
基于在线学习的Siamese 网络视觉跟踪算法
2021-05-17 19:55张成煜侯志强陈立琳马素刚余旺盛
光电工程 2021年4期
张成煜,侯志强*,蒲 磊,陈立琳,马素刚,余旺盛
1 西安邮电大学计算机学院,陕西 西安 710121;
2 西安邮电大学陕西省网络数据分析与智能处理重点实验室,陕西 西安 710121;
3 空军工程大学信息与导航学院,陕西 西安 710077

1 引言
视觉目标跟踪是计算机视觉领域的一个重要研究方向,其主要任务是在视频序列初始帧中给定目标位置和大小,在后续帧中预测该目标的位置和大小。其在智能监控、无人驾驶、军事侦查等领域都有广泛的应用[1-2]。视觉跟踪中,目标通常会面临尺度变化、运动模糊、目标形变、遮挡等问题,如何在这些复杂场景中准确预测目标仍然是一个具有挑战性的问题[3-4]。
近年来,目标跟踪领域取得了飞速的发展,尤其是深度学习技术的使用,使目标跟踪算法的性能得到了很大的提升,其中,基于Siamese 网络的视觉跟踪算法因为有着较高的速度和精度,在视觉跟踪领域得到了众多研究人员的青睐。Siamese 网络能够很好地计算两路输入的相似度,在这类方法中,通常有SiamFC[5]、SiamFC-Tri[6]、DCFNet[7]等算法,其中SiamFC 作为大多数算法的基准算法,得到了广泛关注。在SiamFC 中,选取初始帧中的目标作为模板,把跟踪任意目标当作一种相似性学习任务,利用离线训练的全卷积神经网络学习一个深度相似性函数,以此来预测目标的位置。
由于训练数据中存在样本不平衡问题,简单的相似匹配在复杂场景中难以对目标进行跟踪;另外,Siamese 网络能否和传统的相关滤波方法相结合,进一步提高算法的跟踪性能也是一个重要的研究方向。针对上述问题,SiamFC-Tri[6]基于SiamFC[5]的跟踪框架提出了不同于SiamFC 的损失函数(triplet loss),充分利用了训练数据中模板、正样本、负样本三者之间的关系,使得网络可以提取更具表现力的特征。DCFNet[7]在Siamese 网络中加入了相关滤波层,将相关滤波和Siamese 网络相结合,实现了端到端的设计。SiamRPN[8]不同于传统跟踪算法中的多尺度测试和在线跟踪,它将目标检测领域中的RPN 模块融入Siamese 网络结构当中,在跟踪阶段将跟踪任务构造成局部单目标检测任务,有效提升了跟踪器的精度和速度。
大多数基于Siamese 网络的跟踪算法都是使用ILSVRC[9]和Youtube-BB[10]等大型数据集离线训练出模型然后用于在线跟踪,缺乏类似于相关滤波框架中的在线更新。为了能够在跟踪过程中进行模型更新,Guo 等人提出了DSiam[11]算法,该算法构建了一个动态Siamese 网络结构,其中包含一个快速变换学习模型,在跟踪阶段能够在线学习目标的表观变化和背景抑制,但是它仍然存在以下不足:
1) 在跟踪阶段,历史帧中存在大量与目标有关的时空信息,包括形变、运动、背景等信息,而该算法只是从第一帧模板学习目标的表观变化,并没有利用到历史帧中的丰富信息,无法应对剧烈形变、目标遮挡等情况;
2) 在通过快速变换模型学习背景抑制时,在搜索区域上仅使用高斯权重图,并不能有效地凸显目标,抑制背景。
针对以上问题,本文主要做了以下工作:
首先,将第一帧中的目标当作静态模板,动态模板同样初始化为第一帧中的目标区域。然后在后续跟踪过程中,通过快速变换模型,从两个模板中学习目标的表观变化,并结合高置信度更新策略更新动态模板。其次,在背景抑制模块中,通过计算当前帧的颜色直方图特征获取搜索区域的目标似然概率图[12],与深度特征融合,进行背景抑制学习。最后,对搜索区域和双模板进行相似性计算,将获取到的响应图加权融合求出最终响应,获得跟踪结果。
本文算法在一定程度上解决了基于Siamese 网络跟踪算法中的模板更新问题,双模板的引入可以构建更加稳健和丰富的目标模板,使模型在线学习到更多的目标变化;引入颜色直方图特征获取的目标似然概率图可以有效抑制背景,突出目标。在OTB2015[13],TempleColor128[14]和VOT[15]数据集上的实验结果表明,与近几年的主流跟踪算法相比,本文算法的测试结果在跟踪精度和成功率上均有提升。
2 基于Siamese 网络的跟踪算法
本文算法基于Siamese 网络框架,在DSiam[11]的基础上,引入动态模板和颜色直方图特征,通过快速变换模型学习目标的表观变化并进行背景抑制,有效地提升了视觉跟踪算法的鲁棒性。
基于Siamese 网络的跟踪算法框架如图1 所示,它包含两路并行的全卷积网络,分别对127×127×3 的模板图像和255×255×3 的搜索图像进行特征提取,然后对提取到的两路特征进行相似性计算。用O1和Zt分别表示模板图像和搜索图像,则响应图的计算:

其中:corr 为相似性计算,f(⋅)为特征提取函数,St表示最终得到的响应图搜索区域中各部分与模板的相似度,选取响应最高的点作为预测的目标位置。

图1 基于Siamese 网络跟踪算法示意图Fig.1 Schematic diagram of tracking algorithm based on Siamese network
Simaese 网络对搜索区域进行了正负样本的区分,将搜索区域中的每一个候选窗口作为一个样本,它的输出就是其属于正负样本的概率,也就是一个二分类问题,则损失函数可表示为

其中:v是候选区域的得分,y∈{1,-1},是其真实类别。采用一个模板和一个搜索区域图像来训练SiameseFC 网络,最终损失函数为每一个损失的均值:

其中:u为响应图中的位置,标签y[u]∈{1,-1}由位置u与响应图中心的距离确定。在某一阈值内时,将其作为正样本,否则为负样本。网络使用ILSVRC 数据集进行离线训练,通过随机梯度下降方法调整网络参数。
为了能够应对在跟踪过程中出现的目标形变、背景干扰等情况,Guo 等人提出的DSiam[11]算法在SiamFC[5]的基础上构建了一个动态Siamese 网络,通过在网络中嵌入一个快速变换模型,在每一帧学习目标的表观变化和背景抑制。DSiam[11]将目标跟踪视为一个模板匹配和在线变换学习的联合问题,在SiamFC[5]的匹配机制上针对目标的表观变化和背景抑制引入了快速变换学习模型V和W,将响应图的求解转换为

其中:St表示第t帧搜索区域与目标模板进行相关操作后得到的响应图,Vt−1和Wt−1是在跟踪过程中学习到的表观变化和背景抑制,∗表示循环卷积操作,f(⋅)表示特征提取。
通常的模型更新会直接使用t− 1帧的目标区域Ot−1来替换第一帧目标模板O1,这种方式通常会导致模型漂移,造成目标丢失。在求解张量X相似于张量Y的最优线性变换矩阵R时,常使用正则化线性回归,求解方式如下:
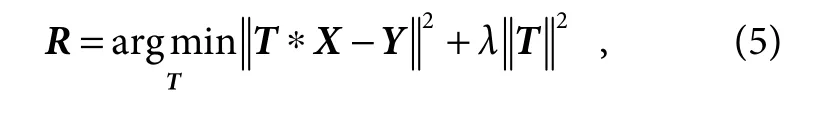
其中:T为线性变换矩阵,可以通过让第t−1 帧中目标区域特征相似于模板特征求解出变换矩阵,即可以在线学习到目标的表观变化Vt−1。

其中:F1表示初始模板的特征,Ft1−表示t−1 帧中目标区域的特征,λv是正则化参数。将求解出的Vt−1与目标模板的特征f(O1) 进行卷积操作,使模板学习到目标的表观变化。
在第t帧,应当选择与目标模板具有较高相似度的区域输入网络,但通常搜索区域中含有大量背景信息,为减少背景干扰,DSiam[10]引入背景抑制学习。跟踪完t−1 帧时,在该帧图像It1−上以目标为中心裁剪出一个与搜索区域相同大小的区域Gt−1,并加上高斯权重图得到,通过式(7)学习背景抑制Wt−1。

3 本文算法
3.1 总体框架
在DSiam[11]中,将第一帧中的目标区域作为模板,后续跟踪中利用快速变换模型从该模板中学习目标的表观变化。但当目标出现剧烈形变,复杂背景等情况时,只从单一模板中学习这些变化容易造成跟踪失败,也没有充分利用到丰富的历史帧信息。其次,模型在学习背景抑制时,只是使用了高斯权重图,并不能有效地突出目标,抑制背景。
本文在DSiam[11]算法的基础上进行了以下改进,其流程图如图2 所示。
1) 在跟踪阶段,将第一帧中的目标当作静态模板,在后续帧中使用高置信度更新策略获取动态模板,使得快速变换模型可以从双模板中学习目标的表观变化;
2) 根据当前帧的颜色直方图特征计算出搜索区域的目标似然概率图,与深度特征融合,进行抑制背景学习;
3) 将搜索区域与双模板得到的响应图加权融合,得到最终响应,实现对目标的定位。
3.2 双模板的建立
3.2.1 静态模板
静态模板是跟踪过程中使用的基准模板,提供目标的初始信息,所以在视频序列的第一帧中,首先以目标位置P为中心裁剪一个正方形区域。假设目标的宽和高记为w和h,则需要裁减的正方形区域边长:

其中:w z=w+c× (w+h),h z=h+c× (w+h),模板需要引入一定的背景信息,可以通过上式中的影响因子c进行调整。然后将裁剪后的区域放缩为127×127×3大小作为基准模板输入特征提取网络。
3.2.2 动态模板
在跟踪过程中仅使用静态模板去学习目标的表观变化无法有效应对目标形变、遮挡等情况,逐帧对静态模板进行替换又容易造成模型漂移。因此本文引入动态模板,通过在跟踪过程中逐帧计算响应图的置信度,选取置信度较高的帧作为动态模板,并结合更新策略对动态模板进行实时更新。

图2 基于在线学习的视觉跟踪Fig.2 Visual tracking based on online learning
在LMCF(large margin object tracking with circulant feature maps)[16]中,Wang 等人提出了平均峰值相关能量指标,可以用来衡量响应图的波动程度。文献[17]中,Chen 等人提出了一种对动态模板的更新方式。根据文献[16]和[17],本文提出了一种高置信度更新策略,在跟踪过程中通过计算响应图的峰值和波动程度,获取当前帧的置信度H,并依据更新策略对动态模板进行更新。通过实验,我们发现在跟踪过程中,当响应图峰值尖锐或波动程度较低时,可以很好地对目标进行定位;而当响应图波动剧烈或出现多峰时,通常会发生目标遮挡或丢失。所以在当前帧的置信度H和最大峰值Vmax均以一定比例大于各自的历史均值mH和mVmax时,对动态模板进行更新。

其中:参数α和β控制动态模板的更新频率,更新过快,易导致模型漂移,更新过慢,使模板无法适应目标变化。如表1 所示,在OTB2015[13]数据集上的实验表明,阈值α和β分别设置为0.8 和0.9 时,效果最优。
动态模板的引入,一方面可以构造更加稳健的目标模型,使跟踪器充分利用到丰富的历史帧的信息,另一方面,通过从双模板中学习目标的表观变化,可以有效应对跟踪中出现的目标形变、遮挡等情况。
3.3 快速变换学习模型
3.3.1 表观变化学习
虽然动态网络的引入能够在线学习目标的表观变化,但也仅仅利用了第一帧模板的信息,无法应对复杂环境下的跟踪问题。为了能够充分利用历史帧中的丰富信息,在跟踪过程中获取更多的目标变化,我们通过前面建立的双模板机制,让表观变化学习模型从静态模板和动态模板中同时学习目标的表观变化。

表1 参数α、β的取值对成功率的影响(OTB2015)Table 1 Influence of parameter values on success rate (OTB2015)
在跟踪完t− 1帧后,以预测位置为中心,在t− 1帧裁剪出与模板相同大小的区域Ot−1,并计算出其深度特征f(Ot−1),我们可以让f(Ot−1)相似于静态模板Os和动态模板Od的特征f(Os)和f(Od),通过求解式(11)和式(12),学习目标表观变化Vs和Vd。

其中:Fs=f(Os),Fd=f(Od),Ft−1=f(Ot−1)。在跟踪过程中,目标的表观变化可视为平滑变化,将学习到的目标表观变化Vs和Vd分别和f(Os) 和f(Od) 进行循环卷积操作,可以使模板适应目标形变、目标遮挡等情况。
3.3.2 背景抑制学习
在线跟踪时,为减少搜索区域中背景对跟踪器的干扰,在跟踪完t−1 帧后,我们以预测位置为中心裁剪出一个与搜索区域大小相同的区域Gt−1,并计算其颜色直方图特征得到该区域的目标似然概率图,如图3 所示。因为深度特征含有较多的语义信息,缺乏空间表征,所以将目标似然概率图与深度特征FGt1−融合,可以有效抑制背景干扰,突出目标的空间细节,弥补深度特征的不足。

图3 搜索区域及其目标似然概率图Fig.3 Search area and its target likelihood probability graph
将Gt−1划分为目标区域O 和背景区域B,并结合贝叶斯公式计算Gt−1区域内每个像素x属于目标区域O 的概率:

令b表示第b个颜色空间,bx表示像素x属于第b个颜色空间,并计算Gt−1中目标和背景区域的颜色直方图根据文献[18],该区域像素点的目标似然概率可以化简为

利用双线性插值对Gt1−区域的深度特征进行上采样,使其与目标似然概率图P的尺寸相同,然后对两者逐元素相乘进行融合[19]。

其中:⊙表示逐元素相乘,↑表示上采样。本文使用AlexNet[20]作为特征提取网络,选取Conv5 层特征与目标似然概率图融合,弥补了深层特征仅包含语义信息,缺乏空间信息的不足,有效抑制了搜索区域中的背景干扰。然后令Gt−1的深度特征相似于与目标似然概率图融合后的深度特征,可以学习到背景抑制
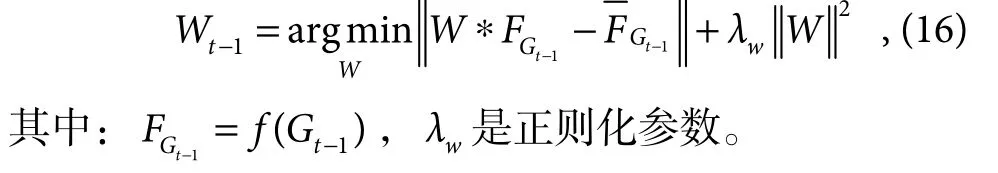
3.4 目标定位
在线跟踪时,跟踪器可以通过快速变换模型从双模板中学习到目标的表观变化Vs和Vd,并与模板图像特征f(Os) 和f(Od) 进行循环卷积操作,由背景抑制模块学习到的Wt−1也与搜索区域特征f(Zt)进行循环卷积操作,之后对模板分支和搜索分支提取到的特征进行相似性计算得到两个响应图,最终当前帧中目标位置由两个响应图加权融合得到:

其中:corr 表示相似性计算,∗表示循环卷积操作,Rs和Rd分别表示通过静态模板和动态模板得到的响应图,Rt为当前帧加权融合后的响应图,Rt中最高响应位置即为预测目标位置,λ作为衡量两路网络重要性的超参数,应对静态模板赋予较大的权重,在保证跟踪性能的同时又不会导致模型漂移。在表2 中给出了参数λ取不同值时对算法成功率的影响,通过大量实验并结合对响应值的综合分析,确定权重因子λ为0.75。
3.5 尺度估计
获取目标定位后,以预测位置为中心进行多尺度采样,本文算法采用 3 个尺度因子,γ=[0.9639,1,1.0375],并将得到的多尺度候选区域转换为255×255×3 大小输入网络,把产生最大响应的作为最佳尺度因子。
最终目标尺度更新式:

其中:(wt,ht)表示当前帧响应最大的尺度,(w t−1,ht−1)表示前一帧目标尺度,τ控制目标尺度的变化速度,在文献[21]算法CREST 中,该参数被设置为0.4,本文采用相同的参数设置进行尺度估计。
3.6 算法流程
本文算法流程如下。


4 实验结果与分析
本文算法的实验平台为Windows 10 系统下的MATLAB 2017b+Visual Studio 2015,所有的实验均在配置为Intel(R) Core(TM)i7-6850k 3.6 GHz 处理器、内存为16 GB 的电脑上进行测试,并采用GPU(NVIDIA GTX 1080Ti)进行加速。为验证本文算法的有效性,我们分别在三个主流的跟踪数据集上做了实验:包含100 个视频序列(77 个彩色序列)的OTB2015[13]、包含128 个视频序列的TempleColor128[14]数据集和VOT[15]数据集。
4.1 OTB2015 实验
4.1.1 定性分析
图4展示了本文算法与4种算法的部分跟踪结果,为说明本文算法在复杂场景下的跟踪性能,我们主要从以下4 个方面对算法进行定性分析:
1) 目标形变。跟踪过程中的目标形变会使当前帧与模板难以匹配,如视频序列MotorRolling 和Diving,在视频序列的前段,所有算法均可跟踪到目标,但在后续帧中,当目标出现旋转时,SiamFC、DSiam、Staple[22]等算法都会跟踪失败,而本文算法通过双模板在线学习目标的表观变化使模板及时适应目标形变,可以在一定程度上解决该问题,仍能较好地跟踪目标。
2) 目标遮挡。目标遮挡是跟踪中常见的问题,如视频序列Liquor 和DragonBaby,目标在运动过程中会出现部分遮挡,在遮挡情况下,通常的模板更新容易使模型漂移,造成跟踪失败。本文算法通过双模板机制,并结合高置信度更新策略,在发生遮挡时避免对模板进行更新,有效避免了模型漂移。

表2 参数λ的取值对成功率的影响(OTB2015)Table 2 Influence of parameter λ values on success rate (OTB2015)

图4 5 种算法部分跟踪结果对比Fig.4 Comparison of partial tracking results of 5 algorithms
3) 快速运动。在视频序Bolt2 和Soccer 中,目标的快速运动容易导致图像模糊,使目标表观发生变化。在视频Bolt2 中,Staple[21]算法在第72 帧就丢失目标,SiamFC[5]和SiamTri[6]也在第190 帧丢失目标,本文算法通过双模板在线学习目标的表观变化和背景抑制,在快速运动的情况下能够跟踪到目标。
4) 尺度变化。以视频序列Box 和Woman 为例,目标在跟踪过程中均发生了明显的尺度变化。在Woman 视频564 帧中,目标尺度明显变大,但大多数算法均跟踪失败,本文算法采用3 个尺度因子,通过相邻帧尺度自适应策略,在保证速率的同时能够应对目标的尺度变化。
4.1.2 定量分析
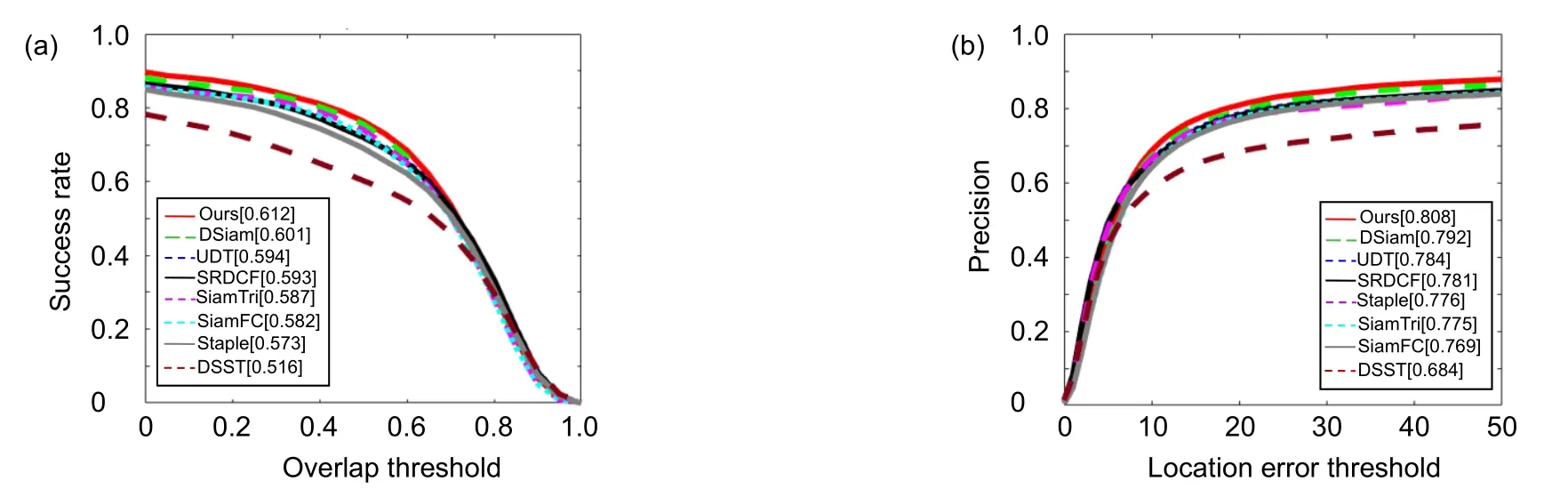
图5 OTB2015 数据集上不同算法的成功率(a)和精度图(b)Fig.5 Success rate (a) and accuracy (b) of different algorithms on OTB2015 data set
在OTB2015 数据集上,跟踪性能的主要评价指标是成功率和精确度。当预测跟踪框与视频标定跟踪框的重叠率大于一定阈值时,视为跟踪成功,成功率是指跟踪成功的帧数与总帧数的比值。目标中心位置误差由跟踪结果与人工标定的目标中心位置之间的欧氏距离确定,精确度是指目标中心位置误差小于一定阈值的帧数与总帧数的比值。
本文算法与近年来主流的跟踪算法进行了比较,包括基于深度学习的跟踪算法SiamFC[5]、DSiam[11]、UDT[23]、SiamTri[6]和基于相关滤波的跟踪算法SRDCF[24]、Staple[22]、DSST[25]。图5 展示了9 种算法在OTB2015 数据集上的成功率曲线和精确度曲线,与基准算法相比,本文算法在OTB2015 数据集上的精确度提高了1.6%,成功率提高了1.1%。
OTB2015 数据集中包含11 种视频属性,包括尺度变化(SV)、快速运动(FM)、运动模糊(MB)、背景混杂(BC)、遮挡(OCC)、光照变化(IV)、形变(DEF)、低分辨率(LR)、平面内旋转(IPR)、平面外旋转(OPR)、目标超出视野(OV),表4 和表5 分别展示了在11 种不同属性下算法跟踪的成功率和精度。其中最优结果加粗显示,次优的算法结果由实下划线表示,排名第三的算法结果用虚下划线表示。

表4 不同属性下算法的跟踪成功率对比结果Table 4 Comparsion results of tracking success of the algorithm under different attributes

表5 不同属性下算法的跟踪精确度对比结果Table 5 Comparsion results of tracking accuracy of the algorithm under different attributes
4.2 TempleColor128 实验
TempleColor128 也是一个极具挑战性的数据集,它包含128 个彩色视频序列,专门用于评估算法在颜色属性上的跟踪性能。本文算法和8 种算法进行了对比,包括DSiam[11],SiamFC[5],MEEM[26],CFNet[27],UDT[22],SRDCF[23],BACF[28]。本文算法在精确度上提高了1.2%,成功率上提高了0.9%,如图6 所示。
4.3 VOT 实验
本文算法在VOT2015[15]数据集上进行了实验。VOT(visual object tracking)测试平台是目标跟踪领域中主流的测试平台,其测试结果具有较高的权威性。VOT2015 都包含60 个视频序列,不同于OTB2015、TempleColor128 等测试平台,它主要从准确率、鲁棒性、期望平均重叠率等方面来评估算法性能。准确率通过计算预测目标框和标签的平均重叠率获取,鲁棒性的计算通过统计跟踪过程中的失败次数得到,基于准确性和鲁棒性,最终计算出期望平均重叠率来反应算法的性能,表6 展示了本文算法与近几年的主流跟踪算法在VOT2015 数据集上实验结果,与近几年的主流跟踪算法相比,在期望平均重叠率上有一定的提升。

图6 TempleColor128 数据集上不同算法的成功率(a)和精度图(b)Fig.6 Success rate (a) and accuracy (b) of different algorithms on TempleColor128

表6 VOT2015 数据集上不同算法的精度和鲁棒性对比结果Table 6 Evaluation on VOT2015 by the means of accuracy and robustness
4.4 消融实验
本文在基准算法的基础上引入了双模板机制和背景抑制模块。其中双模板机制是在跟踪阶段,将第一帧中的目标当作静态模板,在后续帧中使用高置信度更新策略获取动态模板,使得快速变换模型可以从双模板中学习目标的表观变化;背景抑制模块是根据当前帧的颜色直方图特征计算出搜索区域的目标似然概率图,与深度特征融合,进行抑制背景学习。
为验证本文方法的有效性,在OTB2015 数据集上分别对两个模块进行了实验。图7 中,DSiam+T 表示在基准算法上只加入双模板机制,DSiam+B 表示在基准算法上只加入背景机制模块。在OTB2015 数据集上的实验结果表明,当只在基准算法上引入双模板机制时,精度和成功率分别提高了1.3%和0.7%;当只在基准算法上加入背景抑制模块时,精度和成功率分别提高了0.6%和0.3%。通过实验,可以有效验证本文所提两个创新点的可行性,对算法的性能均有一定的提升。
4.5 算法跟踪速度

图7 OTB2015 数据集上加入不同模块算法的成功率(a)和精度图(b)Fig.7 Success rate (a) and accuracy (b) of different modules are added into the algorithm on OTB2015 data set
本文算法在跟踪过程中引入双模板学习目标的表观变化,并在背景抑制模块采用颜色直方图特征对跟踪目标的背景进行抑制,对算法跟踪速度有一定的影响。为保证跟踪速率,降低算法在特征提取和相关性计算上的耗时,本文并未采用逐帧更新方式,而是通过引入APCE 指标,只在该帧响应图的APCE 指标达到一定阈值时才对模板进行更新,降低了更新频率和特征提取次数,同时在实验中采用GPU 加速,使本文算法的跟踪速度达到了实时性要求,速度为29 f/s。如表7 所示。
5 结论与展望
本文提出的基于在线学习的Siamese 网络跟踪算法,通过静态模板和动态模板在线学习的目标的表观变化,并依据高置信度更新策略对动态模板进行更新。在背景抑制模块,通过计算搜索区域的颜色直方图特征获取目标似然概率图,与深度特征融合,进一步加强了背景抑制学习。在OTB2015,TempleColor128 和VOT 数据集上的实验结果表明,本文算法的测试结果与近几年的主流算法相比均有提高。在下一步工作中,我们尝试将目标表观学习和背景抑制加入其它算法,因为大多数基于孪生网络的跟踪算法仍缺乏模型的在线更新,该模块的引入可能会在一定程度上解决该问题。随着更多网络结构的提出,例如SiamRPN[7],SiamDW[29],SiamRPN++[30],TADT[31]等,针对特征提取,能否引入更加鲁棒的特征提取网络也将是我们下一步工作研究的重点。

表7 本文算法与不同算法的跟踪速度对比Table 7 Comparing our method with different trackers in terms of tracking speed
猜你喜欢
建材发展导向(2022年23期)2022-12-22
建材发展导向(2022年12期)2022-08-19
汽车工程师(2021年12期)2022-01-17
河北果树(2021年4期)2021-12-02
当代陕西(2020年14期)2021-01-08
上海公路(2019年3期)2019-11-25
福建基础教育研究(2019年10期)2019-05-28
贵州师范学院学报(2016年4期)2016-12-01
中国房地产业(2016年24期)2016-02-16
中国卫生(2015年9期)2015-11-10
