
基于Q 学习的无人机辅助WSN 数据采集轨迹规划
2021-04-29 03:21:14蒋宝庆陈宏滨
计算机工程 2021年4期
蒋宝庆,陈宏滨
(桂林电子科技大学信息与通信学院,广西桂林 541004)
0 概述
无线传感器网络(Wireless Sensor Network,WSN)是传感器、计算机、无线通信及微系统等技术发展融合的产物[1],是物联网的基础技术之一[2],其由大量廉价微型传感节点组成,通过使用相互连接的智能传感器来感知和监控环境。无线传感器网络应用范围广泛,包括环境监测、工业监测、交通监测等各个方面。由于传感器的大数据环境和大规模无线传感器网络的出现,因此亟需新的节能数据采集技术。目前,无线传感器网络的数据采集方法主要集中在移动数据采集器和汇聚技术方面。随着智能城市、智能家居等概念的提出,无线传感器网络被认为是智能环境的核心技术。无线传感器网络能够以智能通信的方式交互建立一个智能网络,从而产生一个能够处理用户随机需求的应用系统。传统的无线传感器网络结构大多由静态节点组成,这些节点密集地分布在传感器区域内。近年来,人们提出了多种基于移动收集器的无线传感器网络结构,利用移动性来解决无线传感器网络中的数据收集问题,其中,无人机(Unmanned Aerial Vehicle,UAV)具有高机动性、灵活、可达视距点和成本低等特点。由于下一代无线通信领域将网络部署从地面转移到空中,因此无人机被广泛用作汇聚节点与基站之间的通信枢纽[3]。
然而,无线传感器网络的移动性也带来了静态无线传感器网络中不存在的一些问题。文献[4]指出其面临的挑战有感知侦查、唤醒-休眠机制、传输可靠性和移动控制,其中,移动控制指的是当移动收集器的运动可控制时,必须设计访问网络节点的策略,因此,必须定义移动节点的路径和停留时间,使网络性能达到最高。一般而言,轨迹规划分为两类:一类是静态轨迹规划,针对不随时间变化的轨迹;另一类是动态轨迹规划,指为满足数据采集的某些特定条件(例如实时性),能够随时间变化而改变自己下一步轨迹的规划。
本文根据无线传感器网络的移动性,提出非连续无人机轨迹规划算法Q-TDUD。考虑无人机辅助无线传感器网络数据采集的场景,通过相关工作的对比,针对数据采集中各节点数据率随机的问题建立相应的延时模型和能耗模型。在此基础上,结合Q 学习算法设置合适的奖励制度并对场景中的无人机进行迭代训练,使其能够智能地根据场景状态的变化做出相应的轨迹调整。
1 相关工作
多数从静态轨迹规划角度出发设计的无人机飞行策略未考虑无人机自身能耗与飞行轨迹之间的关系,因此,本文主要关注动态轨迹规划方面的研究。文献[5]证明了无论是速度最大化还是能耗最小化的轨迹规划都不是最优的方案,一般而言,轨迹规划需要在这两个目标之间达到最佳的平衡。文献[6]提出空对地无线通信的基本能量权衡问题,推导出无人机和地面终端的能量消耗表达式,得到了两者之间权衡后的最优地面终端发射功率和无人机轨迹。文献[7]联合优化传感器节点唤醒机制和无人机轨迹规划机制,在最小化所有传感器节点最大能耗的同时确保每个传感器数据的可靠传输。文献[8]研究无人机对传感器进行充电的轨迹规划问题,讨论总能量最大化引起的远近公平问题,进而提出一种最优航迹驱动的连续式盘旋航迹方法。文献[9]研究无人机组播系统,提出一种基于虚拟基站布局的新概念和凸优化的路径设计方法。
上述工作均为连续式的无人机轨迹规划研究,即在无人机执行任务之前计算出飞行轨迹,按照该轨迹规划结果连续式飞行直至任务结束。然而,连续式无人机的飞行轨迹规划无法满足实际应用场景中数据收集的可靠性和有效性要求。只有当无人机进入汇聚节点感知范围且汇聚节点完成数据汇集时,无人机才对汇聚节点进行感知,这会造成不必要的能量消耗及数据采集延迟。对此,一些研究者提出非连续无人机轨迹规划。文献[10]针对单无人机给多地面用户进行充电的问题,提出一种基于遗传算法的非连续飞行方案,迭代搜索出最优悬停点并优化相应的悬停时间。文献[11]运用机器学习领域的相关知识,利用认知代理在无线传感器网络中建立基于学习、推理和信息共享的主动学习决策,使无人机能够在多个约束中智能地选择执行悬停或者飞行策略,得到非连续无人机飞行轨迹。文献[12]提出一种改进的多无人机Q 学习算法来解决分散的无人机轨迹规划问题,同时计算使用嵌套马尔科夫链得到的有效数据传输概率。文献[13]研究用户端信息(如位置、发射功率、信道参数等)无法访问情况下的上行速率之和最大化问题,将该问题描述为一个马尔科夫决策过程(Markov Decision Process,MDP),通过无模型强化学习来解决,同时由实验结果表明,无人机能在未知用户侧信息和信道参数的情况下,根据所学习的轨迹对地面用户进行智能跟踪。
为优化无人机的能耗及无线传感器网络的数据采集效率,上述工作主要从无人机的飞行能耗和悬停能耗以及数据传输的信道分配来进行问题建模,但没有考虑到负责接收和发送数据的汇聚节点存在汇聚完成时间不一致及数据量大小不一致的问题,忽略了实际应用中节点数据产生速率随机性的影响。在进行无人机轨迹规划时,悬停点顺序及悬停时间应得到进一步优化。由于强化学习中的Q 学习具有单步奖励机制和离线学习等特点,其能将悬停动作加入无人机动作集中,通过一定次数的迭代得到最优飞行策略,优化悬停点顺序和悬停时间,因此对于合理规划无人机轨迹、保证有效数据率较高且提高能量效率的问题,可以结合强化学习理论进行分析。
本文考虑节点数据产生速率的随机性以及非连续无人机辅助数据采集的应用场景,提出一种基于Q 学习的非连续无人机轨迹规划算法Q-TDUD。在建立汇聚节点时,利用基于距离的K-means 算法对网络中节点分簇并确定汇聚节点,根据传感器网络中单个节点在周期内的数据速率改变概率以及单位数据量和单位距离转发数据的延迟时间,构建汇聚节点的延迟差异模型。在规划非连续无人机轨迹时,将无人机轨迹设计整体细分为离散马尔科夫过程[14],并应用强化学习[15]中的Q 学习算法来优化无人机的飞行轨迹。在无线传感器网络数据收集过程中,将无人机的位置和运动方向作为强化学习中的状态集和动作集。在每次执行某个策略后,收到的汇聚节点的反馈将被用作更新Q 表的即时奖励,通过奖励对Q 表进行更新,从而确定无人机在每个状态的下一步策略。重复该过程直至找到最佳飞行轨迹。不同于现有多数无人机辅助数据采集的轨迹规划研究,本文考虑各簇规模不一致导致相应汇聚节点汇聚完成时间不一致的情况,设置延迟容忍时间来约束无人机数据采集任务的完成效率,提出非连续无人机轨迹规划问题,并利用Q 学习中的奖励机制设置两种奖励方式,使无人机能够智能地选择自己的悬停状态或飞行状态,将传统的连续式无人机飞行轨迹规划转换为非连续的轨迹规划。
2 系统模型
2.1 延时模型
无线传感器网络由大量传感器节点和少量执行器节点构成,其应用涵盖广泛,从工业过程的自动化到系统的通风量和温度控制等均有所涉及[16]。在无线传感器网络中,传感器节点负责从物理世界收集信息,执行器节点负责根据信息做出独立的判断,并执行相应的任务[17-19],传感器节点一旦部署完成,不再移动或者改变。
本文将n个静态传感器节点X={x1,x2,…,xn}随机均匀地部署在大小为W的网络范围内,初始化单个节点的数据生成速率为Va。无人机有能量损耗速度快、自身储能小和工作时长短等缺点,若遍历网络中的每一个节点进行数据采集,则采集时间过长,会出现部分节点的缓存区数据溢出或无人机自身能耗不足导致任务终止等情况。因此,本文将节点组织成簇,在簇中选出汇聚节点负责接收簇内各节点的数据并与无人机进行数据交互,以提高网络的扩展性和节点能量的利用率。此处使用K-means 聚类算法[20]对随机均匀分布的节点进行分簇,得到包含k个簇的集合C={c1,c2,…,ck},其中每个簇的簇成员个数为cn(k),汇聚节点位置表示为,k∈{1,2,…,m},汇聚节点的最大缓存数据量为Dmax。图1 为传感器网络节点数量为30、分簇个数为4 时的节点分簇示意图,将各簇分别用4 种不同的颜色表示(彩色效果见《计算机工程》官网HTML 版),其中,黑色点表示汇聚节点,是距离各簇质心最近的节点。

图1 K-means 分簇结果(k=4,n=30)Fig.1 K-means clustering result(k=4,n=30)
在簇成员向汇聚节点进行数据转发的路由选择上,本文考虑分级多跳路由的方式[21]。分级多跳路由的核心思想是划分节点之间的优先级,首先计算出簇成员节点到汇聚节点的距离,然后根据其距离将簇成员节点由近及远划分为3 个等级。数据转发规则为节点数据只能由较远的低级节点发送给较近的高级节点,不可跨级上传。簇内路由的系统模型如图2 所示,图中心的黑色点为该簇的汇聚节点,浅灰色点为一级转发节点,深灰色点为二级中间节点,白色点为三级边缘节点。当开始数据汇集时,簇成员节点通过多跳的方式将数据转发至汇聚节点进行数据汇集。
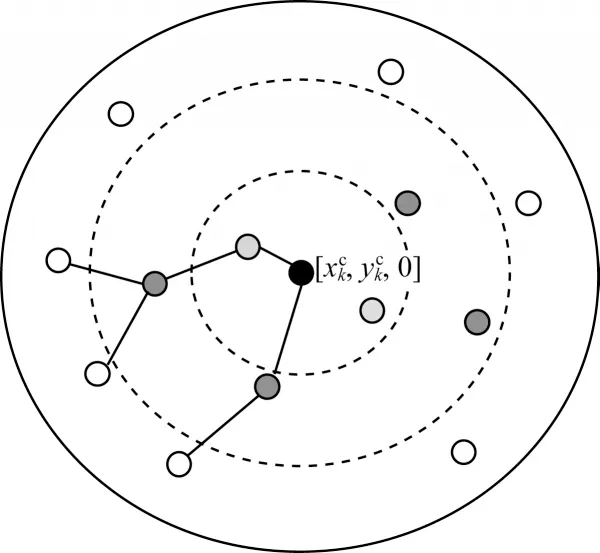
图2 簇内路由Fig.2 Routing within the cluster
对于传感器节点而言,需要考虑采集数据量和能量消耗之间的折中。处于网络区域边缘的节点只需要将收集的数据发送给移动采集器,能量消耗相对较少,而靠近汇聚中心的节点同时还需要为边缘节点转发数据,消耗的能量较多。因此,边缘节点必须对采集到的数据进行一定的压缩和融合处理后再发送给下一跳节点。数据融合机制减少了需要传输的数据量,能够减轻网络的传输拥塞,降低数据的传输延迟,在一定程度上提高网络收集数据的整体效率。用Dk表示汇聚周期Tv内汇聚节点的数据量,用Pn表示节点的数据产生速率在一个汇聚周期Tv内发生改变的概率,用Pc表示边缘节点的数据融合率,则根据文献[21]中对簇头节点汇集数据量的计算方式,在汇聚周期Tv内各簇的数据量为:

在实际应用中,人们希望无人机的单次采集效率最大化。考虑到无线传感器节点监测环境的不确定性以及无人机能耗特性的约束,需要设置汇聚节点的最小数据量大小,使得当汇聚节点只有在汇聚数据量大小达到规定时,无人机才将此汇聚节点考虑至轨迹规划内,若汇聚节点在时隙t未达到最小数据量,则产生汇聚延时。本文通过设立延时机制来提高无人机的单次采集效率。用Ds表示汇聚节点最小数据量,若改变量为∆Va,则Va+∆Va∈[Vamin,Vamax],其中,Vamin为节点最小数据产生速率,Vamax为节点最大数据产生速率。此时可以计算得到汇聚节点的延时为:

(k)为簇k的平均数据生成率,表示为:
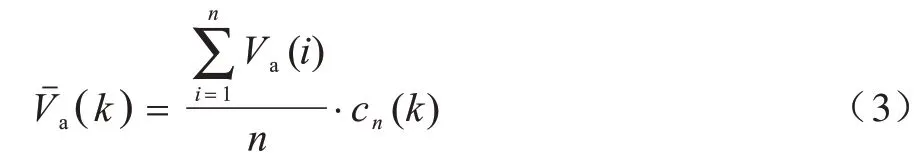
2.2 能耗模型
考虑到在节点度、最大时间延迟等条件相同的情况下,移动采集器的轨迹长度与传感器网络中节点的总跳数成反比[22],若联合考虑无人机与传感器网络的总能耗,当改变网络拓扑使传感器网络节点之间数据传输达到最小时,会一定程度忽略无人机的路径复杂度,使无人机飞行能耗增加,从而系统中的能耗无法达到最优。因此,本文主要考虑无人机的能耗。
如图3 所示,无线传感器网络中的汇聚节点负责接收和处理从子节点多跳上传来的数据,无人机在空中作为一个移动采集器对地面上k个汇聚节点进行数据采集。

图3 无人机采集无线传感器网络数据的场景Fig.3 A scene where UAVs collect data in WSN
将无人机采集数据的总过程分为T个时隙,以便于迭代推导。假设无人机以恒定速度VUAV飞行在固定高度H上空。每个时隙无人机的位置为U={U1,U2,…,UT}。其中,Ut=[xu(t) ,yu(t) ,H]。由于无人机的计算能耗与飞行能耗相比较小,因此可忽略不计。另一方面,本文将无人机完成收集所有汇聚节点数据的任务作为一轮。在每一轮开始时,各汇聚节点的汇聚延时会随着各簇成员节点数据生成速率的更新而更新,因此,在每轮无人机开始采集数据到完成采集的过程中,各汇聚节点的数据量大小是固定的。又因为无人机只有进入汇聚节点的感知范围r时才会与该节点进行数据传输,保证了通信信道较大的稳定性和较小的差异性,所以本文忽略无人机与各汇聚节点之间的数据传输能耗。因此,在保证无人机采集效率的同时提高无人机的能量效率,是优化轨迹性能的关键。设ph为无人机的悬停功率,d(t)为一个时间间隙内无人机飞行距离,则无人机悬停能耗Eh和飞行能耗Ef表示为:

由于无人机在飞行过程中加入了悬停策略,会出现某些汇聚节点数据汇集完成但是无人机尚未进入其采集范围的现象,这使得汇聚节点进入等待时间易造成数据丢失及缓存溢出的情况,从而无人机后续的数据采集将变得毫无意义,因此有必要设置一个等待时间阈值来约束等待时间过长的情况。根据传感器缓冲内存限制及数据汇集的实时性要求,本文规定当无人机在时隙t内与汇聚节点k进行数据采集时,若汇聚节点k的等待时间Tw(k)≤γ,则无人机采集的数据为有效数据,Tw(k)=Th(k) -t。若不在此等待阈值范围内,则将此数据称为无效数据。等待阈值γ定义为:

其中,为平均延迟时间,η、ξ为常数参数。
3 Q-TDUD 算法描述
在无人机轨迹规划中,无人机的能量消耗及通信质量等问题始终是研究者的关注重点。上节已求解出无人机的飞行能耗和悬停能耗,下节将解决在保证无人机与传感器之间上行链路传输稳定的同时使无人机整体能耗最小的问题。本文考虑每架无人机的效用为其任务成功采集有效数据总量,因此,可以通过设计非连续无人机的轨迹来最大化有效数据总量。
本节将给出非连续无人机的轨迹规划,最大化总传输速率和能量消耗的比值。考虑速度的约束,将其建模为如下最优化问题:

Ri表示CN(i)的传输速率,如式(8)所示:
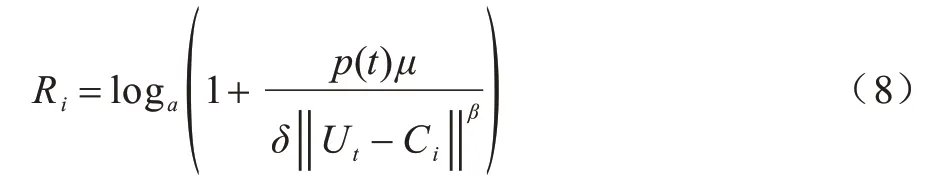
其中,μ表示信道增益,β表示距离衰减,Ci表示汇聚节点所在位置,δ表示信道噪声功率。
由于优化问题是非凸的,全局最优轨迹很难找到,并且在无人机未知汇聚节点位置信息的情况下,只有在多次执行采集操作后才能观察到能耗及有效数据的收集情况,因此本文基于强化学习确定无人机每个状态的动作执行策略来解决式(7)所示的问题。Q 学习算法是强化学习中基于值函数的算法,对任何有限的马尔科夫决策过程,Q 学习都可以找到一种最优策略。Q 学习涉及一个代理(agent)、一组状态S以及一组动作A。通过在环境中执行动作使得代理从一个状态转移到另一个状态,在特定状态下执行动作会提供奖励。简单来说,Q(s,a) 为某一时刻s状态下(s∈S),采取动作a(a∈A) 能够获得的奖励期望。环境会根据代理选择的动作反馈相应的奖励r,因此,Q-TDUD 算法的主要设计思想是以状态s与动作a构建成一张Q 表来存储Q值,最后根据Q值来选取能够获得最大奖励的动作。在非连续无人机轨迹规划中,将无人机在各时隙的位置信息设置为Q 学习中的状态集,再将悬停态加入无人机的动作集之中,构建一个关于无人机当前位置状态和动作的Q 表。在算法的迭代过程中,环境根据下一个状态s,中选取的最大Q(s,,a,) 值乘以奖励衰变系数,再加上真实奖励值计算得到Q的现实值Q,(s,a):
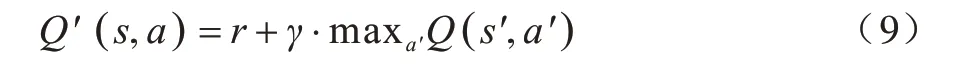
其中,γ为奖励性衰变系数,γ越接近1 代表它越有远见会着重考虑后续状态的价值。当γ接近0 时会着重考虑当前的利益影响,r为当前行为奖励,Q(s,,a,)为下一状态中的最大Q值。
根据以上推导可以对Q值进行计算,即对Q 表进行更新。假设学习率为α,采用时间差分的方法进行更新,则更新后的Q值为:

Q 学习的最大目标是求出累计奖励最大策略的期望。接下来需要明确学习环境、状态集、动作集、奖励设置以及Q 表的更新过程[23]。
1)环境。单架无人机从固定起点飞行,向通信半径范围内的节点广播数据包。在每个周期开始时,汇聚节点更新其数据量大小及数据汇集完成时间。无人机的位置为强化学习的状态集,行为为动作集。在每轮采集开始时,无人机对地面汇聚节点的位置未知,但可通过接受各汇聚节点的反馈来获取每个行为的好坏。
2)状态集S={g1,g2,…,gx}。根据文献[24]中的网格法使无人机的位置状态离散化。将无人机需要采集的网络区域划分为x个网格{g1,g2,…,gx}。文献[25]指出:网格粒度越小,节点位置及无人机状态表示会越精确,但同时会占用大量的存储空间,算法的搜索范围将按指数增大;网格粒度太大,规划的轨迹会很不精确。因此,此处的x与传感区域大小及VUAV如式(11)所示:

其中,W为传感区域大小,λ为常数参数。在每次无人机改变位置状态后将对其位置进行判定,划分到所属的状态集,以便于Q 表的更新。
4)奖励。奖励机制分为悬停优先和非悬停优先两种情况。第1 种是悬停优先的情况,忽略无人机与汇聚节点进行数据采集所耗费的时间,若当前位置状态下无人机到延时最小的汇聚节点的飞行时间小于该节点的延迟时间时,即tf<minTk,无人机动作奖励为悬停优先,其中,tf为无人机到最小延时节点的预估时间,当δ=1 时悬停动作奖励为r=rh,其他动作奖励为0。第2 种是非悬停优先的情况,若tf≥minTk,不满足第1 种奖励情况,则为非悬停优先。两种情况的奖励设置为:
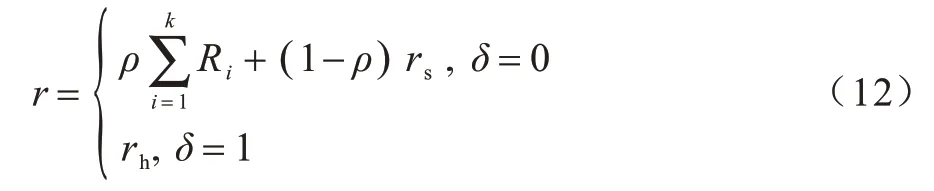
当δ=0 时,使当下无人机状态的各汇聚节点完成时间序列{T1(t),T2(t),…,Tl(t)},根据文献[26]方法进行归一化处理得到{s1(t),s2(t),…,sl(t)},便于奖励的计算。笔者希望无人机朝着延时最小的节点且传输数据较大的方向飞行,因此:

当选择的动作a 使无人机与簇头i的距离减小时,τ=1。
Q-TDUD 算法的伪代码如算法1 所示。其中:第1 行初始化了无人机的位置、地面静态节点的位置以及动作集和Q 表;第2 行~第3 行规定了无人机的总采集轮数,每轮开始前要更新无人机的位置坐标和汇聚节点的延时;第4 行对无人机是否对所有的汇聚节点执行完采集任务的判定,若还有节点尚未采集则程序仍然往下执行,S是每次循环开始时程序根据无人机当下位置坐标判断得到的状态集中的状态;第5 行进行动作选择。为使结果更具非偶然性,在确定选择动作的策略时设置一个冒险概率ξ,这样代理有一定机会不遵从Q 表中当前状态的动作最大值来选择动作,而是从剩余动作中随机选择一个动作执行,有效避免了代理陷入某个动作并反复执行所带来的时间浪费;第6 行~第12 行是对Q 表的更新。在奖励计算方面,根据上述的两种奖励机制,首先计算出当前tf与minTk的大小比较情况。若tf<minTk,进入第1 种悬停优先奖励模式,此时的无人机如果执行的不是悬停动作,则奖励为0;若tf≥minTk,则奖励进入非悬停优先模式,如果此时无人机执行的不是最佳动作则无法获得最大奖励。算法第12 行将当前状态的最大Q值动作的选择策略设置为1,使下一轮代理在进行动作选择时在不冒险的情况下得到最大Q值的动作选择策略。
算法1Q-TDUD 算法

4 仿真与结果分析
本节将对比基于强化学习的无人机轨迹规划的性能仿真结果,包括任务完成时间、有效数据率、有效数据收集以及有效数据和能耗之比。首先设置一个W=100 m×100 m 的正方形区域,在其中随机均匀分布300 个节点,节点的分布情况及分簇多跳结果如图4 和图5 所示(彩色效果见《计算机工程》官网HTML 版)。图4 中的黑色点为各簇的簇头节点,图5 展示了簇内节点的分级情况以及数据的多跳传输过程,图中右下角图案为六角星、右三角形、五角星的点分别为文献[21]中簇内分级算法计算所得的三级、二级、一级节点,黑色的线段表示不同级别节点之间的数据传输路径。

图4 K-means 分簇结果Fig.4 K-means clustering result

图5 簇内节点分簇多跳结果Fig.5 Grading and multiple hops result within a cluster
基于上述网络结构,设置节点初始数据产生速率Va=10bit/s,Vamin=5bit/s,Vamax=50bit/s。节点数据速率改变概率Pa=0.9,数据融合率Pc=0.8。Ds=5×104bit,Tv=3 s。无人机的初始位置为[50,50,H],H=5 m,悬停功率ph=50 w,飞行功率pf=75 w,飞行速率VUAV=6 m/s。延时模型参数为η=0.01,ξ=3,=1。
针对上文无线传感器网络节点部署,将Q-TDUD算法参数设置为ξ=0.2,β=2,p(t)=5 w,λ=0.057,ρ=0.3,学习率α=0.01,奖励衰减系数γ=0.9,并与连续式最小旅行商轨迹规划算法(TSP-continues)[27-28]、非连续最小旅行商算法(TSP)、连续式下一跳最短路径规划算法(NJS-continues)以及非连续下一跳最短路径规划算法(NJS)进行比较,Matlab 仿真结果如图6~图9 所示。TSP 方案的主要原理是先将网络中的节点按照K-means 方法进行分簇并找到簇头,簇成员节点按照前文介绍的文献[21]簇内多跳方法将数据传至簇头,再用文献[27]中蚁群求解TSP 问题的算法找出无人机经过全部簇头的最优轨迹。NJS方案中的簇头选取与簇内节点数据的多跳传输部分与Q-TDUD 一致,在无人机轨迹规划上,簇头节点将根据已被采集和未被采集两种状态分为两个集合,在每轮采集中无人机基于当前的簇头位置与未被采集集合的簇头节点计算欧氏距离,距离最小的当选为无人机执行下一个采集任务的位置。TSP 与NJS方案又分为连续式和非连续式:连续式指的是无人机没有悬停机制,若进入汇聚节点感知区域内但汇聚节点并没有达到汇聚完成状态时,无人机会继续按照计划轨迹行驶,直至将所有数据采集完毕;非连续是指当无人机按照计算出的轨迹行进至某个汇聚节点感知区域内时,若该节点尚未达到汇聚完成状态,无人机会开启悬停机制,悬停在感知区域内直到采集完该节点数据才执行下一个任务。

图6 不同簇规模下的平均任务完成时间Fig.6 Average task completion times for different cluster sizes
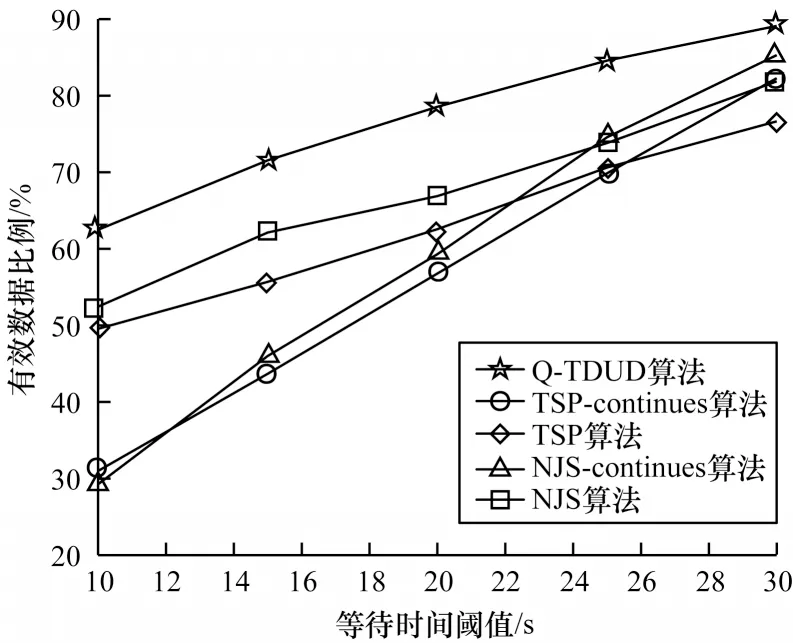
图7 不同等待时间阈值下有效数据率Fig.7 Effective data rates at different waiting time thresholds

图8 1 000 轮内有效数据收集情况Fig 8 Situation of the collection of valid data within 1 000 rounds

图9 1 000 轮内有效数据和能耗比值Fig 9 Effective data and energy consumption ratio within 1 000 rounds
由图6 可以看出,在网络中不同的簇规模下,Q-TDUD 算法完成任务的时间比其他4 种算法完成任务的时间要小,这是因为Q-TDUD 算法考虑到了各汇聚节点的随机性,优先对汇聚完成时间较小的节点执行数据采集任务,显著降低了无人机完成数据采集任务的时间,使网络负载更均衡。
等待时间阈值增大情况下各算法对应的有效数据率变化如图7 所示。等待时间阈值根据式(4)计算得到,图中的横坐标分别是ξ=5,η={0.01, 0.015,0.025,0.03,0.035,0.045} 时计算得到的等待时间阈值。由于传感器小巧轻便的外形设计,其数据缓存区大小受到相应限制,因此等待时间阈值的设置能够揭示无人机是否能及时地执行数据采集任务。从结果图中可以得出,当等待时间阈值增大时,各算法的有效数据比例在增大,但当等待时间阈值较小时,Q-TDUD 算法的性能明显优于其他基准算法,这说明Q-TDUD 算法能使无人机及时地飞行至已完成数据汇集的节点上方采集数据,提高传感器网络的数据采集实时性。
各算法能量效率的比较如图8 和图9 所示。图8显示在η=0.01,ξ=3 的等待时间阈值下,各算法的有效数据量随着循环次数增大而增加,其中Q-TDUD算法略高于其他基准算法,结合能耗情况来看,Q-TDUD 算法的能量效率明显由于其他基准算法。图9 中归一化处理后的有效数据和能耗的比值也显示Q-TDUD 算法性能更好。
5 结束语
针对无线传感器网络中各节点数据产生速率随机和汇聚节点状态不一致的场景,本文提出一种基于强化学习的无人机飞行轨迹规划算法Q-TDUD。该算法采用强化学习的思想,根据无人机的数据传输速率和汇聚节点的反馈信息更新Q值,据此得到无人机当前状态的下一步动作。无人机执行动作后会收到汇聚节点的反馈信息并用于Q 表的更新,经过迭代计算最终得到最佳无人机飞行轨迹。实验结果表明,与连续式无人机轨迹规划方案相比,非连续无人机轨迹规划方案在收集的有效数据总量上约增加了1 倍,并且随采集轮数的增加呈继续增多的趋势,在平均任务完成时间上也比连续式方案缩短近50%,更贴近无人机轨迹规划中实时性这一设计要求。本文提出的单无人机辅助无线传感器网络的数据收集轨迹规划方法较难适用于大规模无线传感器网络,因此,下一步将研究多无人机辅助数据收集的联合轨迹规划问题并设计相应求解算法。
猜你喜欢
昆钢科技(2022年2期)2022-07-08 06:36:14
当代水产(2021年10期)2022-01-12 06:20:28
无线互联科技(2021年4期)2021-04-21 10:12:36
建材发展导向(2021年23期)2021-03-08 01:05:38
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
小猕猴智力画刊(2019年3期)2019-04-19 00:01:52
电子制作(2018年23期)2018-12-26 01:01:08
华人时刊(2018年15期)2018-11-10 03:25:26
现代装饰(2018年5期)2018-05-26 09:09:39
