
基于改进SEGNET 模型的图像语义分割
2021-04-29 03:21:40罗嗣卿张志超
计算机工程 2021年4期
罗嗣卿,张志超,岳 琪
(东北林业大学信息与计算机工程学院,哈尔滨 150040)
0 概述
在传统的计算机视觉领域中,研究人员需要通过手动或统计的方式寻找图像中具有代表性的区域或像素点,并根据这些区域或像素点构建对该图像的全局描述特征。而利用全局描述特征解决图像分类和目标检测等计算机视觉问题时,典型的全局描述特征鲁棒性不强,且当光照、视角、明暗以及纹理等发生改变时,描述特征将会随之改变甚至失效。针对该问题,卷积神经网络为其提供一种新的特征构造方式,通过大量的训练样本寻找最佳特征构造方式,并利用这种构造方式对每张图像进行特征建模。因为有大量训练样本的支持,所以使用卷积神经网络得到的特征相比传统的全局描述特征更加稳定,并且对光照和视角等条件更加鲁棒。因此,卷积神经网络逐渐取代了传统方法,并在计算机视觉子领域中得到广泛应用。
图像语义分割作为计算机视觉领域的主要分支,受到了国内外研究人员的广泛关注。在应用于无人驾驶时,图像语义分割技术可自动划分出汽车在行驶过程中需要避让的行人、路障和其他汽车等障碍,良好的语义分割效果促进了自动驾驶技术的快速发展。
目前,国内外研究人员在图像语义分割方面已取得显著的研究成果。文献[1]将深度学习技术引入至图像语义分割领域中,并提出了著名的FCN 结构。该方法利用全卷积神经网络自动对图像进行编码,且端到端的训练方式简化了语义分割问题过程,得到准确率更优的结果。文献[2]在FCN 的基础上加入了生成对抗网络(Generative Adversarial Network,GAN),利用GAN 能够较好拟合未知分布的能力提升了FCN 结构对蓝藻的分割精度。文献[3]提出了SEGNET 模型,该模型的上采样操作中使用了包含池化索引的上采样,以降低池化操作导致的信息丢失,此外还使用跳层连接传递低层特征,增加特征中包含的信息量。文献[4]基于FCN 提出了UNET 结构,并加入了反卷积操作、横向连接以及更多的卷积层,将上采样操作变为可学习的过程,使得从图像特征编码到最后预测结果更加平滑,有效提升分割效果。文献[5]基于UNET 加入了条件GAN,利用判别器提供的额外信息来提升UNET 对咬翼片的分割精度。文献[6]利用循环GAN 中具备的输入与输出能够相互转化的特性对道路场景进行语义分割。文献[7]提出了Deep Lab V3 模型,并在模型中加入了空洞金字塔池化模块,通过整合不同尺度的语义信息来提升模型分割的精确度。
图像语义分割问题的目标是对图像中包含每个像素的类别进行准确预测。然而在实际应用场景中,由于对图像中像素点间的关系考虑不充分,导致模型预测出现分割效果不佳以及同一目标中像素点间的类别预测不一致的现象。针对该问题,本文提出一种改进的SEGNET 模型,一方面通过改进模型的结构来丰富多尺度语义信息,增强模型对输入图像的表征能力,另一方面在原有模型的基础上加入GAN[8]结构,使模型能够考虑像素点间关系。
1 研究过程与方法
1.1 改进的SEGNET 模型
现有SEGNET 模型在实际使用中对整张图像上像素点类别预测的准确度不理想,这主要是因为SEGNET 模型对多尺度语义信息的利用率有限,每个解码器中仅包含一种尺度的语义信息,而多尺度信息是模型对像素点准确分类的重要依据[9-12],缺乏该信息则限制了SEGNET 模型效率的提升。
为解决上述问题,本文对SEGNET 模型结构进行改进。SEGNET 的结构在编码器部分存在多个卷积层,这些卷积层具备捕捉不同尺度特征的能力(即具备不同的感受野),为了使得解码器能够充分利用编码器部分包含的多尺度特征,在SEGNET 中加入一条自底向上的通路。首先,编码器中各层特征在自底向上通路与跳层连接的作用下层层递进整合,得到具备多尺度语义信息的特征。然后,将该特征发送至解码器中进行下一步卷积操作。显然,相比原始的SEGNET 模型通过跳层连接将编码器中的单尺度特征传递给解码器,自底向上通路的加入使得编码器中包含具有不同尺度语义信息的特征得到了充分利用,每个解码器获得了更加丰富的多尺度语义信息,为后续的解码操作提供信息支撑。

图1 改进的SEGNET 模型结构Fig.1 Improved SEGNET model structure
1.2 对抗式训练
在实际应用SEGNET 模型对图像进行语义分割时,通常会出现对图像中同一目标内相邻的像素点预测值不一致的问题,即同属一个目标的像素点类别预测结果中出现了其他类别。这一问题产生的原因在于原始SEGNET 模型训练使用的是交叉熵损失函数,这种损失函数在训练过程中仅关注当前点的类别标签,每一张图像反向传播更新参数时所使用的梯度只与预测的点标签(Predict per pixel)与人工标注的真实点标签(Ground truth per pixel)间的差异有关,而并未考虑图像中像素点与像素点间的关系。
在模型中加入生成对抗网络结构,通过该结构能够较好地拟合未知分布的能力来缓解上述问题[14-17]。具体的方法是将改进的SEGNET 网络作为生成器,同时使用卷积神经网络构建一个判别器。随机初始化生成器后,使用生成器的输出与人工标注的真实值构成样本对,并利用该样本对判别器进行训练直至收敛。当判别器收敛时就具备了分辨输入来源的能力,而对于生成器的输出,判别器的响应为0,对于人工标记的真实值,判别器的响应为1。接下来使用训练好的判别器对生成器进行训练,此时生成器的目标在于尽可能骗过判别器,生成器将尽量去模仿人工标注的真实值。对于每一个人工标注的真实值,点与点间的相互关系作为帮助人类区分像素点类别的重要性质而受到关注,则生成器在模仿真实值时也会学习关注点与点间的相互关系。在加入生成对抗网络后,模型的整体结构如图2 所示。

图2 加入生成对抗网络后的模型结构Fig.2 The model structure after adding the GAN
训练判别器D采用的损失函数(LD)为二分类交叉熵(Binary Cross Entropy,BCE),其中,xn表示生成器G的输入,G(xn)表示生成器的输出,yn表示xn对应的Ground Truth。
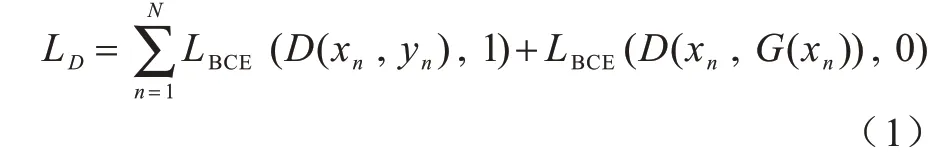
在判别器D训练完成后,将D固定(即暂时固定D中的参数值)并开始训练生成器G,此时的损失函数为:

判别器D损失函数中的第一项会使得生成器对单像素点的预测标签尽可能与真实值相同,第二项包含了判别器对于生成器输出G(xn)的响应,判别器对生成器结果的误检将会导致第二项的数值变大,损失函数的整体数值下降。因此最小化生成器损失函数时,该项的存在会优化生成器产生能够使判别器误判的输出,促使生成器具备关注点与点间相互关系的能力。
模型的最终整体损失函数为:
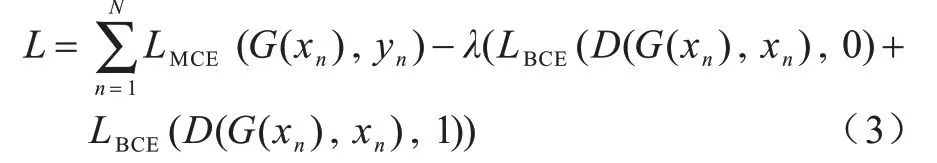
需要注意的是,在本文结构中作为生成器模型的SEGNET 编码器部分使用了Imagenet[18]预训练模型,在解码器部分使用了Xavier[19]初始化,并未使用经过反向传播训练好的SEGNET。这是因为原始的生成对抗网络在训练中,通常因为判别器的收敛速度总是优于生成器而导致生成器训练过程震荡,模型无法收敛,造成整个生成对抗网络训练失败。相应的如果直接使用训练好的SEGNET 作为生成器,那么判别器的训练过程也会出现震荡且无法收敛。使用IMAGENET 预训练模型以及Xavier 初始化的意义是在判别器的优化曲面上选择了一个较好的梯度下降起始点,同时相对于常使用的随机初始化方式,IMAGENET+Xavier 还可有效避免训练初期出现的梯度爆炸或梯度弥散问题,有益于算法的收敛速度和收敛结果。
根据大体积混凝土产生原因和现场施工管理特点,需要从支撑设计、浇筑现场施工工艺控制和成品养生等多个角度综合采用针对性方法进行控制,以达到提前预防的目的。
2 实验过程
2.1 数据预处理
本文选择CAMVID[20]数据集进行对比实验,该数据集由剑桥大学收集整理和标注,是一组分辨率大小为960×720 的道路街景图像构成,标签类别数统一设置为11 类。本文在CCF 卫星影像的AI 分类与识别竞赛提供的数据(下文简称CCF 卫星影像数据集)遥感图像上进行测试,该数据集由高清分辨率遥感影像组成,图像空间分辨率为亚米级,且共包含植被(绿色)、道路(黑色)、建筑(灰色)、水体(蓝色)和其他(白色)5 个类别。数据集中包含5 幅人工标记的遥感图像,平均尺寸为8 000 像素×8 000 像素。
为进一步扩充CAMVID 数据集的图像数量以防止过拟合,本文在对比实验阶段的所有数据预处理中选择与SEGNET 相同的操作对数据集进行增强,主要包括高斯平滑、随机添加噪声点、颜色抖动以及图像的旋转与缩放等,而对测试集与验证集未做数据增强。
由于CCF 卫星影像数据集的数据量稀少且计算资源存在限制,本文先对数据集中的5 幅遥感影像进行划分,将前4 张遥感影像作为训练集,而最后一张作为验证集。接下来将前4 张图像切分(允许重叠)为256 像素×256 像素的图像块,并对得到的图像块添加椒盐噪声、颜色抖动和图像的旋转与缩放等数据增强操作,从而得到10 万幅256 像素×256 像素的图像集合。
2.2 训练过程
CAMVID 数据集上的对比实验是在Ubuntu 16.0.4环境下进行的,并使用Tesla v100 GPU 作为硬件环境,训练过程的批(Batch)选择由8 张图像构成,优化器使用了具有自适应能力的Adam 优化器,学习率初始值设置为0.000 2,针对学习率使用指数衰减策略,动量系数为0.9,共迭代了9 000 轮,在迭代次数为6 000 附近时达到了收敛,具体的训练过程如图3所示。针对CCF卫星影像数据集,在Ubuntu 16.0.4的环境下使用Titan V GPU作为硬件环境,训练过程的Batch 设置为16,优化器选择了具备自适应调节步长的Adam 优化器,学习率的初始值设置为0.000 2,以562 个Batch 为一个epoch,共训练了80 个epoch,具体的训练过程与图3 相同。

图3 训练流程示意图Fig.3 Schematic diagram of training process
2.3 测试过程
模型的测试阶段中仅使用生成器,并将测试样本送入生成器后得到预测结果。测试过程中为避免出现偏差,调整测试样本的输入尺寸与训练样本尺寸相同,且测试过程中不使用数据增强操作。
3 实验评价标准以及结果分析
3.1 评价标准
在图像分割中,通常使用平均像素精度(Mean Pixel Accuracy,MPA)和均交并比(Mean Intersection Over Union,MIOU)这2 种衡量指标来衡量算法精度,其中,MPA 表示各个类别像素准确率的平均值,MIOU 表示语义分割的标准度量,其计算模型预测得到的标注图与人工标注图的交集与并集之比。MPA 和MIOU 的计算方法分别如式(4)和式(5)所示。

3.2 实验结果分析
在CAMVID 数据集和CCF 卫星影像数据集上,以FCN、DeepLabV2[21]、DeepLabV3、原始SEGNET 模型和原始SEGNET+GAN 模型作为对比模型,验证本文改进SEGNET 模型和改进SEGNET+GAN 模型的性能优势。
3.2.1 CAMVID 数据集上的实验结果
7种模型在CAMVID 数据集上的MPA 与MIOU 实验结果对比如表1 所示。从表1 可以看出,改进SEGNET+GAN 模型的MPA 与MIOU 都超越了原始SEGNET 模型、FCN 模型和DeepLab V2 模型,并且达到了与DeepLab V3 相近的效果。

表1 7 种模型在CAMVID 数据集上的实验结果对比Table 1 Comparison of the experimental results of seven models on the CAMVID dataset %
原始SEGNET、原始SEGNET+GAN、改进SEGNET和改进SEGNET+GAN 模型在CAMVID 测试集上对建筑物、树和天空等11种类别图像分割的像素精度如表2所示。从表2 可以看出,与原始SEGNET 模型相比,在加入GAN 结构后,模型对建筑物、树、天空和道路等较大目标类别的像素精确度有明显提升,并且加入自底向上通路的改进SEGNE 模型得到的提升效果更加均衡,在各个类别上的像素精度都有较大提升。

表2 4 种模型在不同类别图像下的平均像素精度Table 2 MAP of four models in different types of images %
表3 给出了在Tesla V100 硬件条件下,5 种模型对测试集上的各张图像预测的平均时长。从表3 可以看出,本文改进SEGNET+GAN 模型在测试阶段的用时与SEGNET 模型较为相近。与DeepLab V2 和DeepLab V3 模型相比,本文模型在得到更强和相近的分割效果的同时,推理速度更快。这是因为本文模型仅在训练时增加了参数量,在测试时并未有大量参数增加,因此对测试时的推理速度影响较小。
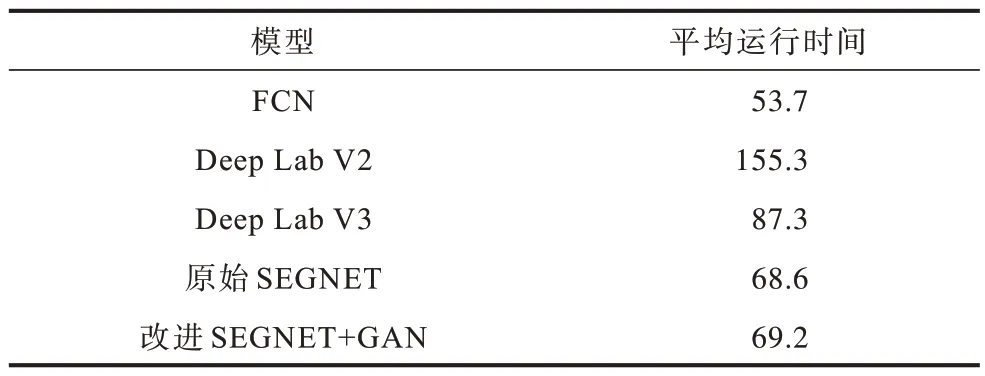
表3 5 种模型的平均测试运行时间Table 3 Average test running time of five models ms
为了更加直观地体现加入GAN 结构对像素类别一致性的提升效果,本文对原始SEGNET 模型与加入GAN 结构后的原始SEGNET 模型的预测结果进行可视化处理,对比结果如图4 所示(彩色效果见《计算机工程》官网HTML 版)。通过对比图4(b)和图4(c)可以看出,与传统的SEGNET 模型相比,在原始SEGNET 模型中加入GAN 后,模型对相邻像素间的类别一致性有明显改善,且包含在同一目标中的像素点类别误检率大幅降低。

图4 原始SEGNET 模型和原始SEGNET+GAN 模型在CAMVID 数据集上的可视化结果对比Fig.4 Comparison of the visualization results of the original SEGNET model and the original SEGNET+GAN model on the CAMVID dataset
3.2.2 CCF 卫星影像数据集上的实验结果
在Titan V 的硬件条件下,5 种模型在CCF 卫星影像数据测试集上的MPA 和MIOU 结果对比如表4所示。通过表4 可以看出,本文模型的效果均优于传统的SEGNET 模型和DeepLabV2 模型。

表4 5 种模型在CCF 数据集上的实验结果对比Table 4 Comparison of the experimental results of seven models on the CCF dataset %
本文对原始SEGNET 模型和原始SEGNET+GAN模型的预测结果进行可视化处理,对比结果如图5 所示(彩色效果见《计算机工程》官网HTML 版)。从图5可以看出,原始SEGNET+GAN 对道路(黑色)中出现的同属一目标的像素类别不一致现象有所压制,在原始SEGNET 预测中出现的建筑被植被包围的错误预测也大幅降低。

图5 原始SEGNET 模型和原始SEGNET+GAN 模型在CCF 数据集上的可视化结果对比Fig.5 Comparison of the visualization results of the original SEGNET model and the original SEGNET+GAN model on the CCF dataset
4 结束语
针对原始SEGNET 对同一目标中像素点类别预测结果不一致的问题,本文提出了改进的SEGNET模型。通过在原始SEGNET 中加入一条自底向上的通路,以充分利用模型中包含的多尺度语义信息,提升模型单像素的分类准确率。此外,在模型训练过程中引入有助于模型学习联合概率分布的生成对抗结构,解决同一目标中像素点类别预测不一致的问题。实验结果表明,改进的SEGNET 模型在CAMVID 数据集上取得了相比原始SEGNET 模型更优的分割效果。下一步将使用残差网络替换当前骨干网络,并对模型的上采样过程进行改进,以减少上采样过程中引入的噪声,进一步提升模型的分割效果。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
电脑知识与技术(2018年35期)2018-02-27 13:29:44
数学物理学报(2017年5期)2017-11-23 07:51:31
自动化学报(2017年11期)2017-04-04 02:52:44
新校长(2016年8期)2016-01-10 06:43:59
电视技术(2014年11期)2014-12-02 02:43:28
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
新课程学习·中(2013年3期)2013-06-14 05:55:20
