
融入中心句的涉案新闻要素实体识别方法*
2021-05-08 06:10王佳雯线岩团余正涛
通信技术 2021年4期
王佳雯,王 剑,线岩团,余正涛
(昆明理工大学,云南 昆明 650500)
0 引言
涉案新闻要素实体识别对涉案新闻追踪具有很好的辅助作用,是涉案新闻舆情分析的重要任务。
通用领域的命名实体识别任务是识别实体的类别,如“人名”“地名”“组织机构名”等[1]。而细粒度的要素实体识别不仅要正确识别句中所含实体,还要识别各实体所对应的属性,如“人名”在涉案新闻句中可对应的具体属性有“被害人”“犯罪嫌疑人”和“非要素实体”。因此,与通用领域命名实体识别任务相比,涉案新闻要素实体识别任务更依赖上下文语义信息。涉案新闻文本上下文语义联系紧密,如新闻句中普遍存在使用代词指代上一句提到的内容的情况,导致在单个句子的语义理解上会出现语义模糊的状况。当一句话中同时出现多个“人名”“地名”“组织机构名”时,仅靠句子中的模糊语义不足以区分要素实体。因此,本文通过融入新闻中心句,对新闻正文句中的语义进行补充增强,以改善要素实体识别的性能。
1 相关工作
涉案新闻领域的要素实体识别可以看作是特定领域的细粒度命名实体识别任务。
最早期的命名实体识别方法是基于规则和词典的方法[2-3]。这种方法不仅依赖于具体语言、领域和文本风格,而且有编制过程耗时、特别容易产生错误、系统可移植性不佳以及对不同的系统需要语言学专家重新编写规则[4]等缺点。
相比基于规则和词典的方法,基于统计机器学习的方法不需要专家知识编写规则。常用的基于统计机器学习的命名实体识别方法有隐马尔可夫方法[5]、最大熵[6]、支持向量机[7]以及条件随机场[8]等。这类方法对特征选取的要求较高,需要从文本中选择对该项任务有影响的各种特征,并将这些特征加入到特征向量中,且对语料库的依赖较大[9]。
目前,深度学习由于不需要书写规则和人工提取特征,成为命名实体识别领域的主流方法[10]。深度学习在命名实体识别任务中的运用多以循环神经网络(Recurrent Neural Network,RNN)加CRF的序列标注方法[11]为基础进行改进,并在不同领域的命名实体识别任务中取得了很好的效果。Huang等人[12]提出Bi-LSTM和CRF相结合的序列标注模型,捕捉上下文语义信息。Zhang等人[13]依据中文需要分词的特性提出Lattice-LSTM方法,将词信息融入到方法中以解决字符方法无法利用句子中的单词信息的问题。成于思等人[14]考虑到中文人名具有多样性和内部成词的特性,提出融合人名词典特征的Bi-LSTM加加权条件随机场(Weighted Conditional Random Fields,WCRF)方法。唐国强等人[15]提出利用语言方法特征和多头注意力捕获病例文本自身的特征。上述方法依赖句子的上下文信息抽取实体,且融入外部特征大都是为了解决实体多样性带来的未登录词问题。而在涉案新闻领域,主要问题是部分句子成分指代引起语义模糊导致要素实体识别率低,因此只关注句子内的信息往往不够。本文提出将涵盖篇章语义信息的新闻中心句融入到新闻正文句中,对语义模糊的新闻中心句进行语义增强,从而有效提升要素实体识别率。
2 融入新闻中心句的要素实体识别方法
融入新闻中心句的要素实体识别方法由4个部分组成,如图1所示。第1部分是词嵌入层,使用Skip-gram[16]方法将新闻中心句和新闻正文句转换成字符向量;第2部分是融入新闻中心句的加权多头注意力(Weighted Multi-Head Attention,WMATT)层,利用多头注意力将新闻中心句与新闻正文句相融合,并对融合了新闻中心句的多维度语义信息进行加权求和;第3部分是Bi-LSTM层,用Bi-LSTM获取融入新闻中心句后的上下文信息;第4部分是CRF层,用CRF识别要素实体。下面将详细介绍方法的各部分内容。
2.1 输入层
本方法的输入分为两个部分:一是涉案新闻的正文句,二是与每一条正文句所对应的新闻中心句。使用Skip-gram方法[16]将中文字符转换成字符向量。正文句表示为Z=z1,z2,…,zm,其中zj表示正文句中第j个字。新闻中心句表示为C=c1,c2,…,cn,其中ci表示中心句中第i个字。通过查找字向量表,将正文句和中心句中的每个字zj和cj转化为字向量序列。

式中,ec表示字嵌入的查询表。
2.2 融入新闻中心句的WM-ATT层
此层有两个输入,一个是新闻正文句L=(l1,…,lj,…,lm),L∈Rm×de,另一个是新闻中心句X=(x1,…,xi,…,xn),X∈Rm×de。其中,m和n分别是正文句长度和中心句长度,de是字向量维度。将新闻中心句融入到新闻正文句中的计算可以分为3个部分。
首先,将新闻正文句X作为key-value,将新闻中心句X作为query,分别通过如式(3)、式(4)和式(5)所示的线性变换进行切分,以映射到不同的维度。
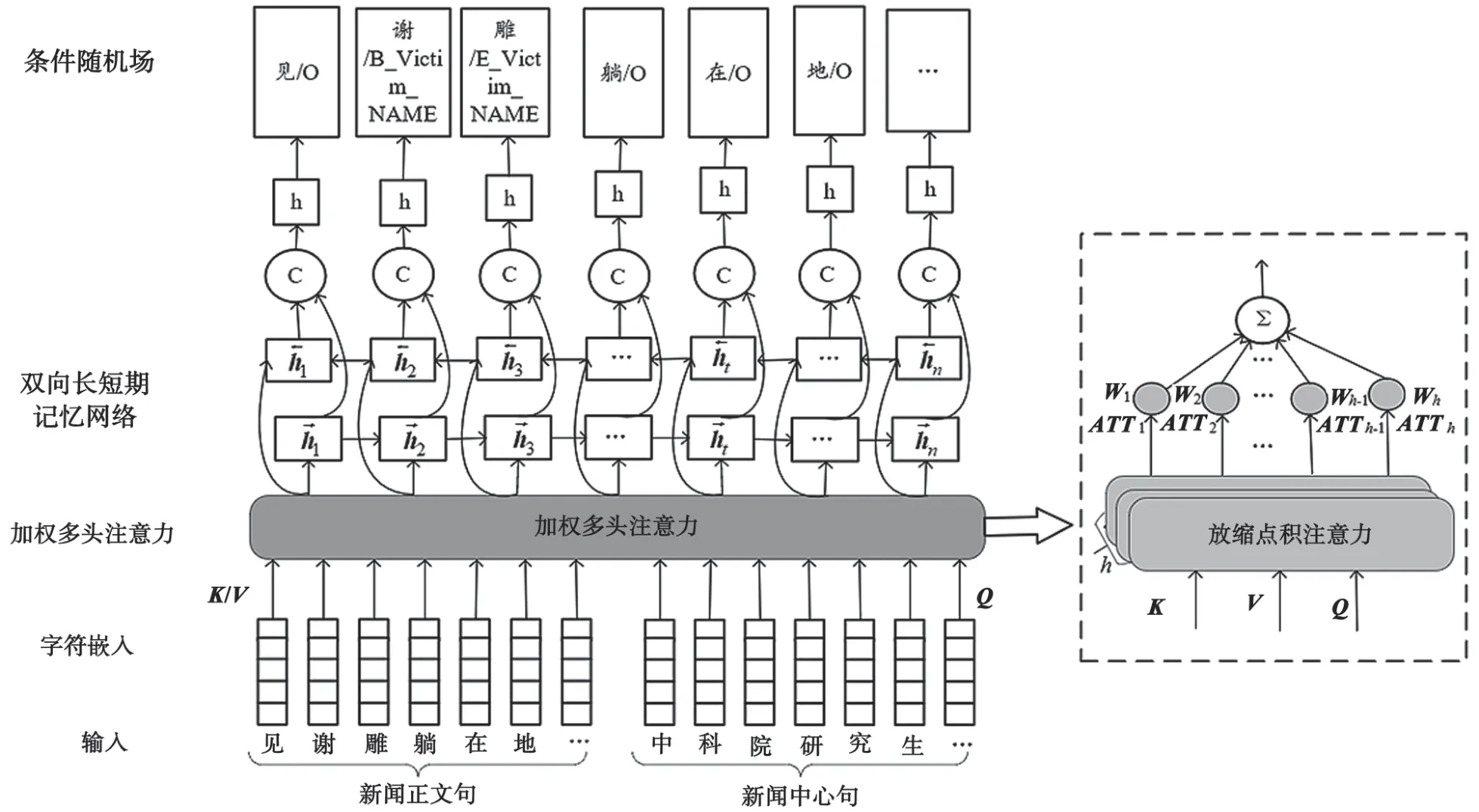
图1 融入新闻中心句的要素实体识别模型
其次,在第i个维度内进行放缩点积注意力,将新闻中心句融入新闻正文句中,如:
通过Qi和Ki点乘计算获得新闻中心句到新闻正文句的关联度得分,经softmax将得分压缩到0-1之间,再将映射得分与新闻中心句相乘,得出在第i个表示子空间内融合了新闻中心句的新闻正文句特征ATTi。
最后,将h个不同维度得到的特征结果加权求和,得到融合篇章语义的多层次语义特征E:

式中,Wi给不同维度上融合了新闻中心句的语义信息分别分配权重,权重矩阵Wi∈Rdmodel×dk。
传统的Multi-Head Attention是句子与自己本身做注意力,映射到不同维度的是同一个语义的不同着重部分;WM-ATT是对中心句与正文句两个不同的句子做注意力,映射到不同维度的是不同的语义部分。因此,在将中心句和正文句做注意力时,不同维度得到的语义信息对辅助要素实体识别的重要性不同。给不同维度上得到的语义信息分配权重,可以减缓无效信息对要素实体识别的负影响,再进行求和,从而实现多维度的语义融合。
2.3 Bi-LSTM层
在融入了新闻中心句特征后,需要采用Bi-LSTM提取融入新闻中心句后的上下文语义特征。
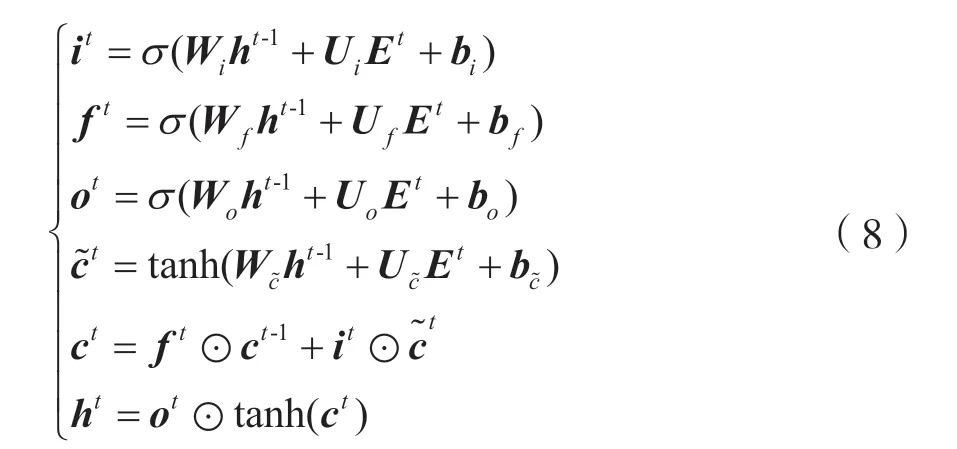
式中,it、ft、ot、ct分别是输入门、遗忘门、输出门、细胞状态;Wi、Wf、Wo、W~c是t-1时刻隐藏状态的权重矩阵;Ui、Uf、Uo、U~c是融合了新闻中心句特征E的权重矩阵;bi、bf、bo、bc~是输入门、遗忘门、输出门、细胞状态的偏置项。反向的LSTM与正向的LSTM的定义相同,但是按照逆序排列。将正反向的LSTM隐藏状态级联形成ct的上下文相关表示,其中分别是时刻t的正向输出和反向输出,⊕表示向量拼接。此时,ct的上下文相关表示中包含了多层次全局语义特征。
2.4 CRF层
本文使用CRF对融入新闻中心句的上下文信息进行约束性解码。CRF对L=(l1,…,lj,…,lm)的输入序列和其对应的标签序列Y=y1,y2,…,ym的评估分数为:
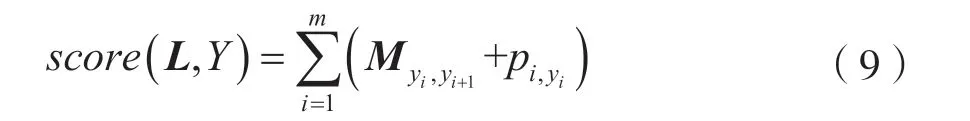
式中,M为状态转移矩阵,Myi,yi+1表示从yi变化到yi+1的概率,pi,yi表示第i个字符对应的yi标签的分数。
3 实验设置与结果分析
3.1 数据集
要素实体类别分别是犯罪嫌疑人、被害人、案发地、查案警方、审理法院和其他非要素实体。通过爬取中国新闻网大案要案模块获取涉案新闻语料,整个语料包括97个案件共2 000条句子。按照7:3的比例划分训练集和测试集,语料中句子和各类要素实体的分布如表1所示。

表1 涉案新闻语料统计
3.2 实验参数设置
本文实验采用TensorFlow1.13.2框架,且中心句和正文句的句子长度设置一致,均为120个字。训练过程中,本文使用Adam优化算法,学习率为0.004;批次为16,字嵌入维度为120,单向的LSTM的神经单元为128。
由图2可知,当多头数被设置为1~4时,融入新闻中心句的要素实体识别方法的识别效果随着多头数的增加而提高。当多头数设置为4时,整体效果达到最优,而后逐渐变小趋于平稳。因此,本文将多头数设置为4。
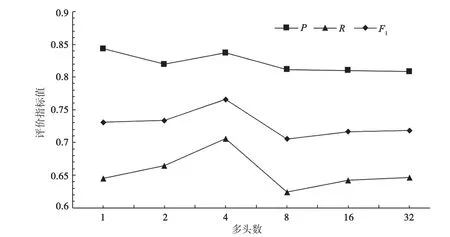
图2 多头数对模型性能的影响
本文采用准确率P、召回率R和F1值作为要素实体识别结果的评价指标,计算过程如下:


式中,TP为被正确划分为正例的个数,FP为被错误划分为正例的个数,FN为被错误划分为负例的个数。
3.3 实验结果分析
3.3.1 对比实验结果分析
为了验证融入新闻中心句的要素实体识别方法的性能,将其与下列方法进行对比。
(1)Bi-LSTM-CRF。本文通过Bi-LSTM网络获取新闻句的上下文信息,再采用CRF预测新闻正文句的标签信息。
(2)Bi-LSTM-Self-Attention-CRF。Lin等人提出一种Self-Attention机制[17],本文用Bi-LSTM获取新闻正文句的上下文语义后,再经Self-Attention获取全局语义,最后用CRF解码。
(3)Multi-Head Attention-Bi-LSTM-CRF。Vaswani等人提出Multi-Head Attention机制[18],本文采用4个多头从新闻正文句获得多角度语义信息,再采用Bi-LSTM获取上下文语义信息,最后用CRF识别要素实体。
在对比实验中,各方法实验环境相同,实验结果如表2所示。

表2 涉案新闻要素实体识别方法比较
从实验结果可以看出,与效果最佳的Multi-Head Attention-Bi-LSTM-CRF方法相比,本文提出方法的3个指标值分别提高了0.66%、5.17%、3.4%。结果说明,本文提出的融入新闻中心句的要素实体识别方法能够有效提升要素实体识别的性能。
3.3.2 消融实验结果分析
为了进一步验证提出方法的有效性,分别将各个部分删除后进行比较,从而分析各个部分是否对要素实体识别有效。
从表3可以看出,融入新闻中心句后Multi-Head Attention-Bi-LSTM-CRF的F1值提升了2.87%;利用WM-ATT的融合方法和利用Multi-Head Attention的融合方法相比,准确率、召回率、F1值分别提高了0.41%、0.62%、0.53%。

表3 消融实验结果
3.3.3 对比实验各类别结果分析
本文使用的是涉案新闻语料,共有5个案件要素类别。各个类别在不同方法中的实验结果如图3所示。
由图3可知,4个方法识别结果最好的类别是“犯罪嫌疑人”,结果最差的类别是“案发地”。本文提出的要素实体识别方法在“案发地”“查案警方”和“审理法院”这3个类别的识别效果上与其他方法相比有很大的提升。
3.3.4 样例测试分析
本小节将使用原始语料中未出现的涉案新闻案例作为测试样本,以测试本文提出方法在新数据上的识别效果,具体如下。
新闻中心句:宁波市公安局宁海分局(以下简称“宁海公安”)成功侦破城关镇杨家村杀人命案,抓获潜逃21年之久的命案犯罪嫌疑人王某金,将于23日,转交宁波市中级人民法院开庭审理。
新闻正文句1:宁海公安接到报警称:城关镇(现为桃源街道)竹口杨家村杨某在自家小店内被人捅伤,送医途中死亡。
新闻正文句2:当天19时许,专案组成功在余姚梨洲一暂住房内找到王某金。
新闻正文句3:1999年11月2日凌晨,王某金带着刀和手电筒在小店周围踩点。
新闻正文句4:他看到受害人杨某要关店门,便一把推开门进去,杨某发现王某金后,王某金用手抱住杨某。
新闻正文句5:一审将于23日,在宁波市中级人民法院开庭审理。
测试结果显示,“犯罪嫌疑人”“被害人”“查案警方”“审理法院”这4类要素实体都能被有效识别,并且在由于成分指代导致语义模糊的新闻正文句4中,“犯罪嫌疑人-王某金”也被识别出。只有不曾在新闻中心句中出现的“案发地-小店”未被识别出。
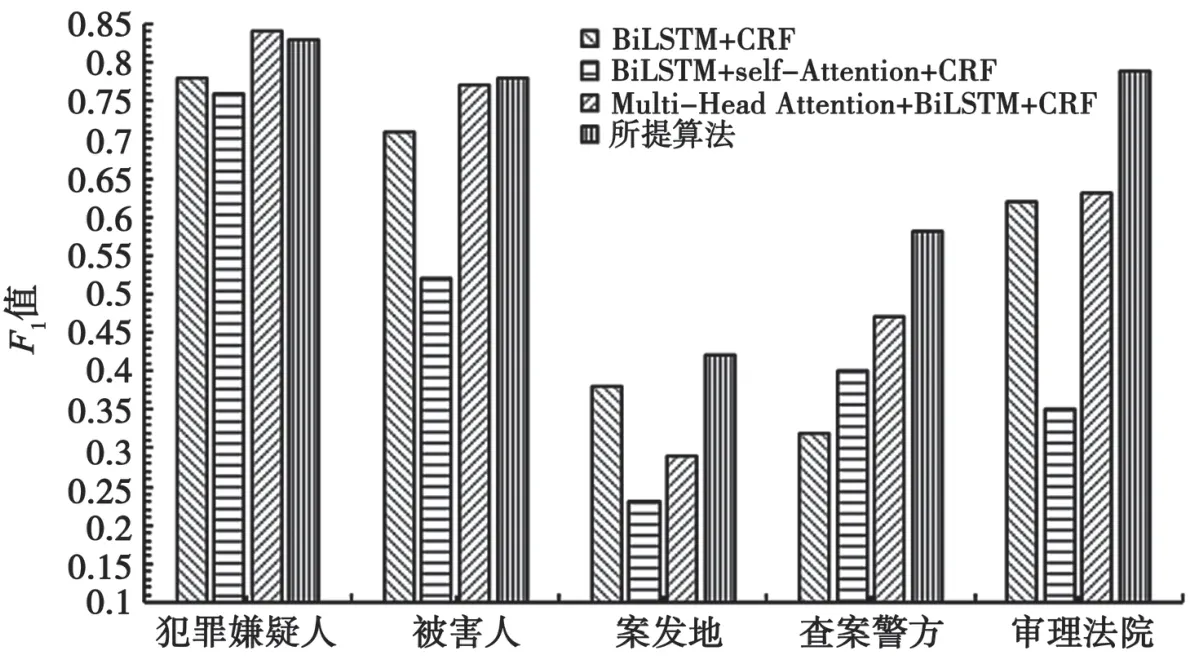
图3 各类别的实验结果对比
4 结语
针对涉案新闻句中由于成分指代引起语义模糊导致要素实体识别率低的问题,本文提出利用WM-ATT将新闻中心句融入新闻正文句中,以此进行语义增强并减缓无效信息对要素实体识别造成的负面影响。尽管本文通过融入新闻中心句增强新闻正文句语义使得识别性能略有提升,但是方法的识别效果依赖于新闻中心句的详尽程度。因此,在未来研究中将会更多关注联合抽取新闻中心句和要素实体的方法,从而提升方法性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
科学养鱼(2021年6期)2021-11-30
现代畜牧兽医(2021年4期)2021-05-15
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
长江学术(2016年4期)2016-03-11
爆笑show(2015年5期)2015-07-09
长江学术(2015年1期)2015-02-27
