
采用深度学习方法的非正面表情识别综述
2021-04-23 04:29:12张秋闻张焕龙
计算机工程与应用 2021年8期
蒋 斌,钟 瑞,张秋闻,张焕龙
1.郑州轻工业大学 计算机与通信工程学院,郑州450001
2.郑州轻工业大学 电气信息工程学院,郑州450002
人的面部表情蕴含着丰富的情感信息,在人们沟通交流的过程中起到了积极和重要的作用。1971年,心理学家Ekman 与Friesen[1]研究提出了人类的六种基本情感的概念,即:生气(anger)、高兴(happy)、悲伤(sad)、惊奇(surprise)、厌恶(disgust)和恐惧(fear)。基本情感有效地归纳了面部表情的种类,有利于一般表情类别的确定。1978年,二人又在前期研究的基础上,创建了人脸运动编码系统(Facial Action Coding System,FACS)[2],该系统根据面部肌肉的类型和运动特征,定义了运动单元(Action Unit,AU),使得人脸面部存在的各种表情和动作,最终能分解为不同的AU 或AU 组合。进一步明确了对复杂表情类别的描述,为后续表情分析与识别的深入研究,奠定了坚实的基础。
伴随着人工智能领域的进一步发展,人脸表情识别作为该领域的一项重要研究内容,吸引了研究者们的广泛关注。目前,大多数人脸表情识别对象集中在正面或接近正面的人脸表情图像上。但是在现实环境中,获取正面人脸表情图像或视频的情况并不是一种常态。多数情况下,识别对象的头部一直处于运动状态。设备拍摄到的人脸图像多处于非正面角度,甚至包括上下、前后等更复杂的运动形式。当偏转角度大于45°时,还会造成人脸被大面积遮挡情况的发生。针对现实环境中人脸表情识别面临的问题,更符合实际需求的非正面人脸表情识别技术逐渐发展起来。非正面人脸表情识别就是针对在自然状态下、人脸偏转时,如何识别面部表情类别的问题而展开的。与正面人脸表情识别相比,非正面表情识别不但需要检测非正面的人脸图像,而且需要考虑头部姿态估计的问题。非正面表情识别的一般流程如图1所示。
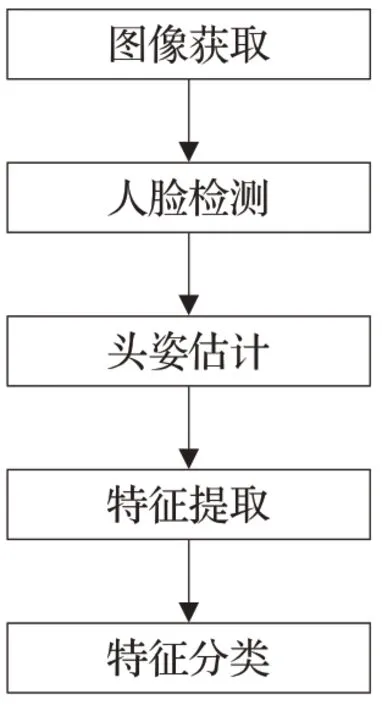
图1 非正面表情识别流程图
然而目前对非正面表情识别问题进行分析的综述论文较少[3],而且经常用于表情识别的经典机器学习算法多属于浅层学习模型,即只采用单层结构将人脸图像转换到表情特征空间中。由于浅层模型的单一性限制了该类算法对复杂分类问题的表达能力,所以在非正面表情识别上,经典的机器学习方法往往不能达到令人满意的结果。
与浅层模型相比,深度学习方法可以通过学习深层非线性网络结构,模拟更加复杂的函数。因而在分类识别问题上有着显著的优势。此外,深度学习方法还用监督或半监督式的特征学习和特征提取算法来替代手工方法,获取人脸图像特征,进而很好地避免了人为获取人脸图像特征所带来的误差。研究者们发现,深度学习的这些优点在解决非正面表情识别问题上,具有其他机器学习方法无法替代的优势。所以近几年,表情识别的研究热点已逐渐转向了深度学习。
如图2所示,基于深度学习的表情识别系统主要包含三个步骤:首先,针对输入样本(图像或视频)进行预处理;其次,将处理好的图像输送到深度学习模型中进行特征提取;最后,将提取到的表情特征对分类器进行训练,进行依靠训练后的分类器正确地预测样本的表情类别。然而,在深度学习方法中,特征提取和分类的过程均可由深度学习模型自行完成。所以上述过程又可分为两步,即非正面表情样本预处理,以及基于深度信息的非正面表情分类。
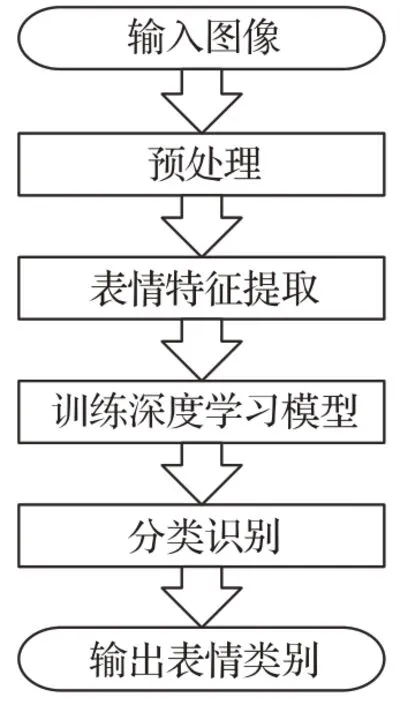
图2 基于深度学习的表情识别流程图
1 针对表情识别的人脸数据库
由于非正面表情样本的特点,使得预处理方式包括:人脸检测与验证、头部姿态估计、光照与尺度归一化处理等。研究者可根据需要,针对不同的输入样本进行选择。与实时采集的数据相比,由专业机构制作的人脸表情数据库由于具有背景简单、噪声干扰小等优点,更受到多数研究者的青睐。目前,国内外的常用的标准数据库可根据头部姿态的不同,分为正面表情数据库和非正面表情数据库,本文将国内外常用数据库按照静态表情数据库(如表1所示)与动态表情数据库(如表2所示)进行分类汇总。
1.1 正面表情数据库
在正面表情数据库中,日本ATR人类信息处理研究实验室和日本九州大学心理学系建立的日本女性人脸表情数据库(Japan Female Facial Expression,JAFFE)[4],是最常用的一个静态图像数据库。该库包括10名日本女性共213 幅静态图像,每人有6 种基本表情和中性表情,每种表情有2~4幅图像。
而在动态图像数据库方面,美国卡内基梅隆大学发布于2010 年的CK+数据库[5]则是其中的佼佼者。该库在实验室环境下记录了年龄在18至50岁之间的210名成年人的正面表情,具体包括123 个对象的593 个图像序列。经过筛选,其中的327 个图像序列满足8 类表情的分类标准,即生气(anger)、轻视(contempt)、厌恶(disgust)、恐惧(fear)、高兴(happy)、中性(neutral)、悲伤(sadness)和惊奇(surprise)。

表1 常用静态数据库
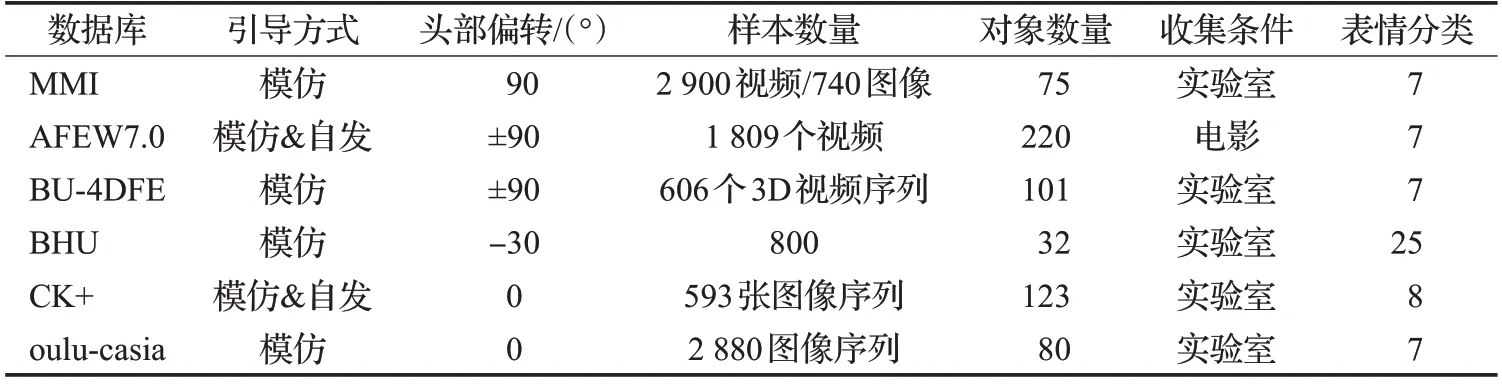
表2 常用动态视频数据库
就视频数据库而言,奥卢大学和中国科学院模式识别实验室于2010 年发布的Oulu-CASIA 数据库[6]从80名受试者中收集了2 880 个视频,每个视频在采集过程中都经历了3种不同程度的照明条件。在视频中,每位受试者被要求展示6种基本的情感表达,即生气、厌恶、恐惧、高兴、悲伤和惊奇。
1.2 非正面表情数据库
在非正面表情数据库中,荷兰代尔夫特理工大学的MMI(Man Machine Interaction)数据库[7],是一个参与者众多、在线、开源的网络数据库。目前已经采集了超过50个人的视频和图像,表情类别包含了FACS的各种动作单元。
Binghamton 大学的BU-3DFE 数据库[8]将数据格式从二维图像扩展到三维模型。该库包括了具有2 500个面部表情模型的对象。100名被采集者中,女性占56个,男性44 个,每个样本执行了7 个表情,分别是中性、高兴、厌恶、恐惧、生气、惊奇和悲伤。2008年,为了分析从静态三维空间到动态三维空间的面部行为,Binghamton大学又将该库扩展到四维(BU-4DFE[9]),即三维+时间维。该库包含了亚裔、非裔、拉丁裔等多个人种,总计约60 600个框架模型。
2008 年,Bogazici 大学发布的Bosphorus 数据库[10]是依靠基于结构光的三维系统采集而来。该库由81个不同姿势、表情和遮挡条件的被采集样本组成。每个扫描样本已手动标记了24 个面部关键点,便于研究者实现对关键点的检测及跟踪。
2010 年,卡内基梅隆大学创建了Multi-PIE[11]数据库。为了系统地捕捉具有不同姿势和照明的图像,在拍摄面部表情的过程中,337 个志愿者从15 个视角、19 种照明条件下,拍摄了超过750 000 张照片。具体表情包含厌恶(disgust)、中性(neutral)、尖叫(soream)、微笑(smile)、斜视(squint)以及惊奇(surprise)。
2010年,奈梅亨拉德布德大学(Radboud University Nijmegen)建立的RaFD(Radboud Faces Database)数据库[12]包含了67位表演者,同样包括了不同的年龄、性别、肤色等。该数据库共包含8种基本表情:高兴、悲伤、厌恶、惊奇、恐惧、生气、轻蔑以及中立表情。每种表情有5 种不同的姿态,3 种不同的眼神方向,共有8 400 张人物图像。
Acted Facial Expressions in the Wild(AFEW)[13]数据库,包含从不同电影收集的视频剪辑,其中具有自发的表情、不同头部姿势、遮挡和照明的多种表情。样本标有6 种基本表情标签加中性表情。此数据集在不断更新中,2017年EmotiW最新的AFEW 7.0包含1 809个视频。
2013 年,在ICML2013 挑战赛中引入FER2013[14]数据库,由Google图像搜索API自动收集的大规模且无约束的网络数据集,包含28 709张训练图像、3 589张验证图像和3 589张测试图像。
2015年,由堪培拉大学视觉与传感组截取的电影画面构成SFEW2.0[15]数据库,该数据库图像均处于自然场景下,而非理想实验室环境,包含7种表情(生气、厌恶、恐惧、高兴、中性、悲伤、惊奇),总共有1 766张样本图像。
2016 年,俄亥俄州立大学发布了一个大型数据库EmotioNet[16],具有从Internet收集的一百万个面部表情图像。其中的自动行动单元(AU)检测模型对总共950 000张图像进行了注释,而其余的25 000 张图像则由11 个AU进行了人工注释。
2017 年,丹佛大学发布了包含超过一百万张来自Internet 的图像数据库AffectNet[17],这些图像是通过使用与情感相关的标签查询不同的搜索引擎而获得的。它是迄今为止最大的数据库,它以两种不同的情感模型(分类模型和维度模型)提供面部表情,其中450 000 张图像具有手动注释的用于8种基本表情的标签。
2018年,由伦敦帝国理工学院和伦敦米德尔塞克斯大学发布的4D Facial Behaviour Analysis for Security(4DFAB)Database[18]数据库,具有超过1 800 000 张高分辨率3D面孔,记录了在5年期间的4个不同会议中捕获的180个主题。它包含对象的4D动态视频,显示6个基本表情的自发性和姿势性面部表情。
相比之下,国内的数据库较少,随着深度学习方法在图像处理领域的广泛应用,研究人员对图像数据库的需求与日俱增,建立大规模的图像数据库是当前急需解决的问题。
2004 年,清华大学建立的人脸表情视频数据库[19],包括了70个人的1 000段脸部表情视频,涵盖了常见的8类情感类表情和中文语音发音的说话类表情。
2007 年,北京航空航天大学建立的BHU(Beihang University)人脸表情数据库[20]是一个较为全面的人脸表情数据库,包含3类人脸表情:单一表情、混合表情和复杂表情。
2008 年,中国科学院发布的CAS-PEAL(Chinese Academy of Sciences-Pose Expression Accessory and Lighting)人脸数据库[21]包含了1 040 个人的6 种面部表情和动作,包括中性、闭眼、皱眉、微笑、惊奇和张嘴。
2017年,北京邮电大学建立了Real-world Affective Face Database(RAF-DB)[22-23]数据库,其中包含从Internet下载的29 672 个高度多样化的面部图像。通过手动众包注释和可靠的估计,为样本提供了7个基本和11个复合情感标签。具体而言,将来自基本情感集的15 339张图像分为两组(12 271个训练样本和3 068个测试样本)进行评估。
2018年,香港中文大学建立的The Expression in-the-Wild Database(ExpW[24]),包含使用Google 图像搜索下载的91 793 张脸孔。每个面部图像都被手动注释为7个基本表情类别之一。
2 针对表情识别的深度学习方法
深度学习是一种模拟人脑活动的网络结构。该类方法可以将原始数据通过一些简单的、非线性的、多层次表征模型,转变成为更高层次的、更加抽象的表达[25]。在处理人脸图像数据时,深度学习通过多层次的结构来学习人脸表情特征,与传统的机器学习相比,深度学习可以依靠自己的学习过程来进行人脸表情特征的提取,将提取到的表情特征融合成更复杂抽象的特征,再输入到表情分类器进行表情分类。因此结构模型的层数越多,学习到的表情特征更高级,深度学习网络的性能就会更强。目前基于深度学习的非正面表情识别方法,主要包括:基于卷积神经网络的识别方法、基于深度置信网络的方法、基于递归神经网络的方法、基于深度自动编码器的方法,以及基于生成对抗式网络的方法,以上几种算法比较如表3所示。
2.1 基于卷积神经网络的识别方法
卷积神经网络(Convolutional Neural Networks,CNN)[28]是一个具有层次结构的多层感知器。如图3所示:一个基础的CNN 是由输入层(input)、卷积层(convolution)、激活层(activation)、池化层(pooling)、全连接层(fully connecter)以及输出层(output)组成的。

表3 用于表情识别的深度学习算法比较
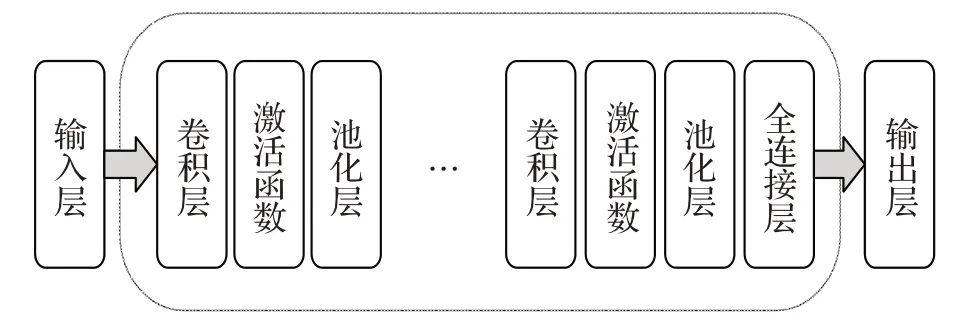
图3 卷积神经网络结构示意图
卷积层是网络中最核心的模块。主要作用是对图像进行特征提取;激活函数是用来模拟人的神经系统,只对部分神经元的输入做出反应。对卷积层的输出做一次非线性映射,不仅可以增加网络的表示能力,还能使网络具备良好的非线性建模能力;池化层主要作用是数据降维,从而减少计算量、内存使用量以及参数的数量,在一定程度上降低过拟合的可能性和提高模型的容错性;全连接层一般是CNN 网络中的最后一层。在经过卷积层、激活层、池化层进行特征提取之后,得到的结果作为全连接层的输入。损失函数用来衡量错误的程度以及用来指导网络训练的大体方向。它表示了预测值与真实值的不一致程度,即通过损失函数来计算样本预测分类的结果与真实类别的误差,利用反向传播算法将误差向前传播,从而指导网络的参数训练。在表情识别中,该方法可以对图像的相关特征和图形的拓扑结构进行自行提取。从CNN 提出至今,已出现了多种模型。2.1 节将对经典的CNN 模型进行详细介绍,并对不同模型的性能进行对比。
2.1.1 LeNet
LeNet 是LeCun 等[29]在1998 年设计的最早用于手写数字识别的卷积神经网络。具体结构如图4[29]所示。
经典的LeNet-5 网络模型由一个输入层、两个卷积层、两个池化层、两个全连接层和一个输出层组成,每层都包含不同的训练参数,是其他深度学习模型的基础。
文献[30]在LeNet-5网络的基础上对网络结构和内部结构进行了优化和改进。添加批量规范化,解决不同特征带来的网络模型过拟合问题。选择最大重叠池化和平均重叠池化减少数据量的同时,充分提取表情特征,有效提高了识别的准确率,增加了对光线、姿势和遮挡物状态下识别人脸表情的鲁棒性。但是还需将网络参数量大、运算量大、对运算设备要求高的问题考虑进去。文献[31]针对局部遮挡问题,提出改进的交叉链接多层LeNet-5 卷积神经网络模型。在LeNet-5 的基础上增加卷积层和池化层,从网络结构中提取的低级特征与高级特征相结合构造分类器,最后,使用Softmax分类器进行分类识别,在遮挡条件下具有较高的识别率。
2.1.2 AlexNet
2012 年,AlexNet[32]获得ILSVRC2012 比赛冠军,如图5[32]所示,该网络模型使用双GPU 并行训练,在LeNet-5 的基础上增加了激活函数ReLU,防止梯度消失,加速网络训练速度;网络使用数据增强并在全连接层使用Dropout,防止模型过拟合问题;提出LRN层,提高模型精度。
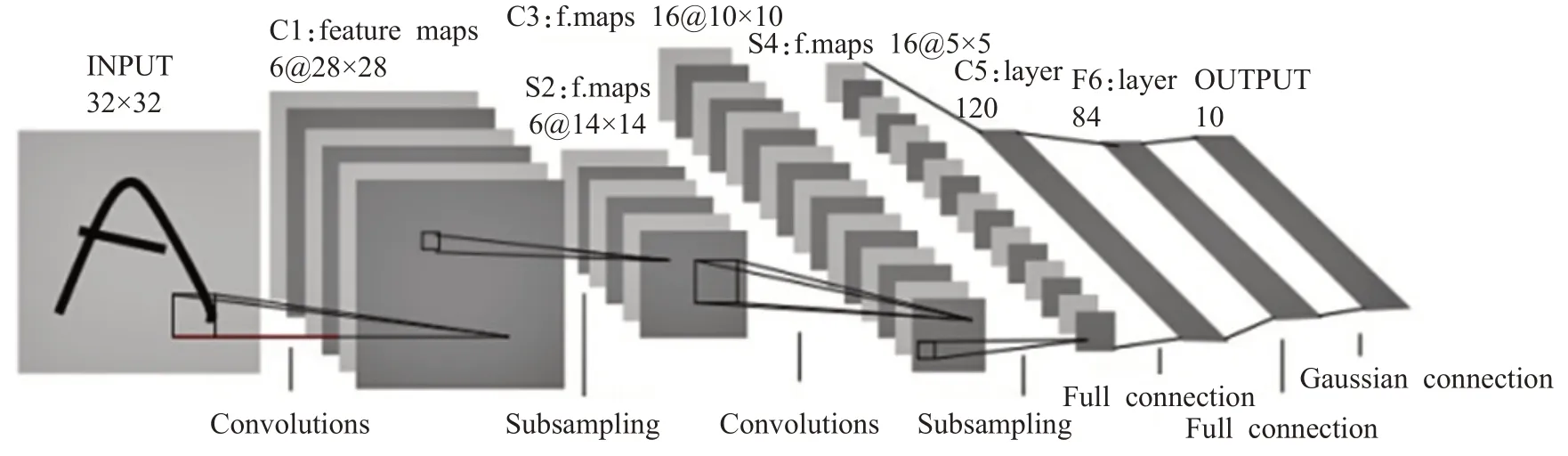
图4 LeNet-5网络结构图

图5 AlexNet网络结构图
文献[33]提出了一种基于LBP 特征映射与CNN 相结合的人脸表情识别算法。首先,将原始图像进行LBP特征映射之后,再送入改进后的AlexNet网络,最后,将LBP特征映射与CNN结合进行特征融合。该方法对光照变化具有很好的鲁棒性。
2.1.3 VGGNet
VGG 网络[34]由牛津大学视觉组和Google Deep-Mind 公司的研究员于2014 年提出,获得ILSVRC-2014中定位任务第一名和分类任务第二名。如表4 所示,VGGNet由5个卷积组、2个全连接特征层和1个全连接分类层组成。该网络实验证明,AlexNet中LRN层对性能的提升并无作用且浪费内存计算的损耗,且在AlexNet的基础上进行改进,使用较小的卷积核,较深的网络层次来提升深度学习的效果。

表4 VGGNet网络结构
文献[35]提出了一种端到端可训练的补丁门控卷积神经网络(PG-CNN),它可以自动感知人脸的遮挡区域,并聚焦于最具甄别性的未遮挡区域。该网络以人脸图像作为输入,图像被馈入VGG网络,并以某些特征图的形式表示;然后,PG-CNN 将整个人脸的特征图分解为24 个子特征图,用于24 个局部patch,每个局部patch被编码为一个加权的局部特征向量;最后,将加权后的局部特征进行级联,作为被遮挡人脸的表征。文献[36]使用改进的VGGNet网络对表情图像进行特征提取,以解决传统方法在表情特征提取方面特征表现能力不足的缺点,再将VGGNet 的最后一个全连接层去掉,设计一个4层神经网络模型对表情特征进行训练,在全连接层中添加BN层,使得每一层之间不会发生偏移。添加Dropout层,使整个网络变得稀疏,降低网络参数量。
2.1.4 GoogLeNet
GoogLeNet[37]在2014 年的ImageNet 比赛中获得第一名,该架构吸收了网络串联网络的思想,并在此基础上做了很大改进,在AlexNet的基础上,将多个不同尺寸的卷积核和池化层串联形成Inception结构,以找出最优的局部稀疏结构并将其覆盖为近似的稠密组件,大幅度减少参数数量,提升对网络内部计算资源的利用。
如图6 所示,Inception 网络结构里有4 个并行的分支,前3 个分支使用3 个不同尺寸的卷积核来提取不同空间尺寸下的信息,中间两个分支用1×1 的卷积核减少输入的通道数,以降低模型复杂度,第4 个分支则使用3×3 最大池化层,后接1×1 卷积核来改变通道数。在经过4个并行的分支对输入图像进行处理后,再将每个分支的输出在通道维度上连结,最后输入到下一层。
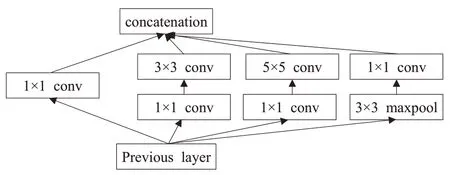
图6 Inception模块
文献[38]在GoogLeNet深度神经网络中引入Dropout方法,有效地减少了过拟合给训练过程带来的影响。文献[39]提出了一种深度神经网络结构。网络包括两个卷积层,每个层后面是最大池化层,然后是4个Inception层,该架构在7 个公开的面部表情数据库(MultiPIE、MMI、CK+、DISFA、FERA、SFEW 和FER2013)上进行了综合实验,其结果与最先进的方法相当,甚至更好,并且在精度和训练时间方面优于传统的卷积神经网络。
2.1.5 ResNet
针对深度学习的表情识别研究中,传统的提高识别精度的直接方法往往依靠网络深度的增加。然而简单通过叠加卷积层的方式来增加网络深度,有时并不能改善识别效果,反而使梯度减缓和梯度消失的现象变得十分严重,从而导致识别性能的迅速恶化。针对这一问题,何恺明等人[40]提出了残差网络(Residual Network,ResNet),在2015年的ImageNet比赛分类任务中获得第一名。
如图7 所示,ResNet 网络结构借鉴了HighWay Network[41],添加了捷径,相比于VGGNet,ResNet没有使用全连接层,而是使用全局平均池化层减少训练参数,并使用批量归一化(Batch Normalization,BN)方法,以促进深层网络的训练。

图7 一个残差模块
文献[42]提出一种跨数据集适应方案。设计了两个组件:(1)一个特征提取器,使用ResNet 学习图像特征,该网络降低了不同数据集之间的差异性,同时提高了对情感类别的判别能力;(2)一个情感标签提取器,使用卷积神经网络(CNN)来减少数据集之间的注释不一致性。再结合多个野外数据集,来解决面部表情识别中的两个主要问题:(1)数据集偏差;(2)类别不平衡。文献[43]针对自然状态下的人脸存在多视角变化、脸部信息缺失等问题,提出了一种基于MVFE-Light Net(Multi-View Facial Expression Lightweight Network)的多视角人脸表情识别方法。首先,引入了深度可分离卷积和ResNet 来减少网络参数,从而改善因网络层数增加而导致识别率下降的问题;其次,在该系统中嵌入压缩和奖惩网络模块来学习特征权重,通过加入空间金字塔池化的方式增强了网络的鲁棒性;最后,采用AdamW(Adam with Weight decay)优化方法使网络模型加速收敛来进一步优化识别结果。在RaFD、BU-3DFE和Fer2013表情库上的实验表明,该方法具有较高的识别率,且减少了网络计算时间。
2.1.6 其他方法
文献[44]采用级联网络的方法。通过将从CNN 中获得的强大感知视觉表示与长短期记忆(Long Short-Term Memory,LSTM)优势相结合,来实现可变长度的输入和输出。提出了在空间和时间上都较深的模型,该模型将CNN 的输出与LSTM 进行级联,以处理涉及时变输入和输出的各种视觉任务。
由于卷积神经网络具有权值共享、局部区域连接和降采样的结构特点,使其在图像处理领域表现较为出色。权值共享减少了网络需要训练的参数个数,同时降低了网络模型的复杂度,而降采样操作使其对于位移、缩放和扭曲,具有稳定不变性。卷积神经网络使用反向传播算法训练神经网络权值和阈值的调整,相比于其他网络结构更容易训练,CNN 的网络结构特点使其在各个领域已被广泛使用,但是,因为其网络结构的特殊性,使得网络在训练时耗时过长,成本较高,并且,卷积神经网络结构的泛化能力也有待提高。
大规模视觉识别挑战赛(ImageNet Large Scale Visual Recognition Challenge,ILSVRC)是近年来机器视觉领域最具权威的学术竞赛之一,CNN 模型在ILSVRC比赛中的性能对比如表5所示。
2.2 基于深度置信网络的方法
深度置信网络(Deep Belief Networks,DBN)[45]是Hinton 等人在2006 年提出的一种包含多层隐单元的概率生成模型。DBN生成模型通过训练网络结构中的神经元间的权重使得整个神经网络依据最大概率生成训练数据,形成高层抽象特征,提升模型分类性能[46]。作为深度神经网络的预训练部分,可以为网络提供初始化权重,并通过反向传播方法对网络进行参数优化,从而提高网络模型的特征学习能力。该模型的每一层都由受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)[47]组成。
网络结构如图8 所示。其中每个圆形符号表示RBM,它的作用是经过预训练初步完成整个深度置信网络的训练之后,采用反向传播的方法,从而提高深度置信网络模型的特征学习能力。RBM可以视为一个二分图模型,隐藏层与可见层之间双向连接,其中H 表示隐藏层,目的是将输入转换成输出层可以使用的东西,用于提取特征,V表示可见层(输入层),目的是输入数据。

图8 深度置信网络结构示意图
DBN 的优点在于,该方法通过预训练得到的初始化权重非常重要,这是因为在预训练这一阶段的权重往往比随机权重更接近最优权重,从而提升了网络的整体性能,让收敛速度加快[48]。该方法具有较强的无监督特征学习能力,在表情识别中,该方法主要用于特征提取和图像降维。
文献[49]使用像素级生成模型作为DBN 的最低级。DBN 可以从被遮挡的人脸中重建出完整的人脸,然后根据完整的人脸预测表情类别。

表5 ILSVRC比赛中CNN模型性能对比
若干个RBM“串联”起来构成了DBN,DBN通过无监督学习框架训练样本,更加抽象地学习高层特征,适用于学习高维复杂的数据。DBN可以很好地将深层特征保留下来,但是细节往往损失严重,为了尽可能地保留细节特征,研究人员还需对DBN进行改进。
2.3 基于递归神经网络的方法
递归神经网络(Recurrent Neural Networks,RNN)[50]是一种可以描述动态时间行为的深度学习方法。和前向传播的神经网络不同,RNN 是在自身网络中循环传递,从而起到了权重共享的作用。在深度学习方法中,RNN 的优点在于能够处理序列数据,其最大的特点就是神经元在某时刻的输出可以作为输入再次输入到神经元,这种串联的网络结构非常适合于时间序列数据,可以保持数据中的依赖关系[51]。
如图9所示,其中x代表RNN网络的输入,St表示时刻t的隐藏状态,Ot表示时刻t的输出,U表示输入层到隐藏层的权重矩阵,它能抽象原始输入,作为隐藏层的输入,V表示隐藏到输出层的权重矩阵,可以调度RNN 网络的记忆,W表示隐藏从到输出层的权重矩阵,它能抽象隐藏层所学习到的东西,并作为最终输出。在表情识别中,该方法主要用于来检测图像序列中的关键点以及行为识别等。

图9 递归神经网络展开图
但是简单的RNN模型在严格整合状态信息的过程中有一个显著的局限性,即所谓的“梯度消失”效应:在实践中,通过长期时间间隔反向传播错误信号的能力变得越来越困难[52]。为了解决这一问题,Hochreiter等人[53]提出了一种基于长短期记忆(LSTM)单元的递归神经网络。LSTM模块中具有一个记忆单元和三个门控单元:输入门、遗忘门和输出门。
如图10 所示,xt表示网络的输入向量,ht是当前隐藏层向量,ct表示记忆单元的输出。在LSTM长短期记忆模块中,记忆单元负责跟踪输入序列中的元素之间的依赖性;输入门it控制记忆单元的输入;遗忘门ft控制输入在记忆单元中保留程度;输出门ot控制网络的输出。
LSTM的控制流程与RNN相似,都是在前向传播的过程中处理流经细胞的数据,不同之处在于LSTM细胞的结构和运算有所变化。该网络通过门控制将短期记忆与长期记忆相结合,解决传统RNN 训练中出现的梯度消失现象和长时依赖问题。
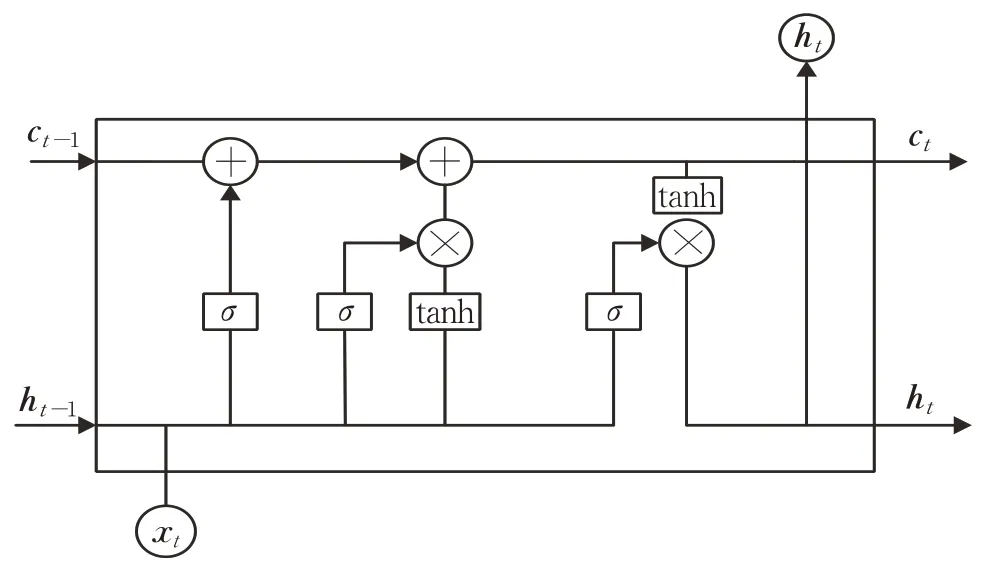
图10 LSTM单元结构
文献[54]和文献[55]都采用了CNN 和RNN 级联的方式,并且都利用了LSTM增强时间特征的学习。文献[54]提出了一种利用LSTM递归神经网络和卷积神经网络来捕获视频序列的时空特征的视频分类方法。首先使用强大的CNN来检测空间特征,然后使用RNN从这些空间特征的序列中学习时间特征,制作出CNN-RNN或CRNN系统,效果显著。文献[55]提出了用重要帧替换视频中不重要的帧的帧替换模块,以此提高RNN 的性能,建立了3D-CNN 和LSTM-RNN 级联的网络,在AFW、CK+、MMI 数据库上得到了有效验证。文献[56]提出一种基于图像序列的双通道加权混合深度CNN长短期记忆网络(Weighted Mixture Deep Convolution Neural Networks-Long Short-Term Memory,WMCNNLSTM)。混合深度卷积神经网络(Weighted Mixture Deep Convolution Neural Networks,WMDCNN)网络能够快速识别人脸表情,为WMCNN-LSTM 网络提供静态图像特征。WMCNN-LSTM 网络利用静态图像特征进一步获取图像序列的时间特征,实现了对面部表情的准确识别。
循环神经网络结构特点使其能记忆之前的信息,并利用记忆的信息影响后面节点的输出,得到的结果会更加准确,这种串联的网络结构在处理时间序列数据时很有优势。然而,RNN在面对长序列数据时,容易出现梯度爆炸和梯度消失的现象,使得RNN 并不能很好地处理长距离的依赖。LSTM是RNN的一种改进,LSTM通过引入记忆单元和门控制单元,在一定程度上解决了RNN 出现的梯度消失问题。但是,相较于RNN,LSTM含有更多的参数需要学习,从而导致LSTM的学习速率会大大降低。
2.4 基于深度自动编码器的方法
深度自动编码器(Deep Auto Encoders,DAE)[57]是一种利用神经网络对输入样本进行映射,从而实现特征提取的方法。该方法的优点在于自动编码器是从数据样本中自动学习的,这意味着很容易对指定类的输入训练出一种特定的编码器,而不需要完成任何新工作。如图11 所示,图像经过输入层进入编码器后得到的数据经过解码器到达输出层。在表情识别中,该方法主要用于降维、去噪和图像生成。
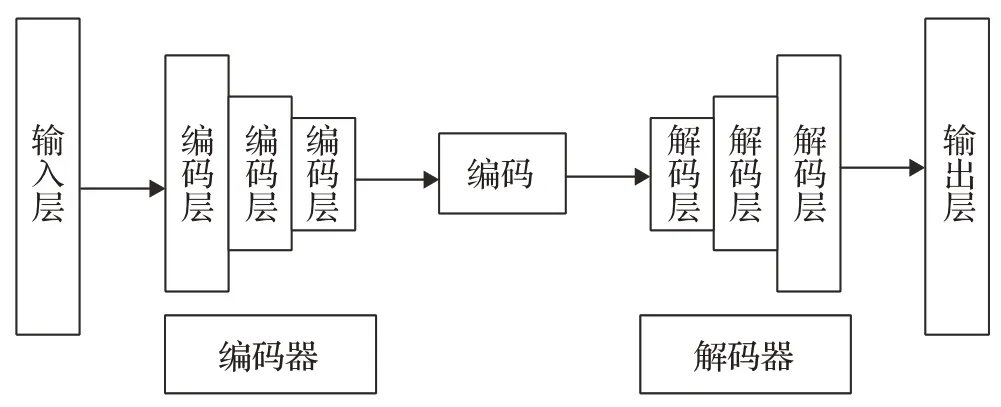
图11 深度自动编码器
文献[58]基于空间连贯特征的快速任意姿态人脸表情识别方法(Spatially Coherent Feature Learning For Pose-Invariant FER,Spatial-PFER)。首先,通过合成技术得到任意姿态人脸图像对应的正脸图像;其次,基于合成的正脸图像检测51 个关键特征点,并以此特征点为中心提取一定大小的关键区域,用来训练无监督特征学习算法稀疏自动编码器,以得到具有高区分度的高层表情特征;最后进行任意姿态的人脸表情识别。文献[59]提出一种基于内核的姿势特定非线性映射(Kernelbased Pose Specific Non-linear Mapping,KPSNM)来识别各种头部姿势下的面部表情。首先,将提出的特征向量串联;其次,利用基于稀疏编码器的方法将特征向量压缩,减少计算量;最后,使用所提方法将所有非正面数据映射到正面视图,再利用“正则化”数据进行面部表情识别。文献[60]提出将深度卷积网络(CNN)作为深度堆叠卷积自编码器(SCAE)在贪婪层无监督的方式预先训练。通过预先训练一个深度CNN 模型作为SCAE模型,以学习调整图像亮度并学习对照明不敏感的隐藏表示。
深度自动编码器能够在无监督式的情况下学习,仅关注最关键的特征,来产生输入的近似值,从而使提取的特征尽可能不受原始数据的污染。但是该网络需要训练的参数较多,花费的时间较长,容易出现过拟合现象。
2.5 基于生成对抗式网络的方法
生成式对抗网络(Generative Adversarial Networks,GAN)[61]是一种无监督的概率分布学习方法,该方法能够在不依赖任何先验假设的情况下,学习到高维且复杂的真实数据分布,并生成具有较高相似性的新数据集。GAN 的核心思想来源于博弈论中二人零和博弈,即使用判别器和生成器两个网络的对抗和博弈来处理生成问题。如图12 所示,生成器利用满足均匀分布或正态分布的随机噪声生成数据,判别器分辨出生成器的输出和真实数据之间的差异性,整个网络的优化过程就是寻找判别器和生成器网络之间的纳什均衡[62]。在表情识别中,该方法主要用于目标检测。
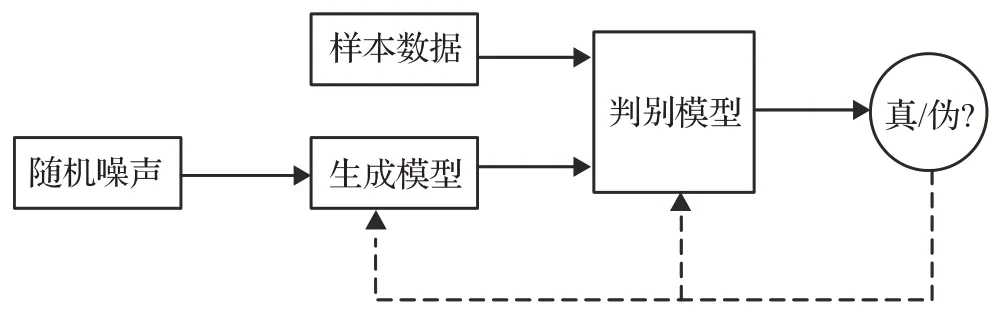
图12 生成对抗网络的结构图
文献[63]提出一种双通路生成对抗网络(Two-Pathway Generative Adversarial Network,TP-GAN),通过同时感知全局结构和局部细节来实现真实感正面图像的合成。文献[64]提出负载平衡生成对抗网络(Load Balanced Generative Adversarial Networks,LB-GAN)来精确地将输入人脸图像的偏航角旋转到任意指定的角度。LBGAN将具有挑战性的综合问题分解为两个约束良好的子任务,分别对应于一个面规范化器和一个面编辑器。归一化器首先将输入图像正面化,然后编辑器将正面化图像旋转到由远程代码引导的所需姿势。文献[65]提出一种基于生成对抗网络(GAN)的多任务学习方法。模型在人脸正面化过程中学习情绪并保留表征,学习到的表征对头部姿态变化较大的面部表情识别具有判别性,合成的正面人脸图像保持了识别任务中有效的表情特征。文献[66]提出一种新颖的基于Wasserstein 生成对抗网络方法来执行遮挡的面部表情识别。在用复杂的面部表情信息对面部遮挡图像进行补充之后,通过学习图像的面部表情特征来实现识别。文献[67]提出一种生成对抗网络用于遮挡重建。该模型是一种适用于图像转换的条件GAN 模型,对于合理的尺寸遮挡,能够消除遮挡的影响,并恢复基本模型的性能。文献[68]提出一种对人脸局部遮挡图像进行用户无关表情识别的方法。该方法能够为图像中的遮挡区域生成上下文一致的补全图像,缓解因局部表情信息缺失带来的影响,提高识别算法的鲁棒性。
GAN 的生成器接收随机变量同时生成“假”样本,判别器根据输入的样本判断其真假性,两者相互对抗彼此提升。独特的对抗思想使得GAN能生成更加真实的样本,而且GAN 框架可以训练任何生成器网络。尽管GAN已被广泛应用于图像视觉领域,但GAN仍有很多待解决的问题,生成器和接收器在训练过程中需要很好的同步,这使得网络难以收敛,训练也变得较为困难,而且GAN在学习生成离散数据时,效率很低。
深度学习算法在正面表情识别中已实现了较高的识别率,但是在非正面表情识别中的研究仍处于起步阶段。本文总结了近年来深度学习应用于非正面表情识别的表现,如表6所示。

表6 非正面表情识别的深度学习主要方法的性能
非正面人脸面部表情识别一直以来是计算机视觉、模式识别的研究热点。传统机器学习利用特征工程,人为对图像数据进行特征提取,其泛化能力较低,深度学习的出现打破了传统的先特征提取,后模式识别的固定模式,并且可以同时进行特征提取和表情分类。
卷积神经网络具有层级抽象的能力,能够利用全局信息进行学习,在图像领域获得了极大的成功,也不断有新的发展。深度学习在非正面表情识别上的应用,大多基于VGGNet、GoogLeNet 与ResNet 网络模型,其核心结构均为CNN。由于生成式对抗网络在生成高质量目标样本方面的优势,逐渐在面部表情识别领域中被使用,以进行姿势不变面部表情识别或增加训练样本的数量和多样性。该模型从生成器中直接提取出该信息用于减轻人物无关信息带来的干扰,从而提高表情识别率。RNN 及其扩展模型LSTM 作为基本的时序网络结构广泛运用于视频序列的学习。然而其网络结构使其难以捕捉到有效的图像特征。针对该问题,提出级联网络,将多个不同网络串联构成更深层次网络,首先提取出有表情判别能力的空间特征,然后将该信息依次输入到时序网络中进行时序信息的编码[70]。
需要注意的是,在表6 中,多数算法是在实验室环境下,采用标准数据库进行训练与识别的。然而在自然条件下,面部表情常常会受到像物体遮挡、光照变化、拍摄条件(设备、噪声)造成的图像分辨率低等不利因素的影响,而传统的机器学习方法无法提取图像的高级特征,需要深度神经网络更有效地学习特征。比如:(1)使用多网络融合,集合多种不同网络并结合各自优势以提取更深层的表情特征;(2)使用多任务网络,联合多个网络,通过共享相关任务之间的表征,减少数据参数以及整体模型复杂度,使预测更加高效;(3)使用级联网络,将两个结构不同的神经网络组合并设计更深的网络模型,以分层方法有序地训练多个网络以增强其特征学习能力。通过这些方法缓解网络模型的过拟合问题的同时,可以消除与面部表情无关的干扰因素。
3 总结和展望
本文首先陈述了课题的背景,接着介绍了深度学习常用的人脸图像数据库后,详细介绍了深度学习的神经网络、循环神经网络等算法结构和原理以及优缺点,接着对非正面表情识别的深度学习解决方案进行了详细介绍。通过分析现有研究成果,认为还有以下几方面是非正面人脸表情识别面临的挑战和可能的研究方向,目前非正面表情识别存在的问题进行总结如下:
(1)标准数据库不够真实。由于采集条件的不同和标注的主观性,数据偏差和标注不一致在不同的人脸表情数据集中非常普遍。最近的研究通常在特定的数据组内评估他们的算法,并能达到令人满意的性能[71]。然而,通过标准数据库训练的模型,往往在未知测试数据上不能取得令人满意的效果。现有的非正面表情数据库包含的人物状态与真实环境具有较大差异,因此导致从标准数据库中训练出来的算法,在推广性方面差强人意,还达不到实用的要求。
(2)训练成本过高。较传统的特征提取和表情分类方法,很多深度学习模型已经可以得到较好的准确率,但在训练过程中,由于深度学习模型的复杂度较高,需要训练的模型参数较多,因而导致算法训练成本高、耗时长。
(3)数据类型单一。现有方法多针对静态图像,开展非正面表情识别研究;而在针对动态图像的非正面人脸表情识别中,由于受光照、遮挡物以及时间因素的影响,算法的识别性仍有待改进。
针对上述问题,考虑可以从以下三个方面入手:
(1)跨数据库性能是面部表情识别系统通用性和实用性的重要评价标准[72-73]。针对数据库问题,构造一个具有丰富自然环境下的人脸表情数据集,是解决真实环境下,保持算法识别率、提升算法推广性与鲁棒性的有效方法。目前出现的自然环境下的表情数据集有AFEW[14],然而由于数据集从电影中提取而来,与自然环境下的人脸图像存在一定差异,这使得该数据集的应用非常小众。但是这仍然是解决该问题的有效方法。
(2)非正面表情识别相对耗时,近年来,许多研究者在深度学习压缩和加速方面,提出了可从以下三个角度进行优化:
①算法层压缩加速。深度神经网络存在大量的参数冗余,网络剪枝目的是移除冗余连接,减少网络的计算量。文献[74]提供了一种结合延迟、网络条件和移动设备的计算能力的上下文感知修剪算法,以获得最佳的深度学习模型,但该方法只注重模型性能,模型训练速度有待提高;权值量化通过减少表示每个权重的比特数,来压缩神经网络。文献[75]对权重参数采取了k均值聚类后量化的方法,对网络进行压缩,虽然该方法加快了网络的速度,但在大规模数据集上表现较差;知识蒸馏[76]的本质是学生对教师的拟合,用于将一个深且宽的网络压缩为一个小型网络,该方法虽然简单,但在多个图像分类任务中取得了很好的效果。
②框架层加速。目前出现的DenseNet[77]在模型优化方面,减少了训练参数,且所需计算量少,与现有算法相比,具有更高的精确度。但该方法着重关注模型结构的优化,而忽略了模型运算速度。Mobile[78]采用了深度可分离卷积,以达到减少网络权值参数和提升模型运算速度的目的。该方法在非正面表情识别的研究中,具有较大潜力。
③硬件层加速。可以通过优化硬件配置,获取性能提升。
(3)深度学习模型在针对动态图像的非正面人脸表情识别中,仍无法取得较好的泛化能力以及算法鲁棒性。针对该问题,文献[54]采用级联网络,先提取图像的空间特征,然后将其输入到时序网络并提取图像的时序特征,以实现动态图像的表情识别。这种网络级联的形式可以较好地解决动态图像的表情识别,是处理动态图像中非正面表情识别研究的有效尝试。
在人工智能迅速发展的大环境下,对非正面人脸表情的实时识别与分析需要显著,非正面人脸表情识别的研究前景也变得更为广阔,非正面人脸表情识别未来的发展可以从以下方向探索:
(1)实用性。目前针对非正面表情识别的研究方案计算量较大,训练时间也较长,对硬件设备要求较高,导致其难以使用到轻便设备中,随着移动终端的大面积普及,如何将深度学习模型运用到移动端与嵌入式设备中,增加表情识别实用性,有待进一步研究。
(2)微表情。微表情是一种自发性的表情,动作幅度小、持续时间短,建立微表情数据库,将表情识别的方法用于微表情进行识别将是未来研究的重点。
(3)多模态表情识别。目前的多模态情感分析方法主要集中在深度神经网络[79]。人的情感表达方式有多种方式,面部表情只是其中的一种模态,可以考虑与其他模态结合到一个高层的框架中,彼此提供互补信息,进一步增强模型的鲁棒性。例如:可以将音频与图像相融合进行多模态的表情识别。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
少儿美术·书法版(2021年9期)2021-10-20 06:35:00
电子制作(2019年19期)2019-11-23 08:42:00
电子制作(2019年11期)2019-07-04 00:34:38
动漫星空(2018年9期)2018-10-26 01:17:14
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
发明与创新(2015年33期)2015-02-27 10:40:09
