
基于随机森林的电网调度多源故障信息数据融合系统设计
2021-05-12 02:59马建伟李颖杰陈根军
电子设计工程 2021年8期
马建伟,覃 海,李颖杰,陈根军
(1.贵州电网有限责任公司电力调度控制中心,贵州贵阳 550002;2.南京南瑞继保电气有限公司,江苏南京 210000)
随机森林是包含多个决策树结构的分类器组织,其输出类别由个别树级输出节点的所属众数属性直接决定。在构建决策树训练集的过程中,需要不断将原始数据集合分裂成多个子数据结构体,且所有被选中特征都必须按照既定次序进行排列,这些待选数据特征也叫备选信息集合[1-2]。
在电网应用环境中,多源数据间极易产生明显的无故调度覆盖行为,从而导致故障信息参量的无误融合能力迅速下降。为避免上述情况的发生,文献[3]基于门控循环单元网络与模型融合,按需求灵活划分不同规模的负荷聚合体,实现对负荷群体的预测。文献[4]研究计数电力网络中的数据传输总量,再根据相似度模型,确定与数据参量融合相关的度量匹配条件。但以上研究过程中综合处置能力有限,很难实现对RTI、RBI 调度参量的同步提升。为此,文中在随机森林结构器的支持下,设计新型电网调度多源故障信息的数据融合系统,并通过对比实验的方式,突出说明该系统的实际应用价值。
1 信息数据融合系统硬件设计
电网调度多源故障信息数据融合系统的硬件执行环境由电网调度架构、信息管理模块、多源故障分析模块3 部分组成。
1.1 电网调度架构
基于随机森林的电网调度架构保持三级化连接形式,位于最上端的电网调度界面可直接控制下级融合代理程序,并可在标准融合网络的作用下,形成完整的数据传输回路。在电网调度界面中,故障信息参量可实现自主化修复及多源性显示,并可借助权限管理、数据管理等多项融合服务,实现各节点之间的信息互感。随机型融合网络与电网管理体系直接相连,位于整个调度架构中部,可同时负载数据通信、数据融合、信息缓冲、协议调度等多项应用处理服务,通常情况下,可按照多源故障信息的控制传输需求,实现对待融合数据参量的定向采集与处理。电网调度架构如图1 所示。
1.2 信息管理模块
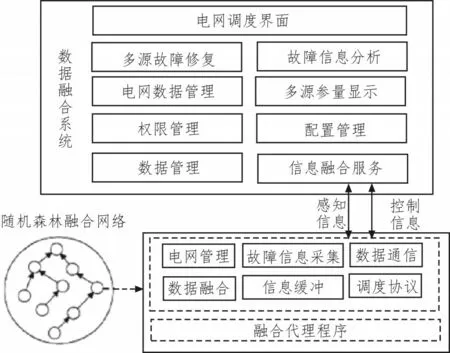
图1 电网调度架构
信息管理模块作为电网调度架构的下级负载结构,以多源型管理中心作为核心执行元件。当电网故障信息录入数据融合系统时,必须执行元件直接开启对信息参量的调度转接处理,并将未存储的数据文件转化为融合待存形式[5-6]。为使系统具备较强的融合处理能力,信息管理模块可同时保持对数据参量的查询与盘点功能,在确保多源故障信息完整传输的情况下,电网环境中的各项调度节点可直接执行已成型的代理应用程序,并可在随机森林决策树组织的作用下,建立与系统数据库间的物理连接,从而实现已存储信息参量的直接调度输出,降低多源电网数据间的无故覆盖占比水平[7-8]。
1.3 多源故障分析模块
多源故障分析模块与系统信息管理模块属于平级硬件结构,可在协调电网信息间输入执行关系的同时,生成必要的信息流结构,并可借助既定处理器结构,实现对电网故障数据的传输与应用。在故障分析主机的作用下,调度处理器可将所有输入信息平均分成多个等分结构体,再融合电力调度网络中的暂存数据参量,形成束状信息流体,以保证后续多源故障数据融合指令的顺利执行[9-10]。为保证已输入信息参量的无误融合,电网环境中的多源故障数据不会在调度网络中停留过长时间,且可随着决策树训练子集的分配,实现对泛化误差系数的精准调节。多源故障分析模块结构如图2 所示。
2 信息数据融合系统软件设计
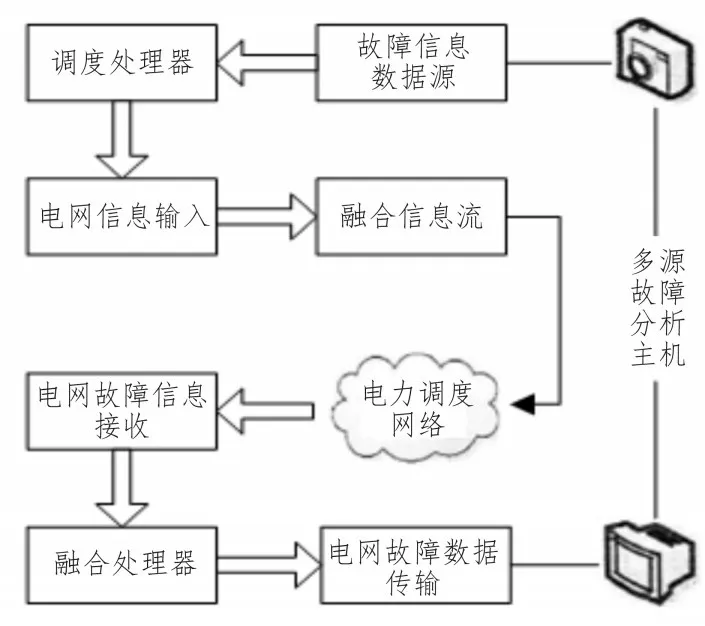
图2 多源故障分析模块结构图
在相关硬件执行结构的支持下,按照基分类器搭建、决策树训练集分配、泛化误差计算的处理流程,实现系统软件执行环境的完善,与硬件设计两相结合,完成基于随机森林的电网调度多源故障信息数据融合系统设计。
2.1 随机森林的基分类器
基于随机森林的融合系统基分类器采取决策树连接形式(如图3 所示),可按照递归分析的方式,实现对电网多源故障数据的传输与简化处理,并最终生成倒立的树状结构,以缩短相邻节点间的融合实施间距。常见的基分类器决策树组织由头节点、中间节点、尾节点共同组成(如图3 中的0、1 和2),为保证多源电网故障信息数据的实时调度融合,0 节点通常代表与管理模块相连的决策树组织结构,1 节点作为中间传输单元,常与多源分析模块相连,在尾节点保持稳定连接的情况下,2 节点可直接反映出电网故障信息数据的最终融合结果,从而提供决策树训练集样本构建所需的多源参量结构[11-12]。
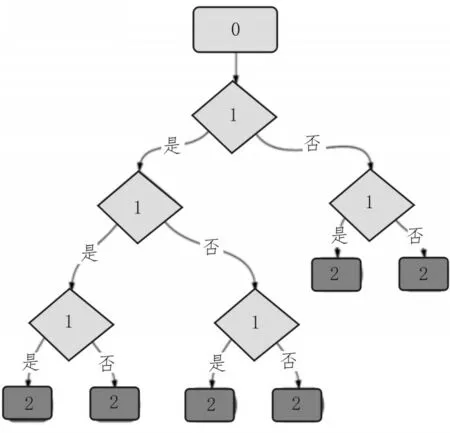
图3 随机森林基分类器结构图
2.2 决策树训练集
决策树训练集是与随机森林相关的多源电网故障信息数据集合,能够完全适应随机调度指令的基本执行需求,并筛选出最符合系统融合标准的信息参量结构[13-14]。若以一个系统融合周期作为信息数据的既定判别时长,则决策树训练集的理论长度标准只受到电网调度权限及多源故障信息表征量的直接影响。电网调度权限常表示为q′,在整个数据融合周期内,始终保持相对稳定的波动变化趋势。多源故障信息表征量常表示为,与其他应用指标不同,该项物理量不受除融合时长外其他信息参量的影响,具备较强的计算稳定性。设代表系统内一个数据融合周期的标准时长,联立上述物理量,可将决策树训练集的理论长度标准定义为:
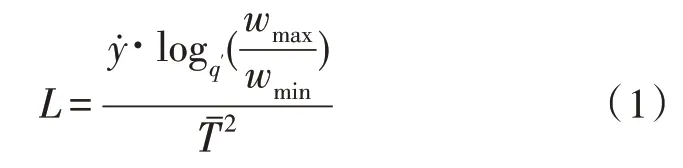
式中,wmax代表与多元电网故障信息相关的最大数据传输参量差,wmin代表多元电网故障信息相关的最小数据传输参量差。
2.3 融合泛化误差计算
泛化误差是指电网调度多源故障信息数据融合系统中与随机森林泛化反应能力相关的应用指标,通常情况下,泛化误差实值越小,则代表系统所具备的学习性能越好,反之则代表性能越差。在决策树训练集分布样本已定的前提下,系统融合泛化误差数值受到决策树节点数量、多源分布系数两项物理量的直接影响[15-16]。决策树节点数量可表示为,在随机森林决策树的作用下,该项物理量始终在上、下极值之间不断波动。多源分布系数可表示为β,通常情况下,该项物理量的实际数值始终小于1,但对最终泛化误差计算结果的物理作用能力始终保持为正向促进。在上述物理量的支持下,联立公式(1),可将系统融合泛化误差计算结果表示为:
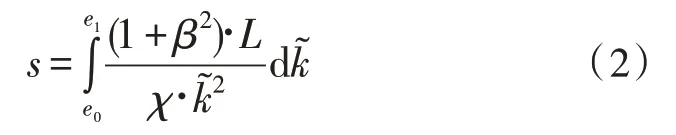
式中,e0代表电网调度信息的下限波动极值,e1代表电网调度信息的上限波动极值,χ 代表多源故障信息数据的边限处置量化系数。至此,完成各项软、硬件执行条件的建立,在随机森林决策树的支持下,实现电网调度多源故障信息数据融合系统的顺利应用。
3 系统实用检测
为验证基于随机森林电网调度多源故障信息数据融合系统的实际应用价值,设计如下对比实验。选取一电网调度设备作为实验监测对象,将各阶段记录所得多源故障数据信息分别输入实验组、对照组融合控制主机中,其中实验组主机搭载新型电网调度多源故障信息数据融合系统,对照组主机搭载无线多媒体融合系统。
为突出实验结果的真实性,实验所用多源故障信息数据均采取人工记录的获取方式,分别输入实验组、对照组监测主机后,待所获指标系数趋于稳定后,开始后续的实验结果分析。
RTI、RBI 调度参量均能反应多源电网数据的无故调度覆盖能力,通常情况下,两项指标的检测实值越大,与之相关的数据无故调度覆盖能力也就越低,实验结果如表1、表2 所示。
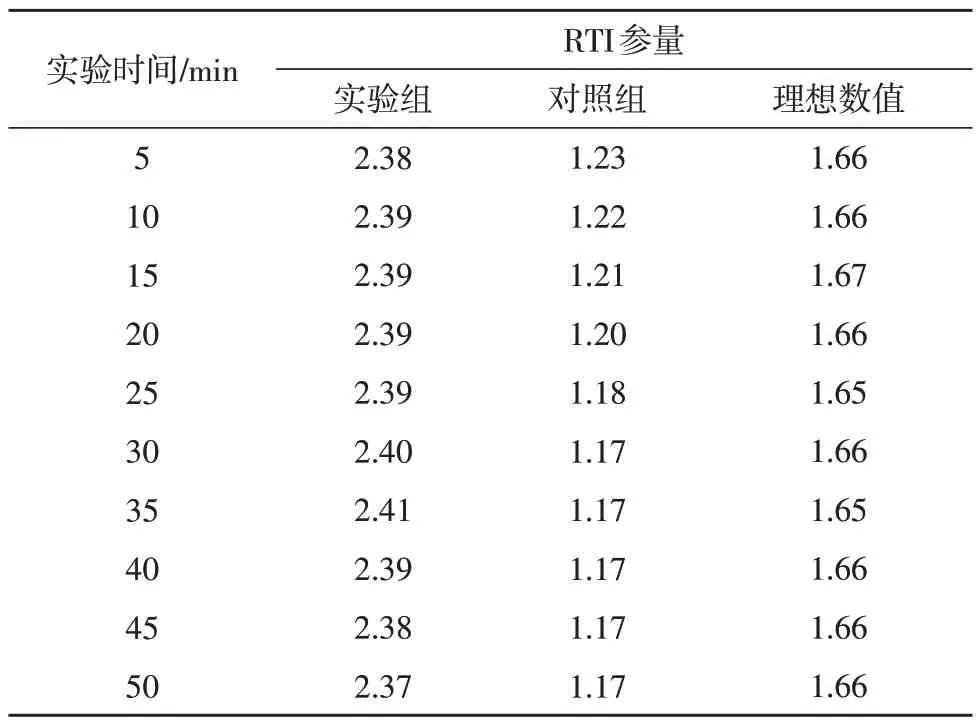
表1 RTI参量对比表
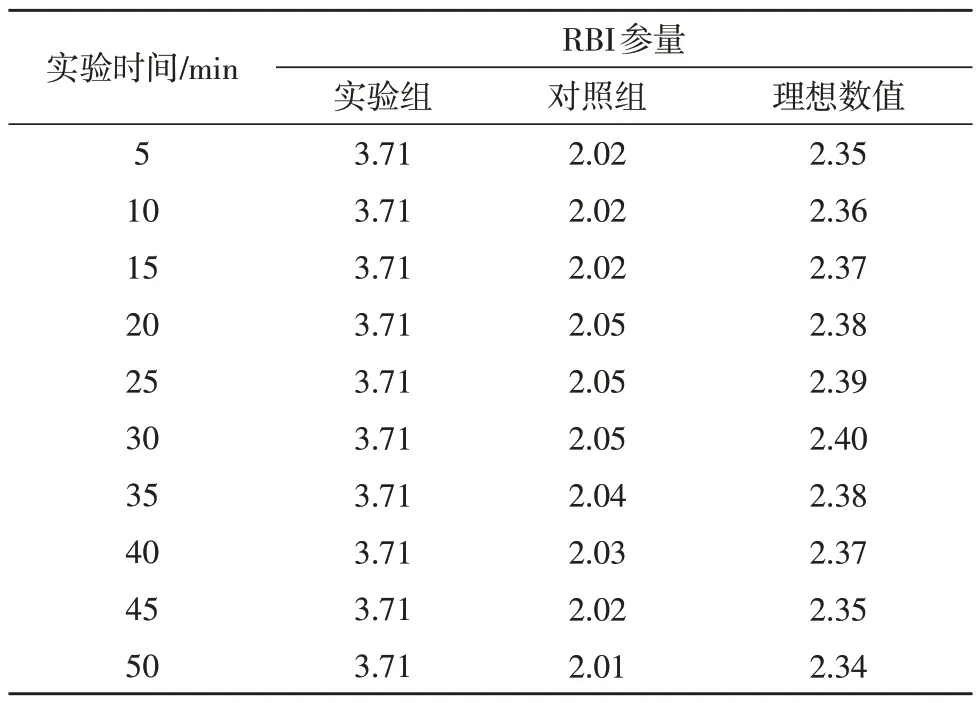
表2 RBI参量对比表
分析表1 可知,在理想状态下,RTI 参量指标基本一直保持稳定,仅在个别时间点处出现小幅度的波动变化状态;实验组RTI 参量指标在检测前期出现小幅度上升的变化趋势,从第40 min 开始,出现连续的下降状态,全局最大值与理想化极值相比,上升了0.74;对照组RTI 参量指标则一直不断下降,在达到极小值水平后,开始趋于稳定,全局最大值与与理想化极值相比,下降了0.44。
分析表2可知,在理想状态下,RBI参量指标先上升、再下降的变化趋势,且后期下降幅度明显高于前期的上升幅度;实验组RBI参量指标在整个实验过程中始终保持不变,该数值与理想化极值相比,上升了1.31;对照组RBI 参量指标先阶梯状上升、再持续下降,全局最大值与理想化极值相比,下降了0.35。
综上可知,随着基于随机森林电网调度多源故障信息数据融合系统的应用,RTI、RBI 调度参量均出现大幅上升的变化趋势,不仅远高于理想化数值水平,更是远超无线多媒体融合系统的标准化数值参量状态。
4 结束语
与无线多媒体融合系统相比,新型电网调度多源故障信息数据融合系统对原有电网调度架构进行初步完善,并联合信息管理模块与多源故障分析模块,实现对决策树训练集样本长度的准确度量。在随机森林基分类器结构的作用下,系统融合泛化误差的实际数值水平不断下降,从根本上解决了RTI、RBI 参量始终不达标的问题,不仅避免了多源电网数据的无故调度覆盖,也从根本上实现了对故障信息参量的无误融合。
猜你喜欢
铁道通信信号(2020年10期)2020-02-07
北京航空航天大学学报(2019年9期)2019-10-26
成都信息工程大学学报(2019年3期)2019-09-25
成都信息工程大学学报(2019年3期)2019-09-25
三门峡职业技术学院学报(2019年1期)2019-06-27
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
物理实验(2015年9期)2015-02-28
郑州大学学报(医学版)(2015年1期)2015-02-27
数学年刊A辑(中文版)(2014年4期)2014-10-30
