种网络控制协议,用于娱乐和通信系统,以控制流媒体服务器。该协议用于建立和控制两端之间的媒体会话。媒体服务器的客户端发出类似于VCR的命令,例如播放和暂停,以便于实时控制服务端的媒体文件的播放[4-5]。
RTSP协议与HTTP相似,但是RTSP添加了新的请求。HTTP是无状态的,而RTSP是有状态的协议。会话标识符用于在需要时跟踪会话,因此,不需要永久的TCP连接。RTSP消息从客户端发送到服务器,只有少数情况下会从服务器发送到客户端。
多媒体消息服务(MMS)是用于发送带有多媒体对象(图像,音频,视频,富文本)消息的电信标准。MMS是SMS标准的扩展,允许更长的消息长度,并使用WAP显示内容。MMS消息的发送方式几乎与SMS相同,但是首先要将所有多媒体内容进行编码,然后以类似于发送MIME电子邮件的方式将其插入文本消息中。
实时消息协议(RTMP)是Adobe Systems开发的一种专有协议,用于在Flash播放器和服务器之间通过互联网传输音频、视频和数据[6]。为了保证视频和音频流的平稳传递,同时保留传输更大信息块的能力,该协议可以将视频和数据拆分为片段。首先所用片段的大小可以在客户端和服务器之间动态协商,如果需要,甚至可以完全禁用它们。然后,来自不同流的片段可以在单个连接上交错和多路复用。Adobe于2009年6月15日开放了RTMP协议的规范,但该规范似乎省略了协议实现的许多细节。
1.2.2 采集RTMP网络视频
根据国家图书馆采集程序对视频采集的研究,本节将介绍基于RTMP协议进行视频网站采集的一些技术细节。
(1)视频页面布局。显示视频的Web页面的结构与HTTP协议网站的相同。HTML页面包含一个主视频面板,其中包括原始视频播放器。每个HTML页面的内容由服务器动态生成,并存储在特定的HTML元素中[7-8]。将Flash Player嵌入到
(2)下载流媒体视频。从爬虫的角度来看,视频文件的URL清晰地写在了JavaScript片段内,这代表了一种有利的情况,因为JavaScript提取器能够识别和提取视频文件的URL。但是,此URL并不是采集程序的有效URL,因为它不支持HTTP/HTTPS以外的协议方案。因此,RTMP URL将在采集的错误日志中报告为无效URL。为了有效地下载视频文件(rtmp://…/foobar-video.flv),将RTMP URL从错误日志中过滤掉,并传递给外部下载器(即FLVStreamer),RTMP下载器需要先将视频内容转储到flv文件中,然后再将其打包存储到WARC文件中。
(3)访问存档中的视频内容。从访问的角度来看,实时网页和已存档网页之间的根本区别在于用于将视频内容交付给播放器的传输协议。在存档的基础架构上部署流服务器需要大量的工作,这是一个开发和维护成本昂贵的解决方案。它还需要针对不同的协议运行不同的服务器。为了实现通用,我们通过HTTP协议对存档视频内容进行访问,并且flv文件与HTML页面及其他资源一起直接从WARC文件提取出来。流媒体的特定功能已丢失(例如快进或增量下载),但是可以确保对视频内容的基本访问,并且可以适应不同的情况而不需要额外的工作。
对于大型视频来说,用纯HTTP代替流媒体的一个重要缺点变得显而易见。如果未进行任何改编,播放器需要在开始播放视频之前加载整个flv文件。我们已调整了访问工具,通过增量地从存档中加载视频文件的块来缓解此问题。块的大小是优化的关键,但是在更快地访问视频和缓冲方法的复杂性之间需要权衡取舍。
在访问时,要进行的主要调整是更换原始Flash Player。由于已存档的视频文件不再流媒体传输,因此页面上的原始播放器无法在存档的版本上使用,HTML容器需要相应地更新。
与实时页面相比,在存档版本中,用包含存档特定播放器的特定