
基于SDN的数据中心网络中考虑等待时间的流调度策略研究
2021-04-29 04:06:02黄梅根庞瑞琴何大聪
重庆邮电大学学报(自然科学版) 2021年2期
黄梅根,庞瑞琴,刘 亮,何大聪,汪 涛
(1.重庆邮电大学 计算机科学与技术学院,重庆 400065;2.重庆邮电大学 通信与信息工程学院,重庆 400065;3.重庆邮电大学 创新创业教育学院,重庆 400065)
0 引 言
近年来,随着大型数据中心的快速增长以及移动终端的大面积普及,数据中心的规模越来越大,这些数据中心包含数十万台服务器,并承载各种不同的分布式应用程序。许多关键数据中心应用程序涉及许多小型事务通信,如社交网络、web搜索、零售推荐等实时性业务对延迟敏感,即使是很小的延迟也会直接影响应用程序的性能,导致用户的体验效果降低[1-3]。因此,最小化平均完成时间(flow completion time,FCT)非常重要。在已有的研究中,有许多关于降低平均流完成时间的方案,这些方案大致可以分为4种,分别是流的优先级调度、多路径流调度机制、资源预留方案和减少交换机内队列长度的方案。
文献[4]和文献[5]基于优先级调度。文献[5]中pFabric通过在包上标记优先级来最小化流完成时间,使得交换机根据流最小剩余大小对流进行调度。pFabric要求交换机根据流的大小给其分配一个独立的优先级队列,但是当今的交换机无法满足其需求,这使得pFabric的性能大大降低,进而影响FCT。文献[5]研究的是在未知流信息的情况下采用离散的流感知服务,其根据已发送流的数量将流分成少量的优先级队列,跨队列执行优先级,并在每个优先级队列中按照先进先出(first inpat first output,FIFO)的顺序对流进行调度,但频繁切换队列的执行时间就会相应增加,并且队列内部按照FIFO的顺序执行会阻塞后进入优先级更高的流。
文献[6]和文献[7]使用多路径流调度机制来减少FCT。文献[6]提出了一种基于策略借助(software defined networking,SDN)的多路径流调度(SDN based multipath flow scheduling, SMFS)机制。主要思想是通过使用周期性轮询和动态流调度的方法来实现负载均衡,从而提高全网吞吐量。SMFS使用分段路由技术减少控制器与交换机之间的交互,但是容易导致次优解,造成局部最优路由。文献[7]提出一种基于多路广播树的SDN多路径路由算法。主要思想是为网络拓扑中的每个节点创建一个以该节点为根节点的无环广播树,然后根据源节点和目的节点间各个路径的可用带宽和时延进行概率分配转发路径。
文献[8]和文献[9]分别是基于资源预留和减少交换机内队列长度的方案。文献[8]认为对延迟敏感流而言,应该分配更多的网络资源给他们,允许其提前完成,但是忽略了流之间的公平性。当负载较高时,一些对于延迟不敏感的流会一直处于等待分配网络资源的状态。DCTCP(data center transmission control protocol)充分利用网络中的显式拥塞通知(explicit congestion notification,ECN),如果交换机内的队列长度达到阈值,那么交换机将向发送方发送ECN信号。发送方根据交换机的拥塞程度减少其拥塞窗口,从而保证交换机缓存空间的数据占据率始终低于某个阈值,这样短数据流就无须排队通过交换机,并同时保证长数据流的吞吐量比较高。但DCTCP要求交换机要带有ECN功能。所有这些研究的目的都是为了减少平均FCT。
目前最理想的是pFabric与最短剩余处理时间优先(shortest remaining time first,SRTF)调度策略。文献[4,10]已经表明,为了最小化FCT,对网络流进行优先级排序,然后以近似SRTF的调度策略是非常有效的。但pFabric要求给数据中心网络中的每一条流都分配一个相对应的优先级进行调度。但事实上,现有数据中心中可用于流调度的优先级队列是有限的,这一情况使得pFabric策略并不适用于实际的数据中心网络环境中。
根据以上的分析,本文提出一种考虑等待时间的动态流调度策略,该策略为控制器中的一个模块。该策略首先定义了流的优先级划分方法,设计了等待时间的流调度策略(flow priority scheduling algorithm considering waiting time,FPWT)算法;然后借助SDN数控分离和动态全局网络视图的优势,选取最优的转发路径对流进行调度,使得流在尽可能短的时间内完成,进而缩短流的平均完成时间,提高网络的吞吐量。本文主要贡献如下。
1)定义了一种考虑等待时间的优先级划分方法——时间比值(time ratio,TR),即流在实际调度策略下的完成时间与在理想状态下的完成时间的比值,依据TR来对网络中的流进行优先级的划分;
2)设计了FPWT算法,该算法依据网络中流的TR大小来确定发送流的先后顺序,TR最大者优先进行发送,之后以此类推;
3)使用Dijkstra算法,依据全局网络视图选择K条最短路径,然后选择使得FP(flow priority)值最小的一条,即为该流的最终选择路径;
4)在Mininet实验环境下实现FPWT调度策略,并与其他算法对比进行验证。
1 FPWT策略模型
1.1 FCT最小化分析
根据参考文献[4,10],首先对流进行优先级排序,然后以SRTF对流进行调度,是目前实施FCT最小化的比较有效的解决方案。
现有的SRTF能够提供接近最优的平均FCT,但SRTF往往容易忽视长流,这极有可能造成长流的饥饿。处理器共享(processor sharing,PS)策略中,长流可以和短流共享带宽,不会出现饿死长流的现象,但会阻塞长流之后进入的短流,短流的完成时间会大大增加,进而影响平均流完成时间,这与我们追求的最小化流完成时间的目标相违背。因而我们提出FPWT算法,在不影响短流的情况下,长流在等待足够时间后,会获得资源进行发送,而不是一直等到短流发送完毕之后。
该示例如表1,采用SRTF调度策略如图1,由于F2的剩余流大小比F1大,同时到达的F2处于等待状态,F1先独占链路资源,而F1需要2个时间才能完成;在1时刻,F3到达,然后与F2一样进入等待状态;当2时刻F1完成,尽管F2早于F3到,但F3的剩余流大小小于F2,因而不是先来的F2占用链路资源,而是之后到达的F3占用链路资源;在3时刻,F3仍在发送状态,此时F4到达进入等待状态;直到时刻4,F3完成,此时F2的剩余流大小小于F4,则F2进入发送状态,直到F2完成,才会将链路资源分配给F4。SRTF的平均流完成时间为(2+3+7+8)/4=5。
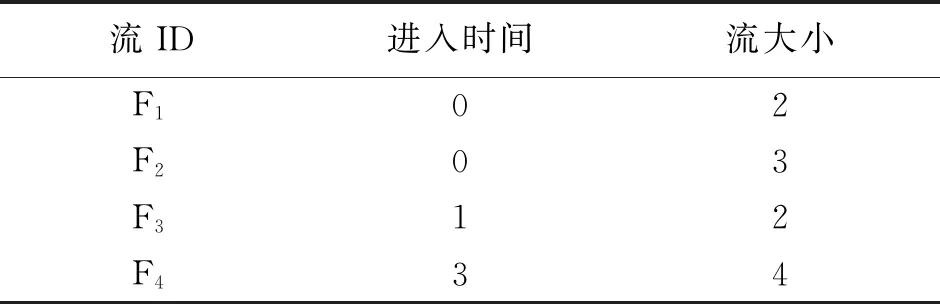
表1 流示例
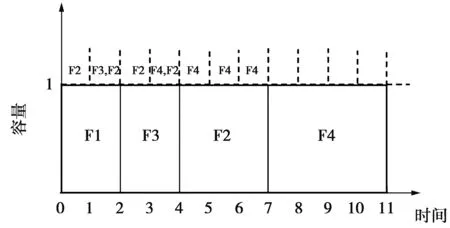
图1 SRTF调度策略示例Fig.1 SRTF scheduling policy
虽然SRTF在平均流完成时间方面可以达到接近最优,但是SRTF容易忽略长流,比如示例中的F2。这会对长流的完成时间造成影响,进而影响平均FCT,从而损害用户的体验效果。
PS策略中所有的流公平的共享带宽。如图2,F1与F2同时到达,链路带宽一分为二,分配给F1与F2,在1时刻F3到达,此时,F1与F2并未完成,链路将会再次平均分配给第三者,即F3。PS的平均流完成时间为((19/3)+(53/6)+(41/6)+8)/4=15/2。
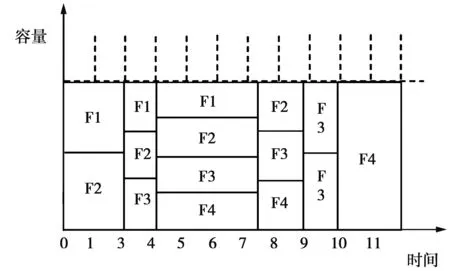
图2 PS调度策略示例 Fig.2 PS scheduling policy
PS的优点就在于所有的流之间实现公平竞争,并且不需提前知道流的任何信息。然而处理器共享的平均流完成时间远远不是最小值。从实例中的SRTF与PS的平均流完成时间对比就可以看出,PS的平均流完成时间大于SRTF。
总之,现有的流调度策略很难在取得接近最优的流完成时间的同时又兼顾长流的饥饿问题,因此,本文提出了FPWT,以兼顾同一时刻进入的短流优于长流进行发送,又能使得等待了一段时间的长流,在保证流完成时间的同时不至于造成长流的饥饿。
1.2 FPWT模型描述
FPWT的目的是最小化平均FCT,并且不能造成长流的饥饿。为了实现这一点,FPWT借鉴SRTF的短流优先策略,引入长流等待时间动态调整的思路,实现不造成长流饥饿的效果,从而达到最小化平均FCT的目的。因此,FPWT设计坚持以下原则。
1)由于SRTF优先处理剩余大小最短的流并且能够获得接近最优的FCT,因此,FPWT针对同一时刻进入的流而言,应保证短流要在长流之前发送;
2)FPWT应保证长流在等待足够长的时间后有机会获得资源进行发送。FPWT使用该时刻流的实际完成时间(包括等待时间与发送时间)与理想状态下的流完成时间(只包含发送时间)的比值对流进行优先级设定,该比值应具有以下2个特征:①如果2个流在同一链路上等待的时间相同,那么越短的流的比值越大;②流的实际完成时间与理想状态下流完成时间的比值随着等待时间的增加而增大。
根据以上分析,给出TR的定义如下。
定义当流到达时,令Afct(f)表示在该调度策略下的实际流完成时间,用Ifct(f)表示理想状态下的流完成时间(也即当流到达就会立即将所有的带宽资源分配给该流,不需要等待)。则流f的TR的定义为
(1)
假设流f在独占链路之前等待的时间为w(也即延迟),则有
(2)
(2)式中:f.size表示流的大小;C表示链路的容量。由(2)式可以看出,假如给定2个流,当链路容量C和等待时间w固定时,较小的流具有较大的TR;当链路容量C和流尺寸大小f.size固定时,任意流的TR随等待时间w的增加而增大。因此,确实满足FPWT应具有的2个特性。
对于网络中大量的流而言,对流的优先级排序始终都是先根据TR的大小进行降序排列,也即是在当前所有流当中依次选出TR最大者进行优先级的降级排序,假设当前有n条流,则某一时刻选择流的规则如公式(3)。
(3)
FPWT根据TR来安排流的发送顺序,在一组流当中TR最大者最先进行发送。表1中的实例使用FPWT调度策略如图3,从图3中发现,虽然F2的大小大于F3,但它比F3先进行发送,这是因为在2时刻,F1完成,此时等待的流有0时刻到达的F2和1时刻到达的F3,虽然F3的大小小于F2,但在2时刻TR(F2)=5/3,TR(F3)=3/2,TR(F2)>TR(F3),因此F2先于F3发送。这在基于SRTF的策略中是不可能发生的。从如图3中注意到,FPWT的平均流完成时间FCT为21/4,仅仅略高于SRTF。
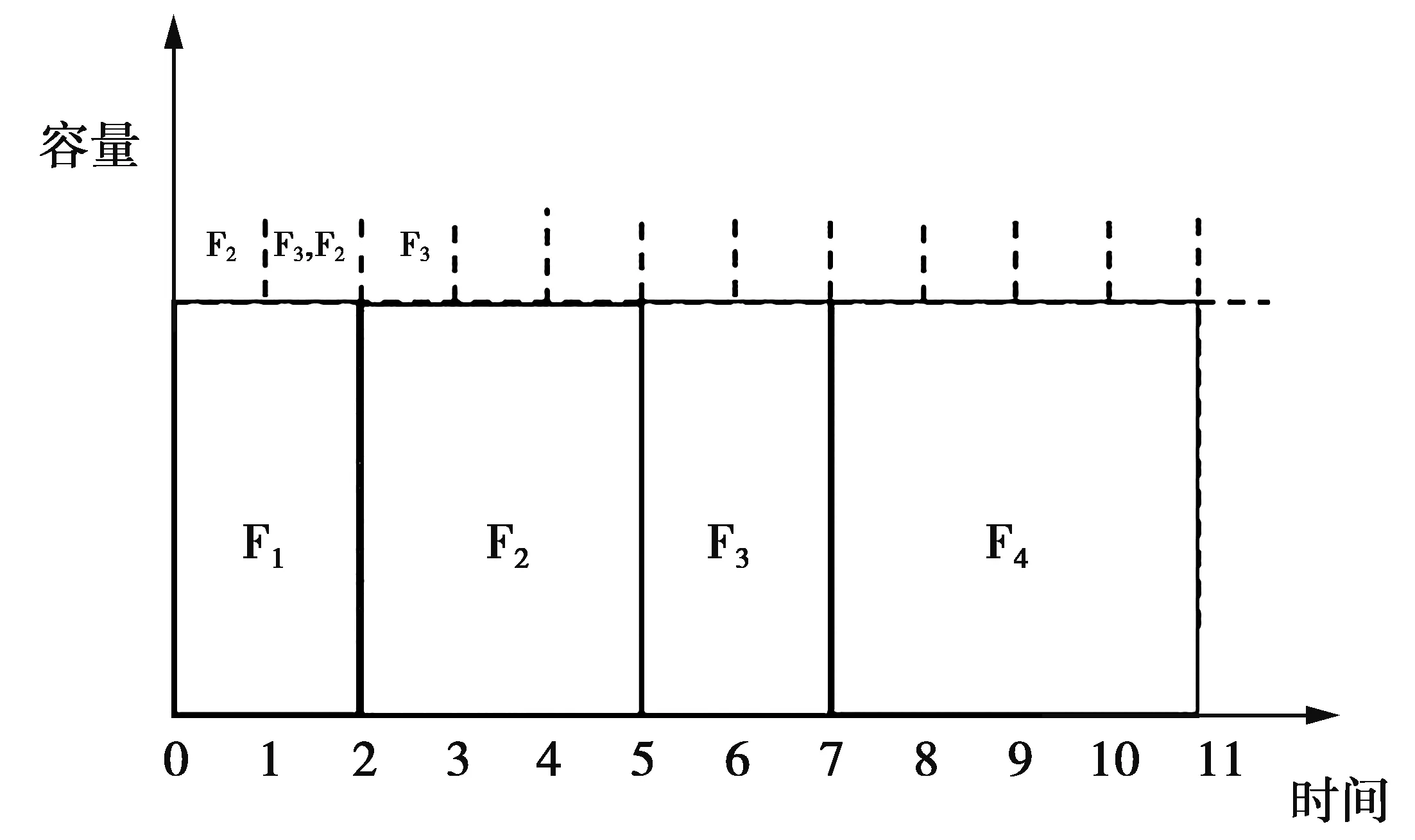
图3 FPWT调度策略示例Fig.3 FPWT scheduling policy
通过前面的例子说明,为了最小化最大的TR,FPWT会给予等待了足够长时间的长流机会,而不是一味优先调度等待少量时间的短流。这样,FPWT可以有效地防止长流饥饿。因此,FPWT可以在不造成饥饿的情况下实现高效的流调度。
2 FPWT策略算法
每个SDN交换机维护一个流表T,流表中存放流ID(id),源地址(S),目的地址(D),流大小(f.size),流到达时间(at),流剩余大小(RS),流的TR(初始化1)。当有TR相同的情况出现时,此时还要考虑RS,RS小者优先进行发送。算法的伪代码如算法1。
算法1FPWT算法
输入:流f,链路容量C,当前时间cT,流表TableT[fi]。
输出:流调度顺序。
1.f.aT=cT
2.TR(f)=∞
3.T.insert(f)
4.while T[fi]≠NULL do
5. maxTR=TR(f1)
6. for fi∈T[fi] do
8. if TR(fi)> maxTR then
9. maxTR=TR(fi)
10. if TR(fi)= maxTR then
11. if RS(fi) 12. maxTR=TR(fi) ⟹Dijkstra 13. return maxTR 在算法1中,第1—3行对新到达的流记录其到达时间,并对TR进行初始化,然后插入流表中。第4—18行找到优先级最高的流,每一步的解释如下。第4—5行当流表T不为空时,假设f1的TR最大,也即f1的优先级最高。第7行计算流表T中的每一条流的TR,然后将每条流的TR(fi)与maxTR相比较,若TR(fi)大于maxTR,则将TR(fi)赋给maxTR(8—9)。如果出现值TR(fi)= maxTR情况,此时就要比较RS(fi)与RS( maxTR)两者的关系,RS更小的赋值给 maxTR(11—12),最终找到maxTR,也即找到优先级最高的流。之后用Dijkstra算法去找路径,对流进行路由。 对于网络中大量的流而言,n条流的TR取决于其中一个流最大TR。当选出一条流之后,总是想让它在尽可能短的时间内完成,那么除了等待时间以外,其他运行时间就要尽可能的短。不同的路径,同一条流的TR也不尽相同,依据全局网络视图,用Dijkstra算法搜索K条候选路径,计算K条路经的该流相应的TR,选择使得该流TR最小的路径即为最终路径,也就是 FP=arg minTR(∪{fn}) (4) 最终路径与其他候选路径相比能让流在更短的时间内完成。为了更好地利用链路带宽,当所选路径仍有剩余带宽时,则将在低优先级队列中选取TR最大的fi进入到高优先级队列中,进行发送,之后依次进行。 对于选取的任意链路uv发送流时要满足以下需求得 (5) 为了验证FPWT的性能,针对所提出的考虑等待时间的动态流调度策略进行仿真,主要对其流完成时间和吞吐量进行性能测试。 基于前面的研究,引入Mininet平台(http://mininet.org/)对所提出的考虑等待时间的动态流调度策略进行仿真实验,使用一个叶-脊拓扑结构(leaf-spine topology),其中有8个叶(leaf)交换机到4个脊(spine)交换机。每个leaf交换机有16个10 Gbit/s的下行链路(即可连接128台主机)和4个40 Gbit/s的上行链路连接到脊交换机,叶脊交换机之间的带宽比例为1∶1,符合叶脊交换机之间的合理带宽比例,不会超负荷。以上仿真环境的搭建全部在一台物理服务器上实现,物理服务器使用Intel(R) Core(TM) i7-7700HQCPU@2.80 GHz处理器,内存为8.00 GB。 本文主要将FPWT与SRTF,DCTCP[4]进行比较。每次用Iperf工具根据需求随机产生20 000条流进行实验,共进行30次实验,记录每次实验的相关数据。以图4—图9中所用数据为30次实验所记录数据的平均值并分析了不同流量大小(0,100) KB,(100 KB,10 MB)和(10,∞)MB的平均FCT,吞吐量(这里的吞吐量以字节为单位进行计算,计算在整个实验期间内输出的总的数据量)。参考文献[4,11],且3种流所占比例分别为50%,30%和20%[11]。 图4 (0,∞)平均流完成时间Fig.4 (0,∞) average FCT 图5 平均吞吐量Fig.5 Average throughput 图6 (0,100 KB) 平均流完成时间Fig.6 (0,100 KB) average FCT 图7 (100 KB,10 MB)平均流完成时间Fig.7 (100 KB,10 MB) average FCT 图8 每组实验的平均吞吐量对比Fig.8 Each group average throughput 图4和图5分别显示了不同链路负载情况下的SRTF,FPWT和DCTCP的总体平均FCT,从图4—5中可以看出,FPWT的总体平均流完成时间表现良好,明显优于DCTCP,平均流完成时间缩短了约27%。虽然与SRPT相比有所增加,但FPWT的稳定性要优于SRTF,与SRTF相不容易出现饥饿的情况,并且吞吐量方面高出SRTF 17%。 针对(0,100)KB的短流,发现在平均流完成时间方面FPWT显著优于DCTCP,平均FCT减少了将近32%,如图6。这是因为DCTCP在终端主机上使用反应速率控制,在网络流量调度方面不如FPWT有效,从图6中我们还可以直观地观察到在短流的情况下,FPWT的平均流完成时间与SRTF相差无几,这是因为在短流和长流同时到达的情况下,FPWT与SRFT一样也是优先发送短流。 图9 (10 MB,∞)平均流完成时间Fig.9 (10 MB,∞) average FCT 对于(100 KB,10 MB)的流,发现FPWT的平均流完成时间高于SRTF,但在平均流完成时间方面优于DCTCP,FPWT在平均FCT相比SRTF多出了近14%,如图7。但在吞吐量方面FPWT的表现优于SRTF(尤其在(100 KB,10 MB)表现的更加明显,吞吐量提高了约36%),如图8。这是因为SRTF总是优先发送短流,当有新的更短的流进入链路时,SRTF总是停止正在发送的流来发送新进入的更短的流,在这种情况下,长流则需要一直等待比它小的短流发送完毕才有机会进行发送,则会导致严重的饥饿问题。而FPWT不仅仅只考虑流的大小,还要考虑流的等待时间来选择流进行发送,当有更短的流进入队列时,并不一定会得到立即发送的机会,因为在队列中已经等待一段时间的长流的TR可能会更大,因此长流仍能早于新进入的短流进行发送。 从图9中可以观察到,对于(10 MB,∞)的长流,FPWT在平均流完成时间方面显著优于DCTCP(尤其是在负载为0.8时,平均流完成时间缩短了近35%)。但是与SRTF相比较而言,平均流完成时间有所增加,增加了大约18%(也是在负载为0.8时,平均流完成时间增加了近约23%),但在平均吞吐量方面的表现仍然优于SRTF。随着链路负载的增大,平均流完成时间也随之增加。 本文提出一种考虑等待时间的动态的流调度策略,定义了流的优先级划分方法,设计了FPWT算法,选取最优的转发路径对流进行调度,使得流在尽可能短的时间内完成,从而缩短流的平均完成时间,提高网络的吞吐量且不容易出长流饥饿的情况。最后实验结果证明,本文提出的FPWT有效缩短了平均流完成时间,提高了网络吞吐量并且不容易出现长流饥饿。 仿真实验发现FPWT的最佳性能体现在(0,10)MB,但随着链路负载的网络流大小的增加,平均流完成时间明显增大。未来,将进一步完善FPWT,并在其他大规模的网络拓扑环境下验证其性能。3 路径选择
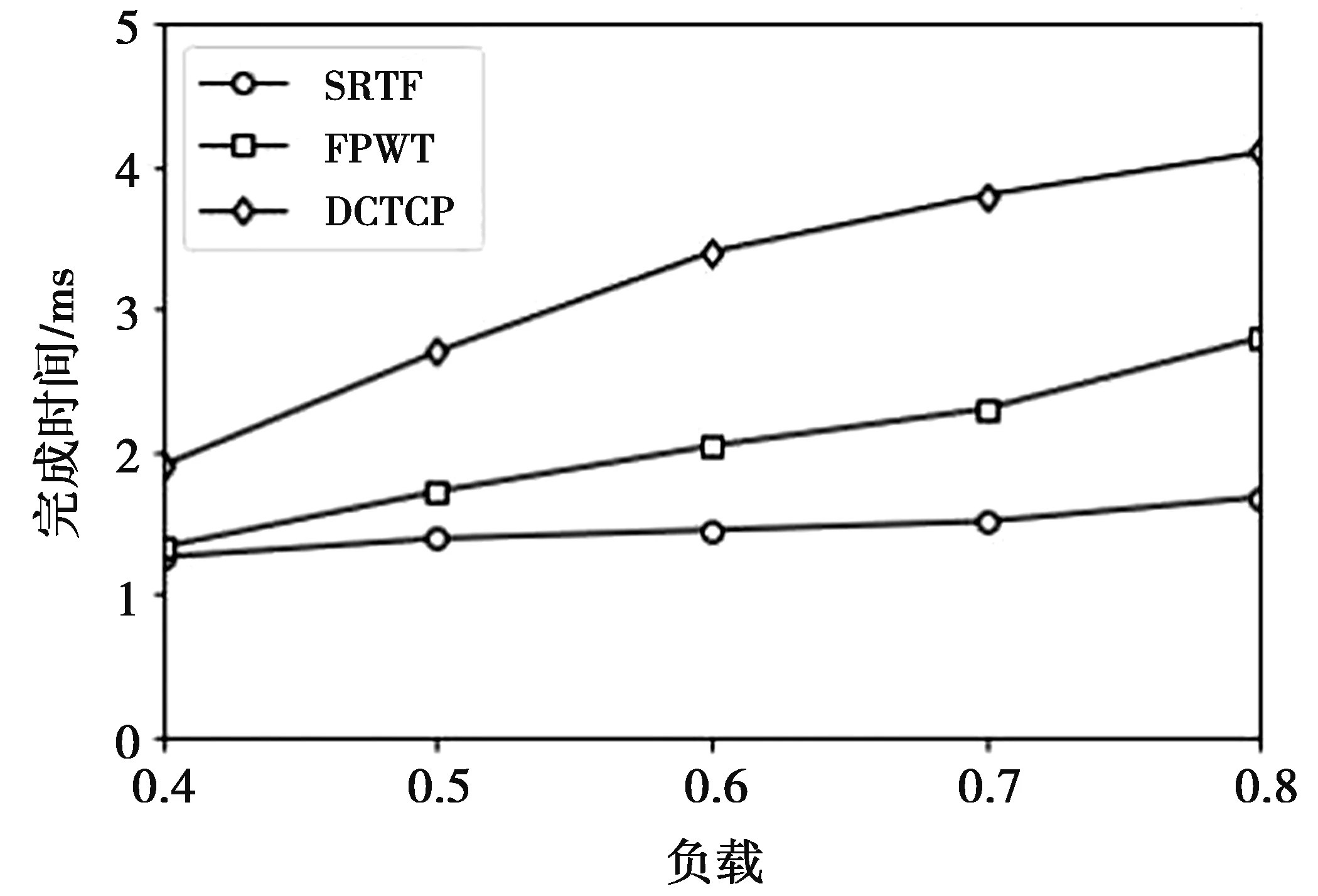
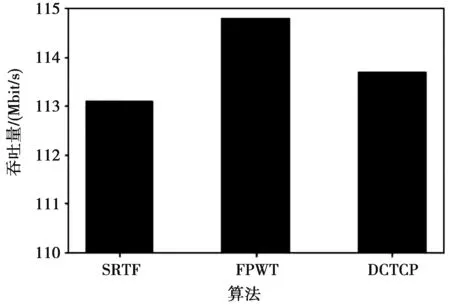
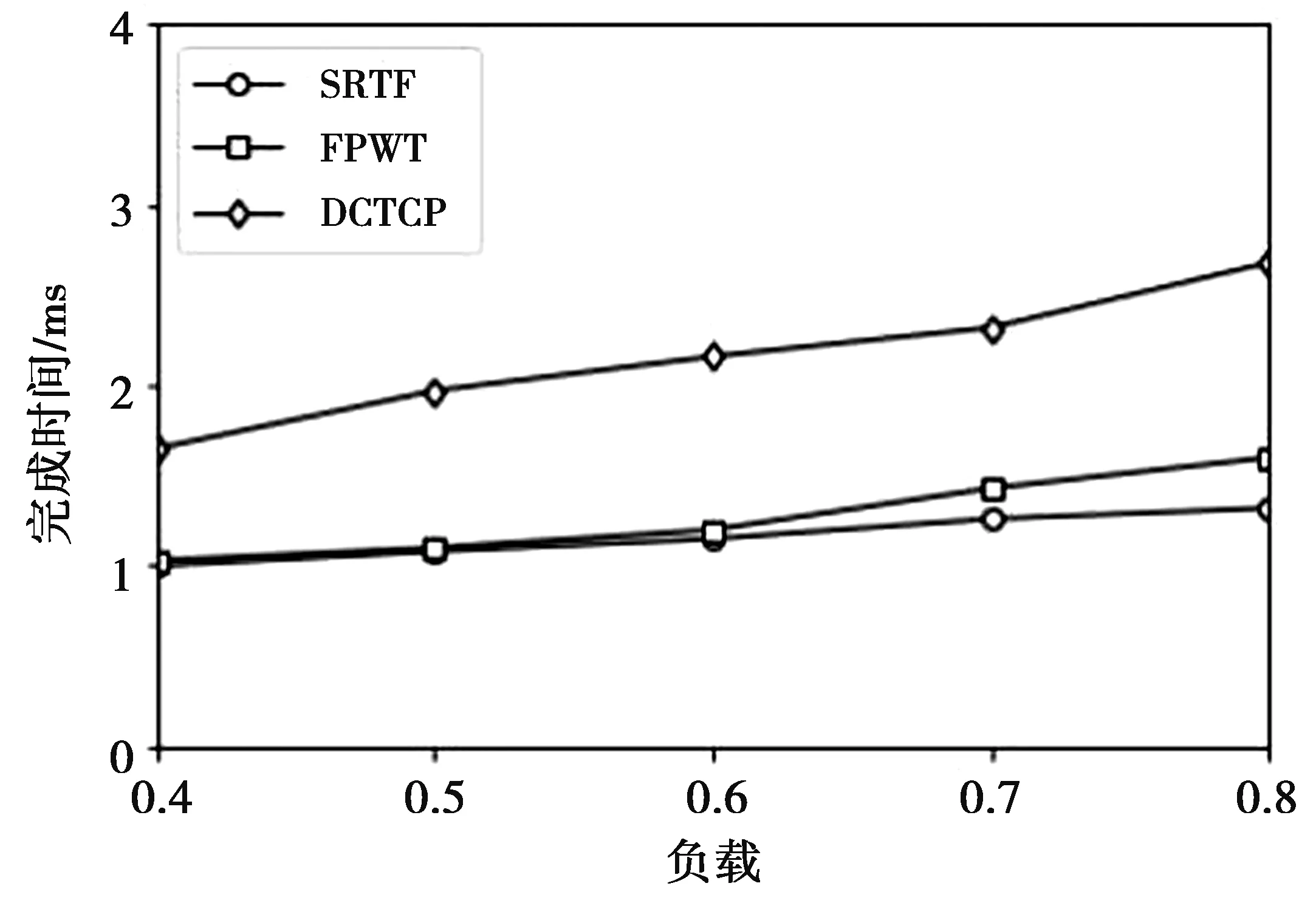
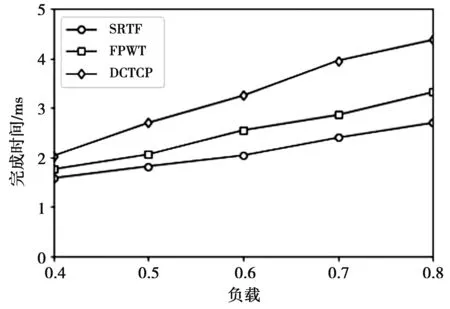
4 仿真和结果分析
4.1 仿真及拓扑结构
4.2 仿真过程及结果分析
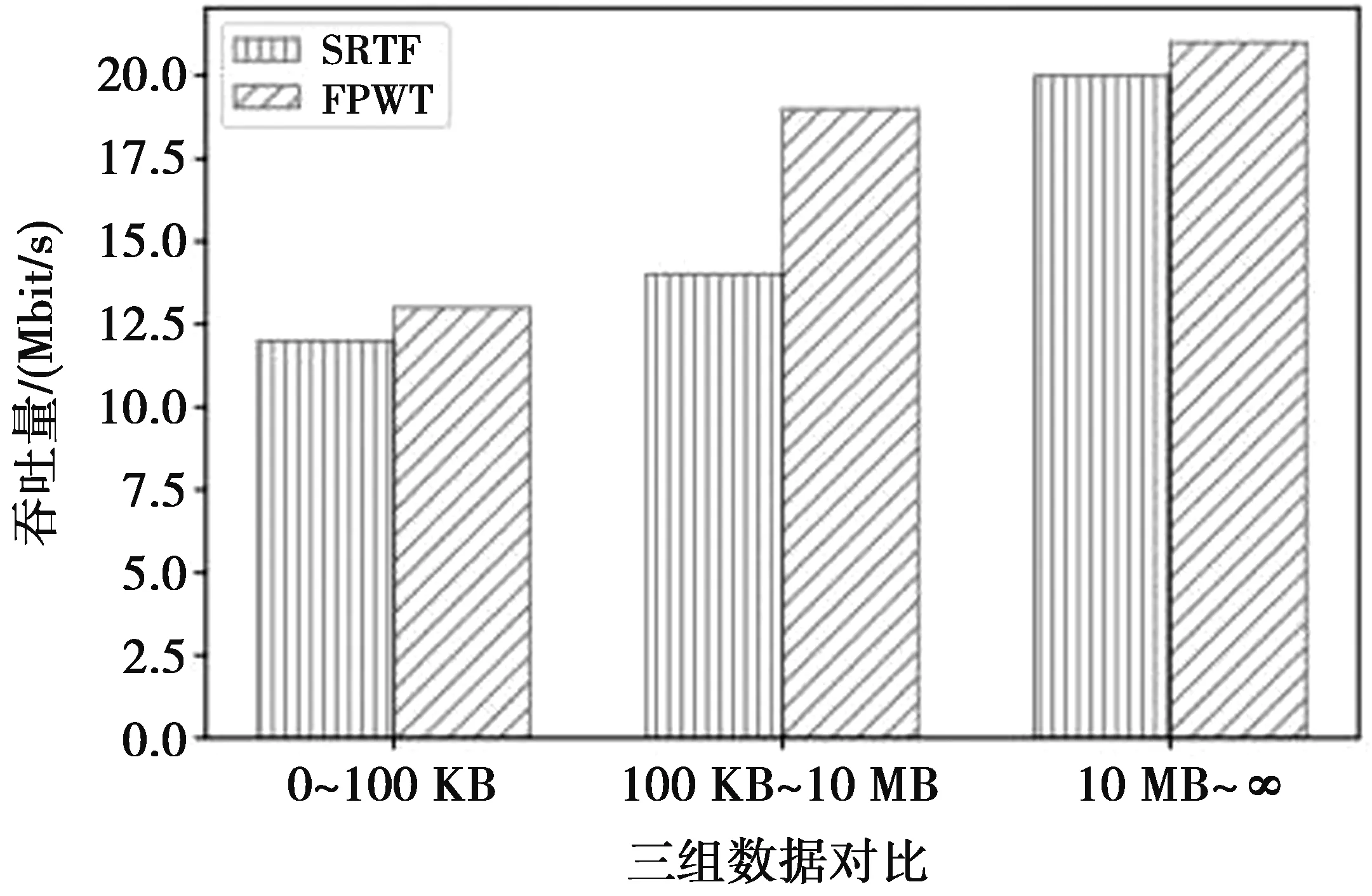
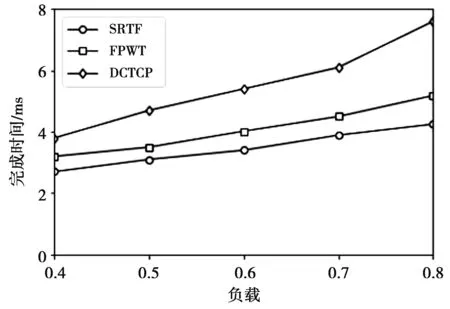
5 结束语
猜你喜欢
——国外课堂互动等待时间研究的现状与启示
中小学教师培训(2022年6期)2023-01-11 02:10:03
扬子江(2020年4期)2020-08-04 09:39:04
生态文明新时代(2018年2期)2018-03-21 05:18:08
作文通讯·高中版(2017年11期)2017-12-20 08:09:30
小雪花·初中高分作文(2017年6期)2017-06-29 08:00:20
集装箱化(2016年11期)2017-03-29 16:15:48
集装箱化(2016年12期)2017-03-20 08:32:27
公民与法治(2016年2期)2016-05-17 04:08:28
视野(2015年14期)2015-07-28 00:01:44
读者(2015年12期)2015-06-19 16:09:14
