
基于历史通行数据的假冒绿通车逃费行为预测
2021-05-14 02:02刘昱岗徐旭东王添碧叶劲松
公路交通科技 2021年4期
刘昱岗,郑 帅,徐旭东,王添碧,叶劲松
(1.西南交通大学 交通运输与物流学院, 四川 成都 610031;2.西南交通大学 综合交通运输智能化国家地方联合工程实验室,四川 成都 610031; 3.交通运输部科学研究院,北京 100088;4.四川省交通运输发展战略和规划科学研究院,四川 成都 610001)
0 引言
为响应惠农兴农的精神,四川省于2010年12月1日全面给予运输鲜活农产品车辆“绿色通道”政策支持。但一些不法车主利用该政策,通过“混装”即在普通货物上覆盖一层鲜活农产品的方式逃缴通行费,给高速运营部门带来了巨大损失。现阶段逃费行为频发,但针对假冒绿通车的稽查手段却相对落后,主要依靠工作人员在车道现场对每辆出站绿通车开箱检验,极少数收费站安装了放射源绿通车专业检测设备。随着鲜活农产品运输需求扩大,绿通车通行量增加,绿通车稽查工作面临的检查难、效率低、成本高、风险大的难题更突出,成为高速公路稽查管理部门亟待解决的问题。
现阶段大数据、数据挖掘技术已经完全具备实际应用能力,将其应用到绿通车排查,可以为绿通车检查工作提供决策参考,降低假冒绿通车成功逃费情况的发生概率,从而提高检查假冒绿通车的效率及收费站通行效率。
国内研究学者对高速公路绿通车稽查管理工作做了大量相关研究,主要从2个方面来解决假冒绿通车逃费的问题。一是通过优化政策和完善制度来解决绿通车管理中存在的不足,二是通过运用放射源等检测设备、图像识别、数据挖掘、互联网等新技术来检查或管理绿通车。国外由于无“绿色通道”类似政策,其研究更多偏向高速公路收费政策、高速公路管理技术应用等方面。陈力[1]认为在全面取消省界收费站且继续执行现有“绿色通道”政策的背景下,建议将绿通车传统的“先检查后免费”模式转变为“先收费后退还”的模式,并根据绿通车诚信度建立分级备案机制,对诚信度高的车辆免检、抽检,对诚信度低的车辆必检。牛建强等[2]建议建立鲜活农产品基准密度库,利用光电体积测算法获取检查车辆的装载体积,再对比车辆装载密度与基准密度的偏差,判断是否混装。熊文磊[3]以放射源扫描绿通车形成的特殊影像作为初始数据集,建立了一个具备影像识别功能的预测模型,并通过试验分析证明了模型的有效性与先进性。孙晓宁[4]提出建立集数据采集、分析、处理为一体的便携绿通查验平台,以实现多系统多平台同步操作、联动存储、多角度监控及移动监管的功能。在数据挖掘技术方面,陈浩泰[5]基于生鲜车辆的高速通行数据利用Logistic回归模型构建了针对家禽肉的假冒绿通车分类模型,并有较好分类效果。申长春[6]针对绿通车的非均衡属性采用机器学习的方法,并结合BP神经网络,进一步提升了对假冒绿通车的分类效果。任文龙和申长春[6-7]针对绿通车的非均衡属性采用机器学习的方法,利用收费记录中的特征字段和偷逃通行费现象之间的关联,分析并设计了用于辅助收费稽查的BP神经网络模型,进一步提升了对假冒绿通车的分类效果。雷毅等[8]和张萌[9]对高速公路网内绿通车流量进行数据分析,确定了绿通车检查点的规划布设来提高绿通车检查资源的利用率。
综上所述,目前对高速公路绿通车稽查方面的研究内容不够丰富,数据集和算法应用的研究十分有限,仅有Logistic回归模型和神经网络等算法在绿通车收费数据得到应用。
机器学习作为预测性分析的常用方法,可从历史假冒绿通车数据中获取规律或模型,应用到类似场景中。因此,本研究利用决策树来建立假冒绿通车预测模型,并比较不同算法的预测准确率找出最优的算法,通过预测车辆假冒绿通车的概率,提前预警提醒稽查工作人员重点检查,以提高绿通车稽查效率。
1 绿通车逃费行为研究
1.1 原始绿通车通行数据集
2019年1月至3月,四川高速公路建设开发集团有限公司(简称“川高”)查获了3 244起假冒绿通车通行事件。本研究以联网收费系统的3 244辆假冒绿通车数据作为研究对象,并从系统中随机导出2019年1月至3月12 976条正常绿通车通行数据为参照对象,提取数据的特征属性,分析假冒绿通车逃费行为特征,并建立假冒绿通车逃费行为预测模型。
1.1.1数据属性提取原则
(1)重要度。剔除车辆信息影响较小的属性或其他无意义属性,保留相对重要属性(车辆行驶路径与地理坐标等属性)或增添其组合属性。
(2)可靠度。利用货车通行正态特征,采用拉依达分析方法剔除整体离散程度较大的属性,保证数据特征的明显性与可靠性。
1.1.2数据属性范围分析
经预处理后,每条数据包含17个属性:目标变量y,y∈{0,1},其结果表示数据车辆是否为假冒绿通车;车辆数据变量xij,包括车辆信息集合、收费站信息集合、通行过程信息集合3个方面,16个自变量,变量基本分析见表1。
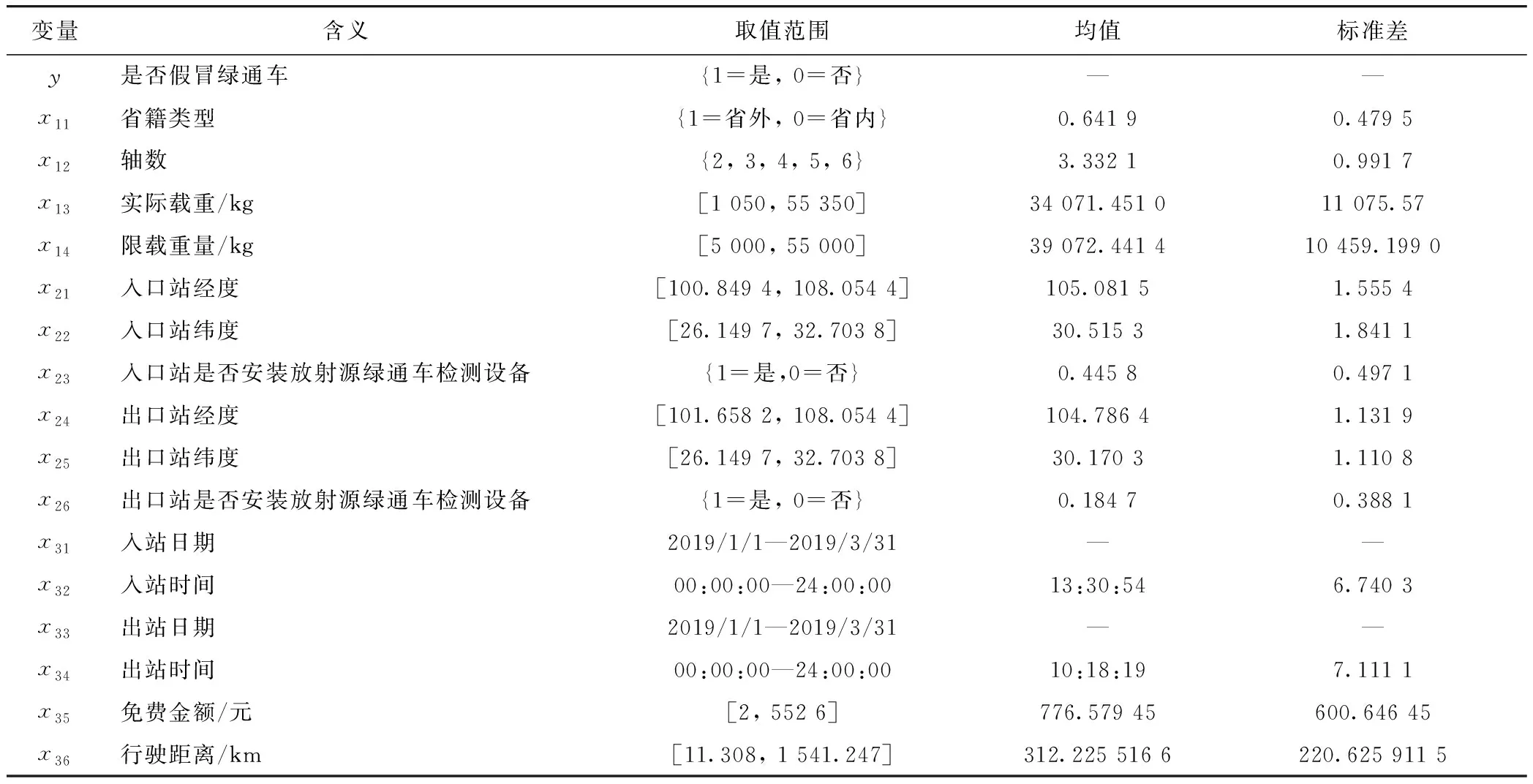
表1 变量特征分析
考虑部分变量对车辆数据信息展示直观度不强,采用变量组合运算,得到6个新增变量zi,见表2,以期从更全面的角度来分析假冒绿通车逃费行为。
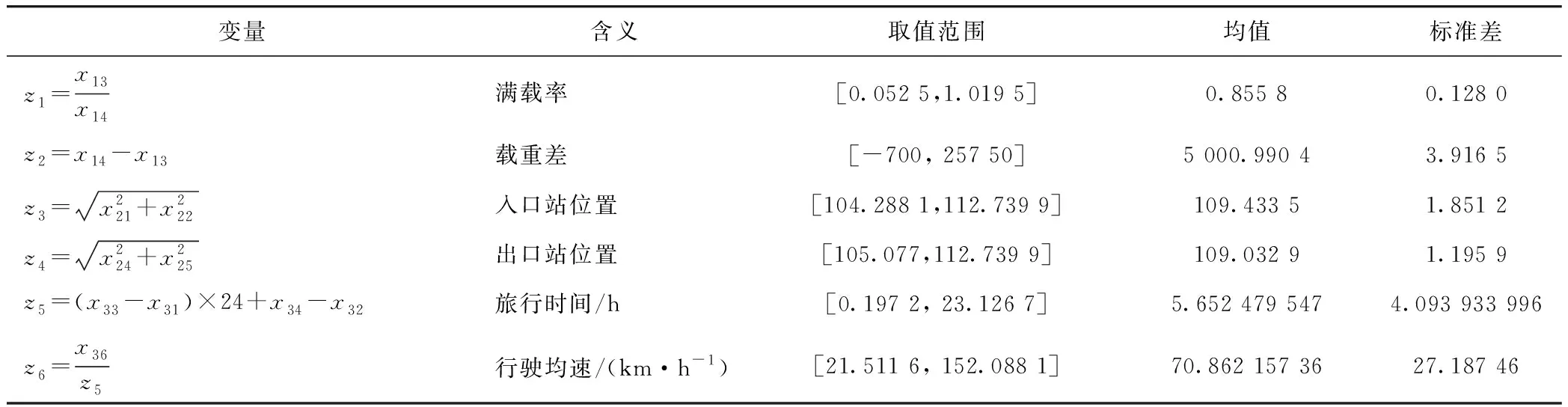
表2 新增自变量基本统计分析
1.2 逃费行为特征分析
对2019年1月至3月川高查获的3 244起假冒绿通车通行事件的通行数据进行逃费行为特征分析。
1.2.1时间特性
据图1, 假冒绿通车通行在1周的分布差异性较大,在星期一和星期三查获的假冒绿通车数量相对较少;入站高峰时期为18:00—24:00,出站高峰时期为凌晨1:00—7:00,且整个过程的行驶时间主要集中在4~10 h。考虑到绿通车检查现状是工作人员检查记录后放行,可能大部分假冒绿通车倾向于选择工作人员比较疲惫和放松警惕的时间段入出收费站,如:晚上18:00—24:00、凌晨1:00—7:00。
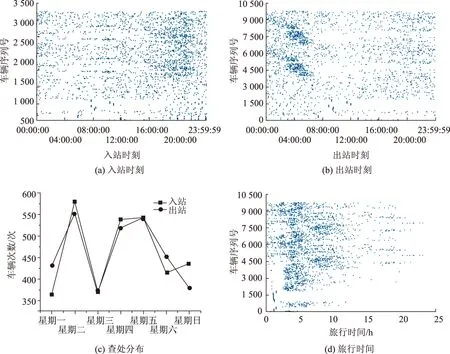
图1 假冒绿通车通行的时间特征Fig.1 Time characteristics of passing of fake TFLVs
1.2.2空间特性
川高在7个绿通车流量大站安装了绿通车检测设备,用于判断车辆是否为绿通车。为判断假冒绿通车的空间通行特性,针对本次采集到的假冒绿通车数据分析其OD属性、路径流向,得到以下特征:假冒绿通车OD属性与行驶轨迹在空间均具有路径集中趋势,主要分布在邻垫四川站-达渝四川站、棋盘关站-绵阳站、宜宾北站-大件站高速公路区间。
3 244辆假冒绿通车通过121个收费站进入、通过111个收费站离开高速公路网络,其中仅有6个站安装了绿通车检测设备。基于此特征分析:假冒绿通车在进出高速公路的过程中倾向于避开安装绿通车检测设备的收费站,选择稽查强度薄弱的路段通行,其可能存在的路径选择情况见图2。
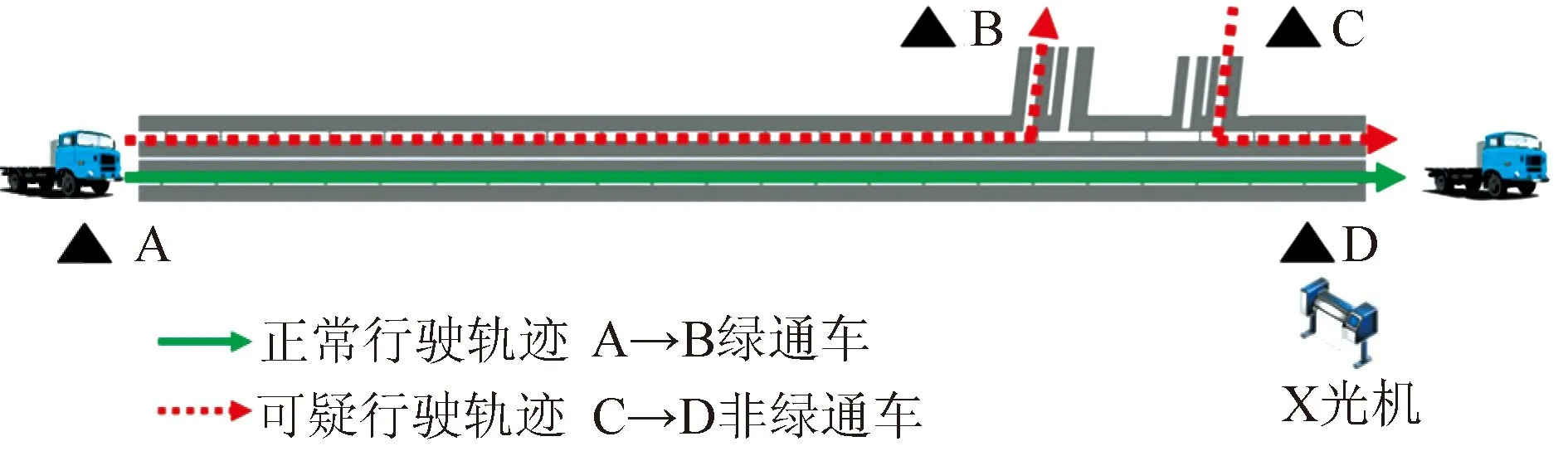
图2 假冒绿通车可能存在的路径选择情况Fig.2 Possible routing options for fake TFLVs
1.2.3其他特性
(1)车牌省籍
据图3,假冒绿通车属地主要为外省,占比63.63%,原因可能是外省绿色通道政策与四川省存在差异,并且外省通行信用记录与四川省通行信用记录不互通。
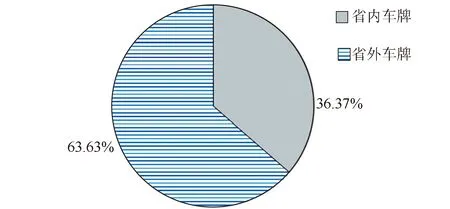
图3 假冒绿通车车牌省籍情况Fig.2 License plate provincial status of fake TFLVs
(2)行驶特征
根据假冒绿通车的行驶均速与行驶距离频率分布情况绘制分布函数曲线,如图4所示。
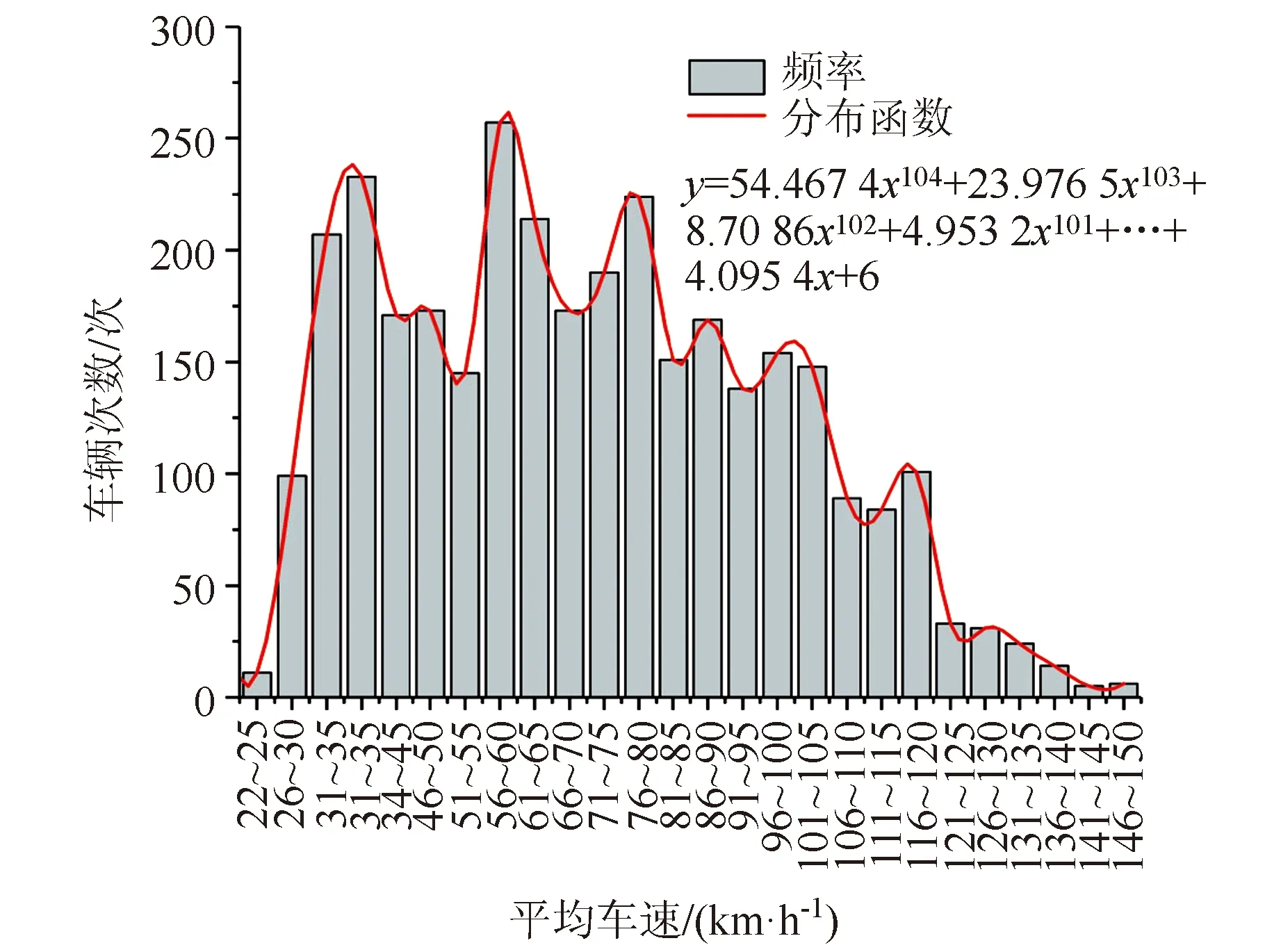
图4 假冒绿通车速度Fig.4 Travel speeds of fake TFLVs
如图4所示,车辆旅行平均速度范围是22~150 km/h,其中,46.54%的假冒绿通车速度处于高速公路规定货车行驶速度范围外:40.2%低于60 km/h,6.34%超速行驶,该部分车辆可能是为寻求离开高速公路合适时间而选择滞留于服务区或加速行驶。
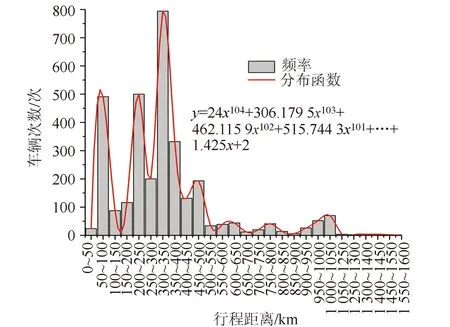
图5 假冒绿通车行驶距离分布Fig.5 Distribution of travel distances of fake TFLVs
如图5所示, 70.28%的假冒绿通车行驶距离集中在150~500 km的范围,小部分车辆为短途运输,造成该情况的原因可能是高速公路通行费用是根据车辆行驶距离与载货重量来收取,当运输距离较长时假冒成绿通车逃缴金额较高,对驾驶员利益诱惑更大。
(3)载重分析
假冒绿通车的实际载重情况如图6所示。实际载重分别集中在3个区间,13.62%位于12~16 t之间、53.32%位于30~40 t之间、16.28%位于45~50 t之间。假冒绿通车的满载率如图7所示。9.43%的假冒绿通车满载率超过100%,61.51%的假冒绿通车满载率超过85%。造成该情况的主要原因可能是每次假冒绿通车载货越多,越有利可图。此外满载率越高,车厢货物堆积越紧密,工作人员检查难度增加,假冒成功率增加。
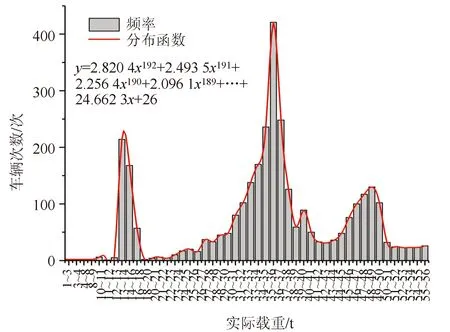
图6 假冒绿通车实际载重Fig.6 Actual loads of fake TFLVs
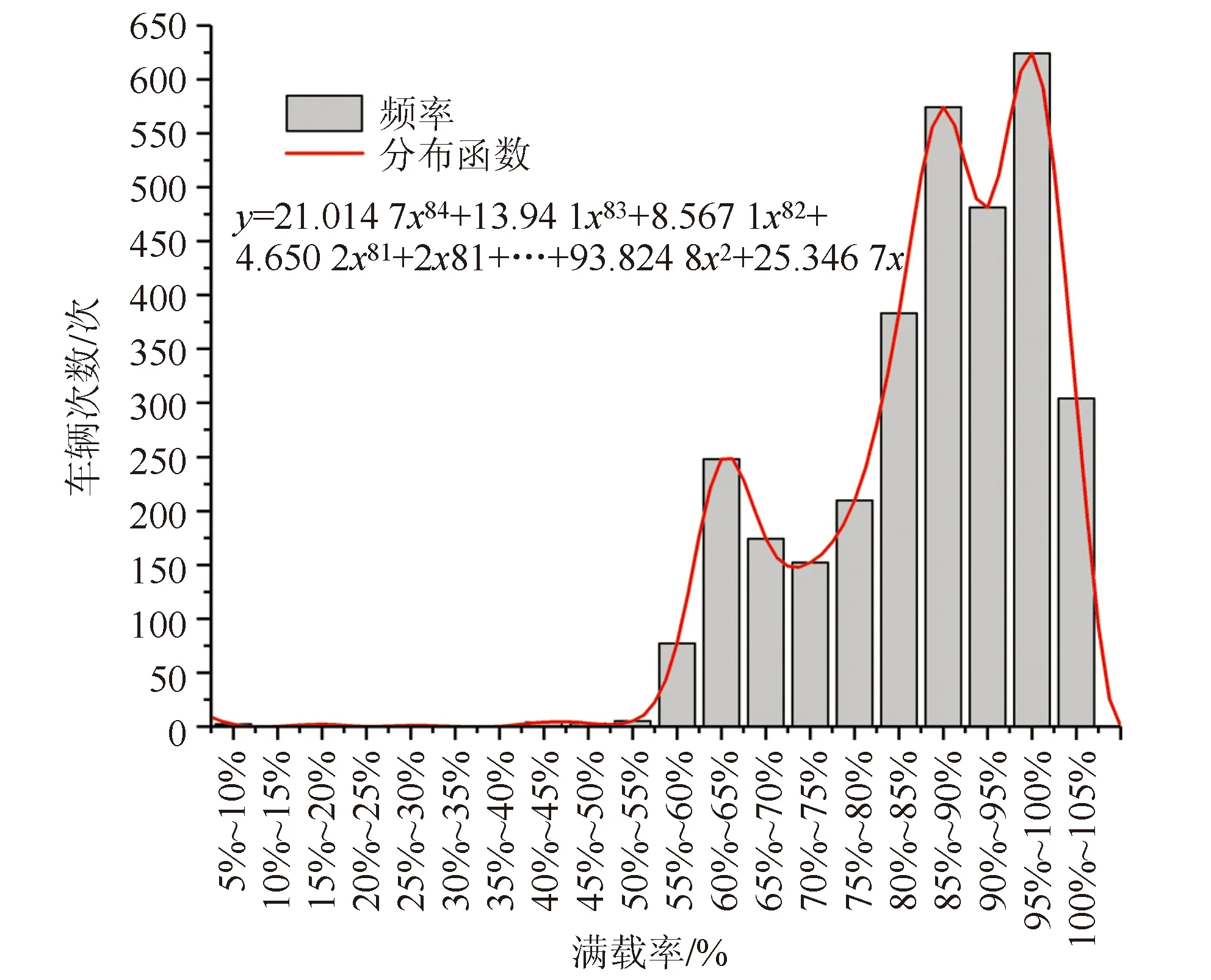
图7 假冒绿通车满载率情况Fig.7 Full load rates of fake TFLVs
分析了高速公路假冒绿通车的时空分布特征,以及在行驶特征、载重分析等方面的表现情况。
2 绿通车通行数据集预处理
由于采集的原始绿通车通行数据集中,各类属性的量纲不同,时空特征分布不均衡,取值范围有一定的差异性,因此需要对绿通车数据集进行采样、离散化、关联项与共线性检验等系列预操作后,再进行建模分析。
2.1 绿通车通行数据采样
绿通车数据集是典型的非平衡数据集,合格绿通车样本为多数类,假冒绿通车样本为少数类,因此本研究采用Synthetic Minority Oversampling Technique(SMOTE)对绿通车数据集进行平衡处理[10-12]。基于SMOTE算法改进形成的Borderline-SMOTE算法能很好地控制新合成的少数类样本使其处于两个类别的边界附近,解决SMOTE算法导致的边界模糊问题。
利用Borderline-SMOTE算法对12 976条正常绿通车通行数据和3 244假冒绿通车通行数据进行过采样,得到12 976条假冒绿通车通行数据,正负比由4∶1到1∶1,基本达到均衡数据集的目的。
2.2 绿通车通行数据离散化
本研究采用考虑样本所属类别信息的ChiMerge方法(卡方分箱法)对连续数据离散化预处理。该方法可以考虑到目标类别的信息差异性,也被称为全局数据离散化方法[13]。具体操作为:按照特定的排序方法对通行数据集进行排序,并对数据离散区间计算卡方统计值,对统计值不满足阈值的区间进行合并,直到离散的区间达到预期,停止离散过程。
选择ROC曲线用于确定绿通车通行数据中连续型属性离散化的区间划分数,利用曲线下面积(AUC)来表示离散区间个数,离散过程的截止条件为离散后的绿通车数据能够有效表达原始绿通车的通行数据特征[14-15]。利用ChiMerge算法将连续变量离散化,结果如表3所示。
表3 连续变量离散化结果
2.3 关联项检验
绿通车通行数据的属性较多, 并不一定都是影响因素, 如果全部选入预测模型, 会影响运行时间和预测精度。先利用K-S检验检验连续值的正态性(sig>0.05, 服从正态分布), 再采用独立t检验检验符合正态分布的连续值自变量与结果的关联性(sig<0.05,有显著性影响);采用Mann-WhitneyU检验,检验不具有正态分布特征的初始连续型属性与结果的关联性(U<0.05,有显著性影响);采用Pearson卡方检验检验离散属性与结果的关联性(χ2<0.05,有显著性影响)。通过检验各自变量与结果的关联性,分析各自变量对结果的影响,并选取合适的自变量。
结果显示x11(省籍类型),x12(货车轴数),x14(限载重量),x23,x26(出入口站安装绿通车检查设备情况)的Pearson卡方检验值χ2<0.01,因此这4类属性与车辆是否为假冒绿通车具有较大的关联性。
2.4 共线性检验
为保证模型预测结果的可靠性,需要对自变量进行属性约简,减少合并具有共线性的属性。首先采用容忍度和方差膨胀因子的方法来判断属性的共线状态,进而得到离散数据转化的协方差矩阵,并计算协方差矩阵的特征根与对应的特征向量,再根据特征根的贡献程度判断自变量的重要程度[16-17]。最后将通过关联项检验和共线性检验的属性选入假冒绿通车逃费行为预测模型。
根据结果,将x12(货车轴数)、x14(限载重量)、z2(载重差)、z1(满载率)剔除,不放入分类预测模型。
2.5 处理后绿通车通行数据集
对绿通车通行数据的22个属性进行关联项和共线性检验后,共剔除x12(货车轴数)、x13(实际载重)、x14(限载重量)、x31(入站日期)、x33(出站日期)、z1(满载率)、z2(载重差)7个属性,不计入x21,x22,x24,x25(出入口站经纬度)采用其组合属性,共得到11个属性。
3 逃费行为预测模型建立与分析
经上述处理,再将数据集划分为测试数据集(正常绿通车通行数据6 488条+假冒绿通车通行数据6 488条)和训练数据集(正常绿通车通行数据6 488 条+假冒绿通车通行数据6 488条)。
3.1 决策树模型
决策树是一种研究对象的属性即xij与对象的值即y之间的映射关系的树结构模型[18]。决策树建模流程如图8所示。
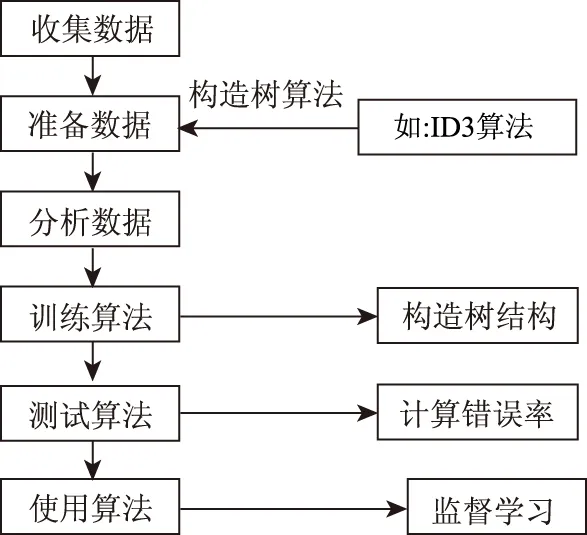
图8 决策树建模流程Fig.8 Flowchart of decision tree modeling
本研究需要区分车辆是否为假冒绿通车,是一个二分类变量。因此用CART算法来构造逃费行为决策树,将基尼系数作为最小分类标准。基尼系数的计算如下:
(1)
式中,k为车辆是否为假冒绿通车;pi为决策输出变量属于第k类的概率值。
据表4的决策树模型分类结果来看,对正常绿通车的判断能力达到97.0%,对假冒绿通车的识别效果为83.4%。总体来说对假冒绿通车逃费行为的识别效果较好,验证数据的准确率高达90.2%。由预测结果绘制混淆矩阵见图9。
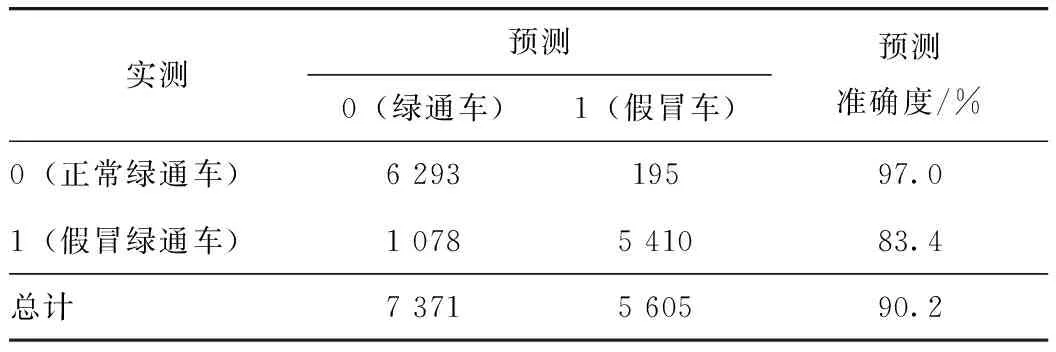
表4 决策树模型分类预测结果
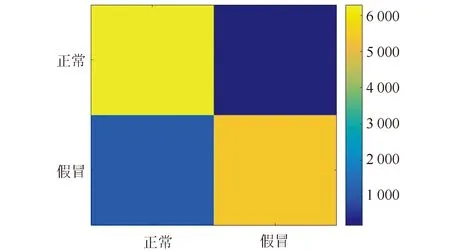
图9 决策树模型的混淆矩阵Fig.9 Confusion matrix of decision tree model
决策树模型的自变量见表5,其中连续型变量需离散化才能利用决策树建模,前文利用ChiMerge算法对连续型变量实现离散化,并利用ROC曲线确定最优的区间划分方式。利用基于基尼系数的CART算法来构造决策树,按照基尼系数的大小,从小到大、从上至下生成子节点,直到决策树不可分枝为止。

表5 选入决策树的变量及变量的重要程度
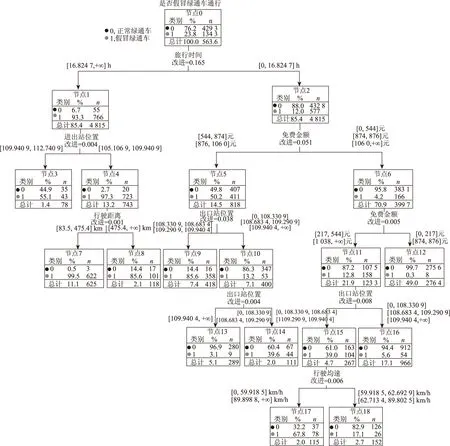
图10 假冒绿通车逃费行为决策树结构Fig.10 Decision tree structure of fake TFLVs evasion behaviors
最终表5的11个变量均被纳入决策树模型,未剔除任何变量。但这11个变量对模型的贡献程度不同,其中最重要的变量是z5(旅行时间),说明假冒绿通车与正常绿通车在高速公路上行驶的旅行时间分布有较大差别。
据图10可知,假冒绿通车逃费行为决策树结构中,与假冒绿通车逃费行为显著相关的变量有z5(旅行时间)、z4(出站位置)、x35(免费金额)、x36(行驶距离)和z6(行驶均速)等,总结出假冒绿通车逃费行为特征如下。
特征1:大部分假冒绿通车逃费行为的x35(免费金额)处在中等水平,即[544, 874]和 [876, 1 060]2个范围之内,原因可能是免费金额太低不值得犯险、免费金额太高在收费站势必面临更加严格的检查,假冒成功的概率降低。
特征2:大部分假冒绿通车逃费行为z6(行驶均速)处在2个极端,即[0, 59.918 5]和[89.898 8,+∞],而大部分合格绿通车则处在[59.918 5, 89.898 8]。原因可能是假冒绿通车的驾驶员在等待或赶上某个时机离开收费站,这个特殊时机可能是绿色通道拥堵,大量绿通车排队,导致工作人员只能快速检查并放行,还可能是工作人员稽查强度的薄弱时段。
特征3:假冒绿通车与正常绿通车的z4(出站位置)也有明显区别,原因可能是假冒绿通车行驶轨迹在空间具有路径集中趋势,在进出高速公路的过程中倾向于避开安装了绿通车检测设备的收费站,选择稽查强度薄弱的路段通行。
3.2 模型预测结论分析
本研究采用Logistic回归模型和随机森林模型进行假冒绿通车逃费行为建模分析,并将其分析结果与决策树模型的分类结果进行比较。
Logistic回归模型是一种利用变量间相互作用的概率作为指标的预测模型,可以弱化不同量纲属性的多类别属性对结果的影响,因此可以用于预测车辆是否为假冒绿通车[19]。表6为Logistic模型对假冒绿通车的分类预测情况,Logistic模型对正常绿通车的判断能力更精准,达到98.7%,但是对假冒绿通车的识别效果不是十分理想,只有61.8%。
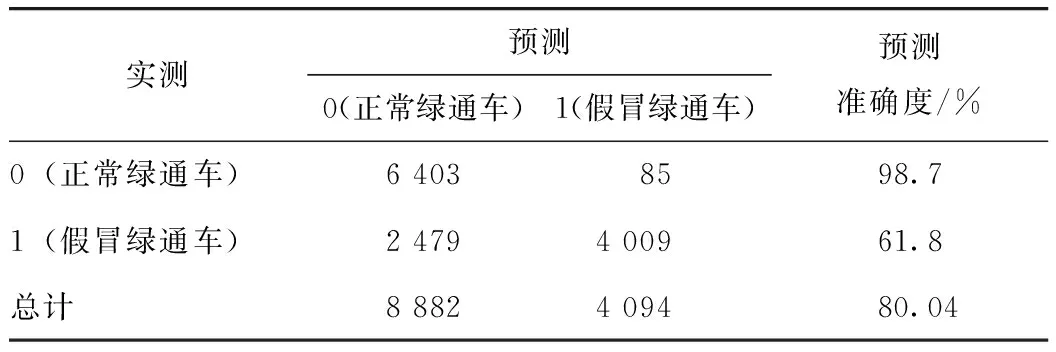
表6 Logistic模型分类预测结果
随机森林是目前比较流行且对回归和分类问题有很好效果的算法[18]。将随机森林模型应用到假冒绿通车逃费行为分类预测,结果如表7所示,其预测假冒绿通车的能力和Logistic回归模型的预测能力相似,可以达到97.4%,但对假冒绿通车的识别效果不是十分理想,只有81%。
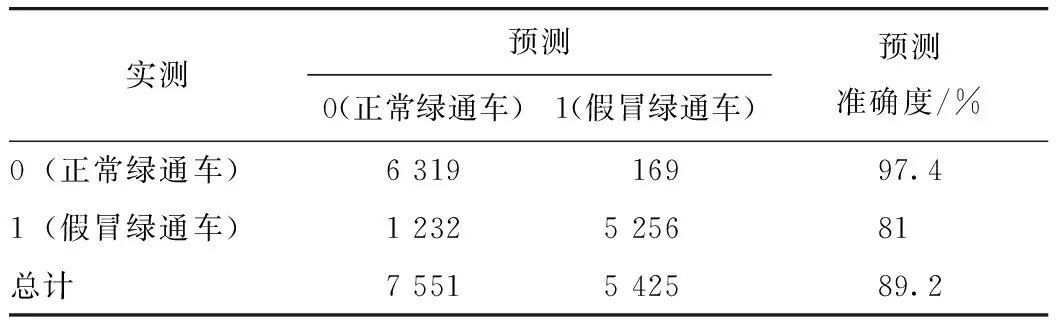
表7 随机森林模型分类预测结果
利用测试数据集来验证3个模型的分类效果,并绘出各个模型的ROC曲线(图11),计算各个模型的AUC值,结果见表8。认为AUC值最大的模型分类效果较好,为较优的模型。
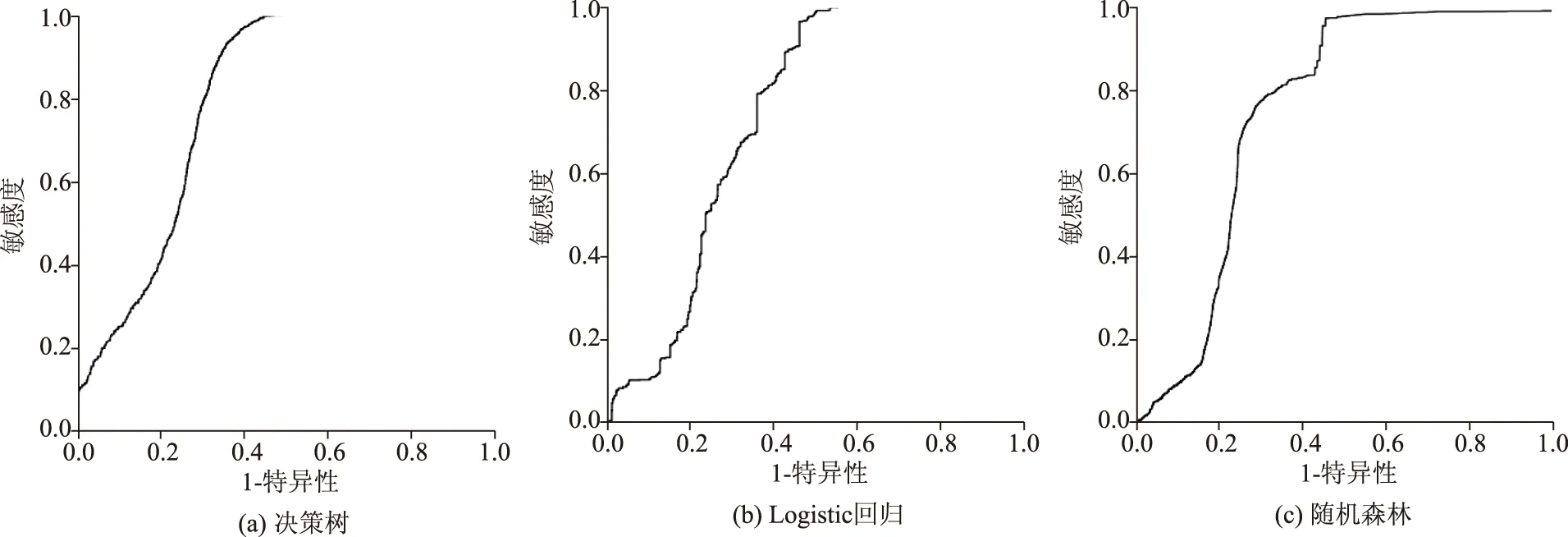
图11 ROC曲线Fig.11 ROC curve
3个模型均能够达到分类预测能力,但相较于分析对假冒绿通车的识别,决策树模型对测试集数据的反映效果最佳。因此决策树模型对假冒绿通车的识别效果优于Logistic回归模型和随机森林模型。
3.3 应用流程分析
实际应用中,车辆在进入高速公路时将车辆入口时间、坐标等信息录入高速公路车辆收费系统,待绿通车到达出口收费站时,增添车辆到达收费站的出口时间、坐标等收费通行数据;利用假冒绿通车逃费行为预测模型,根据车辆行程数据预测其为假冒绿通车的概率值;工作人员可根据经验设定概率值标准,若概率值标准为70%,则将假冒绿通车概率值高于70%的车辆列为重点嫌疑对象,提前预警工作人员,为绿通车检查工作提供决策参考,把有限资源集中在重点对象上,提升绿通车检查的针对性,具体操作流程如图12所示。

表8 三种模型的ROC曲线下面积

图12 假冒绿通车预测操作流程Fig.12 Predictive operation process of fake TFLVs
4 结论
以高速公路假冒绿通车逃费行为为研究对象,基于联网收费系统的绿通车通行数据,建立了假冒绿通车逃费行为预测模型。
(1)利用Borderline-SMOTE算法过采样来平衡数据集,使得正常绿通车通行数据和假冒绿通车通行数据的正负比由4∶1到1∶1,达到均衡数据集的目的。
(2)采用ChiMerge方法离散化连续型数据,选择ROC曲线确定绿通车通行数据中连续型属性离散化的区间划分数。把免费金额、入站时间、出站时间、行驶距离、入站位置、出站位置、旅行时间、行驶均速8个变量,分别划分为6至7个区间。
(3)采用K-S检验、独立t检验、Mann-WhitneyU检验、Pearson卡方检验进行关联性检验,利用容忍度和方差膨胀因子判断自变量的共线情况,共剔除货车轴数、实际载重)、限载重量、入站日期、出站日期、满载率)、载重差7个属性。
(4)对处理后的绿通车通行数据,运用决策树来建立预测建模,得出其对假冒绿通车逃费行为的预测准确率为83.4%,优于其他模型,能为绿通车检查工作人员提供有效决策参考,提升工作效率。
由于外界因素的约束和自身能力的限制,论文还存在一些不足和值得进一步思考和研究的问题:
(1)本研究工作是基于四川省部分绿通车2019年1月至3月的通行数据展开的,可供离散挖掘的数据体量有限,为了最大程度反映出绿通车通行特征,未来工作将扩大数据量进行研究,提高假冒绿通车逃费行为分类模型的预测效果,防止出现过拟合问题。
(2)本研究选取的高速公路绿通车通行特征的属性还不够全面,属性的选取方式还不够科学,未来将进一步优化绿通车通行数据集的结构设计。
猜你喜欢
石油沥青(2022年3期)2022-08-26
环球时报(2022-03-26)2022-03-26
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
石油沥青(2020年1期)2020-05-25
成都信息工程大学学报(2019年3期)2019-09-25
石油沥青(2019年2期)2019-04-28
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
