
基于机器学习算法的肝硬化相关肝性脑病预测模型的构建
2021-05-21 03:33谈军涛许晓梅何雨芯谭超龚军刘蕴宇向守书赵文龙
解放军医学杂志 2021年4期
谈军涛,许晓梅,何雨芯,谭超,龚军,刘蕴宇,向守书,赵文龙*
1重庆医科大学医学信息学院,重庆 400016;2成都市第五人民医院消化内科,成都 611130;3重庆医科大学公共卫生与管理学院,重庆 400016
肝性脑病(hepatic encephalopathy)是严重肝脏疾病并发的一种以代谢紊乱为基础的中枢神经系统功能性失调的综合征,患者主要表现为意识障碍、行为失常甚至昏迷。美国肝病研究协会和欧洲肝脏研究协会将肝性脑病定义为由肝损伤或门体分流引起的脑功能障碍[1]。临床上将肝性脑病分为A、B、C三型,其中A型与急性肝衰竭有关,B型与无肝病的门体分流有关,C型与肝硬化有关[2]。肝性脑病除增加患者、家庭和社会的各种负担外,也是肝硬化患者发生跌倒、骨折、再入院等不良事件的常见原因之一[3]。为减少肝性脑病带来的不良影响,有必要对肝硬化患者进行肝性脑病风险预测,以帮助医护人员进行评估并提前采取治疗和护理措施。机器学习作为一种新兴的统计分析方法,能够对大数据进行深度挖掘与分析,目前已在疾病发生、预后预测等方面广泛应用[4-5]。本研究采用logistic回归、随机森林、决策树和XGBoost等4种机器学习算法,构建并评价肝硬化相关肝性脑病风险预测模型,旨在为肝硬化患者肝性脑病风险评估奠定基础,并为临床防治工作提供参考。
1 资料与方法
1.1 研究对象 本研究为回顾性横断面研究。收集2019年6月-2020年6月就诊于重庆市7家医疗机构(其中5家为重庆医科大学附属医院,2家为教学指导医院)消化内科、肝胆外科、感染科等科室的1498例肝硬化患者。纳入标准:肝硬化失代偿期;年龄>18岁。排除标准:合并恶性肿瘤;合并肝衰竭;既往曾行经颈静脉肝内门-体静脉支架分流术(transjugular intrahepatic portosystemic shunt,TIPS);伴有精神疾病;临床资料不完整。
1.2 分组 参照《肝硬化肝性脑病诊疗指南》[6],结合临床表现、实验室和辅助检查判断患者是否发生肝性脑病,并据此将1498例患者分为肝性脑病组(n=285)与非肝性脑病组(n=1213)。将肝性脑病组和非肝性脑病组按照7:3随机分为训练集(n=1048)和测试集(n=450),进行内部验证。本研究通过重庆医科大学医学研究伦理委员会审批。
1.3 研究指标 患者的一般资料(年龄、性别、吸烟史、饮酒史、高血压、糖尿病)、病因(乙肝、丙肝、酒精肝、自身免疫性肝病)、并发症(消化道出血、腹膜炎、腹水)及实验室检查(血常规、肝功能、肾功能、电解质、凝血功能)等。
1.4 统计学处理 采用SPSS 22.0、R4.0.2、Excel 2013软件进行统计分析。符合正态分布的计量资料以±s表示,组间比较采用t检验;不符合正态分布的计量资料以M(Q1,Q3)表示,组间比较采用Mann-Whitney U检验。计数资料以率(%)表示,组间比较采用χ2检验。内部验证采用单因素logistic回归分析,以P<0.05为纳入多因素分析的标准,将筛选后的变量作为输入变量,以是否发生肝性脑病为结局变量,在训练集中分别建立logistic回归、随机森林(random forest)、决策树(decision tree)和XGBoost模型;然后在测试集中采用ROC曲线分析比较4种模型的预测价值。
采用R语言中的glmnet包、random forest包、rpart包及XGBoost包分别构建4种机器学习模型。随机森林模型主要包含ntree(树的数目)和mtry(随机选择特征的数目)两个重要参数,其中mtry在通常情况下为[log2(p)+1]个,p为纳入指标个数[7],模型采用准确度平均下降量(mean decrease accuracy,MDA)衡量指标的重要度。决策树模型分裂属性的度量指标为信息熵[8],采用后剪枝过程中的最小代价复杂度参数(CP)进行模型优化。XGBoost模型采用gain值衡量某个指标的增益[9],gain值越大,表明指标对模型的影响越大。
2 结 果
2.1 基线资料 两组患者年龄、吸烟史、饮酒史、高血压、糖尿病、乙肝、酒精肝、自身免疫性肝病、腹膜炎、总胆红素、中性粒细胞比值、血红蛋白总量、全血钠、全血钾、白蛋白、尿酸、红细胞计数、淋巴细胞比值、凝血酶原活动度、尿素氮、丙氨酸氨基转移酶及白细胞计数等差异有统计学意义(P<0.05,表1)。
2.2 构建机器学习模型 Logistic回归分析结果显示,高血压、酒精肝、糖尿病、自身免疫性肝病、年龄、全血钠、凝血酶原活动度、尿素氮等10项指标为肝性脑病的影响因素(P<0.05,表2),其中淋巴细胞比值(P=0.123)与红细胞计数(P=0.100)通过咨询临床专家和查阅参考文献,也属于肝性脑病的影响因素,故纳入模型。如图1所示,当ntree超过500后,模型趋于稳定,最终随机森林模型参数设置为:ntree=500,mtry=5。各指标对应的MDA如表3所示。在分裂次数为4次时,决策树模型的交叉验证预测误差最小,为0.936(表4),此时对应的CP值为0.029,模型中各个分裂点对应的指标如图2所示,其中凝血酶原活动度为第一个分裂点,年龄为第二个,其余两个分裂点为白细胞计数和淋巴细胞比值。XGBoost模型中各指标对应的gain值如图3所示,凝血酶原活动度的gain值最大,其次为全血钠、年龄、全血钾、白细胞计数和尿素氮等。
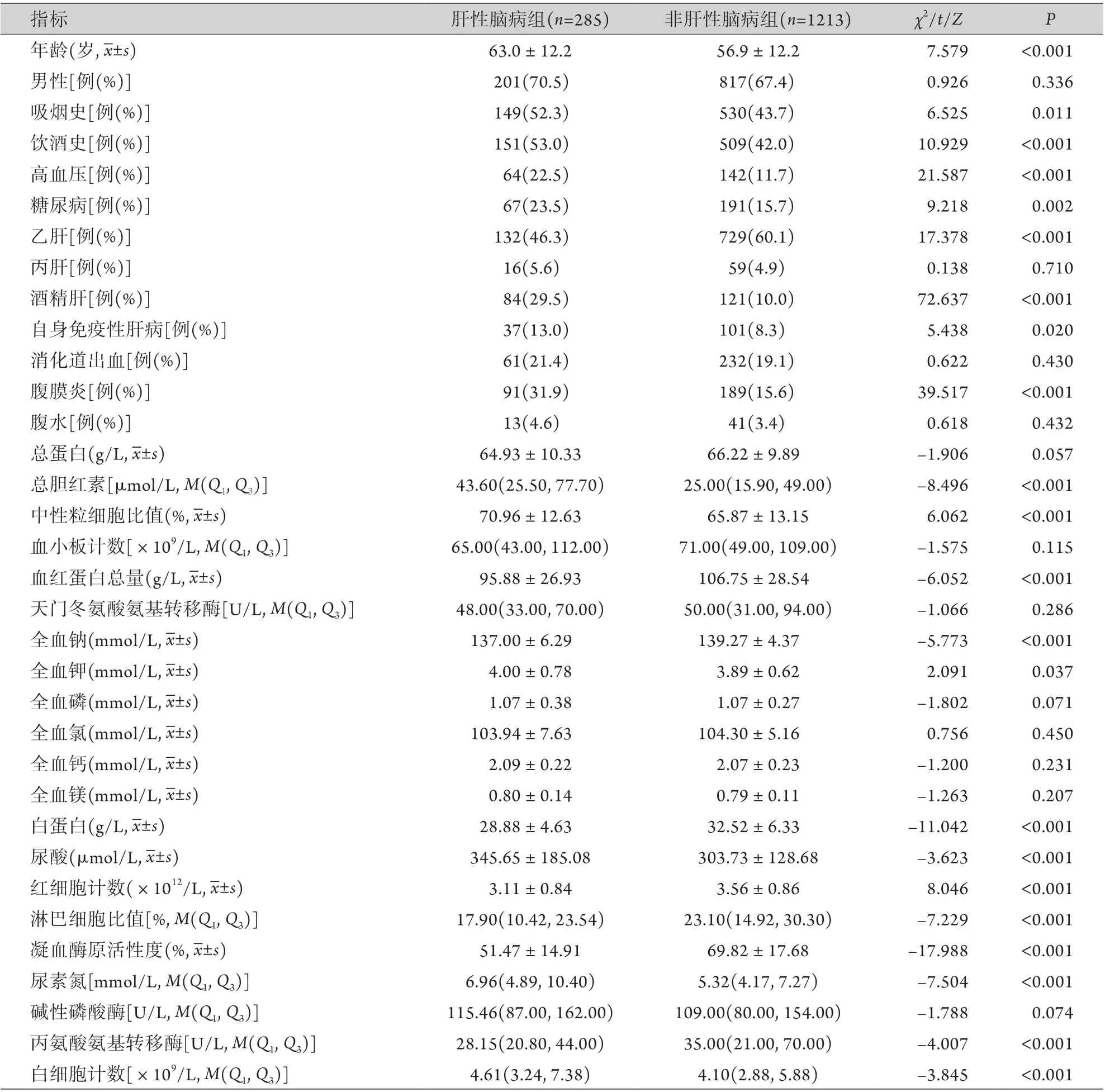
表1 肝性脑病组与非肝性脑病组患者基线资料比较Tab.1 Comparison of the baseline data between hepatic encephalopathy group and control group

表2 Logistic回归分析肝性脑病的影响因素Tab.2 Influencing factors of hepatic encephalopathy (logistic regression model)

图1 两组肝病患者随机森林模型OOB趋势Fig.1 OOB trend of random forest model OOB. 袋外数据

表3 随机森林模型的指标重要性测度Tab.3 Index importance of random forest model

表4 决策树模型参数分析Tab.4 Analysis of decision tree model parameters
2.3 各模型的预测性能比较 将构建的logistic回归模型、随机森林模型、决策树模型及XGBoost模型在测试集中进行内部验证,结果显示,各模型的AUC均较高,依次为0.875、0.883、0.767、0.847。Delong test检验结果显示,logistic回归模型和随机森林模型的预测性能优于决策树模型和XGBoost模型(P<0.05)。随机森林模型的灵敏度最高,为0.904,决策树模型最低,为0.759;logistic回归模型的特异度最高,为0.785,随机森林模型最低,为0.695。随机森林模型的综合预测效能最优,其AUC最高,为0.883(图4、表5)。

图2 决策树模型的可视化分析Fig.2 Visual analysis of decision tree model
2.4 肝硬化相关肝性脑病重要影响因素分析 对比4种模型,综合OR值、MDA值、Gain值发现,凝血酶原活动度、年龄、全血钠及尿素氮在各自模型中均表现显著,提示这几个指标可作为肝硬化相关肝性脑病的重要影响因素。进一步绘制箱线图,并添加各指标显著性程度进行对比,结果显示,肝性脑病组年龄和尿素氮明显高于非肝性脑病组,+-+全血钠和凝血酶原活动度明显低于非肝性脑病组(P<0.05,图5)。
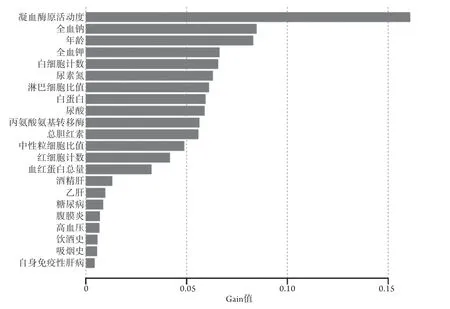
图3 XGBoost模型指标的重要性分析Fig.3 Importance analysis of indexes in XGBoost model

图4 各模型在测试集中的ROC曲线分析Fig.4 ROC curves of four models in test set
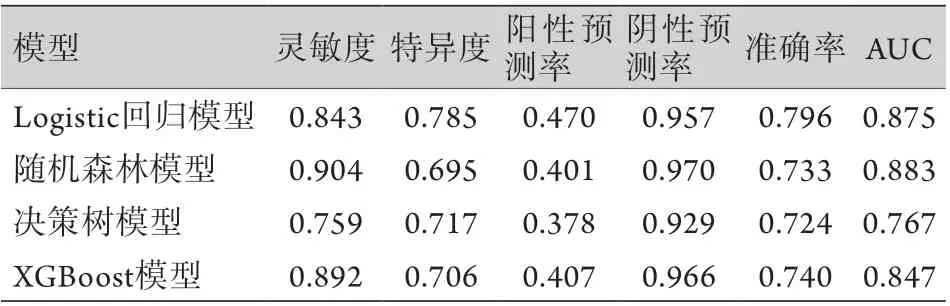
表5 各模型在测试集中的预测性能比较Tab.5 Comparison of the prediction performance of four models in test set
3 讨 论
肝性脑病在肝硬化患者中具有发生率高、病死率高的特点,且其发病机制复杂,目前尚无标准的诊断方法[10],因此,在肝性脑病发生前进行早期评估与预防具有积极意义。既往关于肝性脑病的风险研究局限于危险因素、预后以及神经生理、心理测试筛查方法的探究[11-12],仅少数为基于危险因素的预测模型研究[13-14]。本研究结合患者的一般资料、病因、并发症和实验室检查结果,采用logistic回归、随机森林、决策树和XGBoost算法构建预测模型,所建模型在灵敏度、特异度和AUC等评价指标上表现良好,能够辅助临床医师预测肝硬化患者肝性脑病的发生风险。
机器学习可对大量数据的特征进行有效学习,为精准预测提供了新的研究思路和方法。机器学习算法包括常规算法(K-近邻、决策树和支持向量机等)和集成算法(随机森林、XGBoost和极限树等)。已有专家学者基于机器学习算法在医疗领域进行探索,取得了一定的成果[15-17]。本研究采用logistic回归、随机森林、决策树和XGBoost 4种机器学习算法分别构建预测模型以预测肝硬化患者并发肝性脑病的风险。Delong test检验显示,logistic回归和随机森林两种算法构建的预测模型优于决策树和XGBoost,其中综合预测效能最优的为随机森林模型,其AUC最高,为0.883。随机森林是多个决策树的集合,能弥补决策树泛化能力弱的缺点[18],该方法依靠计算机,通过最小化观测结果和预测结果之间的误差来学习变量之间所有复杂的非线性相互作用[19],使用bootstrap聚合和预测因子随机化来获得较高的疾病预测准确率[20-21]。

图5 显著性指标分组箱线图Fig.5 Grouped box plot of significance index
凝血酶原活动度是判断肝病严重程度最经典的指标,其水平降低常提示患者的肝功能被不同程度地破坏[22]。多项研究发现,凝血酶原活动度是肝性脑病的独立危险因素[23-24]。随着年龄增加,患者肝脏解毒能力变差,脑细胞更容易受到毒性作用,进而导致肝性脑病的发生风险增加。Routhu等[25]发现,高龄是肝硬化患者发生肝性脑病的重要影响因素。尿素氮水平升高是肾脏有效血容量不足的敏感指标。肝衰竭伴有肾功能受损时,会导致氮质血症,表现为血尿素氮水平升高,诱发脑水肿,从而导致肝性脑病发生风险升高。徐言等[26]在一项探究影响肝性脑病预后独立危险因素的研究中发现,除中性粒细胞/淋巴细胞比值外,尿素氮为第二影响因素。低钠血症是肝硬化患者常见的电解质紊乱之一,由于肝硬化患者存在肝功能衰退,因此容易引起心房钠尿肽、抗利尿激素、醛固酮等激素失调,导致钠、水潴留,并常合并低钠血症[27]。蒋汉梅等[28]在探讨失代偿期肝硬化患者血钠水平与病情、肝性脑病、肝肾综合征的关系时发现,低钠血症与失代偿期肝硬化患者的并发症和预后有关,血钠水平可作为患者病情和并发症的判断指标之一。本研究中的随机森林模型(AUC最高)提示,白蛋白是肝性脑病的重要影响因素。白蛋白是判断营养状态的良好指标。最近研究发现,白蛋白是肝性脑病发生的独立危险因素[29],另有研究发现,输注白蛋白有助于预防肝性脑病的发生,并可改善肝硬化患者肝性脑病的严重程度[30]。
综上所述,本研究构建了基于logistic回归、随机森林、决策树和XGBoost算法的肝性脑病预测模型,并结合灵敏度、特异度和AUC等评价指标对模型的效能进行对比,一定程度上减少了单一算法和单一评价指标带来的偏倚。同时本研究纳入的患者来自多家医疗机构,样本量大且具有良好的代表性,研究结果可为临床干预肝性脑病提供决策支持。但本研究仍存在一定的局限性:为横断面研究,无法确立肝性脑病风险与肝硬化之间的因果关系;模型只进行了内部验证,未进行外部验证,模型的准确性仍需今后通过更多的人群进行验证。
猜你喜欢
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
临床肝胆病杂志(2017年4期)2017-03-06
哈尔滨医药(2016年3期)2016-12-01
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
河北中医(2016年12期)2016-03-08
西南军医(2016年3期)2016-01-23
中国卫生标准管理(2015年17期)2016-01-20
中国卫生标准管理(2015年25期)2016-01-14
医学研究杂志(2015年11期)2015-06-10
