
基于车流径路选择偏好的铁路车流运行径路动态预测方法研究
2021-05-10 13:39:52张红斌金福才
铁路计算机应用 2021年4期
张红斌,李 军,金福才
(1. 北京经纬信息技术有限公司,北京 100081;2. 中国国家铁路集团有限公司 调度指挥中心,北京 100844;3. 中国铁道科学研究院集团有限公司 电子计算技术研究所,北京 100081)
提高日班计划编制质量,是充分利用运输能力,提升运输组织效率,保障高质量完成运输任务的重要手段,而准确的车流预测是编制高质量日班计划的前提条件。
关于车流径路的研究主要考虑路网运输方案[1]、空车调整方案[2]等,在推算车流径路时主要使用最短路径、次短路径或K 条最短路径计算方法。目前,铁路运输径路计算机处理系统是铁路部门一个重要的车流径路推算工具,为铁路运输计划管理、车流组织、运费计算以及收入清算提供支持[3-5]。在实际运输生产过程中,由于受到施工、通过能力、机车(车务组)分配、自然灾害、事故等多种因素的影响,经常会发生车流迂回运输[6]。在选择车流迂回径路时,需要考虑多种因素:迂回径路的通过能力、迂回径路的长度、迂回径路上的牵引方式[7]等。若依据实际运输需求、路网能力制约以及迂回运输选择条件等因素,对全路网货运车流径路建模和预测,无疑是一项十分复杂的任务。为此,考虑利用运输信息集成平台提供的货运车流海量历史轨迹和实时位置追踪数据,提出一种基于车流径路选择偏好的铁路车流运行径路动态预测方法。
1 基于车流径路选择偏好的铁路车流运行径路动态预测方法
中国国家铁路集团有限公司(简称:国铁集团)于2013 年建成运输信息集成平台,实现对列车、车辆、货物、机车、机车乘务员位置与状态的实时掌握与动态追踪[8];货运列车在装、卸、技术作业等关键环节均会产生报告信息,可以较为准确地掌握货运列车动态信息,结合列车编组信息,以车号、起讫点、途径站为线索,进而可获得货运车辆的动态运行轨迹。
1.1 车流径路选择偏好概念简介
针对车流运行径路历史数据的统计,提出长期和近短期车流径路选择偏好的概念;其中,长期车流径路选择偏好是过去较长时间内货运车流运行径路的大概率选择,反映长期货物运输运输组织策略影响下,对货运车流不同运行径路的优先选择;近短期车流径路选择偏好则是近短期内货运车流运行径路的大概率选择,可反映车流受到现阶段施工、线路运输能力等因素影响,对货运车流不同运行径路的优先选择,对于预测当前车流运行径路具有较好的参考价值。在预测车流运行径路时,优先使用近短期车流径路选择偏好,只有在近短期车流径路选择偏好数据缺失的情况下,才考虑采用长期车流径路选择偏好。
1.2 车流径路选择偏好参数统计方法
列车动态位置信息主要包括列车到达与出发报告,是由列车运输途中重要节点站上报的列车到发信息。如图1 所示,列车在始发站A、技术站B、C和终到站D,都会上报列车到发信息。结合列车编组信息,可以得到车辆运行动态信息,包含车号、始发站、当前站、终到站、货物品类等信息项;汇总某个车辆的到发信息,以车号、起讫点、货物品类为索引,即可以获得该车辆的完整运行轨迹。

图1 运输信息集成平台中车辆运行径路构成示意
假设车流从始发站A 运行到终点站D,可有2条运行径路:A—B—C—D 和A—B—E—D;利用车流长期历史数据,对10 000 辆车辆运行径路进行统计,发现其中80%车辆的走行径路为A—B—C—D,20%车辆的走行径路为A—B—E—D;利用车流近短期历史数据,对100 辆车辆的走行径路进行统计,发现其中60%车辆走行径路为A—B—C—D,40%车辆走行径路为A—B—E—D,可得到如表1 所示的车流径路选择偏好参数表。
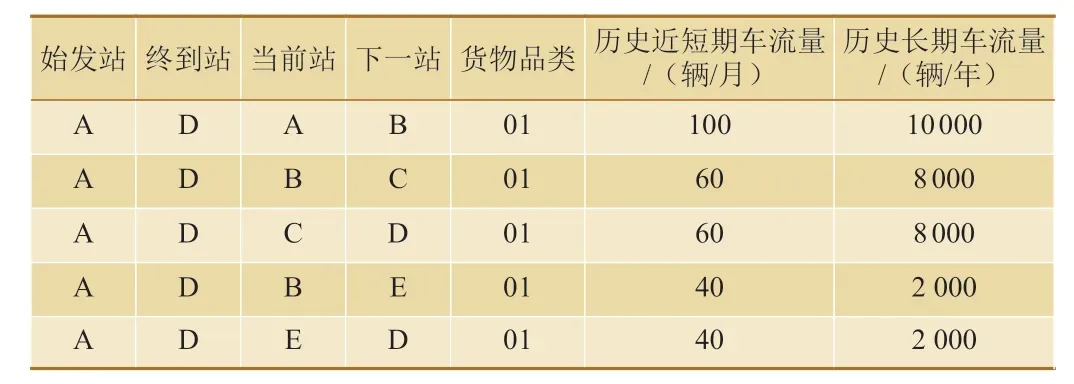
表1 车流径路选择偏好参数表
1.3 车流运行径路动态预测算法
通过实时获取运输信息集成平台提供列车到发报告信息,将其转换成车辆运行动态信息,结合基于车流历史数据生成的车流径路选择偏好参数表,设计货运车流运行径路动态预测方法,具体算法步骤如下:
(1)根据车辆的始发站、当前站、终到站和货物品类信息,在车流径路选择偏好参数表中查找对应的车流径路记录;若查找不到对应的车流径路记录,则结束查找,使用默认的车流径路计算方法确定车辆运行径路;若找到,则转到步骤(2);
(2)检查所有查找到的车流径路记录中的近短期车流量数据项是否为空;若不为空,选择近短期偏好概率最大的车流径路记录;若为空,则选择长期偏好概率最大的车流径路记录;将所选择车流径路记录中的下一站设置为预测站;
(3)判断预测站是否为终到站,若是,则结束搜索;否则转到步骤(4);
(4)将预测站设置为当前站,转到步骤(1)。
2 车流径路预测大数据应用环境与数据处理流程
2.1 车流径路预测大数据应用环境
全路现有货运车辆80 多万辆,每日有50 多万辆货车的动态信息上报,日均上报数据量约为300 万条,车辆历史轨迹数据累计约为20 亿条。为便于分析海量的车辆历史轨迹信息,提高车流径路预测应用的数据处理性能,搭建车流径路预测大数据应用环境,其架构如图2 所示。
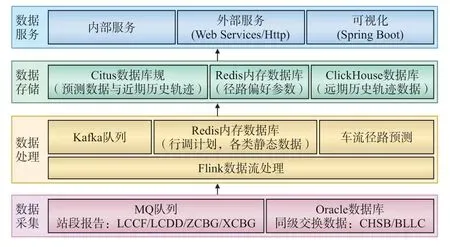
图2 车流径路预测大数据应用环境架构示意
数据采集层通过MQ 消息接收与数据库同步2种方式获取车辆最新动态信息,解析后写入Kafka 消息队列;数据处理层使用Flink 组件调用预测程序,动态预测车流径路;数据存储层使用Redis 数据库存储车流径路选择偏好参数表,Citus 数据库存储动态预测的车流径路与近期车流轨迹历史数据,Click-House 数据仓库存储较长时间之前的海量车流轨迹历史数据;数据服务层基于WebServices/Http 等协议提供数据查询和计算服务,使用SpringBoot 微服务架构实现数据可视化展示。
2.2 车流运行径路预测数据处理流程
车流运行径路预测的数据处理流程如图3 所示,其中,黄色部分为车流径路选择偏好参数更新流程,其余部分为车流运行径路动态预测流程。
对车流径路选择偏好参数的动态更新,是通过将存储在运输信息集成平台Oracle 数据库中的车流历史数据定期同步到分布式实时分析数据库Citus,再调用车流径路选择偏好参数计算程序定期更新该参数表;该参数表保存在内存数据库集群Redis 中,便于车流运行径路动态预测程序快速读取表中的参数。
在车流运行径路动态预测流程中,从运输集成平台的MQ 队列中实时读取最新的车流装、卸和到发信息,转存到Kafka 消息队列集群中;使用Flink流式处理技术,解析Kafka 队列中的最新车流信息,通过Nginx 负载均衡(目的是为了防止并发调用Redis 时造成阻塞),读取存储在Redis 中的车流径路选择偏好参数表,生成预测的货车运行径路;最后,将预测结果存储到数据仓库ClickHouse 中,以供应用查询。
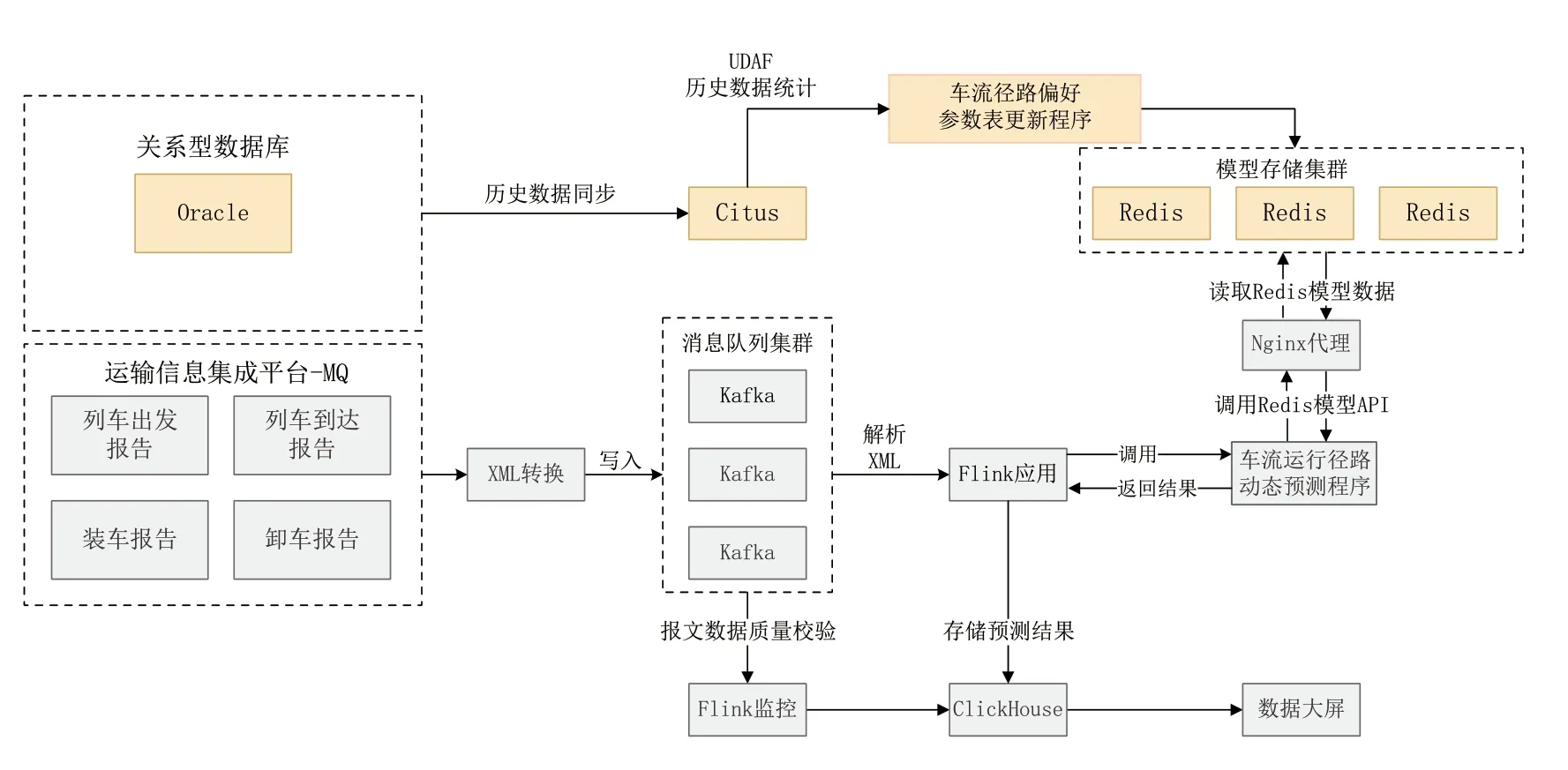
图3 车流运行径路预测数据处理流程
2.2.1 车流径路选择偏好参数更新流程
(1)车流历史数据存储在关系型数据库Oracle 中,每天定时将前一天的数据同步到分布式实时分析数据库Citus 中。
(2)利用自定义聚合函数(UDAF,User-Defined Aggregation Funcation),对同步过来的新增历史数据进行整合处理,包括车流运行径路合并、到发报告合并等。
(3)运行车流径路选择偏好参数计算程序,完成车流径路选择偏好参数的更新计算,并用重新计算的参数更新Redis 集群中存储的车流径路选择偏好参数表,更新频次为每天1 次。
2.2.2 车流运行径路动态预测算法流程
(1)实时获取车流动态信息,包括列车出发报告、列车到达报告、装车报告、卸车报告、车号识别等(通过MQ 以XML 格式接入到车流运行径路实时预测系统的Kafka 消息队列中)。
(2)实时计算Flink 程序通过解析Kafka 中的XML 数据获取获取车辆的始发站、当前站、终到站和货物品类等关键信息,调用车流运行径路动态预测程序,具体的算法流程参见图4,通过Nginx 负载均衡,调用Redis 模型接口,返回货车运行径路的预测结果。
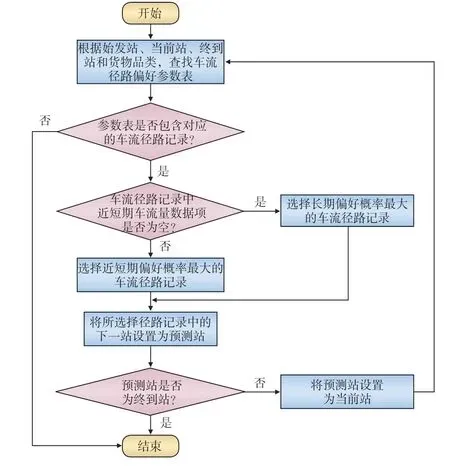
图4 车流运行径路动态预测算法流程
(3)将预测结果数据和报文数据质量校验数据存储在数据仓库ClickHouse 中,以服务形式提供数据访问及数据可视化展示。
3 预测效果评价
该预测方法已在武清数据中心应用,迄今为止车流径路选择偏好参数表已累计生成1500 万条记录,每日增量约为2 万条,可以覆盖全路大多数车流运行径路。为了评价本文提出铁路车流运行径路动态预测方法的效果,定义预测命中率和准确率2 个统计指标。
预测命中是指可根据车辆当前位置准确预测车辆即将到达的下一个车站,命中率H用于衡量单次径路预测的结果准确性,其计算公式为:

式中,T表示统计时间范围,Pt表示某预测时段t内完成车辆下一站预测的频次,Rt表示此预测时段t内准确地完成下一站预测的频次。
预测准确性是指车辆从始发站到终到站的运行径路上的所有车站都能被准确地预测,准确率K用于衡量车辆全程径路预测的准确性,其计算公式为:

式中,T表示统计时间范围,Dt表示某预测时段t内所有终到车辆的辆数,Ωt表示这些终到车辆中全程运行径路预测均正确的辆数。
在目前的实际应用中,全路每天大约有16 万辆车到达终到站,发生约300 万次车辆运行径路更新。根据2020 年11 月的数据统计,预测命中率为83%,准确率为72%,基本达到实用水平。
图5 展示了新丰镇—城厢某品类车流的长期径路选择偏好,可以看出:从新丰镇出发,车流以92%概率直接运行到安康东;车流在安康东会以59%较大概率一站运行至广元西。在车流运行过程中,如果系统动态检测到某车辆运行至达州,那么该车辆的后续运行径路就会根据预测结果,动态修正为“达州—广安—内江”方向。
4 结束语
利用运输信息集成平台提供的海量车流运行轨迹历史数据,提出一种简单易行的铁路车流运行径路动态预测方法;通过对长期和近短期车流运行轨迹历史数据的统计,生成车流径路选择偏好参数,可等效反映路网中多种复杂因素对于车流径路的影响;基于车流径路选择偏好参数,结合货运车辆实时位置跟踪信息,动态预测货运车辆运行径路;搭建大数据应用环境,完成预测程序的开发与部署,采用命中率和准确率2 项指标,对该方法的准确性和实用性进行评价,结果表明:预测结果准确性较高,具有较为满意的实用价值。
目前,车流径路选择偏好参数表可以覆盖全路92%车流运行径路,但存在部分径路找不到终到站或者出现回路,从而导致车流径路搜索失败,这类错误与运输信息集成平台的数据质量有关。后续需要进一步研究如何对参数表数据进行修正,如将终到站数据缺失的记录用临近站近似替换填充,对出现回路的径路进行甄别并剔除折返通路,提高车流径路选择偏好参数表的覆盖范围和准确性,进而提高车流运行径路动态预测的准确性和效率。
猜你喜欢
计算机应用与软件(2021年12期)2021-12-14 01:28:30
智能制造(2021年4期)2021-11-04 08:54:36
河北电力技术(2021年2期)2021-07-29 09:16:24
心电与循环(2020年6期)2020-12-18 12:40:38
铁道通信信号(2018年7期)2018-08-29 01:16:58
汽车实用技术(2018年3期)2018-03-06 04:28:16
电力安全技术(2017年6期)2017-07-31 18:47:06
电脑知识与技术(2017年16期)2017-07-14 13:46:17
新课程·下旬(2016年12期)2017-06-07 11:32:21
电信科学(2016年11期)2016-11-23 05:07:37
