
云计算数据中心网络中资源分配与调度研究
2021-05-21 08:41公诚管理咨询有限公司陈欲科
电子世界 2021年8期
公诚管理咨询有限公司 陈欲科
在互联网发展的过程中,云计算可以实现通过网络将软硬件资源和信息整合共享,按照要求把不同的信息提供给不同计算机的终端和其他设备。提供设备的时候,要用到数据中心作为云计算的支撑设施,所以数据中心的资源分配和调度问题是非常重要的,相关人员需要对其进行深入研究。本篇文章将对云计算数据中心进行结构和特征的详细介绍,通过研究负载均衡对云计算数据中心网络资源分配的问题,解决数据中心资源分配和调度的问题。
云计算服务的基础是数据中心,云计算的特点是低成本和高效率。人们可以使用它对数据进行大规模的处理和储存,云计算数据中心随着互联网时代的不断发展和进步,规模也不得不继续扩张,云数据中心的资源分配和调度问题受到了多方面的重视和关注,面对大量的工作和用户,负载过多,必须要尽快解决资源的分配和调度问题。不仅在学术界,在工业界希望能够深入的研究这个问题。
1 云计算数据中心结构
网络交换机、机架、冷却系统、主机四个部分构成一个云计算数据中心,这是十分典型的组成结构。
2 云计算数据中心网络特征
2.1 服务器和中间设备的资源多样性
云计算数据中心具有差异性,才能准确精准地为客户提供服务,以数据多样性的特点,这也是云计算数据中心网络的显著特征。从大的方面来说,一般可以将网络资源分为两类,一类是通信资源,另一类是计算资源。Hadoop,YARN和Mesos等等都是在数据中心中广泛使用的主流大数据框架,可以支持多种资源的调度与分配。这也就是说,云计算数据中心可以提供很多计算或者资源的类型,例如CPU、GPU,内存、存储、链路带宽等,通常来说,不同种类资源,使用的数量也不一样。
相关学者在Facebook上对一个2000节点的集群进行调查,研究多资源分配的必要性,在一个月内对资源的使用情况做出记录,并依据记录的数据绘制图,这充分证明了多资源分配的必要性。圆圈的大小与圆圈内区域中的任务数量呈对数关系,相对应被用户任务消耗的内存和CPU资源由图中的圆圈代表。大数据中心的任务,尤其是reduce,需要消耗很多CPU资源和内存。
在入侵检测时会消耗更多CPU的资源。也就是说,在NFV环境中,不同的中间设备处理不同的资源,消耗的功能也不同,所以要根据要求来处理数据流,同时根据需求让一个中间设备做出调度的决策,协调多种资源。在处理小型数据包的时候与处理大型数据包时的消耗是不同的,第一种情况瓶颈资源是内存带宽,而第二种则是链路带宽。随着信息时代的不断发展,中间设备的异构化也越来越受到人们的重视。
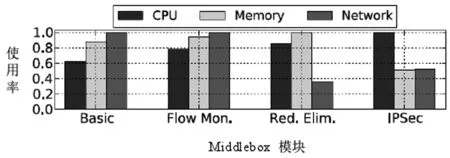
图1 四种在Click中执行的功能模块的归一化的资源使用率
相关学者测量了在Click中执行的四种主要网络功能应用的资源痕迹。这四种网络功能分别为:基础转发功能(basicforwarding,流量监控功能(flowmonitoring,冗余消除功能(redundancyelimination)以及IP安全加密功能(IPSecencryption)。这次的研究证明了在NFV中进行多资源流调度的必要性,这四种网络功能资源占用情况在图1明确体现了。每种网络功能的最大资源消耗归一化为1。从图中可以看到:主要消耗链路带宽的是基础转发功能与流量监测功能,而占用更多的内存空间却是冗余消除功能,同时主要占用CPU资源的是IP安全加密功能。
2.2 分层级的工作负载结构
云计算数据中心的客户很多,不仅有大型小型的公司,还有很多的组织、机构和私人用户,在这些单位的内部还有许多不同的部门和团体。这就要求云计算数据中心的工作负载必须要有明显的分层级结构,这样,在用户想云计算中心发送请求链接时,云计算数据中心会根据用户提供不同的服务。
多租户(multi-tenant)环境也是云计算数据中心经常会涉及到的环境,每个租户都是一个反复的数据流,然而各个租户中间又存在着资源竞争的关系。搜索引擎是时延敏感型的应用,而视频应用和批处理应用却是吞吐量敏感型的。由于每个租户使用的应用软件不同,云计算数据中心使用的中间设备也必须要采用分层的结构才能满足用户的需求。
2.3 用户请求的异构性
用户的需求是各种各样的,有时候不只是不同用户间需要的服务不一样,就连同一个用户的不同部门之间需要的服务都不一样,这就是用户的异构性。为了优化处理性能,对用户提供针对性的服务,云数据处理中心可以对世界各地不同的用户发出的请求进行处理,向不同的用户提供不同的服务,由于愿意投入的预算不同,这些用户得到的体验和服务也大不相同。
用户的资源需要分配隔离,这就需要用到云计算数据中心的调度器,针对不同用户的需求进行处理,保证每个用户的基本资源,这就要求不管其他的用户中是否有人面对着占用的服务器服务中断的问题,都要保证每一个用户都能够获得属于自己的资源分配,保证资源隔离和资源保障,这样公平的资源分配方案是保证每个用户相应资源的基本方法。
数据中心的部分工作负载是被约束的,只能被部署在某些服务器上,所以用户的请求是具有放置约束(placementconstraints)的。Google的数据报告显示,50%以上的工作都在Google服务器上只能在哪些服务器上运行的限制,这个限制是非常明确和严格的,这就导致了服务只能在这个局限里进行。这就是说CUPA的流量只能穿过GPUs的服务器,但是DNS的服务却只能部署在拥有IP地址的服务器上。
2.4 高速调度资源的必要性
在HPC和网络这样的传统网络环境中,经常会采用离线(offline)的方式对资源进行调度分配。在此之中,用户的资源请求需要占用某些服务器,并且持续的时间很长,这就称为用户资源请求的粗粒度(coarse-grained),提前通知调度器执行时间的上限,这样就可以保证调度器可以为每一个用户进行相应的资源调配。
在云计算数据中心里,对调度器的要求很高,一般来说,调度器需要对资源合理的进行分配,并且做出合理科学的调度决策,同时,这些工作是需要在线进行(online)的,这个代表着在用户进行请求或者是离开时都要迅速的反应,对用户的需求进行合理的调度调配。MapReduce和Dryad会将用户的资源请求分割成一个接着一个的细粒度(fine-grained)的任务。作为数据密集型的计算环境,HadoopFairScheduler和Mesos是经常使用的数据中心调度器,在成千上万个用户不断的到达和离开中进行在线决策。一段时间内,每个任务都会占用一定的服务器资源,同时无法确定占用的时长。所以在分配和调度数据中心的资源时,数据中心调度器需要根据实际情况进行迅速的决策,保证算法的复杂性和可实施性。
3 云计算数据中心网络中资源分配与调度——基于负载均衡的资源分配改进
负载均衡器可以均衡资源问题。经常使用的负载均衡技术有很多种,包括硬件负载均衡、软件负载均衡和本地负载均衡。硬件均衡器是在服务器集群间安装的,使用效果得到了显著提高,但是成本也随之增加了。一般的软件均衡器是在服务器上安装的,这样的均衡器成本低,但是十分简单,使用的效果也不好。本地负载均衡是把外部用户的请求平均到许多个服务器,中和服务器可以解决单个服务器的单点问题。使用负载均衡技术可以综合服务器的资源分配,是因为用户的使用时间和占用资源的大小都是不确定的,具有异构性,所以会造成服务器过闲或者是过重的问题。
投票算法俗称“多选一”,资源分配的负载均衡与投票算法类似,本质是从多个资源中选择一个资源进行分配。投票算法需要满足几个基本原则。多个备选资源在本质上平等,就算不同的权重,各资源之间也没有根本区别,都是平等的按照不同的权重进行选择。初期准备过程中,多准备备选资源,再从中选择最优资源。传统的投票算法在搜索过程中易陷入局部最优,所以需要大量准备备选资源。为了实现资源分配的负载均衡,本文对传统的投票算法进行了改进。
组内讨论和组间讨论组成了传统投票法,每个资源数量占资源总数的比例不同。资源类中随机选择一个资源个体,对这个资源个体加入一个随机的扰动,就能形成一个新的资源个体,这就是资源的更新。
结语:总的来说,用户使用时长的不确定性和占用资源情况的不确定性,导致数据中心需要用调度器进行统一的决策和处理。由于用户请求的多样性,云计算的消耗是很多的,它需要消耗大量的资源进行查找,保证云计算数据中心的公平问题,也就保证了云计算数据中心的运行效果。要解决这个问题,要发展调度器的决策性,让它在短时间内迅速作出正确的决策。
猜你喜欢
昆钢科技(2022年4期)2022-12-30
机械研究与应用(2022年4期)2022-09-15
昆钢科技(2022年1期)2022-04-19
建材发展导向(2021年7期)2021-07-16
昆钢科技(2021年6期)2021-03-09
英语文摘(2020年10期)2020-11-26
西藏艺术研究(2019年1期)2019-09-04
小学科学(学生版)(2019年4期)2019-05-11
测控技术(2018年7期)2018-12-09
智富时代(2018年3期)2018-06-11
