
基于混合能量收集的移动边缘计算系统资源分配策略
2021-04-29 04:04:54陈加法赵宜升高锦程陈忠辉
重庆邮电大学学报(自然科学版) 2021年2期
陈加法,赵宜升,高锦程,陈忠辉
(福州大学 物理与信息工程学院福建省媒体信息智能处理与无线传输重点实验室,福州 350116)
0 引 言
采用射频(radio frequency,RF)能量收集技术从环境电磁波中收集能量为移动终端(mobile terminal,MT)提供电能是一种新的供电方式。然而,MT的电池容量和计算能力有限是其不足之处[1]。通过移动边缘计算(mobile edge computing,MEC)将计算任务分流到边缘服务器进行计算,能够显著减少MT的能量消耗[2-3]。此外,通过设计资源分配策略,能够高效利用收集到的能量。因此,研究结合MEC的能量收集通信系统的资源分配问题具有重要意义。
结合MEC的能量收集通信系统的资源分配问题已经引起了广泛关注。文献[4]为具有能量收集功能的MTs提出了一种基于深度学习的分流方案,有效降低了能量消耗、计算时延和任务丢弃率。文献[5]通过将MTs计算任务转移到边缘服务器来提高计算质量,将能量收集纳入多用户移动边缘计算系统中,提出了基于强化学习的资源管理算法以实现MTs时延和能耗成本最优化。文献[6]将无线能量传输(wireless power transfer,WPT)与MEC相结合,利用邻近边缘服务器的近端MT协助远端MT分流计算任务到边缘服务器,提出了一种最大化能量效率的资源分配策略。文献[7]提出一种采用非正交多址的MEC系统,多个MTs可以在同一个子载波下多路复用。在能量和时延约束下,优化子载波和功率分配以最小化计算总时延。文献[8]在多用户WPT-MEC系统中,以最大化MTs计算速率加权和为目标,提出了本地或边缘计算模式选择、WPT与分流任务的系统时间资源分配策略。文献[9]为了应对海量的数据计算,提出了一种异构网络中的宏-微双层边缘计算结构。MTs可以将任务分流到宏边缘或微边缘计算。在总时延和额定能量约束下,提出了一种最小化系统总功率开销的优化策略。文献[10]在能量和时延约束下,将计算时间和任务执行失败率作为计算成本,提出了一种最小化计算成本的动态分流资源分配策略。然而,现有的研究主要关注的是RF能量收集,由于基于RF能量收集的接收功率较低,短时间内收集的能量较少,一旦电池能量耗尽,将会严重影响系统性能。基于磁感应(magnetic induction,MI)的无线能量传输技术[11],具有较高的接收功率,能够在短时间内获得较多的能量。如果在RF能量收集的基础上,通过在基站覆盖区域内部署多个MI能量快速充电站,当具有MI充电功能的MT电池能量即将耗尽时,可以在附近的MI能量快速充电站补充足够的能量,从而保证系统性能。
本文针对MT从环境射频源收集能量较少的问题,提出一种基于混合能量收集的MEC系统中最小化MTs总能量消耗的资源分配策略。在基站覆盖范围内部署一系列MI能量快速充电站,当MT从环境射频源收集的能量快不够用时,在最近的MI能量快速充电站获取能量。MT将计算任务分流到MEC服务器进行计算。在满足MT最大计算能力、边缘服务器最大计算资源、任务计算总时延和MT电池能量的约束条件下,资源分配策略的目标是最小化MTs总能耗。采用量子行为粒子群优化算法(quantum-behaved particle swarm optimization,QPSO)获得次优解。最后,通过仿真对所提出的资源分配策略进行性能分析。
1 系统模型
本节研究系统模型。首先,给出移动边缘计算系统网络结构。然后,分析移动终端能量收集模型。
1.1 网络结构
图1给出移动边缘计算系统网络结构。在该移动边缘计算系统中,存在K个MTs和一个基站(base station,BS),并在基站附近部署MEC服务器。由于MT的电池容量和计算能力有限,为了最小化MTs总能耗,MTs通过蜂窝网络将计算任务分流到MEC服务器进行计算。采用Ti={Di,Ci}来表示MTi(i=1,2,…,K)的计算任务。其中,Di表示计算任务Ti的输入计算数据大小,Ci表示完成计算任务Ti所需要的总CPU计算周期。MTi可以通过本地计算或者边缘计算来完成计算任务。采用α=[α1,α2,…,αK]来表示分流向量。当αi=0时,MTi通过本地计算来完成计算任务。当αi=1时,MTi通过边缘计算来完成计算任务。
1.2 移动终端能量收集模型

(1)

图1 移动边缘计算系统网络结构Fig.1 Networks structure of mobile edge computing system
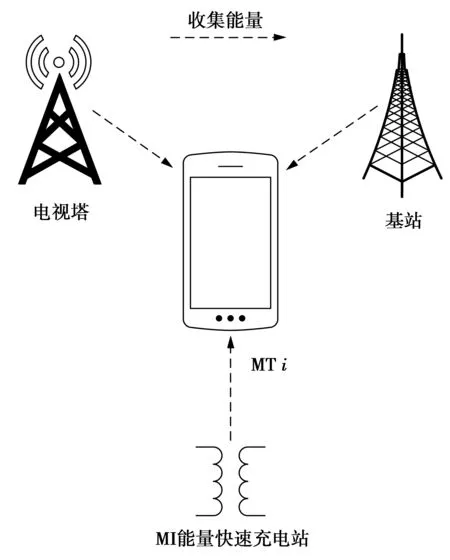
图2 移动终端能量收集方式Fig.2 Energy harvesting mode of mobile terminal

(2)
(2)式中:μ表示自由空间磁导率;Nt和Nr分别代表发射线圈和接收线圈的匝数;at和ar是发射线圈和接收线圈的半径;d表示发射线圈与接收线圈的距离。当发射线圈与接收线圈电路处于谐振状态时,充电距离可以有一定幅度的增加,便于实际应用。
为了使接收功率最大化,负载阻抗ZL为二次回路输出阻抗的复共轭[14],即
(3)
(3)式中:Rt和Rr分别代表发射线圈和接收线圈的电阻(Rt=2πNtatR0,Rr=2πNrarR0,R0是线圈单位长度的阻值);ω表示角频率(ω=2πf,f是系统工作频率);Lt和Lr分别是发射线圈和接收线圈的自感,即
(4)
根据等效电路原理,接收功率等于负载阻抗ZL的功率消耗,即
(5)
(5)式中,UM表示接收线圈的感应电压,其表达式为
(6)


2 问题建模和求解
本节提出具体的资源分配策略。首先,建立资源分配优化问题模型。然后,通过引入QPSO算法,获得次优解。
2.1 问题建模

(7)
同时,MTi本地计算所消耗的能量为
(8)

(9)
此外,K个MTs通过时分多址(time division multiple access,TDMA)方式分流各自的计算任务到MEC服务器进行计算。如图3,每一时间周期TTDMA被分成2K个时间块,每一个时间块为tk,∀k∈{1,2,…,2K}。在第1段K时间块内,K个MTs依次分流计算任务到MEC服务器。在MEC服务器完成了K个MTs的计算任务之后,也就是第1段K时间块之后, MEC服务器通过基站依次把计算结果反馈给K个MTs。由于基站通常具有较高的发射功率,同时需要发送的计算结果也相对较小,所以本文忽略了计算结果反馈时间,并且忽略了计算结果反馈的能量消耗[15]。

图3 多个移动终端分流计算的时间分配图Fig.3 Time distribution of multiple mobile terminals computation offloading

(10)

(11)
同时,MTi分流到MEC服务器进行边缘计算所消耗的能量为
(12)

(13)
(13)式中,δ表示MEC服务器执行计算时,计算每比特数所消耗的能量,其单位为J/bit。另外,假设MEC服务器最大CPU时钟频率为Fe,即MTs分流到MEC服务器进行边缘计算时,MTs所占用计算资源之和不得超过MEC服务器最大计算资源Fe。因此,分流到MEC服务器进行边缘计算时,MTi必须满足约束条件
(14)
本文的优化目标是在特定的能量和时延约束下,最小化MTs总能量消耗。因此,该问题可以建模为
(15a)

(15b)
(15c)
(15d)
(15e)
C5:αi∈{0,1}, ∀i
(15f)
其中,目标函数是MTs总能耗,其单位是J。对于约束条件,分别说明如下:C1表示MEC服务器分配给K个MTs的CPU时钟频率之和不得超过MEC服务器的总计算资源;C2代表MTi本地计算时,执行计算任务Ti的CPU时钟频率不得超过MTi的最大计算能力;C3规定计算任务Ti必须在特定的时延约束ti内完成;C4确保MTi所消耗的能量不得超过MTi电池能量;C5指出MTi完成计算任务Ti是通过本地计算还是边缘计算。
2.2 次优解
对于MINLP问题,难以在较低的计算复杂度下得到最优解。因此,可以采用计算复杂度适中的启发式算法来得到次优解。群体智能算法是基于群体行为对给定的目标进行寻优的启发式搜索算法,其寻优过程体现了随机、并行和分布式等特点。粒子群优化(particle swarm optimization,PSO)算法[17]和QPSO算法[18-19]均是适用于求解复杂优化问题的群体智能优化算法。
源于对鸟群觅食过程的模拟,文献[20]提出了标准粒子群优化(standard particle swarm optimization,SPSO)算法,SPSO算法是带惯性权重w的PSO算法。假设粒子空间为多维空间,每个粒子在搜索空间中运动,维度越大,搜索空间也相应增大。粒子由速度决定它的运动方向和距离,通过追随自身的个体最好位置与群体的全局最好位置来动态地调整自己的位置信息。粒子的个数越多,在整个可行解空间中进行搜索时,能得到更接近全局优化的次优解。假设有N个粒子,对于第n(n=1,2,…,N)个粒子,需要对其位置矢量Xn和速度矢量Vn进行初始化,粒子的更新是在适应度函数的求解下,通过它的当前个体最好位置Pn和全局最好位置G与前一次迭代对比下而产生的。在算法还没达到收敛迭代次数时,迭代次数越大,粒子的位置更新次数就会越多,也能使算法得到更接近全局优化的次优解。每个粒子的速度矢量和位置矢量更新迭代方程式为
(16)
(16)式中:t表示迭代次数;w是惯性权重;c1和c2代表2个固定的加速度系数;r1和r2是处于(0,1)之间的随机数。只有当迭代次数达到最大迭代数时,迭代才会终止。然而,在SPSO算法中,粒子的运动状态由速度和位置描述,随着时间的演化,粒子的运动轨迹是既定的。同时粒子的速度受到一定的限制,使得粒子的搜索空间是一个有限的并逐渐减小的区域,不能覆盖整个可行解空间,导致SPSO算法不能保证全局收敛。针对SPSO算法的这个缺点,基于量子力学理论所提出的QPSO算法,在量子空间中,粒子的聚集性通过在粒子运动中心存在的某种吸引势产生的束缚态来描述,处于量子束缚态的粒子可以以一定的概率密度出现在空间的任何点,满足聚集态性质的粒子可以在整个可行解空间中进行搜索,但不会发散到无穷远处。因此,当所有粒子在迭代搜索过程中,QPSO算法可以覆盖整个可行解空间,从而可以使本文的优化问题获得更接近全局优化的次优解。
本文采用QPSO算法求解(15)式所述的MINLP问题。首先,需要利用惩罚函数法将原约束优化问题转化为无约束形式。因此,构造一个由目标函数和惩罚函数所组成的适应度函数为
(17)
(18)
其对应于(15)式中的5个约束条件,表达式分别为
(19a)
(19b)
(19c)
(19d)
(19e)
(19a)—(19d)中,max(·,·)表示在2个数值之间取较大的一个数值。
接下来,对粒子进行定义,假设在多维目标搜索空间中,QPSO算法由N个代表潜在问题解的粒子组成群体。对于第n个粒子,它的位置矢量Xn可以表示为
(20)
(21)
此外,定义吸引子矢量P,其表达式为P=φPn(t)+(1-φ)G(t)。其中,φ是(0,1)之间的随机数,Pn(t)表示第n个粒子在第t次迭代时的个体最好位置,G(t)代表群体粒子在第t次迭代时的全局最好位置。粒子的进化方程为
(22)
(22)式中,r是(0,1)之间的随机数;β代表第t次迭代的收缩-扩张系数,其计算公式为
(23)
(23)式中,T表示最大迭代数;此外,C(t)表示平均最好位置,他定义为所有粒子个体最好位置的平均,即
(24)
最后,对于(15)式的最小化问题,目标函数值越小,对应的适应值越好。所以,根据(17)式适应度函数,粒子n的个体最好位置确定可以表示为
(25)
群体的全局最好位置确定的表达式为
(26)
为了更加清晰地说明基于QPSO算法的最小化MTs总能耗资源分配策略,其详细的步骤如算法1。
算法1基于QPSO算法的最小化MTs总能耗资源分配策略
1)初始化变量:初始化最大群体规模N,最大迭代次数T,确定问题维数。
2)初始化位置:首先,初始化每个粒子的当前位置Xn(1),n=1,2,…,N。然后,将粒子个体最好位置初始化为当前最好位置Pn(1)=Xn(1)。最后,初始化全局最好位置变量,计算当前位置和个体最好位置的适应值,找到全局最好位置G(1)。
3)迭代:令t=1,n=1,首先计算收缩-扩张系数β值,再计算平均最好位置C(t)和吸收子P,根据所计算的结果,结合(22)式来更新粒子的位置。
4)更新个体最好位置:根据(25)式,将Xn(t+1)的适应值与前一次迭代Pn(t)的适应值比较。如果Xn(t+1)的适应值小于Pn(t)的适应值,则置Pn(t+1)=Xn(t+1);反之,Pn(t+1)=Pn(t)。
5)更新全局最好位置:对于粒子n,将Pn(t+1)的适应值与前一次迭代G(t)的适应值比较。如果Pn(t+1)的适应值小于G(t)的适应值,则置G(t+1)=Pn(t+1);反之,G(t+1)=G(t)。
6)重复:若算法终止条件不满足,令t=t+1,返回步骤3重复计算,否则算法结束。
3 仿真结果与分析
本节通过仿真对所提出的资源分配策略进行性能分析。首先,给出相关参数设置。然后,进行性能分析。
3.1 参数设置

3.2 性能分析

图4给出了QPSO算法在不同粒子数下,总能量消耗与迭代次数的关系。在仿真中,MTs的数量为15。从图4可以看出,随着迭代次数的增加,MTs总能耗随之逐渐减小,当迭代次数为90时,能耗已趋于收敛。此外,当粒子数从10逐渐递增到100时,MTs总能耗也会随之降低。这是因为从更多的粒子数中搜索,所得到的结果将会更接近最优解。然而,当粒子数为70和100时,MTs总能耗降低趋势不是很明显。因此,对于后面的仿真,将迭代次数和粒子数分别设置为90和100。

图4 总能量消耗与迭代次数的关系Fig.4 Relationship between total energy consumption and number of iterations
图5从平均CPU时间的角度给出了在不同粒子数下,QPSO算法时间复杂度与迭代次数的关系。从图5可以看出,平均CPU时间随着迭代次数的增大而增大。此外,当粒子数从10逐渐递增到100时,平均CPU时间随之增加。这是因为问题的求解是根据粒子在位置进化方程的迭代更新来实现的。解空间为多维空间,每个粒子的位置是一个多维矢量。因此,粒子的数量越多,所有粒子的位置迭代更新所花费的时间就会越长。

图5 平均CPU时间与迭代次数的关系Fig.5 Relationship between average CPU time and number of iterations
图6对比了不同方法下,总能量消耗与计算数据大小的关系。从图中可以看出,当计算数据以10 Mbit为单位从360 Mbit到400 Mbit逐渐增大时,MTs总能耗也逐渐变大。这是因为在MTs本地最大计算能力以及MEC服务器最大计算资源固定不变的情况下,计算数据越大,执行任务所需要消耗的能量也会越多。此外,在相同的条件下,相对于SPSO和ER-SPSO,QPSO和ER-QPSO得到较低的能量消耗。这是因为采用SPSO算法在求解过程中,粒子的搜索空间不能覆盖整个可行解空间,从而不能保证全局收敛,往往只能得到局部次优解。采用QPSO算法能得到更接近最优解的全局次优解。

图6 总能量消耗与计算数据大小的关系Fig.6 Relationship between total energy consumption and size of computation data


图7 总能量消耗与移动终端个数的关系Fig.7 Relationship between total energy consumption and number of mobile terminals
4 结束语
本文针对MT从环境射频源收集能量较少的问题,提出一种基于混合能量收集的MEC系统中最小化MTs总能耗的资源分配策略。通过部署磁感应能量快速充电站,使得MT从环境射频源收集的能量快不够用时,可以得到能量补充。MT将计算任务分流到MEC服务器进行计算。在保证MT最大计算能力、MEC服务器最大计算资源、任务计算总时延和MT电池能量的前提下,以最小化MTs总能耗为目标,并使用QPSO算法获得次优解。仿真结果表明,QPSO算法优于SPSO算法。此外,相对于等分配MEC服务器计算资源的ER-QPSO方法和ER-SPSO方法,QPSO算法总能耗更低。由于本文只考虑固定的磁感应能量快速充电站,在未来的工作中,将进一步研究动态磁感应能量收集。
猜你喜欢
大电机技术(2022年4期)2022-08-30 01:38:30
预防青少年犯罪研究(2022年1期)2022-08-15 00:35:32
中国特种设备安全(2021年5期)2021-11-06 05:09:26
英语文摘(2020年10期)2020-11-26 08:12:20
电子技术与软件工程(2019年21期)2020-01-16 05:55:44
模具制造(2019年7期)2019-09-25 07:29:58
测控技术(2018年7期)2018-12-09 08:57:56
电信科学(2017年6期)2017-07-01 15:44:53
汽车维护与修理(2015年6期)2015-02-28 12:17:05
肝胆胰外科杂志(2015年1期)2015-02-27 11:11:30
