
少样本学习下的服装风格分析与评价
2021-04-29 01:09:36胡梦莹钟跃崎
毛纺科技 2021年4期
胡梦莹,钟跃崎,2
(1.东华大学 纺织学院, 上海 201620; 2.东华大学 纺织面料技术教育部重点实验室, 上海 201620)
服装图像包含丰富的特征信息,以服装作为研究对象进行分类识别,并设计相关应用层出不穷,不断吸引着服装行业与计算机视觉方向研究者的注意并为此创新技术。一方面是由于电子商务行业的兴起,大量服装数据需要被合理分类和检索,另一方面是由于深度学习技术在计算机视觉方面不断实现突破。相关的研究包括服装解析与分类[1],服装检索[2],服装搭配推荐[3],服装流行度预测[4]等。结合深度学习的服装风格的分类与评价工作相关记录甚少。
不同于识别一件服装的类别(毛衣,短袖,连衣裙)或其属性(颜色,图案),服装风格是表征服装整体视觉效果的高层次概念,需要分析对比大量的特征来判断其属性。以往研究中,评定服装风格一般采用主观评价的方法,缺少主观感受与评判指标间关系的研究,因此,通过提取各类服装特征并对其进行总结类比对服装风格的量化具有重要意义[5]。
服装风格识别的关键在于服装图像的特征提取,传统的基于目标图像的颜色特征、纹理特征、形状特征、SIFT特征[6]、HOG特征[7]提取方法在这一领域并不适用。卷积神经网络具有复杂的层级结构,具有局部连接特性和权值共享特性,适用于服装图像的特征提取。利用卷积神经网络对服装图像提取对应风格的特征,有助于实现基于服装风格的分类。
本文以不同品牌的服装图像为研究对象,采用卷积神经网络提取服装图像的视觉特征的方法,将其映射到风格特征空间,实现品牌服装风格的分类识别。由于实验数据集样本数量少,采用少样本学习[8-9]的方法进行实验。
少样本学习方法更接近人类的学习模式,是元学习(meta Learning)[10]在监督学习中的应用。元学习旨在让模型学会如何学习(learning to learn),能够处理类型相似的任务,而不是只会单一的分类任务。
少样本学习任务包含3 个数据集: 训练集、支持集和查询集。如果支持集包含N类相互独立的类别,每个类别包含K个样本,此时的少样本学习问题则被称为N类别K样本(N-way,K-shot) 问题。本文选用3种目前比较流行的网络架构来对自建的数据集进行测试,分别是Siamese 网络[11],Prototype 网络[12]和Meta baseline 网络[13]。
1 实验部分
1.1 数据的采集
本文建立了一个品牌服装风格图像数据集,该数据集中所有图像均来自时尚网站VOGUE[14],包含了VOGUE网站时装秀场的50个服装品牌,分别是亚历山大麦昆(Alexander McQueen)、亚历山大王(Alexander Wang)、鄞昌涛(Andrew Gn)、安娜苏(Anna Sui)、阿玛尼高定(Armani Prive)、巴黎世家(Balenciaga)、巴尔曼(Balmain)、蓝色情人(Blumarine)、葆蝶家(Bottega Veneta)、博柏利(Burberry)、卡尔文·克雷恩(Calvin Klein)、卡罗琳娜·埃莱拉(Carolina Herrera)、沙杜·拉尔夫·鲁奇(Chado Ralph Rucci)、香奈儿(Chanel)、克洛伊(Chloe)、克里斯汀·迪奥(Christian Dior)、德里克·林(Derek Lam)、杜嘉班纳(Dolce & Gabbana)、德赖斯·范诺顿(Dries Van Noten)、安普里奥·阿玛尼 (Emporio Armani)、艾特罗(Etro)、芬迪 (Fendi)、詹巴迪斯塔·瓦利 (Giambattista Valli)、乔治·阿玛尼(Giorgio Armani)、纪梵希(Givenchy)、古驰(Gucci)、爱马仕(Hermes)、杰斯· 舞(Jason Wu)、高缇耶 (Jean Paul Gaultier)、吉尔·桑达 (Jil Sander)、浪凡 (Lanvin)、路易威登(Louis Vuitton)、马克·雅可布之马克(Marc by Marc Jacobs)、马克·雅可布(Marc Jacobs)、玛尼(Marni)、麦士迈娜(Max mara)、迈克高仕(Michael Kors)、米索尼(Missoni)、缪缪(Miu Miu)、莲娜丽姿(Nina Ricci)、奥斯卡·德拉伦塔(Oscar de la renta)、普拉达(Prada)、拉尔夫·劳伦(Ralph Lauren)、斯特拉·妮娜·麦卡特尼(Stella Nina McCartney)、汤米·希尔费格(Tommy Hilfiger)、汤丽柏琦(Tory Burch)、瓦伦蒂诺(Valentino)、王微微(Vera Wang)、范思哲(Versace)、圣罗兰(Yves Saint Laurent)。每个品牌的服装图像为30张,共计1 500张图像。随机抽取36个服装品牌用作训练集,剩余14个服装品牌用作支持集。
1.2 预处理
为了提高服装图像分类准确率,对参与训练的服装图像数据进行归一化、去均值预处理,用于后续的实验。
1.2.1 归一化
归一化也是一种简化计算的方式,将有量纲的表达式,经过变换,简化为无量纲的表达式,成为标量,便于不同单位或量级的指标能够进行比较和加权。归一化将数据映射到指定的范围,减少了各维度的数据取值差异,减少了因数据取值范围差异大造成对分类实验结果的影响。常见的归一化方式有特征标准化、图像像素的简单缩放等。本文采用min-max归一化:
式中:xnew为经过归一化处理后得到的新数据值,xmax为样本数据的最大值,xmin为样本数据的最小值。
1.2.2 去均值
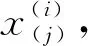
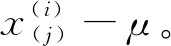
1.2 服装风格分类模型
1.2.1 Siamese网络
在解决N-way、K-shot分类问题方面,孪生神经网络(Siamese neural networks)是最早得到应用的模型[12]。孪生神经网络的结构如图1所示,该类模型包含2个分支(如图1的分支1和分支2)。每个分支分别对应1个输入,该类输入可以是一维的信号、二维的图像、三维的点云或三角形网格。每个输入均经过降维或映射后变成1个长度固定的特征向量,如图1的特征向量1和特征向量2。计算特征向量1和特征向量2的相似程度。
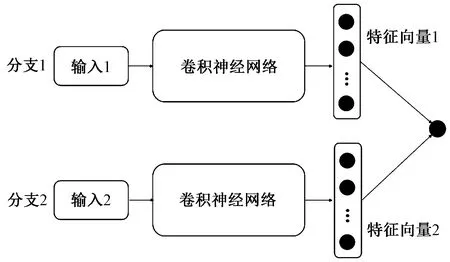
图1 孪生神经网络结构示意
1.2.2 Prototype网络
除了孪生网络以外,本文还使用了Prototype 网络,该模型的原理如图2所示。

c1—类别1的特征向量;c2—类别2的特征向量;c3—类别3 的特征向量;x—查询样本。图2 Prototype 网络原理
如图2所示,若训练样本包含3个类别(不同颜色),每个类别包含5个样本,求每类的特征向量均值ck,其计算方法为:
式中:k=1,2,3,指代类别,每个类别的特征向量均值记为c1、c2、c3。Sk是训练样本中属于第k类样本的集合,xi是集合Sk中的第i个样本,yi是xi的标签,fw(xi)是样本xi的特征映射(特征向量),其中w为待学习的参数。当k为1时,Sk包含5个样本,即i的取值为{1,2,3,4,5}。以每个类别的特征向量均值c1、c2、c3分别作为该类的原型,若1个新的样本x属于图2所示的c2类,则x的特征向量与c2之间的距离要小于其与c1或c3的距离。在训练的过程中以样本x与各个类别均值的距离来计算样本x属于各个类别的概率,同类距离近,异类距离远。使用交叉熵损失函数实现模型的优化。在测试集(支持集)上也采用求特征向量均值的方法,然后计算查询样本与支持集的每个类别中心的距离,以该距离作为度量依据判断查询样本的类别。
1.2.3 Meta baseline网络
该网络包含2个部分,第1部分是Classifier-baseline,是通过预训练得到1个具有分类功能的分类器。具体实现时,首先以交叉熵为损失函数在训练集上训练1个标准的分类网络fθ,然后将该网络最后一层的全连接层(FC)去掉,利用该训练好的卷积模块作为特征提取器,提取支持集(support set)和查询集(query set)中样本的特征向量(representation)。第2部分是meta baseline,元学习框架。元学习框架是以提取的特征向量实现小样本任务的分类,若支持集中每个类别含有多个样本(shot大于1),则将多个样本的特征向量均值(mean)作为该类别的中心,然后计算查询集(query-set)中查询样本的特征向量与支撑集中每个类别特征向量均值的余弦距离(cosine similarity),计算出查询样本对每个类别的得分(概率)。模型结构如图3所示。

图3 meta baseline网络结构图
2 实验结果
为了实现较高分类准确率,同时控制训练的时间成本,设置了80次迭代训练。以线性衰减作为学习率的衰减方式,由于在网络训练中设置适当的学习率、设置适当的权重衰减系数、设置适当的图像大小可以提高网络的学习效率,下面依次对上述影响因素进行验证。
2.1 Siamese网络实验结果
Siamese网络实验结果如表1所示。

表1 Siamese网络实验结果
可以看到,模型的学习率、权重衰减系数的选择、设置图像的大小对实验结果有影响,其中设置图像的大小对实验结果影响较大。从实验结果来看,图像大小设置为224×224 dpi最合适。本文实验还尝试了将图像大小设置为300×300 dpi,但是对结果影响不大,而且训练时间成本比224×224 dpi的大。所以,输入模型的图像大小最终设置为224×224 dpi。
2.2 Prototype网络实验结果
Prototype网络的实验结果如表2所示。
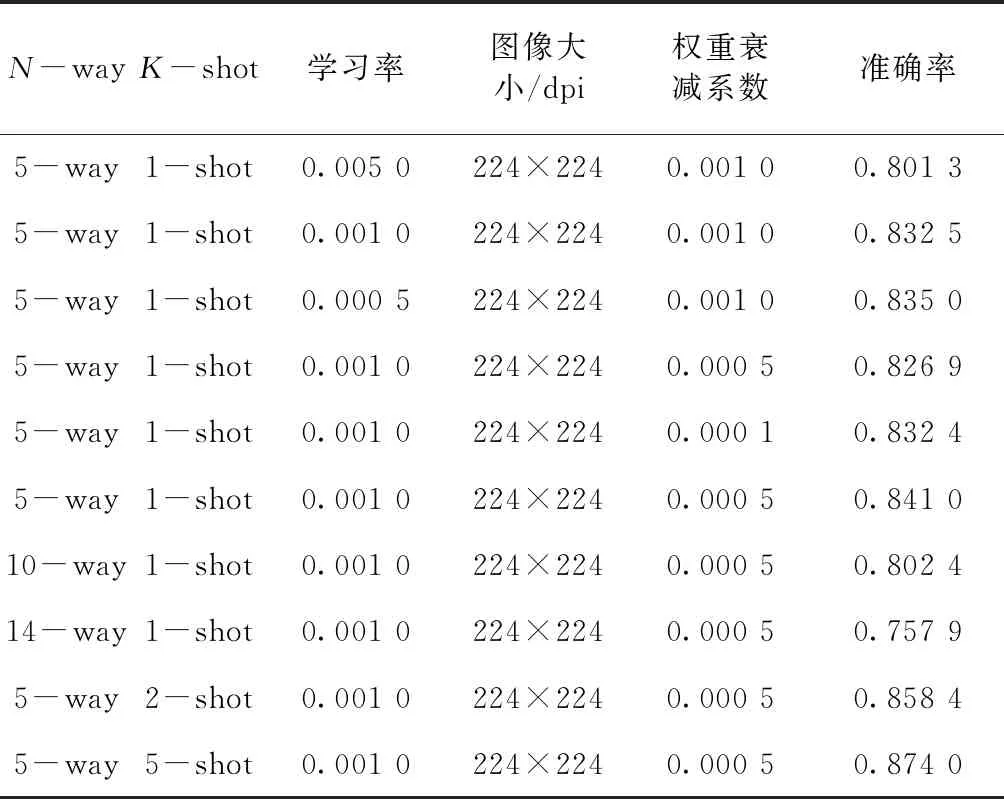
表2 Prototype网络实验结果
实验结果表明,Prototype网络模型对于品牌服装数据集的分类准确率相比于Siamese网络有了一定的提高。在5-way,1-shot任务中,在最优参数下,品牌服装数据集分类准确率高达0.841 0。
2.3 Meta baseline网络实验结果
Meta baseline网络的实验结果如表3所示。

表3 Meta baseline 网络实验结果
实验结果表明,Meta baseline网络对于自建的品牌服装数据集的分类任务的效果比前2种方法的效果都好,分类效果有了很大的提升。在5-way,1-shot任务中,在最优参数下,品牌服装数据集分类准确率高达0.947 5。由于实验环境的限制,本实验选择了ResNet-12作为基线网络,batchsize均为1。虽然理论上这意味着随机梯度下降,但是从实验效果来看,优化的过程中,震荡现象并非过于激烈,可为工程实践中,当硬件条件有限时的网络训练实践提供一定的参考。
3 结束语
本文利用深度神经网络将服装的风格特征提取为特征向量,从数学的角度来描述服装风格特征并判断服装风格特征的相异性。对比分析了适合本文数据集网络模型的分类结果,并验证了可能影响分类结果的参数。本研究对于稳定服装品牌风格,提升传统服装产业,迎合在线服装市场,满足消费者的消费需求,对服装在线交易的风格推荐、风格评估具有一定的参考价值。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
趣味(作文与阅读)(2021年9期)2022-01-19 01:25:56
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
米娜·女性大世界(2016年9期)2016-12-02 19:05:42
新校长(2016年8期)2016-01-10 06:43:59
股市动态分析(2015年20期)2015-09-10 20:40:44
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
