
基于Transformer的普通话语声识别模型位置编码选择
2021-04-28 08:28徐冬冬
应用声学 2021年2期
徐冬冬
(中国航天科工集团第二研究院研究生院 北京 100854)
0 引言
自动语声识别(Automatic speech recognition,ASR)中的序列到序列(Sequence to sequence, S2S)方法渐渐得到广泛关注,这是由于能够训练一个共同的目标来优化整个模型结构,与传统的混合系统相比,它降低了模型优化的复杂性。ASR 系统将声学、发音字典和语言建模组件的功能组合到单个神经网络中,实现从声频号到文本序列的直接映射。早期ASR方法采用连接时序分类(Connectionist temporal classification, CTC)[1],但是,这些模型需要与外部语言模型保持一致才能获得良好的性能[2]。最初提出用于机器翻译的具有注意力[3]的循环神经网络(Recurrent neural network, RNN)编码器-解码器[4]是端到端ASR[5]的有效方法。这些系统在无语言模型设置中[2]的性能下降较少。
最近,Transformer[6]编码器-解码器体系结构已应用于ASR[7−9]。Transformer 训练可实现跨时间并行化,与带有循环机制的模型相比,速度更快[6]。这使得它们特别适合语声识别中遇到的大型声频语料库。此外,Transformer是一种强大的自回归模型[10],在推理过程中无需使用语言模型即可获得不错的识别效果而不会产生存储和计算开销问题[8]。
尽管当前的ASR 技术在准确性上已取得了显着提高,但Transformer 层在自注意的加权操作中不会保留位置信息,为了引入输入特征顺序,使用了正弦位置嵌入。之前ASR 系统在编码网络中显式的添加循环神经网络层,也在一定程度上获得了上下文相关信息。但本文认为上述位置编码增加了模型优化的代价,隐式的添加相对位置信息,会具有更好的效果。具体来说,利用神经网络将输入特征和位置信息融合起来,并映射为高层特征表达,作为Transformer 自注意层的输入。本文通过比较基于Transformer 的不同位置编码技术特点,探索更加适合普通话语声识别的位置编码技术。
1 Transformer语声识别系统
本文工作中使用的架构与Vaswani 等[6]介绍的Transformer 模型类似,模型可以视为编码器-解码器模型。编码器模型以经过子层处理的语声特征作为输入,并对输入进行非线性变换以生成隐状态表示,该隐状态表示被馈送到解码器中,该解码器再次应用非线性变换以产生文本。Transformer 整体架构如图1所示,左半部分和右半部分分别表示堆叠多层自注意层和全连接前馈神经网络层的编码器和解码器结构。下面从局部到整体详细解释每个模块。
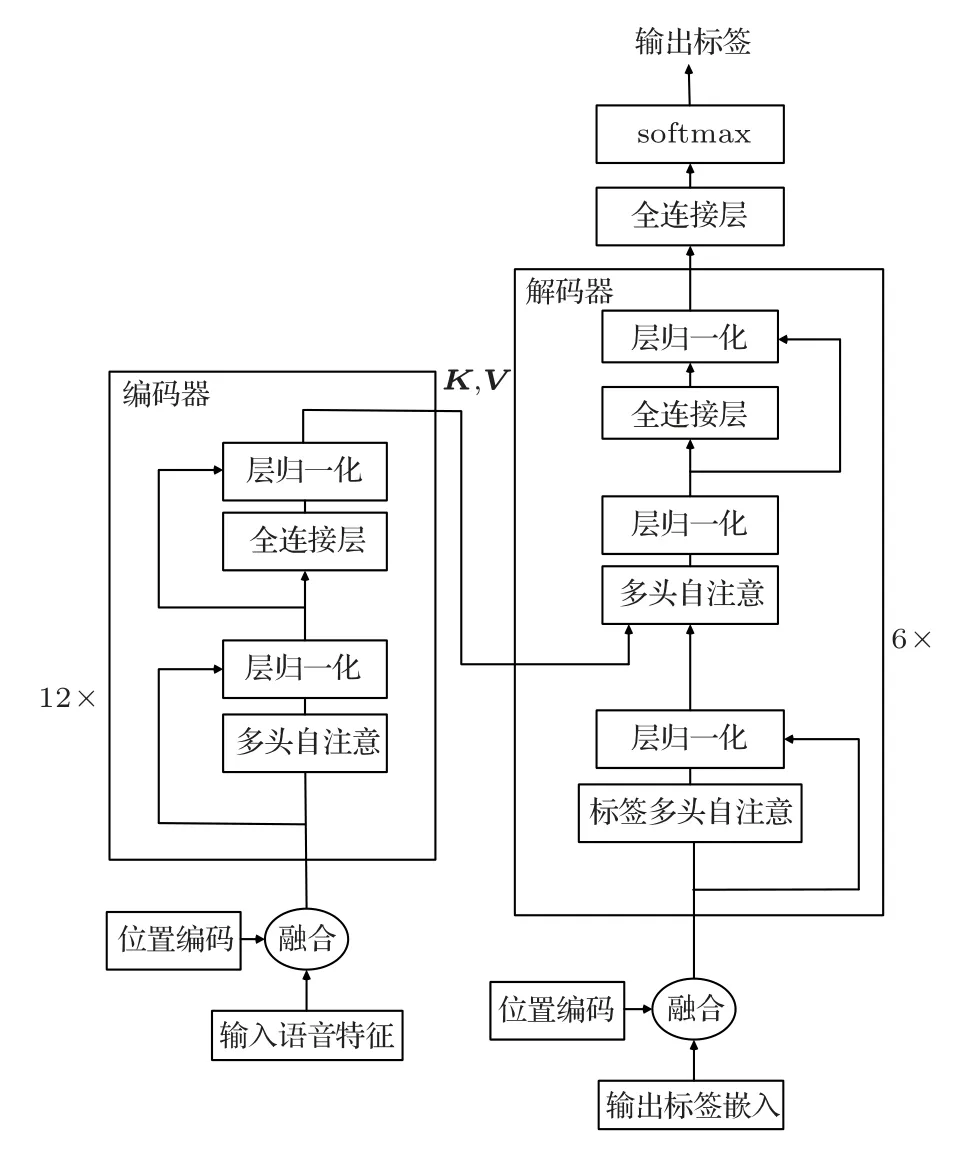
图1 Transfor mer 语声识别系统架构Fig.1 Transformer speech recognition system architecture
1.1 多头注意
首先,注意力是指使用基于内容的信息提取器的方法将维度为dmodel的输入映射到一组查询Q、键K和值V的矢量输出中[11]。其中查询Q和键K的维度为dk,值V的维度为dv。使用所有的键计算查询的点积,再分别用根号dk进行除法运算,并应用softmax 函数来获得值的权重。最后返回值的加权总和,如式(1)所示:
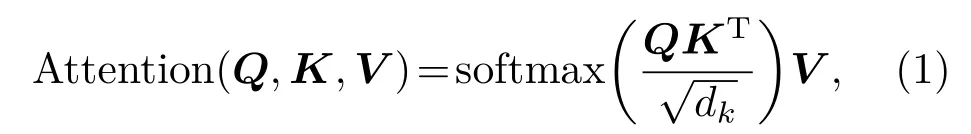
这里除以根号dk的原因是为了抵消softmax 函数输入过大时,计算梯度太小的影响。
多头注意是指采用h个注意力操作表示输入信息,最后将输出结果串联。即多头注意层输出是将各个注意头的级联输出乘以权重矩阵来计算的。
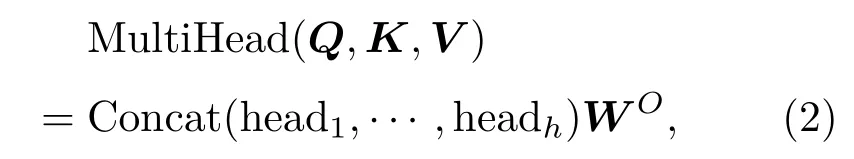
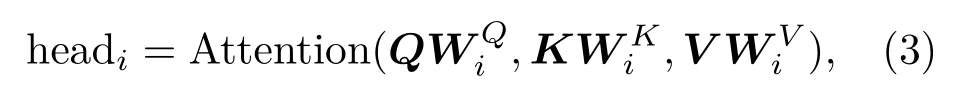
1.2 编码器和解码器模块
编码器:编码器由12个相同的层块组成。每个层块都有两个子层。第一个是多头自注意层;第二个是完全连接的前馈神经网络层,该前馈神经网络由两个线性变换组成,中间具有ReLU 激活。公式表达如下:
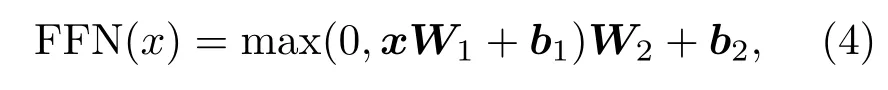
由式(4)可以看出该前馈过程也可描述为内核大小为1 的卷积。两个子层附近都添加了残差连接,接着进行层规范化[12]。
解码器:与编码器类似,解码器是由6 个相同的层块组成。不同的是,解码器层的每个层块由3个子层组成,其中两个子层的功能与编码器子层相同,而两个子层中间的子层对编码器层的输出执行多头关注。具体来说,来自最终编码器层的键和值向量被馈送到解码器层中的多头注意层,查询向量值从其下一层中获得。同时要保持模型的自回归特性,本文在解码器的多头注意层中使用掩蔽,以防止其依赖于将来的位置,从而使输出的标签序列只利用的当前位置以前的信息。残差和层归一化的设置与编码器相同。使用可学习的嵌入将输入标记和输出标记转换为维度dmodel的向量。
1.3 位置编码
Transformer 层的一个明显特点是输出对于输入顺序排列是不变的。即,对于施加在输入序列x1,x2,···,xT上的任何排列π,可以通过在z1,z2,···,zT上应用相同的排列π来获得Transformer 层的输出。这意味着transform 不对输入序列的顺序建模。文献[6]通过正弦位置嵌入将绝对位置信息注入到输入序列中。但本文认为在处理语声识别问题时,相对位置对于语声信号可能更有用。于是在接下来研究中,比较了4 种将位置信息编码到Transformer 层输入中的方法:正弦位置编码、帧组合编码、帧堆叠编码、卷积编码。
(1)在第一种方法中,正弦位置编码,是将绝对位置信息进行了编码。
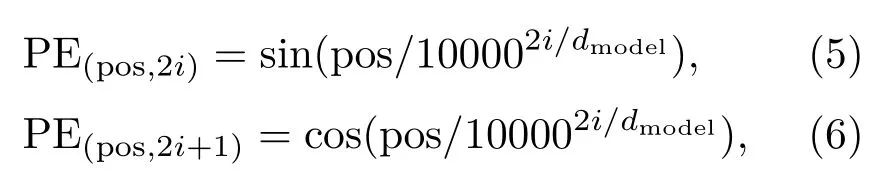
其中,pos 是位置,i是维度。也就是说,位置编码的每个维度对应于正弦曲线。波长形成从2π 到10000×2π 的几何级数。例如,pos=3,dmodel=512,那么3对应的位置向量如下:
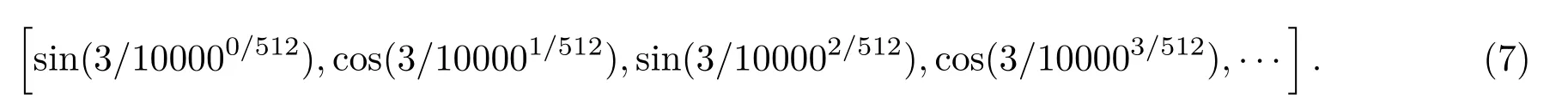
需要注意的是,位置向量与输入序列向量需要进行相加这样的特征组合方式,因此位置向量的长度必须为dmodel。
(2)在第二种方法中,帧组合是每两帧叠加并跨步一次:它不会破坏特征序列中的排列不变性,因此表示为帧组合编码。
(3)在第三种方法中,帧堆叠是将当前帧和接下来的8 个未来帧堆叠在一起,然后进行移动步长stride = 2采样,以形成新的Transformer输入序列。这里由于堆叠的帧与其相邻的堆叠的帧部分地重叠,因此排列不变性不再成立。
(4)在第四种方法中,卷积是对基于帧序列的梅尔滤波器组特征进行操作,结构如图2所示。利用卷积神经网络的在时间和空间维度的平移稳定性,将相对位置信息添加到特征序列中。
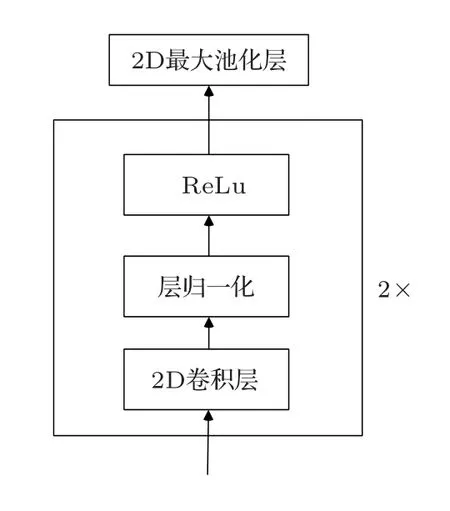
图2 卷积位置编码Fig.2 Convolutional position code
本文配置了两个2D 卷积层,每个卷积层后连接归一化层和Relu激活,第二层后接一池化尺寸为2×2的最大池化层。两层通道数分别为32和64。对于80维的特征输入,输出是2560维。比较了不同卷积核尺寸对识别性能的影响。
最后连接一个线性投影层用于将特征向量投影到Transformer 可以接受的尺寸,即dmodel。为了保证实验公平性,本文标签序列嵌入向量均采用正弦位置编码,维度为512,进一步研究编码器输入的不同位置编码方法对识别性能的影响。
2 实验
2.1 实验数据
语声数据来自于中文语声数据集AISHELL-1,包含178 h 来自400 个说话人的普通话声频和相应文本信息。AISHELL-1 中的声频数据重采样为16 kHz,16 位的WAV 格式。开发人员将数据集分为3 个部分:训练集、验证集和测试集。训练集包含来自340 个说话者的120098 个发音和大约140 h的普通话语声数据;验证集包含来自40个说话者的14326 个语句;测试集包含来自20 个说话者的7176个语句。对于每个说话者,大约发布了360 个语句(大约26 min的语声)。
2.2 特征选择
输入特征是80维梅尔滤波器组特征,将语声通过预加重、分帧和加窗、傅里叶变换和功率谱以及滤波器组有序计算的[13]。设置窗长为20 ms,帧移为10 ms。
2.3 建模单元选择
普通话ASR 任务的典型建模单元是带有声调的声母/韵母分开单元,带有声调的音节和单个汉字[14]。语声数据集中声频对应标注即文本。考虑到使用其他建模单元进行重新标注的成本,本文使用pypinyin库将汉字转化为拼音。例如,“中国航天科工二院”分别用上述3 种建模单元获得的标签序列为“zh ong1 g uo2 h ang2 t ian1 k e1 g ong1 er4 y uan4”、“zhong1 guo2 hang2 tian1 ke1 gong1 er4 yuan4”、“中 国 航 天 科 工 二 院”。考虑到本文的任务需要对齐每个汉字,选择标签数量较少的带声调的音节作为输出标签。
2.4 参数设置
在本文工作中,dmodel参数设置为256。dmodel参数确定子层和嵌入层的输出尺寸。参数注意头数h设置为32。参数dk(查询,键向量维)、dv(值向量维)设置为dmodel/h= 8。参数dff设置为1024。参数dff表示编码器和解码器层中完全连接的前馈神经网络层中隐藏单元的数量。
使用交叉熵作为模型的损失函数。在解码器块之后,线性全连接层用于执行细微变换并将输出映射到标签数量的维度,本文统计的标签数为1356。而softmax 激活用于获得输出预测概率。本文结合使用了波束搜索解码器和外部3-gram语言模型,称为浅层融合[15]。在解码器预测结束标签之后,标签预测过程停止。
使用Adam[16]优化器对该模型进行了120 个周期的训练,并且批处理大小设置为100。在这项工作中,使用了基于带声调拼音的模型。该模型在每个时间步都预测一个拼音。所有代码均使用keras和Tensorowow 2.0深度学习框架编写。
2.5 实验结果
(1)设置两个卷积层的卷积核尺寸大小分别为(31, 9)和(16, 9),移动步长分别为(2, 2)和(2, 1)。这里设置帧数目方向上的核尺寸为9,是为了与堆叠帧编码保持同一水平。将上述配置卷积编码与其他3 种位置编码方法比较,在验证集和测试集上的词错率(Word error rate, WER)实验结果如表1所示。
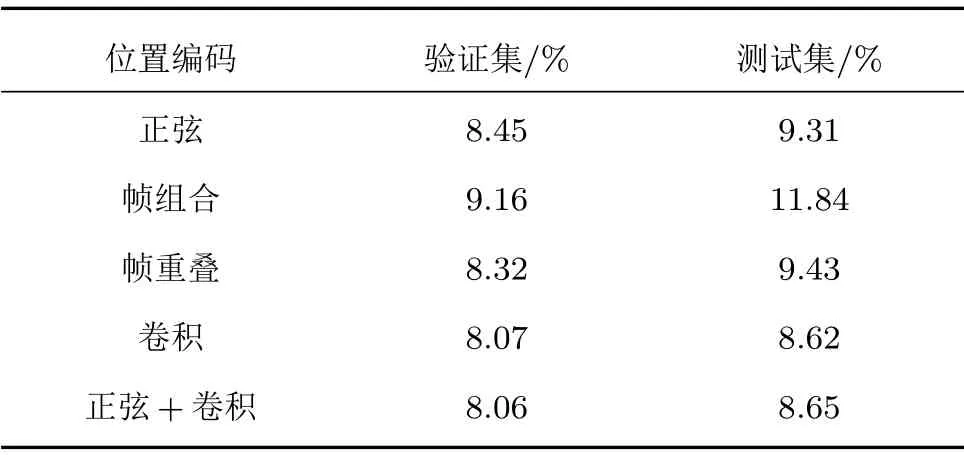
表1 不同位置编码方法的WERTable 1 WER with different position codes
由表1中数据可知,正弦位置编码仍然保持较好的识别效果,测试集上的WER为9.31%。帧组合在验证集上的WER 大小和其他方法接近,但是在测试集上的WER 相比偏高,推测该方法没有将帧序列的相对位置信息编码进特征中,导致模型欠拟合,存在泛化能力不足的问题。
帧重叠位置编码得到与正弦位置编码十分类似的结果,可以判断两者方法都具有改善模型性能的优势。但是也发现,正弦位置编码在验证集WER大于帧叠加的情况下,测试集WER却相对较小。推测正弦位置编码效果更好,其可以在训练集上迭代更少的轮数来获得更好的识别性能,因为降低验证集WER 通常需要调整更多参数设置,导致训练时间更长。
只有卷积位置编码的WER 低于正弦位置编码,测试集WER达到最低的8.62%,相对降低7.4%。进一步验证了卷积操作在时间和空间维度上的平移稳定性。分析原因是,卷积操作不仅在帧序列位置方向表达了相对位置信息,并且在梅尔滤波器组特征方向上提取到了高维特征信息。在共享卷积核参数下实现这两种功能,既起到减少模型优化参数量的效果,又融合了语声的位置和声学特征信息。
表1中最后一行还将正弦位置编码和卷积编码组合在一起,发现得不到任何提升。这进一步支持了本文上述的推测,即卷积位置编码的相对信息为Transformer层提供了足够的特征,以建立更多的全局语声序列信息。
(2)为了进一步探索卷积位置编码能在多大程度上提高模型的识别效果,通过调整两层卷积核尺寸大小,获得最低的测试集WER。实验过程如下:
首先固定第二层卷积核尺寸为(16, 9),实验结果如表2所示。
表2中第一行括号里数据为第一层卷积核的尺寸。由表2中数据可得,(41, 11)时的WER最低。接着固定第一层卷积核尺寸为(41, 11),实验结果如表3所示。

表3 第二层卷积核不同尺寸下的WERTable 3 The second layer convolution kernel WER under different sizes
由表3可得,在本文实验中,两层卷积核尺寸分别为(41, 11)和(21, 11)的条件下,测试集WER达到最低的8.16%。相比与正弦位置编码的基线模型,基于卷积位置编码的Transformer模型WER降低了12.4%,达到了最佳的识别性能。
3 结论
本文针对Transformer 模型中编码器的输入信息,采用了具有可学习性的卷积位置编码,构建了序列到序列的ASR 系统。输入卷积层捕获相对位置信息,这使后续的Transformer 层能够了解编码器中局部概念之间的长距离关系,进而在解码器中预测准确的目标序列。本文的4 个位置编码方法,在添加3-gram 语言模型基础上输出预测标签,最佳配置将WER 相对降低了12.4%。将本文的系统与更好的解码器优化方法结合,或许能够得到更好的识别效果。另外,不同模型的组合也会带来不错的提升,例如结合具有循环机制的Transformer 层,这将是未来的研究工作。
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
中学生数理化·高一版(2018年6期)2018-07-09
制造技术与机床(2017年7期)2018-01-19
中学生数理化·高二版(2016年9期)2016-05-14
电子器件(2015年5期)2015-12-29
