
基于PCIe的高性能FPGA-GPU-CPU异构编程架构*
2021-05-11 01:35孙兆鹏周宽久
计算机工程与科学 2021年4期
孙兆鹏,周宽久
(大连理工大学软件学院,辽宁 大连 116620)
1 引言
5G的到来再次推动了物联网的发展,随之而来的是海量数据。海量数据由于保存占用大量空间和资源而需要及时处理。异构计算[1]是一种特殊新颖的并行计算方式,它能够根据不同计算单元的结构特点为其分配不同的计算任务,在提高服务器计算性能、能效比和计算实时性方面显示出传统架构所不具备的优势,因此异构计算技术是解决未来数据中心能效问题的重要手段。
陈左宁院士等专家认为多维异构硬件资源是由通用计算资源(如CPU)、多用计算资源(如FPGA)、专用计算资源(如GPU)以及存储资源(主存、外存)、互连资源(内部互连、外部接口)所构成的复杂高性能异构计算资源集合,如图1所示。

Figure 1 Heterogeneous computing resource set图1 异构计算资源集合
本文的主要贡献包括3个方面:
(1) 结合现有的CUDA和Vivado编译器与函数库,提出了基于状态迁移矩阵STM(State Transition Matrix)的异构统一自动化编程方法。
(2) 利用PCIe实现GPU到FPGA的直连通信,通过GPUDirect RDMA实现FPGA作为主控器的PCIe通信,突破了GPU作为主控器的PCIe通信当中读取操作的短板。
(3) 以行人检测为应用场景,实现fastHOG+SVM的异构设计,并在异构平台上进行一系列实验,与基于共享内存的间接通信方式进行性能比较,证明了直接通信的优越性。
本文的其余结构如下:第2节介绍异构计算方面相关的工作,第3节介绍异构编程环境的整个流程和实现方案,第4节描述实现直接GPU-FPGA传输的机制,第5,6节介绍实验方案和实验结果,第7节描述未来的工作,并讨论异构编程架构的实际应用价值。
2 相关工作
现如今在大量不同领域,如深度学习[2 - 4]、图像处理[5 - 7]等领域,有相关研究比较了FPGA和GPU的性能。这些研究都体现出FPGA和GPU在计算能力方面有着独特的表现,FPGA擅长浮点算术运算,而GPU在矩阵运算方面有更好的性能。由于这些特性,研究人员开始研究异构体系结构来提高系统的计算能力。
最初的工作当中,大部分研究人员是用不同计算单元处理不同任务模块,例如文献[5]提出了一种运动实时定位的FPGA-GPU-CPU异构平台,文献[8]使用组合FPGA-GPU架构进行心脏生理光学映射。但是,在这些研究中,FPGA只是起到数据采集的作用,GPU始终作为主要的计算单元,并没有充分发挥各个计算单元的计算性能,算不上真正的异构计算。
后续的研究中,通过比较FPGA和GPU的性能给不同计算单元分配计算任务。文献[9]提出了一种FPGA和GPU性能对比的系统方法,并且选取了5种不同的算法进行实验比较,最终给出了目标设备的吞吐性能和硬件特性。文献[10]使用Roofline模型[11]来检测适合不同算法加速的加速器,然后基于fastHOG行人检测程序进行了验证。文献[12]以计算机视觉算法为例对FPGA和GPU进行了非常全面的对比,包括性能、成本和可移植性。后续一些工作大多基于这些研究提出了任务级或代码级的并行计算[13 - 15]以及其他的优化方法。但是,这些工作大部分都是基于共享内存实现通信,实验中并不会遇到传输瓶颈,而实际应用中面对实时的数据处理,主机的内存限制了异构平台的计算效率。
异构系统中涉及多种计算单元,要想发挥出各计算单元的性能,需要以高带宽和低延迟实现它们之间的实时数据传输。文献[16]实现了一种基于共享内存的GPU-FPGA架构的桌面编程环境,初步实现了工业级应用的工具链,并且进行了性能分析。文献[17]使用FPGA通过自定义互连实现了对等GPU通信。文献[18]通过PCIe总线实现了直接的双向GPU-FPGA通信方案。但是,这些工作仅仅实现了GPU作为主控器的传输方式,FPGA向GPU传输数据的效率低下,只有在特殊情景下才能得到传输效率的优化,无法体现出异构计算系统的优势。
经过几年大范围多行业的应用和对行业内其他异构应用的调研,我们总结了用户与科研人员反馈的一些实际问题:(1)OpenCL通用性更强,但是针对实际计算任务,编程复杂困难,计算结果正确性难以保证;(2)高负载运算时共享内存的通信方式对PCIe设备通信压力过大,限制了各计算单元性能的发挥;(3)基本没有考虑计算单元调度策略,无法适应未来数据中心应用。从CUDA 5.0开始,NVIDIA发布了远程直接内存访问(GPUDirect RDMA)[19],使其他PCIeP[20]设备可以完全绕开CPU内存直接访问GPU内存。
针对以上这些问题,本文提出了基于STM的异构统一自动化编程方法,并且利用PCIe实现了GPU到FPGA的直连通信,通过实现FPGA作为主控器的PCIe通信,突破了GPU作为主控器的PCIe通信当中读取操作的短板。进行了文件传输和行人检测的一系列对比实验,表明了异构架构的必要性。并且将本文研究应用于CPU-GPU-FPGA多维异构大数据处理平台MATRIX,实现了虚拟化管理。目前该研究成果已在信息安全、人工智能应用、集成电路设计等诸多领域得到了应用。
3 异构编程环境
3.1 异构编程流程
图2所示是本文提出的基于STM的异构统一自动化编程流程。

Figure 2 Process of heterogeneous programming图2 异构编程流程
通过STM对异构计算所需的标准C代码进行建模与生成,提高了编程效率,保证了代码的可靠性。具体流程如下所示:
(1) 建立状态迁移矩阵实现需求的功能,并且确定由GPU或FPGA加速的应用程序部分。
(2) 通过状态迁移表进行逻辑验证后,生成相应的标准C程序。
①GPU代码→GPU编译器(CUDA 10.0);
②FPGA代码→高层次综合(Vivado HLS)。
(3) 编译程序综合FPGA设计,生成连接CPU、GPU和FPGA二进制文件的可执行文件。
(4) 加载GPU、CPU代码二进制文件和FPGA配置二进制文件。
(5) 执行程序。
3.2 统一编程模型定义
状态迁移矩阵STM[21 - 23],也叫做状态迁移表,它是一种基于表格形式的建模方法,可以对系统的动态行为进行有效建模,如图3所示。
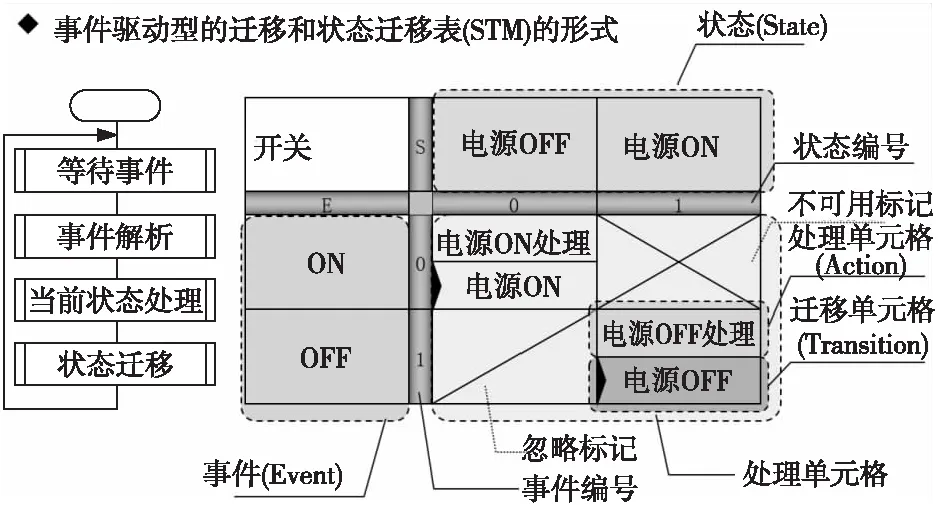
Figure 3 Structure of state transition matrix图3 状态迁移矩阵结构
定义1STM由 (S,E,C) 3元组表示,满足以下条件:
(1)S为有限状态集。STM表的列表示系统模型中状态的集合scolumn,状态scolumn∈S,column∈{1,2,3,…,M},在STM运行过程中,只有唯一的初始激活状态。
(2)E为有限事件集。STM表的行表示系统模型中即将触发事件的集合erow,事件erow∈E,row∈{1,2,3,…,N}。
(3)STM表中状态scolumn与事件erow相交处的单元格集合为C(si,ej,g(i,j),a(c)),i,j∈{1,2,3,…,N},即系统在si状态下,同时触发目标ej事件时,处理动作表达式C中的判定条件g(i,j)并进入目标执行状态a(c)。
根据上述定义,对图3所示模型进行如下说明:
(1)状态集合S={电源OFF,电源ON};
(2)事件集合E={ON,OFF};
(3)单元格集合C={C00,C11},其中:
C00= {cTransition00,cactions00},其中cTransition00为“电源ON处理”,cactions00为“电源ON”;
C11= {cTransition11,cactions11},其中cTransition11为“电源OFF处理”,cactions11为“电源OFF”。
STM中表现的if分支、switch选择和for/while循环结构,将控制流转换成STM模型,若从生成的STM模型中发现一些空白STM单元格,则说明代码可能存在逻辑缺陷,针对STM模型验证可发现C代码逻辑错误。此时,通过完善STM模型可生成逻辑完善的标准C代码,部分生成规则如图4所示。
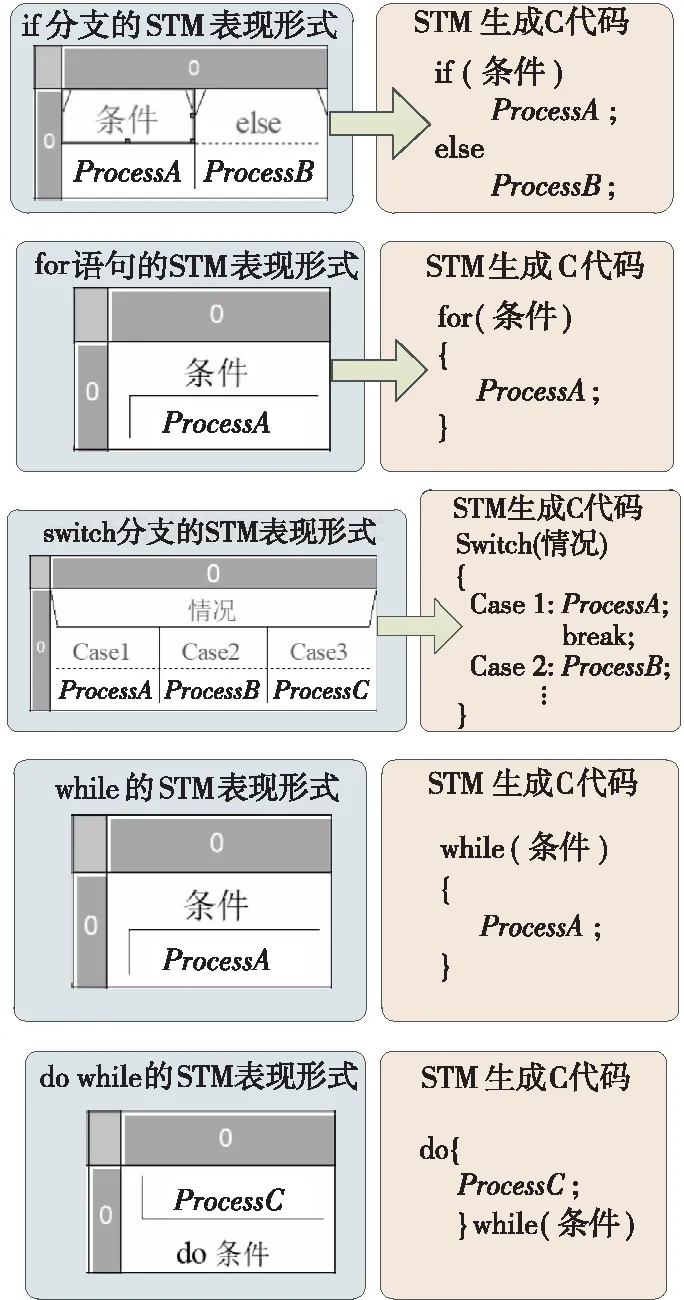
Figure 4 STM to C code conversion example图4 STM到C代码转换示例
4 异构架构直连通信实现
在本文提出的异构编程架构中,顶层通过STM集成CUDA和Vivado的接口来控制GPU和FPGA的计算资源,底层各计算单元之间的通信还需要实现CPU-GPU-FPGA设备之间的两两互相通信来提高数据传输效率。本文的工作是基于PCIe实现整个底层通信过程。NVIDIA和XILINX在各自的产品中已经提供了高效的CPU-GPU和CPU-FPGA通信方法,本文的主要贡献就是实现高效的GPU-FPGA通信。
现有GPU-FPGA通信的主流方法主要有2种,第1种是通过CPU内存传输数据来实现GPU到FPGA的通信,这种通信方式被称为间接GPU-FPGA传输或基于共享内存的通信方式,如图5中粗实线所示。使用基于共享内存的间接方法,数据要经过PCIe交换机2次,并且系统和内存操作也会需要必要的延迟,因此间接通信方式需要额外的通信等待时间。
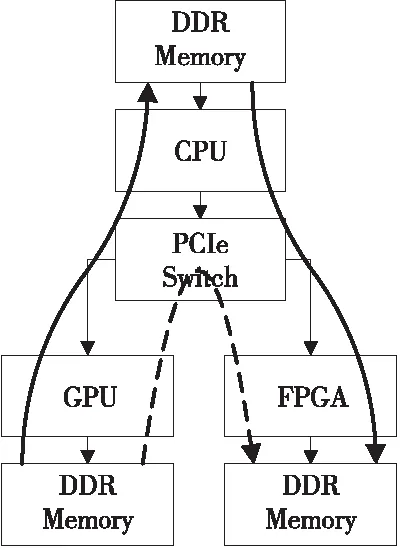
Figure 5 Heterogeneous communication implementation图5 异构架构通信实现方式
第2种则是通过PCIe总线创建直接的GPU-FPGA通信,如图5中虚线所示,每次通信数据仅通过PCIe交换机1次,不会复制到CPU内存中,GPU-FPGA通信具有更高效的通信效率,称之为直接GPU-FPGA传输。这种方法按照主从设备又可以划分为GPU作为主控器的通信和FPGA作为主控器的通信。表1汇总了每种传输类型的主/从关系。本文实现了这2种通信方式并且分别选取了GPU作为主控器的写入操作和FPGA作为主控器的写入操作实现GPU与FPGA的双向通信过程优化整个异构计算系统的通信效率。下面详细介绍如何实现本文的异构架构。

Table 1 Subordination in communication表1 通信中的主从关系
4.1 PCIe内核

Figure 6 XILINX PCIe structure图6 XILINX PCIe结构图
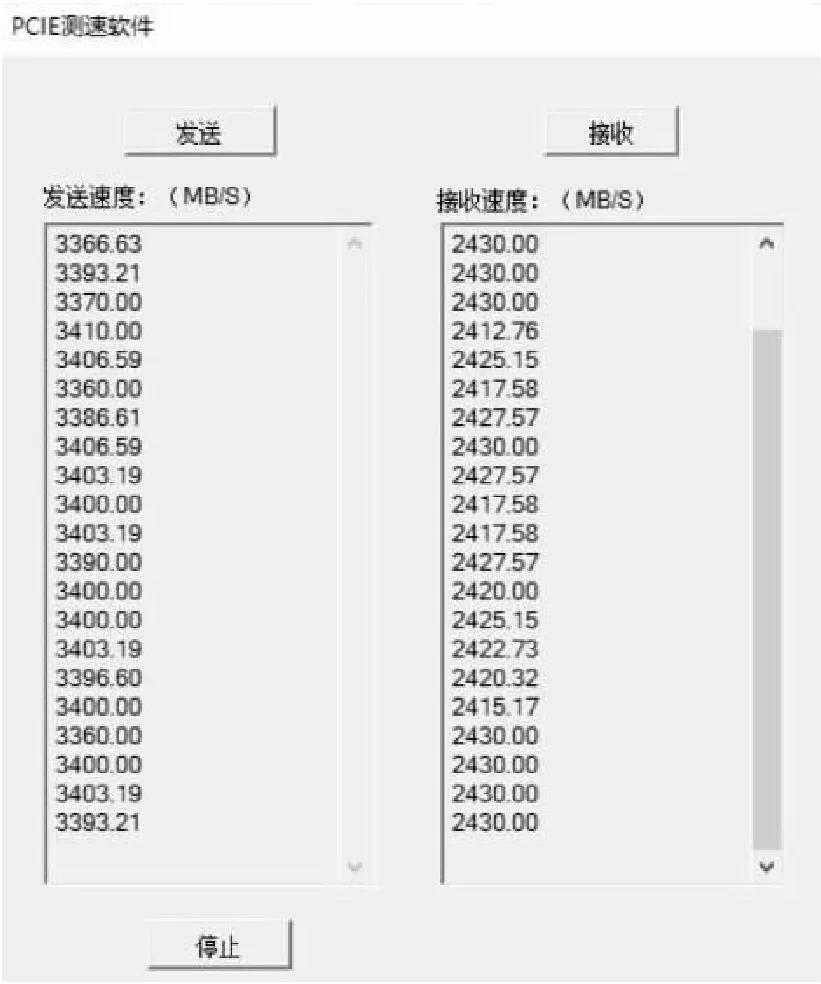
Figure 7 XILINX PCIe Communication speed measurement图7 XILINX PCIe通信测速
图6所示的PCIe内核是XILINX设计的可免费下载的FPGA内核。XILINX PCIe IP核[24]为FPGA设计人员提供了将PCIe总线封装成类似于存储器接口的功能,并将该存储器接口转换为高速DMA引擎;同时,XILINX也提供了Windows环境下的驱动程序,可以实现CPU存储器和FPGA本地的DDR3存储器之间的通信,通信速度高达4.0 GB/s(PCIe 2.0×8)。图7为本文实现的CPU和FPGA之间通信的测速结果。
4.2 GPU与FPGA直连通信的实现
由于图像领域的蓬勃发展,有关GPU各方面的研究在现阶段都已经比较成熟,各种工具封装得非常完善,所以对GPU硬件可以进行的操作很少,当然这本身也非常困难,因为大部分的硬件功能都封装在驱动程序中。通常,CUDA仅支持GPU和CPU内存间的传输,不支持GPU内存与其他任意设备之间的传输。但是,在CUDA 4.0之后,NVIDIA为Quadro和Tesla的专业级GPU提供了对等内存传输功能(GPU-GPU),CUDA 5.0之后,NVIDIA又为专业级的GPU提供了GPUDirect RDMA[19]的接口,通过此接口可以获取GPU memory的总线地址,这样就可以作为FPGA DMA读/写的目的地址。
针对消费者级别GPU不支持GPUDirect RDMA API的问题,本文分别实现了2种GPU与FPGA直连通信解决方案,第1种是GPU始终是总线主控器;第2种是GPU和FPGA分别作为总线控制器,二者仅作为主控器进行写入操作,不进行读取操作。因为文献[18]的工作以及本文后续的实验结果都表明读取操作的复杂程度和耗时远远超过写入操作。将FPGA作为主控器启动PCIe通信进行写入操作需要访问GPU的内部结构,但是消费者级别的GPU并不支持这种方式。
第1种实现方案中,GPU是主控器,FPGA是从属器。这种方式要求将FPGA的内存映射到PCIe总线上,GPU直接对FPGA内存进行读写操作。CUDA API支持CPU内存页面锁定,页面锁定后的内存页具有恒定的物理地址,可以由GPU的总线主控DMA控制器有效地访问。CUDA提供了cudaMalloc(),用于分配和释放此类内存块。经过实验可以发现,CUDA提供的API并不区分操作的是哪个计算单元的虚拟地址。因此,CUDA中的这些功能同样可以直接操作FPGA的虚拟地址。通过这种方式,本文实现了直接访问FPGA存储器的驱动程序,从而使GPU直接向FPGA的内存写入数据或读取数据。文献[18]使用了开源的Speedy PCIe内核,将DDR3物理内存地址映射到PCIe总线上,并将这些CUDA API应用于GPU-FPGA传输。
GPU-FPGA通信中DMA代码示例如下所示:
Example Code 1:
gpu_ptr=cudaMalloc(MEM_SIZE);
//Allocate GPU memory
run_kermel(gpu_ptr,… );
所有子系统的控制器均通过其自身的MVB-EMD(EMD为用于中距离传输的电介质)通信接口接入到MVB网络。其中,关键子系统如牵引控制系统、辅助电源控制系统、制动控制系统、信号系统、车门系统等均具有硬线接口,以便在网络控制系统故障时,进行紧急牵引操作。
/*Perform GPU computation that modify GPU memory*/
fpga_ptr=DeviceIoControl(IOCTL_SPEEDYPCIE_GET_DIRECT_MAPPED_POINTER);
//Map FPGA memory to GPU virtual address space
cudaBostRegister(fpga_ptr,MEM_SIZE );
//Present FPGA memory to CUDA as locked pages
cudaMemcpy(fpga_ptr,gpu_ptr,MEM_SIZE,cudaMemcpyDeviceToHost);
第2种实现方案中,首先使用第1种方案实现GPU作为主控器在FPGA的DDR写入操作;然后还需要利用GPUDirect RDMA[25]的API实现FPGA作为主控器在GPU的DDR写入操作。
FPGA-GPU通信中GPUDirect RDMA的API接口如下所示:
Example Code 2:
Lock the physical page pointed to bypage_ptr
intnvidia_p2p_get_pages(
uint64_tp2p_token;
uint32_tvtl_space;
//GPU memory virtual address
uint64_tvirtual_address;
uint64_tlength;
/*Returns the number of mapped physical pages and the physical address of each page*/
structnvidia_p2p_page_table**page_ptr,
void (*free_callback)(void*data),
void*data)
//Release the physical page pointed to bypage_ptr
intnvidia_p2p_put_pages(
uint64_tp2p_token;
uint32_tva_space;
uint64_tvirtual_address;
structnvidia_p2p_page_table*page_ptr)
5 实验环境与实验结果
5.1 实验环境
本文搭建的实验环境分别选择了一款高端游戏显卡GPU NVIDIA GeForce GTX 2070和一款专业显卡GPU Leadtek Quadro RTX 4000,二者都支持CUDA 10.0 API,唯一的区别是Quadro RTX 4000支持GPUDirect RDMA的API,而NVIDIA GeForce GTX 2070不支持。二者都具有16个PCIe 3.0通道,吞吐量高达15.8 GB/s。
实验中使用的FPGA平台是XILINX Kintex7 AX7325开发板,芯片为XC7K325TFFG900。支持PCIe 2.0×8的接口,吞吐量可达4 GB/s。(GPU的吞吐量是它的4倍左右)。GPU和FPGA加速卡插在支持PCIe 3.0和2.0的定制主板上,CPU采用的是Intel Xeon E5-2600V3处理器。异构计算平台的具体配置如图8所示。
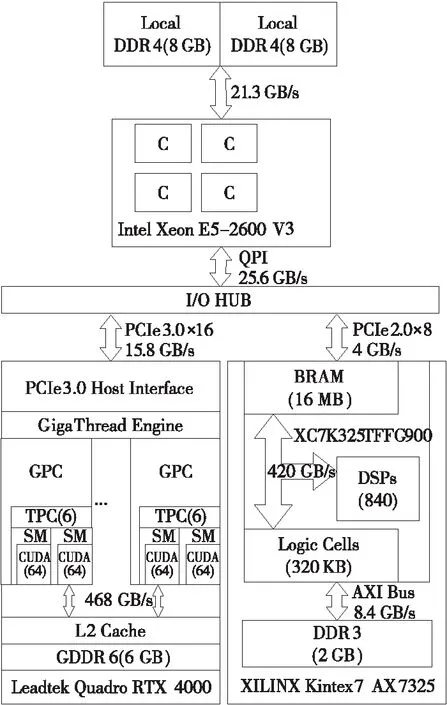
Figure 8 Heterogeneous computing platform configuration图8 异构计算平台配置
CPU和FPGA之间的通信以及CPU和GPU之间的通信都是使用供应商的驱动程序实现的。XILINX 7Series PCIe的驱动程序为用户提供的FPGA文件句柄实现了CPU和FPGA之间的通信,cudaMemcpy()则在CPU内存的用户缓冲区中实现了CPU和GPU之间的通信。GPU/FPGA分别在通信过程中充当PCIe总线主控器,根据任务需求对CPU的内存进行写入或读取操作。而在GPU和FPGA直连通信的2种方式中,分别利用GPUDirect RDMA实现了FPGA作为主控器的通信和利用修改的Speedy PCIe实现了GPU作为主控器的通信。具体实现方案在第4节已做详细描述。
5.2 实验结果
本文进行了不同大小文件传输实验,并统计了每个传送方向上的不同大小文件传输带宽的曲线图。每种实验条件下进行10次传输,计算平均速度作为每个传输方向的带宽。如图9所示,随着单个传输文件大小的增加,传输效率逐渐提高,直到达到理论带宽的渐近值为止。
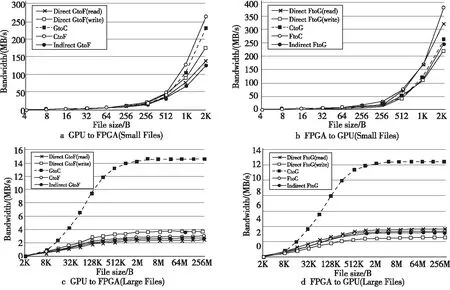
Figure 9 Experimental results of transmission bandwidth图9 传输带宽实验结果
图9a和图9c的5条曲线显示了本文实现的GPU到FPGA通信的带宽,其中,Direct GtoF(write)表示GPU到FPGA直接路径的带宽(GPU作为主控器),Direct GtoF(read)表示GPU到FPGA直接路径的带宽(FPGA作为主控器),GtoC和CtoF分别表示GPU到CPU和CPU到FPGA的带宽,Indirect GtoF表示GPU到FPGA间接路径的带宽。
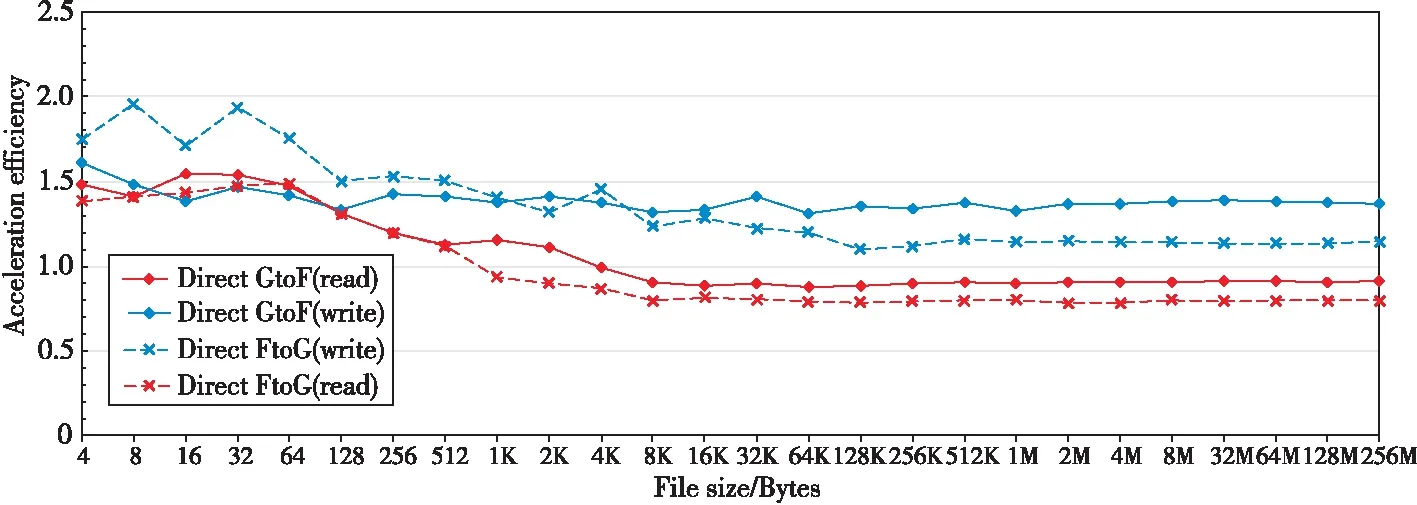
Figure 10 Speedup of GPU-FPGA relative to GPU-CPU-FPGA transmission图10 GPU-FPGA相对于GPU-CPU-FPGA传输的加速比
图9b和图9d的5条曲线显示了FPGA到GPU通信的带宽,图中各符号的含义与图9中的相同,只有数据传输方向是反向的。
从图9中可以看出,大型文件传输中黑色实线代表的是CPU与GPU间的通信效率远远高于其他计算单元之间的通信效率,因为GPU支持生成3.0×16通道的PCIe接口,FPGA仅支持PCIe 2.0×8。所以,GPU到FPGA间接路径的带宽会受到CPU到FPGA带宽的限制,导致间接路径通信效率比较低。
由于在FPGA和GPU与CPU的通信中,始终是CPU作为从属,因此CPU到FPGA/GPU的传输效率远低于FPGA/GPU到CPU传输数据的效率。但是,GPU和CPU之间的带宽较高,因此间接路径当中,GPU-CPU-FPGA方向的传输效率要低于FPGA-CPU-GPU的传输效率。如果仅仅是采用实现GPU作为主控器的传输方式,那么在FPGA到GPU的传输效率反而会降低。如果仅仅是采用实现FPGA作为主控器的传输方式,GPU到FPGA的传输效率就会降低。这就是本文使用更多的硬件资源来实现2种传输方式的目的,使得双向的传输都得到优化。
5.3 实验分析
为了更加清晰地体现出各种通信方式的效率比较,本文根据比值绘制了图10,4条曲线分别代表以下含义:Direct GtoF(write)表示GPU到FPGA的直接通信(GPU执行写入操作)与GPU到FPGA间接通信效率的比值。Direct FtoG(read)表示FPGA到GPU的直接通信(GPU执行读取操作)与FPGA到GPU间接通信效率的比值。Direct GtoF(read)表示GPU到FPGA的直接通信(FPGA执行读取操作)与GPU到FPGA间接通信效率的比值。Direct FtoG(write)表示FPGA到GPU的直接通信(FPGA执行写入操作)与FPGA到GPU间接通信效率的比值。
实验中的主要限制因素是FPGA支持的带宽,因为FPGA是PCIe 2.0×8的接口,因此无论其他计算单元传输性能如何,它的最高性能都是4 GB/s。由于实验条件所限,没有支持PCIe 3.0的FPGA加速卡,但是无论如何这都不影响对直接通信和间接通信的效率进行对比实验,而且如果获得PCIe 3.0的板卡,本文方案的通信效率还会大大提升。从图9中上下图像的相同类型曲线对比可以看出,数据传输的写入操作和读取操作具有不对称的带宽特性。图10比较了直接GPU-FPGA传输和间接GPU-CPU-FPGA传输的相对速度。纵轴表示加速比,加速比由直接传输与间接传输速度的比值计算得出,小于1表示性能降低,大于1表示性能提高。
在GPU到FPGA的传输路径中,对于大型文件的传输,GPU到FPGA的直接通信(GPU执行写入操作)比GPU到FPGA的间接通信效率提高了36.58%,而GPU到FPGA的直接通信(FPGA执行读取操作)与GPU到FPGA的间接通信相比通信效率降低了8.71%。FPGA到GPU的传输路径中,FPGA到GPU的直接通信(FPGA执行写入操作)比FPGA到GPU的间接通信效率提高了14.53%,FPGA到GPU的直接通信(GPU执行读取操作)与FPGA到GPU的间接通信效率相比降低了20.52%。
在编写驱动程序时,主控写入的PCIe协议开销较低。所以,在GPU到FPGA的传输路径中,GPU作为总线主控器,当数据从GPU传输到FPGA时,GPU启动写入操作请求,FPGA可以全速(3.41 GB/s)接收写入操作的请求。反之,数据从FPGA传输到GPU时,GPU发起读取请求,但是在FPGA中读取数据导致了额外的PCIe协议开销,所以实现的传输效率较低(2.40 GB/s)。
GPU-CPU传输中同样体现出这样的不对称特性。在GPU到CPU的传输中,GPU作为主控器启动总线写入操作请求,最大速度为14.2 GB/s, 反之,GPU启动总线申请读取,最大速度降至12.1 GB/s。在PCIe通信中,由于协议开销和实现机制复杂,总线主控写入操作通常比读取操作效率更高。共享内存中解决这种问题的另一种方法是使用CPU作为主控器主控写入操作实现CPU到GPU的数据传输,但这样做会比本文方法产生更多的硬件开销。同时,本文实现GPU到FPGA的直接通信并不仅仅是因为读写操作效率问题,更为严峻的问题是在整个异构系统中PCIe是通信中枢,当同时处理大量数据并且系统并行程度非常高时,间接通信需要经过2次PCIe,占用大量带宽,导致通信阻塞,而直接通信会大大降低PCIe的占用率。
6 行人检测应用
本文选择了fastHOG+SVM的行人检测应用作为GPU-FPGA直接通信的测试程序。图11所示为fastHOG算法的流程。

Figure 11 Flow chart of fastHOG algorithm图11 fastHOG算法流程
在异构系统中进行算法设计首先要对不同任务进行分析,确定适合进行加速的计算单元,这有助于确定最有效的加速方案。文献[26,27]的研究表明了在FPGA中进行HOG计算是非常好的选择,同时,在本文的计算流程当中应该既包含GPU到FPGA方向的数据通信,又包含FPGA到GPU方向的数据通信,根据这2个原则本文确定了如图12所示的异构计算流程。
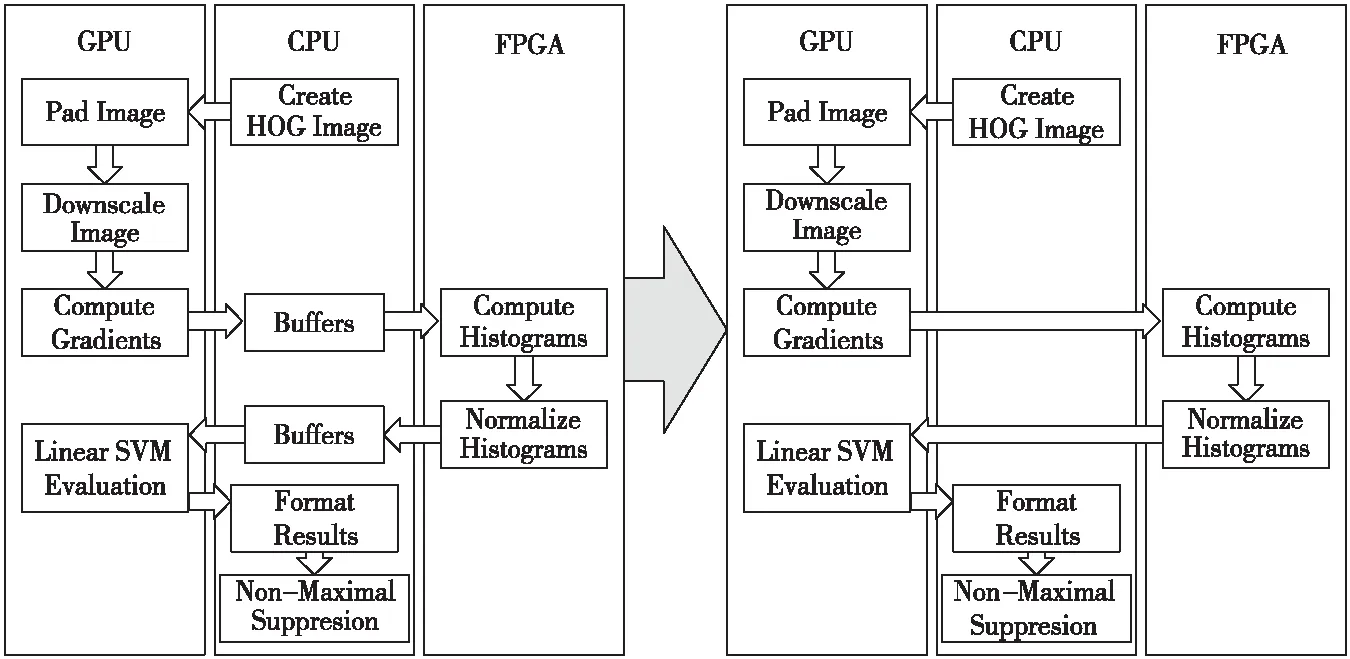
Figure 12 Data flow of person detection in heterogeneous图12 异构计算中行人检测数据流向
确定加速模块后将不同任务分配到不同计算单元就得到了异构环境下的算法流程和数据传输过程,首先摄像头从包含用户行人的场景中捕获到原始的视频数据。摄像头通过USB连接到异构系统,视频数据首先传输到CPU的DDR当中,经过CPU解码处理后,根据需求创建HOG图像,再传输到GPU的内存。GPU进行图像缩小、梯度计算、SVM等计算,将得到的处理结果经过PCIe直接传输到FPGA,然后FPGA进行直方图计算与标准化,最终将结果传输到CPU再进行标准化输出。
为了使直接和间接路径之间的性能比较更有说服力,本文使用相同的算法对相同的数据进行处理,采用相同传输路径,数据传输的起点和终点都是CPU的DDR,这样能够排除其他因素的影响,获得更精确的测量结果。如图12所示,左侧为使用间接GPU-FPGA通信机制的流程,右侧为使用直接GPU-FPGA通信机制的流程。本文将对2种情况进行实验对比。

Figure 13 fastHOG communication delay图13 fastHOG通信延迟
本文统计了程序运行中的数据传输时间,平均了处理300帧图像后的结果。各计算单元之间的传输延迟如图13所示。图13中位于上方的路径是间接传输的结果,间接传输时数据经过GPU-CPU-FPGA的路径通过CPU的内存作为媒介进行数据传输。图13中位于下方的路径是直接传输的结果。2种机制下其传输延迟总耗时平均值分别为263 μs和151 μs。因此,在闲置情况下,最佳的应用程序加速比可能是1.74倍。随着GPU和FPGA处理时间的增加,加速比会降低,并且在本实验中,GPU和FPGA的处理时间在5~20 ms,整个应用程序可以得到15%~20%的性能改善。
7 结束语
本文提出了一种基于状态变迁矩阵(STM)的编程框架,利用CUDA和Vivado提供的端口对GPU和FPGA资源进行了集成。而且通过STM自动生成异构计算所需要的标准C代码同时可以进行形式化验证,既保证了算法的性能,又提高了异构环境的易用性。本文还通过PCIe实现了GPU-FPGA直接通信的机制,同时分析了其性能特征,并且通过实现FPGA和GPU均可以作为主控器,在通信过程中仅使用写入操作来提高PCIe通信的效率。本文使用行人识别算法fastHOG作为案例进行研究,使用GPU始终作为主控器的GPU-FPGA直接通信的机制,数据传输效率与基于共享内存的间接通信方式相比提高了35%;实现使用FPGA作为主控器的GPU-FPGA直接通信的机制优化FPGA到GPU的数据传输效率后,异构平台的整体通信效率进一步提高了20%。希望本文工作能为异构计算和体系结构的发展做出一定贡献。
虽然本文使用专业级显卡解决了FPGA到GPU传输的瓶颈,但是显然这样的成本不是所有人都可以承担的。因此,随着后续各种工具的开发,希望可以使用消费者级的GPU来实现FPGA到GPU的传输带宽增长。更进一步将本文工作融入OpenCL,将这种方法移植到非NVIDIA的GPU与FPGA的通信当中。同时,希望在今后异构计算的研究中不断有更多的研究人员和厂商加入,提供更多的技术支持。另一方面本文已经使用计算机视觉方面的应用程序作为案例进行了异构计算加速性能的研究,下一步希望能应用在神经网络训练和匹配中。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
当代陕西(2019年13期)2019-08-20
测控技术(2018年6期)2018-11-25
测控技术(2018年8期)2018-11-25
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
电脑爱好者(2015年21期)2015-09-10
电子设计工程(2015年8期)2015-02-27
河南科技(2014年16期)2014-02-27
