
一种用于代码注释自动生成的语法辅助复制机制
2021-04-29 03:21:08许柏炎蔡瑞初梁智豪
计算机工程 2021年4期
许柏炎,蔡瑞初,梁智豪
(广东工业大学计算机学院,广州 510006)
0 概述
目前,代码托管平台Github 的提交量已达10 亿,涉及337 种编程语言,但是其中大量代码缺乏可读的自然语言注释[1]。代码注释是软件开发的重要环节,可大幅提高代码的可读性,但是其过程十分耗时[2]。随着深度学习技术的应用,自然语言生成任务得到快速发展,其中典型代表有机器翻译[3-4]和文本摘要生成[5-7]等任务。代码自动注释是自然语言生成中最具挑战性的任务之一,目标是基于输入代码生成相应的可理解的自然语言注释或描述。
早期的研究人员将代码注释生成建模为源代码序列到自然语言注释序列的翻译任务,但是不足之处在于其仅提取源代码中的文本信息而忽略了结构信息。近年来,学者们考虑引入源代码的结构化输入,如抽象语法树(Abstract Syntax Tree,AST),并采用机器学习的方法或模型来提取源代码中结构信息的语义表达。然而,这些研究工作未充分考虑如何从结构化数据输入中复制提取关键信息。代码注释生成的目标注释中通常会出现目标词典中不存在的单词(Out Of Vocabulary,OOV),如数值型、字符型等变量单词,从而导致生成的自然语言注释输出不完整。为解决该问题,研究人员在代码注释生成模型中引入指针网络[8],指针网络通过在单位时间步输出指向输入序列的某一个单词,从而形成一种复制机制。但是,经典的指针网络只支持代码的序列化输入,不支持代码的结构化输入,从而难以利用源代码的结构化信息。同时,源代码的抽象语法树存在复杂多变的语法结构,使得指针网络需花费大量的学习成本来学习复杂语法结构,导致难以准确地提取核心信息。此外,引入复制机制的代码注释生成模型倾向于频繁复制核心词,使得生成的自然语言注释较易出现冗余信息。
本文提出一种用于代码注释自动生成的语法辅助复制机制。将编码器-解码器作为基本框架,编码器为树型长短期记忆网络(Tree-LSTM)[9],解码器为长短期记忆网络(LSTM)[10]。由于经典的指针网络仅支持序列结构网络,无法直接应用于上述框架,因此本文通过改进指针网络结构使其支持源代码的抽象语法树输入。具体地,在编码阶段,编码器网络通过对源代码的抽象语法树进行编码得到结构化的语义信息并存储于节点的隐状态中。在解码阶段,解码器网络在每个时间步通过当前隐状态和输入所有节点的隐状态来计算注意力向量,并输入到二元分类器中以选择复制机制或生成机制。本文所提语法辅助复制机制包含基于语法信息的节点筛选策略和基于时间窗口的去冗余生成策略,前者根据语法节点类型使用掩码向量过滤无关的语法节点,后者在时间窗口内对被复制过的节点进行概率惩罚,从而抑制重复复制该节点的现象。
1 相关工作
多数代码注释生成任务主要关注源代码的文本信息。具体地,文献[11]通过主题模型和n-gram 技术来生成代码注释,文献[12]提出一种基于长短时记忆网络与注意力机制的语言模型Code-NN,从而生成C#和SQL 注释,文献[13]利用卷积神经网络与注意力机制来预测生成代码注释。
近年来,研究人员除考虑源代码的文本信息外,还探究如何提取其抽象语法树中的结构信息。文献[14]提出结合语法结构信息和文本信息的语义表达方法。文献[15]通过遍历Java 的语义解析树节点获得序列形式,将其作为输入以捕获语义特征和语法信息。文献[16]提出的Graph2Seq 将结构化查询语言(SQL)序列看作有向图,利用图网络学习全局结构信息。本文同样采用树型结构编码器,输入源代码的语义解析树以提取结构化信息。
目前,研究人员普遍采用经典的复制机制解决自然语言注释生成的OOV 问题,如文献[17]提出结合复制机制的混合生成网络以进行文本摘要生成,文献[18]利用复制机制复制子句,文献[19]利用复制机制进行代码生成。与上述工作不同,本文建立一种支持树型结构化数据输入的指针网络变体,并基于源代码的语法结构和特性,提出包含节点筛选策略和去冗余生成策略的语法辅助复制机制,以从源代码的语义解析树中提取关键内容信息。
2 代码自动注释模型
代码自动注释模型的输入一般是源代码对应的抽象语法树表示,而非源代码本身[20]。抽象语法树省略编程语法上的部分无用细节,只保留语法结构以及与代码内容相关的部分,作为源代码语法结构的抽象化表示。以SQL 查询语句为例,其对应的抽象语法树表示如图1 所示。
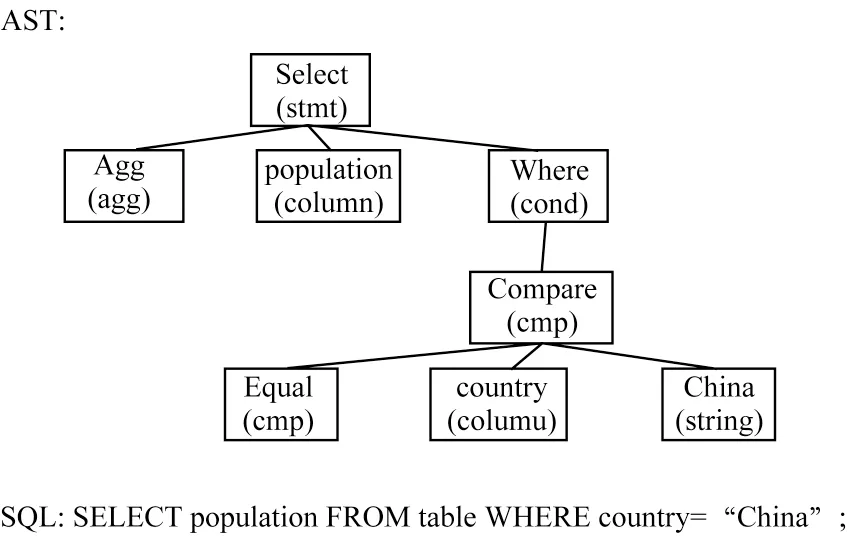
图1 SQL 查询语句对应的抽象语法树表示Fig.1 Abstract syntax tree representation of SQL query statement
本文对代码自动注释任务进行定义:给定一个源代码的抽象语法树X={x1,x2,…,x|X|},目标的自然语言注释为Y={y1,y2,…,y|Y|},其中,xi代表抽象语法树的第i个节点,yj是自然语言注释序列的第j个单词。本文建立的代码自动注释模型是基于编码器-解码器框架设计的,结合编码器(树型长短期记忆网络[9])、解码器(长短期记忆网络[10])和注意力机制[21]。在编码阶段,树型长短期记忆网络自下而上递归式地遍历抽象语法树,最终以根节点的隐含层表示作为抽象语法树的语义表达向量;在解码阶段,长短期记忆网络接收编码器的语义表达并解码出目标序列,在每个时间步基于当前的隐状态与编码阶段得到的抽象语法树上节点的隐状态,通过注意力机制[21]计算注意力向量以复制或生成目标单词。本文模型在给定代码抽象语法树X下,生成对应的自然语言注释序列Y。其中,每个时间步t的预测输出为yt,条件概率为p。本文采用极大似然估计(Maximum Likelihood Estimation,MLE)优化如下的目标函数:

为了解决OOV 问题,本文将复制机制引入到代码注释生成模型中。复制机制使得生成模型除了从目标词典中选择单词外,还可从源代码输入中提取信息。具备复制机制的代码注释生成模型的目标函数可基于式(1)展开为:
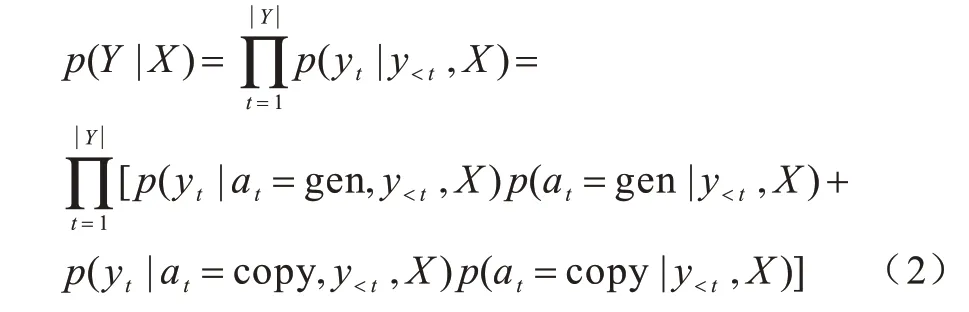
其中,at表示第t个时间步执行的解码动作,可为输入复制或词典生成,即at∈{gen,copy},p(at|y<t,X)表示一个伯努利分布,且p(at|y<t,X)∈{0,1}。
为了从源代码的复杂语法结构中提取信息,本文提出一种语法辅助复制机制,该机制包含基于语法信息的节点筛选策略与基于时间窗口的去冗余生成策略。如图2 所示,编码器(Encoder)对源代码的抽象语法树进行编码,将编码后的语义表达(enc.embed)传递到解码器(Decoder)进行解码。解码器使用LSTM 在每个时间步进行从源输入复制(CP)或从词典生成(GEN)操作。解码器若选择CP 操作,将执行基于语法信息的节点筛选策略(①)和基于时间窗口的去冗余生成策略(②);否则,解码器选择GEN操作,直接从词典中选择单词。长虚线区域内的节点为经过节点筛选策略筛选后的候选语法节点,短虚线框为在时间步t时“China”节点的被复制概率的衰减过程,γ表示衰减持有率,λt-1表示上一个时间步的衰减率,p为每个节点具体的复制概率。节点筛选策略过滤抽象语法树的无关节点,保留字符型变量节点;去冗余生成策略对已被复制的节点“China(string)”进行惩罚,防止该节点被错误地重复复制。

图2 代码自动注释模型整体架构Fig.2 Overall architecture of automatic code comment model
3 抽象语法树编码
编码阶段的目标是得到抽象语法树的语义编码表达,本节将介绍公式化编码过程。编码阶段分为语法节点向量化和抽象语法树向量化2 个过程。
3.1 语法节点向量化
抽象语法树X由多个节点组成,每个节点xi可能包含一个或者多个单词,即。初始化词典词嵌入矩阵为We∈Rle×d,其中,le为输入词典的大小,d为词向量维度大小。对节点i中的第j个单词ωij构建词典的独热(one-hot)索引变量id(ωij)∈Rle,可以得到ωij的词嵌入向量如下:
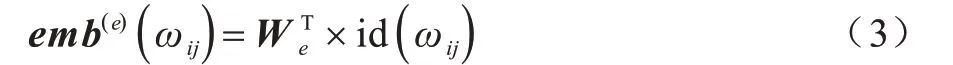
通过式(3)可以得到节点中每个单词的词嵌入向量,为了得到节点的向量化表示,需要获得节点中的单词序列表达。本文采用LSTM[10]作为序列学习网络,在每个时间步循环地输入序列中每个单词ωij的词嵌入向量,并存储更新隐含层信息,如下:
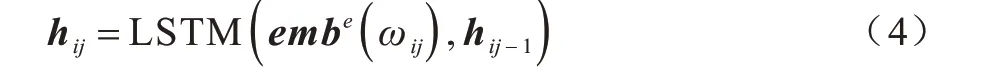

3.2 抽象语法树向量化
通过3.1 节获得抽象语法树的节点向量化,编码器需进一步将节点的表达通过抽象语法树的结构聚合成抽象语法树的整体表达。为了捕捉抽象语法树的语法结构,将Tree-LSTM[9]作为编码器,进一步对抽象语法树进行编码。Tree-LSTM 自下而上递归式和结构化地输入抽象语法树数据,将信息更新至节点隐状态。与经典的LSTM 网络相同,Tree-LSTM 同样包含输入门、遗忘门和输出门,每个门都是基于节点的向量表示及其孩子节点的隐状态。当抽象语法树是N-ary 树时,语法树的非叶子节点最多存在N个孩子节点。对于任意节点j,其第k个孩子的隐状态和单元状态(Cell State)分别为sjk和cjk,则对节点j隐状态的更新过程如下:

其中,ij、fjk、uj、oj∈Rd分别代表输入门、遗忘门、输出门和被用来更新细胞状态cj∈Rd的状态向量,W(⋅)∈Rd×d和U(⋅)∈Rd×d代表可学习的参数矩阵,b(⋅)∈Rd代表偏置向量,vj∈Rd代表节点j的向量化表示。
Tree-LSTM编码器递归式地计算抽象语法树以更新各节点的隐含层信息,根节点的隐含层状态含有其他所有节点的语义结构信息,因此,本文将根节点的隐含层状态作为抽象语法树的语义结构表达,用于解码器更新。
4 自然语言注释
4.1 基于注意力的解码过程
模型的解码器负责将从编码器得到的抽象语法树结构语义表达迭代式地生成自然语言注释。本文解码器采用LSTM[10],以结构语义表达作为初始化隐状态,按单位时间步更新输出新的隐状态,且解码器输出的隐状态用于构造注意力向量。具体地,对于任意时间步t,解码器LSTM 输出的隐状态为ot∈Rd,注意力向量qt∈Rd的计算过程如下:

从上述公式可知,在解码器阶段,根据当前时间步t的隐状态ot与编码器得到的抽象语法树各节点的隐状态分别计算得分rtj;接着,通过softmax 函数进行归一化得到权重向量αt∈R|X|;然后,对各节点隐状态进行加权求和得到当前时间步的内容向量zt∈Rd;最终,利用可学习参数矩阵Wattn∈Rd×2d和tanh 激活函数融合内容向量zt和当前解码隐状态ot,得到注意力向量qt∈Rd。通过上述注意力机制过程,解码器生成自然语言注释时可以更关注抽象语法树的相关节点,使得生成模型输出的自然语言注释具备更高的语义准确性。
为了解决自然语言生成的OOV 问题,本文模型引入复制机制,使其具备从源输入中提取关键信息的能力。本文模型存在2 种生成来源,分别是从目标词典中预测和从源输入中复制提取。因此,该模型需要一种机制来选择生成来源,本文构造基于注意力向量输入的分类器,以选择生成来源。构造参数为Wgc∈R2×d的全连接神经网络,输入注意力向量产生at∈{gen,copy}二元概率分布,如下:

当预测概率大于复制概率时,解码器选择从目标词典中生成。具体地,构造参数为Wgen∈Rld×d的全连接神经网络,输入注意力向量产生目标词典的概率分布,如下:
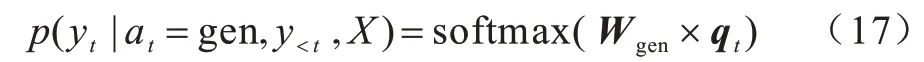
4.2 语法辅助复制机制
4.1节介绍了解码器生成来源为目标词典下的解码过程,本节将重点阐述当生成来源为源输入信息时的解码过程,并通过语法辅助来提高复制提取的准确率。
当生成来源分类器输出的复制概率大于预测概率时,解码器将从输入信息中进行复制提取。具体地,对时间步t的注意力向量qt,计算其与编码器中抽象语法树各节点隐状态的得分向量gt∈R|X|,归一化后选择概率最大的节点并复制其中的文本信息,过程如下:

从上述过程可以看出,复制机制与注意力机制实现过程相似,但是复制机制依赖于注意力机制的注意力向量并进行二次计算。
4.2.1 基于语法信息的节点筛选策略
代码自动注释任务的输入是程序代码的抽象语法树,其具有复杂多变的结构信息。现有的复制机制多为非结构化输入数据而设计,模型需要花费大量的时间学习如何从复杂结构中提取有用的信息,且提取效果通常不佳。本文利用语法辅助复制机制从抽象语法树中提取关键信息。对于代码自动注释任务而言,关键信息一般为抽象语法树上的数值型节点和字符型节点。因此,本文将复制过程的搜索范围从语法树所有类型的节点压缩至这两类节点,该过程可以降低搜索空间,也能够减少抽象语法树结构变化所带来的干扰以及神经网络的学习成本。
本文通过引入掩盖变量来过滤无效候选节点。假设时间步t的节点掩盖向量为dt∈R|X|,长度为节点数,取值为0 或-∞,0 代表对应语法节点有效,-∞代表节点无效,将其从候选节点集中剔除。在复制过程中,剔除无效节点后余下候选节点的概率计算公式如下:
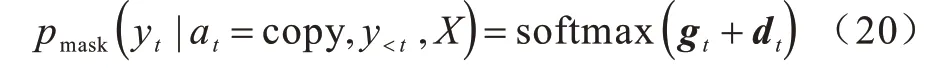
由上述过程可得到复制机制下当前时间步对应的损失函数为:
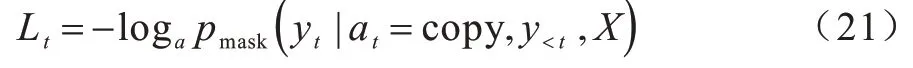
一方面,通过掩盖向量可以剔除无效节点,使得无效节点集概率恒等于0,正确节点掩盖后的概率大于等于原始概率,当前时间步的损失下降,神经网络的整体成本函数也会下降;另一方面,从候选节点集合中过滤无效候选节点,可以使得当前时间步搜索空间得到一定的压缩。因此,节点筛选策略在一定程度上可以加速神经网络的学习。
4.2.2 基于时间窗口的去冗余生成策略
现有代码自动注释方法生成的自然语言注释存在主要关键词冗余与部分关键词缺失的现象,造成该现象的原因是复制机制与注意力机制原理相近,导致指针网络倾向于重复指向最具注意力的少数节点,而忽略了其他有用节点。为解决上述问题,本文提出一种基于时间窗口的去冗余生成策略,通过在时间窗口内对已被复制的语法节点的复制概率进行衰减,从而提高候选集合中其他有用且未被复制的节点被初次复制的概率。具体地,对于一个已被复制的语法节点xi,设置基于时间窗口变化的衰减率λit,用超参数γ∈(0,1) 表示衰减持有率,用于控制每次衰减率的减少量。λit表示如下:

在时间步t下,抽象语法树候选节点集合有一一对应的衰减变量集合。结合基于语法信息的节点筛选策略和基于时间窗口的去冗余生成策略,最终抽象语法树复制候选节点的概率分布如下:
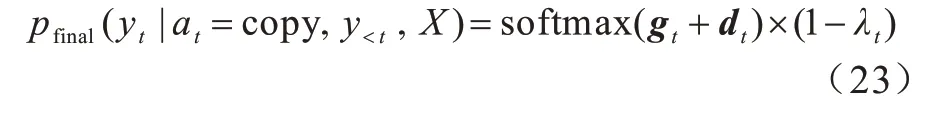
5 实验结果与分析
5.1 数据集
本文采用结构化查询语言(SQL)和逻辑表达式(Lambda)2 种不同编程语言的源代码数据进行测试,源代码数据分别来自WikiSQL[22]和ATIS[23]数据集。WikiSQL 数据集数据来源于维基百科,含有24 241 个小规模数据表格,基于以上数据表格产生80 654 个结构化查询语句-自然语言对。ATIS 数据集数据来源于现实航空业务数据库,含有25 个真实数据表,基于以上数据表格产生5 373 个逻辑表达-自然语言对。为了验证各方法的有效性,将WikiSQL 数据集进一步划分为分别含有56 355 个样本的训练集、8 421 个样本的验证集和15 878 个样本的测试集。同样地,将ATIS 数据集划分为分别含4 434 个样本的训练集、491 个样本的验证集和448个样本的测试集。上述数据集涉及的2种编程语言均可通过抽象语法描述语言(Abstract Syntax Description Language,ASDL)来获得对应的抽象语法树。其中,SQL 结构化查询语言和Lambda 逻辑表达式的ASDL 语法分别在文献[24]和文献[25]中有所定义。
5.2 基准方法
本文将具有代表性的两类结构性方法作为实验的基准方法,其中包括树至序列(Tree to Sequence,Tree2Seq)模型[26]和图至序列(Graph to Sequence,Graph2Seq)模型[16],以上基准方法均采用注意力机制。需要注意的是,Tree2Seq 模型输入结构为源代码的抽象语法树,而Graph2Seq 模型的原文输入结构是专为SQL 查询语句设计的图结构,其无法支持Lambda 逻辑表达式,而且原文没有提供为SQL 查询语句转换的预处理代码。因此,本文将统一采用抽象语法树作为Graph2Seq 模型的输入结构。编程语言的抽象语法树表示具有普遍性,可应用于大部分编程语言。具体地,本文将源代码的抽象语法树看作一个无向图,父、子节点之间的连接看作图节点的边。此外,为了更好地验证语法辅助复制机制的性能,本文在Tree2Seq 模型中引入一种传统的复制机制。
5.3 评价指标
本文采用BLEU[27]和ROUGE[28]作为自然语言注释生成的评价指标。BLEU 是自然语言处理任务常用的评价指标,其通常从字符或单词级别来评价2 个文本或2 个文本集合的相似度。ROUGE 指标评价所生成文本句子的充分性和忠实性,为了提高所生成文本的连贯性,本文使用考虑文本上下文的ROUGE 指标,分别为ROUGE-2 和ROUGE-L。
5.4 实验设置
实验参数设置如下:词向量、编码器和解码器的隐状态维度大小均为128 维,批量大小均设置为32 个,梯度优化器选择Adam 优化器[29],学习率设置为0.001。此外,为了降低词典大小,源词典和目标词典只记录词频不低于4 的单词。实验没有采用由其他语料库预训练的词向量,如Word2Vec[30]和Glove[31]等,而是使用xavier 初始化器[32]随机初始化词向量。本文所提复制机制中基于时间窗口的去冗余生成策略的衰减持有率,在WikiSQL 和ATIS 数据集中分别设置为80%和90%时系统性能达到最优,5.5.3 节将对该参数进行详细的敏感性分析。
5.5 结果分析
5.5.1 模型性能分析实验
表1 和表2 所示分别为本文模型和基线模型在WikiSQL 和ATIS 2 个数据集上进行代码自动生成的实验结果,其中最优结果加粗表示。从中可以看出,本文模型在WikiSQL 数据集中的性能表现明显优于2 个基线模型,与最佳基线模型Tree2Seq+copy 相比,本文模型的BLEU 提升14.5%,ROUGE-2 和ROUGE-L 分别提升10.3%和5.5%。在ATIS 数据集上,与最佳基线模型Tree2Seq+copy 相比,本文模型的BLEU 提升2.8%,ROUGE-2 和ROUG-L 分别提升6.6%和2.5%。上述结果表明,本文模型相比现有代码注释生成方法有显著的性能提升,其能生成更加准确的代码自然语言注释。

表1 3 种模型在WikiSQL 数据集上的性能对比结果Tabel 1 Performance comparison results of three models on WikiSQL dataset

表2 3 种模型在ATIS 数据集上的性能对比结果Tabel 2 Performance comparison results of three models on ATIS dataset
5.5.2 节点筛选策略的有效性实验
为了量化节点筛选策略在压缩搜索空间方面的性能,本文统计WikiSQL 和ATIS 数据集单位时间步内的平均候选节点个数,结果如表3 所示。从表3 可以看出,通过节点筛选策略过滤无效的语法节点,在WikiSQL 数据集中候选节点空间的压缩比例超过60%,在ATIS 数据集中压缩比例超过50%,即节点筛选策略能大幅降低代码注释生成的搜索空间。

表3 2 种数据集在单位时间步内的平均候选节点数Table 3 The average number of candidate nodes per unit time step of two datasets
为了验证节点筛选策略在收敛速度方面的性能,本文在WikiSQL 的验证集下测试BLEU 指标的收敛趋势。为了公平有效地对比,在本文模型中去除去冗余生成策略,仅保留节点筛选策略,并与结合复制机制的Tree2Seq 模型进行对比,结果如图3 所示。从图3 可以看出,相比基线模型,仅保留节点筛选策略的本文模型收敛速度有所提升,即节点筛选策略能在一定程度上加速神经网络的学习。
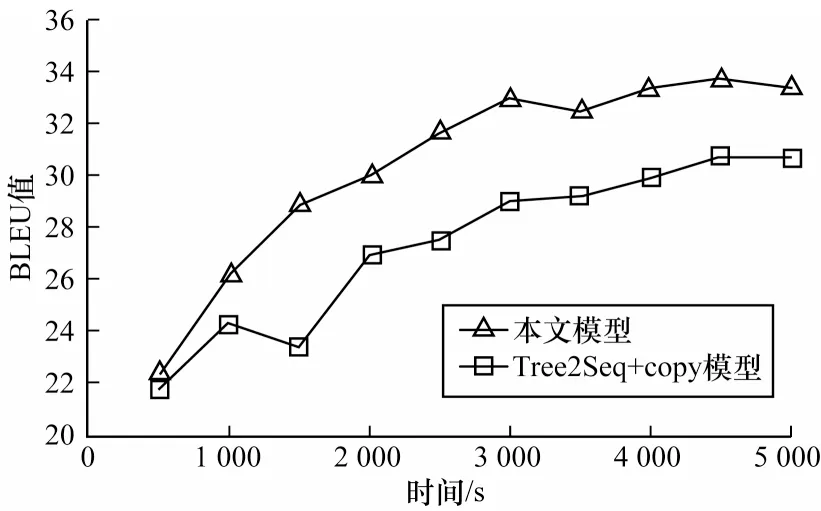
图3 2 种模型在WikiSQL 验证集上的收敛速度对比Fig.3 Convergence rate comparison of two models on WikiSQL verification set
5.5.3 衰减持有率的敏感性实验
为了验证去冗余生成策略中的衰减持有率对模型影响的敏感程度,本文在WikiSQL 和ATIS 数据集上设计针对衰减持有率的敏感性实验,结果如图4和图5 所示。从图4 可以看出,在WikiSQL 数据集上,当衰减持有率为80%时,模型达到该数据集上的最高BLEU 值。从图5 可以看出,在ATIS 数据集上,当衰减持有率为90%时,模型达到该数据集上的最高BLEU 值。衰减持有率能够直观反映自然语言注释中一个字或词重复出现的间距,图4 和图5 的实验结果表明,在2 个数据集上重复字词出现的间距均较大。
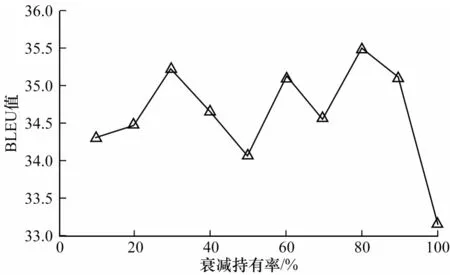
图4 WikiSQL 测试集上的衰减持有率敏感性实验结果Fig.4 Sensitivity experimental results of decay keeping probability on WikiSQL test set

图5 ATIS 测试集上的衰减持有率敏感性实验结果Fig.5 Sensitivity experimental results of decay keeping probability on ATIS test set
5.5.4 分离实验
为了更好地体现基于语法信息的节点筛选策略和基于时间窗口的去冗余生成策略在模型中的重要性,本文设计分离实验以验证去除其中一种策略后的模型性能,测量不同的变种模型在WikiSQL 和ATIS 验证集上的BLEU 值变化。本文定义如下的变种模型:
1)Ours-SA:只去除基于语法信息的节点筛选策略的模型,其他保持不变。
2)Ours-CD:只去除基于时间窗口的去冗余生成策略的模型,其他保持不变。
分离实验结果如表4 所示,从表4 可以看出,与原始模型相比,Ours-SA 和Ours-CD 的BLEU 值在2 个数据集上均出现明显下降,验证了本文所提2 种策略的有效性。此外,基于时间窗口的去冗余生成策略对WikiSQL 影响较大,去除该策略后模型的BLEU 值降低超过10%,而2 种策略对ATIS 数据集的影响相差不大。
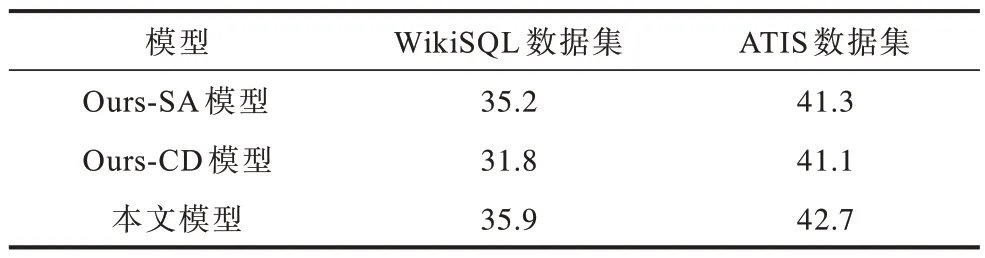
表4 2 种数据集上的分离实验结果Table 4 Results of separation experiments on two datasets
6 结束语
本文提出一种用于代码注释自动生成的语法辅助复制机制,其中主要包括节点筛选策略和去冗余生成策略2 个部分。实验结果表明,与Tree2Seq+copy 和Graph2Seq 模型相比,该机制的BLEU 和ROUGE 指标值均较高。下一步将在代码注释生成模型框架中引入语法信息,以提升模型对复杂语法的学习效果。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
小学生必读(低年级版)(2021年10期)2022-01-18 15:10:46
现代信息科技(2021年21期)2021-05-07 21:44:50
小学生必读(低年级版)(2021年11期)2021-03-09 06:14:46
小学生必读(低年级版)(2021年12期)2021-03-04 07:18:44
家庭影院技术(2019年8期)2019-12-04 14:43:19
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
