
增强卷积神经网络的人脸篡改检测方法
2021-04-23 04:32:44张韩钰吴志昊
计算机工程与应用 2021年8期
张韩钰,吴志昊,徐 勇,陈 斌
1.哈尔滨工业大学(深圳)计算机科学与技术学院,广东 深圳518000
2.深圳市目标检测与判别重点实验室,广东 深圳518000
3.深圳市云天励飞技术有限公司,广东 深圳518040
当前,随着计算机视觉的发展,图像和视频篡改变得越来越容易,甚至可以达到以假乱真的程度。人脸这种具有身份标志性的特征,如果被篡改,会带来身份被盗用或被“嫁接”的严重问题。近年,经由Deepfake这种深度学习换脸算法产生的假视频在互联网上广泛传播,已经对不少公众人物产生了很大的负面影响。
识别一张人脸是否被篡改是一个典型的二分类问题。2012 年,Fridrich 等人[1]手动提取图像特征并使用SVM[2]方法判断图像是否被篡改。2016年,Rahmouni等人[3]利用CNN 架构并使用全局池化层计算特征的统计信息来判断图像的真假情况。2017年,Zhou等人[4]提出了两阶段神经网络算法,但是存在结构复杂、准确率低等问题。2018年Afchar等人[5]提出了一个基于Inception[6]的MesoInception-4模型,并达到了不错的效果。2019年,Sabir 等人[7]提出使用循环神经网络(Recurrent Neural Network,RNN)来从时序上判断人脸视频是否被篡改。Rössler等人[8]发布了一个人脸视频篡改的数据集,并使用预训练模型Xception[9]训练了一个效果不错的模型。这些方法都在一定程度上解决了换脸视频检测问题,但是基本上都存在准确率较低、训练过程复杂或者对未知篡改方式泛化能力低下等问题。
鉴于此,本文基于一个性能优异的预训练模型resnext101_32x8d_WSL[10]进行人脸篡改检测。为了减轻模型训练时的过拟合并增强模型的鲁棒性,在训练时使用cutout[11]数据增强技术,随机遮盖图片的一部分,使得神经网络不会过分依赖人脸图像的某一个特征来区分图像的真假。此外,本文使用labelsmoothing[12]作为损失函数,并在训练中后期借鉴知识蒸馏[13]的思想对labelsmothing[12]进行修改,这样可以进一步增加模型泛化性能的能力。
1 方法
本文的算法流程如图1所示。训练流程总共分为7个步骤,具体解释如下:
(1)从原始训练集和验证集视频中随机抽取1帧或等间距抽取5帧(见步骤1)。
(2)对每一帧做人脸检测(见步骤2)。
(3)根据人脸检测的边框截取人脸图像(见步骤3)。
(4)对人脸图像做Cutout操作(见步骤4)。
(5)将做完Cutout 操作的人脸图像输入神经网络(见步骤5)。
(6)神经网络输出二分类概率值(见步骤6)。
(7)计算二分类概率值的损失,并进行反向传播(见步骤7)。
测试流程总共分为5个步骤,具体解释如下:
(1)从原始测试集视频中随机抽取1帧或等间距抽取5帧(抽取方式与训练时保持一致)(见步骤1)。
(2)对每一帧做人脸检测(见步骤2)。
(3)根据人脸检测的边框截取人脸图像(见步骤3)。
(4)将人脸图像输入神经网络(见步骤5)。
(5)神经网络输出二分类概率值即为预测结果(见步骤6)。
以下对关键步骤做出详细解释。
1.1 人脸检测与提取
由于换脸算法只替换了人的脸或者对其进行了部分修改,而人的其他部位并没有改动,所以本文的重点关注对象应该是人脸,只对人脸的特征进行分析,以判别出其真伪。调用dlib 库中的一个训练好的人脸检测器[14],使用该检测器检测图像会得到4个坐标值,然后根据这4个坐标值画出截取人脸的边框(见图1中步骤2),然后根据边框裁剪出一张人脸图像(见图1中步骤3)。
1.2 数据增强方法
不同的换脸算法产生的人脸图像有不同的篡改痕迹,甚至未来更加先进的换脸算法产生的图像的篡改痕迹更加隐匿,单纯使用已有的换脸算法产生的有限数据训练出来的模型泛化能力不强,只能识别与原始图像差异很大的篡改痕迹,而那些比较小的痕迹则很难被检测出来。Cutout[11]方法则可以较好地缓解该问题。Cutout[11]覆盖图像的某一个或多个区域,这样会使神经网络寻找其他有差异的特征进行分类,而且每一张图像覆盖的区域是随机产生的,这样训练多次可以使网络尽可能多地识别不同的篡改痕迹。
具体过程为对于一张输入的人脸图像,首先将其缩放到224×224,然后随机将其中1/4 面积的区域像素值设为0,并使每张图像所遮盖的区域是随机选取的(见图1中步骤4)。
1.3 神经网络模型
神经网络[15-16],尤其是深度卷积的神经网络[17]已经在图像处理中获得巨大的成功[18-20]。由于ResNet[21]在ImageNet[22]上的准确率取得大幅度提升,残差网络已成为一个广为使用的分类模型。因此,使用基于ResNext[23]的预训练模型resnext101_32x8d_WSL[10]来提升分类效果。ResNext[23]与Resnet[21]一样使用了残差网络模块,不同之处在于ResNext[23]将ResNet[21]中的通道分组,即将ResNet[21]模块中的256个通道每8个分成一组,总共分为32组,文献[23]中定义该组数为网络的基数(cardinality),作者何恺明等人通过实验证明增加网络的基数(cardinality)比增加网络的深度和宽度更加有效,而且还能降低模型的复杂度。在文献[10]中,作者仍然使用Resnext[23]模型,只是先利用Instagram库的9.4亿张图片做弱监督预训练,然后利用ImageNet[22]做微调,这样训练的效果相比仅仅只在ImageNet[22]上训练的ResNext[23]的效果有显著提升。在Resnext[23]模型家族中,resnext101_32x8d_WSL比resnext101_32x4d_WSL准确率更高,且比resnext101_32x16d_WSL 模型参数少。综合考虑,resnext101_32x8d_WSL是一个性能优异且运行效率较高的模型,所以本文决定使用该预训练模型。将该模型的最后一层全连接层改为2 048×2,以适应本文的二分类任务。

图1 方法主要流程
1.4 损失函数
在图像分类任务中,交叉熵(Cross Entropy)是最常见的损失函数,但是交叉熵使用的one-hot 编码产生的真实标签概率值(0和1)不能保证模型的泛化能力。0-1概率标签促使某一类图像的预测概率尽可能靠近1,其他类的预测概率尽可能靠近0,但是本次任务中,原始图像与换脸的图像只在一些细节处有差异,无限制地增加2类图像的预测概率的差距会使模型容易过拟合。本文所使用的labelsmoothing[12]就是将0-1 标签平滑化,这样更能反映原始图像与换脸图像的真实差距,使得预测的结果不会过于极端,起到提高鲁棒性的作用。
对于样本x,softmax 层的输出对应每个标签的概率为,其真实标签值为q(k|x),此时交叉熵如式(1)所示:

为了减小0-1 标签带来的过拟合,对标签做平滑处理,如式(2)所示:
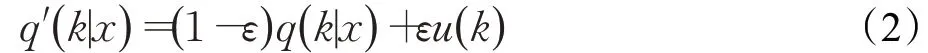
ε是超参数,文献[12]中取值为0.1。u(k)服从均匀分布,按照文献[12]的做法,定义,其中K为类别数。从而,labelsmoothing[12]损失函数为式(3)所示:
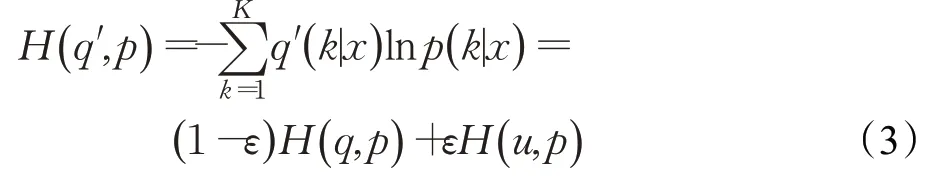
另外,在训练过程的后半部分时间,借鉴知识蒸馏[13]里面的软目标(softtarget)将softmax进行修改,使得在神经网络能够继续拟合而且还能避免过拟合的风险。修改方式如下:
在softmax 公式中增加一个参数T,此时改进的softmax的公式为:
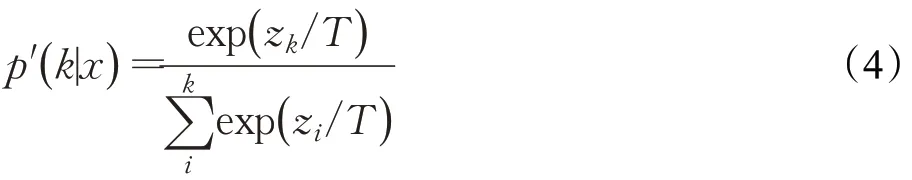
然后改进的labesmoothing为:
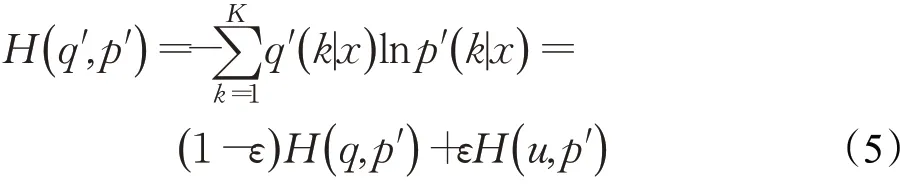
在此公式中,定义T为分类的类别数,即T=2。
2 实验结果及分析
为了验证本文所使用的方法的有效性,本章在FaceForensics++[8]数据集上做测试。该数据集是由Andreas Rossler团队从互联网上收集了1 000个包含人脸的短视频,视频时间长度基本上在10 s 到20 s 之间,然后作者分别使用了4 个不同的换脸算法对原视频进行了篡改,并分别产生1 000个对应的视频,这4种换脸算法分别为Deepfake、Face2Face[24]、FaceSwap、Neural-Textures[25]。此外,作者还对原视频做了两种不同程度的压缩,分别为轻度压缩(c23)和重度压缩(c40),然后对压缩后的视频使用4 种换脸算法对视频进行篡改。由于原视频和经过轻度压缩的视频在作者给出的测试结果上准确率已经超过了98%[8],再继续研究已经没有太大意义,所以使用重度压缩的视频来验证本文方法。
如图2 所示,(a)为各数据集原始图像的示例图,(b)为截取人脸后的示例图,可以看出,确实凭借肉眼比较难分辨这些图像的真假。文献[8]中取视频的所有帧进行训练,但是这样效率很低,所以在本次实验中并不使用所有帧,而是对每个视频分别取1帧和5帧。取1帧的方法是对每个视频随机取1 帧,取5 帧的方法是对每个视频的帧数按照最大间距取5 帧。最后与文献[8]一样,将数据集分成3部分,训练集720个视频,验证集140个视频,测试集140个视频。当每个视频取5帧时,测试集视频的准确率是其对应的5张图像的预测值的平均值。
表1是在4个数据集上单独训练的结果,表中R101指Resnext101_WSL[10],CU指方法cutout[11],LS指损失函数labelsmoothing[12],TLS 指改进的损失函数,见式(5),DF 指Deepfakes,F2F 指Face2Face[24],FS 指FaceSwap,NT 指NeuralTextures[25],文献[5]和[8]中没有做Neural-Textures的实验,用”—”代替。可以看到,即使是在每个视频取1帧或5帧时,使用的模型Resnext101_WSL[10]比文献[8]中使用的XceptionNet性能相差无几或者更加优异,而且从表1 最后2 列来看,本文所使用的数据增强cutout[11]方法和labelsmoothing[12]损失函数的确起到了很好的抑制过拟合、增强泛化能力的作用。最后一列的实验是在训练的后30次迭代中使用本文改进的损失函数(见式(5))替换labelsmoothing,训练的结果比只用labelsmoothing 要好,同时也都超过了对比实验[8]中使用所有帧训练的结果。
此外,将4种不同换脸方式产生的视频与原视频混合在一起做了一个5分类训练,这样训练的结果不仅能看出图像是否被篡改,还能看出使用了哪一种篡改方式。除了数据集混合训练之外,其他的操作方式和训练参数与上面分开训练的一样。结果如表2和表3所示。

表1 各种方法在不同数据集上单独训练的准确率 %

表2 各种方法在不同数据集上混合训练的准确率 %

图2 各数据集示例图

表3 各种方法在不同数据集上混合训练的综合准确率
表2 的结果是不同数据混合训练后在各个数据集的测试集上单独测试的结果。可以看到,当每个视频只取1 帧时,由于数据太少,所以模型基本上没有泛化能力,但是当每个视频等间距取5帧时,使用本文方法在4个数据集上得到的结果已经超过了文献[8]里面使用所有帧训练得到的结果。表3 是将各个换脸数据集的测试集混合在一起之后整体测试的结果。可以看出,当每个视频取5帧时,能够以高达92.22%的准确率识别出使用不同换脸算法产生的视频。
表4 是本文方法与两种对比方法平均测试一个视频所花的时间,表中模型参数的计算使用的神经网络框架为Pytorch-1.0.1,测试时间所使用的硬件为i7-8700(CPU)。本文提出的方法中有测1 帧和测5 帧的情况,Ours一列的数据是指测5帧的情况。可以看到,由于本文方法对每个视频只需取5 帧,从整体来看,本文的方法平均测一个视频所花的时间更少,效率更高。

表4 各种方法的模型参数与检测时间对比
为了更好地复现本文所达到的效果,本段说明本文训练时所使用的参数。使用的优化器为随机梯度下降(Stochastic Gradient Descent,SGD),学习率设置为0.005,批量训练大小为64,训练60 轮并保存验证集上准确率最高的模型。在cutout[15]中,参数n_holes 取为1,参数length取为112。Labelsmoothing[17]使用默认参数。
3 结束语
判断视频中的人脸是否被篡改是一个典型的二分类问题,本文使用了一个性能优异的预训练网络,并结合了一个数据增强方法和一个减少过拟合的损失函数,在数据集FaceForensics++[8]上对4种不同的换脸算法产生的视频的检测都取得了很好的效果。未来将继续探索更加高效的算法。
猜你喜欢
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年19期)2019-11-23 08:42:00
动漫星空(2018年9期)2018-10-26 01:17:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
