
基于预训练语言模型词向量融合的情感分析研究
2021-05-14 03:57魏上斐乔保军于俊洋姚相宇
计算机应用与软件 2021年5期
魏上斐 乔保军 于俊洋 姚相宇
1(河南大学软件学院 河南 开封 475000) 2(河南大学计算机信息与工程学院 河南 开封 475000)
0 引 言
随着网络的盛行与网络技术的发展,用户可在网络中发表自己对事物的观点,这些观点中含有用户想要表达的情感因素。更加准确地发掘评论中的情感因素已成为当前工业界和学术界的迫切要求。
情感分析又称为意见挖掘、主观因素挖掘等,是通过计算机分析并整理互联网上大量的评论信息,对带有情感因素的主观性文本进行分析、处理的过程[1]。情感分析的主要工作是将文本所含有的情感因素(如积极、消极、中立等)进行分类。目前,国内外学者提出基于传统的机器学习方法,在语法层面上进行语义分析。周枫等[2]提出了一种双向GRU与CNN相结合的文本分类模型,通过增大重要信息的权重,提高分类精度。现在流行的深度学习采用浅层神经网络的方法也可以进行情感分类。一些研究学者在文本的词向量表达上进行了改进,得到了更好的分类效果。Biswas等[3]利用特有领域的信息训练词向量,使情感分类模型有了更好的提升。Cotterell等[4]提出了一种新的形态学词向量,在词相似方面得到了很大的提升效果。Abdeddaïm等[5]提出了一种新的MeSH-gram模型,通过句向量捕捉语义联系,性能高于传统skip-gram模型。Yao等[6]提出了一种新方法LSI,通过将外部知识转化为语义空间以增强词向量表达方式。文献[7-8]通过结合主题模型来训练词向量进行文本分类。文献[9-11]均使用深层次模型训练词向量,并应用在词表征任务上。
综上所述,现阶段的情感分类问题在于无法更好地抓取情感因素。词向量表示方法能够更好地对文本特征进行描述,在分类时的效果更好。本文提出GE-BiLSTM情感分析模型。通过预训练语言模型构建文本的特征词向量,然后将文本的特征词向量作为BiLSTM神经网络的输入,通过训练神经网络获取深度词向量特征,最后使用softmax层对文本进行情感分类。
1 相关介绍
1.1 Glove模型
Glove(Global Vectors for Word Representation)模型由斯坦福大学的Pennington等[12]提出,Glove模型是基于共现矩阵分解生成词向量的模型。假设共现矩阵为X,Xi表示词i,Xij表示词j在目标词i的上下文中出现的次数。模型在训练时用到了全局信息,利用了词共现的信息状态,使用上下文信息建模,如果两个词在语料库中出现的上下文位置类似,这两个词的词向量就相似,对词语具有更好的描述。Glove模型的损失函数为:
(1)
式中:|V|是词典的大小;Wi为词i的词向量;Wj为词j的词向量;bi和bj分别为矩阵X行、列的偏移值。J的计算复杂度和共现矩阵矩阵X的非零元素的数目呈线性关系。设共现矩阵X中,Xij代表词j在词i上下文出现的次数。词i和词j的上下文是k时,k与i、j存在共现关系。
(2)
式中:P(k|i)为单词i、k共现概率。
(3)
式中:P(k|j)为单词j、k共现概率。
(4)
如果F(wi,wj,wk)的值较大,说明k和i的相关性强;反之,则说明k与j相关性比较大。Glove模型的不足是上下文单词之间的联系不强,同一个词出现在不同场景的文本中,词汇的向量表征矩阵变化不大。
1.2 LSTM网络结构
LSTM网络结构是基于循环神经网络(RNN)改进而来的。循环神经网络最早由Schuster等[14]提出,该网络结构更适合对序列化数据进行处理和预测,在处理文本信息时,可以使之前的信息对后面的输入信息产生影响,输入信息为{x1,x2,…,xt},xi的输入都会经过激活函数转化为输出值oi和上一个状态的记忆值hi,所以当前时刻t的输入除了来自当前输入层的xt,还有上一个状态的ht。LSTM具体单元结构公式如下:
zt=tanh(Wz[ht-1,xt]+bz)
(5)
it=σ(Wi[ht-1,xt]+bi)
(6)
ft=σ(Wf[ht-1,xt]+bf)
(7)
ot=σ[Wo(ht-1,xt)+bo]
(8)
ct=ft·ct-1+it·zt
(9)
ht=ot·tanhct
(10)
式中:z为输入值;i为输入门;f为遗忘门;o为输出门;ct为结合遗忘门选择的信息后输出的新状态;ht为结合ct、输入和上一个状态所生成的进入下一层隐藏层的状态;σ为sigmoid激活函数;b是训练时的偏置项。“门”机制可以更好地筛选有用的信息,虽然在训练时会产生更多的参数,但在数据量不大的数据集上具有更好的效果,所以本文选择了LSTM作为提取情感因素的网络结构。
2 GE-BiLSTM情感分析模型
本文提出一种GE-BiLSTM情感分析模型,引入了预训练语言模型,针对于当前传统情感分类模型无法更好地抓取情感因素导致文本向量矩阵稀疏的问题进行了改进及处理。通过训练语言模型,以BiLSTM作为语言模型训练的网络结构在训练结束后可以得到输入文本中每个词汇的m层向量矩阵,由于两个模型的训练机制不同,最终生成向量矩阵需进行运算重组,运算函数如下:
(11)
式中:e′为新的ELMO模型词向量;e为原始词向量;n为词向量维度;h为每个词汇的词向量层数。将预训练语言模型ELMO训练结果与Glove词向量通过运算融合为新的词向量矩阵。最终放入BiLSTM模型训练,进行情感分析。
2.1 预训练语言模型
本文引用了Peters等[13]提出的ELMO模型(Embeddings from Language Models),以语言模型为目标在双向LSTM上训练模型,利用LSTM网络结构生成词语的表征。Word2Vec等传统模型生成词向量时,不同句子中的相同词汇的词向量是一样的;而本文预训练双向语言模型的输入度量是字符而不是词汇,从而可以增强单词的联系,以语言模型为目的,更好地预测下一个单词的出现概率。该语言模型的前后网络结构如下。
前向LSTM结构:
(12)
反向LSTM结构:
(13)
联合前向和后向语言模型,并最大化前后向语言模型,得到该语言模型的联合似然函数如下:
(14)
式中:θx为输入的初始词向量参数;θs为输出的softmax层参数。本文利用预训练语言模型的概念,使用双向LSTM训练语言模型,对该模型加以应用,每个词语经过语言模型的预训练后,情感词的权重通过最大条件概率随之增大,更加突出情感关键词的重要性,结合特定数据语境的情感词的条件概率可通过极大似然估计求得:
(15)
通过结合全局信息和局部上下文信息,可以充分弥补传统情感分类模型中,只能通过前后句子判断关键情感词重要性的缺陷,情感词条件概率的增大,可以通过不同场景,产生不同意义的词语表征。情感信息在融合新机制下得到了更好的保留,效果优于传统主题模型。
2.2 词向量的运算重组
本文所选择的传统词向量模型为Glove模型,该模型在Word2Vec模型的基础上加以改进,结合了全局信息,弥补了Word2Vec只能结合局部语义信息的缺点,在词表征任务上具有更好的效果。本文模型首先通过预训练语言模型训练词向量,在得到局部上下文信息后,再结合Glove模型训练得到的全局信息重组运算成新的矩阵。传统词向量模型Glove训练出来的词向量矩阵设为G,文本分词之后每个词的tokens设为g,词向量矩阵维度过大容易造成训练参数增加、时间复杂度提升。经过实验证明,词向量维度在200~300维之间时词向量差别很小;当维度超过300维,会造成维度过长,训练时参数过多,提高时间复杂度。本文Glove模型词向量维度选择为256维,矩阵为文本词向量的集合G。
(16)
通过预训练语言模型训练出来的词向量矩阵设为E,文本分词之后每个词的tokens设为e,维度与Glove模型输出保持一致,矩阵为文本词向量的集合{e1,1,e1,2,…,e229902,256},训练出的每个词的词向量有m层,将ELMO模型每个词的词向量求平均值,转为新的词向量矩阵E′。
(17)
将两个模型训练的词向量通过运算融合,即W=concat(G,E′),运算后的具体矩阵为:
(18)
融合后的词向量维度为512维。
2.3 GE-BiLSTM模型结构
本文提出的GE-BiLSTM模型的关键部分在于通过预先训练语言模型,得到包含上下文信息的词向量,再结合传统的Glove所生成的全局词向量,提高了词语之间的联系,以语言模型为目的训练词向量可以更好地抓取情感因素,双向LSTM网络进一步提取文本特征,以提高分类精度。LSTM网络结构是在RNN(Recurrent Neural Network)基础上改进得到的网络结构,其克服了RNN无法存储更多信息的缺点。但是在训练时,文本中每个词汇的理解不仅依赖于前面所存储的信息,也与后面输入的信息有关。LSTM是单向的网络结构,如果要同时考虑上下文的信息,就需要同时考虑文本句子前后方向的信息。在经过对模型性能和训练复杂性之间进行权衡之后,本文选择双向的LSTM结构作为词向量融合之后训练的网络结构,以此可以充分地理解词汇的上下文信息。GE-BiLSTM情感分析模型的流程如图1所示。

图1 GE-BiLSTM情感分析模型流程
在训练之前,先通过停用词表去除无用词并处理原数据,通过两个模型分别训练出词向量,经过维度调整和矩阵处理后,将预训练语言模型与Glove模型最终训练得到的矩阵运算融合成新的词向量矩阵。融合后分类交叉熵得到的目标函数为:
(19)

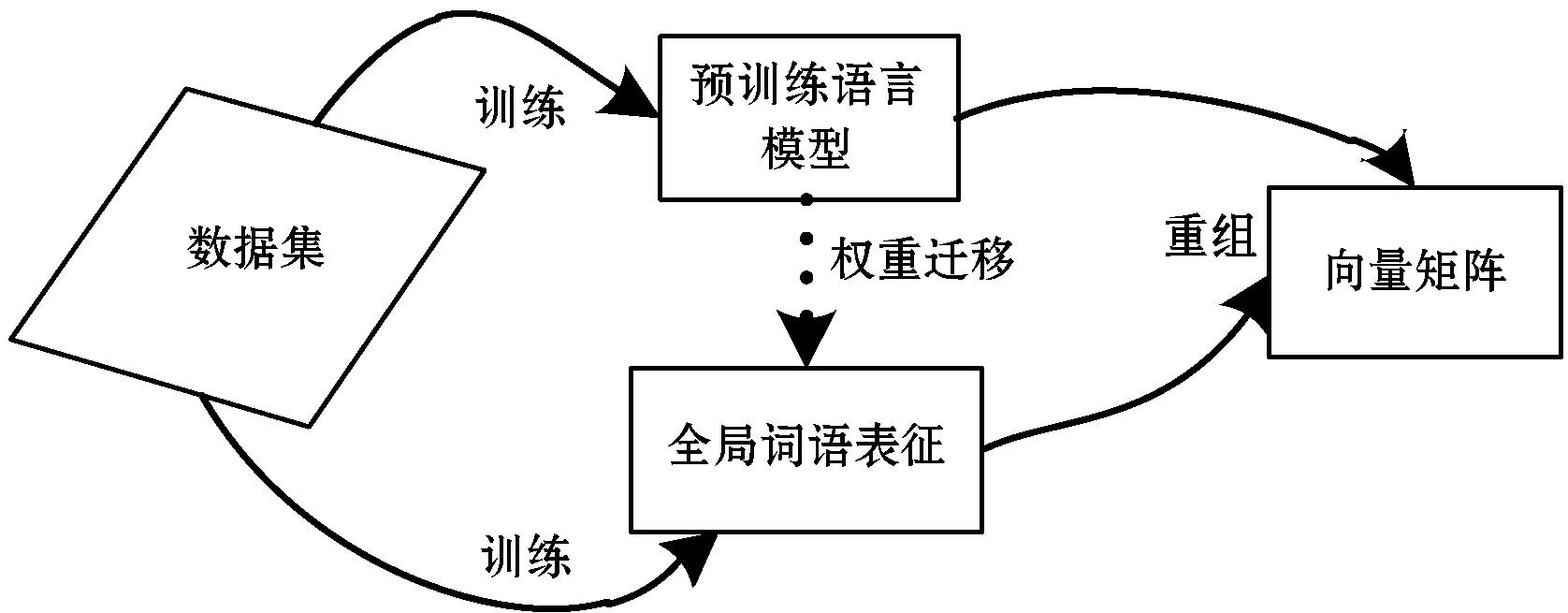
图2 融合细节图
将融合之后的结果作为网络结构的输入放到输入层中,再次通过BiLSTM网络结构进一步抓取情感因素,将输出结果作为softmax层的输入,最终得到分类结果。
2.4 情感分析
最终生成的词向量矩阵通过BiLSTM网络训练,在得到情感特征向量后,利用向量矩阵做分类,softmax函数是归一化的指数函数,其定义如下:
(20)
式中:X是经过网络结构训练后的矩阵;d是输入数据的向量维度,W是输入层的向量矩阵。设softmax函数的输入数据为d维的向量W,最终softmax函数结果也是一个d维的向量,每个维度的值在0到1之间。利用softmax输出两个取值在0到1之间的数值,通过数值判断最终输出的概率,选择输出概率最大的作为文本分类的结果。GE-BiLSTM算法流程如算法1所示。
算法1GE-BiLSTM
1. 通过对数据集处理成句子与标签对应形式
2. 通过式(4)和式(14)得到融合后的情感词向量矩阵
3. foriin [1,N]
4. 使用预训练语言模型与传统词向量模型训练词语表示
5. 使用式(15)的最大条件概率再次定义情感词权重
6. 运算重组训练后的词向量矩阵
7. end
8. 将BiLSTM再次训练之后的向量矩阵,通过式(19)更新权重参数
9. 将最终的词语表征矩阵输入到softmax 分类器中,输出最终的分类结果
3 实 验
本文实验数据集采用了IMDB大型电影评论集。该评论集具有良好的特征情感词,评论集中共有50 000条含有标签的评论,其中积极的文本为25 000条,消极文本为25 000条。在训练时,采用5 ∶1的比例划分训练集与测试集。训练集文本为40 000条,测试集文本为10 000条。通过统计数据集文本,每条文本评论在500词左右,本次实验对训练词汇设定统一长度,最大词汇数设定为500,超过部分进行截断,不足的补0。
3.1 实验数据集
本文所选数据集为IMDB大型电影评论集,该评论语料集中主要为积极评论与消极评论两种,表1所示为数据集中部分积极与消极评论。

表1 实验数据集
3.2 实验参数
本文所提出的GE-BiLSTM模型训练参数如表2所示。该模型训练时使用的激活函数是tanh,可以有效地降低在训练时梯度爆炸的概率。常用的SGD优化函数在优化过程中,容易陷入局部次优解,相比较下Adam优化函数可以直接并入梯度一阶矩估计中,其鲁棒性更强。

表2 实验参数

续表2
3.3 评价标准
本文选取查准率P(precision)、召回率R(recall)和F1值(F1-score)作为情感分析的评价标准。查准率与召回率是一对矛盾量,为了达到一个较为平衡的评价标准,需要用到F1值来衡量。F1公式如下:
(21)
3.4 对比实验
为了验证GE-BiLSTM情感分析模型的有效性,本文将分别与Glove-LSTM、ELMO-LSTM、Glove-BiLSTM、ELMO-BiLSTM模型进行对比实验。
图3为Glove模型与双向LSTM训练后得到的acc/loss图,图4为ELMO预训练语言模型与双向LSTM训练后得到的acc/loss图,图5为本文模型的acc/loss图。可以看出,GE-BiLSTM具有更好效果,训练集在第6轮左右,数据收敛趋于平缓。具体实验结果数据对比如表3所示。

图3 Glove-BiLSTM acc/loss图
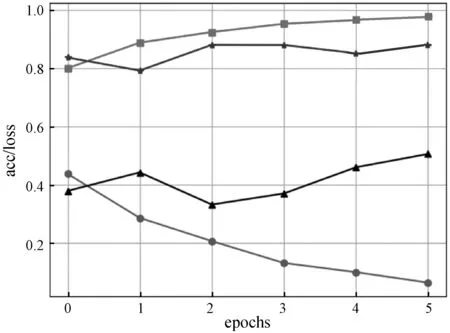
图4 ELMO-BiLSTM acc/loss图

图5 GE-BiLSTM acc/loss图

表3 实验结果对比
本文还与文献[16]方法做比较,通过结合LDA主题模型来捕捉单词之间的语义和情感相似性,分析语义成分,再结合上下文语义结构,通过无监督概率模型学习单词向量,最终将生成语义向量通过SVM(支持向量机)进行情感分类。实验证明,本文提出的GE-BiLSTM情感分析模型具有更好的分类效果,F1值比ELMO-BiLSTM方法提升0.045,比Glove-BiLSTM方法提高0.025。
4 结 语
本文提出了一种基于预训练语言模型ELMO与传统词向量模型融合的GE-BiLSTM情感分析模型。通过模型输出向量矩阵调整后,进行词向量矩阵运算融合,在文本向量化表示部分增加了文本的特征描述及上下文词汇之间的联系,减少了向量矩阵的稀疏度,再通过双向LSTM的训练可以更好地抓取情感因素。实验表明,GE-BiLSTM情感分析模型具有更好的分类效果。下一步将对文本的特征描述做进一步研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
读与写·教育教学版(2017年10期)2017-11-10
科学与财富(2016年15期)2016-11-24
科技视界(2016年18期)2016-11-03
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
