
基于升降编解码全卷积神经网络语音增强技术
2021-05-11 19:06孙立辉曹丽静张竟雄
智能计算机与应用 2021年2期
孙立辉 曹丽静 张竟雄


摘 要:步兵战车强噪声背景下由于强背景噪声的存在,既影响了口令识别的正确率,又降低了指挥所后台监听的清晰度,为了提高语音质量,本文对口令数据进行增强处理。为此,本文提出了一种基于升降编解码全卷积神经网络(IncreaseDecreaseEncoderDecodeConvolutionNeuralNetwork,IDEDCNN)的语音增强算法,该算法将输入语音信号通过预处理,获取其傅里叶幅度谱特征,并将连续8帧的语音信号作为网络的输入,通过编码器来对相邻多帧语音信号建模以提取上下文信息,利用解码器挖掘当前待增强语音帧和上下文信息之间的联系,从而实现语音增强的目的。通过实验证明了该算法能够实现较好的语音增强效果。
关键词:噪声估计;语音增强;全卷积神经网络
【Abstract】Duetothepresenceofstrongbackgroundnoiseinthebackgroundofinfantryfightingvehicles,theaccuracyofpasswordrecognitionisnotonlyaffected,butalsotheclarityofbackgroundmonitoringofcommandpostisreduced.Inordertoimprovethevoicequality,thispapercarriesoutenhancedprocessingofpassworddata.Tothisend,thispaperputsforwardaliftdecodingtheconvolutionalNeuralNetwork(happensDecreaseEncoderDecodeConvolutionNeuralNetwork,IDEDCNN),whichisthespeechenhancementalgorithm.Inthisalgorithm,theinputspeechsignalispreprocessed,theFourieramplitudespectrumfeaturesareobtained,andeightadjacentframesofspeechsignalaretakenasnetworkinput,modelofadjacentframesofvoicesignalismodeledthroughtheuseoftheencodertoextractcontextinformation.Thedecoderisusedtominetheconnectionbetweenthespeechframeandthecontextinformationsoastorealizethepurposeofspeechenhancement.Experimentalresultsshowthatthisalgorithmcanachievebetterspeechenhancementeffect.
【Keywords】noiseestimation;speechenhancement;FCNN
作者簡介:孙立辉(1970-),男,博士,教授,主要研究方向:计算机视觉、机器学习;曹丽静(1994-),女,硕士研究生,主要研究方向:语音增强、深度学习;张竟雄(1996-),男,硕士研究生,主要研究方向:计算机视觉、深度学习。
0 引 言
随着军事化训练的自动化,实现对综合采集的战士口令数据的识别,对评估战士的训练效果具有重要意义。在战车训练过程中要对采集的战士口令数据进行后台监听以及口令识别操作。但是由于战车强噪声背景的存在,导致目前的算法无法实现较好的口令识别效果,因此,有必要增强口令数据,从而提高监听效果和口令识别准确率。
神经网络具有强大的学习能力,能够很好地实现语音增强的效果。文献[1]提出利用冗余卷积编码器解码器网络结构学习有噪声语音光谱和干净语音光谱之间的映射,解决了助听器中存在的噪声问题,提高了语音的清晰度。文献[2]通过将新的网络建立到编码器和译码器上,增加基于卷积的短时傅里叶变换层(STFT)和逆STFT层来模拟STFT的正逆操作,得到了较好的语音增强效果。文献[3]并没有直接对时域信号进行处理,而是将信号转换为频域上的信号,并且使用增强STFT幅度和干净STFT之间的平均绝对误差损失来训练CNN,该方法避免了无效STFT问题,实验结果表明该算法能够完成增强的目的。
本文提出了一种基于升降编解码全卷积神经网络(IncreaseDecreaseEncoderDecodeConvolutionNeuralNetwork,IDEDCNN)的语音增强算法,该算法将输入语音信号通过预处理,获取其傅里叶幅度谱特征,并将连续8帧的语音信号作为网络的输入,通过编码器来对相邻多帧语音信号建模以提取上下文信息,利用解码器挖掘当前待增强语音帧和上下文信息之间的联系,从而实现语音增强的目的。通过实验证明了该算法能够实现较好的语音增强效果。
1 步兵战车环境下语音增强问题描述
步兵战车强噪声背景下的语音数据是由战士的口令数据s和发动机等背景噪声d组成的带噪数据y,即:
y=s+d,(1)
步兵战车环境下的语音增强目标就是输入带噪语音数据y,得到s的较为准确的估计值s'。为了完成步兵战车背景下战士语音数据增强的任务,在网络的训练阶段使网络学习含噪语音特征和干净语音特征之间的映射关系,即:
s'=f(y),(2)
在增强阶段利用训练好的模型获得估计的干净语音信号。步兵战车环境下战士语音口令数据增强系统如图1所示。
2 升降编解码全卷积神经网络
本文通过实验验证直接利用全卷积神经网络结构实现步兵战车环境下战士语音口令数据的增强,无法实现较大跨度的增强效果,提高语音的质量。受Lee等人[1]利用R-CED(R-ConvolutionEncodeDecode)网络实现了助听器语音数据的增强,本文提出了另外一种卷积网络体系结构,即升降编解码全卷积神经网络(IncreaseDecreaseEncoderDecodeConvolutionNeuralNetwork,IDEDCNN)来解决步兵战车环境下战士语音口令数据增强。升降编解码全卷积神经网络结构如图2所示。
步兵战车背景下战士语音口令增强网络的输入为129*8的STFT矢量,网络是重复的卷积、归一化和ReLu激活函数组成,网络深度为15个卷积层,实验训练轮数16轮,学习率最初设置为a=0.0015,并且当验证损失在4次训练不变时,学习率依次下降为a/2,a/3,a/4来进行训练,损失函数为交叉熵,为了验证本文提出网络结构的可行性,与FCN结构进行对比,2种网络结构见表1。
3 实验与结果分析
3.1 数据集
步兵战车环境下战士语音口令数据增强分为训练和增强两个阶段。对此拟做阐释分述如下。
(1)训练数据集。实验数据集分为训练集、测试集和验证集,干净数据为CommonVoice,噪声数据是步兵训练场上采集的各种战车的背景噪声,并且在0dB信噪比时随机添加噪声来增强鲁棒性测试集。训练集共计5000个语音数据段,测试集200个语音数据段,实验中1%的数据集作为验证集。
(2)增强数据集。增强阶段输入含噪语音口令数据,进行特征提取后输入到预训练好的模型中,进行增强和语音重构后,获得增强后的数据集。数据集共计3300条步兵战车强噪声背景下战士语音口令数据。
3.2 预处理和参数选取
将输入的音频数据进行降采样操作,降到8kHz,通过256点短时傅里叶变换(32ms汉明窗口)计算得到频谱矢量,窗口移动长度为8ms,并且通过对称移除信号操作,将256点的短时傅里叶(theshort-timeFouriertransform,STFT))向量简化为129点。
通过预处理操作,获得的网络输入特征是由8个连续的STFT向量组成,并且输入特征都进行了标准化,使其均值和单位方差均为0。由于语音增强系统是逐帧进行语音增强,因此文中解码器最终只输出当前待增强语音的干净语音特征估计,即只输出一帧,因此输出特征为129*1的向量,并且进行标准化使其均值和单位方差都为0。
3.3 优化
为了提高语音的质量,减小噪声过估计,保证噪声估计的鲁棒性,进行了优化,具体如下。
3.4 实验与分析
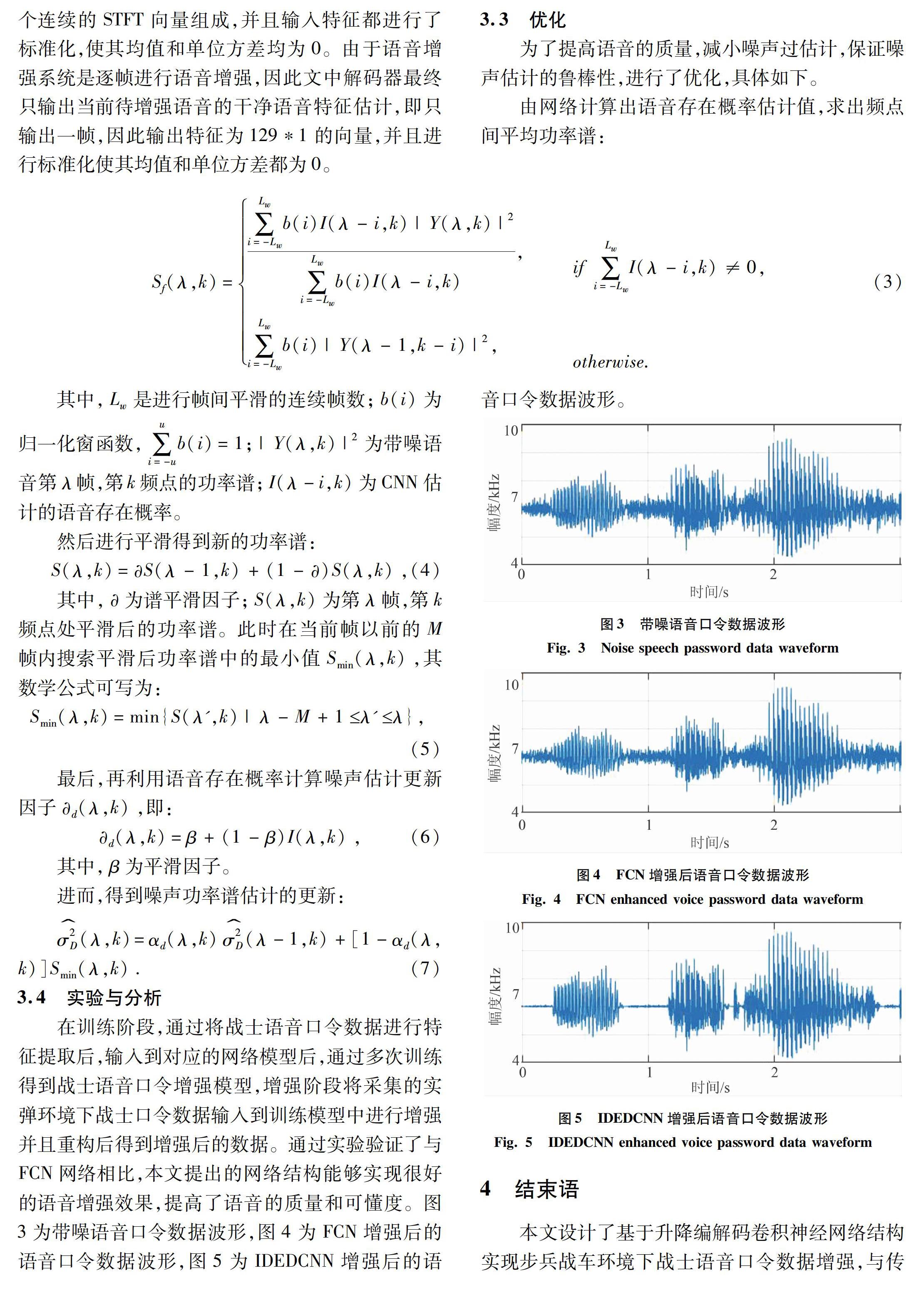
在训练阶段,通过将战士语音口令数据进行特征提取后,输入到对应的网络模型后,通过多次训练得到战士语音口令增强模型,增强阶段将采集的实弹环境下战士口令数据输入到训练模型中进行增强并且重构后得到增强后的数据。通过实验验证了与FCN网络相比,本文提出的网络结构能够实现很好的语音增强效果,提高了语音的质量和可懂度。图3为带噪语音口令数据波形,图4为FCN增强后的语音口令数据波形,图5为IDEDCNN增强后的语音口令数据波形。
4 结束语
本文设计了基于升降编解码卷积神经网络结构实现步兵战车环境下战士语音口令数据增强,与传统的全卷积神经网络相比,该网络结构在编码阶段滤波器数量逐渐增多,从而获取数据更高维特征,解码阶段压缩特征,并且为了保持语音数据上下文之间的联系,网络的输入为相邻8帧的数据。通过与传统全卷积神经网络结构相比,本文提出的网络结构能够实现更好的增强效果。但是由于战车强噪声的极其不稳定,增强结果仍然会存在噪声残留,接下来会继续分析如何更好降低战车强噪声背景下的语音增强,从而实现更好的识别工作。
参考文献
[1] ARKSR,LEEJW.AfullyConvolutionalNeuralNetworkforspeechenhancement[C]//INTERSPEECH2017.Stockholm,Sweden:ISCA,2017:1993-1997.
[2]ZHUYuanyuan,XUXu,YEZhongfu.FLGCNN:Anovelfullyconvolutionalneuralnetworkforend-to-endmonauralspeechenhancementwithutterance-basedobjectivefunctions[J].AppliedAcoustics,2020,170(2):107511.
[3]PANDEYA,WANGDeLiang.AnewframeworkforCNN-basedspeechenhancementinthetimedomain[J].IEEE/ACMTransactionsonAudio,SpeechandLanguageProcessing(TASLP),2019,27(7):1179-1188.
[4]TANKe,CHENJitong,WANGDeLiang.GatedresidualnetworkswithDilatedConvolutionsformonauralspeechenhancement[J].IEEE/ACMTransactionsonAudio,SpeechandLanguageProcessing(TASLP),2019,27(1):189-198.
[5]彭川.基于深度學习的语音增强算法研究与实现[D].成都:电子科技大学,2020.
[6]张明亮,陈雨.基于全卷积神经网络的语音增强算法[J].计算机应用研究,2020,37(S1):135-137.
[7]JIAHairong,WANGWeimei,MEIShulin.CombiningadaptivesparseNMFfeatureextractionandsoftmasktooptimizeDNNforspeechenhancement[J].AppliedAcoustics,2021,171:107666.
[8]YUHongjiang,ZHUWeiping,CHAMPAGNEB.SpeechenhancementusingaDNN-augmentedcolored-noiseKalmanfilter[J].SpeechCommunication,2020,125(2):142-151.
[9]王師琦,曾庆宁,龙超,等.语音增强与检测的多任务学习方法研究[J/OL].计算机工程与应用:1-8[2020-11-26].https://kns.cnki.net/kcms/detail/11.2127.TP.20201126.0923.004.html.
[10] 房慧保,马建芬,田玉玲,等.基于感知相关代价函数的深度学习语音增强[J].计算机工程与设计,2020,41(11):3212-3217.
[11]郑展恒,曾庆宁.语音增强算法的研究与改进[J].现代电子技术,2020,43(21):27-30.
[12]袁文浩,时云龙,胡少东,等.一种基于时频域特征融合的语音增强方法[J/OL].计算机工程:1-10[2020-11-26].https://doi.org/10.19678/j.issn.1000-3428.0059354.
[13]张行,赵馨.基于神经网络噪声分类的语音增强算法[J].中国电子科学研究院学报,2020,15(9):880-885,893.
[14]范珍艳,庄晓东,李钟晓.基于变换域稀疏度量的多级FrFT语音增强[J].计算机工程与设计,2020,41(9):2574-2584.
[15]田玉静,左红伟,王超.语音通信降噪研究[J/OL].应用声学:1-11[2020-07-22].http://kns.cnki.net/kcms/detail/11.2121.O4.20200721.1827.008.html.
[16]袁文浩,胡少东,时云龙,等.一种用于语音增强的卷积门控循环网络[J].电子学报,2020,48(7):1276-1283.
[17]龚杰,冯海泓,陈友元,等.利用波束形成和神经网络进行语音增强[J].声学技术,2020,39(3):323-328.
[18]李劲东.基于深度学习的单通道语音增强研究[D].呼和浩特:内蒙古大学,2020.
[19]张宇飞.基于深度神经网络和循环神经网络的语音增强方法研究[D].绵阳:中国工程物理研究院,2020.
[20]蓝天,彭川,李森,等.单声道语音降噪与去混响研究综述[J].计算机研究与发展,2020,57(5):928-953.
[21]孔德廷.一种改进的基于对数谱估计的语音增强算法[J].声学技术,2020,39(2):208-213.
[22]高登峰,杨波,刘洪,等.多特征全卷积网络的地空通话语音增强方法[J].四川大学学报(自然科学版),2020,57(2):289-296.
[23]王文益,伊雪.基于改进语音存在概率的自适应噪声跟踪算法[J].信号处理,2020,36(1):32-41.
[24]吴庆贺,吴海锋,沈勇,等.工业噪声环境下多麦状态空间模型语音增强算法[J].计算机应用,2020,40(5):1476-1482.
[25]DANIELM,TANZhenghua,SIGURDURS,etal.Deep-learning-basedaudio-visualspeechenhancementinpresenceofLombardeffect[J].CoRRabs/1905.12605,2019.
[26]SALEEMN,KHATTAKMI,PEREZEV.Spectralphaseestimationbasedondeepneuralnetworksforsinglechannelspeechenhancement[J].JournalofCommunicationsTechnologyandElectronics,2019,64(12):1372-1382.
[27]董胡,徐雨明,马振中,等.基于小波包与自适应维纳滤波的语音增强算法[J].计算机技术与发展,2020,30(1):50-53.
