
铁路软件可靠性增长模型应用研究
2021-05-10 13:39李红辉管军霖江周娴
铁路计算机应用 2021年4期
李红辉,赵 森,管军霖,江周娴
(1. 北京交通大学 计算机与信息技术学院 高速铁路网络管理教育部工程研究中心,北京 100044;2. 桂林电子科技大学 计算机与信息安全学院,桂林 541004)
列车在运营过程中高度依赖软件的可靠性,如果软件瘫痪甚至出现一个小故障,造成的后果可能都是灾难性的[1]。目前,我国列车主要采用按运行里程计划维护的策略,运营和维护费用较高[2],对于突发性或紧急事件的响应效果也比较差,严重时会造成重大经济损失和人员伤亡。
软件可靠性增长模型(SRGM,Software Reliability Growth Model)用于软件可靠性的评估和预测[3]。利用SRGM 对铁路软件进行可靠性预测,能提前预知故障的发生时间,不但能有效帮助铁路企业控制成本,还能更好地保证行车安全。目前,公开发表的SRGM 有100 多种,它们的基本假设条件不同、考虑的因素不同,适用性也不同,因此,用它们估测同一款软件,所得结果可能差异较大。选择或设计合适的评估模型、有效进行铁路软件可靠性评估是目前亟需研究的问题。
邢颖[4]等人讨论了铁路软件可靠性测试关键技术及软件可靠性模型,但未针对铁路软件失效数据集进行实验。潘浪涛[5]建立了一个铁路自动售票系统的可靠性分析模型,总结了系统可靠性与系统模块失效概率之间的关系,但是,对模型的普适性未进行说明。廖亮[6]等人基于非齐次泊松过程(NHPP)对处于开发后期阶段的铁路信号计算机联锁软件进行可靠性评估,但未用NHPP 模型与其它SRGM 作对比。
本文选取G-O 模型、Delayed S-shaped 模型、Ohba-Chou 模型及P-N-Z 模型[7]4 个较经典的SRGM,分析它们的特点及适用场景,提出一种可靠性模型参数计算的优化算法,在此研究基础上开发了一款软件可靠性增长模型分析工具(SRGM Tool)。以铁路联锁软件为例,研究软件可靠性增长模型应用方法,确定了适合被测软件的可靠性增长模型,验证了方法的有效性。
1 SRGM 简介
SRGM 是在软件失效数据集的基础上,采用统计学方法,用数学方程式来表达软件错误数量与不同因素(时间、测试工作量、不完美排错及错误检测率等)之间的关系。一般而言,随着软件中错误的排除,软件中累计错误数量增长速度变慢,即软件的可靠性逐渐增强。SRGM 是对软件可靠性增长趋势进行建模,该趋势可用随机变量分布描述,建模过程中提出基本假设,同时,引入与该趋势相关的参数。
设m(t)表示t时刻累计错误数量的函数,a(t)为软件总错误量,b(t)为错误检测率,t> 0。
文中,假设所研究的模型均符合以下条件条件:累计检测到的错误数量变化率(dm(t)/dt)与当前错误检测率(b(t))条件下剩余的错误数量(a(t)-m(t))成正比,可用式(1)表示:
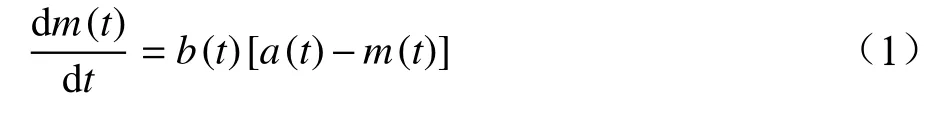
1.1 排除错误类型
针对SRGM,假设发现错误,在排除错误时,如果错误可以完全被改正,且不会引入新的错误,称为完美排错;如果在排除一个错误时引起其它错误,则称为不完美排错。
1.2 4 种SRGM
1.2.1 G-O 模型
G-O 模型的假设条件较理想化,在数学表达上较简单,假设总错误数量与错误检测率恒定,即:

属于完美排错型。
1.2.2 Dealyed S-shaped 模型
该模型考虑了延迟效应,开始时增长比较慢,然后增长迅速,直至到达峰值,所以其可靠性增长曲线是一个呈S 型的曲线。假设总错误数量恒定,但错误检测率考虑延迟效应,函数表达为:

同样属于完美排错类型。
1.2.3 Ohba-Chou 模型
该模型在G-O 模型的基础上改进,考虑排除错误时有可能引入新的错误,假设在排除错误时引入新错误的概率与t时刻检测到的错误数量成正比,比例系数为r,且r< 1,则a(t)、b(t) 可表示为:
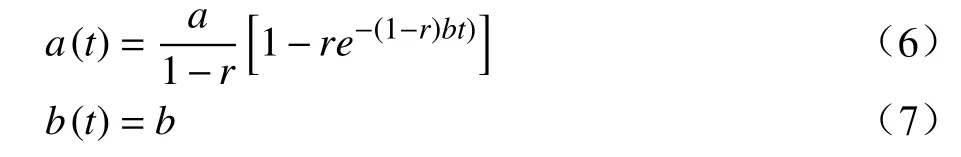
1.2.4 P-N-Z 模型
考虑测试人员学习能力对失效过程的影响。a(t)增加,意味着错误总数增加,排除错误过程不完善;错误包括已检测和排除的错误,以及在排除错误过程中引入的错误。b(t) 增长,意味着错误检测率增大,测试人员学习能力提升。设α为引入错误率参数,β为拐点因子,a(t)、b(t)可分别表示为:

1.3 模型对比分析
4 种模型的对比分析见表1,从表中可以看出4种模型的差异,主要体现在a(t)和b(t)的不同,使得各模型的适用场景也不同。
2 可靠性增长模型评价指标
本文采用拟合与预测效果相结合的方法衡量4个模型的优劣。

表1 4 种模型的对比
2.1 拟合效果评价指标
拟合效果即拟合数据与真实数据的吻合程度,本文选取均方误差(MSE)和拟合优度(R-Square)两个指标进行评价。
2.1.1 MSE
MSE 可以反映模型拟合出的数据与真实数据的差距,计算公式为:

式中,EMSE为均方误差值,yi为真实失效数据,m(ti) 为拟合数据。EMSE值越小,说明拟合数据与真实数据差距越小,拟合效果越好。
2.1.2 R-Square
与MSE 相似,同样可以用于评估模型的拟合效果,计算公式为:
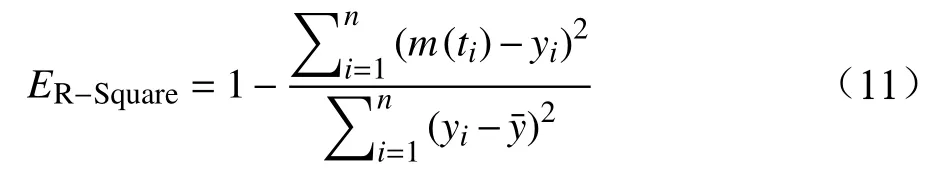
式中,ER−Square为拟合优度值,m(ti) 为ti时刻累计错误数量的拟合值,yi为ti时刻累计错误数量的真实值。
R-Square 的值越接近1,说明拟合数据与真实数据越接近,拟合效果越好。
2.2 预测效果评价指标
相对误差(RE)[8]根据记录到的失效数据预测未来失效发生的趋势,从而评价模型的预测效果,可通过计算数据集中所有记录的RE 值来表达,计算公式为:

式中,ERE为相对误差值,根据此值绘制模型的RE 曲线,RE 值越小,说明该模型的预测结果具有更小的误差,预测性能更好。
3 软件失效趋势分析方法
软件失效数据集包含记录时间、累计错误数量等,可借助可视化方法对其可靠性增长趋势进行初步分析。常用的趋势分析方法包括图形法、拉普拉斯法、曲线图技术、数据建模技术等,不同失效数据分析技术具有各自的使用场合和优势。本文采用图形法和拉普拉斯法分析软件失效数据集的可靠性增长趋势,用可视化方法更方便地观测软件失效数据集的发展趋势,以便选择合适的可靠性模型。
3.1 图形法
图形法比较直观,主要对软件运行时间、累计失效数等各种变量之间关系进行分析。
横轴表示时间ti;
纵轴表示累计错误数量m(ti),即ti时累计故障数量。
用描点法绘制折线图,若折线图呈现凸出状态,可 以认为可靠性在增长,否则认为可靠性在下降。
3.2 拉普拉斯法
拉普拉斯法[9]是把软件失效数据集采集数据的时间划分成n个等长的单位时间,在第i个单位时间中记录到的错误数为n(i),拉普拉斯法表达式为:
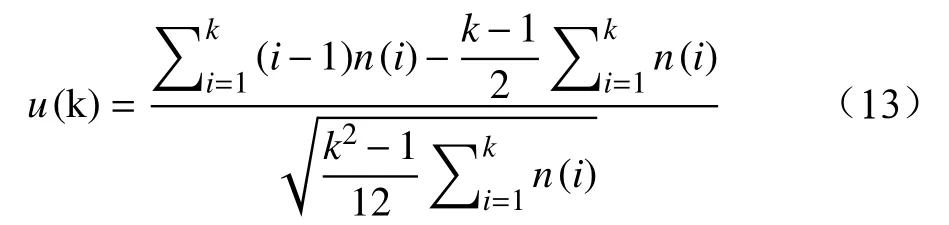
式中,u(k) 为第k个记录的拉普拉斯因子,k=1, 2, ···,n,以时间顺序观察拉普拉斯因子值,若拉普拉斯因子值减小,说明失效强度降低,则软件可靠性逐渐增强。
结合图形法和拉普拉斯法两种方法,可以得到软件失效数据集的可靠性增长趋势。
4 参数计算及算法优化
4.1 参数计算
计算SRGM 中的参数(即a、b、r、α、β),需要在软件失效数据集的数据上进行参数计算,将得到的参数值代入模型,计算出拟合数据,与软件失效数据集进行拟合。
4.2 算法优化
本文参数计算采用极大似然估计法,将软件失效数据集代入模型,给出参数值的初始化值和范围,通过设定的步长逐个枚举参数值,求MSE 值,输出得到最优MSE 值时的参数值。为减少计算时间,在实验过程中将范围和步长设置大一些,以快速获知参数的最优值所在的范围,然后逐步缩小范围和步长,计算出精确的参数值。
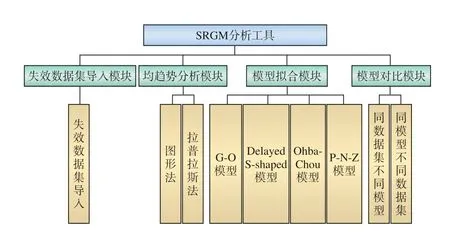
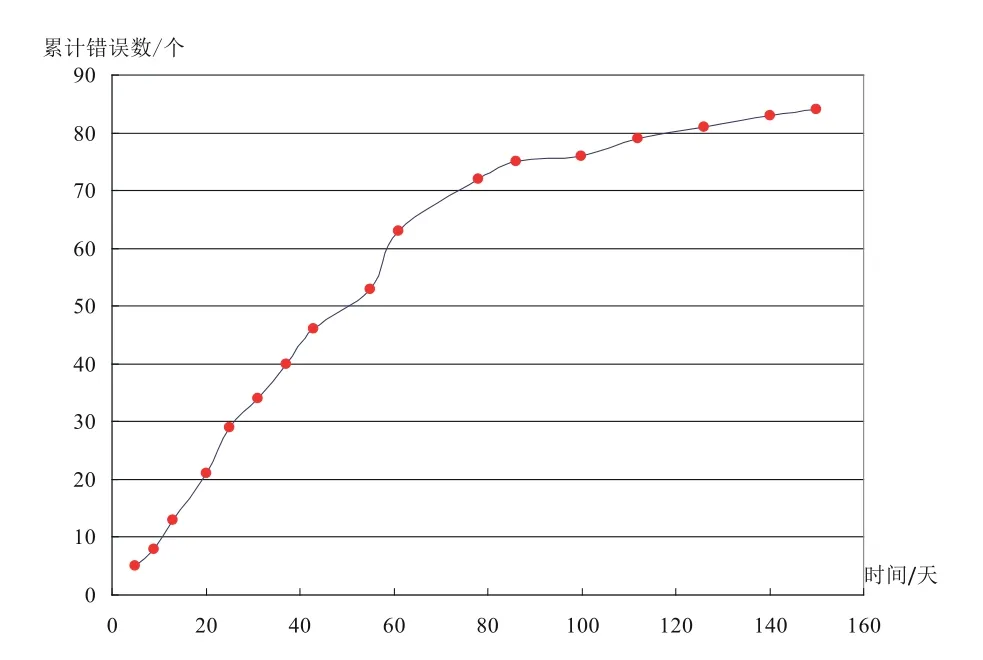
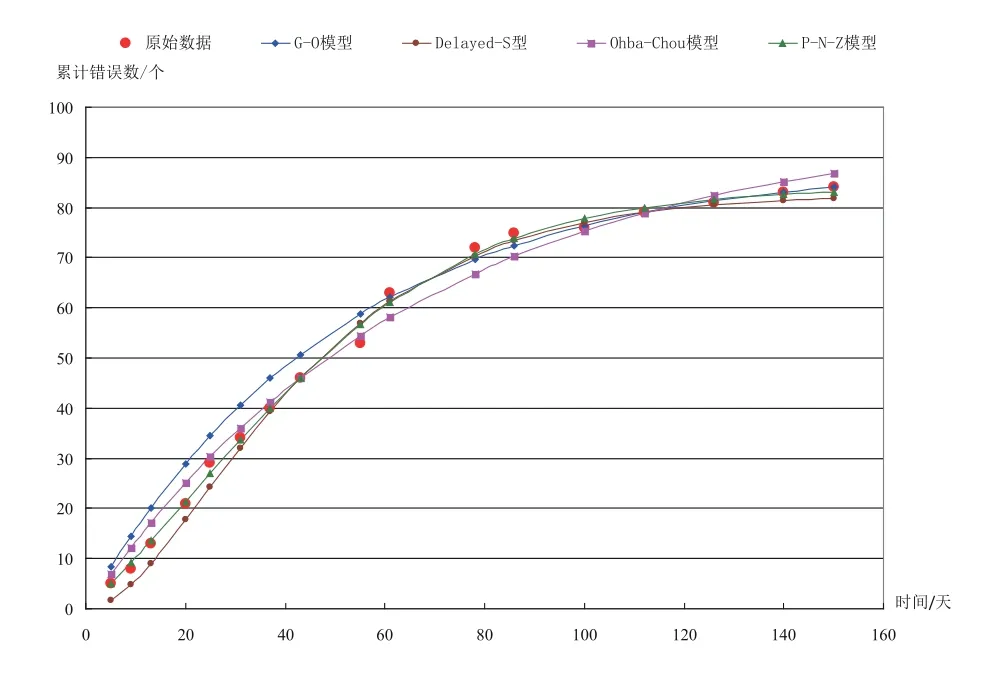
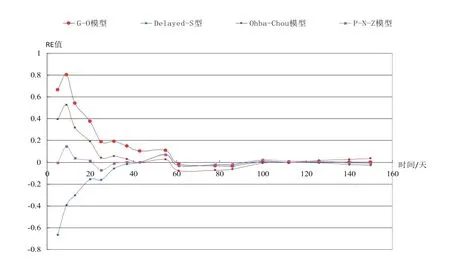
在实验过程中发现,用软件失效数据集全部数据得到的模型参数,生成的拟合数据与真实值的误差较大。在几个软件失效数据集中进行大量实验,使用数据集的前一部分数据进行参数计算,后一部分数据用于验证,结果表明,使用部分数据进行参数计算和MSE 值计算,所得的MSE 值优于使用全部数据进行相关计算得到的MSE 值。因此,改进了参数计算算法,使用前i(n/2 图1 参数计算的优化算法流程 在上述理论研究和优化算法的基础上,基于Java 语言,设计并开发了一款SRGM Tool,该工具可在个人计算机Web 端使用:导入软件失效数据集,计算得到模型参数,进行可靠性分析,辅助完成可靠性模型的选择。 SRGM Tool 的功能模块包括:软件失效数据集导入,可靠性趋势分析,可靠性拟合和预测,不同模型的效果对比,如图2 所示。 图2 SRGM Tool 功能模块示意 (1)软件失效数据集导入模块:选择一个数据集导入SRGM Tool 中,为趋势分析和模型的拟合做准备。 (2)趋势分析模块:分析失效数据集趋势,利用图形法和拉普拉斯法对可靠性增长趋势进行刻画,得到所选数据集的可靠性增长趋势。 (3)模型拟合模块:在所选软件失效数据集的基础上,根据模型的均值函数和参数值,计算得出拟合值,将它们与软件失效数据集的数据进行拟合,在同一坐标系中展示结果,并计算相应的评价指标值(MSE 值、R-Square 值、RE 值)。 (4)模型效果对比模块:支持同数据集不同模型的对比、同模型不同数据集的对比。其中,同数据集不同模型的对比,在同个数据集上进行拟合,绘制所有模型的曲线;同模型不同数据集的对比,在3 个数据集上进行拟合,展示3 个拟合图形。 为了对铁路软件进行准确估计,需要真实的铁路软件失效数据集,保证数据的真实性、准确性及完整性。本文在进行模型对比实验验证时选取了铁路计算机联锁软件的失效数据集,该数据集以《计算机联锁技术条件》为标准判断软件是否出错,软件运行半年,共采集了17 组失效数据,每组数据记 录了测试的时间和累计错误数量。 在SRGM Tool 上,以铁路计算机联锁软件的失效数据集为例开展实验。 (1)导入软件失效数据集,进行可靠性趋势分析,将计算得到的结果绘制成图形。 (2)计算模型参数,得到参数后,利用可视化方法展示各模型与铁路软件失效数据集的拟合效果,同 时,计算、展示可靠性评估的指标值。 5.3.1 软件可靠性增长趋势分析 运用图形法得到的结果如图3 所示,运用拉普拉斯法得到的结果如图4 所示,两种方法所展现的效果基本一致,曲线斜率总体上随时间变化逐渐减小。拉普拉斯法中,总体上数值在减小。第9~第78 天期间出现了波动,局部可靠性下降,但该软件失效数据集总体上呈可靠性增长趋势。 图3 软件可靠性增长趋势结果(图形法) 对于铁路软件失效数据集进行初步的可靠性增长趋势分析后,可根据该数据集的趋势特点选择合适 的模型进行验证,本文利用4 个模型进行对比验证。 5.3.2 模型拟合对比 利用改进的参数计算方法,多次试验发现,运用前14 组数据计算参数,得到的MSE 值最小,即拟合效果最好,因此,选择前14 组数据得到的参数组合作为最终采用的参数数值,以达到更好的拟合效果,同时,选择第15~第17 组数据作为验证数据。 图4 软件可靠性增长趋势结果(拉普拉斯法) 将铁路联锁软件失效数据集运用于G-O 模型、Delayed S-shaped 模型、Ohba-Chou 模型及P-N-Z 模型上,进行拟合测试,计算各模型引入参数的数值,绘制相应的拟合曲线,4 种模型的拟合结果在同一图形中进行对比,如图5 所示,图6 为相对误差曲线,表2 列出各模型的拟合效果评价指标值。 图5 拟合结果图形对比 图6 各模型相对误差曲线 结合实验结果,可以得到以下结论: (1)图5 中,第1~第14 组数据作为拟合数据,第15~第17 组数据作为验证数据。从图中可以看出,拟合数据中,P-N-Z 模型与数据集数据的拟合优度最好;而验证数据中,G-O 模型的拟合效果则更好一些,但是总体上P-N-Z 模型的效果最优。从图6 的相对误差曲线也可以得到同样的结论; (2)从图5 中可以明显地发现,Delayed S -shaped 模型在初始时增长缓慢,反映了模型的延迟效应,但是对于本文的铁路软件失效数据集,总体拟合效果较差,说明此数据集可能不存在排除错误延迟问题; (3)G-O 模型拟合和预测效果均为4 个模型中最差的,Ohba-Chou 模型在该数据集上拟合较好,从量化指标来看差距较小,原因为Ohba-Chou 模型是在G-O 模型基础上考虑新引入的错误数与纠正的错误数成正比,比较理想化,所以Ohba-Chou 模型较G-O 模型有改进,但是改进不大; (4)从表2 中可以看出,对于该联锁软件的失效数据集来说,P-N-Z 模型的拟合优度最好,若用于实 际生产中,该模型是最佳选择。 本文对铁路软件可靠性模型应用方法进行了研究,利用4 种可靠性增长模型,对铁路软件进行可靠性增长趋势分析和可靠性评估预测,提出了一种可靠性模型参数计算的优化算法,并通过实例给出铁路联锁软件可靠性模型分析和预测的方法,可为铁 路领域其它软件的可靠性分析和预测提供参考。 每个可靠性模型都有其适用的失效数据集和场景,具体情况应结合实际应用进行分析。对于本文实验中的铁路联锁软件失效数据集而言,P-N-Z 拟合效果最优。 在铁路领域其它软件的实际使用中,可结合收集到的软件失效数据集,与各个模型相结合,考察模型的拟合优度和预测效果,结合MSE 和R-Square等指标,进行综合比较,最终选择更适合其失效过程的模型,预测下次失效的时间或发生错误的频率,提前做好排除错误计划和相关措施,从而保障铁路运营和维护安全,最大限度地减小因软件失效带来的经济损失。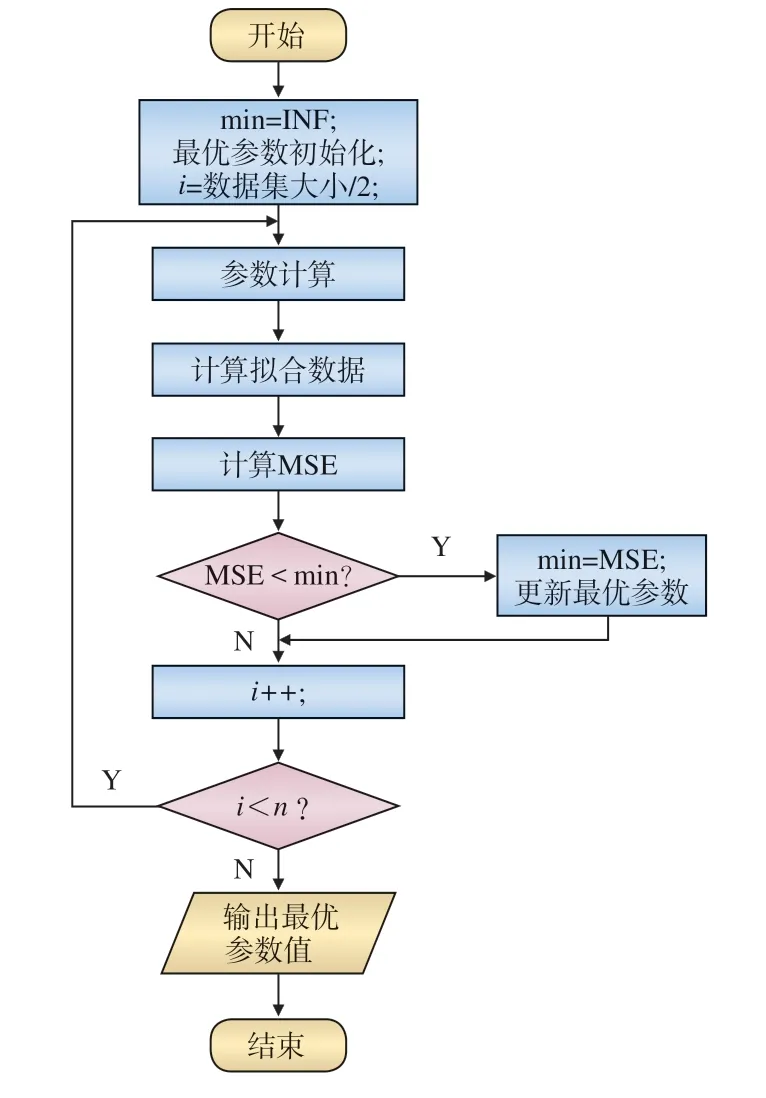
5 可靠性分析工具及实验分析
5.1 SRGM Tool
5.2 铁路软件失效数据集
5.3 实验

5.4 结果分析
6 结束语
猜你喜欢
金桥(2022年10期)2022-10-11
北京航空航天大学学报(2022年6期)2022-07-02
小天使·一年级语数英综合(2022年2期)2022-03-30
汽车实用技术(2022年4期)2022-03-07
建材发展导向(2021年15期)2021-11-05
现代仪器与医疗(2021年1期)2021-06-09
云南画报(2021年12期)2021-03-08
云南画报(2021年12期)2021-03-08
电子制作(2019年24期)2019-02-23
人生十六七(2015年29期)2015-02-28
