
面向边缘计算的电力通信网告警归并技术研究*
2021-04-24 11:36李霁轩吴子辰朱鹏宇吴季桦
电子技术应用 2021年4期
李霁轩 ,吴子辰 ,郭 焘 ,朱鹏宇 ,吴季桦
(1.国网江苏省电力有限公司信息通信分公司,江苏 南京 210000;2.国网电力科学研究院有限公司,江苏 南京 210012;3.北京邮电大学网络与交换国家重点实验室,北京 100876)
0 引言
我国电力行业的高效平稳发展是保证经济安全、快速、稳定发展的能源保障。人工智能时代对电力通信领域提出了新的要求,也为电力通信管理系统(Telecom Management System,TMS)的发展提供了新方向[1]。TMS 作为电力领域信息化产物,为整个电力系统中的电网调度、自动化、继电保护、安全自动控制、电力市场交易以及企业信息化等工作提供了坚实的基础,同时也为电力通信中的异常检测、路由优选等智能化应用提供支撑。
随着特高压电网、各级电网协调的统一发展,智能网的建设的需求也逐渐加强,对支撑电网信息化基础TMS 系统提出了更高要求。在电力通信信息化、智能化建设和应用实践过程中,电力公司积累了海量的实时数据和运行数据,传统基于规则的缺陷处置方法难以满足智能化的需求,尤其缺乏一种对拓扑复杂、设备类型繁多的缺陷数据进行智能分析的方法[2]。
电力通信网在信息化过程中产生了大量的数据,然而这些数据的海量增长,促使了数据归并技术(即告警归并技术)的发展。目前国内外主要使用基于规则匹配的方法进行告警归并[3]。具体而言,就是操作员根据系统实时情况结合专家知识动态地调整告警归并规则。同时,也有基于规则匹配方法上的改进。例如,加入数据预处理和数据过滤等方法辅助告警归并[4]。上述方法在告警数据规模较小、告警延迟低、告警类别固定等情况下,能达到很好的归并效果。但随着告警数据的海量增长,上述方法及其相关改进方法难以适应当前的数据环境。MADZIARZ A 在移动通信网领域提出了基于K-MEANS聚类的告警聚类方法[5],尝试引入无监督聚类以摆脱对规则的依赖。虽然该方法无须大量人力资源的投入,但实际归并效果差强人意,且需要业务专家参与预测缺陷的数量,有着极大的局限性。
5G 技术、边缘计算、人工智能新技术的到来给电力通信领域带来了新鲜血液。新技术与电力通信领域的有机结合,对于构造电力通信新生态,解决遗留问题,节约人力资源,面对新的挑战至关重要。
本文介绍了一种基于密度聚类(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)[6]结合人工规则进行告警归并协助通信缺陷诊断的无监督学习算法。该算法具有良好的鲁棒性、轻量性,支持边缘云部署,将算法在TMS 系统提供的数据中进行实验,结果显示算法达到了较好的效果。
1 电力通信领域相关数据介绍和归并系统方法原理
1.1 电力通信领域相关数据介绍
本文依托国网电力科学研究有限公司建设的国家电网通信管理系统(SG-TMS)进行实验数据采样、模型调试并进行算法验证。SG-TMS 系统在国家电网通信处2019 年通信专业重点工作部署项目中,依据人工规则制定缺陷自动派单规则,实现了传输网监视优化及缺陷自动派单功能[7]。但是该方法依然存在局限性,具体表现在:(1)基于人工规则的方法依赖于专家经验知识积累,只能总结整理常见的影响较大的缺陷;(2)随着工作的推进,积累的规则逐渐丰富时,给运维人员带来了巨大的维护压力,同时也容易产生规则间的冲突,时间一长则难以为继。
SG-TMS 提供海量的电力通信网核心数据,主要涉及SDH、OTN 等设备,覆盖光缆(传输光路)、传输设备、通信电源和机房环境告警[8]。数据由边缘节点进行数据采集和过滤清洗。在系统中,数据主要分为以下两部分:
(1)原始告警数据,告警数据由传输设备直接产生,经北向接口采集后存入系统数据库。但是由于系统中同时存在不同制造商生产的设备,同样的缺陷现象产生的告警存在差异,设备告警名称和实际问题的映射缺乏统一定义。
(2)缺陷单数据,缺陷单数据描述了缺陷的具体位置、实际原因和实时告警的对应关系,由具备相关专家知识的运维人员总结整理而来,是电力通信运维领域知识的结晶,同样也是人工智能算法中天然的标签数据。但是相对于庞大的原始告警数据,缺陷单数据较少,其次,缺陷单和告警由于现场设备的复杂性以及人为检修的干预可能不会直接呈现一对一的映射关系。
综上所述,TMS 系统在一定程度上实现了信息化自动化,但是仍然依赖专家干预。由于原始数据数量巨大,标注数据完备性不足,结合电力通信设备中同种缺陷导致相似的告警模式频繁出现的基本前提,考虑使用无监督学习来协助完成告警归并,采用基于密度的DBSCAN聚类来捕获告警簇。
1.2 归并系统方法原理
DBSCAN 算法作为经典的密度聚类算法,其在无监督密度聚类中的得到了广泛的应用。算法将点分类为核心点和非核心点,定义1~定义6 描述了该算法[9]。
定义1邻域内的点的集合(Eps-neighborhood of a point):NEps(p)表示从p 点出发,邻域内所有点的集合,即:
NEps(p)={q∈D|dist(p,q)≤Eps}其中,D 表明全体点的集合,dist(p,q)表示p 点和q 点之间的欧氏距离,Eps 表示邻域半径。
定义2直接密度可达(Directly density-reachable):点p 被称为从点q 直接密度可达,当且仅当:
p∈NEps(q),|NEps(q)|≥MinPts其中MinPts 为给定的使q 成为核心点的邻域内最小点数。
定义3密度可达(Density-reachable):如果有一系列的点p1,…,pn,p1=q,pn=p,pi+1到pi直接密度可达,那么称点p 从q 密度可达。
定义4密度相连(Density-connected):如果点p 和点q 都从点o 密度可达,则称点p 和点q 密度相连。
定义5簇(Cluster):对于集合D,簇C 是D 的一个满足以下条件的子集:
(1)∀p,q:if p∈C,并且q 从p 密度可达,那么q∈C。
(2)∀p,q∈C:p 和q 密度可达。
定义6噪声(noise):噪声为不属于任意一个簇Ci的离散点,即:
noise={p∈D|∀i:p≠Ci}
具体而言,在划分簇时,对于给定的边界距离Eps和最小核心节点数MinPts,和非空节点集D,簇C 构建时首先检测其密度直达性。首先将核心点中具有密度直达关系的点分类给簇C,之后检测相连性,对剩下的点检测其与簇内任意一点的密度相连性,如果密度相连则归入簇C[10]。
在分类完成后,对于不属于任何簇的孤立点p,将其视为噪声[11]。
2 告警归并系统实现
2.1 数据处理和特征构建
面对海量、复杂、标准不一的原始告警库,需要做一定的数据处理工作[12]。规则部分根据专家知识和运维经验,将告警种类划分为:根告警、伴随告警、未被分类的告警。基于告警之间衍生关系和业务、通道的关系,系统制定了一套归并规则作为基准参考。缺陷单数据存在人工填写部分,不是规格化文本,无法简单地进行文本匹配。因此利用自动化文本分析方法[13],对缺陷单进行信息提取。为了后续的有效性评价,系统对于缺陷单抽取的信息进一步进行分类,以此间接获取告警和缺陷的分布信息。
DBSCAN 是基于密度的算法,意味着输入的特征应当是对应空间的坐标点,或者是点之间的距离矩阵。在实际背景当中告警是连续的文本信息,因此告警的向量化过程应该体现为特征提取和特征向量之间的权重分配。
基于一个缺陷可能会引起一个或多个设备在一段时间内持续输出相似告警的特性,聚类目标是将属于拥有这种特性的属于同一缺陷的告警聚为一个簇[14]。对告警而言,有两方面的信息较为重要:告警本身的相关参数(告警种类、发生位置、设备类型、设备位置等)以及告警时间[15]。其中告警本身的相关参数反映了告警之间的相关程度以及告警在空间上的相近程度,告警时间是当前告警产生的时间,蕴含了缺陷发生的时间信息。对于告警本身的相关参数,使用one-hot 方法[16]将其映射为特征向量,对于没有制定权重的one-hot 来说,告警之间任意一个特征的差距映射在空间上面距离相同,在DBSCAN算法当中作用相同,而通过调整各个特征的权重可以反映不同特征的重要性。对于时间信息而言,显然不能简单运用one-hot 方法,则关键在于统一时间和其他特征在特征向量上的距离关系。告警集合为D,告警具有1个时间特征和m 个其他经过one hot 转换的相关参数特征。则第i 条告警对应特征向量表述为Di=(Ti,Xi,j,…,Xi,m),其中Ti为告警i 的一维时间特征,Xi,j(1≤j≤m)表示告警i 的第j 个相关参数对应的向量。则假设告警本身相关参数的每个特征都被赋予同样的权重,如果要使得任意变化一个特征带来的空间坐标之间的距离变化等价于两个相邻告警a 和b 的时间差超过了时间窗口的距离变化,设变化的特征为第t 个特征,特征维度为n,时间窗口为WINDOWS,则可以得到:
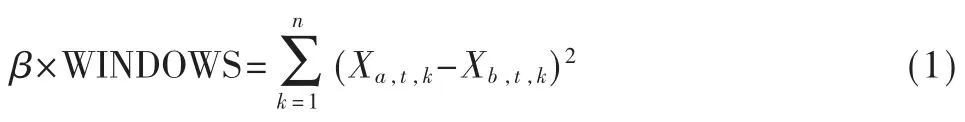
对于单纯的one hot 向量特征,显然β=2/WINDOWS。
进一步,可以得到:
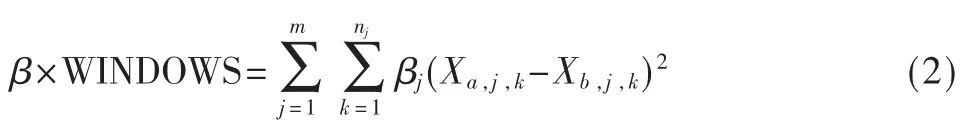
其中nj表示第j 个特征对应的维度,βj表示第j 个特征的权重。可以通过调整β 和βj(1≤j≤m)的值来调整时间和其他参数之间的权重。
不同样本的距离综合考虑了告警本身相关参数距离和时间距离。以此对所有告警进行聚类,则最后得到的聚类结果应该是使得时间上较为聚集的相似告警或者是时间上极为聚集的较相似告警成为同个簇[17]。
2.2 系统架构设计
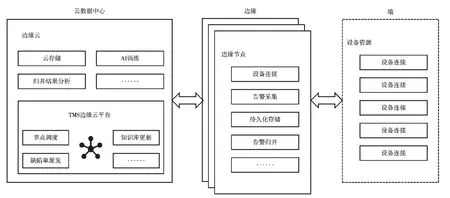
图1 电力通信网自动派单边缘计算系统
如图1 所示,使用基于边缘计算的电力通信告警归并架构构建的计算平台,可以由边缘节点对端设备进行告警采集,在边缘节点进行告警归并,完成边缘计算资源生命周期管理,最后将告警归并结果返回云侧,支持后续缺陷定位定级、可靠性评估、迂回路由优选、缺陷单自动派发等功能,实现知识库的自动化迭代更新,助力建立电力通信行业边缘计算新生态。
图2 介绍了单边缘设备上告警归并方法的基本流程。缺陷单数据经过自动化文本分析和分词得到缺陷单以及对应告警的关系,保留数据以支持后续有效性评估[18]。
原始告警经过数据清洗、数据预处理完成特征分解,进一步对特征进行向量化,细节在2.1 小节中已经讨论。然后对特征向量进行DBSCAN 聚类,对得到的簇进一步使用人工规则进行告警归并[19]。对于输出的告警归并数据使用缺陷单得到的缺陷-告警关系来进行有效性验证,根据效果调节前面聚类部分的参数。
3 系统有效性验证
3.1 算法参数Eps 和MinPts 的确定
对于本系统中应用的聚类算法而言,预先设定参数的选择会最大程度上影响归并表现效果,其中预先需要设定的参数为邻域半径Eps 和密度判断阈值MinPts。算法细节在第1 小节中已经给出,显然,邻域半径Eps 设定过大或密度判断阈值MinPts 设定过小会使得噪声点或者多个不同的类被并入一类,邻域半径Eps 设定过小或密度判断阈值MinPts 过大会使得原先的同一类被划分到多个簇中。
为了确定来自单边缘节点所收集设备的本告警数据集中不同参数对算法结果的影响,表1 列出了不同参数(即邻域半径Eps 和密度判断阈值MinPts)的不同设置对应的仅基于DBSCAN 方法的告警归并效果以及对应的训练时间,评价指标为V-measure 对应的h-score、c-score和v-score,指标含义在3.2 节中进一步阐述。
从表1 的比较中可以发现,在Eps=5 以及MinPts=2时,基于DBSCAN 的告警归并方法可以获得最优,在这种情况下c-score 也同时达到了最优。由于本系统中的规则应用于基于DBSCAN 生成的簇内,并在后续进一步细化簇,因此簇的完整性指标也就是c-score 是应当被首要保证的。在本系统实例中,选用参数为Eps=5和MinPts=2。
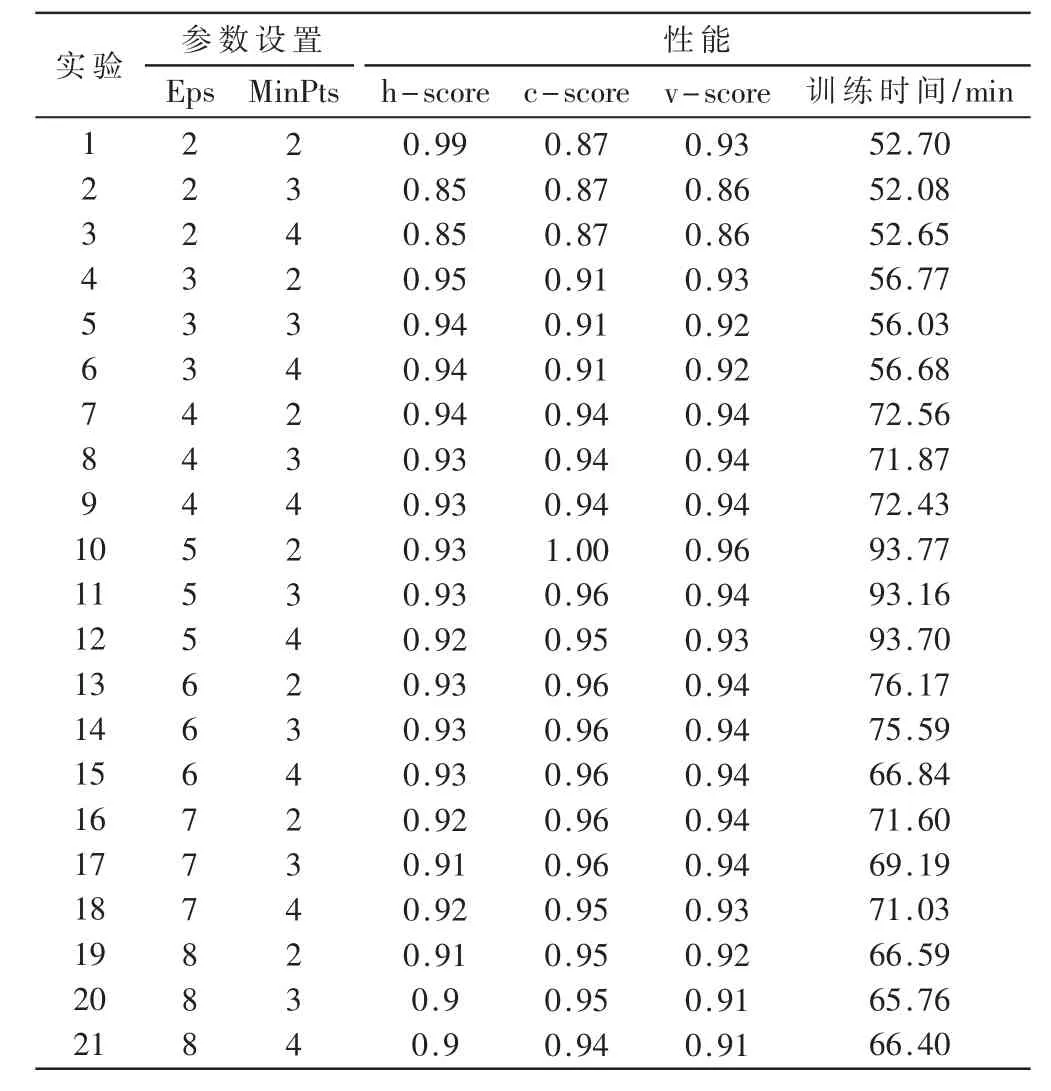
表1 不同参数对基于DBSCAN 的告警归并性能和效率影响
3.2 结果分析
本文利用SG-TMS 已有的缺陷单作为检验聚类效果的标准,因为缺陷单由具有相关专业知识和从业经验的人员进行归并,反映了告警与缺陷的真实关系。
在实际对数据进行处理时,考虑到SG-TMS 库中缺陷单相对有限,对原始告警进行切分,使其与缺陷单的时间范围一致,保证能对DBSCAN 算法的聚类效果进行有效评估。由于原始告警数据的复杂性,需要结合人工规则进行辅助划分。针对不同制造商的设备对于同一种告警现象制定的告警文本信息不一致的情况,通过建立专家知识库[20]实现了不同厂商设备告警的关联映射。
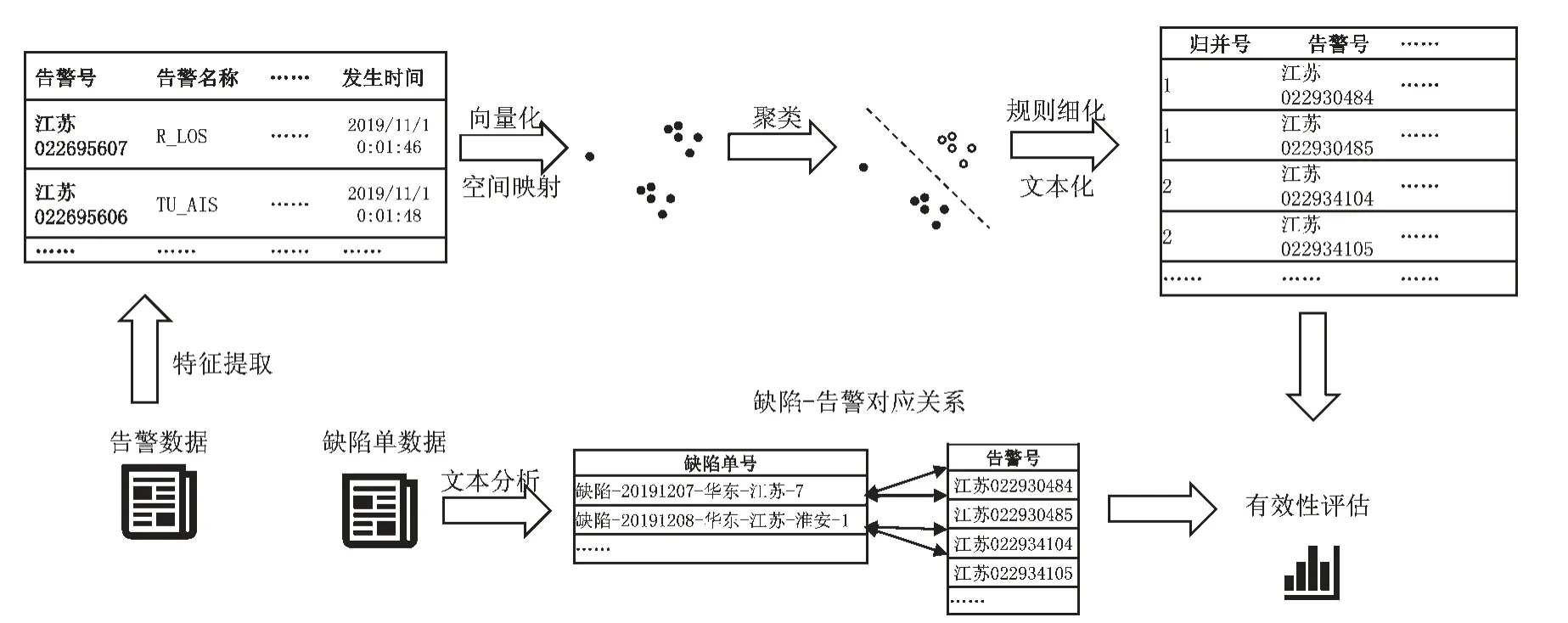
图2 单边缘设备上基于无监督聚类结合规则的告警归并流程
归并结果的有效性验证[21]借鉴了聚类方法的评估指标,聚类方法的评价指标[22]分为外部指标和内部指标,内部评价聚类的估计趋势,体现数据的非均匀分布程度。在电力通信系统中,比起数据的非均匀程度更加关注告警与实际场景的一致性(告警归并结果直接影响后续缺陷处理),因此借助缺陷和告警簇的分布情况通过外部指标来评价归并结果是否准确且完备。
原始告警进行聚类归并之后,选取缺陷单的对应告警与得到的告警归并结果进行比对,要求同一缺陷单对应的告警应当被归并在一起,且不同缺陷单对应的告警不应被归并在一起,选择了V-measure 方法[23]进行有效性评估。

其中,H(C|K)是给定簇划分条件下类别划分的条件熵,H(C)是类别划分熵,H(K|C)是给定类别划分条件下的簇划分的条件熵,即:

式中,N 表示实例总数,nc表示类别c 下的实例数,nk表示簇k 下的实例数,nc,k表示类c 中被划分到簇k 的实例数。
表2 给出了分别基于规则匹配、K-MEANS、DBSCAN以及本系统中DBSCAN 与规则结合的告警归并方法的特性和效果对比。其中K-MEANS 方法需要业务专家的先验知识推测出可能发生的缺陷个数进行预设簇的数目,其他方法不需要进行预设簇;规则匹配方法不具备自学习能力,只能够在规则中学习,而K-MEANS 方法与DBSCAN 方法可以从数据中进行自学习。

表2 不同告警归并方法的特性和效果对比
h-score、c-score 和v-score 分别表明了归并结果的同质性、完整性和同质性与完整性的调和平均值,取值为0 到1,取值为1 时为最理想结果。
显然观察表中结果,可以直观地看出,几种方法在信息熵上的表现都能够有效消除不确定性。其中在同质性表现上,规则匹配和本系统方法表现最佳;在完整性表现上,DBSCAN 方法表现最佳;综合考虑同质性与完整性的表现,本系统方法和DBSCAN 方法表现最佳。性能表现具有可解释性。K-MEANS 方法在缺陷具有突发性的前提中并不适用,因此性能表现都不太理想。规则匹配方法得到的归并结果基于人工经验因此归并的结果同质性较高,但是对于规则以外的模式无法进行捕获因此完整性欠缺。DBSCAN 方法基于数据之间的粘连程度进行聚类,会对所有数据进行归并,因此完整性较好,同质性欠缺。本系统方法结合了DBSCAN 和规则方法,在完整性和同质性上都能获得较好的性能表现。本文的基于聚类结合规则的告警归并方法在消除不确定性上表现更强,具有自学习能力,不需要预先人为预测缺陷数目。
表3 给出了分别基于规则匹配、K-MEANS、DBSCAN以及本系统中DBSCAN 与规则结合的告警归并方法的缺陷一致性对比。
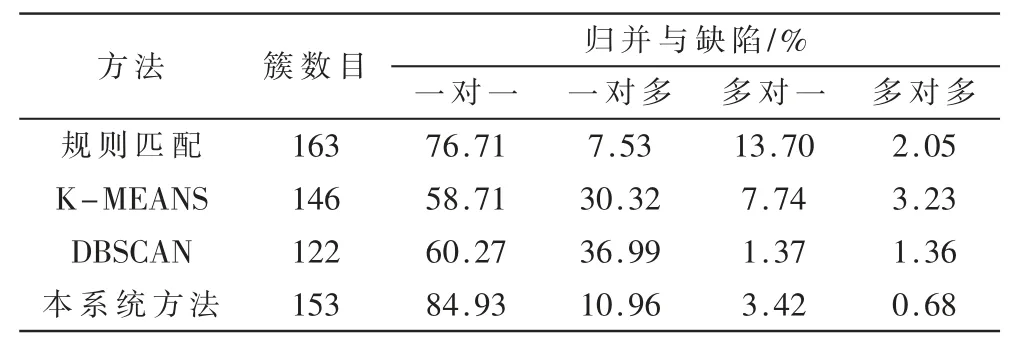
表3 不同告警归并方法的缺陷一致性对比
归并与缺陷一对一:表明归并集合中仅包含一个缺陷且一个缺陷对应的告警被归并到了同一个集合中。归并与缺陷一对一表明告警被正确归并,显然本系统方法显著优于其他方法。
归并与缺陷一对多:表明归并集合中包含多个缺陷但一个缺陷对应的告警被归并到了同一个集合中。归并与缺陷一对多表明部分簇被划分得过大,可以通过细化簇来降低该比例,可见本系统方法通过结合规则匹配比起单纯的DBSCAN 方法降低了更多归并与缺陷一对多比例,提高了归并与缺陷一对一比例。
归并与缺陷多对一:表明归并集合中仅包含一个缺陷但一个缺陷对应的告警被归并到了多个集合中。归并与缺陷多对一表明部分簇被划分得过小,可见本系统方法通过结合DBSCAN 方法比起单纯的规则匹配降低了更多归并与缺陷多对一比例,提高了归并与缺陷一对一比例。
归并与缺陷多对多:表明归并集合中包含多个缺陷且一个缺陷对应的告警被归并到了多个集合中。本系统方法在归并与缺陷多对多上占比最小,表现最优。
系统评估使用了146 个缺陷单数据,其中12 个缺陷单存在重复派单的现象,因此归并与缺陷一对多的比例较高。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在本实例中,每一个簇对应着归并方法得到的被预测为由同一个缺陷导致的告警的集合。则簇的数目对应着归并告警集合数,也就是预测的缺陷数目。在簇的数目上,K-MEANS 算法需要提前预设簇数目才能运行,预设簇数目为146,因此生成簇的数目与缺陷总数保持一致,而其他方法生成簇的数目与实际缺陷数目有偏差。簇的数目与实际缺陷数目的一致性部分显示了归并方法的准确性。由表中结果可知,本系统的基于聚类结合规则的告警归并方法在归并与缺陷一致性表现上更强,不需要预设簇数目且生成簇与实际缺陷数目较为一致。进一步经过数据分析可得,未能正确被归并到一起的5 个缺陷对应的告警时间间隔较大往往在3 小时以上,不符合预设的时间聚集前提,同样也不符合运维的常规情况,推测可能采集装置存在问题或由检修动作引发[24]。结果表明,该方法能被部署在边缘侧节点完成数据收集和告警归并,具有较强的鲁棒性和泛化能力,同时实验效果表明将无监督方法应用到告警归并流程中能够显著提高归并率和告警与缺陷的匹配率,给后续缺陷定位和故障诊断打下了坚实的基础。
4 结论
本文提出了一种面向边缘计算的基于密度的无监督聚类方法结合人工规则应用于电力通信网中的告警归并方法,讨论了告警特征空间构建和时间与相关参数指标的权重矫正方法,并且引进了有效性评价指标表明该方法对时间上聚集和性质相似的告警数据有着较好的效果。后续研究可以通过加入空间拓扑关系特征[25]以及调整特征[26]权重来进一步提高归并效果。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29
数学小灵通(1-2年级)(2021年4期)2021-06-09
铁道通信信号(2019年6期)2019-10-08
通信电源技术(2018年5期)2018-08-23
Coco薇(2017年11期)2018-01-03
雷达学报(2017年6期)2017-03-26
暨南学报(哲学社会科学版)(2016年9期)2017-01-15
通信电源技术(2016年1期)2016-04-16
湖州师范学院学报(2015年4期)2015-03-11
湖州师范学院学报(2015年4期)2015-03-11
