
基于流行度和CDT的NDN名称查找方案*
2021-05-08 06:10:16江凌云
通信技术 2021年4期
张 进,江凌云
(南京邮电大学,江苏 南京 210003)
0 引言
命名数据网络(Named Data Networking,NDN)[1-2]不是像TCP/IP基于目的地址转发数据包,而是基于数据名称。其中名称采用类似URL的层次化结构,便于流量多路分解,为数据的使用提供上下文信息。在NDN中,路由转发过程中转发信息表(Forwarding Information Base,FIB)的名称查找同样支持最长前缀匹配,但与TCP/IP的最长前缀匹配有两个实质性的区别[3]。首先,NDN名称是由“/”分割的各个名称组件组成的,需要将名称组件看成一个整体进行匹配。而IP地址可以在任何二进制位匹配前缀。其次,IP地址是固定长度的,NDN名称长度是可变的,没有明确的上限。这就造成相比传统的TCP/IP中的路由表条目,NDN中FIB的名称条目会呈现指数级爆炸性增长。于是,在如此庞大的FIB表中快速、准确地命中兴趣包中的名称条目,减少FIB的占用内存成为一个亟需解决的问题。现有的名称查找改进方案尚不成熟,例如基于FIB表拆分的名称查找方案专注于FIB表的拆分,不考虑底层数据结构,基于底层数据结构的一些名称查找方案采用的底层数据结构还具备改进空间。针对以上缺陷,提出了一种基于流行度和CDT的NDN名称查找方案。
1 相关工作
针对NDN中FIB条目的数量级大、层次化名称的查询效率低等问题,专家和学者提出了一些名称查找方案,主要分为3个方面:基于底层数据结构的名称查找方案、基于FIB表拆分的名称查找方案、基于查找方式的名称查找方案。
1.1 基于底层数据结构的名称查找方案
FIB的底层数据结构是一个研究热点,许多专家和学者致力于研究采用何种数据结构可以在减少FIB内存占用的同时加速NDN的名称查找速度。所提出的方案采用的数据结构主要包括hash表、前缀树、布隆过滤器等,具体如下。
Saxena等[4]提出了一种基于可扩展且高效存储的Patricia trie(前缀树)的名称转发方案,称为N-FIB。N-FIB将数据名称存储在Patricia trie中,同时在存储的过程中支持FIB聚合,以极大地减小大FIB和高FIB更新成本的影响。Kim等[5]提出了一种将hash表和Patricia trie相结合的名称查找方案。其中,hash表采用分层表,将层次化名称的每一级名称组件进行一次hash运算,并存储进Patricia trie中,这也就意味着每一级名称组件都包括一组hash表和Patricia trie。此方案可以有效地容纳可变的和无界的内容名称,加快了查找速度,但会加大内存占用。并且,以上两种方案没有将名称的流行度考虑进底层数据结构的设计当中。
Hao等[6]提出了一种新颖的名称查找机制(Bloom Filter+Popularity Table+Degraded Trie,BF-PDT),该机制结合了Counting Bloom Filter,Popularity table和Degraded Trie。当需要在FIB中检索名称条目时,首先在CBF中进行判断。如果CBF判断该条目在FIB中,则继续在流行度表(Popularity Table,PT)中搜索。PT记录了一些流行度最高的前缀信息。如果条目的前缀在PT中,则可以大大提高搜索速度。最后,在Degraded Tire(DT)中搜索条目。此方案考虑了名称流行度的影响,但其在流行度表中存储的是DT中节点的地址,还需要去DT进一步寻找下一跳信息,不能充分发挥流行度表的作用。同时,DT中一个节点只存储一个名称组件,是十分占用内存的。
1.2 基于FIB表拆分的名称查找方案
FIB表项数目在实际规模中会非常庞大,给名称查找带来很大的困难。但是将庞大的表拆分为不同的表,在这几张表中建立联系,会减少每张表的名称数量,从而提升名称查找的效率,以下的方案就是在这种思想下形成的。
Khelifi等[7]采用了一种“名称到哈希”编码方案。这个方案将每个名称组件分别进行哈希计算,使之成为固定长度。存储时将其切割拆分到两个表(hash表、前缀表)中进行存储,两张表中分别通过一个字段相连。然后执行启发式(类似Wu-Manber[8])的算法查找过程。将长度很大的hash值切割分散存储会提升名称的查找速度并具有良好的可扩展性。但是,此方案同样没有考虑名称流行度对FIB表拆分设计的影响。
Nguyen等[9]提出了SmartFIB方案,将FIB拆分为主FIB、eFIB,eFIB作为新路由的存储,主FIB作为高频路由的存储。当新路由在本地路由存储中不存在时,该路由首先进入eFIB,并且如果没有被兴趣包所请求,则可能会在eFIB的特征时间之后从eFIB中移出。主FIB用作高频路由的存储。高频是指流行前缀和具有重复路由请求的路由,可以利用eFIB来决定将哪些路由放入主FIB中。此方案着重考虑了名称流行度的影响,但其专注于FIB表的拆分,没有给出具体的底层数据结构方案。
1.3 基于查找方式的名称查找方案
NDN中默认是使用最长前缀匹配(Longest Prefix Match,LPM)的方式来将兴趣包中的名称与FIB中的名称条目进行匹配,如/school/library/book在FIB中可匹配/school、/school/library以及/school/library/book。而/school/library/book是最长前缀匹配。为了支持LPM匹配算法,名称查找从名称前缀的最长长度开始,并按组件粒度逐渐减小。该过程反复进行,直到找到LPM。但是,这种线性搜索方法不仅性能欠佳,而且安全性也不理想,n个组件的名称的不匹配兴趣包需要进行n次FIB查找。因此,一些专家和学者提出了改进这种查找方式的方案。
Yuan等[10]提出了将二分查找的思想应用到NDN名称查找的方案。令L和H为二分查找的上下限,而M=[(L+H)/2]为要查找的长度。命中时L=M+1,没有命中时H=M-1。利用二分查找的思想会使名称查找的时间复杂度从O(n)下降为Ologn。但是,为了保证二分查找的顺利进行,需要在FIB表中添加虚拟条目,这无疑会加大内存的占用。为解决这一问题,Hu等[11]对存入FIB中条目的长度(组件个数)进行了约束(可以为奇数、偶数或其他自定义长度)。对于FIB表中的真实条目,需要确保其所有长度在其范围内的名称前缀都插入FIB中。如果不存在相应的真实条目,则将虚拟条目作为填充插入以支持二分查找。此方案可以相对减少虚拟条目的数量以及内存占用,但查找速度相对会变慢。
总的来说,以上名称查找方案对FIB表的查找速度、内存占用都有一定的改进,但也存在明显的不足。例如,文献[6]在流行度表中存储的是名称前缀与前缀树中节点的地址相对应的关系,还需要进一步去前缀树中寻找具体的下一跳端口,并且其采取的DT是一个节点,只存储一个名称组件,这会加大DT中的节点数量,导致FIB占用的内存过大。文献[9]专注于FIB表的拆分,没有给出具体的底层数据结构方案。
2 基于流行度和CDT的NDN名称查找方案
针对上节中讨论的现有名称查找方案存在的一些缺陷,本节提出了一种基于流行度和CDT的NDN名称查找方案,该方案将FIB划分为计数布隆过滤器(Counting Bloom Filter,CBF)、流行FIB、CDT、辅助FIB这4个部分,如图1所示。
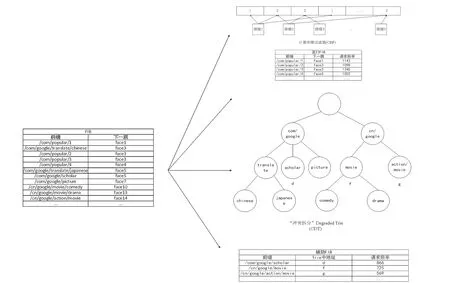
图1 FIB的构成
2.1 计数布隆过滤器(CBF)
布隆过滤器(Bloom Filter,BF)是一种节省空间的概率数据结构,初始状态下每个位置的值都为0。当向BF中插入元素时,会将元素用不同的哈希函数计算,映射到BF中的不同位置,并将相应位的值设置为1。当要在BF中检索是否存在某个元素时,使用与插入元素时相同的哈希函数进行哈希运算,只有所有位的值都为1时,才能证明此元素位于BF中,否则不存在。
计数布隆过滤器(Counting Bloom Filter,CBF)是对BF的改进,每个位置的值不再只是0或者1,当元素映射到某个位置时,会将元素的值进行加1,删除时会将元素的值减1。因此,CBF提升了准确度并支持了删除功能。与文献[6]一样,这里同样将FIB中的名称前缀映射进CBF中来判断某一名称前缀是否位于CBF中,从而及时过滤掉不存在的名称前缀,避免在后续数据结构查找中增加时间成本。只有在CBF中检测到此名称前缀,才进行后续操作。
2.2 流行FIB
流行FIB存储名称前缀与下一跳端口的对应关系,同时还存在一个隐藏列:请求频率。它会统计规定的时间段内此表中的名称前缀被请求的频率次数,根据阈值来判定其是否属于高流行度的名称前缀,并且当上一时间段统计完毕进行下一时间段的统计时,会从0开始重新计数,保证名称流行度的实时性。其底层采用的是hash表,与之前的方案存储名称前缀及前缀树中节点地址不同的是本文方案直接在这里存储名称前缀与下一跳的关系。因为此表中存储的已经是流行度高的前缀了,应该加快其查找命中并转发的速度,不用在这里考虑优化其内存占用。因此,本文采用的是效率高的hash表的数据结构,如图2所示。
2.3 Conflict-split Degraded Trie(CDT)
除流行FIB中存储的名称前缀外都要存储在Conflict-split Degraded Trie(CDT)中。
前缀树(Trie)又称为单词查找树,是常用于存储大量的字符串的树形数据结构,其优点是可以利用字符串的公共前缀来节约存储空间。因此,很多学者将Trie运用到了NDN中FIB的底层数据结构中,但其运用的方案仍有改进空间。如文献[6]采用的Degraded Trie,其特点如下:
(1)除根节点外的每个节点不再仅包含一个字符,而是包含一个组件(条目/com/baidu具有com和baidu两个组件),这将大大减小树的深度。
(2)对于所有节点,其子节点的数目不再固定,仅添加FIB中存在的节点,以便对前缀树进行裁剪。
此方案已将节点数量进行了一定程度的削减,但实际存储中会存在大量“单支”(前缀树的某一分支只存储一个名称前缀)的情况,如果此名称前缀很长,一个节点限制只能存储一个名称组件的话也是相当耗费内存占用的。因此本文采用一种Conflict-split Degraded Trie(CDT)的数据结构。它遵循这样的原则,即名称前缀默认存储在一个节点中,只有在出现冲突时才进行拆分,产生冲突的情况有如下两种:
(1)CDT中名称组件存在冲突的情况。
首先向一个空的CDT中插入一个名称前缀/com/google/movie/comedy,如图3中左图所示,此时CDT中除根节点外只存在一个节点。当插入另一个名称前缀/com/google/movie/drama时,名称中的前3个组件(com、google、movie)不存在冲突,依旧存储在一个节点当中,而最后一个组件drama与CDT中已存在的名称/com/google/movie/comedy中的最后一个组件comedy产生冲突,则进行拆分,将comedy从原节点拆分出来存放在一个新节点中,drama组件也新建一个节点进行存储,如图3中右图所示。
(2)CDT中公共前缀与原名称前缀存在冲突的情况。
仍使用仅存储了一个名称前缀/com/google/movie/comedy的CDT。当插入此名称的公共前缀/com/google/movie时,需要将原来的节点拆分,将/com/google/movie存储在一个节点,将名称组件comedy新建一个节点进行存储,如图4所示。这是因为原来的节点存放的是/com/google/movie/comedy的下一跳,而插入其公共前缀/com/google/movie,会存在新的下一跳,为了使得兴趣包能够被准确地转发到对应名称的下一跳,将其拆分进行存储来保证正确性。
当存储图1中FIB除流行FIB外的名称条目时,如图5所示。

图4 CDT中公共前缀与原名称前缀存在冲突的情况

图5 除流行FIB外的名称条目在DT及CDT的存储
图5中/com/google、/cn/google以及/action/movie就是之前所说的“单支”的情况,如果按照Degraded Trie的存储方式存储,将像左图一样各需要两个节点。如果按照本文方案,例如com与google之间是没有冲突的,则会存储到1个节点,如图5右图所示。这样前缀树的节点数量有所减少,树的深度也有所降低,会大大减少内存占用。并且名称前缀的数量越大,优化效果越明显。
2.4 辅助FIB
辅助FIB用于辅助流行FIB、CDT。其存储的是名称前缀与CDT中的地址对应的关系。这里的名称前缀是除流行FIB中存储的名称前缀外的流行度较高的前缀,同时也包括一些公共的名称前缀。与流行FIB类似,它也具备一个隐藏列——请求频率。它会在规定的时间段后与流行FIB进行流行前缀的更新替换,来保证流行FIB中存储的一直是高流行度的名称前缀。它也会用来辅助在前缀树中快速定位到一些名称前缀的位置,可以是具体的名称前缀,也可以是一些公共名称前缀,如图6所示。

图6 辅助FIB及其底层数据结构、CDT
/com/google/scholar就是一个具体的名称前缀,可以通过在辅助FIB中检索定位到其在CDT中的地址快速找到存储下一跳的节点进行转发。而在实际网络中往往也会出现一些公共名称前缀出现的概率较高,而具体的前缀出现的概率反而不高,例如辅助FIB中的/cn/google/movie,当想要检索/cn/google/movie/comedy时,可以先在辅助FIB中定位到/cn/google/movie在前缀树中的地址,找到此节点后再向其子节点进行遍历从而找到具体的节点获取到下一跳进行转发。
当然,辅助FIB还有一个功能就是与流行FIB进行实时的更新替换,它们会在规定的时间段内统计其包括的名称前缀的请求频率,每一个时间段都重新从0开始计数。设置一个阈值,高于阈值的进入流行FIB中,并在辅助FIB、CDT中进行删除。低于阈值的插入到辅助FIB以及CDT中。如图7所示,假设经过了规定的时间段统计的请求频率发生了变化,流行FIB中的/com/popular/4请求频率由1 002变为956,辅助FIB中的/com/google/scholar的请求频率由866变为1 044。假设阈值为1 000,则在流行FIB中删除/com/popular/4,将其添加到辅助FIB及CDT中。在辅助FIB中删除/com/google/scholar,将其添加进流行FIB中,从而保证了流行FIB中的名称前缀的高流行度。
3 名称查找方案的处理过程
本节将对提出的名称查找方案具体的处理过程进行详述,主要包括名称查找、名称插入、名称删除3部分。
3.1 名称查找
如图8所示,当要在FIB中查找某一名称前缀对应的下一跳端口时,主要包含以下几个步骤:

图7 辅助FIB与流行FIB的更新替换过程
(1)首先在CBF中检索,如果CBF中不存在此名称前缀,则直接丢弃掉请求该名称前缀的兴趣包,否则在流行FIB中检索。
(2)如果在流行FIB中查到了对应的名称条目,则直接通过下一跳端口转发,没有的话则检索辅助FIB。
(3)如果辅助FIB检索到此名称前缀,则根据其定位的CDT中的节点地址快速定位到对应的节点获取到下一跳。
(4)如果辅助FIB检索到此名称前缀的公共前缀,则根据其定位的CDT中的公共前缀的节点地址快速定位到对应的节点,并继续向其子分支节点进行遍历,从而获取到下一跳。
(5)如果辅助FIB中也不存在,则从CDT的根节点开始向下遍历,直到找到对应的节点获取到下一跳。
(6)如果CDT中也寻找不到此名称前缀,则丢弃掉请求该名称前缀的兴趣包。

图8 名称查找过程
3.2 名称插入
如图9所示,要向FIB中插入名称前缀,主要包含以下几个步骤:
(1)由于需要根据其请求频率进行插入,因此首先要获取到要插入的名称前缀的请求频率。
(2)将此名称前缀进行哈希运算映射进CBF中。
(3)当其请求频率高于流行FIB中的最低请求频率时,则插入流行FIB中。
(4)如果低于流行FIB的最低请求频率,但高于辅助FIB中的最低请求频率时,则首先添加进CDT中,再在辅助FIB中保留其与节点地址的关系。
(5)如果请求频率低于辅助FIB的最低请求频率,则只在CDT中添加。
3.3 名称删除
如图10所示,要在FIB中删除名称前缀,主要包含以下几个步骤:
(1)首先在CBF中删除掉此名称前缀的映射结果。
(2)如果要删除的名称前缀在流行FIB中,则直接在流行FIB中删除此名称前缀和其下一跳的关系条目即可。
(3)如果在辅助FIB中,则首先根据辅助FIB定位到的节点地址在CDT中删除对应的节点,再在辅助FIB中删除掉对应的名称前缀与CDT中节点地址的关系条目。
(4)如果辅助FIB中没有,则直接从根节点遍历,直到找到对应的名称前缀节点并删除。

图9 名称插入过程

图10 名称删除过程
4 实验和结果
在本节中,将对本文所提出的NDN名称查找方案进行仿真实验,使用Java语言在Windows系统下进行仿真验证。
4.1 实验设置
由于需要验证本文方案相比文献[6]提出的方案在NDN名称查找上的优势,因此直接使用Java语言在Windows平台上对其底层采取的数据结构进行模拟验证,Windows平台配置如表1所示。数据集来自文献[12]提出的NameGen,它是一个生成NDN/CCN名称数据集的程序。本文用其生成了创建时间统计数据集、查找时间统计数据集、内存占用统计数据集。

表1 仿真平台配置
如图11所示,在本文名称查找方案中采用四个数据结构:CBF、流行hash表(流行FIB,存储名称前缀与下一跳的关系)、辅助hash表(辅助FIB,存储名称前缀与CDT中地址的关系)、CDT(一个节点不是只能存储一个组件,如果不存在冲突,则可以存储多个名称组件)。本文在模拟文献[6]中的BF-PDT方案采用三个数据结构:CBF、流行hash表(与本文方案中的流行hash表不同,这里存储流行名称前缀与DT中地址的关系)、DT(一个节点只存储一个名称组件),如图12所示。
同时,为了验证BF-PDT方案中流行度表以及本文方案中流行FIB、辅助FIB的作用,本文在实验时增加了2个对比方案:BF-DT(只有CBF和DT)以及BF-CDT(只有CBF和CDT)。

图11 基于流行度和CDT方案的实验数据结构

图12 BF-PDT方案实验数据结构
4.2 实验指标
(1)创建时间:将2~100 000的数据集分别存储进4种方案的数据结构所花费的时间。同样数量的数据集存储进不同的数据结构中存储的时间越少,证明数据结构的存储效率越高。
(2)查找时间:分别在已经存储了2~100 000数据的数据结构中查找对应数据集数量的名称前缀所花费的时间。查找时间花费得越少,证明名称查找方案的处理过程越合理,数据结构的查找效率越高。这是NDN名称查找方案中比较重要的一个实验指标。
(3)内存占用:将10~100 000的数据集分别存储进四种方案的数据结构所占用的内存。同样数量的数据集存储进不同的数据结构中占用的内存越少,证明数据结构的内存设计越优。
4.3 实验结果
4.3.1 创建时间
图13显示了本文提出的基于流行度和CDT的名称查找方案与BF-PDT方案、BF-DT方案以及BFCDT方案分别将2~100 000的数据集存入所花费的时间的变化曲线。可以看出,4种方案的创建时间随着FIB中名称数量的增长处于上升趋势。从本文方案与BF-PDT方案、BF-DT方案与BF-CDT方案的对比情况来看,方案中采用CDT的比采用DT的花费的时间更少,这是因为CDT中一个节点不一定只存储一个名称组件,而DT中一个节点只能存储一个名称组件。节点数、深度有所下降,名称前缀存入数据结构花费的时间会减少。从本文方案与BF-CDT方案、BF-PDT方案与BF-DT方案的对比情况来看,采用流行度表的方案所花费的时间更少,这是因为hash表中用到的哈希运算是很快速的,相比前缀树中进行遍历来创建节点时间花费是更少的。
4.3.2 查找时间
图14显示了本文提出的名称查找方案与其他3种方案分别在存入2~100 000的数据集的数据结构中查找对应数据集数量的名称前缀所花费时间的变化曲线。与创建时间类似,4种方案的查找时间呈现上升趋势。从本文方案与BF-PDT方案的对比情况来看,本文方案查找时间更少,这是因为本文方案直接将流行的名称前缀和其下一跳的对应关系存入到了流行度表而不是像BF-PDT里那样流行度表存储名称前缀和DT中节点地址的对应关系,仍需要进一步去DT中寻找下一跳,因此流行的名称前缀会更快地命中FIB中的名称条目。从BF-DT与BFCDT方案的对比情况来看,BF-CDT的查找时间更少,这是因为CDT的节点数目和树的深度低于DT,自然在树中进行遍历寻找下一跳信息也会更快。从本文方案与BF-CDT方案、BF-PDT方案与BF-DT方案的对比情况来看,流行度表对于查找时间的优化效果是很明显的,可见在FIB底层数据结构的设计中考虑名称流行度的影响是可以提升查找性能的。
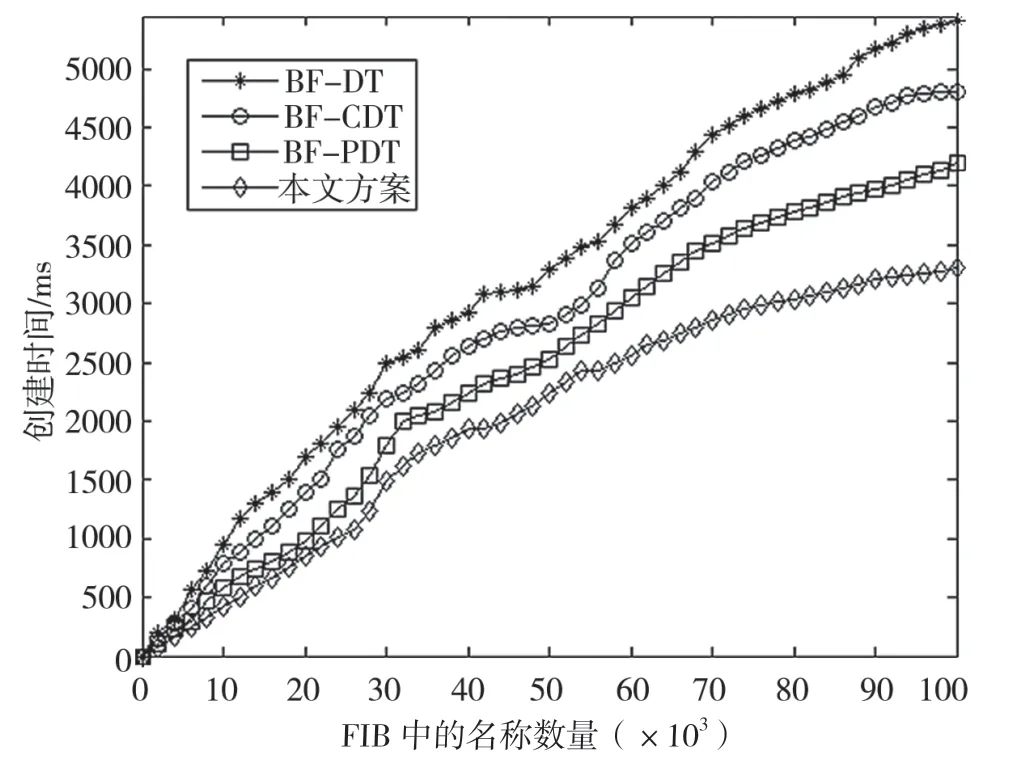
图13 创建时间随FIB中名称数量的变化曲线

图14 查找时间随FIB中名称数量的变化曲线
4.3.3 内存占用
图15显示了四种方案分别在存入10~100 000的数据集的数据结构所占用内存的变化柱状图。从本文方案与BF-PDT方案的对比情况来看,本文方案的内存占用也是更少的,同样是因为采用CDT会比DT节点数目更少,节点数更少也就会导致树的内存占用更少。而从BF-PDT方案与BF-DT方案、本文方案与BF-CDT方案的对比情况来看,本文方案与BF-PDT方案相比不存在流行度表的方案内存占用会稍多一些,这是因为hash表需要对每个前缀开辟空间存储,而前缀树会对前缀的公共部分进行聚合存储,内存占用会相对更少一些。
5 结语
命名数据网络中的FIB的存储和名称查找是一个亟需解决的问题。本文从基于FIB表拆分的名称查找方案以及基于底层数据结构的名称查找方案的基础上,针对它们的缺点,提出了基于流行度和CDT的NDN名称查找方案。该方案将FIB划分为CBF、流行FIB、CDT以及辅助FIB。CBF用于快速筛选掉不在FIB中的名称前缀。流行FIB底层采用hash表,存储流行名称前缀与下一跳端口的对应关系,用于高流行度的名称前缀的快速转发。所有除了流行FIB中存储的名称前缀都要存储到CDT中。CDT通过一个节点不一定只存储一个名称组件且只有在产生冲突时拆分的机制减少了树的深度以及节点的数目。辅助FIB用于辅助流行FIB、CDT,底层采用hash表,存储CDT中存储的名称前缀中的流行名称前缀(包括一些公共前缀)与CDT中节点地址对应的关系,便于其快速定位到CDT的节点。辅助FIB、流行FIB根据流行度的变化进行实时更新、替换。最后通过实验表明,该方案在创建时间、查找时间、内存占用指标上存在优化效果,证明该方案进一步提升了NDN中FIB的存储和名称查找性能。
猜你喜欢
军民两用技术与产品(2022年2期)2022-06-01 06:29:44
股市动态分析(2016年17期)2016-10-20 13:51:33
股市动态分析(2016年13期)2016-10-17 13:53:39
股市动态分析(2016年11期)2016-10-11 13:56:32
股市动态分析(2016年10期)2016-09-30 13:59:11
广东技术师范大学学报(2016年5期)2016-08-22 09:07:32
中国市场(2016年45期)2016-05-17 05:15:48
小说林(2014年5期)2014-02-28 19:51:47
上海理工大学学报(社会科学版)(2014年2期)2014-02-28 14:42:19
河南科技(2014年5期)2014-02-27 14:08:57
