
基于联邦学习的网络异常检测
2021-05-12 01:08王丽宝陈骏君
北京化工大学学报(自然科学版) 2021年2期
赵 英 王丽宝 陈骏君 滕 建
(北京化工大学 信息科学与技术学院, 北京 100029)
引 言
随着网络信息技术的迅猛发展,互联网已成为人们日常工作和生活中必不可少的一部分,为人们带来了极大的便利,但同时也时刻威胁着人们的财产与信息安全,因此,进行网络信息安全研究具有重要意义。目前,作为网络安全研究的一个重要方向,网络入侵检测方法[1]已经成为网络安全技术领域研究的热点。
近年来,各种机器学习技术被应用于网络异常检测领域[2-4],但由于传统机器学习需要人工选择特征,存在特征选择困难的问题,需要进行多次测试才能获取分类效果最佳的数据特征组合。深度学习技术是目前解决这一问题的最有效的一种途径。该技术能够自动学习原始数据中的特征,不需要进行人工选择,在自然语言处理、图像识别以及语音识别等领域都显示出较为优秀的识别分类性能[5]。因此,这一技术被越来越多的研究者应用到网络异常检测模型中,并获得了较好的效果[6-8]。
目前,缺乏标记数据是网络异常检测面临的重大挑战之一。如何利用不同数据源的网络流量数据来共同训练网络异常流量检测模型并保护数据隐私是一个亟待解决的问题。联邦学习(federated learning)[9]是解决多源数据共同训练模型的一种有效途径,这一概念是由Bernd等[10]最先提出的。联邦学习的宗旨是在不共享隐私数据的情况下进行协同训练,其不用汇聚模型训练所需要的数据进行集中计算,只是传递加密的梯度相关数据,利用多源数据协同训练同一模型[11]。鉴于传统网络异常检测模型存在的检测准确率低、误报率高以及缺乏标签数据等问题,本文提出一种融合联邦学习和卷积神经网络的网络入侵检测分类模型(CNN-FL)来检测网络异常。该模型能够利用多源数据协同训练同一模型,解决数据孤岛以及标签数据缺乏的问题;并在NSL-KDD数据集上进行实验验证,结果表明,本文模型在二分类以及多分类实验中具有较高的分类精度,较传统的机器学习方法具有更好的分类性能。
1 联邦学习与卷积神经网络模型
1.1 联邦学习
联邦学习作为一项人工智能技术,其设计目的主要是在保障数据交换的同时确保信息安全,保护个人数据隐私。联邦学习解决了多计算节点在不交换原始数据的情况下,共同训练全局模型的问题。
在联邦学习中,全局模型通过分布式的方式在大量参与者中进行训练。为了避免服务器访问本地数据,参与者只在本地训练模型,并且只与服务器共享模型参数来更新全局模型,这一技术对于许多分布式学习场景来说具有很大的优势。典型的联邦学习体系结构如图1所示。假设在联邦学习中有K个具有相同目标的参与者联合训练一个模型,在每一次迭代时,服务器将全局模型M分发给参与者,参与者通过本地数据单独训练模型。在本地训练完成后,每个参与者将模型参数发送回服务器,服务器通过平均各参与者的模型参数来更新全局模型。全局模型的更新过程如式(1)所示。
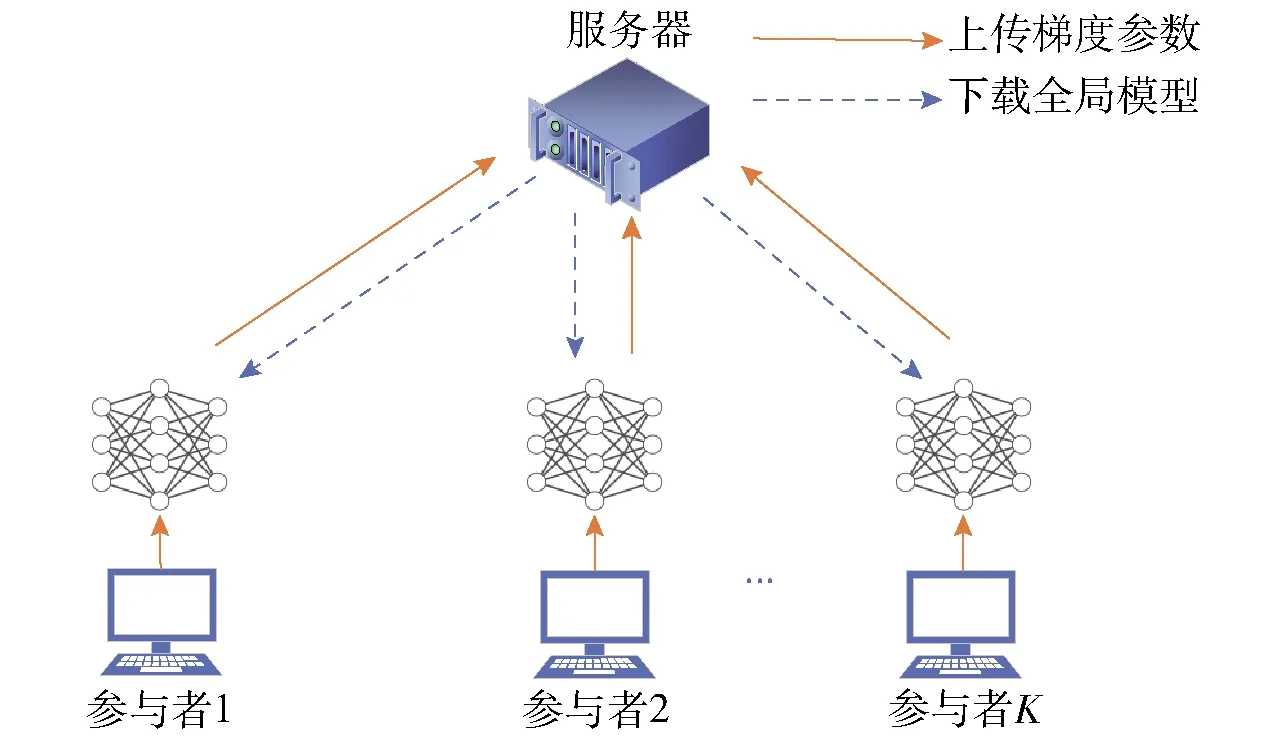
图1 联邦学习体系结构Fig.1 Federated learning architecture
(1)
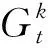
1.2 卷积神经网络
卷积神经网络(CNN)的概念最先是由LeCun等[12]提出的,LeCun首次将反向传播技术应用于神经网络,并将其命名为卷积神经网络。但由于当时计算能力有限,无法满足反向传播技术所需要的巨大计算量,导致对卷积神经网络的研究一直停滞不前。随着半导体技术的飞速发展,计算能力不断提高,基于卷积神经网络的图像识别算法在各类竞赛中均取得了较好的识别效果,由此卷积神经网络技术逐渐被人们所熟知。近年来,越来越多的研究者将卷积神经网络技术应用于图像和语音识别领域,并取得了显著的研究成果[13-14]。同时,这一技术也被越来越多的公司应用到最新的研发产品中,包括Google的Google Net以及人工智能领域极为热门的Alpha Go。
图2为CNN的网络结构图。CNN模型通过卷积和池化操作对相邻像素点进行处理,为了增强图片信息的连续性,CNN模型只处理图片中每一块的小像素集,不再单独对每一个像素点进行处理。在图像识别中,CNN模型能够去除图片中大量无关的参数,保留图片中较为关键的数据特征,以获取较好的识别效果。CNN方法处理过程如式(2)所示,首先将输入的初始图像与线性滤波器进行卷积运算,然后加上偏置项,最后再经过激活函数来获取特征图。
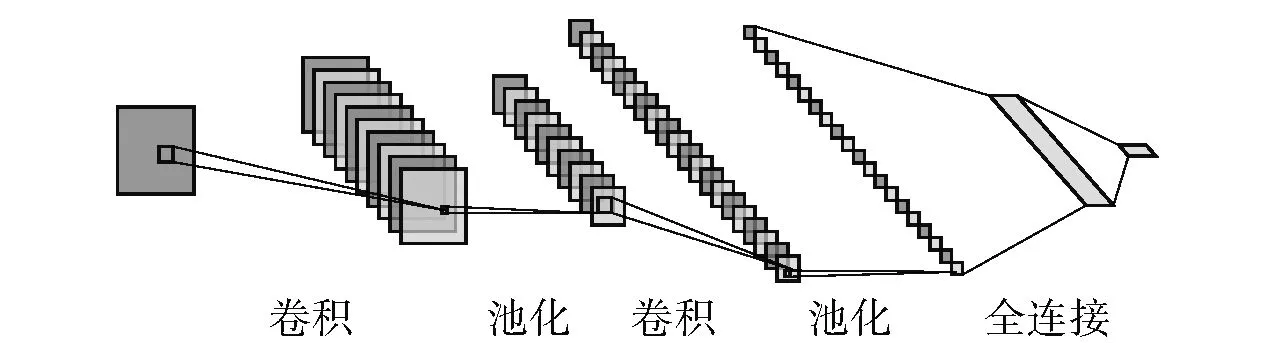
图2 卷积神经网络结构Fig.2 Convolutional neural network structure
(2)
式中,hk为给定层上第k个特征映射,Wk为滤波权重,x为给定灰度图中相应区域的像素值矩阵,bk为偏置,tanh为激活函数。
1.3 基于CNN的网络异常检测方法
在网络异常检测领域,CNN模型在获取局部特征以及处理具有统计平稳性和局部关联性的数据方面较其他机器学习方法具有更加优良的特性[15]。 CNN模型通常是由输入层、卷积层、池化层、全连接层以及输出层这5部分组成。基于CNN的网络异常检测模型原理图如图3所示。
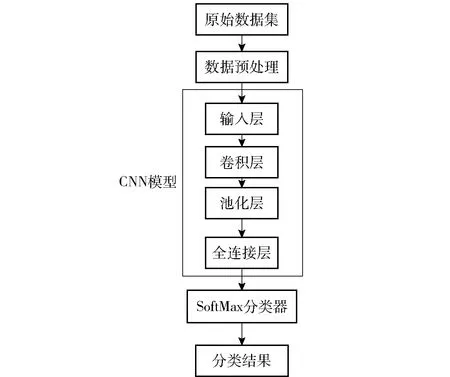
图3 基于 CNN 的网络异常检测模型原理图Fig.3 Block diagram of the CNN-based network intrusion detection system
2 基于CNN-FL的网络异常检测方法
为了优化网络异常检测模型,提高网络异常检测模型的准确率,降低误报率,同时为了解决缺乏标签的训练数据的问题,本文提出一种融合联邦学习和卷积神经网络的网络入侵检测模型。使用联邦学习来解决数据稀缺问题并保护用户数据隐私,使多位参与者在不共享隐私数据的情况下协作训练一个全局模型。对于每一位参与者,首先需要对本地数据进行预处理,然后利用CNN-FL模型进行特征提取。每一位参与者与服务器只传递加密的梯度相关数据,最后通过SoftMax分类器获得分类结果。该算法的原理图见图4。
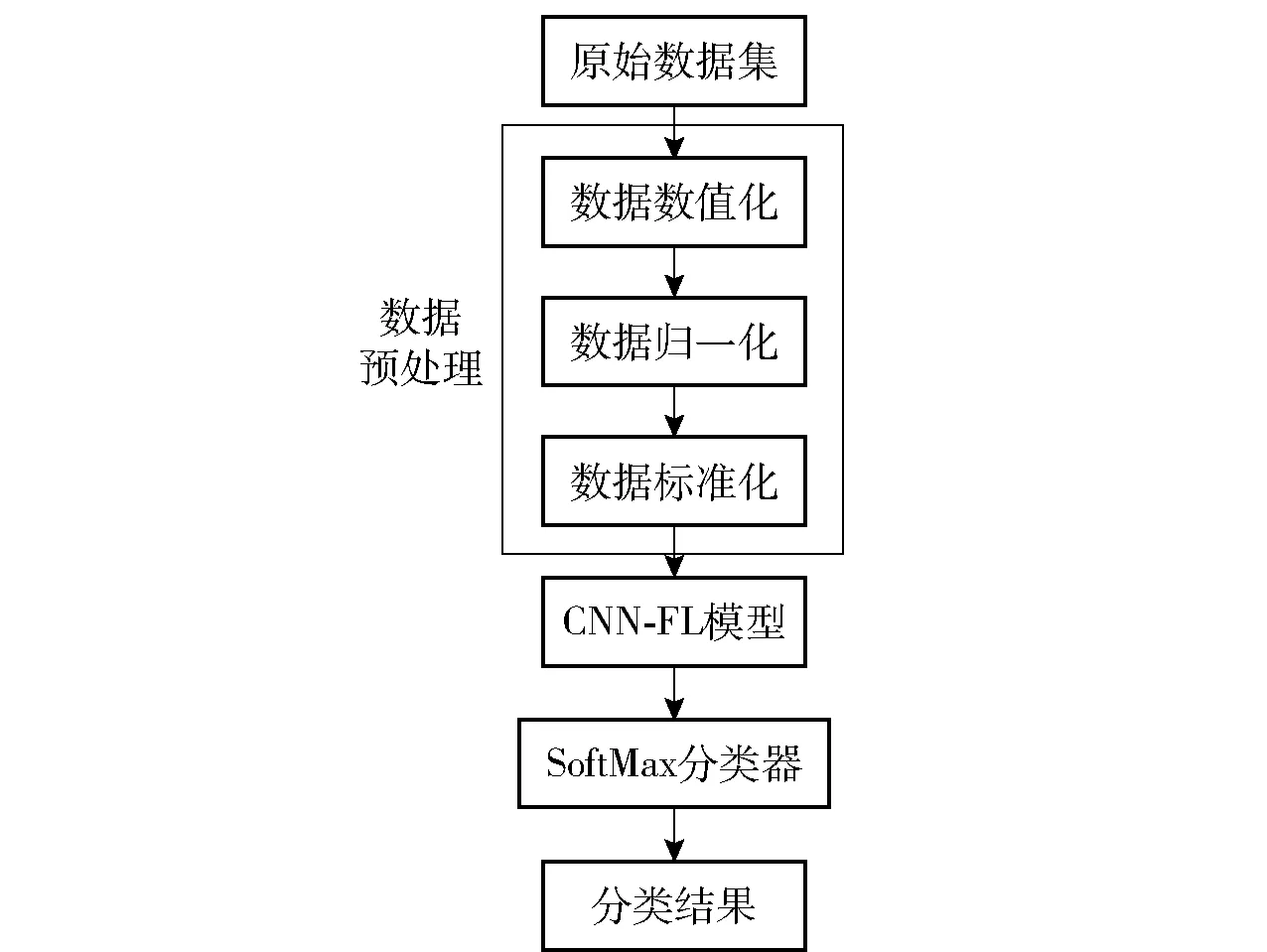
图4 基于CNN-FL的网络入侵检测原理框图Fig.4 Block diagram of the CNN-FL-based network intrusion detection principle
如图4所示,每一位模型参与者首先对本地原始数据集进行数值化操作,通过one-hot编码方式将字符型特征转换为数值型特征,然后采用min-max方法对数据集以列为单位进行标准化处理,使数据统一映射到[0,1]区间上,之后将处理后的特征映射至矩阵中并生成灰度图,最后通过CNN-FL模型对特征进行提取,并通过SoftMax分类器获取分类结果。
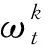
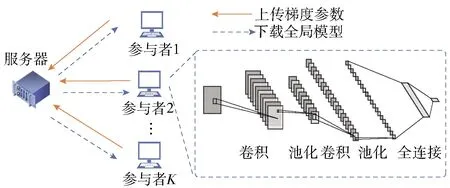
图5 CNN-FL模型结构Fig.5 CNN-FL model structure
算法1CNN-FL模型训练
1 for Iteration t do
/*服务器端: */
3 sendωtto each participant;
/*参与者 */
4 for Participantkdo
6 for Local epoch e do
8 end
9 end
10 end
如图5和算法1所示,每位模型参与者使用本地数据集训练CNN模型,在每次迭代过程中,每位模型参与者首先将当前的模型梯度相关系数上传至服务器,服务器通过平均每位参与者最新的梯度相关系数来更新全局模型,每一位参与者在下一次迭代中通过下载最新的全局模型参数,并利用本地数据来训练CNN模型。不断循环迭代,直至整体模型达到最优,使得CNN-FL模型对每一位模型参与者本地的数据集都具有较好的检测效果。
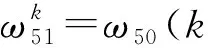
3 实验结果与分析
3.1 数据集与环境
目前在网络检测和网络攻击领域,通常采用KDDcup99数据集作为算法和模型的测试与评价标准。鉴于KDDcup99数据集中存在包含大量重复数据以及未区分训练集与测试集等问题,本文采用NSL-KDD数据集作为实验数据集。NSL-KDD数据集针对KDDcup99数据集中存在的问题进行的一系列优化如下。
1) NSL-KDD数据集针对KDDcup99数据集中需要人为划分训练集和测试集的问题,区分了训练集和测试集。
2) NSL-KDD训练数据集整理并清除了KDDcup99数据集中冗余的部分。
3) NSL-KDD数据集数据量的大小更加合理,训练集中共有125 973条数据,测试集中共有22 544条数据。
4) NSL-KDD数据集较其他数据集更能体现出网络异常检测模型的泛化能力。在NSL-KDD数据集中,训练集中存在的攻击类型有22种,测试集中存在的攻击类型有39种,有17种网络攻击类型在训练集中是不存在的,因此网络异常检测模型在NSL-KDD数据集中识别效果的好坏能更好地体现出模型是否具有较强的泛化能力。
在NSL-KDD数据集中,每一条网络流量数据均由42维特征组成,其中包括38维数值型特征、3维字符型特征以及1维标记特征。NSL-KDD数据集中的攻击类型分为Dos、Probe、R2L和U2R这4种类型。本文实验中训练集及测试集的数据类别、数量与比例如表1、2所示,实验环境配置如表3所示。
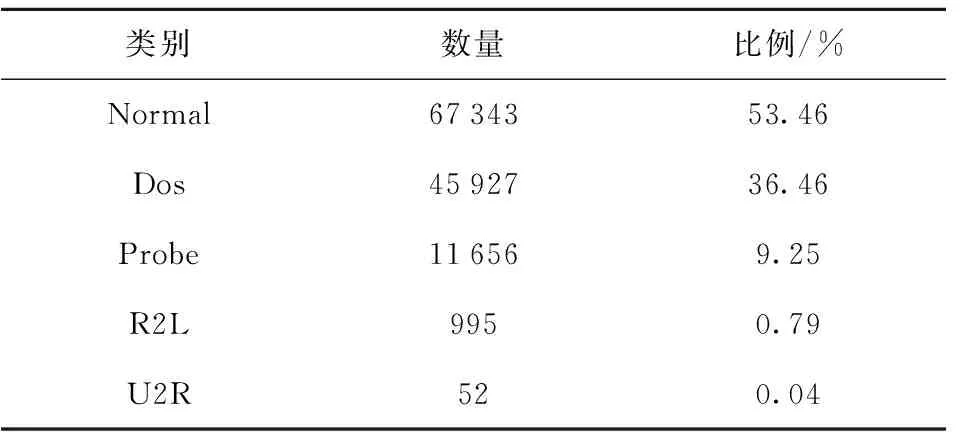
表1 训练集的类别、数量与比例Table 1 Types, quantities and proportions of the training set
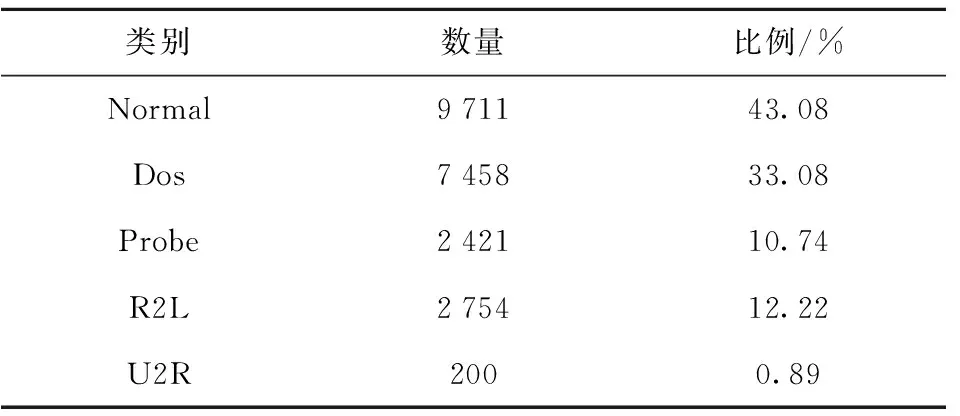
表2 测试集的类别、数量与比例Table 2 Types, quantities and proportions of the test set
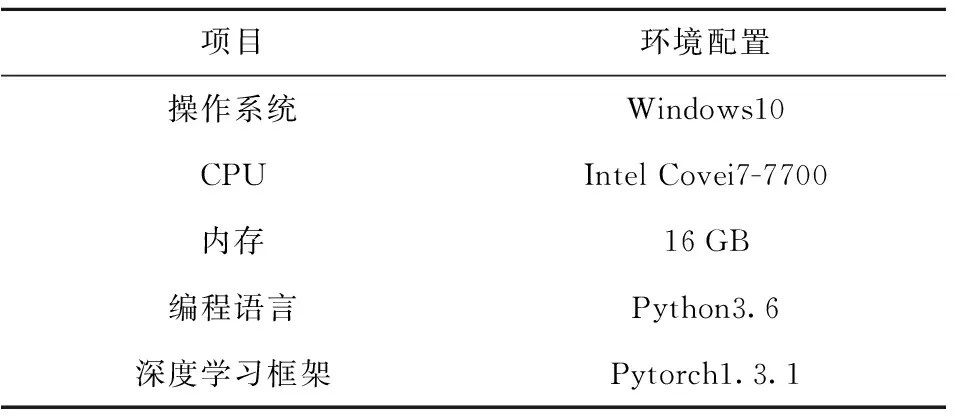
表3 实验环境配置Table 3 Experimental environment configuration
3.2 评价指标
本文通过准确率、精确率和召回率等网络异常检测中常用的指标对实验结果进行评价分析,这些指标可以用真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)4个度量标准来表示。
真阳性(TP):分类结果属于i预测的结果也属于i。
假阳性(FP):分类结果不属于i预测的结果属于i。
真阴性(TN):分类结果属于i预测的结果不属于i。
假阴性(FN):分类结果不属于i预测的结果不属于i。
准确率A、精确率P和召回率R的定义如式(3)~(5)所示。
(3)
(4)
(5)
式中,nTP为属于真阳性情况的数据条数,nTN为属于真阴性情况的数据条数,nFP为属于假阳性情况的数据条数,nFN为属于假阴性情况的数据条数。
3.3 实验方案
为了测试所提出模型,我们模拟了CNN-FL模型训练所需要的环境。实验步骤如下。
1) 数据扩充 NSL-KDD数据集中有125 973条训练数据,为了便于拆分以供K位参与者训练模型使用,补充27条正常流量数据,使训练数据扩展到126 000条。
2)数据数值化 由于NSL-KDD数据集中存在字符型特征,需要对其进行数值化操作。数据集每一条网络流量数据均包含3维字符型特征,分别为“protocol_type”、“service”和“flag”,需要对这3维特征进行one-hot编码,将字符型特征转换为数值型特征,以其中的“flag”为例,其对应的one-hot编码如表4所示。
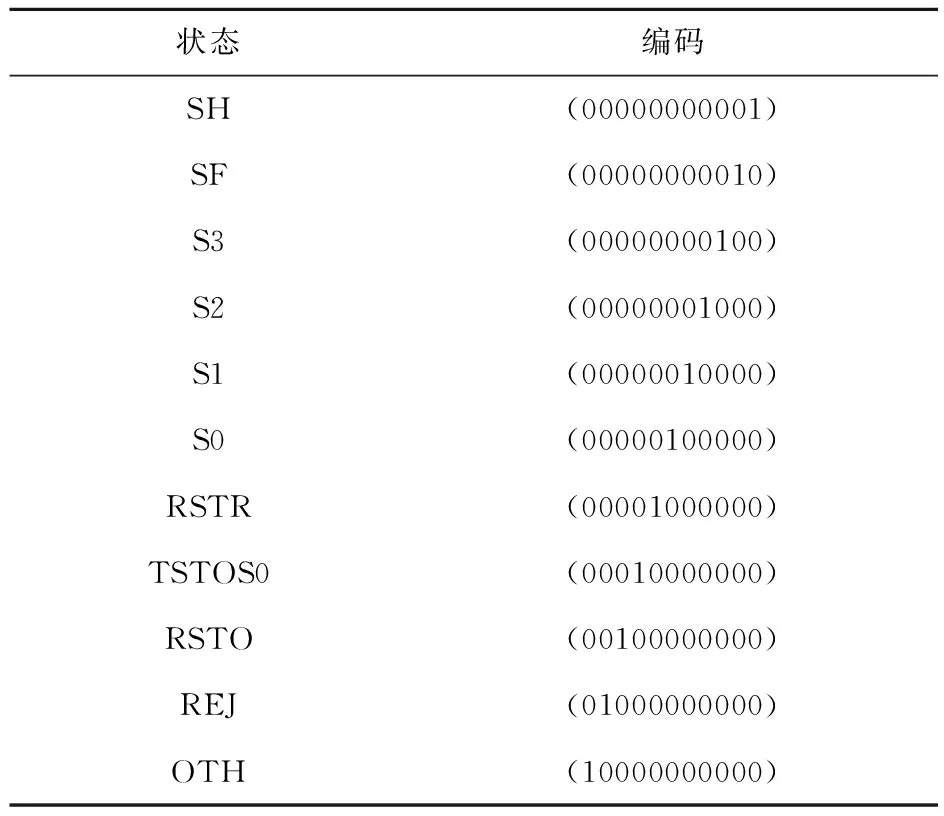
表4 Flag属性one-hot编码Table 4 Flag attribute one-hot encoding
3)数据标准化 由于NSL-KDD数据集中数值差异较大,因此对训练集以及测试集均采min-max方法,以列为单位进行标准化处理,使数据统一映射到[0,1]区间上。
4)生成图片 为了便于后续使用卷积神经网络处理数据,将经过步骤3)处理后的122维特征映射到12×12的矩阵中,不足的部分用0填充。为了生成12×12的灰度图,需要将矩阵中的数值乘以255,从而获得图片中各个点的像素值。图6为生成的部分样本图片。

图6 部分样本图片Fig.6 Some sample pictures
5)数据拆分 将步骤4)中生成的图片随机均匀分成K份,用于K位参与者训练模型使用。
6)模型训练 在实际训练中,参与者与服务器只交换加密的梯度相关系数。
本文将从以下两个方面对CNN-FL模型在网络异常检测中的可行性进行验证。
(1)从整体角度出发 以网络异常检测二分类为例设置了6个不同的场景K{5,10,20,50,100,1 000}来研究不同参与者模型训练的准确率并与基于卷积神经网络的网络异常检测模型(K=1)进行对比,详细结果如图7所示。
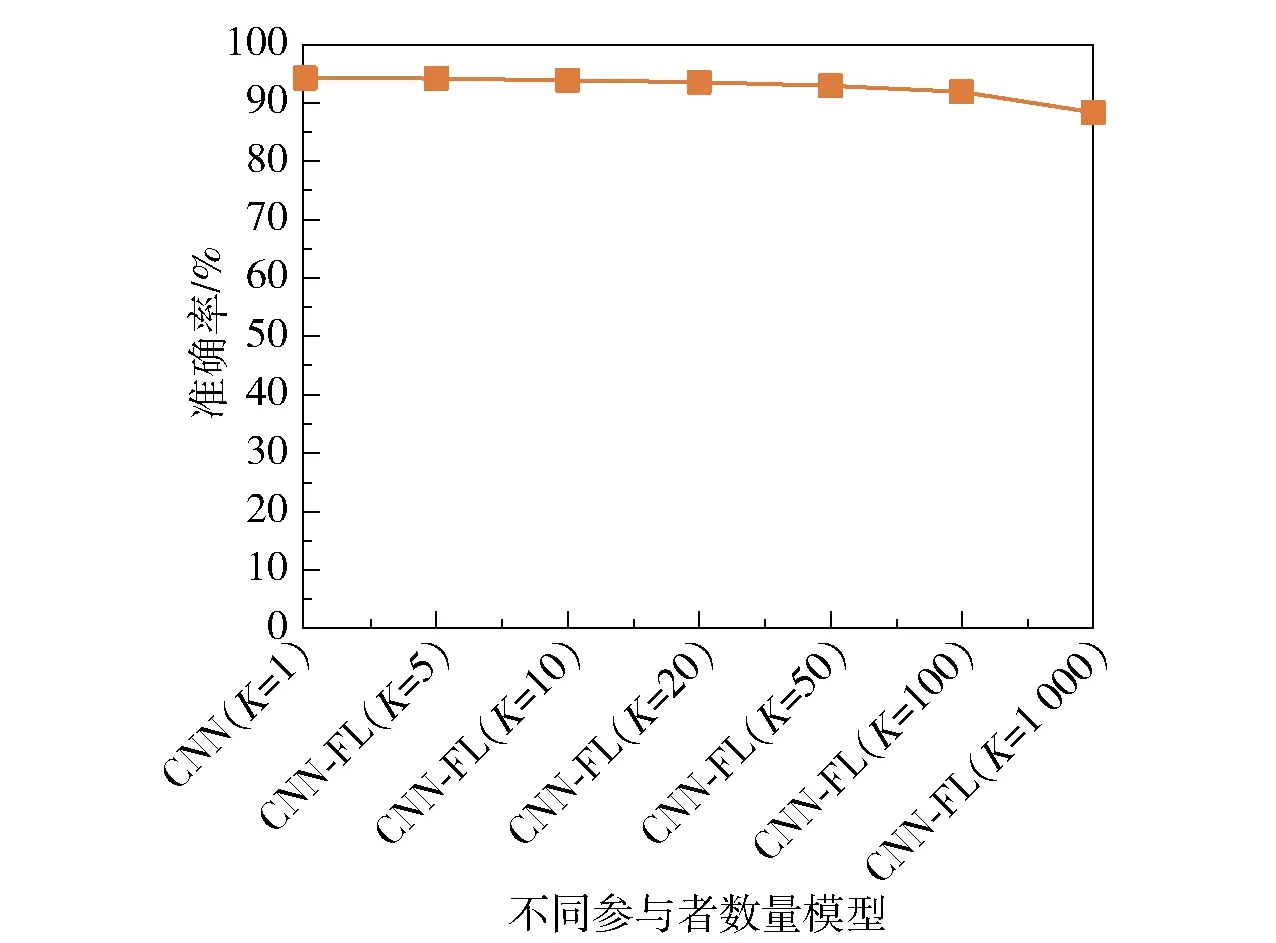
图7 不同参与者模型准确率Fig.7 Model accuracy for different participants
从图7可以明显看出,随着参与者数量的不断增加,CNN-FL模型的准确率逐步下降。与CNN模型相比,CNN-FL模型准确率虽有所下降,但准确率基本相近(迭代100次后,CNN模型的准确率为94.26%,CNN-FL模型(K=100)的准确率为91.88%)。同时CNN-FL模型解决了缺乏标注的训练数据的问题,该模型能够使用多源数据训练同一模型,并保护数据隐私。因此,CNN-FL模型在网络异常检测中是可行的。
(2)从个体角度出发 将数据集中的数据随机均匀分成K份,分别代表每位用户所拥有的数据集。同样设置6个不同的场景K{5,10,20,50,100,1 000},以二分类为例研究在不同数据规模的情况下,每位用户仅使用本地数据训练的CNN网络检测模型的识别准确率,并取均值。随后与相同场景下基于联邦学习的检测模型的识别准确率进行对比,结果如图8所示。
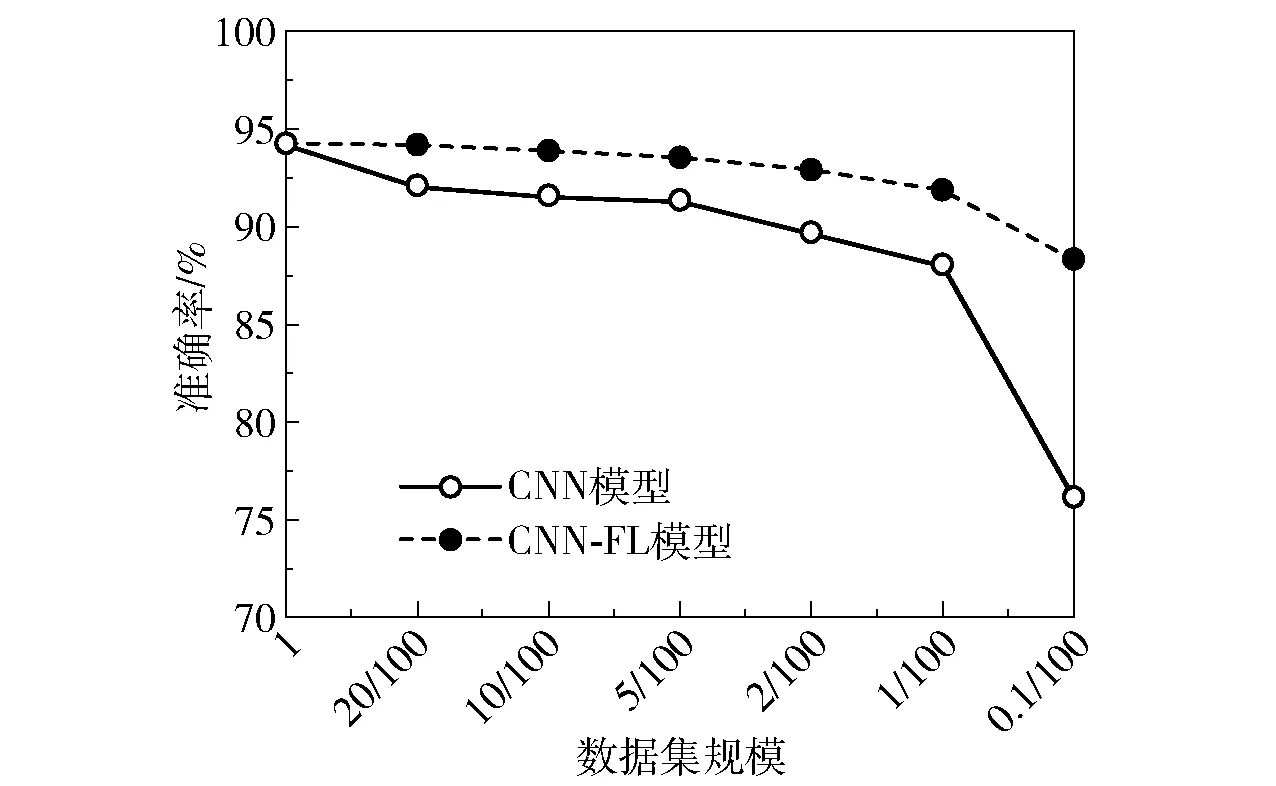
图8 不同数据规模准确率对比Fig.8 Comparison of accuracy of different data scales
K值越大,代表每位用户拥有的数据集规模越小。图8可以明显反映出随着每位用户拥有的数据集规模不断减小,其使用CNN-FL模型以及仅使用本地数据训练的CNN网络的检测模型准确率均不断下降。但在同等数据集规模的情况下,用户使用CNN-FL模型的识别准确率要高于仅使用本地数据训练的CNN网络检测模型的识别准确率。在多分类情况下,由于某些攻击类型的数据较少,每位用户本地数据集中该类型数据较少或不存在该类型数据,如果仅使用本地数据集训练模型,会造成模型识别准确率较低甚至无法训练模型的问题,对比效果将会更加明显。因此,在相同数据规模下,用户通过使用CNN-FL模型能够获得更好的识别效果,充分验证了该模型在入侵检测领域的可行性。
3.4 绩效评估
本文设计了两个实验来研究CNN-FL模型(K=100)的二分类(Normal,Anomaly)和五分类(Normal,Dos, Probe,R2L和U2R)性能。为了与其他机器学习方法进行比较,同时还设计了对比实验,将CNN-FL模型的分类性能与C4.5决策树、随机森林、随机树、支持向量机、循环神经网络等机器学习方法进行了对比。
3.4.1二分类
表5显示了二分类实验中测试集上CNN-FL模型的分类效果。实验表明,经过100次迭代后,CNN-FL模型具有较高的检测准确率,训练集中准确率为97.44%,测试集中准确率为91.88%,如图9所示。

图9 二分类模型在训练集、测试集上的检测准确率Fig.9 Detection accuracy of the binary classification model for the training set and test set

表5 二分类实验中CNN-FL模型的分类效果Table 5 Classification effect of the CNN-FL model in the binary classification experiment
与之前研究人员提出的C4.5决策树、随机森林、随机树、支持向量机、循环神经网络等方法在同一基准数据集(NSL-KDD)上进行比较的结果如图10所示。很明显,在二分类实验中,CNN-FL模型的各项性能均优于其他分类算法。
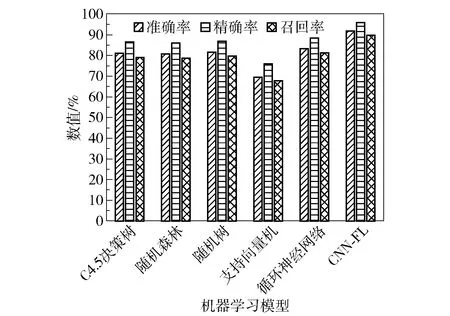
图10 二分类各模型性能对比Fig.10 Performance comparison chart of each model in the binary classification test
3.4.2五分类
在五分类实验中,CNN-FL网络检测模型在训练集上的准确率达到97.47%,在测试集上的准确率达到82.40%。CNN-FL模型在测试集上的效果如表6所示。表7显示了不同攻击类型的检测精确率和召回率。
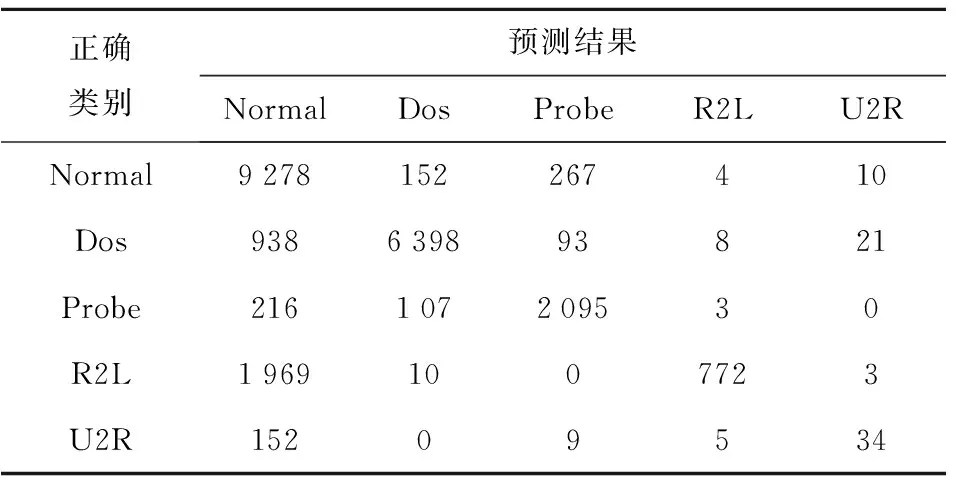
表6 五分类实验中CNN-FL模型的分类效果Table 6 Classification effect of the CNN-FL model in the five-category experiment
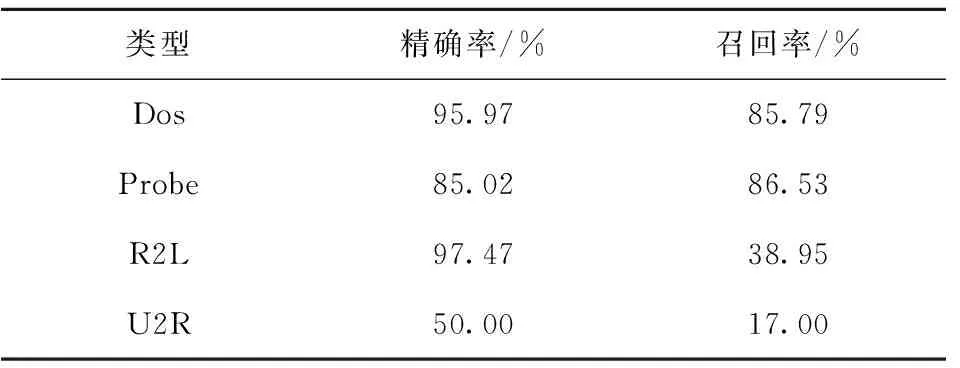
表7 不同攻击类型的检测精确率与召回率Table 7 Detection accuracy and recall ratio of different attack types
如图11所示,CNN-FL模型的检测准确率较C4.5决策树、随机森林、随机树、支持向量机、循环神经网络等分类算法所获得的准确率要高。由于数据集中样本分布不均匀,与二分类相比,五分类的模型检测准确率有所下降。
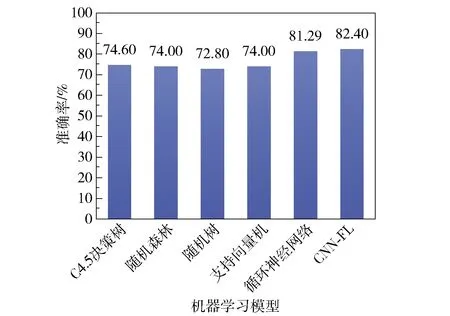
图11 五分类各模型准确率Fig.11 Accuracy of each model in the five classification test
4 结束语
针对目前网络异常检测技术还存在着检测准确率低、误报率高以及缺乏标签数据等问题,本文提出了CNN-FL网络异常检测模型。在CNN-FL模型中,参与者不会将他们的训练数据共享给第三方,只是传递加密的梯度相关数据,从而保护了数据隐私,同时解决了数据孤岛以及缺乏标签数据的问题。在实验中CNN-FL模型具有强大的入侵检测建模能力,在二分类和多分类中均具有较高的准确率、精确率和召回率,优于传统的分类方法。在未来的工作中,将进一步拓展联邦学习的使用领域,并研究长短期记忆网络(LSTM)、双向循环神经网络(双向RNNs)等深度学习算法与联邦学习模型结合在网络异常检测领域的分类性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算技术与自动化(2022年1期)2022-04-15
南京理工大学学报(2022年1期)2022-03-17
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
青少年科技博览(中学版)(2017年4期)2017-06-13
