
基于网格搜索-随机森林算法的水合物结构与生成条件预测
2021-05-06 03:14蔡文慧田东海梁昌晶
石油工程建设 2021年2期
杨 威,薛 钊,蔡文慧,王 婷,田东海,梁昌晶
1.华北石油管理局有限公司苏里格勘探开发分公司,内蒙古鄂尔多斯150626
2.中国石油华北油田公司友信勘探开发服务有限公司,河北任丘062552
3.中国石油华北油田公司第二采油厂,河北霸州065700
4.中国石油华北油田公司二连分公司,内蒙古锡林浩特026000
目前,水合物生成条件的预测方法主要有经验图解法、关联公式法和热力学模型法[1-3],其中经验图解法和关联公式法在油气田现场应用较多,但预测精度及效果不好,热力学模型法是基于室内试验的结果,通过引入状态方程以提高预测结果精度,但涉及的参数较多,专业性较强,不能很好地推广使用。
随着机器学习技术的不断发展,越来越多的学者采用人工智能算法对水合物的生成条件进行预测[4]。卞小强等[5]通过引入CO2和H2S 的贡献因子,采用SVM 对含酸性气体的水合物生成条件进行了预测,其平均相对偏差为5.7%;Mesbah 等[6]为了解决SVM 算法产生局部最优问题,引入了最小二乘向量机,可有效预测高酸天然气水合物的生成;唐永红等[7]将小波分析和神经网络相结合,通过求解权值向量、平滑因子、伸缩因子等变量,对I 型水合物的生成温度进行了预测;马贵阳等[8]将遗传算法与SVM 相结合,通过数值计算拟合了相平衡曲线,其精度与热力学模型的精度接近。综上所述,以上研究均基于大量的试验数据,本身容易陷入局部最优,出现超参数选取困难的现象,且未考虑抑制剂、水中盐类的影响,对水合物结构进行智能算法分类也未见报道。在此,采用具有分类和回归功能的随机森林算法[9-10],以不同的气体组分为输入变量,对水合物结构进行分类;以气体组分、压力、抑制剂、盐类等为输入变量,对水合物的生成温度进行预测,以期为水合物的相关研究提供理论依据和实际参考。
1 水合物相平衡影响因素
影响水合物相平衡的因素可分为气体组分和外部因素两方面,外部因素包括抑制剂、盐类、温度、压力等[11]。
(1) 气体组分。首先,水合物结构的形成主要与气体组分相关,CH4、C2H6等小分子气体和非烃类气体可形成I 型水合物;C3H8、i-C4H10和非烃类气体可形成II 型水合物;H 型水合物的形成需要2,2-二甲基丁烷、甲基环己烷、甲基环戊烷等大分子配合CH4、N2等小分子[12],在现场未检测到有关组分,在此不予讨论。其次,气体组分的差异化可改变相平衡曲线,在纯CH4中分别加入C2H6和C3H8可以促进水合物的生成,且C3H8与十六面体大空腔的结合作用更强;加入H2S 和CO2也会使相平衡曲线右移,由于H2S 的溶解度更高,对水合物的促进作用更强。
(2) 水合物抑制剂。常用的水合物抑制剂有甲醇、乙醇、乙二醇、二甘醇、三甘醇[13],不同抑制剂的抑制效果不同。随着抑制剂摩尔分数的增加,甲醇的抑制效果基本不变,乙醇和二甘醇的抑制效果变小,乙二醇的抑制效果变大,三甘醇的抑制效果先变小后变大,主要与气- 水两相体系中非电荷基团的数量和性能有关。
(3) 水中盐类。对于气田采出水,水中盐类的成分和含量对水合物相平衡影响较大[14]。由于水中溶解的离子会形成强弱不同的电场,而水合物形成笼型结构需要额外的能量来破坏这种电场,根据分子间氢键的破坏程度,Cl-对水合物的抑制作用比S要强[15]。
(4) 温度、压力。高压、低温环境下容易生成水合物,这是水合物生成的最重要热力学因素[16]。低压下相平衡曲线较敏感,高压下敏感程度降低;低温下相平衡曲线不敏感,高温下敏感程度上升很快。
2 数据来源及研究方法
2.1 数据来源
分类问题方面,以不同的气体组分为输入变量,其中C1+C2的摩尔分数为第一变量,C3+C4+N2的摩尔分数为第二变量,C5+摩尔分数为第三变量,CO2摩尔分数为第四变量,H2S 摩尔分数为第五变量,以水合物的结构类型为输出值,对结构类型进行数字化标签转化,I 型水合物定义为1,II 型水合物定义为2。回归问题方面,以气体组分、压力、抑制剂含量、盐类含量等为输入变量,其中气体组分变量输入与回归模型一致,抑制剂中以甲醇和乙二醇应用最为广泛,且一般不同时使用,以甲醇+乙二醇摩尔分数为第六变量,对水合物形成影响最大的孔隙水中主要含有NaCl 和MgCl2,以NaCl+MgCl2的摩尔分数为第七变量,以井口压力为第八变量,以Du-Guo 公式计算的水合物形成温度为输出变量。
采用华北油田2018—2019 年气井的水合物数据,包括气质组分、水质组分、抑制剂注入量、压力、温度等,这些数据充分考虑了不同影响因素对水合物生成的贡献程度,按照现场工况,CH4摩尔分数为80%~96%,C2H6摩尔分数为0%~5%,C3H8摩尔分数为0%~5%,H2S 摩尔分数为0%~5%,CO2摩尔分数为0%~10%,N2摩尔分数为0%~6%,抑制剂在水相中的摩尔分数为0% ~30% ,NaCl+MgCl2在水相中的摩尔分数为3%~8%,井口经节流后压力不超过5 MPa。取100 组数据,按照4∶1 的比例,取其中80 组作为训练集用于建立模型,取其中20 组作为测试集用于评价模型,部分数据见表1。
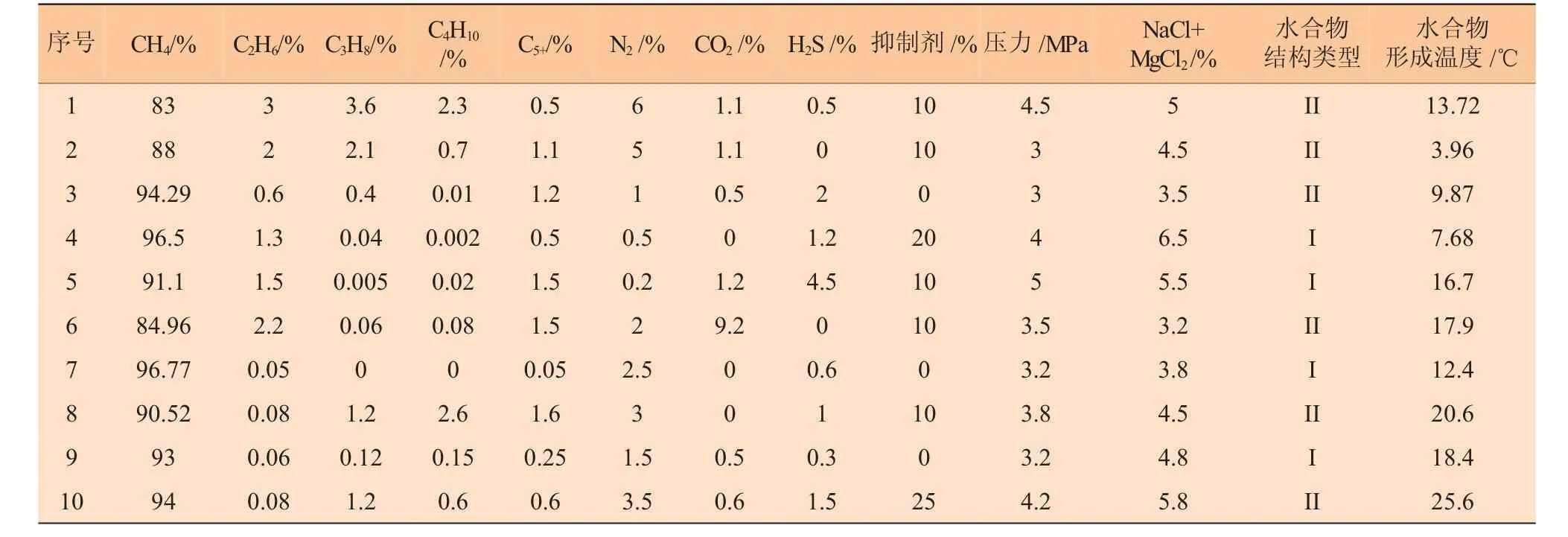
表1 水合物生成条件部分数据
2.2 随机森林算法
随机森林算法RF(Random Forest) 由Leo Breiman 在2001 年提出,根据bootstrap 重抽样方法,从原始数据样本中随机抽取M 个观测值,同时再随机抽取k 个自变量作为分类树的节点,产生成百上千个分类树,是决策树的随机集成[17]。对于分类问题,可根据不同分类树的投票结果,按照特征判定标准决定分类结果,模型为RFC(Random Forest Classification);对于回归问题,可根据预测均值,按照待回归属性决定回归结果,模型为RFR(Random Forest Regression)。随机森林算法中最为重要的两个超参数为树的数量(Nt) 和候选特征子集的数量(Mt)[18],同时随机森林算法本身对节点最小样本数(Nodesize) 不敏感,在此不予考虑。采用运算速度最快的网格搜索法GS(Grid Search),通过对不同固定范围内的超参数进行寻优,得到最优解。
2.3 评价指标
为了防止模型出现高方差或高偏差问题,需要对模型的适应性进行评估,在此采用K 折交叉验证的方式,K 取5。采用二维混淆矩阵对分类模型的预测结果进行评价,评价指标为召回率Recall、精确率Precision 以及召回率和精确率的调和均值Fβ,为了加大Recall 的相对重要程度,β 值取2,公式如下:

采用相对误差百分比、平均绝对百分比误差MAPE、均方根误差RMSE 对回归模型的预测结果进行评价,公式如下:

式中:n 为测试集样本的个数,n=16;y 为实际值;y'为预测值,即经随机森林算法计算的预测值。
3 结果与讨论
3.1 水合物结构类型预测
(1) 超参数Mt预选。采用GS 对超参数Mtry进行预选,采用残差均方值(mean of squared residuals) 和拟合优度(var explained) 作为判定依据,见表2。当Mt=3 时,残差均方值最小,拟合优度最大,模型在计算精度、运算时间、拟合程度上最优。

表2 不同Mt 的残差均方值和拟合优度
当Mt=3 时,对不同决策树的数量Nt的残差均方值变化进行验算,见图1。当Nt>100 时,模型误差较小,但Nt在100~200 之间时,仍有小幅波动。Nt数量过小,训练不稳定,容易过拟合,过大则影响运算速度,综合各方因素,Nt取300。

图1 Nt 数量与残差均方值的关系
(2) 模型的适应性对比。为了进一步评价模型的适应性,对比不同的超参数寻优方法和分类模型,选取经网格搜索优化后的支持向量机分类模型(GS-SVC)、经遗传算法优化后的支持向量机分类模型(GA-SVC)、神经网络分类模型(BP) 与经网格搜索优化后的随机森林分类模型(GS-RFC)进行对比,见表3。

表3 不同超参数寻优方法和分类模型的交叉验证结果
GA-SVC 和BP 算法的训练集和测试集的准确率均较低,训练集的准确率不超过88%,测试集的准确率不超过83%,这是由于SVC 求解的是二次规划问题,计算量较大,虽然经过GA 算法进行了超参数寻优,但适应性较差;BP 算法由于不同层数神经元的连接,容易造成参数膨胀,出现过拟合,且网络深度太浅,数据区分度不高,因此适应性最差。GS-SVC 算法的训练集准确率为92.8%,测试集准确率为87.6%,较GA-SVC 有所提高,证明GS 比GA 的寻优方式更好,模型适应性有所提高。GS-RFC 算法训练集和测试集的准确率均超过了92%,对于不同水合物结构类型,虽然不同气体组分形成的水合物类型具有明显的指向性,但具体轻微的含量差别对于水合物结构的内在影响不易区分,不同组分的区分度不大,随机森林算法可以处理离散型或连续性数据,也可以处理异常数据的缺失,因此模型的适应型最佳。
(3) 预测结果对比。不同分类模型的预测结果对比见表4。

表4 不同分类模型的预测结果
BP 算法的召回率、精确率和Fβ值最小,共出现了4 个分类错误,BP 模型需要具有独立的分类假设,因此分类效果不佳;GA-SVC 算法出现了3个分类错误,数据集的数据具有离散非线性特点,对于除二元分类问题外,表现效果不佳;GS-RFC算法的召回率、精确率和Fβ值分别为0.94、0.91和0.915,共出现了1 个分类错误,在4 种算法模型中的准确率最高,分类效果最好。
3.2 水合物生成温度预测
水合物生成温度预测模型与水合物结构类型预测模型相比,输入变量增加了压力、抑制剂和盐类等参数。超参数寻优过程与分类模型相同,其中Mt=3,Nt=300。选取经网格搜索优化后的支持向量机回归模型(GS-SVR) 和基于径向基核函数的支持向量机模型(RBF-SVR) 与经网格搜索优化后的随机森林回归模型(GS-RFR) 进行对比,预测结果见图2、图3、表5。其中GS-SVR 和RBF-SVR 的平均绝对误差和均方根误差较大,预测模型效果较差,而GS-RFR 预测模型的误差最小,平均绝对误差为1.91%,均方根误差为0.35。主要是由于SVR 模型虽然是将非线性的数据映射到高维空间后再进行分类处理,但仍然属于浅层模型,对于区分度不大、维度较高的数据集预测效果不好,而随机森林算法抗过拟合能力较强,对于预测不平衡的数据集误差很小,属于无偏估计数据驱动的深层模型,更适合水合物生成条件的预测。从相关系数R 来看,GS-RFR预测模型的相关系数最大为0.987,证明预测结果与实际值更接近。
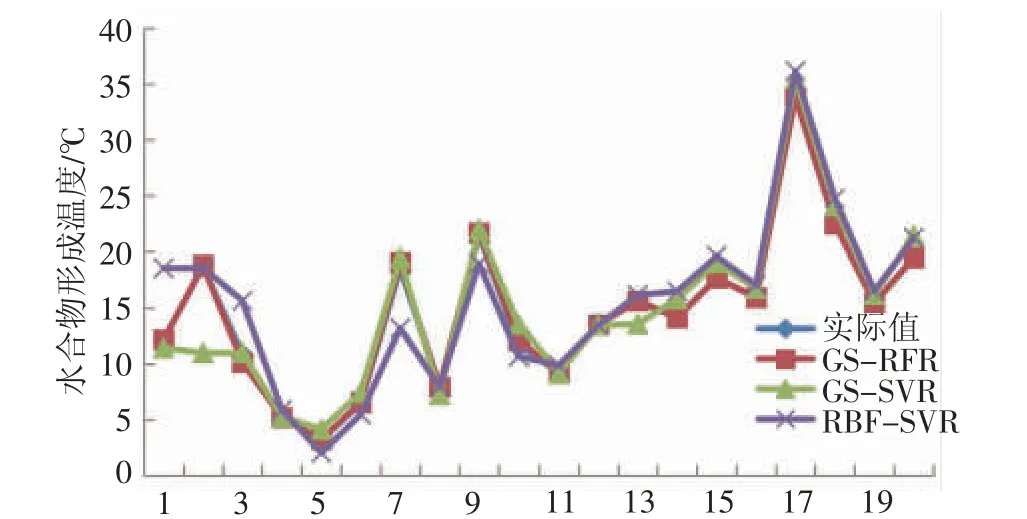
图2 水合物生成温度预测结果

图3 水合物生成温度预测结果相对误差
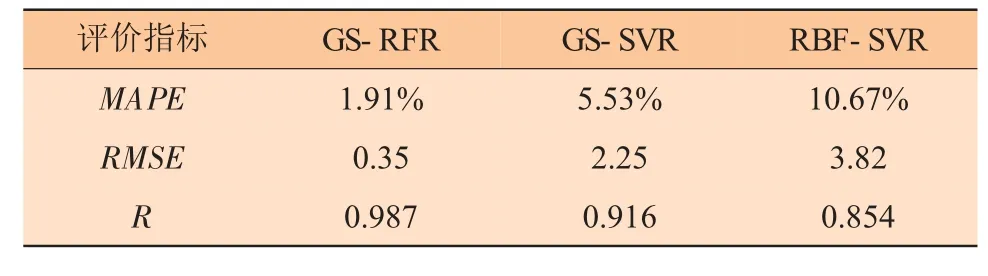
表5 预测结果评价
4 结论
(1) 通过交叉验证,GS-RFC 算法训练集和测试集的准确率均超过了92%,模型的适应性最佳,召回率、精确率和Fβ值分别为0.94、0.91 和0.915,共出现了1 个分类错误,分类效果最好。
(2) 对于水合物形成温度的预测,GS-RFR预测模型的误差最小,平均绝对误差为1.91%,均方根误差为0.35,相关系数为0.987,模型的准确性和保守性最好,属于无偏估计数据驱动的深层模型,证明机器学习算法可为水合物的相关研究提供理论依据和实际参考。
(3) 研究表明,可通过预测结果判断是否采取添加抑制剂或电加热等措施。
猜你喜欢
化工管理(2022年13期)2022-12-02
油气藏评价与开发(2022年5期)2022-09-28
煤气与热力(2021年12期)2022-01-19
海洋石油(2021年3期)2021-11-05
环境卫生工程(2021年3期)2021-07-21
西南石油大学学报(自然科学版)(2021年3期)2021-07-16
河北画报(2020年10期)2020-11-26
当代化工(2019年3期)2019-12-12
英美文学研究论丛(2018年2期)2018-08-27
表面工程与再制造(2014年2期)2014-02-27
