
一种基于国产嵌入式CPU 核的BP 神经网络SoC 设计
2021-04-24 11:36徐文亮
电子技术应用 2021年4期
徐文亮
(杭州电子科技大学 电子信息学院,浙江 杭州 310018)
0 引言
人工神经网络的实现方法主要分为硬件实现[1]和软件实现[2]两种。神经网络软件实现的方法具有并行度低和实现速度慢的特点,并且不能满足神经网络对实时运算的要求。除此之外,最大的缺点是用软件模拟实现的方法需要庞大体积的计算机作支持,这样就很不适合应用于嵌入式场景。基于硬件实现的神经网络具有运算速度快、并行性高等优点[3],并且在实时运算方面也能满足要求。综合考虑,本文采用硬件实现的方法来设计人工神经网络。
本文设计的目的是找到一种方法——硬件实现的神经网络能够进行动态调节,既可以实现神经网拓扑结构的动态调节,即每层网络和每层神经元的个数动态可调,也可以实现输入权值和阈值的自动更新。本文以BP神经网络为例,使用国产嵌入式CPU CK803S 及其SoC设计平台SmartL-Prime,实现一款BP 神经网络SoC 的设计。
1 SoC 结构设计
本文设计的BP 神经网络SoC 采用平头哥(杭州中天微)提供的基于CK803S 嵌入式CPU 的SmartL-Prime 平台。CK803S 是面向控制领域的32 位高能效嵌入式CPU核[4],采用了精简的3 级流水线结构,具有低成本、低功耗等特点。BP 神经网络SoC 的系统结构图如图1 所示。

图1 BP 神经网络SoC 的系统框图
图1 中ANN IP 即为BP 神经网络加速器,通过系统总线挂载到SmartL-Prime 平台上,系统总线使用了AHB-Lite总线为单主机结构[5]。将CK803S 处理器作为主机,BP神经网络加速器作为从机,在处理器的控制下,通过AHB-Lite 总线实现对BP 神经网络加速器IP 核的访问和数据的交互。设计的IP 经过封装打包完成后完成兼容AHB-Lite 的协议,将其挂载到总线上后,即可通过CK803S 作为主机,实现对神经网络IP 核的访问。
BP 神经网络加速器的AHB-Lite 总线连接方式如图2所示。BP 神经网络加速器为从机,主机CK803S 输出BP神经网络加速器的地址,译码器产生了选通信号使能BP神经网络加速器,其余的地址输出到多路复用器中,用于选通从机的输出,从而通过系统总线读取到BP 神经网络加速器的数据。对BP 神经网络加速器的写操作与读操作类似,地址稳定之后有效,给BP 神经网络加速器发送写使能信号,接收到就绪响应后,往写数据总线上输出数据,即可完成对BP 神经网络加速器的写操作。
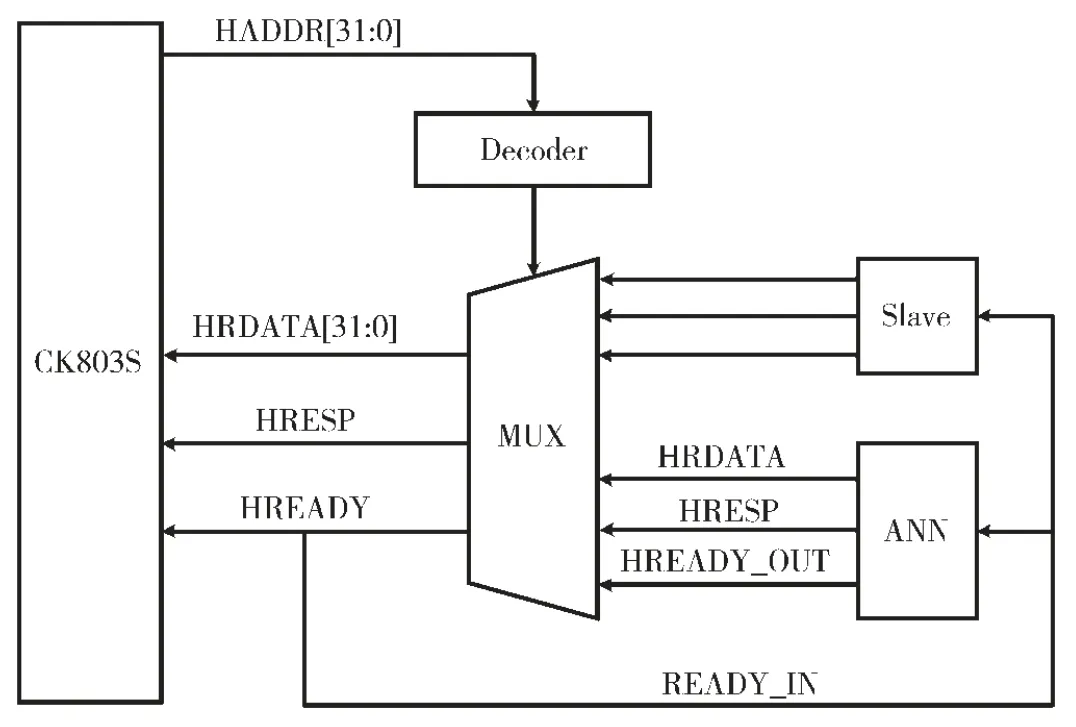
图2 主机和BP 神经网络加速器的AHB-Lite 总线连接
图3 所示为从机的选通信号通过译码器生成框图。AMBA 的交互总线结构和统一编址设计方便了系统的寻址,AHB-Lite 的单主结构也简化了总线的复杂度,减少了复杂的仲裁逻辑。
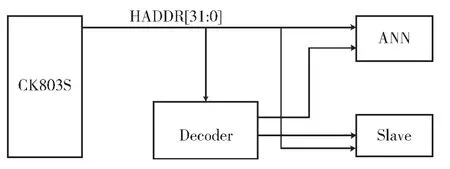
图3 从机选通信号生成图
2 BP 神经网络加速器的设计
2.1 神经元设计
为实现BP 神经网络的硬件设计,首先应该完成神经网络的基本单元,即人工神经元的硬件设计[6-8]。图4是单个神经元的运算过程示意图。
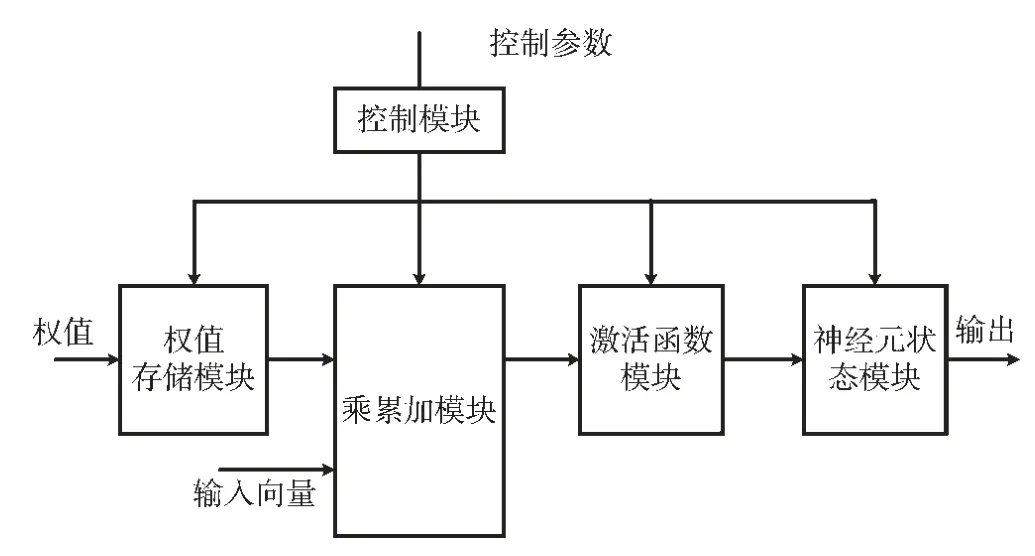
图4 神经元运算过程示意图
控制模块的控制参数通过软件可配置,来控制数据流在模块间的传输,并最后将数据通过神经元状态模块传输出去。首先控制模块控制数据流从权值存储模块开始,权值和输入向量一起被加载到乘累加模块进行乘累加运算,接着将计算结果输入到激活函数模块,经过该模块计算后输出到神经元状态模块。
CPS(Connections-Per-Second)即每秒的连接率,是对神经网络硬件性能评估的一种重要的方法。为了测试训练的速度,往往通过每秒钟联接的更新率来评估。此外学习的速率也与选用的学习算法有关。
针对不同神经网络的设计,激活函数的选择可以是不同的。本设计中,使用的激活函数是Sigmoid 函数和Guass 函数[9-10]。此外学习的速率也与选用的学习算法有关。神经元具体的硬件设计如图5 所示。
2.2 BP 神经网络设计
一个三层的BP 神经网络由输入层、隐含层和输出层组成[11]。如果具有足够的隐含层神经元数,它就能以任意精度逼近任何连续的非线性函数,所以BP 神经网络通常用来进行函数逼近和分类问题[12-13]。神经网络每进行一次完整的训练,BP 神经网络硬件都会进行一次误差反向运算和前向运算,并会修改相应的权值矩阵。隐含层和输出层使用的函数分别是Sigmoid 函数和线性函数。本设计中将BP 神经网络的整个计算过程总结为以下几个功能:激活函数运算Sigmod 模块,误差运算Error 模块,权值修正与更新Updata 模块,输入输出层RAM 存储模块以及功能可复用的神经元乘累加模块。
BP 神经网络的硬件实现整体结构如图6 所示。
从硬件实现框图可以看出,BP 神经网络的层内的执行过程是并行的。整个神经网络的硬件实现过程如下:
(1)开始时把初始权值分别存放于隐含层权值RAM和输出层权值RAM 中以及训练用到的样本集存放在输入层RAM 中,作为训练使用。
(2)根据对输入层RAM 中的输入和对于隐含层权值RAM 中的数值,对隐含层神经元进行计算,送到MAC模块进行累加计算,并将运算完成的结果输出到激活函数模块。
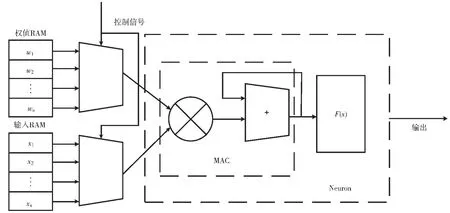
图5 神经元的硬件实现结构

图6 BP 神经网络的硬件实现整体结构图
(3)把激活函数的计算结果存放到隐含层输出RAM 中。
(4)分别读取隐含层输出RAM 中的数据和输出层权值RAM 中的权值数据,输出到MAC 模块进行第二次乘累加运算,最终得到输出层的输出数据。至此,前向运算阶段结束。
(5)误差运算单元Error 用来计算隐含层的输出和输出层的输出数据。至此,误差反向传播阶段完成。
(6)将得到的误差、输入以及隐含层输出送到权值修正和更新单元,得到新的权值,重新存入权值RAM 中[13]。
至此,整个神经网络完成一次完整的训练过程,接着重复训练其他样本,直到满足指定的训练步数或者是误差满足要求为止。这样完成了对整个BP 神经网络硬件的实现。
3 验证和分析
神经网络加速器使用VHDL 实现,通过Synopsys VCS的验证环境,验证神经网络IP 核的功能和逻辑[14-15],并使用了Assertion 方式进行了误差分析。对于SoC 的测试软硬件的协同设计,本文使用基于FPGA 的FMX7AR3B平台,在基于CK803S 的SmartL-Prime 平台进行设计之后,使用FPGA 平台进行配置实现。使用CDK 工具链进行软硬件协同设计和验证[16]。
SoC 设计和验证完成之后,本文使用Vivado 分析工具进行PPA(Perfromance Power Area,即性能、功耗和面积)分析。性能分析结果如图7 所示,是Dhrystone 的基准跑分测试;当波特率设置为115 200Bd,数据位为8 位,无校验位,停止位为1 位的情况下,结果为0.34 DMIPS/MHz,满足设计要求。
图8 所示为在Vivado 下查看的资源使用情况。从图中可以看出Look Up Table 的资源使用率约为18%,BRAM 的资源使用率约为78%,IO 的资源使用率约为87%。

图7 benchmark 跑分结果
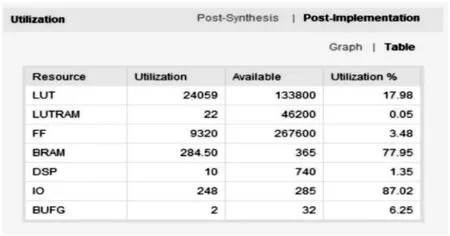
图8 资源使用情况
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
成都信息工程大学学报(2022年3期)2022-07-21
少先队活动(2021年6期)2021-07-22
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
测控技术(2018年6期)2018-11-25
测控技术(2018年8期)2018-11-25
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
电子设计工程(2015年8期)2015-02-27
