
交通监控场景中的车辆检测与跟踪算法研究
2021-04-23 04:30:00李震霄刘明明郑丽丽陈劭颖
计算机工程与应用 2021年8期
李震霄,孙 伟,刘明明,郑丽丽,陈劭颖
1.中国矿业大学 信息与控制工程学院,江苏 徐州221116
2.地下空间智能控制教育部工程研究中心,江苏 徐州221116
3.江苏建筑职业技术学院 智能制造学院,江苏 徐州221000
近年来基于视觉的车辆检测和跟踪技术在电子警察、卡口监控、道路监控等设备中得到了广泛应用。但是设备中大多采用传统的图像处理方法实现车辆的检测与跟踪,算法在复杂场景下的监控效果不够理想。随着深度学习算法的迅速发展,其在复杂场景下表现出的优越性,已经逐渐取代传统算法。但是深度学习算法对设备的硬件性能要求较高,如果将其应用在电子警察、智能监控摄像头等边缘设备中,需考虑其性能限制[1-2]。
在多目标跟踪算法中,按照轨迹生成的顺序可分为离线和在线两种情形,通常,基于在线的多目标跟踪更适用于实际情况。根据系统初始化策略的不同多目标跟踪可分为基于检测的跟踪算法和不依赖检测的跟踪算法。基于检测的目标跟踪在跟踪之前,每一帧图像中的目标都已经检测到,其包含一个独立的检测模块,检测器的性能对目标在后续跟踪过程中起到巨大影响。不依赖检测的跟踪往往在初始帧人工选定目标,后续帧中对选定目标进行跟踪,对于非第一帧出现的目标或中间消失的目标无法处理[3]。
考虑本文交通监控场景中对多车辆跟踪存在的实时性和目标多变等问题,选择基于检测的多目标跟踪算法。使用深度学习算法作为检测模块,对车辆获取实时准确的检测,利用检测结果实现多车辆跟踪。
1 相关工作
深度学习检测算法大致分为基于候选框的方法与基于回归的方法两类,前者的发展历程为RCNN[4]、Fast-RCNN[5]、Faster-RCNN[6],需要先提取大量候选框后再分类与回归;后者不同于前者,只需通过一次前向传播就能得到最终的检测结果,代表算法有YOLO[7]、SSD[8]。前者的优点在于准确率高,后者优点则是速度快。毛其超等[9]针对复杂的交通监控场景下车辆漏检和车辆重叠等问题,引入空洞卷积和Soft-NMS 机制改进Faster-RCNN 算法,改进算法提高了检测准确性,但是算法无法在低性能硬件设备上部署。杜金航等[10]针对道路车辆检测算法存在的检测精度低和速度慢等问题,改进YOLOv3 主干网络,提升车辆检测算法速度,利用Kmeans 聚类重新得到锚点框,提升算法精度,改进算法中没有考虑网络不同层间的特征融合,忽略了特征信息融合对检测精度的重要性。柳长源等[11]利用轻量级网络Mobilenetv2 替换YOLOv3 的主干网络,同时融合不同尺度的特征层解决传统检测算法对道路车辆小目标检测效果差、检测速度慢等问题。
在多目标跟踪算法中,许多学者从外观模型、运动模型等方面入手,实现目标之间的准确关联。在外观模型的构建中,如HOG、颜色直方图等传统手工特征发挥着重要作用。但是在复杂场景中,手工设计的特征针对性较强,难以取得满意的效果。同时在拥挤场景中,对于外观相似的目标,仅仅使用外观模型容易造成错误关联,为此Bewley等[12]利用卡尔曼滤波构建运动模型,辅助基于深度特征的外观模型进行数据关联,取得了不错的跟踪效果。李俊彦等[13]使用YOLOv3 目标检测和KCF 跟踪算法结合,实现对多目标车辆的长时跟踪,但是KCF 作为单目标跟踪算法,在多车辆跟踪过程中需要为每一个车辆赋予一个单目标跟踪器,在多车辆跟踪中跟踪速度较低。周苏等[14]使用YOLOv3 算法和卡尔曼滤波跟踪算法结合,利用YOLOv3的中间层特征计算外观特征相似度并且结合马氏距离构造的坐标特征相似度进行多目标关联,实现多车辆跟踪,算法解决了车辆跟踪过程中出现车辆交叉遮挡情况下造成的错误轨迹。Sadeghian 等[15]利用LSTM 网络融合外观模型和运动模型的历史信息,使用数据驱动的方法在跟踪过程中获得目标间的准确关联。
基于上述研究,本文构建基于深度学习的轻量级目标检测算法YOLOv3-Mobilenetv2;利用LSTM 长短时记忆网络进行轨迹预测,使用Deepsort 跟踪算法的匹配策略,提出多车辆跟踪算法L-Deepsort;最后融合YOLOv3-Mobilenetv2和L-Deepsort算法,得到本文基于检测的多目标跟踪算法MYL-Deepsort,算法在保证跟踪精度的前提下,满足嵌入式设备的实时性要求。
2 车辆检测算法介绍
2.1 YOLOv3算法
YOLOv3 在特征提取阶段使用Darknet-53 的基础网络,基础网络中大量使用残差连接,减小模型训练的难度;引入特征金字塔结构,解决物体检测中的多尺度问题;特征图预测前,将浅层特征与深层特征进行特征融合,使浅层特征图也包含丰富的语义信息。YOLOv3输入416×416 的图像,经过基础网络进行特征提取,获得13×13、26×26、52×52 特征图。采用K-means 算法对数据集中的边界框进行聚类,得到9 个锚框,从大到小分为3组,分别分配给13×13、26×26、52×52特征图。将特征图划分为S×S个等大的网格区域,每个网格预测3 个边界框。每个单元格为每个边界框预测4 个值(tx,ty,tw,tz)与存在目标的置信度σo。如果数据集中有k个类别,最终特征图的输出维度为3×(5+k)维。
2.2 YOLOv3-Mobilenetv2检测算法
Mobilenetv2[16]作为轻量级网络结构,使用深度可分离卷积减少模型的参数量与计算量,为了提高特征提取能力,提出了倒残差和线性瓶颈结构,广泛地应用于移动端和嵌入式设备中。本文YOLOv3-Mobilenetv2检测算法使用Mobilenetv2 替换YOLOv3 主干网络,同时为了获取浅层特征信息,引入Bottom-up[17]连接。
2.2.1 深度可分离卷积
深度可分离卷积将标准卷积分解为深度卷积和标准点卷积两个过程,先使用单通道卷积核与输入特征图的每个通道进行卷积,然后使用1×1 的点卷积进行信息融合。具体操作如图1所示。

图1 标准卷积与深度可分离卷积对比
设输入特征图的大小为W×H,采用SAME 填充,以图1方式计算两者的参数量C和运算量F。对比深度可分离卷积和传统卷积的参数量和运算量:
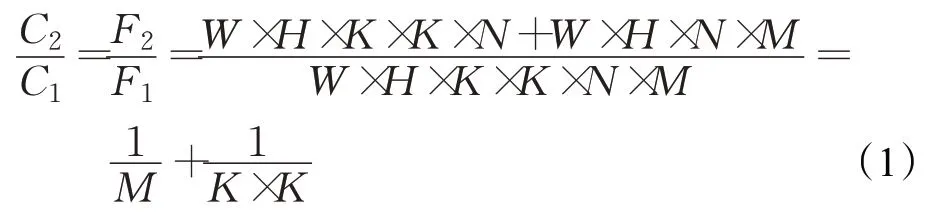
从式(1)可知,深度可分离卷积有效减少运算量与参数量。
2.2.2 倒残差块与线性瓶颈
倒残差块在前向传播的过程中起到了特征重用的效果,同时在反向传播时缓解梯度消失,解决了网络退化的问题。由于深度卷积参数少、计算量低,特征提取的过程中获取的信息较少。如果使用残差块先降维,则深度卷积在特征提取中获取的信息较少,损失增大。为此使用倒残差块,先采用第一个1×1 的卷积升维,使深度可分离卷积在高维度中提取特征,可以提高模型的表达能力,减少信息损失,随后经过第二个1×1卷积降维,使其与输入特征图通道数相同。
倒残差的目的是减少参数数量,但是这种结构在输出时,特征图的通道数很少,由于Relu激活函数在低维空间的非线性映射将会造成部分特征信息变为0,从而导致特征流失。为了保证特征的完整性,使用线性结构替换第二个1×1 卷积后的Relu 层,形成线性瓶颈结构。图2(a)是Mobilenetv2 中步长为1 的特征提取模块,使用倒残差块和瓶颈结构,图2(b)是Mobilenetv2 中步长为2 的特征提取模块,进行下采样操作,使用线性瓶颈结构。

图2 Mobilenetv2模块
Mobilenetv2 网络通过使用深度可分离卷积降低网络的计算量和参数量,替换YOLOv3 算法的主干网络Darknet-53,形成轻量级目标检测算法YOLOv3-Mobilenetv2。YOLOv3-Mobilenetv2 算法与YOLOv3 算法相比在模型尺寸上缩小14 倍,算法沿用YOLOv3 中的特征金字塔结构和多尺度特征融合策略,解决物体检测中的多尺度问题,丰富的特征图的语义信息。但是在网络逐渐加深的过程中,特征图分辨率降低,13×13 特征图中的细节信息逐渐丢失,为此在13×13特征图上引入Bottom-up连接,在52×52特征图中使用步长为4的卷积进行下采样,与13×13 特征图进行像素加融合,增强高层特征图位置信息。YOLOv3-Mobilenetv2的网络结构如图3所示。
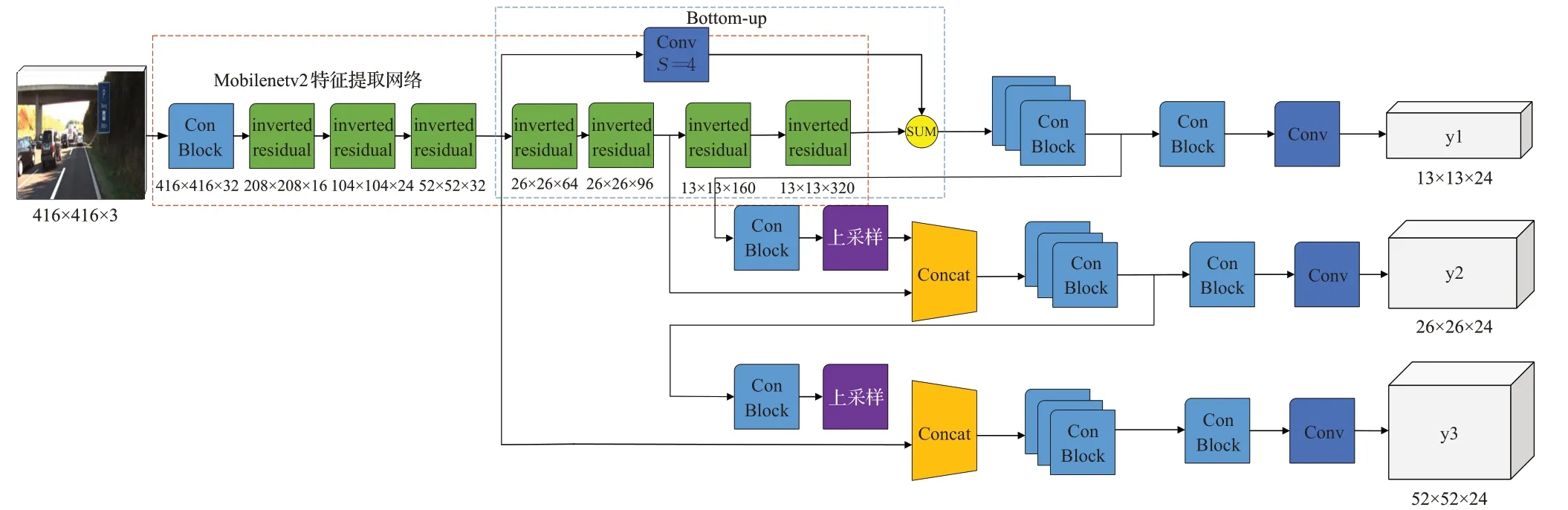
图3 YOLOv3-Mobilenetv2算法网络结构
3 MYL-Deepsort多目标跟踪算法
3.1 Deepsort多目标跟踪算法介绍
Deepsort 算法是基于检测的多目标跟踪算法,在Sort算法的基础上引入深度外观模型,利用重识别数据集训练深度余弦模型[18],在保证实时性的前提下,取得了较高的跟踪准确度。通过卡尔曼滤波构建运动模型,对目标的运动状态进行预测,使用8 个参数(cx,cy,γ,h,c'x,c'y,γ',h')描述目标的位置和运动信息。其中(cx,cy)表示目标检测框的中心坐标,γ是检测框的长宽比,h表示检测框的高度信息。(c'x,c'y,γ',h')则表示前面4 个参数的速度信息。融合外观模型和运动模型使用级联匹配策略进行目标关联,随后使用匈牙利算法进行匹配指派。级联匹配之后,对未匹配的检测、未确认状态的跟踪器和未匹配的跟踪器进行IOU匹配,随后再次使用匈牙利算法进行匹配指派。
3.2 L-Deepsort多目标跟踪算法
Deepsort算法中使用的运动模型为卡尔曼滤波,为一种线性轨迹预测方法,通过输入轨迹的历史位置坐标,利用特定函数进行预测,辅助外观模型进行目标匹配。但是目标在运动过程出现遮挡,检测结果带来的噪声等干扰时,运动状态为非线性,使用卡尔曼滤波在非线性状态下不能进行准确的轨迹预测。针对非线性问题虽然出现扩展卡尔曼滤波、无迹卡尔曼滤波、粒子滤波等基于统计学的传统轨迹预测方法,但是传统的轨迹预测方法需要对运动目标进行建模,在建模的过程中需要先验的假设条件来初始化,先验知识需要通过大量的数学统计和数学推导得到。但是先验知识是有限的,对于在现实复杂的场景下,难以利用数学公式进行建模。同时,基于统计学的轨迹预测在建立模型的过程中也不可避免地会引入误差,此时轨迹的预测精度取决于模型的合理建立。但是基于深度学习的轨迹预测采用完全数据驱动的方法,不需要对数据进行假设,只需要利用大量的数据训练,便可以得到符合真实世界描述的模型。基于深度学习的LSTM 长短时记忆网络由于其具有记忆功能,同时可以解决RNN 存在的梯度消失和梯度爆炸问题,常被用于机器翻译、语音识别、股票预测等各类时间序列预测。为此,本文使用LSTM网络替代卡尔曼滤波进行轨迹预测,基于Deepsort 中的匹配策略,构建L-Deepsort 多目标跟踪算法,提高Deepsort 算法中运动模型预测的准确度。
3.2.1 LSTM算法介绍
LSTM网络增加了记忆单元,在时间序列预测中可以长时间记住之前输入信息。LSTM结构如图4所示。
图4 中的矩形方块称为LSTM 的记忆块,其中包括三个门,分别为忘记门、输入门、输出门,门控状态分别表示为it、ft、ot和一个记忆单元,通过门控结构控制信息在记忆单元的传输。
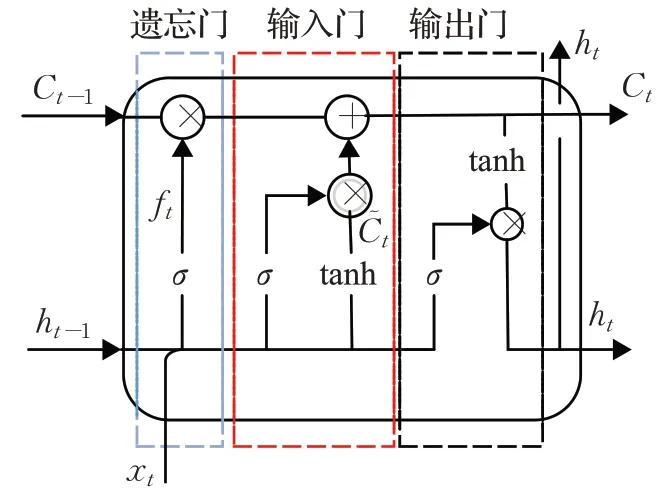
图4 LSTM单元结构

3.2.2 基于LSTM的轨迹预测
由于车辆基本都以直线方式进行运动,在交通场景的多车辆跟踪过程中,如果能够获取车辆在1~t时刻的历史坐标,则可以通过车辆的历史状态来预测未来车辆运动状态。如图5为本文轨迹预测模型的网络结构图。
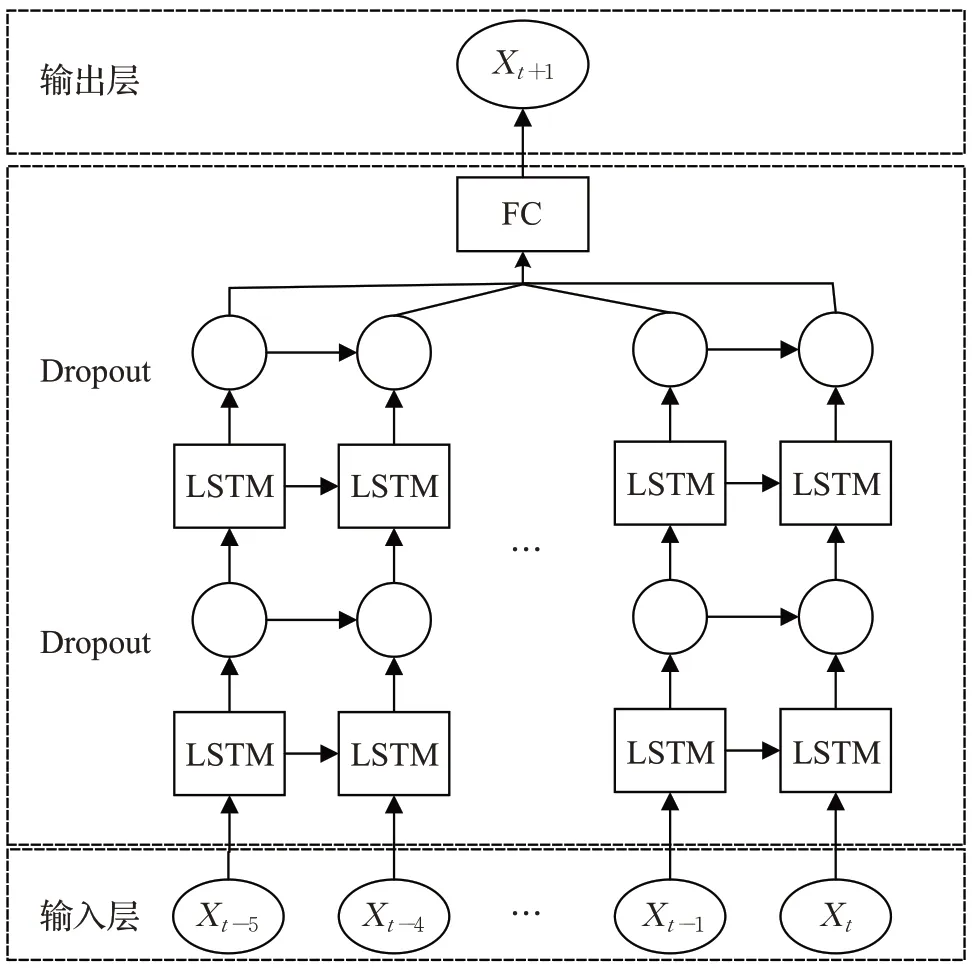
图5 LSTM轨迹预测网络结构
LSTM 神经网络中,沿用Deepsort 算法中卡尔曼滤波的目标框的中心坐标(cx,cy),边框高度h参数,为了减少预测误差,将边框长宽比γ变为边框宽度w。通过对车辆在每一时刻检测到的目标框的中心坐标(cx,cy),边框宽度w,边框高度h,来确定其位置Xt。在输入层将t-5 到t时刻的车辆位置Xt的状态信息(cx,cy,w,h)作为LSTM的输入,预测t+1 时刻的状态信息。两层LSTM网络的超参数设置如表1所示。

表1 LSTM网络参数
3.3 MYL-Deepsort多车辆跟踪算法流程
本文融合上述YOLOv3-Mobilenetv2 检测与LDeepsort 跟踪算法,构建MYL-Deepsort 多车辆跟踪算法。算法流程如图6所示。
(1)首先通过YOLOv3-Mobilenetv2 车辆检测算法对输入的实时视频进行目标检测,得到检测目标的边界框和特征信息,利用非极大值抑制得到目标检测框。
(2)设Age为目标跟踪帧数,当Age>5时,使用3.2.2小节构建的预测模型预测下一帧的状态;对于每一个目标,计算该帧检测结果距上次匹配成功的帧数a,成功匹配时,参数a置0,否则在LSTM预测过程中参数a递增,当参数a大于阈值Amax时,则判断目标丢失,结束对该目标的跟踪。
(3)对检测目标和跟踪预测目标的匹配中,先使用级联匹配对已确认状态的跟踪器进行匹配,并且使用匈牙利算法进行匹配指派在级联匹配中,分别需要进行运动相似度匹配和外观相似度匹配。
运动相似度匹配:使用平方马氏距离计算LSTM轨迹预测状态和新到检测目标之间的相似值,将最小值作为运动相似度,如式(8):

其中,dj为第j个检测框的状态信息,yi为第i条轨迹在当前时刻的预测状态信息,Si则是由LSTM 轨迹预测得到的在当前时刻观测空间的协方差矩阵。
使用二值函数式(9)对式(8)的匹配度进行限制:


图6 MYL-Deepsort算法流程图
外观匹配时:本文基于Deepsort算法中深度余弦外观匹配模型进行外观相似度计算,但是Deepsort算法中使用的外观匹配模型是在行人重识别数据集中训练的,不适用于车辆跟踪。为此使用VERI 车辆重识别数据集[19]进行重新训练,将训练好的模型应用于Deepsort和本文算法L-Deepsort 中进行实验对比。外观匹配时,Deepsort中将每个跟踪目标成功关联的最近100帧特征向量存储到一个集合中,使用余弦距离计算当前检测目标与集合中特征向量的最小值,将最小值作为外观相似度。但是本文车辆和Deepsort中行人的运动方式不同,行驶的车辆大多情况下是直线运动,不像行人通常会出现随意走动,突然改变位置等情况,车辆的外观特征是逐渐变化的,相邻两帧的车辆外观相似度最高。为此本文不再构建车辆外观特征集合,只计算检测结果与跟踪车辆最近时刻的相似度,避免了其他时刻的干扰,这样关联性更强,跟踪效果更好。余弦相似度计算公式如式(10):

其中rj为每个检测框dj计算得到的外观描述符。
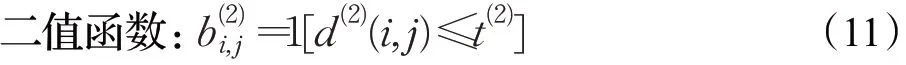
对以上运动相似度和外观相似度两种度量方式线性加权,得到最终的匹配值,如式(12):

(4)随后对未确认状态的跟踪器、未匹配的跟踪器和未匹配的检测,进行IOU 匹配,再次使用匈牙利算法进行匹配指派。
(5)对参数进行更新及后续处理。
4 实验与分析
4.1 实验准备
实验配置:英特尔酷睿I7-8700k 处理器,NVIDIA GTX 1060 6 GB显存,软件环境为Windows10,CUDA8.0,OpenCV2.49和keras深度学习框架。
目标检测数据集:选用当前最全面的自动驾驶场景下的数据集KITTI,其中包含市区、乡村、高速等场景采集的真实图像数据,KITTI 数据集部分示例如图7 所示。本文将KITTI 数据集原来的8 类转换为实验需要的4 类。保留Car 类,将Van、Truck、Tram 这3 类数据样本合并为Truck类,剩余类别删除。在修改后的7 481张带标签图片中,选取6 001张作为训练集,740张作为训练验证集,740张作为测试集。将其分别转化为VOC数据集格式,便于后续算法评测。

图7 KITTI数据集部分示例
多目标跟踪数据集:选用KITTI-Tracking 数据集,KITTI-Tracking 数据集部分示例如图8 所示,数据集中由21条训练序列和29条测试序列组成,序列为2,3,4,5,6,7,8,9,10,11,12,18,20 的数据符合车辆道路行驶场景,选取上述序列作为多目标跟踪测试数据集。

图8 KITTI-Tracking数据集部分示例
轨迹预测数据集:选取上述序列中的标注文件,提取Car类目标制作车辆轨迹数据集。标签文件如图9所示,本文使用3,7,8,9,10列数据,制作为表示LSTM运动状态(cx,cy,w,h)的格式。从每个目标的第一帧起,每次截取长度为7 的数据作为一组训练数据,前6 帧作为输入数据,最后一帧作为训练标签。

图9 KITTI-Tracking标签格式部分示例
4.2 评价指标
目标检测。本文选择均值平均精度mAP,每秒检测帧数FPS,模型大小MB(MByte)作为模型的评价指标。计算mAP 需要先计算精确率Precision 和召回率Recall两个指标,分别表示为:

目标跟踪。以MOT Challenge 评估标准对本文多目标跟踪算法进行评价,评价指标如下,评价指标中(↑)表示数值越高跟踪效果越好,(↓)则相反。
MOTP(↑):多目标跟踪精度;
MOTA(↑):多目标跟踪准确度;
MT(↑):对于大部分被跟踪的目标、轨迹中80%以上的检测被准确跟踪;
ML(↓):对于大部分未被跟踪的目标、轨迹中20%以下的检测被准确跟踪;
IDS(↓):目标发生身份切换次数;
Speed(↑):不考虑检测器影响,跟踪算法每秒跟踪的帧数。
4.3 实验结果与分析
4.3.1 检测算法实验对比
本文选择YOLOv3、Tiny-YOLOv3、Mobilenetv2-ssd三种目标检测算法,均采用预训练权重,在KITTI 数据集上进行拟合并测试。前2 种网络的输入图像尺寸为416×416,Mobilenetv2-ssd 网络输入尺寸为300×300,使用4.2 节评价指标与本文算法进行对比。实验结果如表2 所示,由表知,虽然本文YOLOv3-Mobilenetv2 的mAP 值不及YOLOv3,但是其模型缩小9.16 倍,速度在TX2 平台是其8 倍。与轻量级网络Tiny-YOLOv3、Mobilenetv2-ssd 对比,YOLOv3-Mobilenetv2 的mAP 值最高,模型最小,速度达到16 frame/s,满足实时性要求。
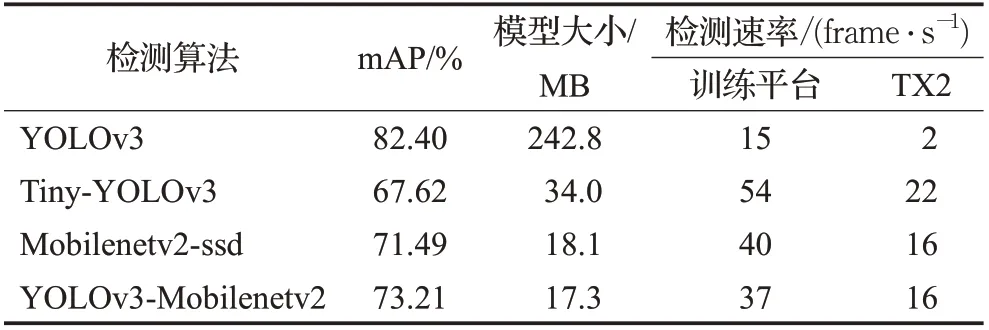
表2 不同目标检测算法实验结果
选取Tiny-YOLOv3和YOLOv3-Mobilenetv2在KITTI数据集不同场景中进行可视化对比,实验效果如图10所示,Tiny-YOLOv3 中出现漏检和误检的情况,而YOLOv3-Mobilenetv2能准确检测出Tiny-YOLOv3中漏检目标。

图10 不同情景的数据集下的检测结果
4.3.2 多目标跟踪算法实验分析
选取KITTI-Tracking中序列为0002的训练数据集,其中编号为1 和5 的车辆,模拟目标正常行驶和遮挡两种情况,对目标状态值(cx,cy,w,h)分别对比,预测结果如图11 所示,蓝色表示真实值,红色为LSTM 轨迹预测值,绿色为卡尔曼滤波预测值。由图11(a)可知,正常行驶情况下,边界框的宽w、高h预测误差相差不明显,LSTM对中心坐标(cx,cy)的预测更加准确。由图11(b)可知,目标在60 帧附近发生遮挡情况时,LSTM 可以及时地做出调整,而卡尔曼滤波在遮挡后的10帧内,出现了较大的预测误差。

图11 轨迹预测结果分析
本文选取Sort 和Deepsort 两种算法和本文算法LDeepsort 进行对比实验。由表3 知,Sort 算法在速度上占据绝对优势,Deepsort 引入深度外观模型后,速度下降明显,但是其他指标均优于Sort算法。本文L-Deepsort算法通过改进Deepsort算法的运动模型,虽然在速度上稍有下降,但是MOTA、MOTP、MT分别提高2.1个百分点、1.5 个百分点、1.2 个百分点,ML 下降0.3 个百分点,同时IDS 减少37 次。为了进一步反映本文算法的跟踪效果,可视化数据集0002序列中编号1的目标,由图12(a)可知,本文算法从8 帧、102 帧到203 帧一直连续跟踪,表现出不错的跟踪效果。
4.3.3 组件消融实验
实验通过控制变量法验证改进部分对算法最终性能的影响,算法的基础框架由Mobilenetv2-YOLOv3 和Deepsort组成,命名为MY-Deepsort,在此基础上分别引入Bottom-up 连接和LSTM 轨迹预测模型,同时为了符合车辆跟踪场景,对MY-Deepsort中的外观匹配策略进行了改进。实验过程中使用Mobilenetv2-YOLOv3 对KITTI-Tracking 数据集中的车辆目标进行检测,得到检测结果。实验结果如表4 所示,引入Bottom-up 连接,MOTA和MOTP都有一定提升,表明检测器的性能对整体的跟踪效果具有一定影响;引入LSTM轨迹预测模型后,与基础网络相比,5个指标均有巨大的改善,表现出优秀的效果,并且IDS 下降明显;同时引入LSTM 和外观匹配策略,5个指标的跟踪性能继续小幅度提升,IDS参数的下降说明本文外观匹配策略使目标间具有较好的关联性;当同时引入上述3 个组件时,跟踪算法表现出最优的效果,不仅MOTA 和MOTP 继续提升,同时IDS也达到最小值。

表3 不同跟踪算法在KITTI-Tracking测试集中的对比

图12 跟踪结果可视化
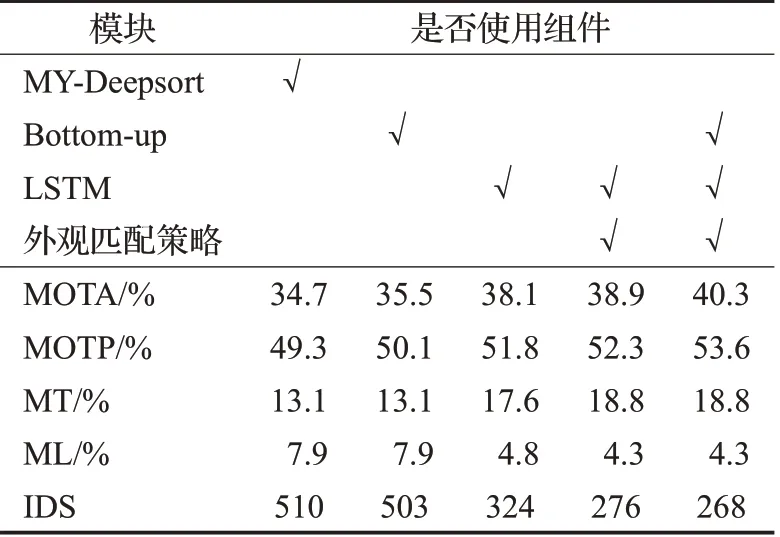
表4 各组件跟踪效果
4.3.4 现实场景跟踪结果分析
为验证算法在现实场景中的实用性,对YOLOv3-Deepsort 和本文MYL-Deepsort 两种算法分别进行性能测试,测试结果如表5,MYL-Deepsort 算法的MOTA,MOTP 指标低于YOLOv3-Deepsort,从而可知基于检测的多目标跟踪算法中,检测器性能对跟踪精度和准确度的重要程度。但是本文算法在其他跟踪指标中均优于YOLOv3-Deepsort,可见本文LSTM轨迹预测模型的有效性。同时,YOLOv3-Deepsort在训练平台达到13 frame/s,但是在TX2 平台无法运行,而本文MYL-Deepsort 算法在训练平台达到34 frame/s,在TX2平台达到13 frame/s。选取现实交通监控视频中的车辆进行检测和跟踪,可视化15、139、207帧的跟踪效果,白色框代表跟踪框,蓝色框代表检测框,如图12(b)所示,MYL-Deepsort 算法对于刚进入视野中的车辆的检测和跟踪效果不太理想,但对大部分进入监控范围内的车辆可以准确地检测和跟踪。通过对车辆的跟踪,可以有效地获取道路信息,辅助交通部门进行交通管制。
5 结语
本文利用Mobilenetv2替换YOLOv3构建轻量级目标检测算法YOLOv3-Mobilenetv2,作为多车辆跟踪的检测模块。通过实验表明,本文检测算法虽然精度有所下降,但是起到了模型压缩的效果,同时极大地提升了运行速度。引用LSTM 神经网络进行轨迹预测,替换Deepsort 算法中的卡尔曼滤波,有效提升跟踪算法性能。最后在现实场景下测试本文MYL-Deepsort 算法,实验表明,算法在保证实时性的情况下,表现出不错的跟踪效果。但是基于检测的多目标跟踪算法对检测器的性能要求较高,对检测器的优化是今后的研究重点。

表5 算法跟踪评价结果对比
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
家庭影院技术(2021年10期)2021-11-20 06:08:52
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
读友·少年文学(清雅版)(2020年4期)2020-08-24 07:36:26
读友·少年文学(清雅版)(2020年3期)2020-07-24 08:57:04
电子制作(2019年11期)2019-07-04 00:34:38
现代装饰(2018年5期)2018-05-26 09:09:39
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
紫禁城(2017年6期)2017-08-07 09:22:52
