
一种基于卷积神经网络的环境声音分类方法*
2021-05-21 01:20:00敏邓伟赵
电子器件 2021年2期
朱 敏邓 伟赵 力
(1.常州信息职业技术学院电子工程学院,江苏常州 213164;2.东南大学网络空间安全学院,江苏南京 210096)
近年来,自动环境声音分类问题越来越受到科研人员的广泛关注。目前其应用范围包括情境感知计算[1]和监控[2]、智能声学传感器网络实现的噪声缓解[3]。
目前已经有多种方法应用于环境声音分类的问题,包括矩阵分解[4-6],字典学习[7-8],小波滤波器组[8-9]以及深度神经网络[10-11],还有很多与环境声音分类类似的研究[12-14]。根据许多研究结果,深度卷积神经网络原则上非常适合环境声音分类的问题[15]:首先,其能够捕获跨时间和频率的能量信息;其次,通过使用具有小的感受野的卷积核,神经网络能够学习识别代表不同声音类的时域-频域模式[16]。然而,卷积神经网络在环境声音分类中的应用还受到很大的限制。例如,Piczak K J[11]提出CNN 结构获得的结果没有明显的提升。
具有较好分类效果的深度神经网络尤其依赖于训练集的数据量。CNN 模型应用于环境声音分类效果有限的一方面原因可能是具有标记的环境声音数据集较小。虽然近年来不同的研究机构已经发布了几个新的数据集[17-18],但它们仍然比其他领域(比如图像分类[19])可用于研究的数据集小得多。
数据增强是上述问题的一个可行方案,即将一个或多个数据转换应用于具有标记的训练数据集合,用以产生额外的训练数据[19-21]。数据增强的关键点在于标记数据的变形不改变其语义含义,使其仍属于已有的标签。以图像为例,汽车的旋转、平移、镜像或缩放图像仍然是属于汽车类别的图像,因此可以应用这些变形来产生额外的训练数据。音频领域已经提出了使语义不变的数据变形,并且已经提升了音乐分类任务的模型精度[21]。然而,在某些环境声音分类的情况下,数据增强的应用相对有限[11-22],Piczak K J[11]使用时移,音高变换和时间拉伸的随机组合来增加数据,得出结论:简单的增强技术被对UrbanSound8K 数据集效果不佳,因为它们产生的训练时间大大增加,而对模型精度的影响却可以忽略不计。
提出了一种深度卷积神经网络结构,对ESC-50 数据集进行分类。此外,应用数据增强来克服数据稀缺的问题,并探索不同类型的音频变形及其对训练得到的模型性能的影响。展示了所提出的CNN 与音频数据增强相结合的方法,使得环境声音分类效果得到显著提升。
1 数据增强
数据增强用于提高训练数据的数量,如果训练数据质量较高,则系统的准确性也会变高。数据增强本质上是一种变形技术,通过这种变形,我们能够成倍地增加数据集的数据量。
我们应用了3 种不同的数据增强方法来扩展数据。数据增强的重要前提是在数据变形后应保持语义有效性。4 种音频数据增强方案描述如下:
音高变换(PS1):通过这种增强,音频样本音高被改变,使得降低或提高数据样本的音高而音频的持续时间应保持不变。本次实验中所有音频样本的音调移位值为1.5。
音高变换(PS2):在这个变换中,所有音频样本的音调偏移值越大。移位值为2.5。
高斯噪声(GN):该变形可以在原音频样本中添加高斯噪声。
2 卷积神经网络
卷积神经网络[23](CNN)建立在多层感知器(MLP)的架构之上。CNN 可以在2 个阶段发挥重要作用。第1 个是特征提取阶段。过滤器窗口在输入上滑动,并在每个位置提取卷积的总和,然后将其存储在特征图(features map)中。卷积层后通常为池化,其中通常采用每个窗口中的最大值,这减小了特征图大小但保留了重要数据,从而降低了网络的维度,这意味着减少了训练时间和过度拟合的可能性。最后是分类阶段,这时网络中的三维数据已降维成要输出的一维向量。所用卷积神经网络的大致流程如图1 所示,其中类似的中间层在整个结构中重复4 次,每一层中间层均为卷积层(convolution)、最大池化层(maxpooling)、舍弃层(dropout)的组合,如图1 所示。上述重复的3 层组合的详细参数会在后续介绍。
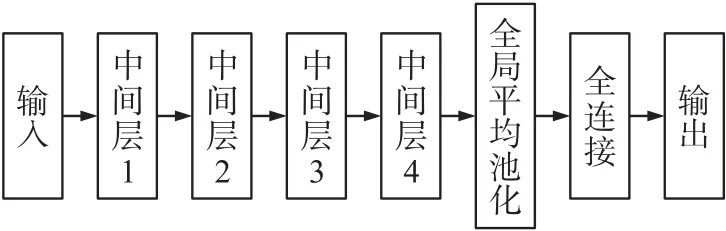
图1 深度卷积神经网络的流程图
2.1 卷积层
卷积层是CNN 网络的核心,卷积层的参数由1组可学习的滤波器组成,它们具有小的感受野,延伸到输入容积的整个深度。在每一层卷积层的filter_size 和kernel_size 都为2。在前向传播期间,每个滤波器对输入进行卷积运算,计算滤波器和输入之间的点积,并产生该滤波器的二维激活图。简单来说,卷积层用来对输入层进行卷积,提取更高层次的特征。
对于第l层卷积层,其输入通常为前一层卷积层的输出特征图。通过将本层的若干个卷积核与输入特征图进行卷积运算,得到输出特征图。记第l层卷积层的第i个特征图为,其前一层卷积层的第j个特征图为表示卷积核,则的计算如式(1)所示:
把芋梗用草捆扎起来的时候,母亲对我说:“这是西北雨,如果边出太阳边下雨,叫作日头雨,也叫作三八雨。”接着,她解释说:“我刚刚以为这阵雨不会下到芋田,没想到看错了,因为日头雨虽然大,却下不广,也下不久。”

2.2 激活函数
卷积实际上是一种线性操作,机器学习中必须将一个特征空间的向量通过非线性变换映射到另一个空间才能实现线性可分。激活函数就是引入非线性的手段。传统的sigmoid 函数容易造成梯度消失。为了解决梯度消失的问题,一种更有效的激活函数修正线性单元(Rectified Liner Units,ReLU)被引入,定义函数如式(2)所示:
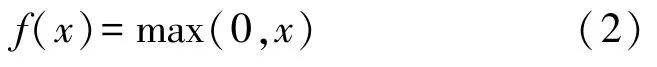
ReLU 函数的导数如式(3)所示:
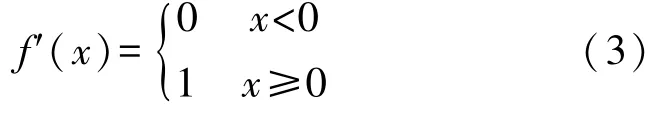
当x取负值时,就相当于直接封闭了节点,而当x取零或正值时,由于函数导数始终是1,就完全避免了梯度消失问题。AlexNet 的论文中也提到,对于同一个网络结构,使用ReLU 作为激活函数,其收敛速度要比使用tanh 快6 倍以上。以上优势使得ReLU 成为现在所有CNN 模型首选必备的激活函数。
2.3 池化层
池化即为降采样,可以达到降维的目的。池化窗口大小为2×2,处理后的矩阵的长和宽都是原矩阵的1/2,输出矩阵的尺寸是矩阵的1/4。对于池化来说要使特征提取拥有平移不变性。
池化将原特征图以不同的方式聚合,没有算术运算过程,所以池化层本身没有可学习的参数,在误差反向传播过程中,池化最重要的工作是计算并传递误差。定义两种不同的采样操作符:down(.)表示前向推理过程中池化层的下采样操作,利用最大池化或平均池化,up(.)表示误差反向传播过程中对自上层的误差信号的上采样操作,数学表示如式(4)所示:

第一层卷积层的卷积核大小为2×2,有16 个卷积核,所以第一层在输入为40×250×1 的情况下,输出16 个特征图,则输出维度为39×249×16,而池化的窗口大小为2×2,即特征图维度减半,池化后输出19×124×16,如图2 所示。
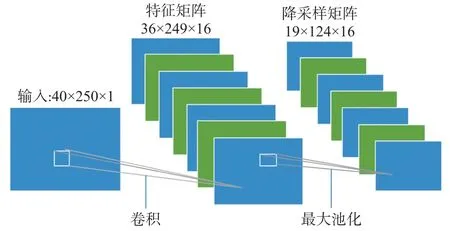
图2 卷积层与池化层组合的过程图
由于提出的CNN 结构是以上卷积层加池化层的4 次重复,图2 展示的是第1 层卷积加池化的过程。第2 层卷积核个数为32 个,所以第2 层卷积层的输出为18×123×32,再经过第2 层池化后输出为9×61×32,第3 层卷积核个数为64,则第3 层的卷积输出为8×60×64,第3 层池化输出为4×30×64,第4层卷积核个数为128,则第4 层卷积输出为3×29×128,池化后为1×14×128。
2.4 舍弃层
Dropout[19]是Hinton 提出的去过拟合技术。在每一轮的训练过程中,随机让一部分隐藏节点失效,但每个节点的权值都会被保存下来。在最终预测时,打开全部隐藏节点,使用完整的网络进行计算,相当于把不同结构的网络结合在了一起。本文使用较小的dropout 值20%
由图1 可知,CNN 结构最后还有一个全局平均池化层和全连接层。全局平均池化层的输入为最后一层卷积层的输出,即1×4×128,全局平均池化后为输出为128,全连接层将有50 个节点(判定类别数),这些节点与可能的分类数相匹配,全连接层的激活是softmax。
3 实验
3.1 数据集
ESC-50 数据集是环境音频的数据集。这一数据集由2 000 个标记的环境声音组成,他们被均匀地划分为50 个类别(每个类别40 个样本)。这50个类别又可以粗略地分为5 个大类,分别是:动物的声音、自然声音和水声、人(非言语)声音、室内声音、室外噪音。
该数据集提供了各种环境声源,一些样本彼此不同(玻璃破碎,刷牙),还有一些差异很小(直升机和飞机噪音)。该数据集的一个明显的缺点是每个类的音频样本数量有限。这与手动注释和提取的高成本有关,也与奇特的声音事件的可用量有限而样本类之间又要保持严格平衡有关。然而,这一数据集在当下的研究中仍有望以其目前的形式发挥作用。
在该数据集中除了包含2 000 个音频文件之外,还包含一个元数据的csv 格式文件。在该文件中包含了每个音频样本的信息,这些信息包括:音频文件的文件名,音频类别等等。
3.2 实验配置
实验使用在加载音频时也将归一化数据。这消除了具有多种位深度的数据集的复杂性。
在归一化的数据中中提取Mel 频率倒谱系数(MFCC)。这些音频特征将用于进行分类识别。本文计算了音频样本的250 帧的一系列40 阶MFCC,连续为数据集中的每个音频文件提取MFCC,并将其与其分类标签一起存储。为了克服因音频文件的持续时长不同而导致的MFCC 向量大小不同的问题,会对MFCC 向量进行零填充,使得它们有相同的大小。
在读取音频数据并进行特征提取以及标签编码后,所有数据用dataframe 的类型存储,成为可使用的数据。然后将数据集拆分为训练和测试集,测试集占总数据集的20%,划分依据为随机划分。在CNN 上训练模型迭代至收敛,最后使用测试数据集测试模型的分类准确率。训练过程的batch_size 设置为128,优化算法设置为adam。
利用前文提到的语音增强,分别对原音频样本实行不同的增强策略,然后比较这几种策略下的测试准确率。
3.3 分类方法对比试验
为了比较提出的卷积神经网络结构和数据增强方法的效果,分别在进行时间拉伸的数据集上和原数据集上测试准确率,同时使用支持向量机分类方法在原数据集和时间拉伸的数据集上测试准确率。结果如表1 所示。

表1 不同分类方法分类准确率
结果表明,在训练数据集相同时,卷积神经网络效果优于支持向量机,这与前文提到的CNN 结构的原理有关,而对于同一分类方法,在时间拉伸的数据集上的测试准确率要有所提到,这显然是有效的训练数据的增加的影响。
3.4 数据增强对比试验
在该实验中,分别采用不同的数据增强方法(如表2 所示)对数据集进行增强,然后在增强后的数据集上根据前文的实验配置参数训练模型,最后测试分类准确率。

表2 不同数据增强方法分类准确率
由以上实验结果可以看出,不同的音频数据增强方法的分类准确率不同。而同一种增强方法,增强参数不同时,最终的准确率也有区别。产生以上结果的原因在于,采用不同的方法进行数据转换时,原本音频数据的时域-频域模式的改变程度不同的,所以产生的新的训练数据对于模型的优化程度不同。
4 结束语
提出了一种深度卷积神经网络架构,它结合音频数据增强方法,对环境声音分类效果较好。研究发现,改进的性能源于深度,高容量模型和增强训练集的组合,这种组合优于没有增强的CNN 和具有增强的其他机器学习模型。最后,不同数据增强方法对模型分类准确性的影响也会不同。
猜你喜欢
无线电工程(2024年8期)2024-09-16 00:00:00
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
家庭影院技术(2018年11期)2019-01-21 02:20:52
计算机技术与发展(2019年1期)2019-01-21 00:56:38
电子制作(2018年19期)2018-11-14 02:37:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
