
基于深度学习的机器人目标检测设计
2021-05-12 02:59余佳恩马国军任永恒王亚军
电子设计工程 2021年8期
余佳恩,马国军,任永恒,王亚军
(江苏科技大学电子信息学院,江苏镇江 212003)
室内机器人在移动过程中,需要感知周围环境,以进行目标检测和路径规划。常用的传感器有激光雷达、超声波和红外传感器等,为获得较多的信息,视觉传感器也广泛应用于机器人目标检测。
机器人目标检测方法是将提取的目标图像特征转化为特征向量,利用分类器进行分类[1-2],同时用滑动窗口对目标定位,找到与目标特征最相似的位置。
随着人工智能技术的不断发展,基于深度学习的目标检测算法逐步被应用,并成为研究热点。基于区域建议的算法先对可能存在的目标区域进行大量的建议,构成候选目标,然后进行识别,得到检测结果,如Faster R-CNN 系列检测算法[3-4],但该类算法存在处理数据速度慢,对候选区域进行处理时有大量的重复计算等问题。基于回归学习的检测算法能够一步完成检测过程,如YOLO 在去除区域建议的过程中[5],直接利用卷积神经网络(Convolutional Neural Networks,CNN)对整幅图像进行处理,预测出目标的位置和类别,该方法虽然提高了运算速度,增加了实时性,但其定位的准确性较低[6]。
基于此,文中设计并研究了基于MobileNet-SSD模型的目标检测方法,并且输出机器人到目标障碍物的距离。该方法使用MobileNet 网络作为SSD 的基础网络进行特征提取,将检测到的目标投影到深度图中,同时计算包围盒内的深度平均值作为障碍物到机器人的距离。
文中融合计算机视觉和深度学习的方法,进行机器人障碍物目标全自动检测,并得到距离信息,为机器人避障、路径规划提供基础。
1 MobileNet-SSD目标检测
1.1 MobileNet
目前,为得到较高的准确率,CNN 的深度逐渐增加,复杂度逐渐增强[7]。但是,硬件资源的限制使得巨大且复杂网络模型在嵌入式设备上无法实际应用。针对CNN 存在的问题,Google 于2017 年发布了MobileNet 卷积神经网络模型[8]。
MobileNet 采用深度可分离卷积[9]代替普通卷积,为每个输入通道提供单独的滤波器,使用点卷积结合所有输出的深度卷积,使计算量大大减小,标准卷积分解为可分离卷积的示意如图1 所示。

图1 普通卷积和深度可分离卷积
1.2 SSD目标检测算法
针对R-CNN 系列检测算法处理数据速度慢,YOLO 类算法定位准确率低的问题,文献[10]提出了SDD 算法。与两阶段目标检测算法相比,SSD 采用端到端的方法和金字塔式的多尺度特征层,具有实时性好、结果准确的特点。
SSD 算法以VGG16 为基础网络,通过增加4 个卷积层获得更多的特征图。通过多尺度特征信息和待检测图像的大小信息,生成候选框位置和置信度。在输出层,利用非极大值抑制算法((Non-Maximum Suppression,NMS)去掉无效的候选框,将候选框和标注框进行匹配,从而得到目标的信息,包括位置、类别和置信度[11-13]。
SDD 由基础网络和辅助网络组成。辅助网络在VGG-16 的基础上增加用于目标检测的卷积层,其目标检测步骤如下:
Step1:初始化,载入模型进行网络训练;
Step2:提取部分图像区域,构造候选框;
Step3:计算置信度,置信度值越大,准确性越高;
Step4:输出置信度和物体在图像中的位置。
1.3 MobileNet-SSD目标检测流程
利用RGB 相机获取场景的彩色图像,利用MobileNet-SSD 进行障碍物检测并构建目标包围盒;然后,利用左右两个红外相机获取场景的深度图像,将RGB 彩色图像和深度图像融合配准,得到RGBD图像数据;最后,将目标包围盒投影到深度图中,并输出目标的类别和距离。具体流程如图2 所示。

图2 MobileNet-SSD目标检测流程图
2 RGBD图像配准
图像配准是将多个传感器从不同视角获得的多幅图像,在同一场景下寻找几何上的对应关系。
图像配准可分为基于区域的配准和基于特征的配准两种方法[14]。基于区域的配准方法[15]由事先定义好尺寸的窗口来进行相关性估计。比较典型的算法有相关算法、傅里叶算法和互信息算法。
基于特征的配准方法[16]是对不同图像中提取的特征,如点、线特征进行关联,因而对图像的旋转、平移和尺度变换等具有不变性。
在深度图像配准中,由3D 相机获得的图像包括深度图像和彩色图像。由于深度相机和彩色相机的位置不同,因而需要通过配准,将深度图像坐标系转换到彩色图像坐标系下,使得深度图像和彩色图像融合,得到配准深度图像。
设3D 相机的左侧相机为深度相机,右侧相机为彩色相机,深度图像配准到彩色图像的过程由式(1)描述:
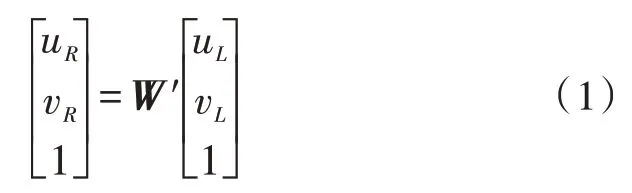
其中,W′为变换矩阵,(uL,vL,zL)T为深度图像的像素坐标,(uR,vR,zR)T为彩色图像的像素坐标。
变换矩阵W′的构造过程如下:
1)构造深度相机坐标系到图像坐标系的变换,由摄像机标定原理可知,相机坐标到图像坐标的变换为:
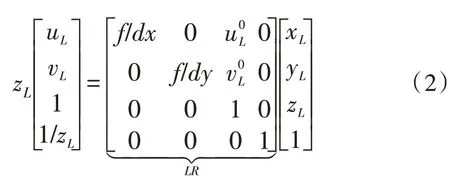
于是,图像坐标系到相机坐标系的变换为:

其中,LR为双目相机标定的左侧相机内参矩阵。
2)同理,构造右侧相机坐标系到图像坐标系的变换:
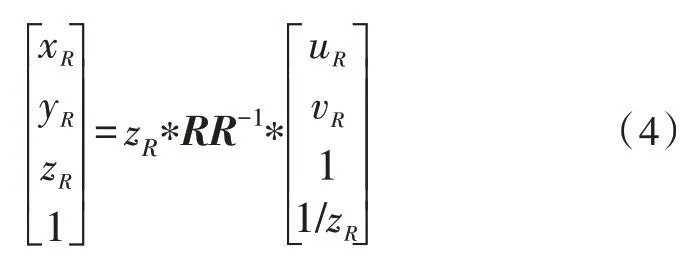
其中,RR为双目相机标定的右侧相机内参矩阵。
3)左侧相机坐标系到右侧相机坐标系变换为:
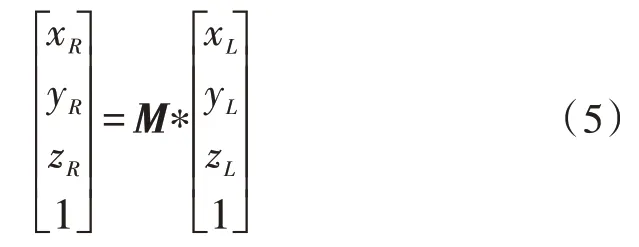
其中,M为两个相机光心的外参矩阵。
4)左侧图像坐标转换到右侧图像坐标系,并左乘RR矩阵得到:
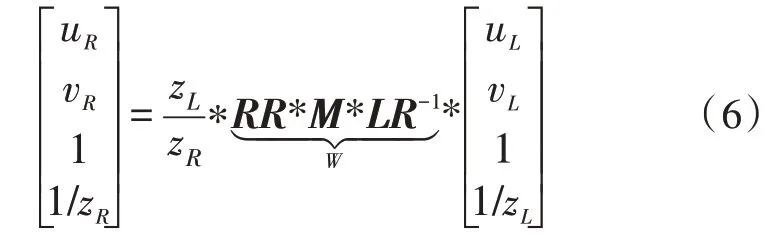
此时,根据深度图像和彩色图像中像素的坐标,可以得到配准深度图像中的像素坐标。
3 实验结果与讨论
研究中的软硬件实验平台为PC 端,操作系统为Ubuntu16.04,计算机配置为Intel 酷睿4 核CPU,内存为8 GB,框架使用TensorFlow 深度学习框架,使用的视觉相机是Intel RealSense D435i。
Intel RealSense D435i 可用于室内外的视觉检测与导航,最大测距为10 m,与光照、场景、校正有关。图像传感器采用全局快门,每个像素大小为3 μm ×3 μm,深度相机最小测距为0.105 m,视场深度为(87°±3°)×(58°±1°)×(95°±3°),深度输出分辨率最大为1 280×720,帧率为90 f/s,RGB 相机最大分辨率为1 920×1 080,RGB帧率为30 f/s,RGB传感器视场FOV(H×12 V×D)为69.4°×42.5°×77°(±3°),长宽高为90 mm×25 mm×25 mm,所用接口为USB 接口,采用Vision Processor Board 及Intel Real Sense Vision Processor D4。文中实验示意图如图3 所示。

图3 实验示意图
红外光发射器将红外结构光投射到场景中,红外接收部分主要有左右两个红外相机,用于接收被物体反射的红外光,并采集场景内物体的空间信息;RGB 相机用于获取彩色图像。
实验中,在D435i 前方放置目标,获取彩色图像和深度图像,并配准对齐,融合到一幅图像中,利用MobileNet-SSD 模型定位场景中的目标,构建包围盒,通过深度图像计算机器人到目标之间的距离。实验中测到的距离为105.1 cm,实验结果如图4 所示。
4 结束语

图4 实验结果图
对于机器人移动过程中的障碍物检测,为了判断目标障碍物的类别与距离,研究融合深度学习和视觉感知的障碍物检测技术,利用Intel RealSense D435i 深度相机获取场景信息,基于深度学习MobileNet 和SSD 网络提取场景中的目标并输出目标类别和距离,为机器人障碍物检测提供新的方法。
猜你喜欢
动漫界·幼教365(中班)(2020年3期)2020-04-20
铁道通信信号(2020年9期)2020-02-06
电子制作(2019年16期)2019-09-27
中学生数理化·七年级数学人教版(2018年4期)2018-06-28
数学大世界(2018年1期)2018-04-12
中等数学(2017年2期)2017-06-01
自动化学报(2017年5期)2017-05-14
东北电力大学学报(2015年1期)2015-11-13
中国海洋大学学报(自然科学版)(2014年8期)2014-02-28
电子设计工程(2014年18期)2014-02-27
