
融合注意力机制的孪生网络目标跟踪算法研究
2021-04-23 04:31:44王家沛孙爽滋
计算机工程与应用 2021年8期
王 玲,王家沛,王 鹏,孙爽滋
长春理工大学 计算机科学技术学院,长春130022
近年来,目标跟踪逐渐成为计算机视觉领域的热点课题,它被广泛地应用在视频监控、自动驾驶、人机交互和医学诊疗等众多领域。目前,目标跟踪面临诸多挑战,比如跟踪目标的尺度变化、跟踪漂移以及背景杂乱等。因此,设计一个准确率和稳健性较高的算法成为目标跟踪研究的重点。
主流的跟踪算法分为相关滤波类算法和深度学习类算法。在相关滤波算法中,KCF(Kernelized Correlation Filter)[1]使用循环矩阵扩大样本容量,提高分类器的准确性。成悦等[2]提出使用加权方法融合多种特征,增强算法的鲁棒性。在深度学习算法中,Bertinetto等[3]提出基于相似度匹配的目标跟踪算法SiamFC(Fully-Convolutional Siamese Networks)。SiamFC 使用离线训练的网络模型,通过比较输入图像和模板图像的相似度大小来得到跟踪结果。以SiamFC为基础,Representation Learning for Correlation Filter(CFNet)[4]将相关滤波器作为一个网络层嵌入到孪生网络中,加强对深度特征的学习。在SiamFC中,模板图像由简单裁剪得到,背景也被当作正样本来和检测图像匹配。这可能会导致:(1)当模板图像中背景与前景外观较为相似的时候,背景可能获得更大的相似度评分从而导致跟踪漂移。(2)在目标运动过程中背景发生多次变化时,算法可能会跟踪到与模板中背景相似的目标上。此外,SiamFC 使用最深层的卷积特征,缺乏对目标底层颜色及纹理信息的学习。
最近,注意力思想被融合到目标跟踪中,用来提高算法的准确率。其中,CSR-DCF(Discriminative Correlation Filter with Channel and Spatial Reliability)[5]使用空间置信图和似然概率判断检测区域中的正样本图像,降低背景系数的权重。LSART(Learning Spatial-Aware Regressions)[6]将空域正则化卷积核加入到神经网络中,使网络聚焦于特定区域。ACFN(Attentional Correlation Filter Network)[7]使用长短期神经网络,选取最优滤波器来适应目标的外观变化。在以上算法中,注意力机制作为单独学习的部分,需要较大的计算量,因而跟踪速度都比较慢。
针对以上问题,本文提出一种融合注意力机制的孪生网络目标跟踪算法。具体贡献如下:(1)在孪生网络的模板分支中融合空间注意力和通道注意力,抑制背景信息,增强卷积网络对正样本的辨别力;(2)使用离线训练并融合注意力机制的VggNet-19(Very Deep Convolutionnal Networks)[8]网络提取目标的深层特征和浅层特征,进行自适应融合,增强算法鲁棒性;(3)注意力机制通过神经网络学习得到,不需要单独训练,并且可以主动适应不同的图像。
1 算法概述
算法的整体框架如图1 所示。搭建两支共享权值的卷积神经网络,组成孪生网络。使用VggNet-19网络提取图像的深层特征和浅层特征。深层特征提取Conv5_1,浅层特征提取Conv1_2。在孪生网络的模板分支,融合通道注意力与空间注意力机制(Channel And Spatial Attention,CASA)。模板分支与搜索分支中的深层与浅层特征分别进行自适应融合,并通过互相关进行相似度匹配。
1.1 用于跟踪的全卷积孪生神经网络
本文使用的全卷积孪生网络由两支共享权重的卷积神经网络组成,使用离线训练的VggNet-19网络提取目标的特征,去掉网络中计算量较大的全连接层,使用相似度函数来计算结果,公式如下:

其中,Z代表模板图像,X代表搜索图像,X的面积大于Z,包括了更多的空间上下文信息。ψ表示卷积函数,*表示互相关,b1 是偏置项,b1 ∈ℝ,ℝ 是实数域。首先对Z和X进行卷积操作,然后通过密集滑动窗口的移动,使ψ(X)和ψ(Z)做互相关,每一次互相关都会得到一个相似度得分,并映射到标量得分图D中,互相关值最大的位置即为目标。训练时,使用logistic 损失函数计算真实值与预测值之间的误差:

其中,s表示模板图像在搜索图像上进行一次互相关操作时得到的相似度得分,y∈{-1,+1} 代表目标的正负样本值标签。对于Z和X在匹配中产生的所有误差,使用下面的损失函数进行计算:
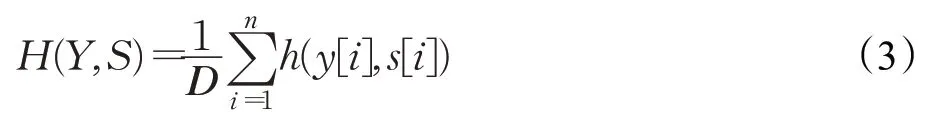
其中,s[i]表示第i个滑动窗口映射在D中的得分,y[i]表示第i个滑动窗口的真实值。最后使用随机梯度下降法SGD(Stochasic Gradient Descent)进行多次迭代,得出卷积神经网络的最优参数θ:
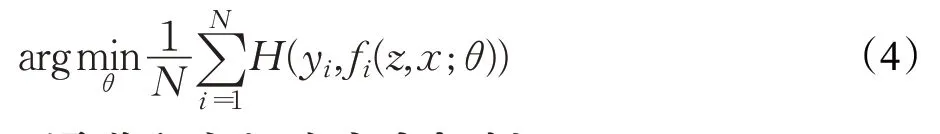
1.2 通道和空间注意力机制
本文算法的注意力机制包括通道注意力和空间注意力。对于通道注意力,先对图像压缩然后激励,由网络学习各通道的重要程度,进而对各个通道的特征进行重新标定,增强模板图像中的前景特征同时抑制背景特征。对于空间注意力,使用两次不同的池化来加强局部特征。算法首先融合通道注意力,然后融合空间注意力。注意力机制的整体流程如图2所示。
设输入图像为Z,经过一次卷积变换后的得到图像为M。Z∈ℝW×H×C,M∈ℝW'×H'×C'。变换过程如公式(5)所示:其中,为二维的空间卷积核,⊗代表卷积操作。mc即为M在单通道下的图像。对于长为W,宽为H,通道数为C的图像M,为获得它全局信息,使用公式(6)进行平均池化。具体来说,就是通过图像的二维空间维数W×H对M进行压缩从而生成一个像素统计点p,p∈ℝC:
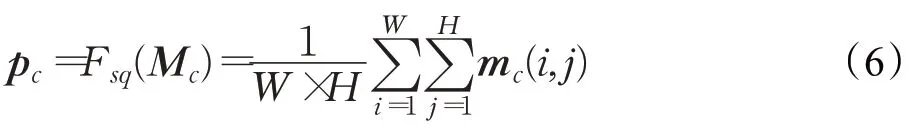

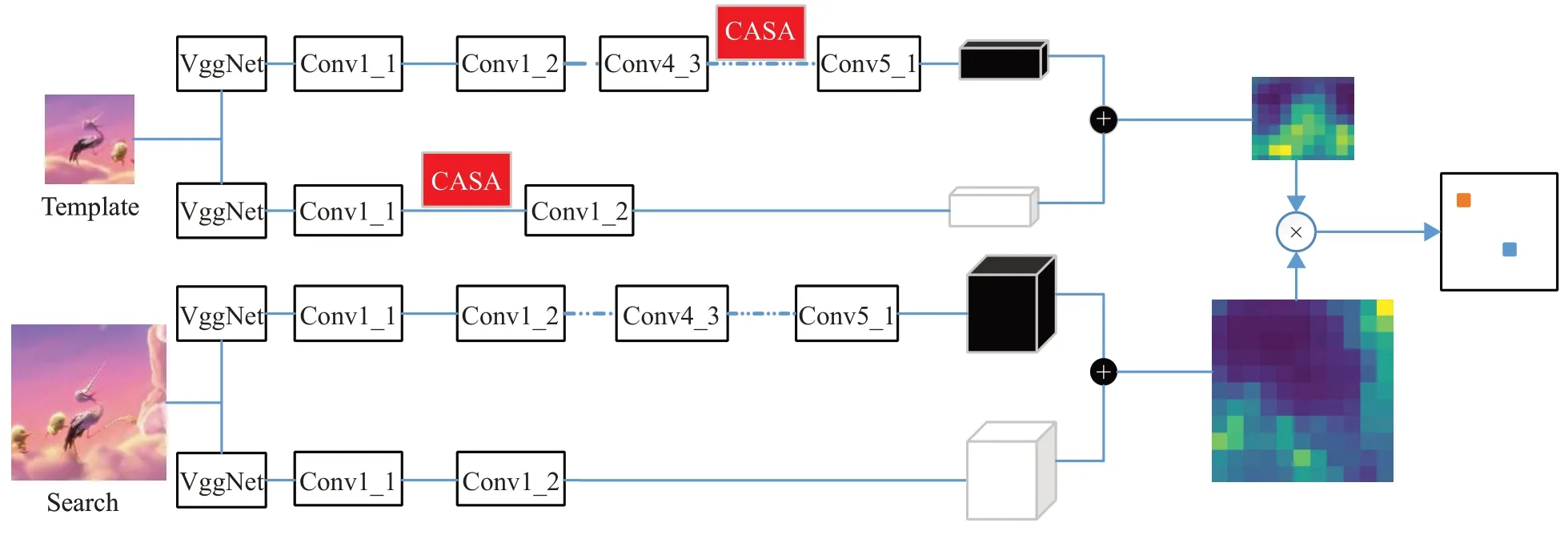
图1 算法框架图
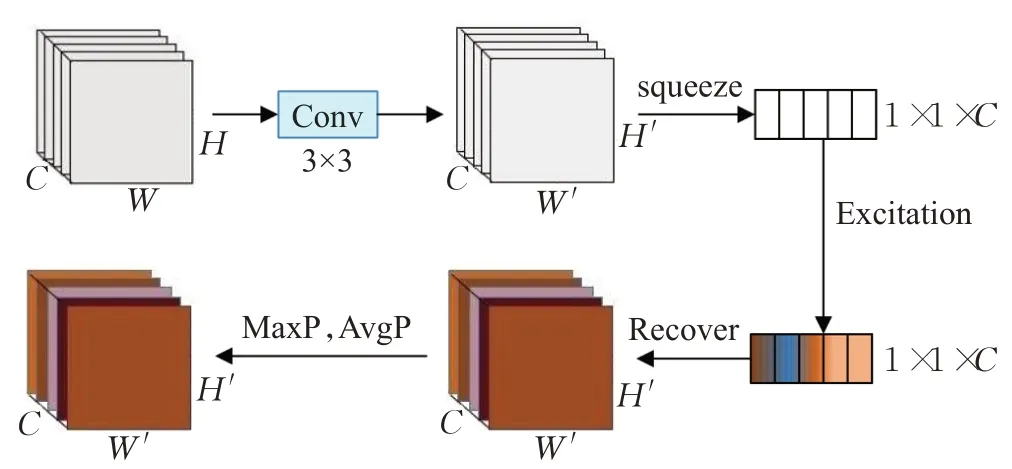
图2 注意力机制流程图
之后,对p进行激励来获取各通道间相关性。激励操作如公式(7)所示:
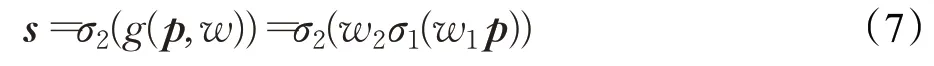
式中,σ1中代表激活函数Relu,σ2代表激活函数Sigmoid,。最后,经过重新标定后输出图像:

其中,Z'=[z1',z2',…,zc']是重新标定特征后的多通道图像。G表示卷积后的图像mc和标量sc的乘积函数,Mc'表示重新标定通道权重后图像的卷积特征图。
空间注意力通过学习空间信息获得模板图像中的正样本区域。在上文得到的图像Z'中,使用一个7×7的卷积核,对图像进行全局平均池化(AvgP)和最大池化(MaxP)以增加局部特征信息。Fs(Z')是最终生成的特征图。如公式(10)所示:

1.3 分层融合
本文使用的深层特征由VggNet-19网络提取,相比AlexNet[9]网络提取的深层特征,层次更深,对目标的语义和属性具有更好的表征能力。但是完全使用深层特征会导致对浅层纹理特征和位置特征的学习不足,无法分辨属性相同但是表观差异较大的目标。为了兼顾算法的准确率与实时性,本文提取深层特征conv5_1和浅层特征conv1_2。
在孪生网络的模板分支,对提取到的分层特征,采用双线性插值的方法扩大高层分辨率较小的特征图,最终使深层和浅层的特征图具有相同的尺寸,实现融合。双线性插值的计算公式如下所示:

其中,pj表示原特征图,pi'表示插值后的特征图,wij为插值系数。
1.4 网络结构和参数
表1展示了孪生神经网络的模板分支中加入CASA机制后的网络结构和各层对应的参数。
2 实验结果及分析
2.1 实验环境和参数
本文算法使用Python 语言在TensorFlow 框架下进行实验。实验环境如表2所示。
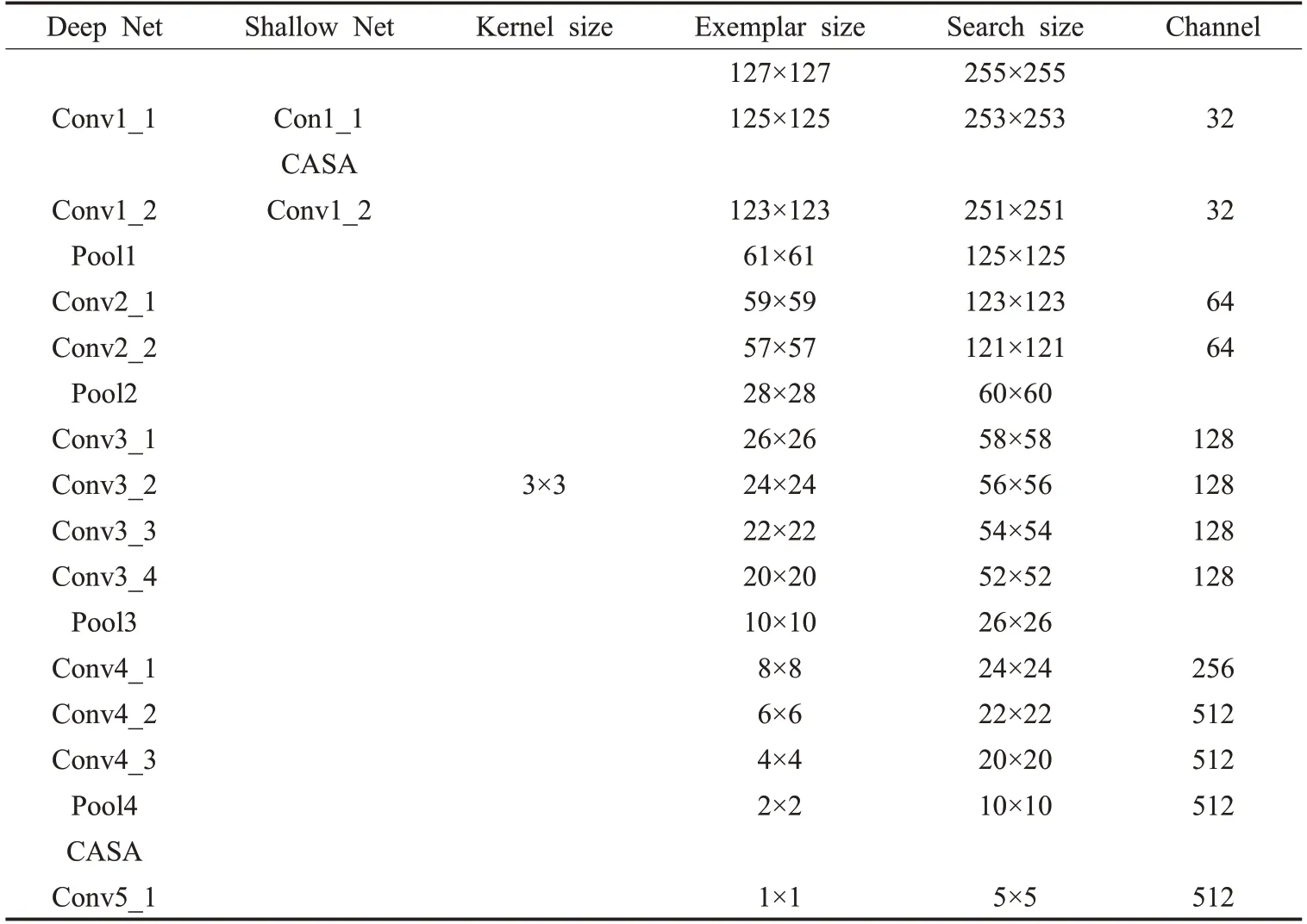
表1 网络结构和各层对应的参数

表2 实验环境
训练时,深度学习的衰减率为10-2~10-5,训练过程分为50个阶段,每个阶段训练5 000对样本,进行8次迭代。为应对目标的尺度变化,匹配时对模板图像进行三个尺度的缩放,缩放的比例为1.025{-1,0,1}。
2.2 训练集和测试集
本文使用ILSVRC 2015-VID[10]数据集作为训练集,它包含了30多种目标和4 000多个视频片段,并且标注的帧数超过100万个。使用OTB2015[11]和VOT2018[12]数据集作为验证集。OTB2015有100个视频序列,VOT2018数据集则包括了具有多种挑战的60个视频序列。
2.3 评价标准
2.3.1 OTB评价标准
OTB 数据集评测工具使用准确率(Precision plot)和成功率(Success plot)对算法进行评估。其中,准确率的评判标准是中心位置误差ρ小于阈值T1的帧数在所有跟踪帧数中所占的比例,如公式(12)所示:
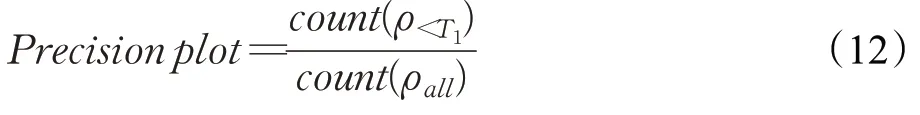
实验中,将T1设定为20 个像素点。中心位置误差ρ的计算方法如下所示:
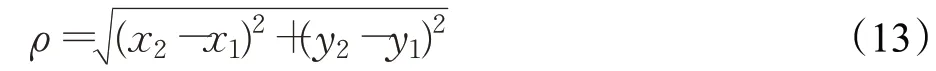
其中,x1、y1表示真实的位置坐标,x2、y2表示预测的位置坐标。
成功率为算法预测的跟踪区域和目标真实区域的交并比IoU(Intersection-over-Union)大于阈值T2的帧数占所有跟踪帧数的比例。计算如公式(14)所示:
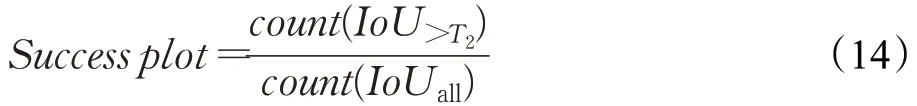
实验中,设置T2为0.5。IoU的计算公式如下所示:
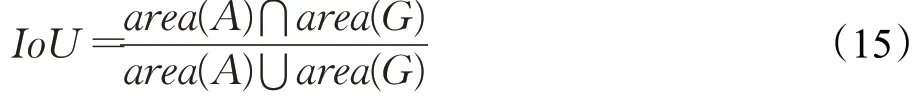
其中,area(A)表示预测的跟踪区域,area(G)表示目标真实区域。
钢渣作为混凝土骨料利用可以提高混凝土强度和耐久性,用钢渣配制C30混凝土,结果表明混凝土的抗压和抗折强度均明显提高[33],也有研究表明标准养护下钢渣对混凝土抗压强度影响小,而高温养护下可提高混凝土抗压强度[34]。对碎石混凝土和全钢渣集料混凝土的抗氯离子渗透性能研究表明全钢渣混凝土具有更好的耐久性,但钢渣粗骨料混凝土的体积稳定性不良是一个显著的劣势。
2.3.2 VOT评价标准
VOT数据集使用Accuracy和EAO(Expected Average Overlap)对跟踪算法进行评测。其中,精确率(Accuracy)是指跟踪器在单个跟踪序列下,跟踪框和目标真实区域的平均交并比。在VOT 评测中,当重叠率为0 时,认为跟踪失败,会对目标进行重新跟踪。EAO 是将跟踪成功的视频拆分出来,计算几个短期序列上重叠曲线值的平均值。
2.4 OTB数据集的实验结果
2.4.1 定量分析
为证明注意力机制和分层特征融合的有效性,本文首先使用OTB2015 数据集进行了3 组对比实验。分别是使用最深层特征的onlyDeep、使用分层特征融合的ML-Deep 和使用融合注意力机制后的最终算法proposed,结果如图3 所示。可以看出ML-Deep 比onlyDeep高了0.048,而proposed比ML-Deep高了0.012,是最优。
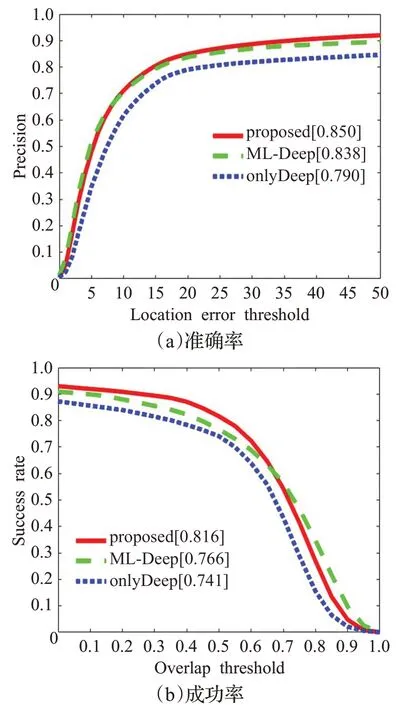
图3 多特征对比结果
此外,本文算法与使用浅层特征的相关滤波算法KCF、BACF(Background-Aware Correlation Filters)[13]和ECO-HC[14]、融合深度特征的相关滤波算法Deep-SRDCF[15]以及使用孪生神经网络的算法SiamFC 和CFNet 在OTB2015 中进行了对比实验。各算法的特性如表3所示。

表3 算法特性
从图4 可以看出,本文算法的准确率达到了0.850,和目前比较好的DeepSRDCF算法的结果基本相同。成功率为0.816,比DeepSRDCF算法提高了0.044。

图4 OTB2015数据集中的实验结果
2.4.2 定性分析

表4 各视频序列的场景属性
(1)尺度变化
序列car4 中,汽车在行驶过程中,尺度逐渐变小。没有针对尺度进行优化的KCF无法适应目标的不同尺度,而包括本文算法在内的其他跟踪模型可以较好地适应汽车的尺度变化。

图5 各跟踪算法在OTB2015数据集上的定性结果
(2)运动模糊与背景杂乱
序列matrix 中,目标与背景颜色相似,且分辨率较低。目标的运动轨迹变化较大且在运动过程中逐渐模糊。KCF算法几乎无法跟踪目标,DeepSRDCF和SiamFC漂移到了目标的局部,只有融合了注意力机制的本文算法能够很好地跟踪到原始目标。
(3)平面旋转
序列motorRolling 中摩托车在运动中出现多次旋转。本文算法融合高层属性特征,能够很好应对目标旋转。在第76帧时,SiamFC、CFNet和本文算法可以跟踪到目标。而145帧时只有本文算法能够跟踪到目标。
(4)光照影响
以序列singer2为例,视频中灯光颜色多变,画面由浅变深。在12 帧时,所有算法都很好地跟踪到了目标。之后,随着目标的移动,大部分的算法开始漂移到与目标相似的背景中。在第268帧时,只有本文算法能够准确地跟踪到物体。
2.5 VOT2018数据集的实验结果
本文算法还在VOT2018数据集中与包括融合注意力思想的算法在内的多种目标跟踪算法进行了对比。实验结果如表5所示。
和SiamFC相比,本文算法的精确率提高了0.022 6,EAO提高了0.064 7。由于使用了层次较深的VggNet-19网络提取目标特征,并融合注意力机制,速度略有下降,但是与表中其他算法相比,本文算法具有较高的综合性能。
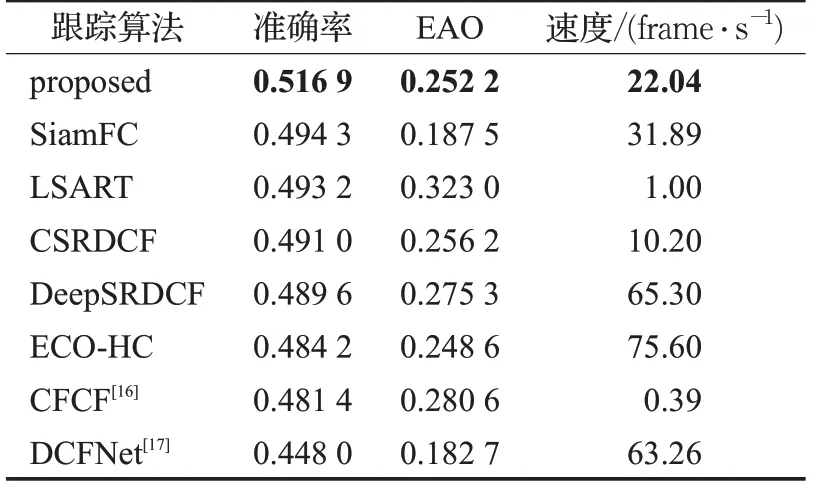
表5 在VOT2018数据集中算法评价指标比较结果
3 结束语
本文提出一种融合注意力机制的目标跟踪算法。在SiamFC 的基础上,使用VggNet-19 网络作为骨干网络提取目标的深层和浅层特征,并进行分层融合,使网络能够同时学习到目标底层的纹理特征和高层的属性特征。在孪生网络的模板分支融入空间注意力和通道注意力机制,提高网络对模板图像中正样本的辨别力。跟踪过程中,为保证跟踪速度和避免跟踪漂移,目标模板不再更新。实验证明,相比SiamFC算法,本文算法具有更高的精确度和更强的鲁棒性。但是,由于模板不更新,算法不能学习目标在运动中产生的形变,对于形变程度较大的目标不能很好地跟踪;同时,算法的实时性也略低于SiamFC算法。未来的研究方向是在孪生网络中设计稳健的模板更新机制,并优化网络结构,提高跟踪速度。
猜你喜欢
建材发展导向(2022年23期)2022-12-22 07:30:02
建材发展导向(2022年12期)2022-08-19 02:33:10
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国房地产业(2016年24期)2016-02-16 06:10:20
中国卫生(2015年9期)2015-11-10 03:11:10
