
基于频率时效感知的混合内存写冷热页面调度
2021-05-07 08:43:08汪令辉陈友良
湖南工业大学学报 2021年3期
刘 兵,汪令辉,张 涛,陈友良
(1.中国科技大学 计算机科学与技术学院,安徽 合肥 230027;2.铜陵职业技术学院 信息工程系,安徽 铜陵 244061;3.铜陵有色金属集团公司,安徽 铜陵 244000;4.中国安全生产科学研究院,北京 100012)
0 引言
随着大数据技术、人工智能和工业互联网等技术的发展,需处理的数据量越来越多,对内存的节能、存储密度、随机写、高并发性随机读和实时处理分析等都提出了更高的要求。当前主要的内存技术是DRAM(dynamic random access memory),要通过不断地刷电来保持数据,能源的消耗比较大。另外,DRAM 的存储集成也已经接近极限。非易失性存储(non-volatile memory,NVM)技术为解决这一问题提供了一种新方法,其中以相变存储器(phase change memory,PCM)[1]性能最为突出,其作为近些年存储技术发展的热点技术,有着广泛的应用前景。PCM 相对于DRAM 的优点是存储密度较大、功耗低;缺点是写入的速度比DRAM慢、写的次数有限。因此,减少PCM 的写操作,提高其写耐久性,是许多研究者探讨的问题。
1 相关研究
1.1 混合内存架构
针对PCM 和DRAM 的特点,目前的研究集中在将PCM 和DRAM 二者的优点结合。在混合内存[2-5]结构上的使用,分为同级混合内存和层次混合内存,如图1所示。
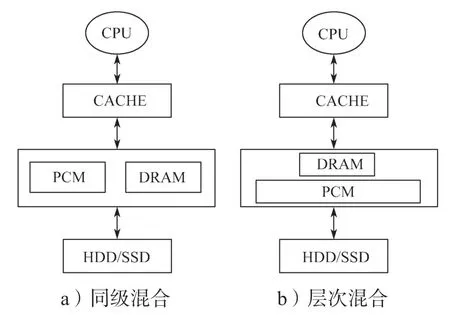
图1 同级混合和层次混合内存结构框图Fig.1 Peer and hierarchical hybrid memory structure
1)同级混合内存[6](图1a)利用PCM 字节寻址的特点,内存由PCM 和DRAM 两部分构成,并当作一个整体统一编址。访问时,根据页面特点,将页面分别放入PCM 或DRAM。2)层次混合内存[7](图1b)。其将DRAM 作为PCM 的缓存,先访问DRAM,如DRAM 没有命中,再访问PCM,通过DRAM 的写无限性缓冲PCM 的写有限性。
1.2 已有混合内存冷热页的判定
由于PCM 的写耐久性有一定的次数限制,读写不均衡,写时间较长,所以在混合内存缓冲区管理调度策略的设计中,通常要达到2 个目标:1)减少PCM 的写次数,延长PCM 的使用年限;2)提高访问时缓冲区页面的命中率,从而减少页面调度时资源的消耗及同时产生的PCM 写操作。
Seok H.等[8-9]提出以“最近最少使用”(least recently used,LRU)算法为基础的LRU-WPAM(LRU with prediction and migration)算法,增加了一个页面的读写预测,根据判断缓冲区页面是否命中。当未命中时,用最近最少使用页面置换;命中时,根据读写请求修改页面权值,再判断权值是否达到阀值。判断页面是读倾向高的页面(“读热页”),还是写倾向高的页面(“写热页”),如果页面达到阀值,将“读热页”移动移动进PCM,将“写热页”移动进DRAM。Lee S.等[10]提出CLOCK-DWF 算法,将DRAM 和PCM 各组成一个环状队列,当空间充足时,把读请求页面存入混合内存的PCM 中,写请求页面放入混合内存的DRAM 中。当DRAM 空间不足时,进行冷热页的调度,将写冷页调度进入PCM,PCM的空间不足时,使用CLOCK 算法调度页面。类似的还有Chen K.M.等[11]提出的MHR-LRU(maintainhit-ratio LRU),刘兵等[12]提出的FWLRU(favors write LRU)策略等。
以上算法都涉及页面冷热页的判定。LRUWPAM 中给每个页面设置权值,当页面是“读请求”时,权值增加,当是“写请求”时,权值减少,通过权值和阀值的比较判定页面的读写热页类型。CLOCK-DWF 通过每个页面写次数来判断“写热页”和“写冷页”。其它几种算法也都通过次数来判断页面的冷热。
2 频率时效感知页面划分
在PCM 的读写操作中,根据PCM 的特性,读操作和DRAM 中的操作区别不大,写操作的使用对于PCM 的扬长避短有决定性的作用。如果能准确及时地预测出“写冷页”和“写热页”,既可利用PCM 的低能耗、存储密度大的特点,又可避免写操作有限的缺点,从而提高PCM 的写耐久性,同时提高页面的命中率。但已有的冷热页面预测或者判定方法,忽略了如下几个方面的问题:
1)页面访问有局部性
存储系统负载访问有局部性[13]的特点,即写操作聚集在若干页面上。在某一时间段内,若干页面访问次数很多,比较密集,其它页面没有访问或者零星访问。
2)“写热页”和“写冷页”和页面调用的时段有关页面调用的阶段性
某些页面写入后,可能很长时间不再调用,也可能阶段性爆发,并且在较近时段发生过写操作页面为“写热页”的概率比较大,即局部爆发和爆发的间隔时段有关。
针对上述问题,本文提出根据先前访问的频率距离现在访问的间隔、当前局部爆发访问的特点,将页面的局部写频率和上次的高频访问和最近高频访问的时间间隔来计算权值,并根据权值对页面“写”冷热进行划分,即频率时效写页面划分。
2.1 模型定义
页面写访问的局部爆发性、访问频率和最近写访问间隔对页面写的冷热有着直接影响。根据这一特点,本文通过写访问频率和最近写访问间隔、频率时效(frequency time interval,FTI)进行计算,预测页面的冷热度。首先引入如下几个概念。
局部写访问统计器(local write access statistics,LWAS)。如图2所示,该统计器为长度为20 的队列,按照写访问的时间顺序,记录最近发生的20 次写请求访问,并不重复统计最近每个页面的访问次数,计算得到局部写访问频率的值为Pn。

图2 局部写访问统计器Fig.2 Local write access statistics
频率时效页面写冷热权值计算公式为
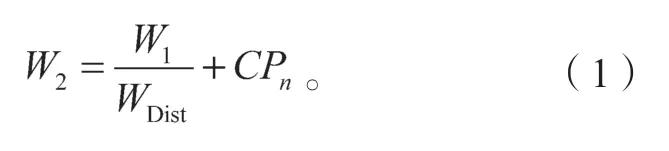
式中:W1为当前页面上一次写访问时的权值;W2为出现最近页面写请求时计算的权值;WDist为上一次最近的权值除以这个页面的最近写距离。C取值时,先假定为0.4~0.6 的区间,然后经过实验数据测定,取0.5 比较合适。当页面没有出现过,W1没有值时,取默认值0.45,WDist取默认值1。
高频访问页容器(high frequency access page container,HFAC)。该容器为一链表,由局部写访问统计器中Pn≥2 的页面按照时间次序组成,每个节点由页面序号和权值构成,权值根据式(1)得到。当LWAS 中出现大于两次的页面时,将页面放入HFAC,如果HFAC 中出现过这个页面,在记录值后,将其从前面链表中删除。
混合内存CLOCK 链表(hybrid memory CLOCK)。DRAM 和PCM 混合内存页面整体链表,按CLOCK 算法处理。
CLOCK-DRAM。将DRAM 中页面按CLOCK算法组织并处理页面。
CLOCK-PCM。将PCM 中页面按CLOCK 算法组织并处理页面。
2.2 冷热页调度
DRAM 和PCM 按照4:1 的比例进行配置,DRAM 存储的页面个数为DSize,PCM 存储的页面个数为PSize。
频率时效页面写冷热度权值计算过程如下:
当出现页面写访问请示时,将页面序号放入局部写访问统计器头部;
统计局部写访问统计器,如果出现Pn≥2的页面,读取高频访问页容器中各项,寻找是否存在此页面;
如果高频访问页容器有该页面,根据式(1)计算页面权值,放入高频访问页容器头部,删除先前的节点;如果没有该页面,计算权值放入高频访问页容器。
在混合内存中,由于PCM 的写次数限定性,写页面存放以DRAM 为优先,以频率时效的CLOCK算法(frequency time interval CLOCK,FTI-CLOCK)来实现页面的调度。出现写请求时,进行局部写访问频率统计并按式(1)计算权值,将权值插入HFAC。如果出现Pn≥2 写请求时,调度原则如下:
如果页面在CLOCK-DRAM 中,执行操作,如果页面在CLOCK-PCM 中或者未命中,查找DRAM中是否存在空闲空间;
如果存在空闲空间,将页面调入DRAM,如果没有空闲空间,比较CLOCK-DRAM 和HFAC,查找CLOCK-DRAM 不在HFAC 中的页面,如果存在,按照CLOCK 算法将页面转换进PCM 或者淘汰,如果没有,浏览HFAC;
将HFAC 中权值最小,且在DRAM 中的页面,与页面置换。
2.3 算法过程
频率时效页面写冷热权值计算过程如算法1 所示,其中输入为W1、WDist和Pn,输出为计算的权值W2。
算法1频率时效页面写冷热权值计算

频率时效的CLOCK(FTI-CLOCK)调度过程如算法2 所示,在Pn≥2 的页面写请求时,执行算法进行页面调度。
算法2FTI-CLOCK 页面调度


3 实验仿真及分析
3.1 实验方法
为了模仿混合内存环境,通过在ubuntu 18.04 系统上架设仿真模拟器GEM5[14]+NVMain[15]来实现DRAM 和PCM 混合内存实验环境。GEM5 是GEMS和M5 结合的全系统模拟器,它有ISA 和多种CPU模型,本实验用它来模仿整个系统,NVMain 是循环级的内存模拟器,本实验用它来模仿PCM,从而实现DRAM+PCM 的实验环境。实验时采用系统级仿真模式SE,每个页面设为4 kB 大小,延迟数据:PCM 参照F.Bedeschi 等的研究[16],DRAM 参照Micron 的测试[17]。
具体实验数据集[16]测试参数见表1。
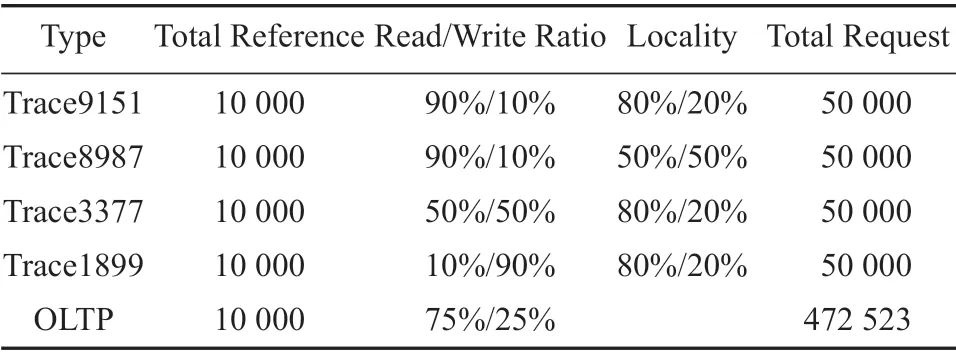
表1 实验数据集Table 1 Experimental data set
本实验数据集由两部分构成:真实数据和合成数据。真实数据采集于安徽省芜湖市某天猫网站某段时间的交易记录,数据集经过去噪处理,有356 733 次读和115 790 次写;合成数据通过开源软件DiskSim获得,通过它对磁盘的模拟读写操作来获取比例不同的局部性读写操作数据集,表1中的数据集中Locality(局部性),如“80%/20%”,表示在20%的局部空间上发生的80%的读写操作。
3.2 存储空间变化的PCM 写次数
将数据集Trace9151、Trace8987、Trace3377、Trace1899 和OLTP 在频率时效下的FTI-CLOCK 页面调度和CLOCK、CLOCK-DWF 和D-CLOCK 的页面调度进行比较。图3给出了5 组数据集在4 种不同页面调度下的PCM 写次数统计,本次实验中内存页面逐渐增大,DRAM 和PCM 按照4:1 统一修改的比例进行配置。
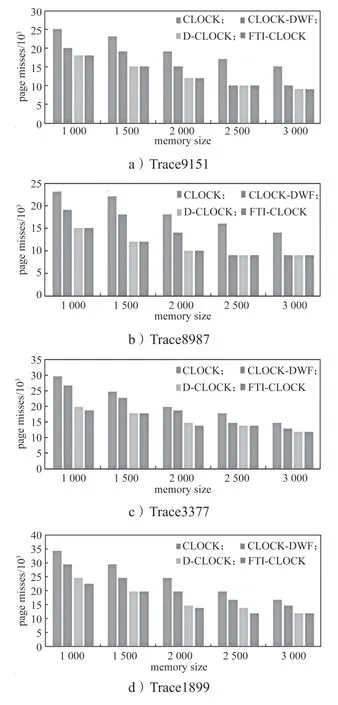
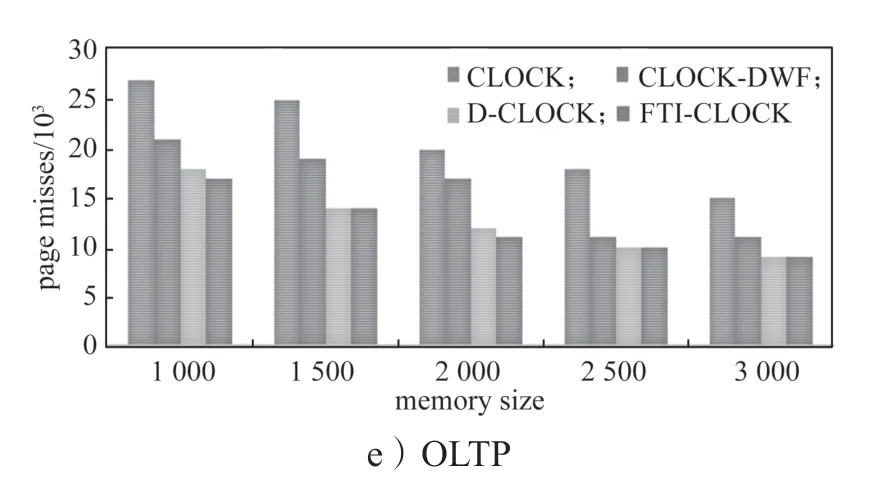
图3 存储空间变化的不同调度PCM 写次数Fig.3 Different scheduling PCM write times with storage space changing
通过数据集在4 种调度策略下的PCM 写次数的数据显示,如图3中a~e 图所示:
1)随着混合内存空间容量的增大,各数据集在4 种调度策略的写次数都下降。实验结果显示当存储空间增大时,可以显著减少PCM 的写次数;
2)合成数据集中读写的比例,对PCM 写的次数影响较大,实验结果表明当写比例增大时,PCM写的次数明显增大;
3)数据的局部操作性对PCM 的写次数有影响,但不是很大;
4)实验结果显示,频率时效的FTI-CLOCK 调度算法,可以有效减少PCM 的写次数。
3.3 固定存储空间的PCM 写次数
当存储空间固定为2 GB,DRAM:PCM 为4:1,实验数据集在FTI-CLOCK 页面调度、CLOCK、CLOCK-DWF 和D-CLOCK 情况下,PCM 写次数的实验结果如图4所示。
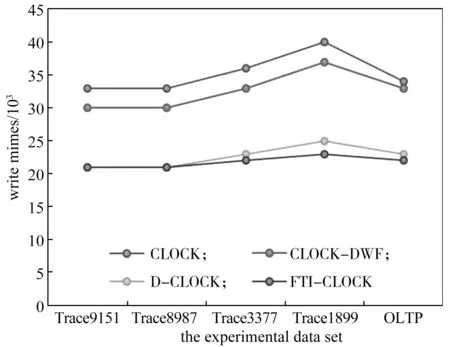
图4 存储空间固定的不同调度PCM 写次数Fig.4 Different scheduling PCM write times with fixed storage space
通过分析实验得出的数据可知,当存储空间、比例一定时:CLOCK 算法没有对混合存储空间进行区分,进行无区别的读写操作,PCM 的写次数较多;CLOCK-DWF 操作,仅根据页面的读写请求,就对页面的冷热进行划分,并将读页面置换进PCM,页面划分较为简单,造成写PCM 写次数还是比较高;D-CLOCK 根据当前页面的写次数和平均写次数比较来划分页面的冷热,降低了PCM 写次数,但没有考虑页面写的局部爆发和时间间隔;FTI-CLOCK 考虑了页面的局部爆发写特点,并将局部写频率和写的时间间隔相结合,在4 个算法的写操作中,写次数最低。实验证明,频率时效的FTI-CLOCK 调度能够有效减少PCM 写次数,明显地优化PCM 写,提高PCM 的使用时长。
4 结论
作为新一代存储材料,PCM 有着许多优点,有着较高的存储密度,并且低能耗,已经进入工程应用阶段,但如何解决PCM 的写耐久性是一个急需解决的问题,多年来,许多研究人员给出了多种解决方案。本文通过分析内存页面写的局部性和时效性,提出了新公式将二者结合在一起,通过计算权值的形式来区分页面的冷热。
1)通过局部访问统计器对局部密集写访问的频率进行了统计;
2)将最近时间的高频写请求,上次密集写和这次访问的时间间隔统一到一个计算公式中,并根据频率和时效计算权值;
3)在考虑局部密集写访问和频率时效权值的基础上,实现写页面的调度,实验结果表明,该方法可以有效降低PCM 的写次数;
4)本文只是从比较小的数据出发来实现频率时效的写冷热页面调度,但对大数据环境下,如何通过局部写访问和时效性来进行页面的调度,是下一步研究的方向。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
当代陕西(2019年13期)2019-08-20 03:54:22
自动化学报(2017年7期)2017-04-18 13:41:02
材料科学与工程学报(2016年1期)2017-01-15 13:33:58
上海金属(2016年3期)2016-11-23 05:19:47
中国环境监察(2016年4期)2016-10-24 05:24:34
上海金属(2014年1期)2014-12-18 06:51:59
测绘科学与工程(2014年5期)2014-02-27 07:06:14
电脑爱好者(2009年13期)2009-07-07 09:52:52
