
基于深度强化学习的黑盒对抗攻击算法
2021-04-23 12:55韩立新
计算机与现代化 2021年4期
李 蒙,韩立新
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
随着深度神经网络(Deep Neural Network, DNN)的广泛应用,人脸识别[1]、目标检测[2]、目标跟踪[3]等领域都出现了与DNN相结合的方法。在图像识别领域中,基于深度神经网络的方法甚至已经超越了人眼的识别效率。尽管在许多领域中DNN取得了成功,但一些研究发现DNN很容易受到一些人为的微小扰动的干扰,从而产生错误的结果。Szegedy等[4]首次提出将微小扰动添加到图像上的方法并成功欺骗了当时最先进的图像分类DNN模型,这些被误分类的图像被称为对抗样本,这种对模型输入进行微小扰动,试图使模型产生错误输出的算法被称为对抗攻击算法。当DNN模型部署到涉及安全、隐私等领域的应用上时,对抗样本的存在会对这些应用的可靠性造成重大影响,因此研究对抗攻击方法具有重要意义。
对抗攻击算法可以根据攻击目的分为2类[5]:1)目标攻击,攻击者使受攻击的模型将对抗样本误分类到指定的类别;2)非目标攻击,不指定攻击的类别,使受攻击模型产生错误的分类结果即可。根据攻击者获得的受攻击模型知识,还可以将对抗攻击方法分为2类[5]:1)白盒攻击,攻击者可以利用受攻击模型的所有信息,如模型的结构、参数和训练方法等;2)黑盒攻击,攻击者只能与受攻击模型进行交互以获得有限的知识,如模型的输出等,目前主要有基于对抗样本迁移性的攻击和基于交互的攻击。根据模型输出信息的特点,可以将基于交互的攻击分为基于分数的攻击和基于决策的攻击[6],基于分数的攻击需要模型输出样本的预测分数,基于决策的攻击仅需要模型离散的标签输出。
本文针对非目标黑盒攻击问题提出一种基于深度强化学习的黑盒对抗攻击算法(Deep Reinforcement Learning Black-box Adversarial attack, DRLBA),通过对干净图像迭代扰动生成对抗样本,利用奖励函数约束对抗样本质量。本文提出的对抗攻击算法仅需要受攻击模型输出标签,不需要输出标签的概率。在对抗攻击的研究中,尚未出现与深度强化学习方法结合的算法,本文提出的深度强化学习黑盒对抗攻击算法将对抗样本的生成问题转化为寻找最优决策序列问题,智能体与受攻击分类器交互获得奖励信号,使智能体具有生成高质量对抗样本的能力。
1 相关工作
1.1 对抗攻击
近年来,研究人员提出了大量的对抗攻击算法,其中基于白盒和基于黑盒的对抗攻击方法引起了学术界和工业界的广泛关注。
Szegedy等人[4]首次提出了对抗攻击的概念并在白盒条件下通过L-BFGS算法生成对抗样本,但由于L-BFGS算法采用线性搜索方法搜索最优值,导致计算代价过大。在此基础上,Goodfellow等[7]提出了快速梯度符号算法(Fast Gradient Sign Method, FGSM)生成对抗样本。FGSM算法在白盒条件下计算受攻击模型的输入导数,并通过符号函数获取最大化损失函数的梯度方向,最终将生成的扰动和原输出相加获得对抗样本。Goodfellow等认为DNN模型在高维空间的线性性导致了对抗样本的产生,但Dropout等正则化方法并不能提高DNN的鲁棒性。Papernot等[8]提出了白盒条件下利用雅可比矩阵计算前向导数生成对抗样本的算法,但存在当输入的维数过高时,计算雅可比矩阵的代价极高这一问题,还没有得到有效的解决。
相对于白盒的对抗方法,Chen等[9]提出了基于零阶优化(Zeroth Order Optimization, ZOO)的黑盒对抗攻击算法,通过估计受攻击模型的梯度来生成对抗样本,该算法在测试阶段需要与受攻击模型进行大量的交互,这增加了在实际应用中被发现的风险。因此,Su等[10]提出了基于进化计算的黑盒攻击算法,仅改变了干净图像的一个像素就使得DNN分类错误,使用了进化计算中的遗传算法对初始种群迭代地交叉变异,保留适应度高的子代并淘汰适应度低的子代,通过这个过程引导子代向最优解逼近,初始种群和迭代次数越多则成功率越高,但基于进化计算的攻击算法需要的计算资源极高,且仅单个像素的扰动很容易被人眼发现。
目前大部分算法都是通过直接或间接的方式计算受攻击模型的梯度,但没有考虑到扰动对于图像语义信息影响的问题,因此本文的算法从干净图像和对抗样本间的视觉关系出发[11],生成的对抗样本只改变图像的颜色而不影响图像的物体形状。
1.2 深度强化学习
强化学习是一种智能体通过执行动作不断地与环境交互获得奖励进而获得最大累计奖励策略的一种学习方法[12]。深度强化学习是强化学习和深度学习的结合,经常用于一些状态空间极大任务上,如Atari2600视频游戏[13]、棋类游戏[14]等。
Mnih等人[13]提出使用深度Q网络(Deep Q-Network, DQN)拟合值函数,DNN输出值函数后结合ε-贪婪(ε-greedy)策略输出动作。Van Hasselt等人[15]提出了双DQN(Double DQN, DDQN)算法,将计算目标Q值和选择动作的过程分开,缓解了DQN算法过高估计动作值函数的问题。
Wang等人[16]提出了Dueling神经网络结构,分别估计状态价值(Value)函数和动作优势(Advantage)函数,合并后组成动作价值函数,加快了DQN的收敛速度。
本文提出的DRLBA方法将对抗样本的生成问题转化为寻找最优决策序列的马尔可夫决策(Markov Decision Process, MDP)问题,使用全局色彩调整操作定义动作空间,智能体执行动作后接受由受攻击模型的分类结果、干净图像和对抗样本结构相似性组成的奖励。奖励用于训练智能体进行攻击,使得智能体拥有生成高质量对抗样本的能力。本文使用DDQN框架和Dueling神经网络结构解决MDP问题。
2 问题描述
在使用图像处理软件时,使用者通过应用一组色彩操作来调整图像,这种色彩调整操作对图像的物体形状信息影响较小。本文将色彩调整的操作用于生成对抗图像,这种方式的优势在于生成的图像符合人类的视觉,不易丢失物体形状信息。
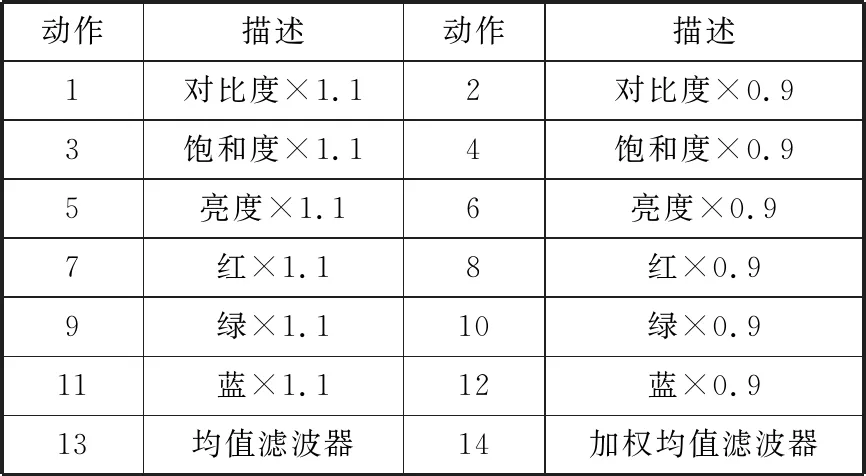
表1 DRLBA动作空间
本文将对抗攻击表述为智能体寻找使受攻击模型F误分类的最佳色彩调整动作序列问题。该问题可以看作一个MDP问题,其中状态空间S由干净图像和对抗样本的拼接(Iraw,Iadv)组成。动作空间A如表1所示,由14个色彩调整操作组成,动作空间中的滤波器操作用于平滑图像,滤波器的大小均为3×3。对每一张干净图像I,限制最多的色彩调整次数T。奖励信号由受攻击模型的分类结果、干净图像和对抗样本的结构相似度指数[17](Structural SIMilarity index, SSIM)组成,SSIM在超分辨率[18]、图像修复[19]等领域有重要应用。SSIM基于图像x和y的亮度l(x,y)、对比度c(x,y)、结构s(x,y)等3个距离度量:
(1)
(2)
s(x,y)=(σxy+c3)/(σxσy+c3)
(3)
SSIM(x,y)=l(x,y)c(x,y)s(x,y)
(4)
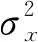
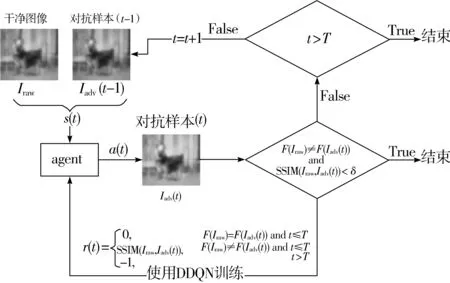
图1 DRLBA训练流程图
如图1所示,t步时,本文将干净图像Iraw和对抗样本Iadv(t-1)的拼接作为智能体的输入s(t),智能体根据神经网络输出的动作a(t)∈A和ε-贪婪策略生成对抗样本Iadv(t),然后受攻击模型对Iadv(t)进行分类,SSIM(Iraw,Iadv(t))>δ且分类错误则攻击成功,否则继续进行扰动,在到达最大扰动次数T后结束本次攻击。奖励函数设计为:
(5)
3 实验及分析
3.1 实验设置
实验环境:实验使用语言为Python,采用PyTorch深度学习框架,在Manjaro 18.04操作系统上实现。
数据集:1)CIFAR10数据集[20],由50000张训练集图像和10000张测试集图像组成,图像大小均为3×32×32,图像标签共有10类,每一类都包含5000张训练图像和1000张测试图像;2)CIFAR100数据集[20],由50000张训练集图像和10000张测试集图像组成,图像大小均为3×32×32,图像标签共有100类,每一类都包含500张训练图像和100张测试图像。本文仅使用被受攻击模型分类正确的训练集的图像训练智能体。
受攻击模型:本文使用SENet18[21]、VGG19[22]、GoogLeNet[23]、ResNet18[24]作为受攻击模型。在训练智能体时,仅使用SENet18与智能体交互。CIFAR10数据集和CIFAR100数据集上训练的受攻击模型结构仅在全连接输出层不同。SENet18、VGG19、GoogLeNet、ResNet18在CIFAR10测试数据集上的准确率为94.10%、94.65%、94.75%、94.82%,在CIFAR100测试数据集上的准确率为77.19%、69.90%、74.92%、76.52%。
对比实验:本文使用FGSM作为对比算法,限制FGSM的最大扰动范围eps=0.03。FGSM算法仅进行白盒非目标攻击。
3.2 实验参数
智能体:本文使用DDQN框架和Dueling网络结构训练智能体,智能体的神经网络结构如图2所示,由8个卷积层和3个最大池化层提取特征,动作优势函数全连接层和值函数全连接层组合成为输出。智能体根据神经网络输出和ε-贪婪策略输出动作。在训练阶段,仅使用SENet18作为受攻击模型,ε从0.9衰减到0.1,在测试阶段,使用SENet18、VGG19、GoogLeNet、ResNet18作为受攻击模型,设置ε=0。
优化算法:本文使用Adam算法[25]训练智能体,batchsize设置为128,初始学习率设置为0.0001。
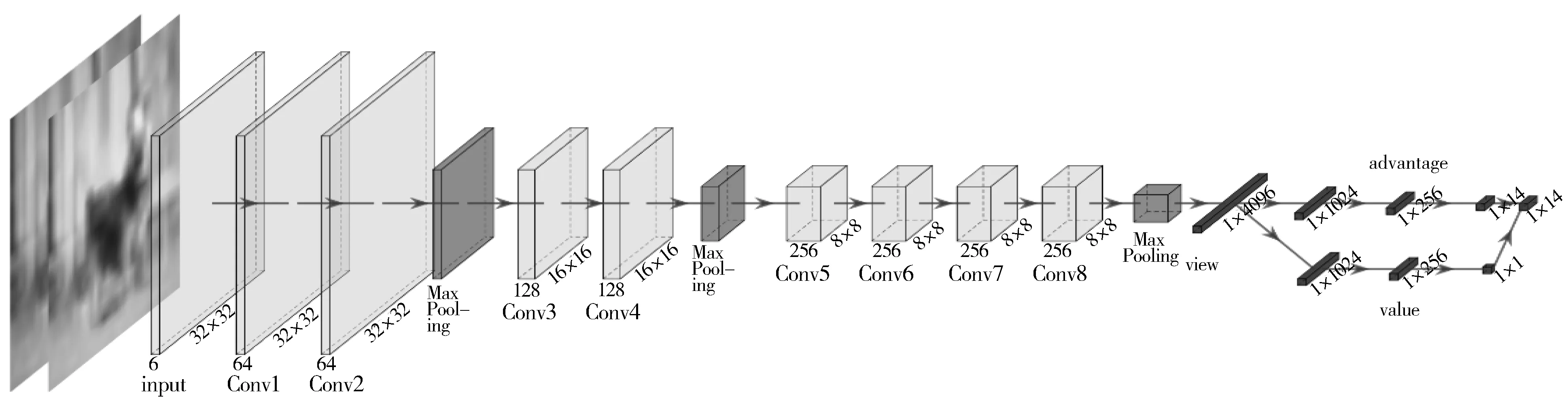
图2 智能体神经网络结构图
3.3 实验结果及分析
本文采用DRLBA算法、FGSM算法和4种分类模型在CIFAR10、CIFAR100数据集上进行对比实验。FGSM和DRLBA都是通过对干净样本添加全局扰动生成对抗样本。FGSM通过计算模型的导数进行单步攻击,DRLBA通过与模型交互进行迭代攻击,与模型的最大交互次数由参数T控制。本文使用攻击成功率评价攻击算法的攻击能力,用平均SSIM评价对抗样本的质量。
CIFAR10、CIFAR100数据集上的实验结果如表2所示,攻击算法仅攻击被受攻击模型正确分类的图像,仅计算攻击成功的对抗样本的平均SSIM。本文提出的基于强化学习的黑盒攻击算法在CIFAR10测试集和4个受攻击模型上的攻击成功率均超过了90%,在CIFAR100测试集和4个受攻击模型上的攻击成功率均超过了96%,FGSM算法仅在CIFAR100数据集上攻击SENet18时成功率超过了本文提出的攻击算法,在其他受攻击模型上的成功率不稳定且低于DRLBA。
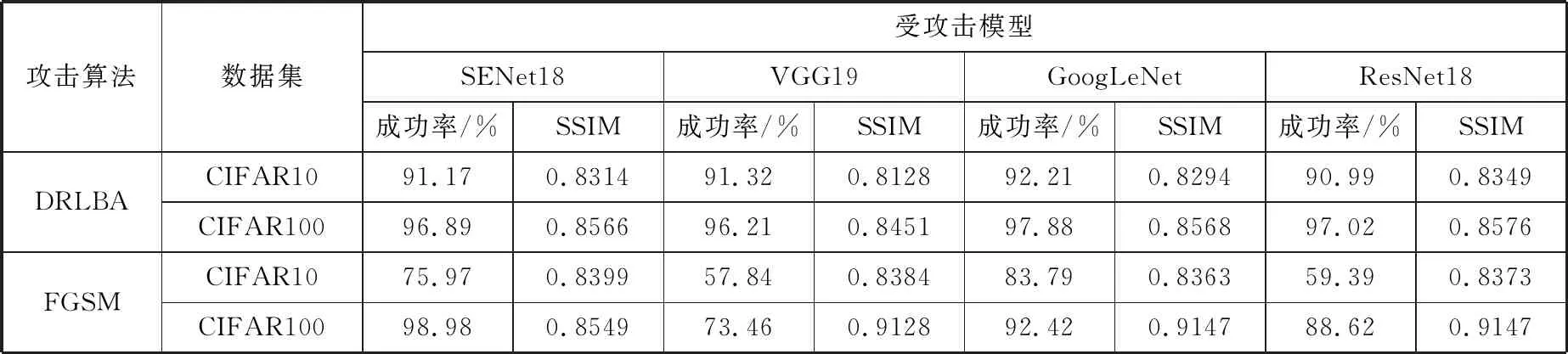
表2 各数据集上的攻击成功率和SSIM比较
本文提出的攻击算法在CIFAR10和CIFAR100数据集上取得了理想的攻击效果。图3展示了DRLBA生成的对抗样本示例,并注明了视觉标签,受攻击模型将第1列中的飞机误分类为鸟,将第2列中汽车误分类为猫,将第3列中鸟误分类为猫等。对抗样本只改变了干净样本的颜色属性,对图像的语义影响很小。

图3 DRLBA对抗样本示例
4 结束语
在黑盒非目标攻击的环境下,本文提出了基于深度强化学习的黑盒对抗攻击算法,该方法使用色彩调整动作对干净样本进行迭代扰动,攻击成功时返回对抗样本和干净样本的结构相似度作为奖励以训练智能体。本文提出的算法仅需要受攻击模型提供离散的决策信息,实验结果表明,在结构复杂的神经网络模型上能够达到较好的攻击效果。下一步工作将提高攻击范围,扩展到目标攻击任务上,在更复杂的环境下进行对抗攻击。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
数学物理学报(2022年4期)2022-08-22
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2019年4期)2019-10-10
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
贵州师范学院学报(2016年3期)2016-12-01
电源技术(2015年11期)2015-08-22
新课程学习·中(2013年3期)2013-06-14
