
视觉SLAM在室内动态场景中的应用研究
2021-04-23 04:31:50徐少杰曹雏清王永娟
计算机工程与应用 2021年8期
徐少杰,曹雏清,王永娟
1.南京理工大学 机械工程学院,南京210094
2.安徽工程大学 计算机与信息学院,安徽 芜湖241000
视觉SLAM(同时定位与建图)作为移动机器人领域的核心技术已经发展了二十多年,在这期间涌现出了大量优秀的视觉SLAM 方法。这些方法按视觉里程计算法不同可分为两个大类:一类是特征点法,一类是直接法[1]。PTAM[2]、RGBD-SLAM[3]、ORB-SLAM2[4]都是基于特征点的视觉SLAM 系统。PTAM 利用Bundle Adjustment(BA)首先实现了实时的SLAM系统,RGBDSLAM 是基于RGBD 相机的可实时构建稠密三维点云地图的SLAM 系统,文献[4]在单目的基础上增加了对双目和RGBD 相机的支持,是单目、双目和RGBD 相机三种传感器都可运行的SLAM 系统。由于特征点对于光照变化、运动、旋转都不敏感,所以基于特征点法的SLAM系统比较稳定,鲁棒性较好,但是提取特征点、计算描述子和特征匹配比较耗时。DTAM[5]、LSD-SLAM[6]都是基于直接法的视觉SLAM 系统。DTAM 首次利用直接法实现了实时稠密三维重建并提升了SLAM 系统的准确性和鲁棒性,LSD-SLAM利用图像灰度来实现定位和半稠密点云地图构建。基于直接法的SLAM 系统节约了计算特征点和描述子的时间,计算速度较快。直接法假设同一空间点的像素灰度值在各个图像中是固定不变的(灰度不变假设),由于环境中光照变化、相机自动曝光等的影响,这一假设很难实现,因此基于直接法的SLAM系统稳定性较差。
此外,无论是特征点法还是直接法的视觉SLAM系统均将环境视为静态的,但是现实环境中不可避免地会出现动态物体,如室内环境中的人等。为了解决动态场景下的SLAM问题,研究者们已经做了一些尝试。房金立等人[7]提出将光流法与实例分割结合的方式进行检测并剔除动态特征点,以此来提高动态环境下的定位精度。DS-SLAM[8]采用语义分割结合光流法的方法,降低了动态物体对视觉SLAM的影响,构建出语义八叉树地图。Wang 等人[9]通过彩色图像中的光流来检测动态物体。然而光流法的假设太强,实际环境中很难能够满足假设。
为了解决上述问题,本文提出一种用目标检测网络检测潜在动态物体所在的图像区域,在特征提取后剔除分布于这一区域中的特征点,以此来降低动态物体对位姿估计带来的影响,并对关键帧进行语义分割,在构建点云地图时剔除动态地图点,构建出无动态物体影响的三维稠密语义地图。
1 动态环境下的位姿估计
本文选择基于特征点法的ORB-SLAM2 来提供视觉SLAM 方案,框架如图1 所示,分为5 个线程:目标检测线程、跟踪线程、局部地图线程、回环检测线程和语义建图线程。数据处理流程为:RGB-D 相机采集的RGB图和深度图输入跟踪线程进行ORB 特征提取,同时将RGB 图输入目标检测线程检测出动态物体所在区域,跟踪线程根据目标检测结果剔除动态特征点,用剩余的稳定的静态特征点进行相机位姿估计。关键帧传入局部建图线程进行局部BA,剔除冗余关键帧,然后将关键帧传入回环检测线程和语义建图线程,回环检测线程中进行回环检测和全局BA,语义建图线程中用语义分割网络对关键帧进行分割,构建点云地图时结合先验知识剔除动态物体地图点,最后结合位姿信息进行点云拼接构建出全局一致的不含动态物体的语义地图。

图1 本文SLAM系统框架
1.1 动态目标检测
传统目标检测算法基于人工设计的特征,对于多样性变化敏感,鲁棒性差。为了解决以上问题目标检测算法渐渐从传统方法转向基于卷积神经网络的检测方法。YOLOv4[10]中集成了很多优秀的方法,在相同检测精度下检测时间大大减少。现阶段的目标检测器主要由四部分组成:Input、Backbone、Neck、Head。YOLOv4采用CSPDarknet53 作为Backbone,SPP 作为Neck 的附加模块,PANet 作为Neck 的特征融合模块,YOLOv3 作为Head。在MS COCO 数据集中AP 为43.5%,实际应用中可达65 frame/s,可实现实时检测。本文采用YOLOv4 作为目标检测网络,检测环境中的动态物体,室内环境下的动态点主要来自于环境中的行人。为了检测行人,本文用PASCAL VOC数据集训练YOLOv4,该数据集包含20 种物体,从中提取出“person”类别,共提取出4 015 张图像用于训练网络。重训练后的YOLOv4检测结果如图2所示。

图2 动态目标检测结果
1.2 动态特征点剔除
如图2 所示,YOLOv4 的检测结果是一个个的检测框,假设一帧图像上的所有特征点的集合是A={p1,p2,…,pn},单个特征点坐标为pi=(ui,vi),检测框定义为d=(l,t,r,b),其中l为检测框的左边的x坐标值,t为上边的y坐标值,r为右边的x坐标值,b为下边的y坐标值。检测框将图像中的特征点分成两类:在检测框外的静态特征点和检测框内的动态特征点。设静态特征点集合为B,动态特征点集合为C,对每个特征点进行如下判断:如果点p满足{(u,v)|l<u <r,t <v <b}则p∈C,否则p∈B。在对当前帧提取特征点后按上述判断条件判断容器中的特征点是否属于集合C,如果是,则将其删除。动态特征点剔除效果如图3所示。
从图3(a)中可以看出在剔除之前有一些特征点分布在两个人身上,这部分特征点将会影响位姿估计,不利于机器人准确定位,从图3(b)中可以看出,经过剔除处理后的特征点已经全部都分布于静态的物体之上,可以有效降低动态物体对机器人位姿估计的影响。

图3 动态特征点剔除
1.3 位姿计算
通过对动态特征点的剔除,在计算机器人位姿时便可使用集合B中的静态特征点来计算。设图像中满足条件的特征点pi=(ui,vi)的空间点为Pi=(Xi,Yi,Zi),则特征点pi与空间点Pi的对应关系如下:
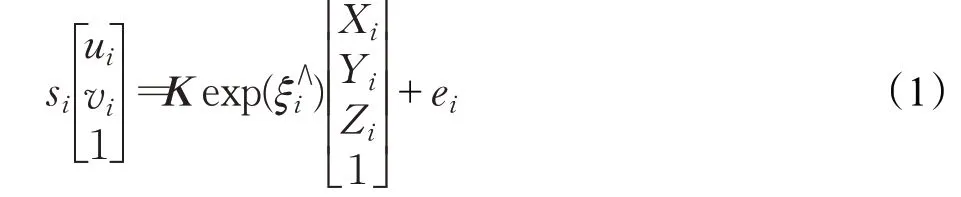
其中,s为尺度因子,K为相机内参矩阵,ξ为位姿的李代数,∧为李代数转换为矩阵的运算符,e为误差。
将式(1)改写为矩阵形式:

将所有误差累加求和,构建最小二乘问题:
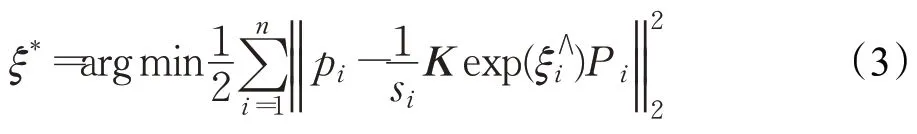
由于p∈B,所以上式中的Pi均为固定值,这样式(3)中的ξ*即为所求的相机位姿。
2 动态环境下的语义建图
2.1 语义分割
上述工作虽然可以获得动态环境下的相机位姿,但是构建语义地图还需要按像素分割的语义分割图像。考虑到SLAM系统的实时性,所用语义分割网络需要在准确率和分割速度达到一个平衡,因此本文采用基于Caffe框架的实时语义分割网络SegNet[11]来对关键帧进行分割。训练神经网络的数据集是NYU-Depth V2,该数据集是一个室内静态数据集,共包含室内场景中常见的13个类别,但是不包含动态的行人类别,因此添加上PASCAL VOC中的行人类别构成新的数据集用来训练SegNet,训练后的网络分割结果如图4所示。图中不同种类用不同的颜色表示,其中行人用白色来表示。
2.2 三维语义点云地图构建
本文利用PCL点云库构建点云地图,将地图点定义为pcl::PointXYZRGBA 类型,地图点定义为q=(x,y,z,r,g,b),其中(x,y,z)表示地图点的空间坐标,(r,g,b)表示地图点的颜色信息。

图4 语义分割结果
设像素点p,对应的相机坐标系下的空间点P,则这两点的对应关系为:

由公式(4)像素点可以投影到相机坐标系下的三维空间中,可将单帧图像转换成相机坐标系下的单片点云,但相机在运动中相机坐标系也在不断变化,因此还需要将相机坐标系下的单片点云拼接到统一的世界坐标系中来构建全局一致的点云地图。
在动态环境下动态物体在不停地运动,所在空间位置在不停地变化,但是所在的每个位置都会被相机记录下来,这样在构建点云地图时会将每个时刻的动态物体都重建出来,造成地图混乱,不利于机器人执行任务,因此需要在构建地图时将动态的点滤除。滤除方法是按RGB 值滤除,如图4 所示,表示动态的人的像素点的颜色RGB值为(255,255,255),因此在构建地图时只要地图点满足(r,g,b)=(255,255,255)就将其滤除,这样构建的地图就可免除动态物体移动带来的影响,构建出全局一致的三维语义点云地图。
3 实验结果
为验证本文方法的有效性,采用TUM 数据集对本文方法进行实验。TUM数据集是通过Kinect深度相机采集的不同室内场景的图像序列,提供了采集图像时的相机位姿真值,可供研究者们评估自己的SLAM系统性能。本文采用该数据集中的三个高度动态的场景数据walking_halfsphere、walking_static、walking_xyz 来进行测试。
3.1 位姿估计实验
实验时采用ATE[12](Absolute Trajectory Error,绝对轨迹误差)作为评价指标,绝对轨迹误差指的是相机的位姿真值与SLAM 系统位姿估计值之间的差值。表1为本文算法和ORB_SLAM2 在三种数据集中的测试结果对比,其中的提升率计算方式为:

其中rmes、mean 和std 分别指的是均方根误差、平均值和标准差。表2 为本文算法与其他同类方法的绝对轨迹误差结果对比。

表1 绝对轨迹误差对比

表2 同类算法结果对比
从表1可以看出,本文算法在对动态目标进行处理之后的位姿估计精度相对于ORB_SLAM2 的位姿估计精度有了很大的提升,平均提升率约为88.3%。表2 显示了本文算法与其他同类算法的结果对比,结果表明本文算法在实验的三个数据集中表现更优。图5(a)是ORB_SLAM2 计算出的walking_xyz 序列中的相机轨迹,图5(b)是本文算法计算出相机轨迹。其中灰色虚线表示相机轨迹的真值,彩色线表示计算值,右边的彩色线条从蓝到红表示误差值从小到大。图6 是本文算法与ORB-SLAM2计算出的轨迹与真值间的误差分布图,图6(a)是ORB-SLAM2的计算误差分布图,图6(b)是本文算法的计算误差分布图。从图6(a)中可以看出ORBSLAM2 的计算误差主要分布在0.5 m 到1.1 m 之间,只有极短时间内的误差能降到0.1 m左右,从图6(b)中可以看出本文算法除了极短的时间段内的误差较大之外绝大部分时间误差都分布在0 m 到0.1 m 之间。从图5和图6 能直观地看出本文算法相对于ORB_SLAM2 算法在动态环境中对相机位姿的计算准确率更高。

图5 轨迹真实值与计算值曲线

图6 绝对轨迹误差分布对比
3.2 语义建图实验
本文选择walking_static 序列作为语义建图的图像序列,在该序列中有两个人在相机前绕着一张办工桌走动,是一个高度动态的序列,若不考虑这两个人的影响,建图效果如图7(a)所示,图中只保留了行人走动密集的区域,这样更加明显地看出动态物体运动对地图构建带来的影响,地图中出现了大量的“残影”,这样机器人在运动到此处时会认为前方有物体阻拦而无法通过。图7(b)则是通过语义分割滤除了行人后构建的语义地图,相比于图7(a),图7(b)不仅消除了运动的人带来的影响,而且赋予了空间点语义信息,这样不仅有利于机器人执行路径规划、导航等任务,而且可以执行诸如“到桌子上取一个杯子过来”这样的高级任务。

图7 处理前后地图对比
4 结束语
为了解决传统视觉SLAM 无法适用于高动态场景以及地图缺少语义信息问题,提出了一种融合目标检测网络、语义分割网络的语义SLAM方法。在位姿跟踪阶段利用YOLOv4 目标检测网络检测出环境中动态物体所在区域,在特征提取时剔除分布在动态物体区域的特征点,保留静态特征点,然后利用静态特征点进行位姿跟踪,减少动态物体带来的负面影响,在地图构建阶段利用SegNet 语义分割网络对关键帧进行语义分割,在构建点云时根据RGB 信息滤除动态物体,从而构建出不含动态物体的语义地图。在TUM数据集上的实验结果表明,本文算法相对于传统视觉SLAM算法在动态环境中明显拥有更好的效果。
猜你喜欢
汽车工程师(2021年12期)2022-01-17 02:29:56
电子制作(2019年10期)2019-06-17 11:45:06
成都信息工程大学学报(2018年4期)2019-01-23 06:57:18
自动化学报(2017年4期)2017-06-15 20:28:55
环球市场(2017年36期)2017-03-09 15:48:21
光学精密工程(2016年5期)2016-11-07 09:05:55
光学精密工程(2016年4期)2016-11-07 09:05:11
湖北工业大学学报(2016年5期)2016-02-27 13:14:48
组合机床与自动化加工技术(2014年12期)2014-03-01 02:22:51
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
